建设摩托车125价格东莞网站seo优化
一、DBSACAN与K-means:
我们刚入门时,大部分学的都是k-means聚类。当我们进行实例操作时,会发现k-means聚类方法有很大的局限性,它无法分离任意形状的数据集如下图。
该数据集对于k-means方法来说,有点过于强人所难了,但对DBSCAN来说,却是小菜一碟。下面我将向大家介绍DBSCAN算法的原理,以及代码是实现。
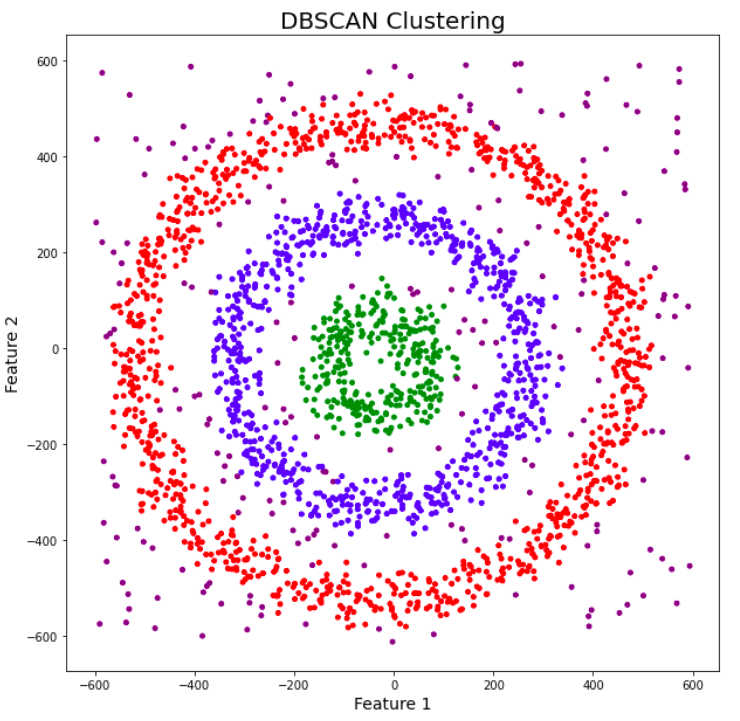
应用场景:适用于非凸形状聚类(如验证码识别、3D点云分割),解决k-means无法处理的复杂分布问题。
二、核心思想:
想象你在校园里发问卷:
ε-邻域:以你为中心,半径 ε 内的同学就是你的“直接朋友圈”。
核心点:如果你的直接朋友圈人数 ≥
min_samples,你就是“核心人物”,有资格成立社团。边界点:你恰好在别人的朋友圈里,但自己朋友圈人数不够,只能算“编外成员”。
噪声点:既没资格成立社团,也不属于任何朋友圈,就是“独行侠”。
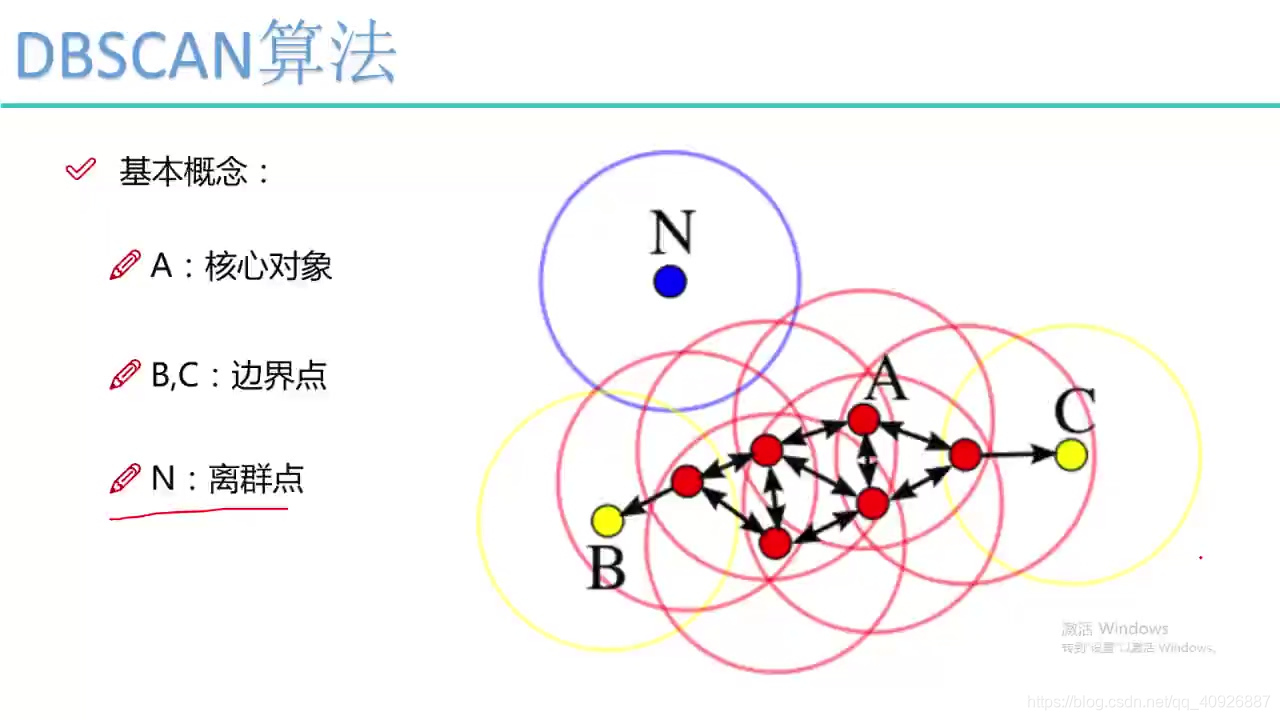
从图中可以看出:
A是核心对象:它可以感染3个点,半径就是ε阈值,
红色的点都可以独立感染3个点都可以叫做核心点
B、C:由于不能独立感染,有其他点感染过来,不能感染其他点,所以叫做边界点,小于min——samples都叫做边界点。
N:噪声点也叫做离群点,从图中可以明显看出,独立成团。
算法流程一句话:
从任意一个未访问点出发,如果是核心点,就把它的 ε-邻域里所有能连上的点归为一个簇;循环往复,直到所有点被访问。
三、三大超参数
| 参数 | 作用 | 常用取值建议 |
|---|---|---|
eps (ε) | 邻域半径 | 先用 k-距离图 找拐点,或网格搜索 0.1~2.0(标准化后) |
min_samples | 成为核心点的最少邻居数 | 维度×2 或 3~10 |
metric | 距离度量 | 默认欧氏距离,也可曼哈顿、余弦… |
四、sklearn 接口速查表
from sklearn.cluster import DBSCANmodel = DBSCAN(eps=0.5, # 邻域半径min_samples=5, # 最小邻居数metric='euclidean',# 距离函数algorithm='auto', # 近邻搜索算法 {'auto','ball_tree','kd_tree','brute'}p=2 # 闵可夫斯基距离的 p
)
labels = model.fit_predict(X)常用属性:
labels_:每个样本的簇编号,-1 代表噪声core_sample_indices_:核心点索引components_:核心点本身坐标
五、实战演练(含完整代码)
1. 读数据 & 标准化
DBSCAN 对尺度极度敏感,标准化是必须的:
如果有些数据较大,如800,900等数据,如果ε-邻域较小,就会造成无法感染。所以必须标准化
import pandas as pd
from sklearn.preprocessing import StandardScalerdata = pd.read_table("data.txt", sep=' ')
num_cols = ['calories', 'sodium', 'alcohol', 'cost']
X = data[num_cols]X_scaled = StandardScaler().fit_transform(X)2. 训练模型
先用 k-距离图粗估 eps:
这段代码是用来画 k-distance 曲线,帮助给 DBSCAN 选择超参数 eps 的经典套路。
from sklearn.neighbors import NearestNeighbors
import matplotlib.pyplot as pltk = 4 # min_samples
nn = NearestNeighbors(n_neighbors=k).fit(X_scaled)
dist, idx = nn.kneighbors(X_scaled)
k_dist = np.sort(dist[:, -1])[::-1]plt.plot(k_dist)
plt.ylabel(f"{k}-distance")
plt.show()找“拐弯处”作为 eps 初值,再微调。
from sklearn.cluster import DBSCAN
db = DBSCAN(eps=1.5, min_samples=2).fit(X_scaled)
labels = db.labels_3. 评价指标
噪声点不计入:
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_scoremask = labels != -1
if len(set(labels[mask])) > 1:sil = silhouette_score(X_scaled[mask], labels[mask])ch = calinski_harabasz_score(X_scaled[mask], labels[mask])dbi = davies_bouldin_score(X_scaled[mask], labels[mask])print(f"Silhouette: {sil:.3f}, CH: {ch:.1f}, DBI: {dbi:.3f}")完整代码:
# -*- coding: utf-8 -*-
"""
DBSCAN 聚类完整示例
- 读取 data.txt
- 标准化
- k-distance 图选 eps
- DBSCAN 训练
- 计算 3 个聚类指标
- 结果写回 DataFrame
"""import pandas as pd
import numpy as np
import matplotlib.pyplot as pltfrom sklearn.preprocessing import StandardScaler
from sklearn.neighbors import NearestNeighbors
from sklearn.cluster import DBSCAN
from sklearn.metrics import (silhouette_score,calinski_harabasz_score,davies_bouldin_score,
)# 1. 读取数据 -------------------------------------------------------------
data = pd.read_table("data.txt", sep=' ')
num_cols = ['calories', 'sodium', 'alcohol', 'cost']
X = data[num_cols]# 2. 标准化 ---------------------------------------------------------------
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 3. k-距离图辅助选 eps ---------------------------------------------------
k = 5 # 与 min_samples 保持一致
nn = NearestNeighbors(n_neighbors=k).fit(X_scaled)
distances, _ = nn.kneighbors(X_scaled) # 修正:用 X_scaled
k_dist = np.sort(distances[:, -1])[::-1] # 第 k 近邻距离,降序plt.figure(figsize=(6, 3))
plt.plot(k_dist)
plt.title(f"{k}-distance graph")
plt.xlabel("Points sorted by distance")
plt.ylabel(f"{k}th nearest neighbor distance")
plt.tight_layout()
plt.show()# 4. 训练 DBSCAN ----------------------------------------------------------
# 根据拐点手动设定;这里演示用 1.5(标准化后的尺度)
eps = 1.5
min_samples = 5
db = DBSCAN(eps=eps, min_samples=min_samples)
labels = db.fit_predict(X_scaled)# 5. 评价指标(忽略噪声)--------------------------------------------------
mask = labels != -1
n_clusters = len(set(labels[mask]))
if n_clusters > 1:sil = silhouette_score(X_scaled[mask], labels[mask])ch = calinski_harabasz_score(X_scaled[mask], labels[mask])dbi = davies_bouldin_score(X_scaled[mask], labels[mask])print(f"簇数量: {n_clusters}")print(f"Silhouette: {sil:.3f}, CH: {ch:.1f}, DBI: {dbi:.3f}")
else:print("簇数量 ≤ 1,无法计算指标")# 6. 结果写回并查看 -------------------------------------------------------
data['clust_db'] = labels
print("\n前 10 行聚类结果:")
print(data.sort_values('clust_db').head(10))# 7. 统计每个簇的样本数 ---------------------------------------------------
print("\n簇样本分布:")
print(pd.value_counts(labels))