【项目】年会抽奖系统
一、业务模块设计
- 人员管理:管理员的登录(手机+密码、手机+验证码)、注册;普通用户增加、查询。
- 奖品管理:奖品增加、查询。
- 活动管理:活动的增加并圈选人员和奖品,查询活动状态。
- 抽奖服务:展示奖品、抽奖、分享结果。
- 通知服务:短信、邮箱通知中奖信息。
二、数据库设计
- 创建主键(添加主键时自动会创建)、唯一、普通索引,提高高频查询字段的查询效率。
- 命名按照 阿里巴巴规范。
- 包含创建、更新时间,以便后续需要时可查询。
- 若想加删除功能:删除时仅逻辑删除,加上 delete_flag 标记,1 为删除,0 为正常。
- 抽奖结果包含:活动、中奖人员、奖品信息。因为抽奖结果是历史结果,因此活动、人员、奖品表的更新不会影响到抽奖结果表。为了提高查询效率(避免联合查询),我们将具体信息字段冗余在抽奖结果表中。
- 因为我们需要将活动与奖品、人员绑定,需要设计活动-奖品表、活动-人员表。
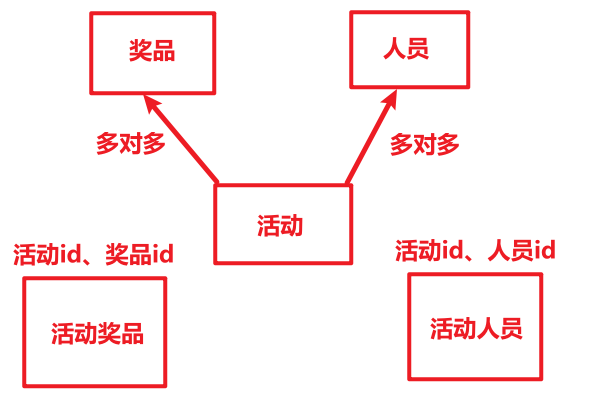
- 关于活动-奖品表:奖品数量、奖品等级是活动创建时设置,故不能从奖品表中查询。活动奖品状态:奖品是否被抽完。
- 关于活动-用户表:为什么不从用户表查用户名?一是加快查询效率,二是避免把用户删了,历史设置的活动用户就没了。活动用户状态:用户是否已中奖,中奖了就不能再抽了。
- 关于人员表:因为需要频繁查询 email、phone 来校验是否唯一,或者给用户发送中奖通知,所以对他们建立了索引。
-- 设置客户端(Navicat、命令行、Spring Boot JDBC驱动等)与服务器(运行数据库服务的主机)之间的字符集为utf8mb4,告诉数据库用 Unicode 字符集解析、编码。
SET NAMES utf8mb4;
-- 关闭外键约束检查,删除表时,主表删除某条 id 信息,会查看子表是否也有该 id 相关的信息,有的话会报错。
-- 我们想不顾设计好的表的顺序建表、删表,就需要暂时关闭。建好数据库后再开启外键检查约束。
SET FOREIGN_KEY_CHECKS = 0;drop database IF EXISTS `lottery_system`;
create DATABASE `lottery_system` CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;USE `lottery_system`;-- ----------------------------
-- Table structure for activity 用于展示活动详情
-- ----------------------------
drop table IF EXISTS `activity`;
create TABLE `activity` (`id` bigint UNSIGNED NOT NULL AUTO_INCREMENT comment '主键',`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP comment '创建时间',`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON update CURRENT_TIMESTAMP comment '更新时间',`activity_name` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL comment '活动名称',`description` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL comment '活动描述',`status` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL comment '活动状态',PRIMARY KEY (`id`) USING BTREE,UNIQUE INDEX `uk_id`(`id` ASC) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 24 CHARACTER SET = utf8mb3 COLLATE = utf8mb3_general_ci ROW_FORMAT = DYNAMIC;
-- ENGINE = InnoDB:指定表的存储引擎为InnoDB,这是MySQL的默认存储引擎,支持事务、外键等特性。
-- AUTO_INCREMENT = 24:为自动增长的ID字段设置起始值。
-- ROW_FORMAT = DYNAMIC:变长字段(如 VARCHAR、TEXT、BLOB)只存储前 768 字节在主记录页里,剩余的内容存储在单独的溢出页里,主记录只保留一个指向溢出页的指针。
-- 存放在溢出页,而不存放在主记录目的:防止页分裂,导致查询时进行更多的磁盘IO-- ----------------------------
-- Table structure for activity_prize 用于将活动与奖品关联
-- ----------------------------
drop table IF EXISTS `activity_prize`;
create TABLE `activity_prize` (`id` bigint UNSIGNED NOT NULL AUTO_INCREMENT comment '主键',`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP comment '创建时间',`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON update CURRENT_TIMESTAMP comment '更新时间',`activity_id` bigint NOT NULL comment '活动id',`prize_id` bigint NOT NULL comment '活动关联的奖品id',`prize_amount` bigint NOT NULL DEFAULT 1 comment '关联奖品的数量',`prize_tiers` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL comment '奖品等级',`status` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL comment '活动奖品状态',PRIMARY KEY (`id`) USING BTREE,UNIQUE INDEX `uk_id`(`id` ASC) USING BTREE,UNIQUE INDEX `uk_a_p_id`(`activity_id` ASC, `prize_id` ASC) USING BTREE,INDEX `idx_activity_id`(`activity_id` ASC) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 32 CHARACTER SET = utf8mb3 COLLATE = utf8mb3_general_ci ROW_FORMAT = DYNAMIC;-- ----------------------------
-- Table structure for activity_user
-- ----------------------------
drop table IF EXISTS `activity_user`;
create TABLE `activity_user` (`id` bigint UNSIGNED NOT NULL AUTO_INCREMENT comment '主键',`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP comment '创建时间',`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON update CURRENT_TIMESTAMP comment '更新时间',`activity_id` bigint NOT NULL comment '活动id',`user_id` bigint NOT NULL comment '圈选的用户id',`user_name` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL comment '用户名',`status` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL comment '用户状态',PRIMARY KEY (`id`) USING BTREE,UNIQUE INDEX `uk_id`(`id` ASC) USING BTREE,UNIQUE INDEX `uk_a_u_id`(`activity_id` ASC, `user_id` ASC) USING BTREE,INDEX `idx_activity_id`(`activity_id` ASC) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 3 CHARACTER SET = utf8mb3 COLLATE = utf8mb3_general_ci ROW_FORMAT = DYNAMIC;-- ----------------------------
-- Table structure for prize
-- ----------------------------
drop table IF EXISTS `prize`;
create TABLE `prize` (`id` bigint UNSIGNED NOT NULL AUTO_INCREMENT comment '主键',`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP comment '创建时间',`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON update CURRENT_TIMESTAMP comment '更新时间',`name` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL comment '奖品名称',`description` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NULL DEFAULT NULL comment '奖品描述',`price` decimal(10, 2) NOT NULL comment '奖品价值',`image_url` varchar(2048) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NULL DEFAULT NULL comment '奖品展示图',PRIMARY KEY (`id`) USING BTREE,UNIQUE INDEX `uk_id`(`id` ASC) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 18 CHARACTER SET = utf8mb3 COLLATE = utf8mb3_general_ci ROW_FORMAT = DYNAMIC;-- ----------------------------
-- Table structure for user
-- ----------------------------
drop table IF EXISTS `user`;
create TABLE `user` (`id` bigint UNSIGNED NOT NULL AUTO_INCREMENT comment '主键',`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP comment '创建时间',`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON update CURRENT_TIMESTAMP comment '更新时间',`user_name` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL comment '用户姓名',`email` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL comment '邮箱',`phone_number` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL comment '手机号',`password` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NULL DEFAULT NULL comment '登录密码',`identity` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL comment '用户身份',PRIMARY KEY (`id`) USING BTREE,UNIQUE INDEX `uk_id`(`id` ASC) USING BTREE,UNIQUE INDEX `uk_email`(`email`(30) ASC) USING BTREE,UNIQUE INDEX `uk_phone_number`(`phone_number`(11) ASC) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 39 CHARACTER SET = utf8mb3 COLLATE = utf8mb3_general_ci ROW_FORMAT = DYNAMIC;-- ----------------------------
-- Table structure for winning_record
-- ----------------------------
drop table IF EXISTS `winning_record`;
create TABLE `winning_record` (`id` bigint UNSIGNED NOT NULL AUTO_INCREMENT comment '主键',`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP comment '创建时间',`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON update CURRENT_TIMESTAMP comment '更新时间',`activity_id` bigint NOT NULL comment '活动id',`activity_name` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL comment '活动名称',`prize_id` bigint NOT NULL comment '奖品id',`prize_name` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL comment '奖品名称',`prize_tier` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL comment '奖品等级',`winner_id` bigint NOT NULL comment '中奖人id',`winner_name` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL comment '中奖人姓名',`winner_email` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL comment '中奖人邮箱',`winner_phone_number` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL comment '中奖人电话',`winning_time` datetime NOT NULL comment '中奖时间',PRIMARY KEY (`id`) USING BTREE,UNIQUE INDEX `uk_id`(`id` ASC) USING BTREE,UNIQUE INDEX `uk_w_a_p_id`(`winner_id` ASC, `activity_id` ASC, `prize_id` ASC) USING BTREE,INDEX `idx_activity_id`(`activity_id` ASC) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 69 CHARACTER SET = utf8mb3 COLLATE = utf8mb3_general_ci ROW_FORMAT = DYNAMIC;-- SET FOREIGN_KEY_CHECKS = 1;:在脚本的最后,重新开启外键约束检查。
SET FOREIGN_KEY_CHECKS = 1;
三、公共模块
1、错误码和异常
- 错误码可方便客户端区分错误,前端人员根据不同错误码提供不同前端页面。后端人员可根据错误码追踪日志、定位错误。
- 错误码分层、分类:全局错误码(成功、系统错误,程序员 try-catch 的、未知错误,程序员没有处理的)、controller 层错误码(参数校验等)、service 层错误码(业务办理失败错误、数据库操作错误(dao 层的异常也会在 service 层处理))。
- 异常类也分层:根据抛出的异常类型不同,快速定位异常所在层。异常类是供后端抛出然后catch 打日志的。
- 用枚举类定义常量,枚举类是单例模式,对于每种错误码,只需创建一次实例,不可以 setter、只能 getter,更安全。
- 对于异常类、返回类型,这些经常被传输给前端、本地持久化、缓存的类,需要序列化才能完成。如果用 JDK 原生序列化等工具,会要求标识 Serializable,所以建议需要序列化/反序列化的类实现 Serializable,便于之后的扩展。而异常类的父类本就加了 Serializable,所以自己定义的异常类不用加。如果某个对象需要反序列化,需要定义无参构造方法,因为反序列化时,是先用无参构造方法创建空壳子,再通过反射填充对象属性。
- 当比较两个异常类时,如果不设置比较父类的属性(如果没 super(message),默认是 null),则只会比较子类的属性,这样是不准确的。为了便于之后扩展,构造方法加了 super(xxx),所以也要比较父类。
@EqualsAndHashCode(callSuper = true)
2、统一返回值类
- 为了便于前端根据返回值,给出不同的处理,我们把返回值统一封装。一是便于区分(code),二是便于处理(统一判断 code = 200,做成功的逻辑),不用再根据不同的 data 设计不同的 if 判断。
![]()
3、Jackson 序列化/反序列化工具
- 把对象用日志的形式输出,需要序列化。对象在内存中以二进制存储,而传输、存储到外存、缓存要以字符串的形式,为了避免针对不同类重写 toString,我们使用序列化/反序列化工具转换。
- 使用 jackson 的 writeValueAsString、readValue 时都要处理异常,为了避免重复的处理代码,我们模仿 jackson 源码中的 tryParse 方法统一处理异常。其中有一个 Callable 类型参数,类似于 Runnable,不同的是可以有返回值。因为序列化需要返回字符串或对象,所以重写 Callable 的 call 方法执行序列化/反序列化。
- 另外,在反序列化时,需要提供反序列化后的对象类型作为 readValue 参数。因此,若是反序列化为泛型类对象,需要构造类型。
- 使用了单例设计模式,ObjectMapper 实例化只在类加载好后执行一次,getter 方法供外界使用,不提供 setter。
4、配置日志
使用 Spring Boot 内置的 SLF4J。
yml 配置日志配置文件路径:classpath 表示 resource 路径下。
logging:config: "classpath:logback-spring.xml"xml 日志配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="60 seconds" debug="false"><!--开发环境--><springProfile name="dev"><!--输出到控制台--><appender name="console" class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern>%d{HH:mm:ss} [%thread] %-5level %logger{36} - %msg%n%ex</pattern></encoder></appender><!--日志级别为INFO及以上,输出到控制台--><root level="info"><appender-ref ref="console" /></root></springProfile><springProfile name="prod,test"><!--ERROR级别的日志放在logErrorDir目录下,INFO级别的日志放在logInfoDir目录下--><!--变量名,具体值--><property name="logback.logErrorDir" value="/root/lottery-system/logs/error"/><property name="logback.logInfoDir" value="/root/lottery-system/logs/info"/><property name="logback.appName" value="lotterySystem"/><contextName>${logback.appName}</contextName><!--ERROR级别的日志配置如下--><appender name="fileErrorLog" class="ch.qos.logback.core.rolling.RollingFileAppender"><!--日志名称,如果没有File 属性,那么只会使用FileNamePattern的文件路径规则如果同时有<File>和<FileNamePattern>,那么当天日志是<File>,明天会自动把今天的日志改名为今天的日期。即,<File> 的日志都是当天的。--><File>${logback.logErrorDir}/error.log</File><!-- 日志level过滤器,保证error.***.log中只记录ERROR级别的日志--><filter class="ch.qos.logback.classic.filter.LevelFilter"><level>ERROR</level><onMatch>ACCEPT</onMatch><onMismatch>DENY</onMismatch></filter><!--滚动策略,按照时间滚动 TimeBasedRollingPolicy--><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><!--文件路径,定义了日志的切分方式——把每一天的日志归档到一个文件中,以防止日志填满整个磁盘空间--><FileNamePattern>${logback.logErrorDir}/error.%d{yyyy-MM-dd}.log</FileNamePattern><!--只保留最近14天的日志--><maxHistory>14</maxHistory><!--用来指定日志文件的上限大小,那么到了这个值,就会删除最旧的日志,直到日志文件大小小于这个值--><!--<totalSizeCap>1GB</totalSizeCap>--></rollingPolicy><!--日志输出编码格式化--><encoder><charset>UTF-8</charset><pattern>%d [%thread] %-5level %logger{36} %line - %msg%n%ex</pattern></encoder></appender><!--INFO级别的日志配置如下--><appender name="fileInfoLog" class="ch.qos.logback.core.rolling.RollingFileAppender"><!--日志名称,如果没有File 属性,那么只会使用FileNamePattern的文件路径规则如果同时有<File>和<FileNamePattern>,那么当天日志是<File>,明天会自动把今天的日志改名为今天的日期。即,<File> 的日志都是当天的。--><File>${logback.logInfoDir}/info.log</File><!--自定义过滤器,保证info.***.log中只打印INFO级别的日志, 填写全限定路径--><filter class="io.gitee.piggymi.lotterysystem.common.filter.InfoLevelFilter"/>
<!-- 这种也行,只不过这种不能定义过滤低于 INFO 级别的-->
<!-- <filter class="ch.qos.logback.classic.filter.LevelFilter">-->
<!-- <level>INFO</level>-->
<!-- <onMatch>ACCEPT</onMatch>-->
<!-- <onMismatch>DENY</onMismatch>-->
<!-- </filter>--><!--滚动策略,按照时间滚动 TimeBasedRollingPolicy--><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><!--文件路径,定义了日志的切分方式——把每一天的日志归档到一个文件中,以防止日志填满整个磁盘空间--><FileNamePattern>${logback.logInfoDir}/info.%d{yyyy-MM-dd}.log</FileNamePattern><!--只保留最近14天的日志--><maxHistory>14</maxHistory><!--用来指定日志文件的上限大小,那么到了这个值,就会删除旧的日志--><!--<totalSizeCap>1GB</totalSizeCap>--></rollingPolicy><!--日志输出编码格式化--><encoder><charset>UTF-8</charset><pattern>%d [%thread] %-5level %logger{36} %line - %msg%n%ex</pattern></encoder></appender><root level="info"><appender-ref ref="fileErrorLog" /><appender-ref ref="fileInfoLog"/></root></springProfile>
</configuration>自定义过滤器:
package io.gitee.piggymi.lotterysystem.common.filter;import ch.qos.logback.classic.Level;
import ch.qos.logback.classic.spi.ILoggingEvent;
import ch.qos.logback.core.filter.Filter;
import ch.qos.logback.core.spi.FilterReply;public class InfoLevelFilter extends Filter<ILoggingEvent> {@Overridepublic FilterReply decide(ILoggingEvent iLoggingEvent) {if (iLoggingEvent.getLevel().toInt() == Level.INFO.toInt()) {return FilterReply.ACCEPT;}return FilterReply.DENY;}
}
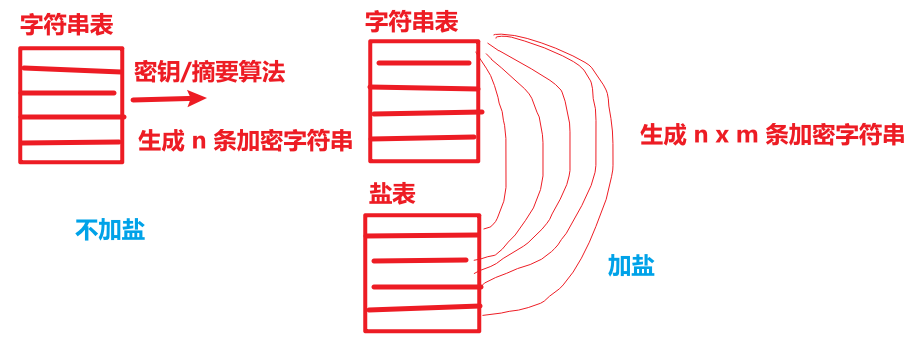
5、加盐加密
代码存在漏洞,有泄露数据的风险(用户隐私信息);管理员可以查看数据库,也有泄露数据的风险。因此要加密。
- 对称加密,AES、3DES:密钥加密了可以再用密钥解密。因此可用于加密手机号这类需要再次明文的信息(通过手机号发短信)。
- 哈希加密(摘要加密)MD5、SHA256:摘要算法加密了不可逆。因此用于加密账号密码这类不需要再次明文的信息。
- 加盐:黑客可以建一张包含所有字符串的表,通过密钥/摘要算法,生成加密后的表(相当于字典),通过对比数据库的加密内容盗取明文信息。因此需要加盐,即在密码中加上随机字符串,每条字符串都需要匹配 m 条盐表里的数据生成密文表,代价》收益,黑客不愿做。
工具包:Hutool 使用说明,我们使用摘要算法中的 SHA256、对称加密中的概述![]() https://hutool.cn/docs/#/crypto/%E6%A6%82%E8%BF%B0
https://hutool.cn/docs/#/crypto/%E6%A6%82%E8%BF%B0
依赖仓库地址:Maven Repository: cn.hutool » hutool-crypto![]() https://mvnrepository.com/artifact/cn.hutool/hutool-crypto
https://mvnrepository.com/artifact/cn.hutool/hutool-crypto
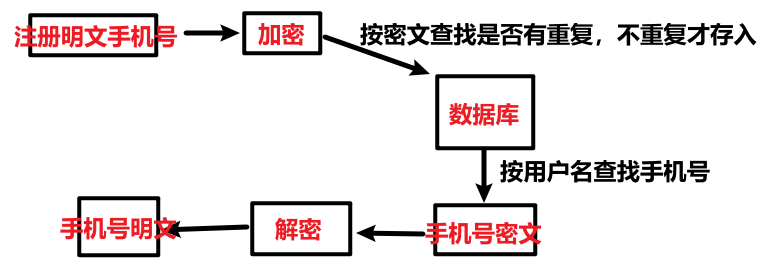
- 对于加盐存在一个问题,那就是随机盐不可重现,即密文不可重现,尽管明文相同。所以我们没有办法根据明文加盐加密后查询,加盐就不能应用在手机号、邮箱等对称加密上了(有时需要直接根据手机号值查询:校验唯一性);但是加盐可以应用在摘要加密的密码上,因为密码是通过唯一用户名间接查询的。
对称加密校验唯一性思路:
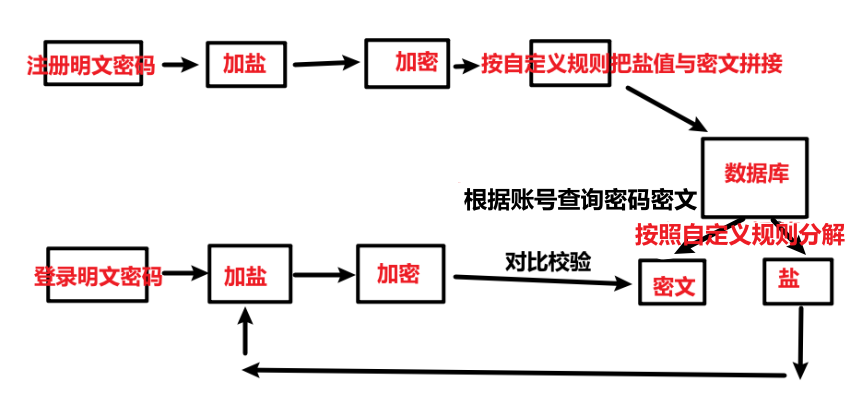
摘要加密校验匹配思路:摘要加密不可逆,需要存储盐值到数据库,登陆时,用同样的盐值加盐,与数据库中的加密密码对比。
6、统一返回值格式、异常处理

四、使用插件
1、Database Navigator(可视化数据库)
直接在 IDEA 查看数据,不再需要 navicat 连接数据库然后写 select 命令查询。
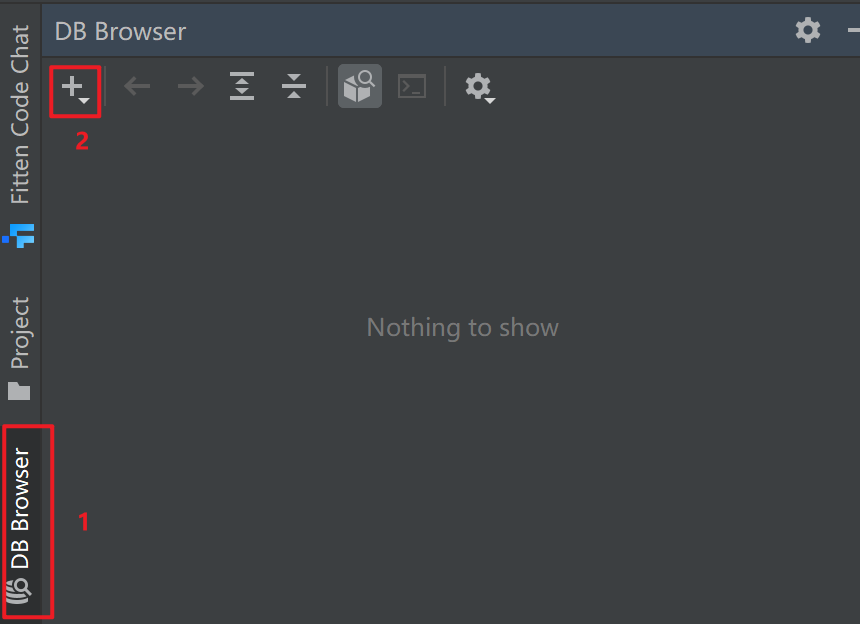


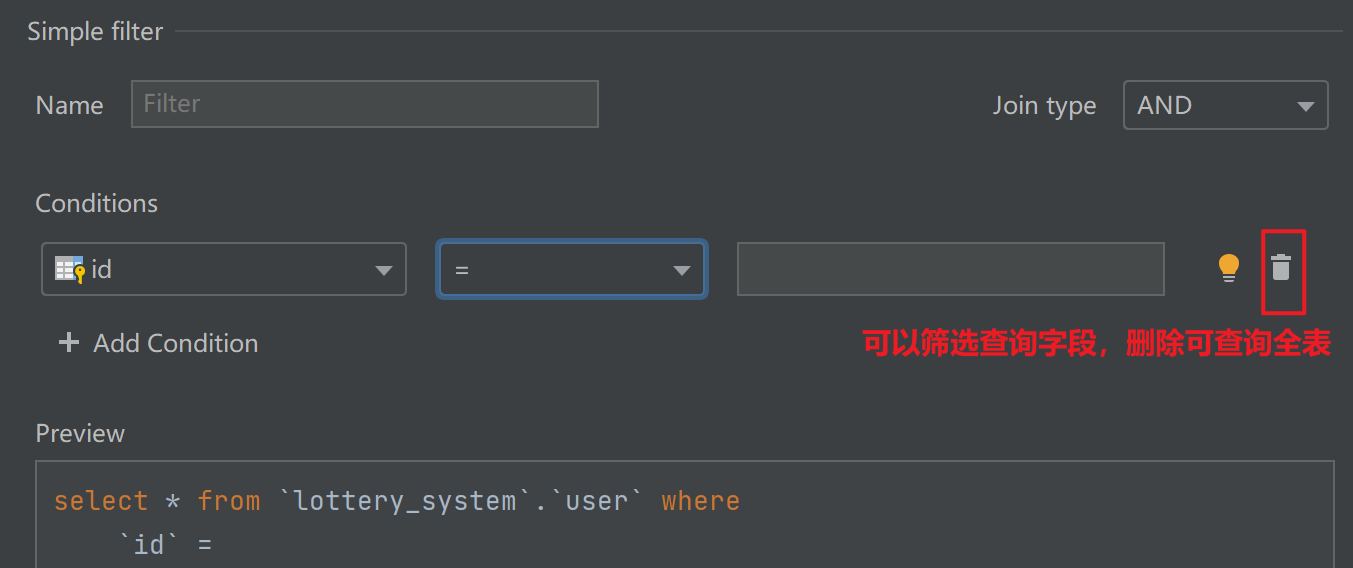
2、Redis Helper(可视化Redis)
IDEA 下载插件,可视化 redis:
![]()
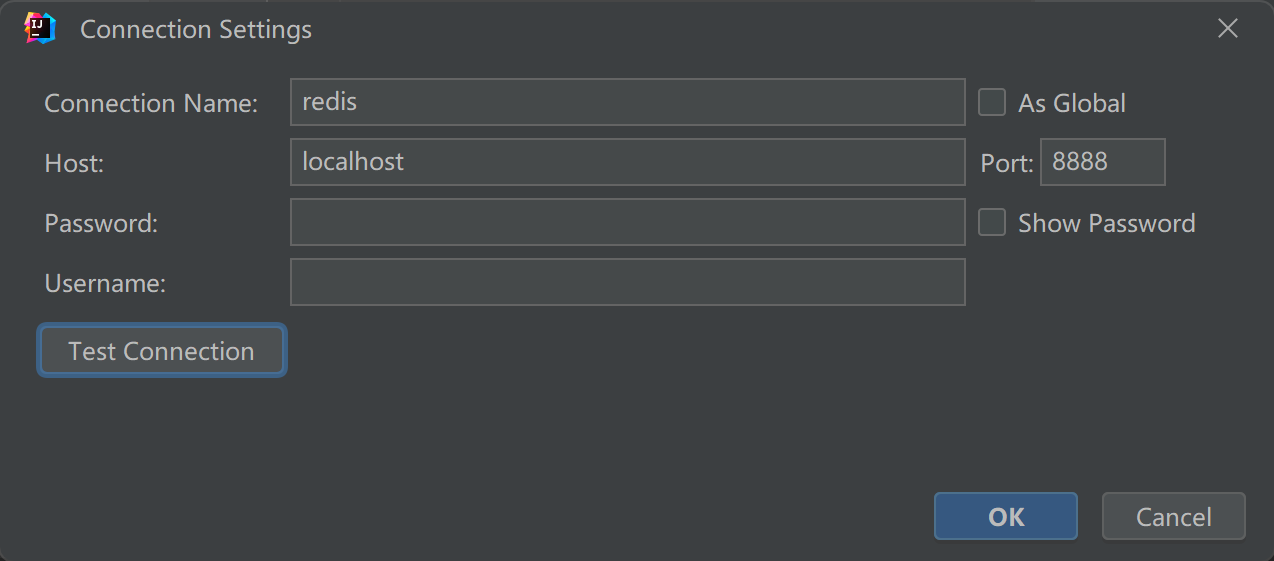
创建连接:
五、用户注册
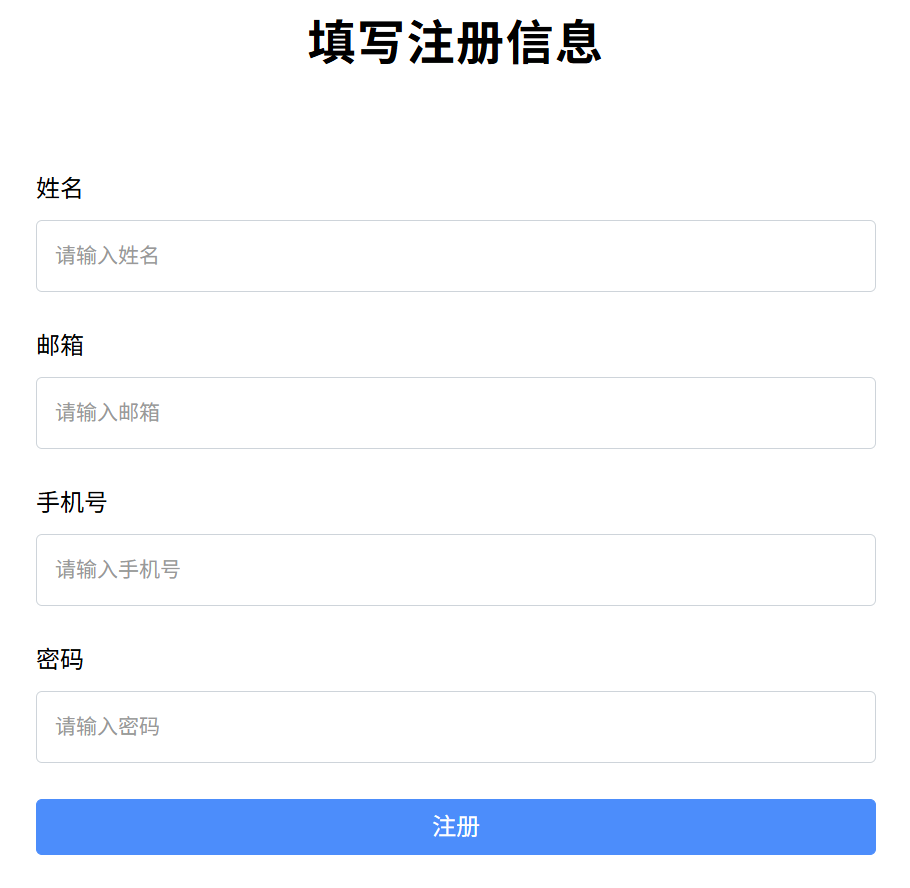
1、UI 界面
管理员注册:
普通用户注册:没有密码框(若 url 的查询字符串没有 admin 参数则默认为 ADMIN、有参数且为 True 也为管理员,否则为普通用户)。
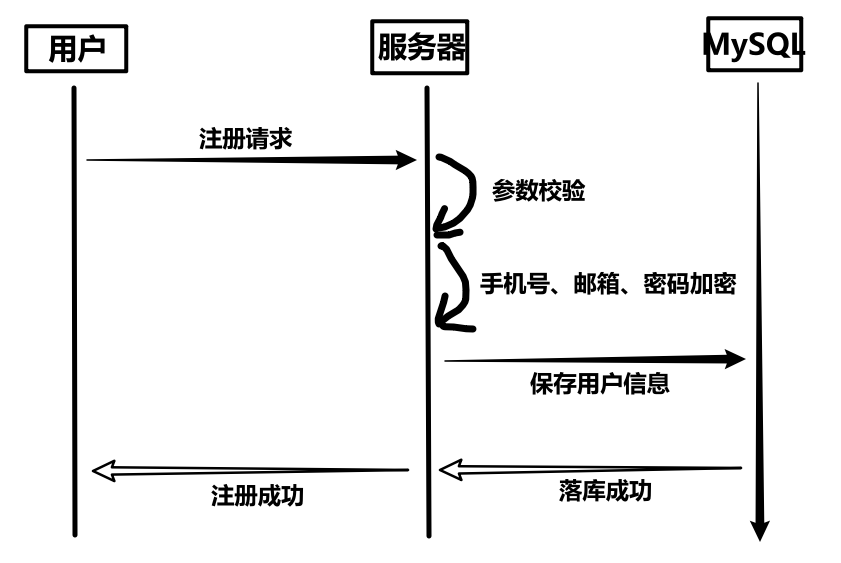
2、时序图
3、接口设计
请求:/user/register POST
{"name": "张三","email": "123@qq.com","phoneNumber": "19754576398","password": "1234567","identity": "ADMIN" // 分辨普通用户和管理员
}响应:
{"code": 200,"msg": "","data" {"userId": 24 // 虽然前端目前不需要这个值,但是也准备一个}
}4、创建实体类
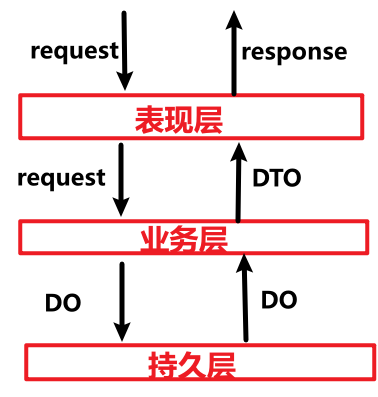
根据接口设计的请求、响应参数,创建 request、response 实体类;根据数据库表的字段创建 dataobject 实体类;因为所有表都有主键 id、创建时间 gmt_create、更新时间 gmt_modified 字段,因此创建一个 BaseOD 实体,让所有实体继承它;为了让controller 层的 response 的改变不影响 service 层,因此在 service 创建 DTO 实体类,尽管目前有些 DTO 与 response 一模一样。
因为所有 dataobject 类继承了父类 BaseOD,所以在生成当前类的 equals、hashCode 方法时,需要合并父类的,因此加上 @EqualsAndHashCode(callSuper = true)。
5、Controller(参数校验)
- 因为请求中是序列化的字符串,要映射到对象中,需要 @RequestBody;因为打印日志,需要将对象映射到序列化的字符串,需要使用 Jackson 工具序列化;因为请求、响应经常涉及到序列化、反序列化,所以标识上 Serializable。
- 返回时,需要将 DTO 转为 Response,最后经过统一返回值数据格式处理,包装成 CommonResult。
- 参数校验:简单的参数校验(比如校验属性值不能为空、长短限制)使用 jakarta.validation 工具。复杂的参数校验(比如校验属性值的格式:邮箱、手机、密码格式)需要自己写正则表达式工具类进行校验。
6、Service 层(自定义参数校验+TypeHandle)
- 实现参数校验的方法(校验格式;校验手机号/邮箱是否被使用过(用来通知中奖,需要唯一;如果不唯一,那就通知了多个人中奖了,但奖品只有一份))。
- 将 Request 转为 DO,并将数据加密(通过实现 TypeHandle 类,自动完成对自定义类 Encrypt(区别于其它普通字符串)对象加密、解密)。手机、邮箱属于对称加密,因为需要解密发信息;密码属于摘要加密,因为不需要解密,只需要对比加密后的是否匹配(mapper 方法参数是自定义类,走TypeHandle 的 set;查询的结果走 TypeHandle 的 get)。

mybatis:type-handlers-package: io.gitee.piggymi.lotterysystem.dao.handler # 类型处理器包路径- 调用 mapper 插入 DO。用到了 @Option,以获得插入后自动生成的主键值。
- 构造 DTO 返回。
六、登录
1、自定义验证码工具
概述 | Hutool
2、邮箱工具类
因为现在短信服务不能个人使用,所以把手机-验证码登录换成了邮箱-验证码登录。
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-mail</artifactId>
</dependency># 邮件配置
spring.mail:host: smtp.qq.com # SMTP 邮件服务器地址username: 你的邮箱账号password: 你的授权码default-encoding: UTF-8授权码:邮箱》设置》账号》SMTP 服务,开启服务》复制授权码。
3、Redis 使用
(1)简介
一种基于 key-value 非关系型数据库,value 不仅支持 String 类型,还支持哈希、列表、集合等复杂数据结构。最大的特点是把数据放在内存,存取快;存放快照在硬盘,防止断电数据丢失。支持键过期、发布订阅、事务等功能。
获取验证码,请求量大(每隔一段时间就需要重新生成,并且定时删除,数据存取频率很高),且有过期需求,因此我们使用存取高效、支持键过期功能的 redis 数据库(而密码登录,密码是持久的、有高安全需求,绝对不能使用 redis,如果 redis 的持久化没配置好,客户数据丢失是巨大损失)。
(2)Ubuntu 安装 Redis
因为 Redis 利用了 Linux 内核,所以官方推荐在 Linux 使用,才能最好地发挥它最佳性能。
// -y 自动跳过交互回答,全 yes
apt install redis -y// 启动 redis 服务
service redis-server start// 停止 redis 服务
service redis-server stop// 重启 redis 服务
service redis-server restart我们在电脑上开发,所以需要远程连接到 Linux 服务器上运行的 Redis 服务。但是直接在云服务器的控制台上把 Redis 的端口防火墙开放到公网上不安全。因此,我们通过端口转发的方式,把电脑上的端口映射到服务器的关口,建立 ssh 安全连接(ssh 连接不能断,所以 xshell 客户端也不能关)。
右键会话》属性》隧道》
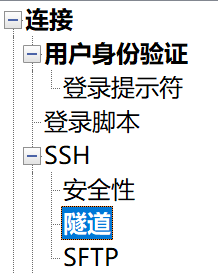
将目标服务器的 localhost 6379 映射到本机电脑的 localhost 8888。
![]()
(3)简单使用 Redis
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency># redis 配置
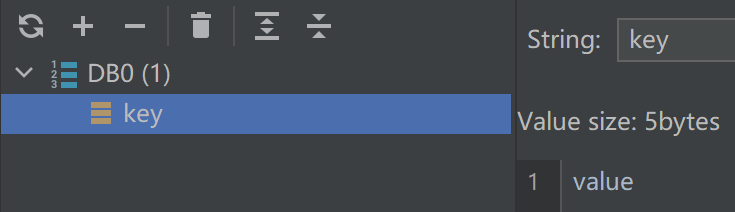
spring.data.redis:host: localhostport: 8888timeout: 60s # 连接空闲超过 N(s秒、ms毫秒) 后关闭,0为禁⽤lettuce.pool: # 默认使⽤ lettuce 连接池max-active: 8 # 允许最⼤连接数,默认8(负值表⽰没有限制)max-idle: 8 # 最⼤空闲连接数,默认8min-idle: 0 # 最⼩空闲连接数,默认0max-wait: 5s # 连接⽤完时,新的请求最多等待时间(s秒、ms毫秒),超过该时间抛出异常 JedisConnectionException,(默认-1,负值表⽰没有限制)尽量避免使用 RedisTemplate,因为他是以二进制字节数据存储到 redis,可读性差,不能跨语言(默认序列化器用的 Java 实现的,不能用到其它编程语言),并且读取时还需要手动序列化。而 StringRedisTemplate 存的是字符串,可读性高方便调试,不需要手动序列化,跨语言(默认使用 StringRedisSerializer 序列化器。)
@SpringBootTest
public class RedisTest {@Resourceprivate StringRedisTemplate stringRedisTemplate;@Testpublic void testRedis() {stringRedisTemplate.opsForValue().set("key", "value");String value = stringRedisTemplate.opsForValue().get("key");System.out.println(value);}
}
实现 RedisUtil 工具:
4、JWT 令牌
(1)传统的 cookie-session
优点:
- 框架自带实现。
- 存取 cookie 由浏览器自动发送。
缺点:
- 对服务器来说有状态,存储在服务器内存,占用资源。
- 不能跨域,对前后端分离不友好。(前后端分离,会部署在不同服务器,域名不同。访问前端域名front.com,点击登录,请求后端域名 back.com 实现登录,校验成功后为 back 域名设置 cookie 到响应头,类似 Set-Cookie: sessionId=xyz123; Domain=back.com。前端再次请求后端,会查看 cookie 发现有后端域名 back.com,应该携带 cookie,但浏览器出于安全考虑,不会携带跨域的 cookie。如果非要携带,必须在前后端都进行严格的配置)
- 在集群环境下失效。登陆时请求服务器A,后续操作又请求服务器B,但 session 只存储在服务器A中的。
- 只适用于 Web。
(2)JWT 令牌
优点:
- 对服务器来说是无状态的,不占用服务器资源,令牌存储在客户端。
- 能够在跨域、集群环境下生效。
- 多平台适用,不仅是 Web。
缺点:
- 框架没有,需要自己实现令牌。(但是能引入第三方 JWT 工具)
- 前端需要手动从 HTTP header 中存取令牌。(也不难,前端也能实现统一处理)
JWT 工具类实现:
5、UI 界面

6、发送验证码邮件
(1)时序图
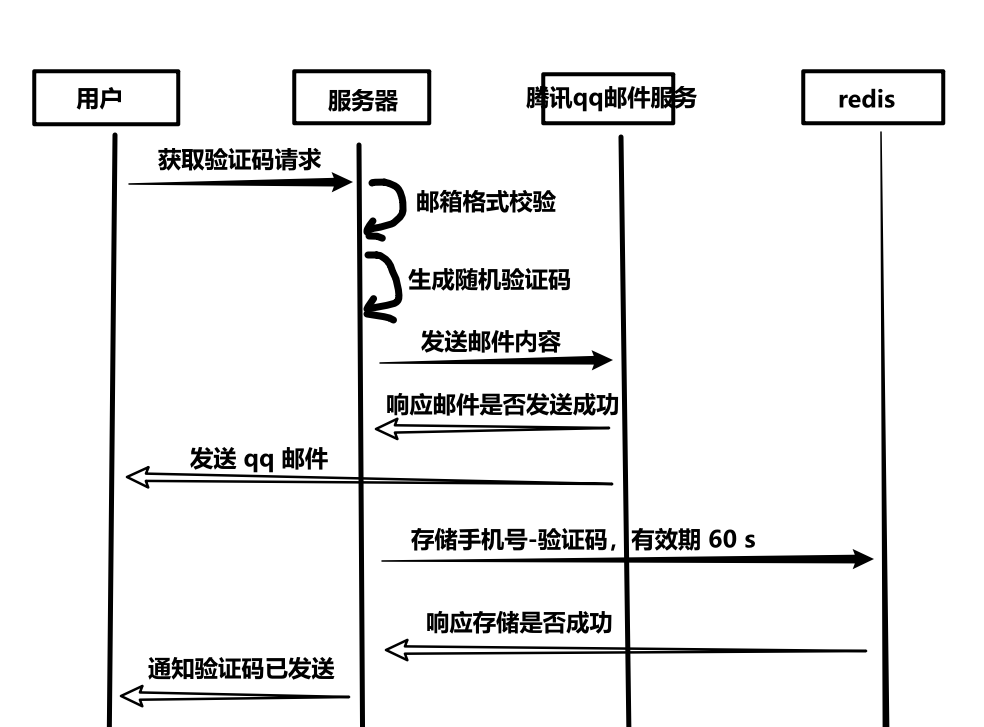
(2)接口设计
请求:/user/verification-code/send?email=253637@qq.com GET响应:
{"code": 200,"msg": "","data" true
}
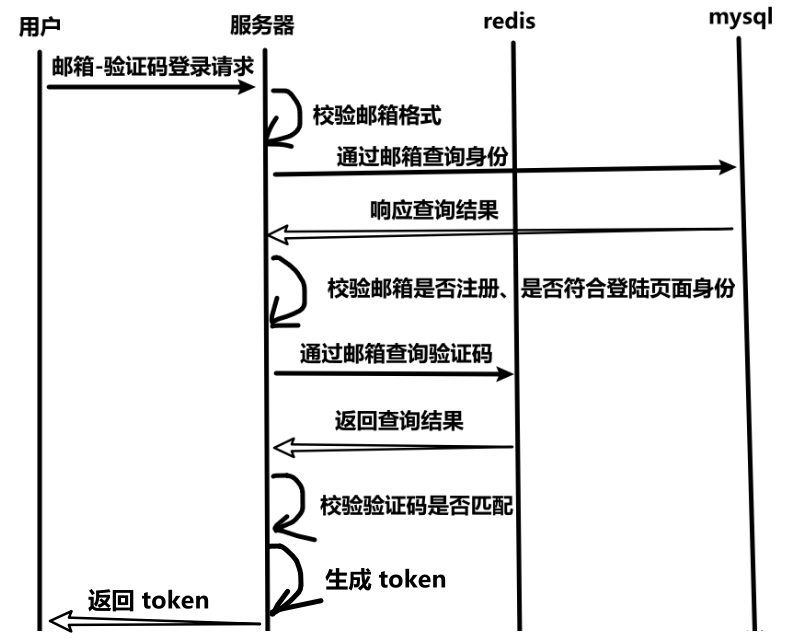
7、邮箱-验证码登录
(1)时序图
(2)接口设计
请求:/user/message/login POST
{"email": "xxxxxxx@qq.com","verificationCode": "xxxxxx","identity": "ADMIN" // 当前页面的权限身份,数据库登录用户的身份要与此匹配才能成功
}响应:
{"code": 200,"msg": null,"data": JWT token
}邮箱作为 key 存到 redis,需要加前缀以区分不同业务的邮箱key,因为可能不止有验证码这块业务需要把邮箱作为 key。
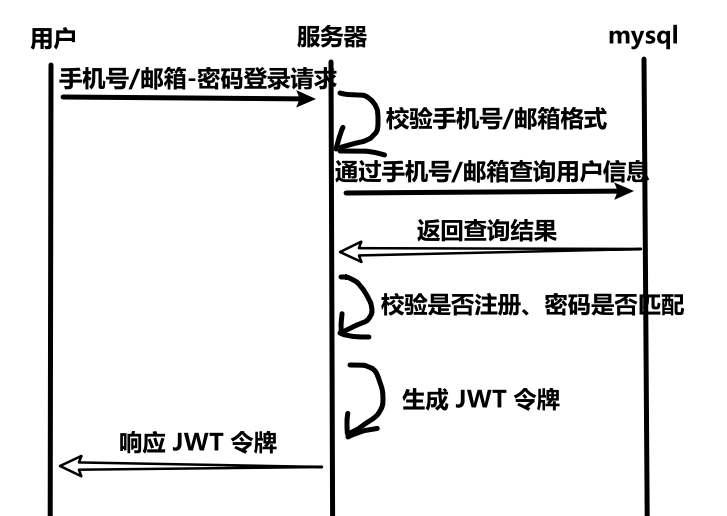
8、手机号/邮箱-密码登录
(1)时序图
(2)接口设计
请求:/user/password/login POST
{"loginName": "xxxxxxx@qq.com"/"138xxxxxxxx","password": "xxxxxx","identity": "ADMIN"
}响应:
{"code": 200,"msg": null,"data": JWT token
}9、未登录拦截
(1)时序图
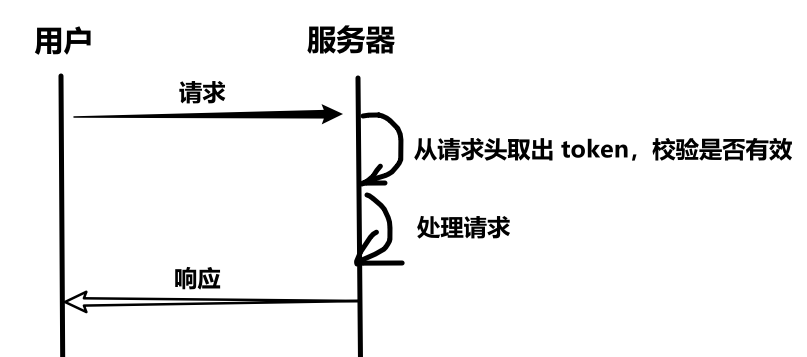
前端需要执行统一 token 放入请求头,统一拦截处理。
七、人员列表
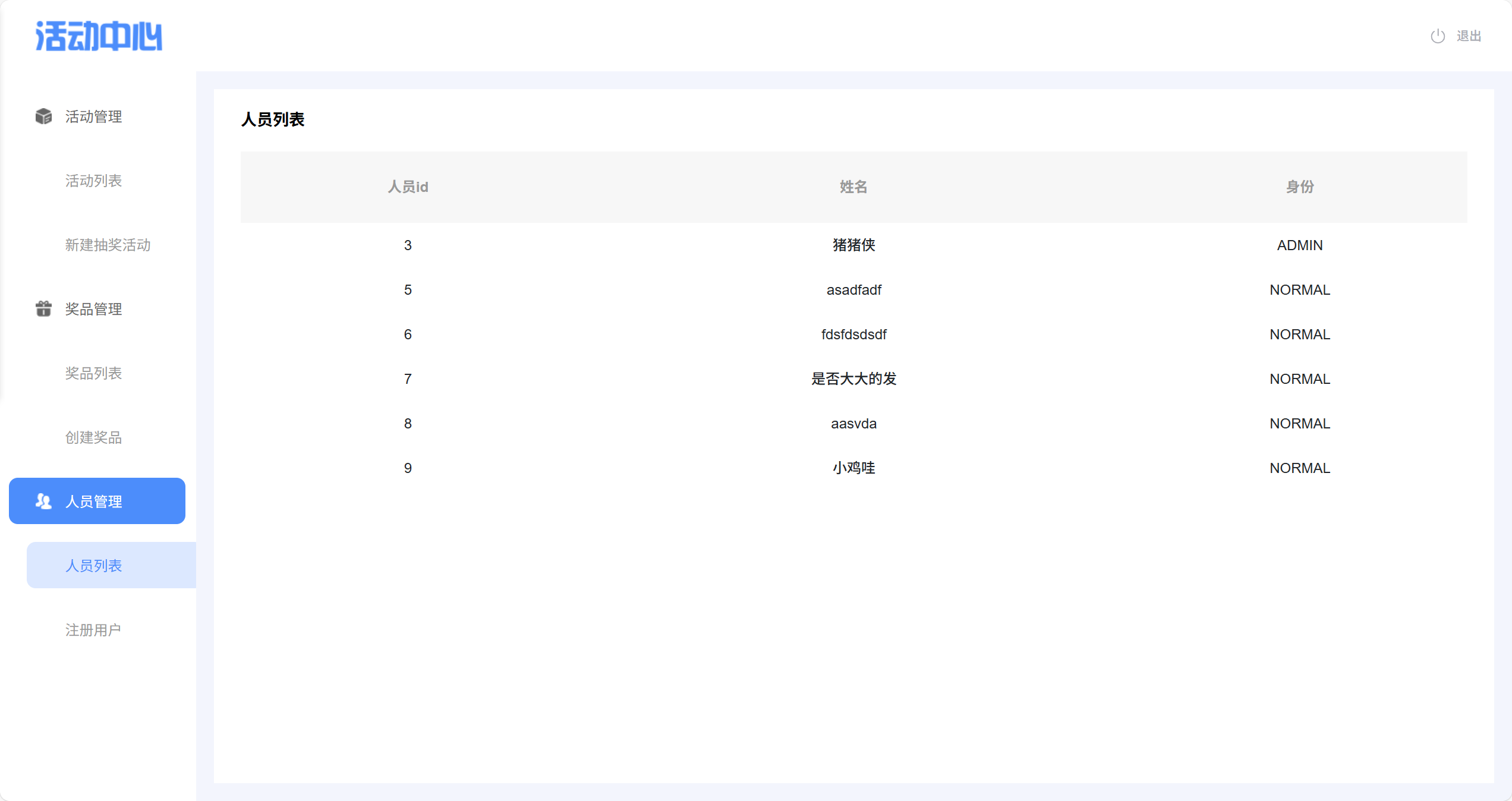
1、UI 界面
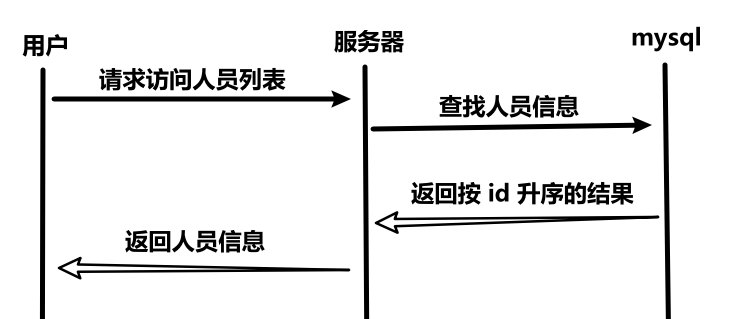
2、时序图
3、接口设计
请求:/user/show-list GET
{"identity": null // ADMIN/NORMAL 按照身份查询;其它则查询所有
}响应:
{"code": 200,"msg": null,"data": [{"id": 1,"userName": "张三","identity": "ADMIN"},……]
}- 需要校验参数 identity,不合规的身份直接设置为 null,如果身份为 null,就查询所有人员信息(动态 SQL)。如果合规,就查对应身份的人员信息。如果查询到的用户身份有不合规的,直接置为 null。
八、创建奖品
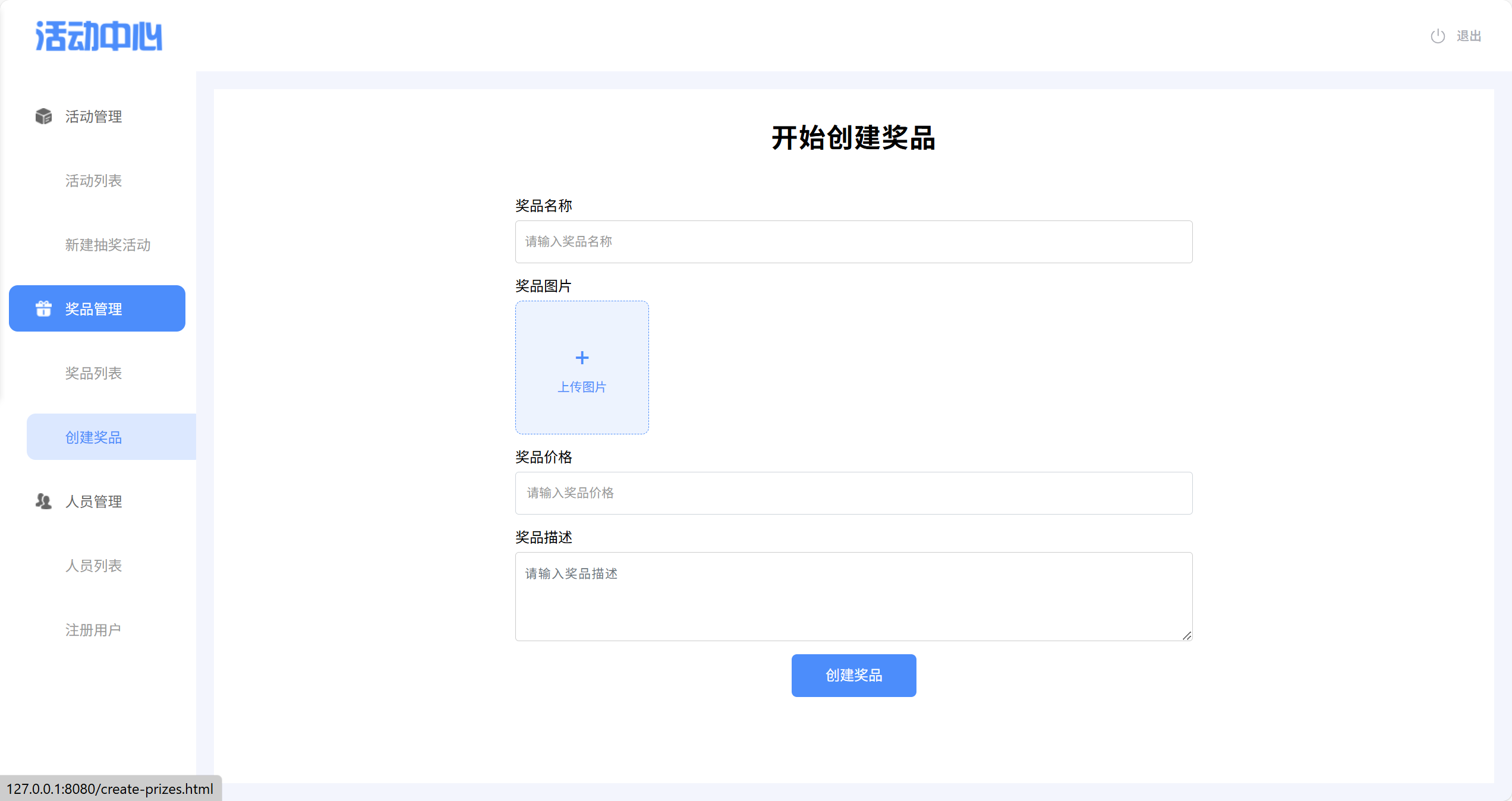
1、UI 界面
2、时序图
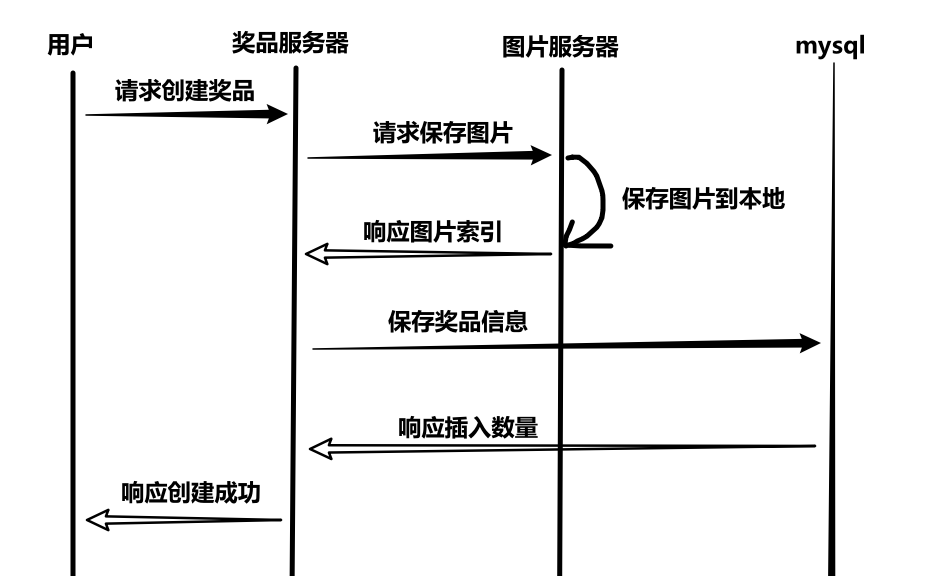
3、保存图片
-
写在图片服务中,传入文件处理工具,返回图片索引。
-
创建图片文件目录》转换图片文件名为唯一的,作为索引》使用文件处理工具保存图片到本地》返回图片索引,数据库中保存的是索引。
-
注意在配置文件,配置图片存储路径、配置静态文件路径(让索引名映射到静态文件路径)。
4、保存奖品信息
- 接口设计
请求:/prize/createPrize POST
表单数据:
prizeInfo: {"name": "吹风机", "price": 200, "description": "美的吹风机"}
prizeImg: obj.jpg (FILE)响应:
{"code": 200,"msg": null,"data": prizeId
}- 表单参数需要 @RequestPart 绑定前端参数名。
九、奖品列表(翻页)
1、UI 界面
2、时序图
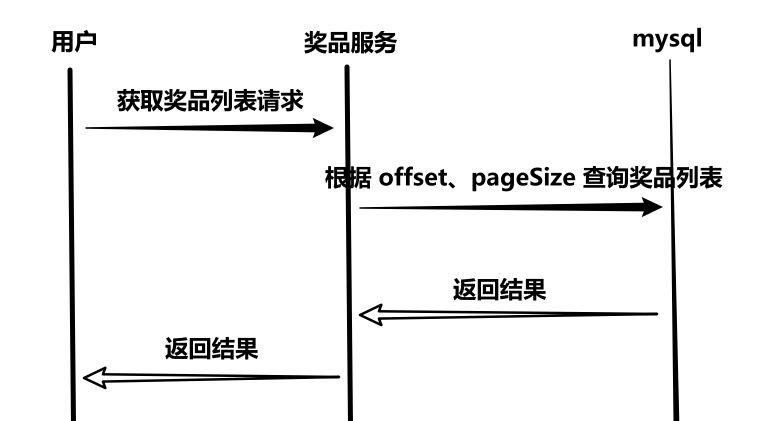
3、接口设计
请求:/prize/find-list?currentPage=1&pageSize=10 GET响应:
{"code": 200,"data": {"total": 3,"records": [{"prizeId": 17,"prizeName": "吹⻛机","description": "吹⻛机","price": 100,"imageUrl": "d11fa79c-9cfb-46b9-8fb6-3226ba1ff6d6.jpg"},{"prizeId": 13,"prizeName": "华为⼿机","description": "华为⼿机","price": 5000,"imageUrl": "5a85034b-91b7-48fe-953d-67aef2bdcc2d.jpg"}]},"msg": ""
}- 翻页列表请求(当前页、页面数据大小、计算偏移位置从哪个位置开始获取列表)、翻页列表DTO 类统一为上述格式(数据总数用于前端跳转到尾页(总数/页面大小=尾页),当前页数据列表)。
- 翻页列表 DTO 写成泛型类,可以存各种类型的 List。
十、创建活动
(1)UI 界面
(2)时序图
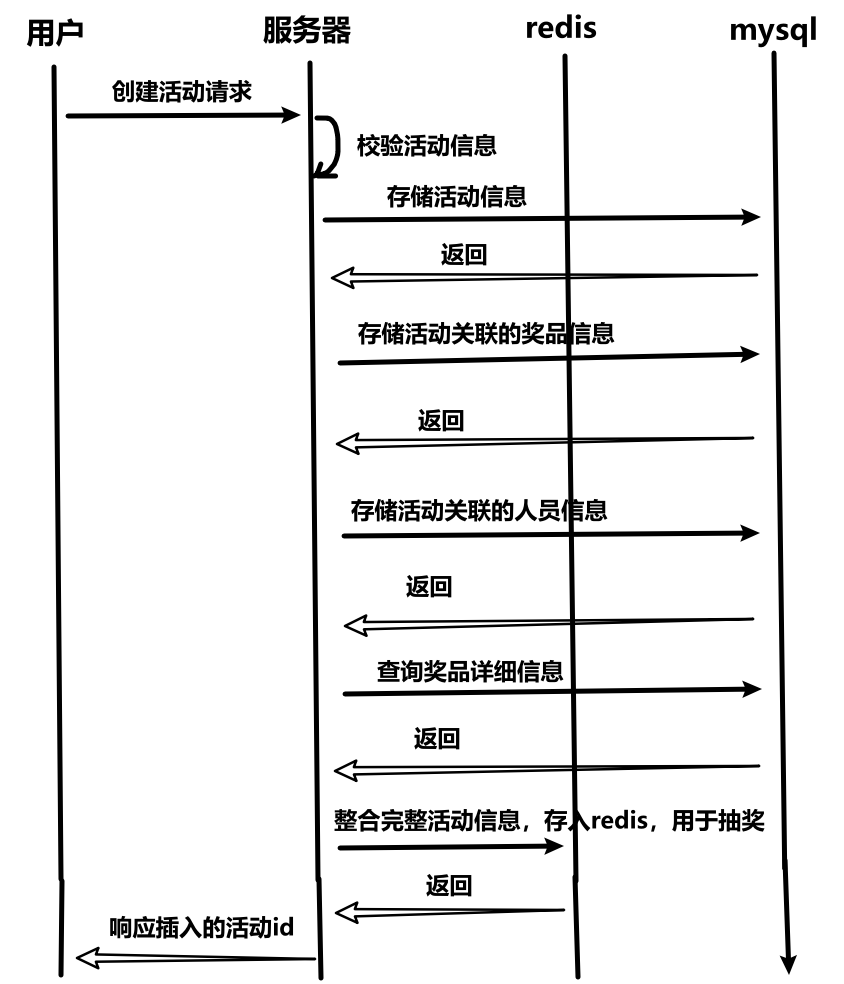
- 参数校验:人员、奖品 id 是否在 mysql 中存在;人员数≥奖品数;奖品等级是否符合规范。
- 存储信息到 mysql:涉及到多表操作,因此需要用到事务,一旦一个表插入失败就回滚。
- 存储完整活动信息到 redis:抽奖功能一是高并发(同时多个用户都要点击去抽奖,需要显示活动完整信息)二是抽奖需要快速的反应,给用户更好的体验。所以需要将活动完整信息缓存到 redis,在内存中快速存取。这部分抛出异常不需要回滚,它只是缓存的功能,如果缓存中查询不到该活动信息,就可以从 mysql 再次加载到 redis。
(3)接口设计
请求:/activity/create POST
{"activityName": "抽奖测试","description": "年会抽奖活动","activityPrizeList": [{"prizeId": 1,"prizeAmount": 1,"prizeTier": "FIRST_PRIZE"},{"prizeId": 2,"prizeAmount": 1,"prizeTier": "SECOND_PRIZE"}],"activityUserList": [{"userId": 25,"userName": "郭靖"},{"userId": 23,"userName": "杨康"}]
}响应:
{"code": 200,"msg": "","data": {"activityId": 1}
}- 抽奖时用到的奖品完整信息(另外的图片、价格、描述等)需要根据奖品 id 查询 mysql。
- 抽奖时需要用到用户名,直接由前端提供,避免还要从 mysql 查询。
插件使用,自动生成 setter,用于 Request、DTO、DO、Response 之间的转换:
十一、活动列表
(1)UI 界面
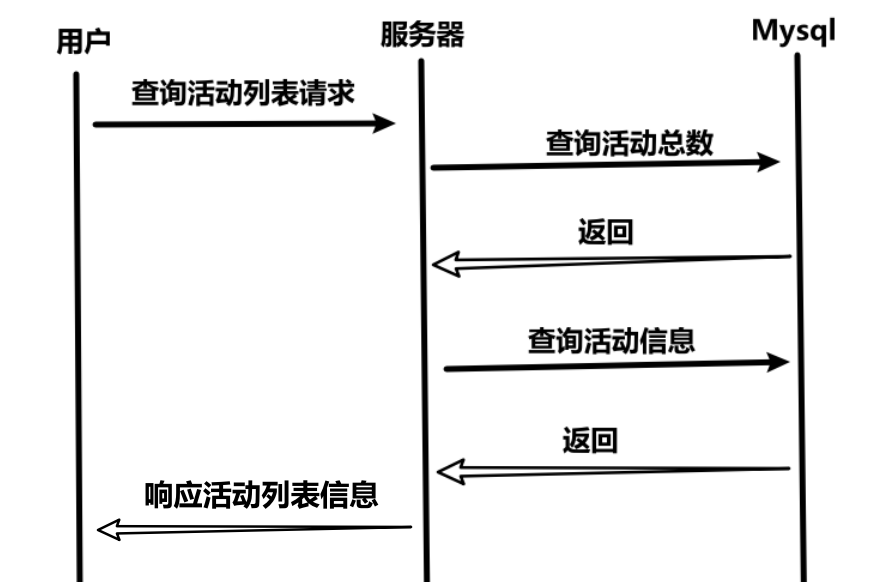
(2)时序图
(3)接口设计
请求:/activity/find-list?currentPage=1&pageSize=10 GET响应:
{"code": 200,"msg": "","data": {"total": 10,"records": [{"activityId": 23,"activityName": "抽奖测试1","description": "年会抽奖活动","valid": true},{"activityId": 22,"activityName": "抽奖测试2","description": "年会抽奖活动","valid": true}]}}- PageListDTO 泛型类,传入的泛型的是 ActivityBaseDTO,直接给 status 写一个 valid 方法,用于判断活动是否在进行中。controller 层直接将 response 里的 records 记录的活动列表的 valid 属性设置,调用 DTO 中的 valid 方法。
- 活动状态:RUNNING状态前端显示“活动进行中,去抽奖”,完成状态显示“活动已完成,查看中奖名单”。
- 奖品状态:初始状态点击“开始抽奖”就开始抽奖,完成状态点击“开始抽奖”直接显示中奖名单。
- 用户状态:初始状态为被抽中,完成状态已被抽中不再参加抽奖。
十一、活动详情
(1)时序图
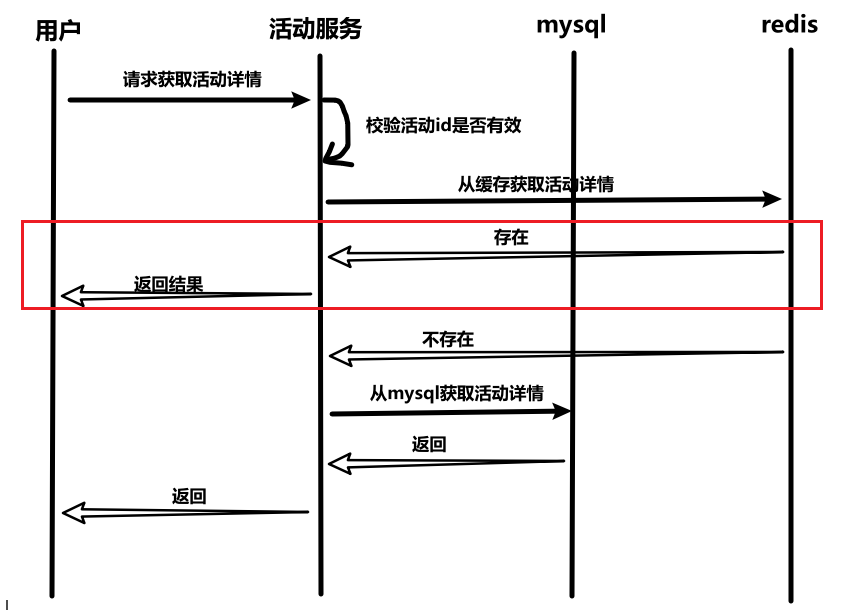
(2)接口设计
请求:/activity/find-detail POST
{ "activityId": 1
}响应:
{"activityId": 1, // 抽奖时使用"activityName": "抽奖", // 前端显示"description": "抽奖","valid": true, // 活动进行中"prizes": [{"prizeId": 1, // 抽奖时使用"name": "吹风机", // 前端显示"imageUrl": "xxxxxx.jpg", // 前端显示"price": 200,"description": "美的品牌","prizeTierName": "一等奖", // 前端显示"prizeAmount": 1, // 前端显示"valid": true // 未被抽取},........],"users": [{"userId": 1, // 抽奖时使用"userName": "猪猪侠", // 前端显示"valid": true // 未被抽取},........]
}十二、抽奖
1、抽奖流程分析

但因为前端提前显示中奖人,没有更改的余地,所以后端必须保证抽奖处理成功:

2、RabbitMQ 使用
(1)简介
主要功能就是实现异步,然后通过异步解耦耗时的操作、流量大时请求削峰放到流量小时填谷处理、延迟处理、消息分发。
主流的MQ产品:Kafka 吞吐量上十万,适合项目高并发的大公司;RabbitMQ 吞吐量上万较小,但是够中小公司用,并且可视化界面、社区活跃度高,适合用来学习 MQ。
(2)Ubuntu 上安装
最新版安装比较复杂,参考:Installing on Debian and Ubuntu | RabbitMQ
Ubuntu 仓库里的 RabbitMQ 版本旧,但是更好安装,先装这种:
- 安装
# ------------安装erlang-----------------# 更新
sudo apt-get update# rabbitmq 是 erlang 语言写的,所以要安装
sudo apt-get install erlang# 启动 erl 查看版本
erl# 退出 erl
halt().# ------------安装rabbitmq-----------------# 安装 mq
sudo apt-get install rabbitmq-server# 确认安装成功,查看 mq 状态
systemctl status rabbitmq-server# 安装可视化管理界面
rabbitmq-plugins enable rabbitmq_management# ------------服务操作-----------------# 启动服务
sudo systemctl start rabbitmq-server# 停⽌服务
sudo systemctl stop rabbitmq-server# 重启服务
sudo systemctl restart rabbitmq-server
- 登录 rabbitmq 管理页面:IP:端口号(可用隧道),默认用户名和密码都是 guest。非本机登录不能用默认用户名和密码,就新建个用户赋予权限:
# 创建用户
rabbitmqctl add_user 用户名 密码# 给用户添加权限
rabbitmqctl set_user_tags 用户名 角色名称角色:
- Administrator超级管理员,可登陆管理控制台(启⽤managementplugin的情况下),可查看所 有的信息,并且可以对⽤⼾,策略(policy)进⾏操作。
- Monitoring监控者,可登陆管理控制台(启⽤managementplugin的情况下),同时可以查看 rabbitmq节点的相关信息(进程数,内存使⽤情况,磁盘使⽤情况等)。
- Policymaker策略制定者,可登陆管理控制台(启⽤managementplugin的情况下),同时可以对 policy进⾏管理。但⽆法查看节点的相关信息。
- Management普通管理者,仅可登陆管理控制台(启⽤managementplugin的情况下),⽆法看到 节点信息,也⽆法对策略进⾏管理。
- Impersonator 模拟者,⽆法登录管理控制台。
- None其他⽤⼾,⽆法登陆管理控制台,通常就是普通的⽣产者和消费者。
(3)管理界面使用
rabbitMQ 的模型图:
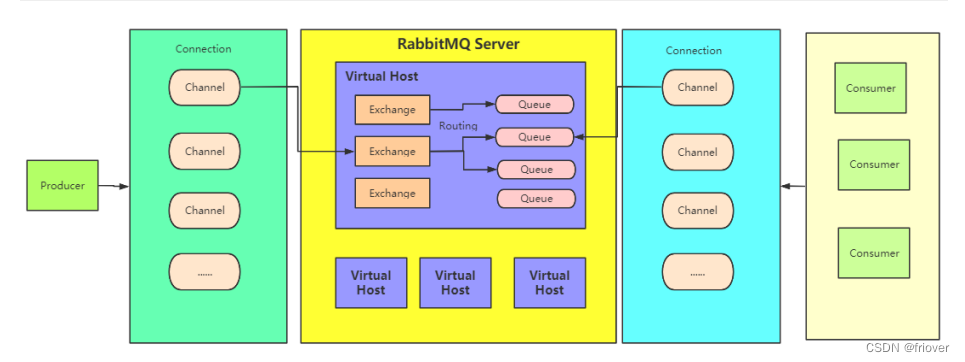
- 生产者、消费者与MQ服务建立 TCP 连接:一个连接中有多个信道,可供同一个项目中不同任务的使用,并行通信效率更高、进行了逻辑隔离互不影响、可重复使用同一 TCP 连接减少因连接带来的消耗。
- virtual host 对不同项目进行逻辑隔离,相当于 mysql 中的不同数据库。
- 声明交换机、队列,并将交换机与队列按路由键绑定。(配置部分)
- 消息路由:交换机收到消息后,根据自身路由键查询对该键绑定的队列,并复制消息到队列。(生产者只关心把消息发送到哪个路由器、消息用哪个路由键)
- 消费者的信道监听队列,接收消息并处理。(消费者只关心接收哪个队列的消息)
AMQP(高级消息队列协议),RabbitMQ 就是用 Erlang 语言实现了 AMQP 协议,当然也支持其他协议。
多个消费者订阅同一队列:轮询方式接收,一个消息只能被一个消费者处理。消息1给消费者1、消息2给消费者2......但轮询存在问题,不关心不同消费者的消费速度,导致慢的消费者堆积消息,所以MQ提供预取机制,给MQ应答消费完成后,再发预取的几条消息。
消息确认机制分为消费者消息确认机制(保证消息被成功处理)和生产者消息确认机制(保证消息被Broker成功接收)。
spring 消费者确认机制有三种:none(发送给消费者后就删除队列里的消息)、自动(消费者正常处理完,回应确认;抛出异常,回应失败/拒绝)、手动(显示调用确认、失败、拒绝)。
生产者确认机制:broker 回执成功/失败,默认失败的消息丢弃,可设置为原路返回。
死信队列:存储各种处理失败的消息,防止正常队列堆积阻塞、异常消息的丢失。可用于监控异常、消息重试。

注意:
- 管理页面端口号:15672
- AMQP 通信端口号:5672(项目中配置文件填这个)
(4)配置
依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId></dependency>yml 配置:
# rabbitMQ 配置
spring:rabbitmq:host: 127.0.0.1port: 9998username: guestpassword: guestlistener.simple:acknowledge-mode: auto # 消息确认机制,默认 auto# 这个重试是 spring 的重试机制,如果失败,会最多执行 process 5 次# 不能改为 false,spring 默认直接放回队列,造成一直异常、放入队列重试,造成死循环retry.enabled: true retry.max-attempts: 5 # 设置失败重试 5 次配置类,按配置名自动创建交换机、队列、绑定:
import org.springframework.amqp.core.*;
import org.springframework.amqp.support.converter.Jackson2JsonMessageConverter;
import org.springframework.amqp.support.converter.MessageConverter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class DirectRabbitConfig {public static final String QUEUE_NAME = "DirectQueue";public static final String EXCHANGE_NAME = "DirectExchange";public static final String ROUTING = "DirectRouting";/*** 声明队列 起名:DirectQueue*/@Beanpublic Queue directQueue() {// durable: 队列是否持久化。默认false 存在内存,重启 rabbit 服务器后队列消失。生产环境设置为true// exclusive: 是否当前连接私有队列。默认false,只能被当前创建的连接使用,当连接关闭后队列即被删除。此参考优先级高于 durable// autoDelete: 不再被使用时,是否自动删除。默认false,当没有生产者或者消费者使用此队列,该队列会自动删除。// 一般设置一下队列的持久化就好,其余两个就是默认falsereturn new Queue(QUEUE_NAME,true);}/*** 声明 Direct交换机 起名:DirectExchange*/@BeanDirectExchange directExchange() {return new DirectExchange(EXCHANGE_NAME,true,false);}/*** 绑定 将队列和交换机绑定, 并设置用于匹配键:DirectRouting*/@BeanBinding bindingDirect() {return BindingBuilder.bind(directQueue()).to(directExchange()).with(ROUTING);}/*** 消息转换器 生产者发送的消息序列化,消费者接收的消息反序列化*/@Beanpublic MessageConverter jsonMessageConverter(){return new Jackson2JsonMessageConverter();}
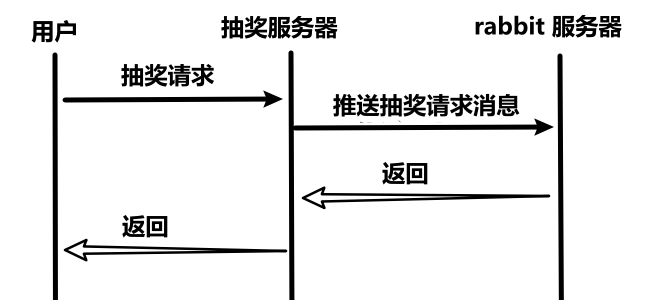
}3、推送抽奖请求消息(生产者)
(1)时序图
(2)接口设计
请求:/draw-prize/draw-prize POST
{"activityId":4,"prizeId":5,"winningTime":"2025-05-21T11:55:10.000Z","winnerList":[{"userId":5,"userName":"asadfadf"},{"userId":9,"userName":"小鸡哇"},......]
}响应:
{"code": 200,"msg": "","data": true
}- 构造消息体,给消息绑定路由键,推送到MQ的交换机(实现了生产者)。
4、抽奖逻辑执行(消费者)
(1)时序图
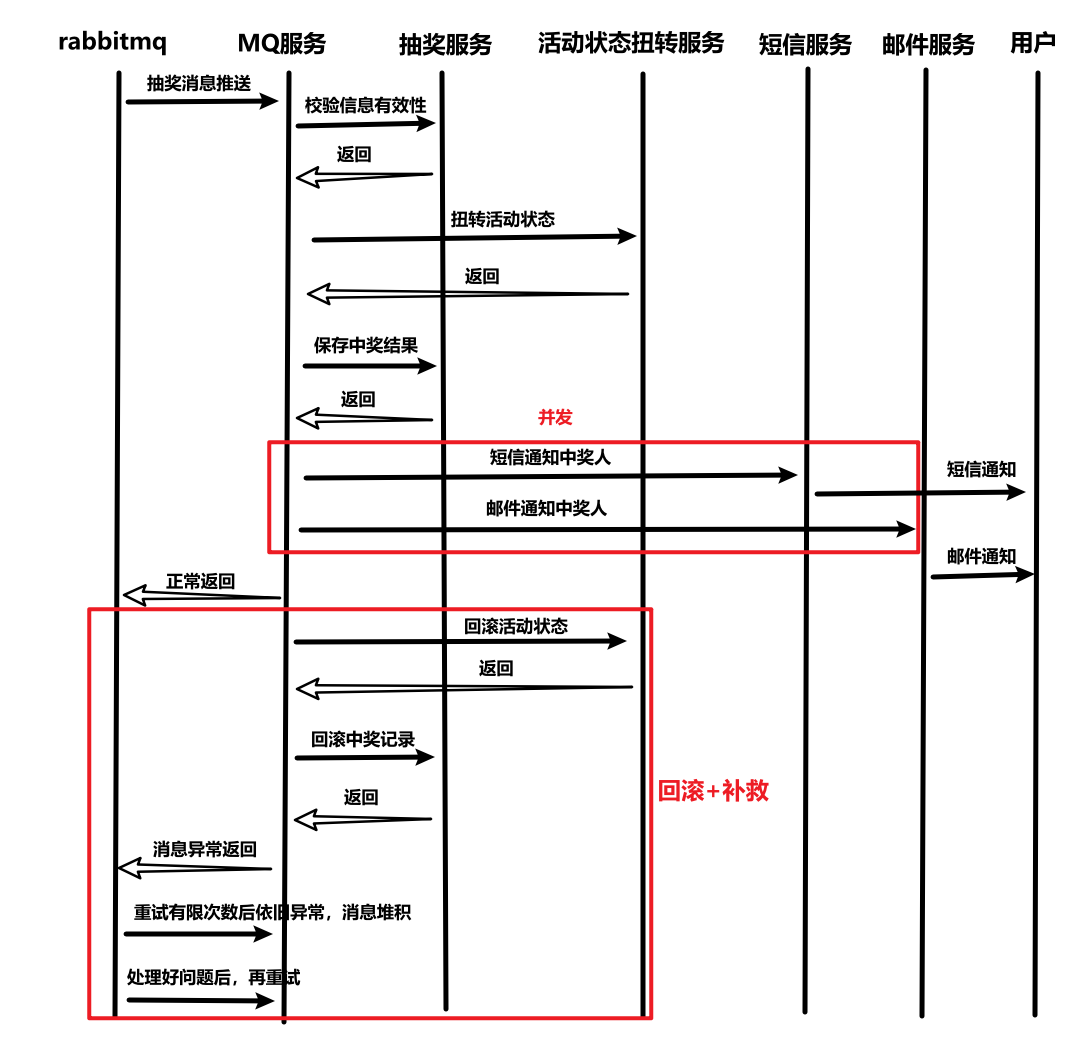
(2)消费 MQ 消息
- @RabbitHandler 注解的消费者 process 会监听队列 @RabbitListener(queues=xxxx),队列一有消息就会处理。
- 预取+消息应答机制可以根据服务器访问流量,自动控制消费者消息接收速度。(可扩展配置)
(3)校验抽奖信息
- 根据活动、用户、奖品 id,查询数据库。校验是否存在该活动、奖品、用户,以及状态是否可进行抽奖,以及奖品与用户数量是否匹配。
- 注意,校验抽奖信息若发现信息不符合抽奖的要求,不能抛出异常,而是返回布尔值,不符合要求直接不进行抽奖。因为异常的抛出,会被 catch 捕获,然后进行回滚处理。我们考虑这样的情况:用户手速太快,同一时刻连续点击了多次抽奖按钮,这些请求的数据都是一样的。第一个请求正常完成,此时活动、奖品、用户的状态已被扭转。第二个请求在参数校验处发现状态不符合抽奖要求,就会抛出异常,第一次请求扭转的状态就会被回滚,导致代码出现bug,这也是属于没有保证幂等性(多次同样的请求,得到的结果是一样的)。因此我们不能让校验模块抛出异常。
(4)状态扭转(多设计模式)
- 主流程 Manager:先扭转用户、奖品的状态(次序1),再根据奖品的状态(根据xxx的状态)扭转活动的状态(次序2)。最后,如果状态扭转了,就更新缓存;如果抛出异常,就回滚(开启事务)。
- 分析:状态扭转有先后次序,活动状态必须最后扭转。此时,如果需要扩展其它业务,那么1)就需要把扭转 xxx 状态放到扭转活动状态前面,但如果是新人写代码就很自然地扩展到扭转活动状态后面,导致业务逻辑出错(扩展性差)。因此,我们必须固定执行顺序,先其它状态扭转执行,后活动状态扭转执行。管道设计模式:固定流水线的执行流程。2)需要修改已有代码主流程 Manager(加入扭转 xxx 状态的方法),不符合开闭原则,容易影响已有代码。策略设计模式:对于状态扭转操作,有不同的可替换扭转逻辑。
- 管道设计模式具体实现:实现多种状态扭转Operator类(包含指定次序的方法,返回次序编号,必须按这个次序执行),把这多个Operator对象依次存于PipeLine 类的 List 对象中,再遍历Operator对象执行convert状态扭转方法。
- 策略设计模式具体实现:多种状态扭转Operator类实现同一个抽象类,重写扭转方法实现不同扭转逻辑。
- 优势:1) 扩展一个新的状态扭转时,必须注意次序问题,减少错误的发生。2) 一个循环就可以遍历所有状态扭转操作,代码更优雅;扩展新节点无需修改已有代码,只需要实现具体的扩展扭转逻辑。
- 责任链设计模式:责任链跟管道很相似,都是指定了一个处理流程。但是,责任链更像是“路由”的功能,根据节点优先级在链上遍历,直到找到能够处理输入数据的节点或到达链尾就终止遍历,即只有一个节点会真正处理数据。但是管道的每个节点都会处理数据,并且每个节点都没有控制是否调用下一个节点的权力,只有处理数据的功能。责任链模式在真实的状态扭转业务场景中很常用,比如订单状态机(某一订单的多种状态变化,一个行为action只能触发一种扭转;而我们的抽奖行为,触发了用户、奖品、活动多个对象的状态同时扭转):
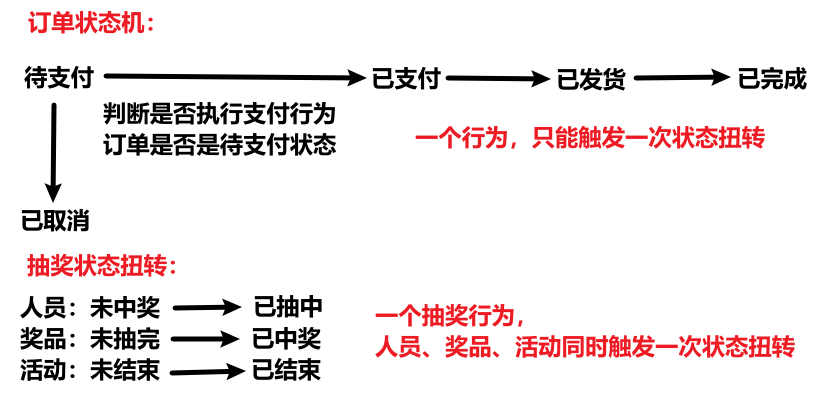
一次抽奖行为,人员、奖品、活动都需按序状态扭转一次,因此使用管道;实际上活动的状态还能扩展很多(草稿未发布、已发布未开始、进行中、已完成、已过期、已取消......,这个路由顺序最好要符合活动生命周期的逻辑,避免因条件重叠带来的错误,并且应该让发生概率最大的状态放在前,即在生命周期中靠前的状态),因此可以使用责任链设计模式(虽然目前只有未结束、已结束两个状态),避免后续扩展修改“执行活动状态扭转”的已有代码。
(5)保存中奖信息
- 在mysql、redis中保存。
- (关于缓存)我们有两处需要显示中奖信息:1)根据活动、奖品缓存的中奖信息(每次成功抽奖都要保存)。2)根据活动缓存的所有奖品中奖信息(每个活动的最后一次抽奖保存)。
- 缓存异常不应该影响正常抽奖流程,因为可以允许缓存失败,所以要捕获异常然后打日志即可。
(6)通知中奖者
- 抽奖之后的多个处理,可以并发执行。
- 配置异步线程池:主线程提交任务后,不用等待任务执行完毕,任务会在后台线程池中异步执行。
- 后续也可以扩展为管道+策略模式并行执行多个处理,避免添加新处理时修改已有代码。
- 由于手机短信发送的服务不能个人申请,所以也用邮件代替了。
(7)事务的一致性与消息重试
- 我们需要保证事务的一致性,如果抽奖消息消费失败,应该让数据库表(mysql 和 redis)恢复原样,即实现回滚。
- 中奖通知等抽奖主业务的后续处理,不影响主业务数据,不需要回滚。如果短信发送失败,补发即可。
- 如果失败,我们希望消息重试有限次数,若依旧失败则放入死信队列堆积,便于后续处理异常(网络、服务器、代码 bug)再次重试。为了让消息队列感知到失败,我们需要抛出异常。
- 理清回滚的逻辑:在状态扭转、保存中奖名单两处,对数据库进行了修改。1)扭转状态时,我们设置了遇到异常回滚的事务,那么如果扭转失败,就会终止后续抽奖逻辑(此时状态已经回滚了,而保存名单没有执行,不需要任何回滚);如果扭转正常执行,则会继续执行保存中奖名单。2)如果保存名单正常执行,则会正常退出;如果异常执行,此时状态已经被修改需要回滚,保存名单发生异常也需要回滚。
- 如何回滚,总结:若状态扭转没有被修改,则必不需要任何回滚,立即 return。若状态扭转被修改了,回滚状态后,还需要继续判断中奖名单是否被修改。
- 状态扭转是否需要回滚:因为使用@Transaction,所以要么全部回滚(活动除外),要么全部不会滚。所以只需判断mysql奖品状态是否被修改即可。
- 状态扭转回滚:依然使用活动状态扭转 manager,但是不用判断是否需要回滚(如果想判断,得改一下管道的顺序为倒序,否则奖品先回滚为INIT了,活动状态就会被判断为不需要回滚扭转),直接把所有都回滚了。
- 中奖名单是否需要回滚:判断mysql是否有对应活动奖品的中奖记录。
- 中奖名单回滚:活动奖品维度的要删,活动未完成-》整个活动维度的也要删。
(8)死信队列实现消息重试
- 如果只有普通队列,消费者抛出异常后,普通队列会直接丢弃异常消息,为了实现消息重试/人工处理异常消息,需要配置死信队列。
- 配置死信交换机和死信队列,普通队列要通过死信路由与死信交换机绑定,每次消费者抛出异常给普通队列,普通队列将异常消息路由给死信交换机,再路由给死信队列。异常消息在死信队列堆积,我们处理好异常后,死信队列再把消息传给普通队列,进行消息重试。
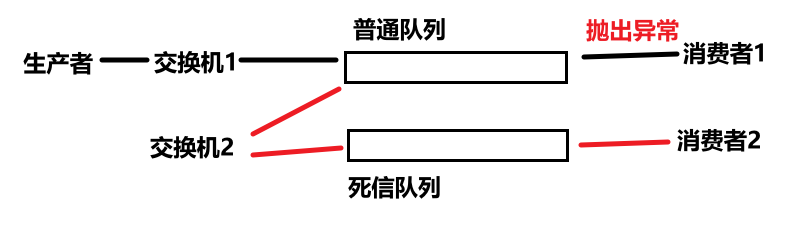
- 配置好后,由于死信队列的消费者也会实时监听死信队列,所以会形成死循环:普通队列消费者重试x次,抛出异常,普通队列捕获,将异常消息给死信队列,死信队列消费者监听到异常消息,获取异常消息又传给普通队列,消息重试。这过程中并没有留给我们时间去处理异常,所以死信队列的消费者仅仅是把堆积的消息传给普通队列,是不行的。
- 正确的做法:死信队列收到异常消息,监听死信的消费者消费异常消息,将异常消息存入数据库表。-》处理异常。-》完成脚本任务,判断数据库表是否存在数据,存在则需要处理。-》将消息发送给普通队列。
-
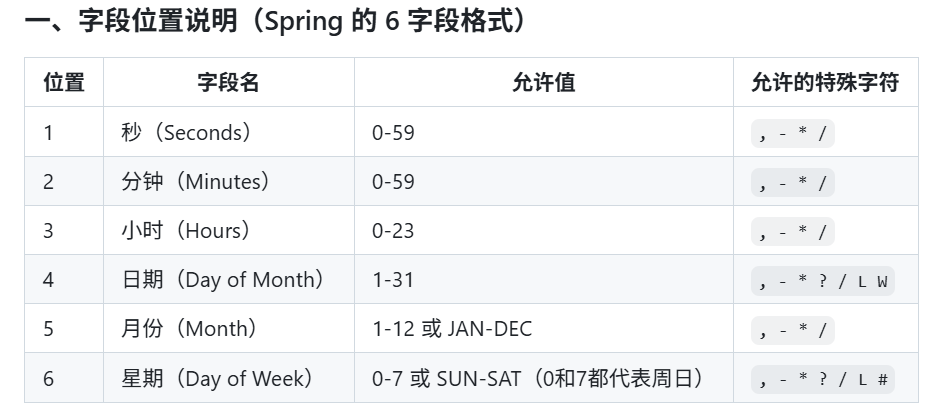
@Scheduled(cron 表达式) 声明该方法是定时任务;@EnableScheduling 开启定时。
- 定时器 cron 表达式:
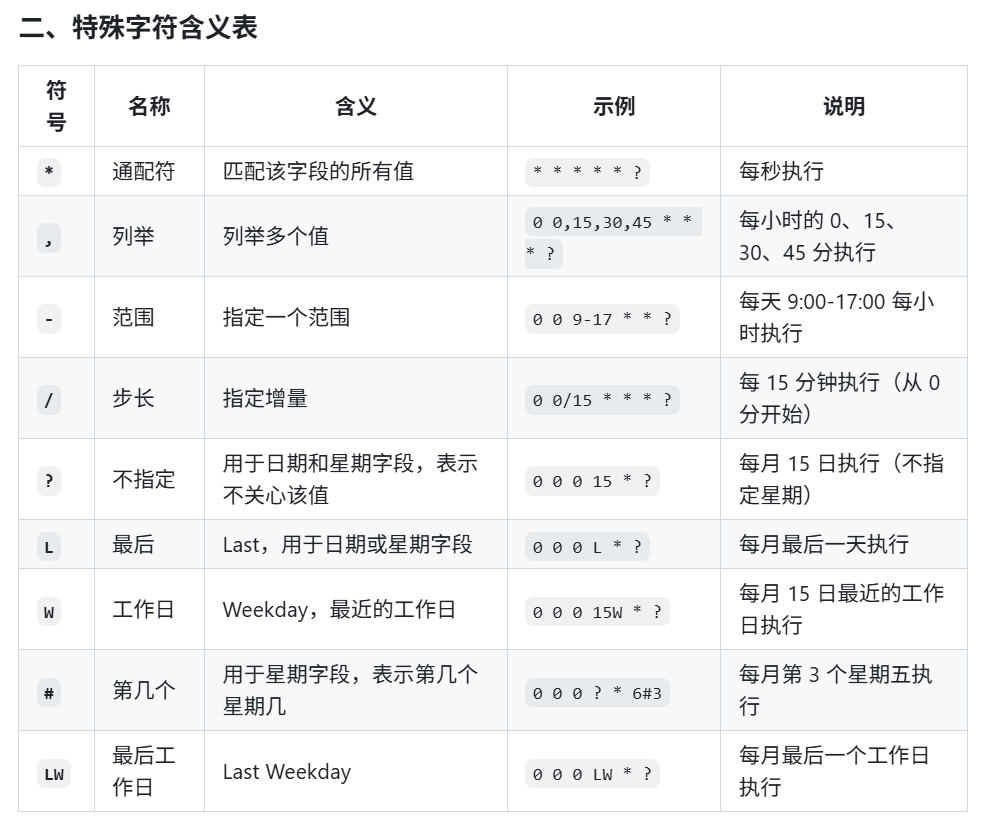
- 时序图
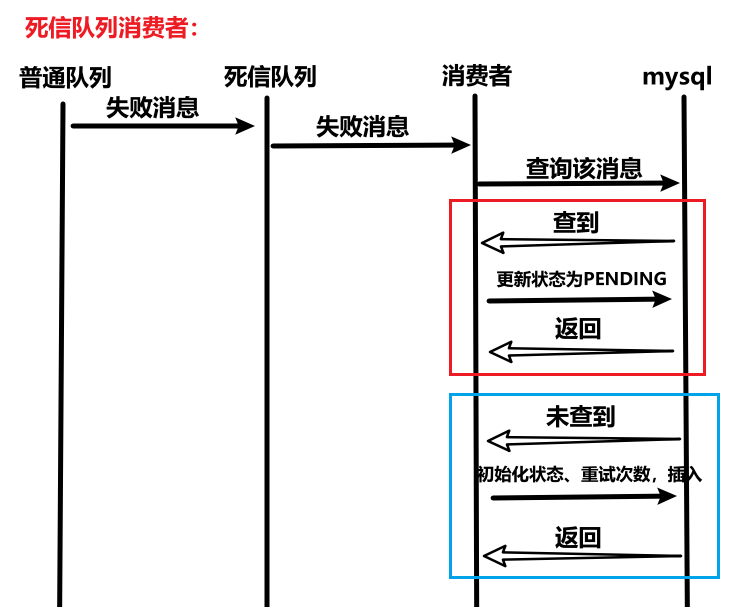
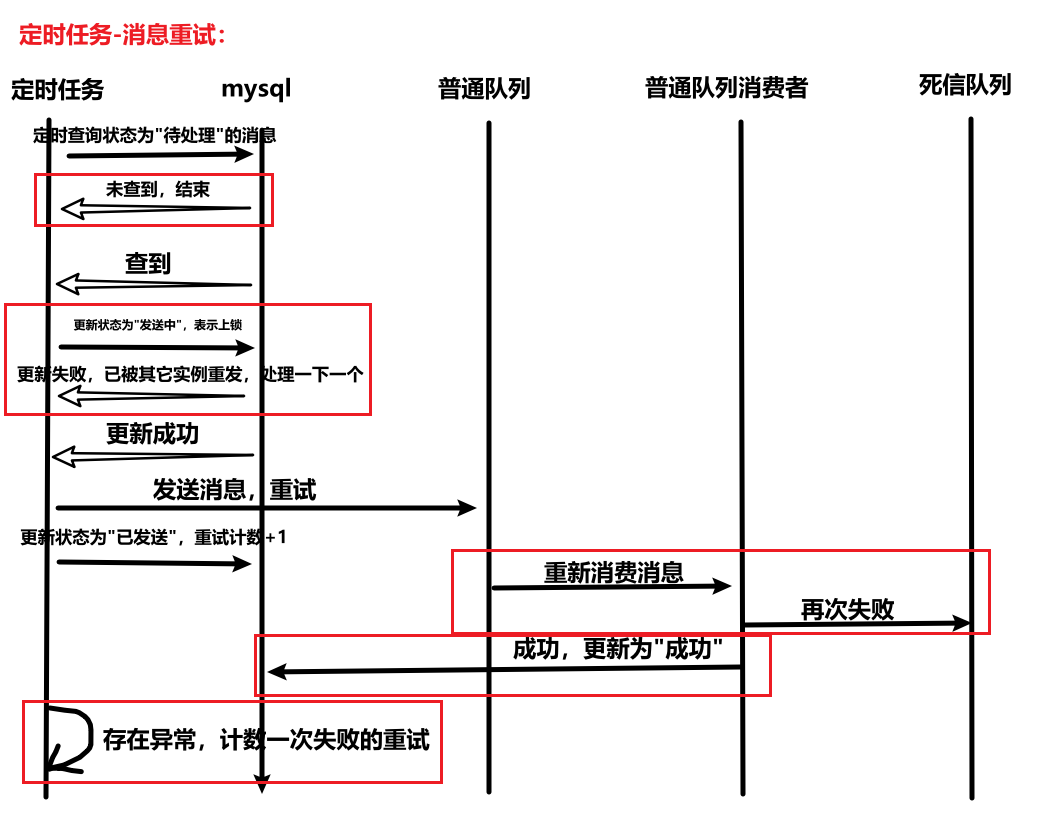
- 为什么要加锁:当多个实例同时执行定时器任务,同时查到同一条待处理的消息。接下来的操作是重试消息,这必定意味着对同一个数据的修改(消息状态、重试次数计数器),这种情况下需要加锁,未抢到锁的不能进行后续处理。
5、测试
可以用 JSON在线解析格式化验证 - JSON.cn 转缓存中的 json 查看。
(1)正向流程
抽奖,但不是最后一次抽奖:
{"activityId":3,"prizeId":5,"winningTime":"2025-05-21T11:55:10.000Z","winnerList":[{"userId":3,"userName":"猪猪侠"}// {// "userId":9,// "userName":"小鸡哇"// }]
}缓存中更新的活动3信息:
{"activityId": 3,"activityName": "抽奖测试","activityDescription": "抽奖","status": "RUNNING", // 活动未结束"prizeDTOList": [{"prizeId": 5,"name": "吹风机","imageUrl": "bda1823a-45af-4639-9666-67f6e0bcae92.jpg","price": 200,"description": "","tiers": "FIRST_TIER","prizeAmount": 1,"status": "COMPLETED" // 已被抽取},{"prizeId": 6,"name": "吹风机2","imageUrl": "951bdb67-5093-43a2-b0e3-4985d8492de7.jpg","price": 200,"description": "","tiers": "FIRST_TIER","prizeAmount": 1,"status": "INIT" // 未被抽取}],"userDTOList": [{"userId": 3,"userName": "猪猪侠","status": "COMMENT" // 已中奖},{"userId": 9,"userName": "小鸡哇","status": "INIT" // 未中奖}]
}缓存中活动3奖品5的中奖记录:
[{"id": 6,"gmtCreate": null,"gmtModified": null,"activityId": 3,"activityName": "抽奖测试","prizeId": 5,"prizeName": "吹风机","prizeTier": "FIRST_TIER","winnerId": 3,"winnerName": "猪猪侠","winnerEmail": {"encrypt": "166564989@qq.com"},"winnerPhoneNum": {"encrypt": "13458961625"},"winningTime": 1747828510000}
]最后一次抽奖:
活动3信息更新:
{"activityId": 3,"activityName": "抽奖测试","activityDescription": "抽奖","status": "COMPLETED", // 已结束"prizeDTOList": [{"prizeId": 5,"name": "吹风机","imageUrl": "bda1823a-45af-4639-9666-67f6e0bcae92.jpg","price": 200,"description": "","tiers": "FIRST_TIER","prizeAmount": 1,"status": "COMPLETED"},{"prizeId": 6,"name": "吹风机2","imageUrl": "951bdb67-5093-43a2-b0e3-4985d8492de7.jpg","price": 200,"description": "","tiers": "FIRST_TIER","prizeAmount": 1,"status": "COMPLETED" // 已被抽}],"userDTOList": [{"userId": 3,"userName": "猪猪侠","status": "COMMENT"},{"userId": 9,"userName": "小鸡哇","status": "COMMENT" // 以抽中}]
}活动3奖品6的中奖记录:
[{"id": 7,"gmtCreate": null,"gmtModified": null,"activityId": 3,"activityName": "抽奖测试","prizeId": 6,"prizeName": "吹风机2","prizeTier": "FIRST_TIER","winnerId": 9,"winnerName": "小鸡哇","winnerEmail": {"encrypt": "1456@qq.com"},"winnerPhoneNum": {"encrypt": "15245673588"},"winningTime": 1747828510000}
]活动3所有中奖记录:
[{"id": 8,"gmtCreate": 1760324402000,"gmtModified": 1760324402000,"activityId": 3,"activityName": "抽奖测试","prizeId": 6,"prizeName": "吹风机2","prizeTier": "FIRST_TIER","winnerId": 3,"winnerName": "猪猪侠","winnerEmail": {"encrypt": "1770674989@qq.com"},"winnerPhoneNum": {"encrypt": "13658361623"},"winningTime": 1747828510000},{"id": 9,"gmtCreate": 1760324437000,"gmtModified": 1760324437000,"activityId": 3,"activityName": "抽奖测试","prizeId": 5,"prizeName": "吹风机","prizeTier": "FIRST_TIER","winnerId": 9,"winnerName": "小鸡哇","winnerEmail": {"encrypt": "1456@qq.com"},"winnerPhoneNum": {"encrypt": "15245673588"},"winningTime": 1747828510000}
](2)异常流程
在状态扭转后抛出异常(测试@Transaction事务对异常回滚):查看mysql表状态、缓存活动详情状态。
在保存中奖名单后抛出异常(测试我们写的回滚流程):查看mysql表状态、缓存活动详情状态、活动奖品中奖名单、活动中奖名单。
(3)消息重发
- 抛出异常后,一共要执行设置的次数(测试项目配置的重试次数)。
- 死信队列消费者,要把失败消息存储到数据库表;对于重试的失败消息,要更新表中状态恢复为 PENDING(测试第一次进入死信队列的情况、测试再次进入死信队列的情况)。
- 定时器任务执行消息重试(测试第一次消息重发、测试消息重发到最大次数、测试消息重发过程中出现异常)。
十三、查询中奖名单
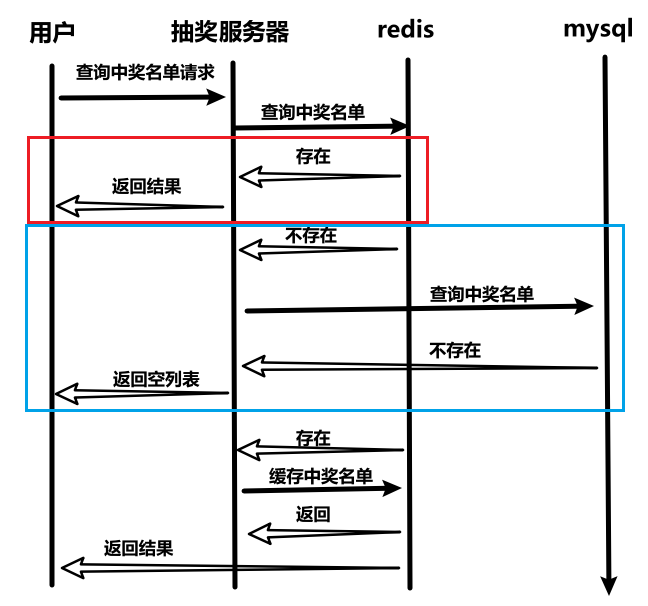
1、时序图
2、接口设计
- 如果只有活动id,则查询活动所有中奖记录;如果有活动id和奖品id,则查询活动某奖品的中奖记录。
请求:/draw-prize/show-winning-records POST
{"activityId": 3// "prizeId": 5
}响应:
{"code": 200,"data": [{"winnerId": 3,"winnerName": "猪猪侠","prizeName": "风扇","prizeTier": "⼀等奖","winningTime": "2025-10-13T11:55:10.000+00:00"},{"winnerId": 9,"winnerName": "小鸡哇","prizeName": "风扇2","prizeTier": "⼀等奖","winningTime": "2025-10-13T11:55:10.000+00:00"}],"msg": ""
}十四、抽奖前端页面
- 活动列表展示活动信息,如果处于进行中,点击连接会进行抽奖;已结束,点击连接会直接显示结果。

- 抽奖链接有3个参数:活动ID、活动名称、是否进行中 valid。
![]()
- 抽奖页面加载:活动valid 为 true,加载抽奖页面配置;为 false,加载抽奖结果。由于普通用户能够访问抽奖页面,来查看抽奖结果,因此当 valid 为 true 时,需要判断访问用户是否为管理员(后端获取 JWT 的 payload 中的 identity)。
我们现在获得了活动的所有信息,包括 steps 奖品列表、names 用户列表。我们初始化了 step 为 0,用于表示目前操作的是第一个奖品;state 为 ' ',表示正在对奖品进行什么操作(展示奖品showPic、人员闪动执行抽奖showBlink、当前奖品抽完展示结果showList、所有奖品抽完展示结果showRecords),初始是展示奖品。
nextStep 按钮根据 state 转换抽奖动作:
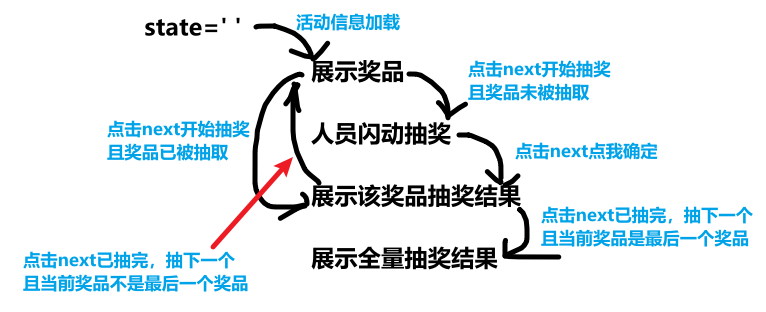
- 展示奖品:加载奖品名称、等级、份数、图片;切换 nextStep 按钮文字为“开始抽奖”。
- 人员闪动抽奖:加载奖品名称、等级、份数;names 用户随机排序,每次闪动取前 prizeAmount 个用户名展示;切换 nextStep 按钮文字为“点我确定”。
- 展示该奖品抽奖结果:加载奖品名称、等级、份数、图片;选中的用户保存在 list 中,用户可能会刷新页面导致丢失,因此若 list 为空,则从后端查询该奖品中奖记录;切换 nextStep 按钮文字为“已抽完,下一步”。
- 展示全量抽奖结果:加载中奖时间、用户、奖品、等级;创建分享链接按钮和触发行为的定义,构造url链接和参数(活动是否有效、按钮是否隐藏),根据参数隐藏按钮。
previousStep 按钮将 state 设置为 ' ',step 回退 1 个奖品。
十六、遇到的问题
1、手机号唯一性校验失效
发现 bug:校验手机号唯一值失败,插入重复手机号也能成功。
我一开始是想把手机号也随机加盐的,因为我认为我在 TypeHandle 重写了 get 方法解密,按明文手机号 select count 的时候就会先把 select 的数据库加密手机号一行行解密再条件筛选后 count,这个错误也是因为我对 TypeHandle 的使用不够到位(一开始认为 get 由 select 触发)。通过查资料,set 是 SQL 参数值(即 #{} 里的类型)有 TypeHandle 指定类型时触发;get 是对查询到的结果集字段有指定类型触发。而 select count 的结果集是字段是 count,所以并不会触发 get 解密,而是触发 set 加密,再进行手机号密文筛选计数。而手机号密文加了随即盐,同一手机号每次生成的密文都是不一样的,所以重复的手机号也能插入成功。因此,如果想通过手机号明文直接查询,就不能加盐。
2、再次执行 sql 脚本失败
发现 bug:终端再次 source 同一 sql 脚本卡死。
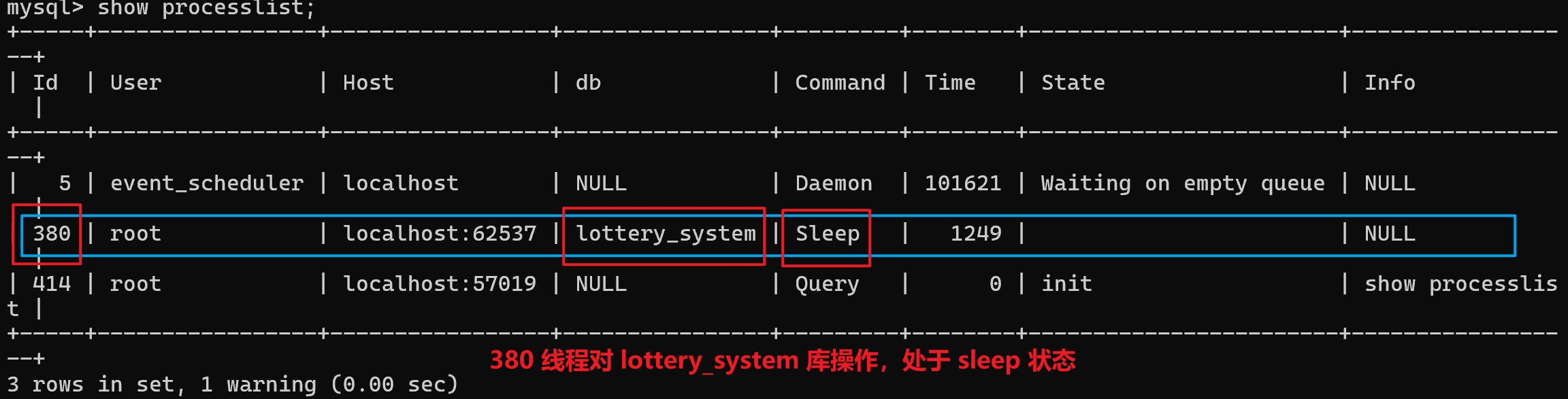
库中杂乱数据太多,想重建,结果卡死,无奈 crl+c 强制结束。后面发现直接 sql 语句删库也卡死:

查资料,是之前有个连接操作了同一个数据库没有断开,处于 Sleep 状态(持有共享锁),其它连接执行 drop 操作(持有排他锁)就会阻塞。(原理:对数据的增删改查需要使用共享锁;对库、表结构的创建删除修改需要使用排他锁;并且排他锁和共享锁是互斥的)
show processlist 查看数据库服务器上的所有线程(连接):
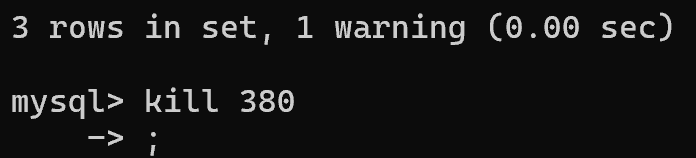
kill 掉 380 即可:
3、邮箱发送功能抛错
① mailSender 可能为空:因为我想实现工具类静态方法,那么 mailSender(@Resource 注入)和 from(@Value 注入) 发件人都要加上 static,但这些注解注入的是实例,不能被 static 修饰。
② SMTP 服务器要求与客户端建立安全连接,但客户端未配置。

配置 SSL 安全连接:Spring Boot 发送邮件 - spring 中文网
port: 465 # SMTP 邮件服务器端口, SSL 加密的端口号为 465protocol: smtps # 协议properties:"mail.smtp.auth": true # 启用 SMTP 身份验证"mail.smtp.starttls.enable": true # 启用 SSL 加密连接4、RabbitMQ 队列参数不一致
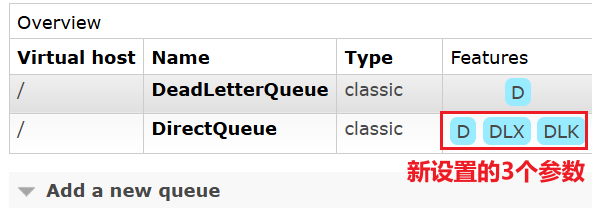
之前直接创建了普通队列,它只设置了是否持久化参数;后面又创建了设置了死信交换机和路由键的同名普通队列,导致参数不一致。解决办法:去可视化页面删掉之前创建的交换机、普通队列。
5、JSON 反序列化解析失败
从redis读取中奖记录,反序列化为 List<WinningRecordDO> 时出现异常:
com.fasterxml.jackson.databind.exc.MismatchedInputException:
Cannot construct instance of `io.gitee.piggymi.lotterysystem.dao.pojo.security.SymmetricEncrypt`
(although at least one Creator exists): cannot deserialize from Object value
(no delegate- or property-based Creator)at [Source: REDACTED (`StreamReadFeature.INCLUDE_SOURCE_IN_LOCATION` disabled);
line: 1, column: 204] (through reference chain: java.util.ArrayList[0]->io.gitee.piggymi.lotterysystem.dao.pojo.dataobject.WinningRecordDO["winnerEmail"])- 简单来说,这个错误表示 Jackson 在尝试反序列化 JSON 数据时,无法将 JSON 中的
winnerEmail字段的值转换为SymmetricEncrypt类型。这可能是由于SymmetricEncrypt类缺少 Jackson 所需的无参构造方法或反序列化逻辑。 - 所以对于需要序列化的类,写上无参构造函数 和 Serializable 真的很重要!!这个场景的错误是因为 JSON 用无参构造函数创建属性没有值的对象,再通过反射/注解给属性赋值。