特斯拉前AI总监开源的一款“小型本地版ChatGPT”,普通家用电脑就能运行!
就在前天,前特斯拉AI总监Karpathy推出的开源项目“nanochat”一夜间爆火,该项目仅用约8000行代码便复现了 ChatGPT 的全流程,用户只需要有一台GPU、再花上 4 小时做下训练,就能训练出一个能写诗、回答基础问题的“小型ChatGPT”。全场费用下来成本不到 100 美元!
项目地址:https://github.com/karpathy/nanochat
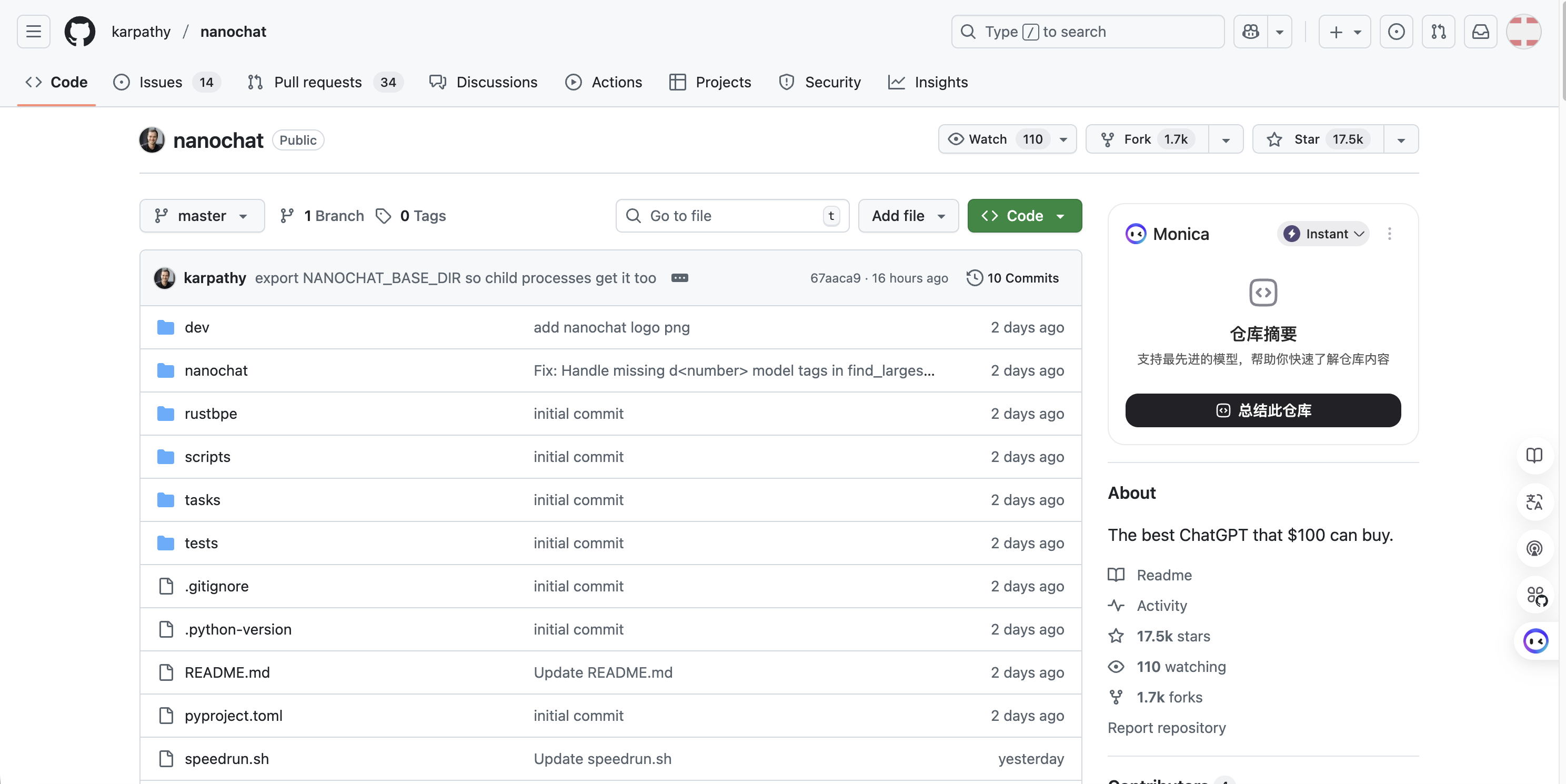
该项目只用了不到 2 天时间,就已经快达到 20K 星标了,这也是博主见过的近几年涨粉最快的开源项目了!
接下来,我将和大家详细聊聊这玩意是什么?以及如何进行本地化部署!
项目速览
nanochat 是 Karpathy 继 nanoGPT 之后推出的全栈式小型语言模型训练框架,目标是在 4 小时内、以约 100 美元的成本,复现一个可对话的 ChatGPT 克隆体。
| 维度 | 指标 |
|---|---|
| 代码行数 | ≈ 8 000 |
| 训练时长 | 4 h(100 ) |
| 模型规模 | 561 M 参数(depth=30) |
| 训练硬件 | 8×H100 GPU |
| 最终交付 | CLI + ChatGPT-style WebUI |
都包含了哪些技术路径?
分词器
用 Rust 重写训练级 tokenizer,压缩率 4.8 char/token,兼容 tiktoken 推理。
预训练
在 FineWeb 语料上预训练 GPT-style Transformer(MQA + RoPE + ReLU²),同步输出 CORE 分数。
中期训练(Midtrain)
使用 SmolTalk 的对话、选择题、工具调用子集继续训练,对齐对话格式。
监督微调(SFT)
在 ARC-E/C、MMLU、GSM8K、HumanEval 上微调,提升问答、数学、代码能力。
强化学习(RL,可选)
采用 GRPO 算法在 GSM8K 上进一步对齐,显存占用低于 PPO。
推理与交互
• KV-Cache 引擎,支持流式解码 • 内嵌轻量级 Python 沙箱,可执行工具调用 • CLI 与 WebUI 双接口
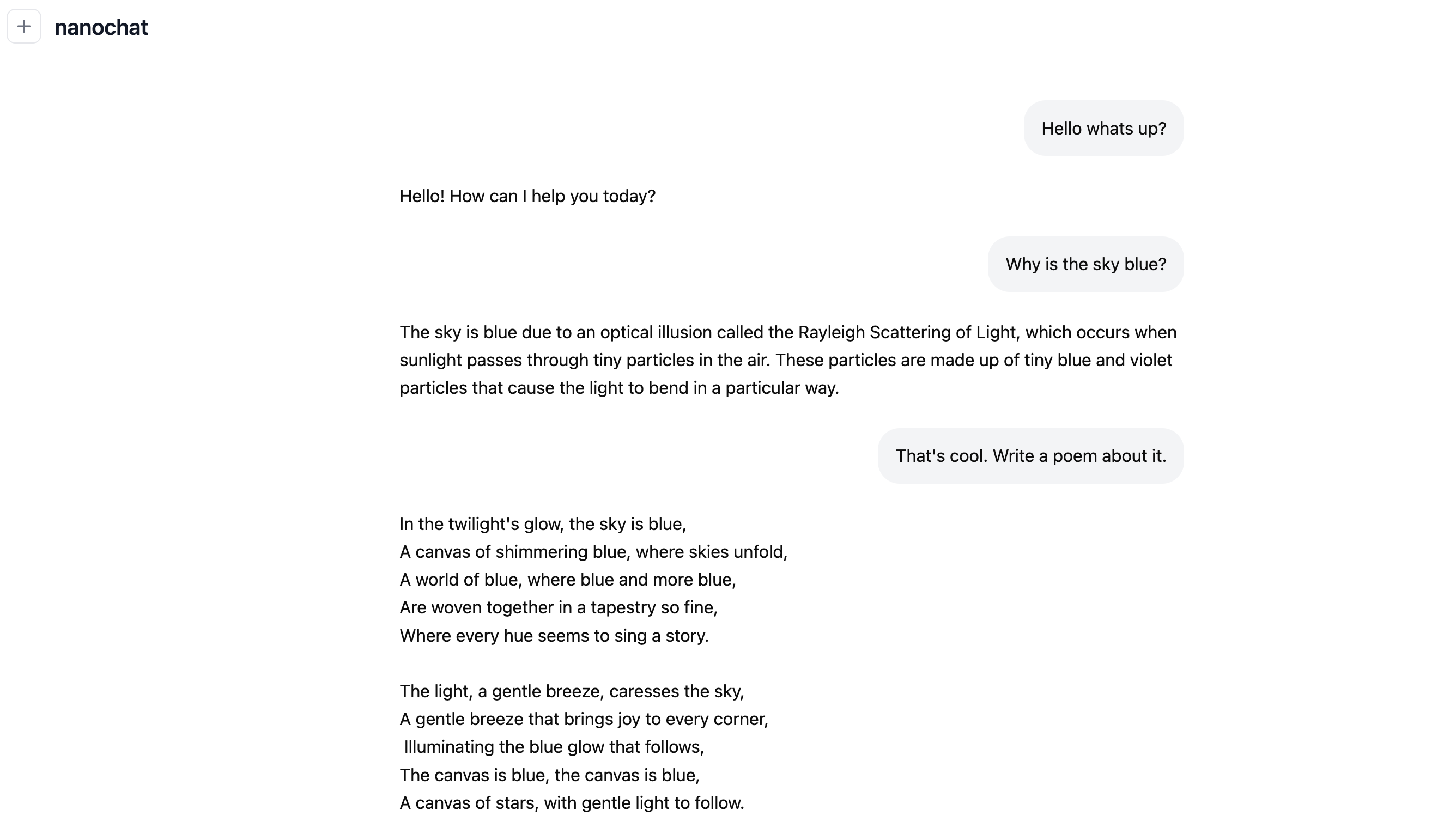
性能阶梯
| 训练成本 | 训练时长 | CORE 指标 | 能力描述 |
|---|---|---|---|
| 100 $ | 4 h | ~GPT-2 级 | 闲聊、写诗、简单问答 |
| 300 $ | 12 h | >GPT-2 | 逻辑推理、短篇故事 |
| 1 000 $ | 41.6 h | 接近 GPT-3 125 M | 数学、代码、多选题 |
🌈
“depth=30 的模型在 MMLU 上 40 分、ARC-Easy 70 分、GSM8K 20 分,与 GPT-3 Small 的 FLOPs 相当。”
🌈
—— Karpathy 推文
快速开始
1、克隆 github 仓库
git clone https://github.com/karpathy/nanochat.git
克隆完成后,切换到nanochat 目录
cd nanochat
2、启动云 GPU(示例:RunPod)
执行以下命令启动
runpodctl create pod --gpu 8xH100 --image ubuntu:22.04
3、一键训练
使用以下命令即可开始一键训练了
python base_train.py --depth 30 --budget 100
4、启动 WebUI
使用以下命令启动 web 界面
python serve.py --checkpoint out/model.ckpt
接下来,浏览器打开 `http://:5000 就可以开始对话了!
文件结构(核心)
├── train_tokenizer.rs # Rust 分词器
├── base_train.py # 预训练 + SFT
├── rl_train.py # GRPO 强化学习
├── serve.py # 推理服务器
├── static/ # WebUI 前端
└── report_card.md # 自动生成的游戏化报告
这个小模型都有哪些适用场景?
- 教育:LLM 101 课程实验,完整展示数据到部署。
- 研究:低成本验证新算法或数据配比。
- 私有化:内网部署,无需调用外部 API。
- 边缘实验:在 8×A100 或 4090 上复现小规模结果。
还可以做些私有化模型语料库,例如:博主最近开发的改写 Agent 就是用的自训练小模型,经过了大量 AI 浓度为 0 的文章进行词元拆解训练!
局限与展望
• 当前 RL 阶段仍处实验性,稳定性待提升。
• 仅支持英文,多语言 tokenizer 需自行训练。
• Karpathy 计划将 nanochat 作为 LLM101n 顶点项目,未来或引入 LoRA、MoE 等扩展。
🌈
“这不是最优雅的实现,但一定是最易 fork 的基线。”