数据湖Hudi-读取流程可视化
要理解 Hudi(Hadoop Upserts Deletes and Incrementals)的读取流程,需先明确其核心存储模型与表类型差异——Hudi 基于 “File Group(文件组)+ File Slice(文件切片)” 组织数据,且分为COW(Copy-On-Write,写时复制) 和MOR(Merge-On-Read,读时合并) 两种表类型,两者的读取逻辑因 “数据合并时机” 不同而存在显著差异。
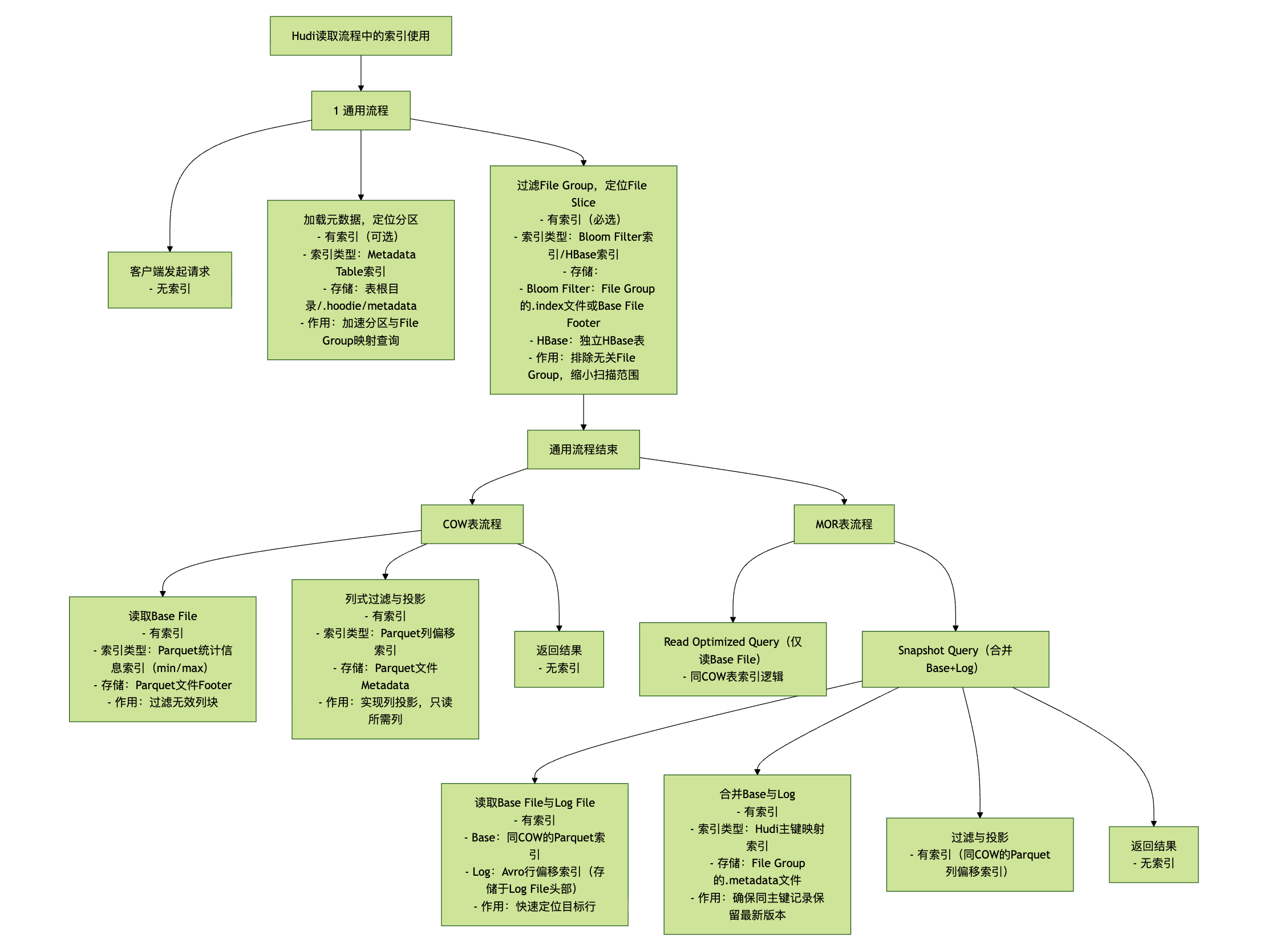
以下从 “通用基础流程” 切入,再分别拆解 COW 和 MOR 的具体读取逻辑,结合 Hudi 的元数据组件(如 Timeline、Metadata Table)说明关键步骤。
一、Hudi 读取的核心基础:先明确 3 个关键概念
在梳理流程前,需先理解 Hudi 存储的核心组件,它们是读取流程的 “骨架”:
- File Group(文件组):按主键(Record Key)哈希分区,每个 File Group 对应一组 “同主键范围” 的数据,用
File Group ID唯一标识; - File Slice(文件切片):每个 File Group 包含多个 File Slice,每个 Slice 对应一次数据写入 / 更新的 “版本”,由两部分组成:
- Base File:列式存储的 Parquet 文件(COW 表的唯一数据文件,MOR 表的基础数据文件);
- Log File(Delta Log):仅 MOR 表存在,行式存储的 Avro 文件,记录 Base File 之后的增量更新(插入 / 删除 / 修改);
- Timeline(时间线):记录 Hudi 表的所有数据操作(如 Commit、Compaction),每个操作有唯一的
Instant Time(时间戳),读取时需指定 “读取哪个 Instant 的快照”。
二、Hudi 通用读取流程:所有表类型的共通步骤
无论 COW 还是 MOR 表,读取流程的 “前置环节” 一致,核心是 “定位目标数据文件”,步骤如下:
1. 客户端发起读取请求
- 读取入口:通过 Hudi 提供的 API(如
HoodieDataSourceReader)、Spark SQL(SELECT * FROM hudi_table)或 Flink SQL 发起请求,需指定关键参数:- 表路径(如 HDFS 路径
hdfs://cluster/hudi/db/orders); - 查询类型(如 Snapshot Query:读取最新快照;Incremental Query:读取增量数据;Read Optimized Query:仅 MOR 表,读取优化后的 Base File);
- 过滤条件(如分区键
dt='2025-01-01'、主键order_id=12345)。
- 表路径(如 HDFS 路径
2. 加载 Hudi 元数据,定位目标分区
- 客户端首先读取 Hudi 表的元数据目录(
/.hoodie),获取以下信息: