深度学习赋能基因与蛋白质研究:从“盲猜”到“精准导航”的生命科学革命
你有没有过这样的经历
面对一幅一万块的巨型拼图,不仅没有说明书,还少了近一半的拼块,却要在规定时间内拼出完整图案?
这曾是生命科学家研究蛋白质结构时的真实困境——我们知道基因是“生命的密码”,却花了几十年时间,都难以破解“密码如何变成有功能的蛋白质”这关键一步。
深度学习(Deep Learning)的出现,这场持续半个世纪的“拼图游戏”终于迎来了“智能导航”。
困境:生命科学里的“拼图难题”
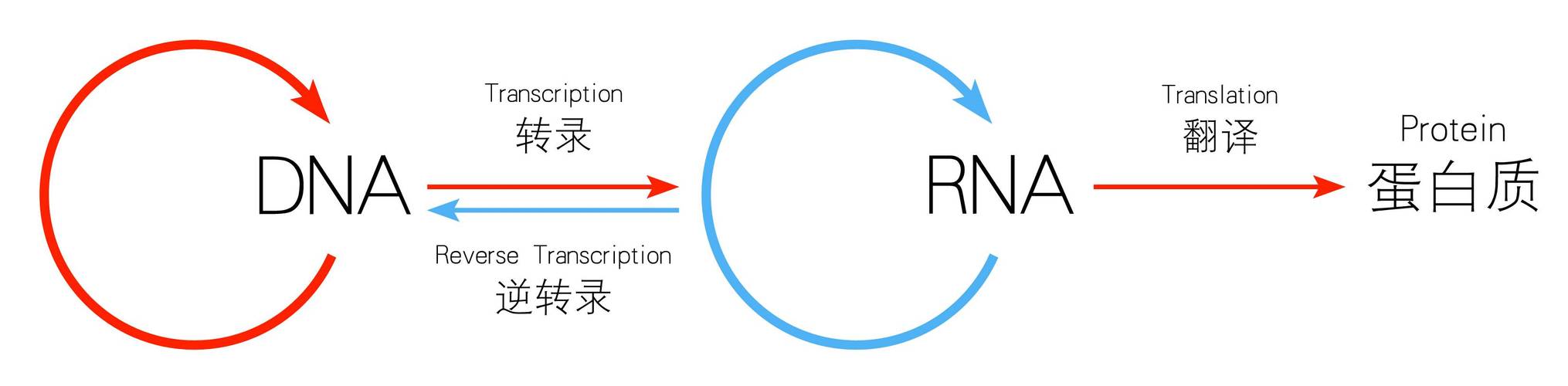
要理解这场革命,我们得先回到一个基础问题:基因和蛋白质到底是什么关系?
简单来说,基因(DNA)就像一本“食谱”,上面写满了制作蛋白质的“配方”——氨基酸序列;
而蛋白质则是根据食谱做出的“菜肴”,它的3D结构(比如螺旋、折叠的形状)直接决定了“味道”(生物功能):有的蛋白质是运输氧气的“快递员”(血红蛋白),有的是对抗病毒的“战士”(抗体),还有的是调节代谢的“指挥官”(酶)。
一旦蛋白质结构出错,就可能引发癌症、阿尔茨海默症等大病。但要“看清”蛋白质的3D结构,曾经比登天还难。
传统方法比如X射线晶体学,需要先把蛋白质变成晶体,再用射线照射分析——这个过程就像“把棉花糖冻成冰块”,不仅成功率低(很多蛋白质无法结晶),还耗时耗力:解析一个蛋白质结构平均要3-5年,花费数百万美元。
到2018年,人类已知的蛋白质序列超过1亿种,但解析出结构的还不到10万种,就像手里攥着海量“食谱”,却不知道对应的“菜”长什么样。
更棘手的是,基因到蛋白质的“翻译”过程还藏着无数“暗码”:一段DNA序列如何决定氨基酸的排列?氨基酸又如何折叠成特定结构?
传统实验方法就像“逐个试错”,根本追不上生命系统的复杂程度。生命科学迫切需要一种能“从规律中找答案”的新工具——深度学习应运而生。
医学AI交流群
目前小罗全平台关注量120,000+,交流群总成员3000+,大部分来自国内外顶尖院校/医院,期待您的加入!!
由于近期入群推销人员较多,已开启入群验证,扫码添加我的联系方式,备注姓名-单位-科室/专业,即可邀您入群。
一、深度学习如何“看透”生命密码?
深度学习解决蛋白质和基因问题的核心逻辑,和我们“从经验中学习”的过程很像:比如看了1000张猫的照片后,再看到一只新猫,你能立刻认出它——AI则是“看”了百万级的基因和蛋白质数据后,总结出规律,进而预测未知。
第一步:收集“生命拼图的所有参考图”——数据准备
就像拼拼图前要先收集所有已拼好的图案,AI首先需要“阅读”海量的已知数据:包括已解析的蛋白质结构(来自蛋白质数据银行PDB)、基因序列(来自人类基因组计划等数据库),以及它们之间的对应关系。

比如“这段DNA序列对应胰岛素的氨基酸序列,胰岛素的结构是两个螺旋加三个折叠”。
为了让AI“读得懂”这些数据,科学家会把基因序列转换成“数字语言”(比如用不同数字代表A、T、C、G四种碱基),把蛋白质结构转换成“空间坐标”(记录每个氨基酸的位置)。
这一步就像把“食谱”和“菜的照片”整理成统一格式,方便AI快速学习。
第二步:训练“找规律的智能眼睛”——模型设计
这是深度学习最核心的一步,不同的AI模型就像“不同的拼图技巧”,针对不同问题发挥作用:
卷积神经网络(CNN):擅长“看局部细节”
它能捕捉基因序列中的“局部特征”,比如某段碱基组合可能是“启动基因表达的开关”。
就像拼拼图时,先看相邻几块的边缘形状是否匹配——CNN能快速识别DNA中的调控元件,比如DeepBind模型用它找出了RNA结合蛋白的结合位点,发现了很多以前未知的基因“控制器”。
循环神经网络(RNN):擅长“读顺序逻辑”
基因和蛋白质都是“有顺序的序列”(比如DNA是碱基的线性排列),RNN就像“读句子时关注上下文”,能分析序列中前后元素的依赖关系。
比如预测某段氨基酸序列会如何折叠时,RNN会考虑“前一个氨基酸是疏水的,可能会和后面的亲水氨基酸形成特定角度”。
Transformer架构:擅长“看全局关联”
这是让AlphaFold“封神”的关键技术。

蛋白质折叠时,不仅相邻的氨基酸会相互作用,相隔很远的氨基酸也可能“隔空拉近距离”——Transformer的“注意力机制”就像“拼拼图时看盒子上的成品图”,能同时关注所有氨基酸之间的联系,计算它们形成特定结构的概率。
比如AlphaFold2会先预测每对氨基酸的距离,再根据这些距离“搭建”出3D结构,就像先确定拼图中每块的相对位置,再整体拼接。
第三步:“试错优化”——让预测更精准
AI不是一开始就能完美预测的。
科学家会把一部分已知数据“藏起来”,让AI先根据其他数据预测,再对比“藏起来的正确答案”——如果预测的蛋白质结构和实际结构差得远,就调整模型参数,直到误差缩小到“接近实验精度”。
这个过程就像你拼完拼图后,对照成品图调整错位的几块,直到严丝合缝。
二、从“实验室胜利”到“拯救生命”的实战
CASP竞赛——蛋白质预测的“奥运会”
CASP(国际蛋白质结构预测竞赛)是生命科学领域的“世界杯”,让全球科学家预测未知的蛋白质结构,再用实验结果打分。

2018年以前,最好的模型预测误差(RMSD)还在4埃以上(相当于头发丝直径的1/20000,看似小,但对蛋白质功能来说足以“失之毫厘,谬以千里”)。
2020年,DeepMind的AlphaFold2参加CASP14,交出了震撼全场的答卷:对25个蛋白质靶点的预测中,有21个达到“接近实验精度”(RMSD<1埃),其中最难的一个膜蛋白(与癌症相关),预测结构和后续实验结果几乎完全重合。
评委评价:“这相当于把蛋白质结构预测从‘猜谜’变成了‘常规操作’。”
更关键的是速度:传统方法解析这个膜蛋白可能需要2-3年,AlphaFold2只用了2周。这意味着,以前“不可能解析”的蛋白质,现在能快速“看清”它们的样子。
与病毒赛跑的“关键武器”
2020年初,SARS-CoV-2肆虐时,科学家首先需要知道它的“致命武器”——刺突蛋白(S蛋白)的结构,才能设计疫苗和药物。但传统方法解析刺突蛋白至少需要3个月,而疫情不等人。
DeepMind在疫情爆发后10天内,就用AlphaFold预测了刺突蛋白的结构;随后,美国德克萨斯大学的团队基于这个预测,快速设计出能结合刺突蛋白的抗体片段,为mRNA疫苗(如Moderna、辉瑞)的研发提供了关键参考。
后来的实验证明,预测的结构与实际解析结果误差仅0.5埃,完全满足药物设计需求。
这场“实战”让人们看到:深度学习不仅能“做研究”,还能在危机时刻“救死扶伤”。
三、从“解析生命”到“改造生命”的新可能
深度学习带来的,远不止“更快的拼图工具”,而是整个生命科学研究范式的改变。
精准医疗:从“一刀切”到“私人定制”
以前,医生治疗癌症可能用同一种化疗药物,因为不知道每个患者的肿瘤细胞中,到底是哪种蛋白质发生了突变。
现在,通过AI分析患者的基因序列,能快速预测出“异常蛋白质”的结构,进而设计针对性的靶向药。
比如针对肺癌的EGFR抑制剂,就是基于AI预测的EGFR突变蛋白结构开发的,能精准杀死癌细胞,减少对正常细胞的伤害。
未来,每个人的“基因-蛋白质图谱”可能会成为病历的一部分,医生能根据你的独特图谱,提前预测可能出现的疾病,甚至“修复”有问题的蛋白质——这就是“预测性医疗”的核心。
药物研发:从“大海捞针”到“精准定位”
传统药物研发就像“大海捞针”:在数百万个化合物中筛选能结合目标蛋白质的分子,平均耗时10年,花费28亿美元。
而AI能根据蛋白质结构,“反向设计”出能精准结合的分子——比如美国Insilico Medicine公司用AI设计的一款抗纤维化药物,从靶点发现到临床前试验只用了18个月,成本降低了70%。
更颠覆的是“蛋白质设计”:科学家已经能用AI设计出自然界中不存在的蛋白质,比如能高效降解塑料的酶、能储存二氧化碳的“人工蛋白”。
这意味着,我们不再只是“解读生命”,还能“改造生命”,解决环境、能源等全球性问题。
解锁“生命暗物质”:看清以前“看不见”的世界
人类基因组中,有98%的DNA是非编码序列(曾被称为“垃圾DNA”),以前不知道它们的作用。
现在,用CNN和Transformer分析这些序列,发现很多“垃圾DNA”其实是调控基因表达的“开关”——比如某段非编码序列突变后,会导致蛋白质折叠异常,引发自闭症。
AI正在帮我们“读懂”这些以前“看不懂”的生命密码,揭开更多疾病的根源。
结语:一场“读懂生命”的永恒旅程
回到开篇的拼图类比:如果生命是一幅无穷无尽的拼图,那么深度学习就像给了我们一盏“透视灯”——它不仅能帮我们快速拼出已知的部分,还能照亮那些“缺失的拼块”,让我们看清生命的全貌。
从AlphaFold解析第一个蛋白质,到AI设计第一个人工酶,再到未来可能的“基因编辑治疗”,我们正在经历一场“读懂生命、改造生命”的革命。
这场革命的核心,不是AI取代科学家,而是让人类更懂生命的规律,更有能力对抗疾病、守护健康。
参考资料
本文核心技术参考:Zaw Myo Hein等2025年发表于Preprints.org的综述《AI and Machine Learning in Biology: From Genes to Proteins》,doi:10.20944/preprints202508.1952.v1