映诗:基于视觉编码与自然语言生成的作诗平台
项目描述
本平台通过识别用户上传的图片匹配关键词,再根据得到的关键词生成诗句。
– 基于CLIP模型对传入图片编码,将图像编码与关键词编码计算余弦相似度,取出相似度前TOP5的关键词。
– 在诗句生成阶段,基于关键词及古诗词重新训练一个T5模型。模型推理阶段,根据上一阶段匹配到的关键词生成诗句。
相关知识点
1. CLIP模型
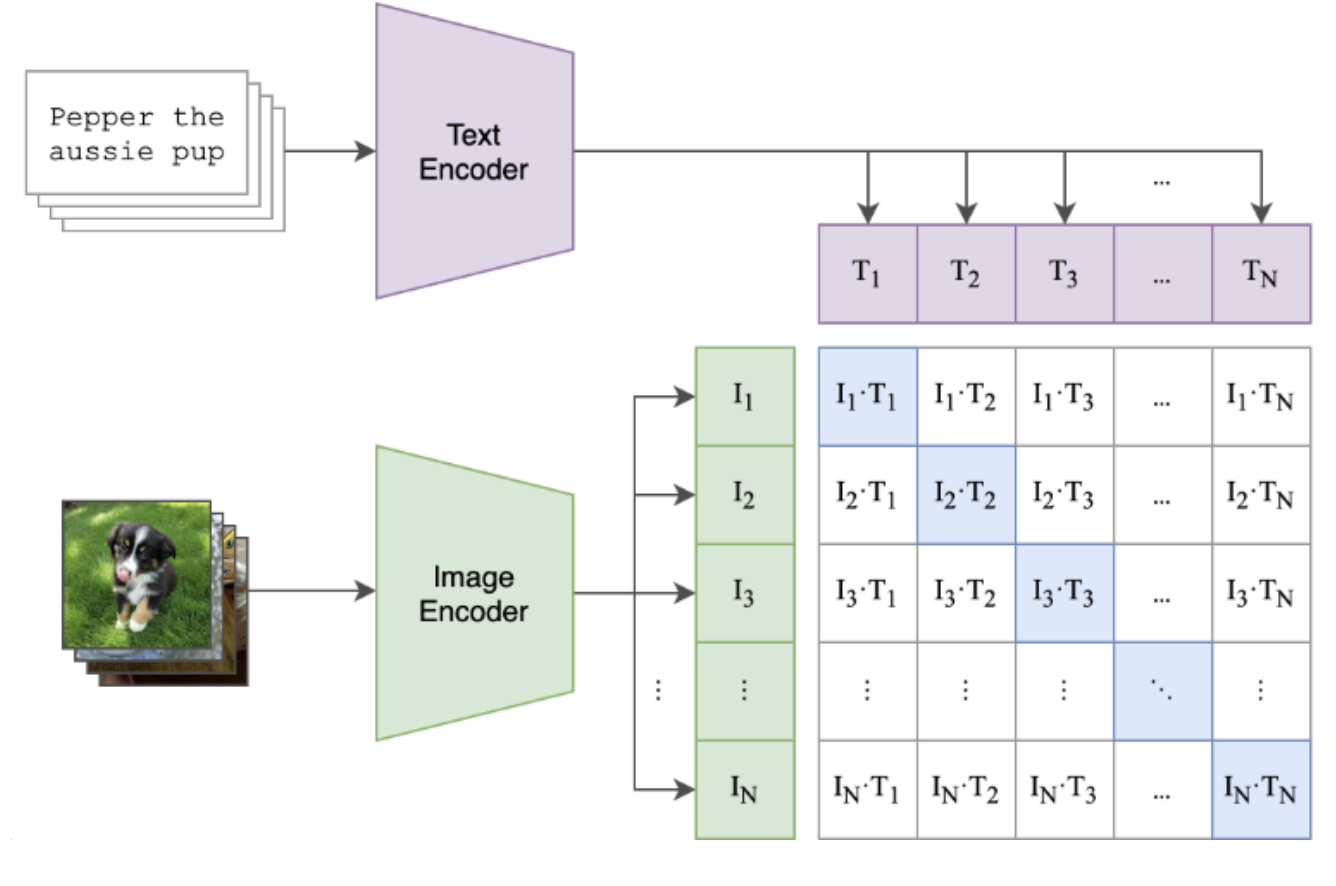
1.1. 原理
同时处理图像和文本,并将其分别映射到同一个向量空间。让对应的图像和文本在该空间中的向量表示尽可能接近,而 非对应的文本和图像则要尽可能远离。
1.2. 模型架构
- 图像编码器:VIT 或者 ResNet模型,将输入图像转换成一个高维向量。
- 文本编码器:Transformer模型,将输入文本转换成另一个高维向量。
1.3. 训练过程
- 从一个批次中取出N个(图像,文本)对。
- 分别经过图像编码器和文本编码器,得到N个图像向量和N个文本向量。
- 计算N✖️N对相似度矩阵。(使用余弦相似度)
- 训练目标: 最大化 对角线上的相似度, 最小化 非对角线上的相似度。
1.4. 本项目中的应用
由于CLIP的“零样本”分类能力,可以无需任何特定任务的训练,直接用于将图像和任意文本描述关联起来。
用户上传的图片 + 预先构建的唐诗关键词库 -----> CLIP模型 ----> 选取top5的关键词。
2. T5模型
接收一段文本输入,并生成一段文本输出。将纷繁复杂的NLP任务统一到一个简单的文本到文本框架下。
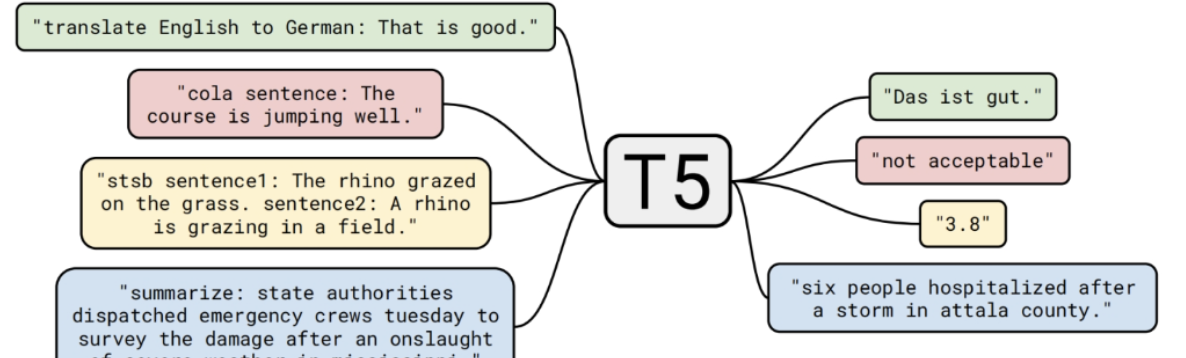
2.1. 模型架构:编码器-解码器
T5采用了经典的Transformer编码器-解码器架构。
- 编码器:负责处理和理解输入文本。它双向地查看整个输入序列,生成一个包含上下文信息的表示。
- 解码器:负责生成输出文本。它自回归地(一个接一个词)生成结果,在生成每个词时,会关注编码器的输出和已经生成的部分。
2.2. 训练过程
预训练:采用BERT式的训练方法,掩盖一部分词,还原被掩盖的词。例如:Thank you<MASK>``<MASK>me to your party<MASK>week|Thank you for inviting me to your party last week.
2.3. 本项目的应用
对T5微调,通过用大量的(关键词, 诗句)配对数据来微调T5,模型学会了将一组看似无关的关键词,组织成一首符合古诗词格律和意境的连贯诗句。
- 输入文本:匹配到的top5的关键词。["柳树", "春风","别离","月光","剑"]
- 输出文本:模型需要生成完整的诗句。