linux网络服务+linux数据库7
1.数据库
1.1 概念
一个完整的数据库系统(Database System,DBS)不止 “存储数据的集合”,还包括以下部分:
| 组成部分 | 作用 |
|---|---|
| 数据库(DB) | 核心,即结构化的数据集合(比如 “电商数据库” 包含用户表、商品表、订单表)。 |
| 数据库管理系统(DBMS) | 操作和管理数据库的软件(如 MySQL、Oracle、SQL Server),是用户与数据库的 “中间层”。 |
| 数据库用户 | 使用数据库的人或程序(比如开发人员、APP 后台程序)。 |
| 数据应用程序 | 基于数据库开发的软件(比如手机银行 APP、电商网站,通过程序间接操作数据库) |
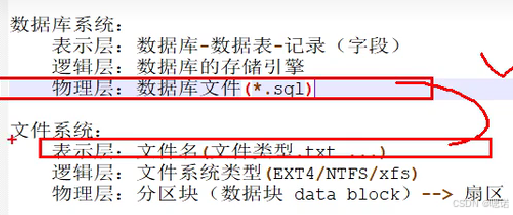
1.2 数据库和文件系统对比
一、核心定义与设计目标
| 维度 | 数据库(以关系型数据库为例) | 文件系统(如 Ext4、NTFS) |
|---|---|---|
| 核心定义 | 由数据库管理系统(DBMS,如 MySQL、Oracle)管控的结构化数据集合,通过预设规则组织数据(如表格、字段)。 | 操作系统用于存储和管理文件 / 目录的机制,将数据以 “文件” 为单位保存在磁盘,通过路径(如/home/user/data.txt)定位。 |
| 设计目标 | 解决 “大量数据的高效查询、多用户并发访问、数据一致性保护” 问题,主打 “数据管理能力”。 | 解决 “磁盘空间的基础分配、文件的创建 / 删除 / 读取” 问题,主打 “存储介质的基础管理”,不关注数据本身的业务逻辑。 |
二、关键特性对比
| 对比维度 | 数据库 | 文件系统 |
|---|---|---|
| 1. 数据结构 | 结构化存储:数据需遵循 “schema(模式)”,如关系型数据库的 “表 - 列” 结构(例:用户表含id(整数)、name(字符串)、age(整数)),非关系型数据库也有半结构化格式(如 MongoDB 的 JSON 文档)。 | 无结构化约束:数据以 “字节流” 形式存储,文件内容可任意格式(如 TXT 的纯文本、Excel 的表格、图片的二进制),文件系统不理解数据的业务含义(如无法识别 Excel 中 “姓名列” 和 “年龄列” 的区别)。 |
| 2. 数据查询能力 | 支持复杂查询:通过专用查询语言(如 SQL)实现 “多条件筛选、关联查询、聚合统计”。例:从 100 万条订单数据中,查询 “2024 年 1 月北京用户的订单金额总和”,可通过WHERE+GROUP BY+SUM()一键实现,毫秒级响应。 | 仅支持路径查询:只能通过 “文件路径 + 文件名” 定位文件,无法直接筛选文件内的数据。例:要从 100 个 Excel 文件中找 “北京用户的订单”,需逐个打开文件、手动筛选,效率极低。 |
| 3. 并发访问控制 | 原生支持多用户并发:通过 “锁机制”“事务隔离级别” 解决并发冲突,保证数据一致性。例:100 个用户同时下单时,数据库会避免 “同一商品库存被超卖”(如先锁定库存记录,修改后释放锁)。 | 基础并发支持:仅提供 “文件级锁”(如 Windows 的 “只读 / 独占打开”),无法处理文件内数据的并发修改。例:两个用户同时编辑同一个 Excel 文件,后保存的用户会覆盖前者的修改,导致数据丢失。 |
| 4. 数据一致性保障 | 事务机制(ACID):确保一组操作 “要么全部成功,要么全部失败”,避免中间状态。例:转账时 “扣减 A 账户余额” 和 “增加 B 账户余额” 是一个事务,若中间断电,两个操作都会回滚,不会出现 “A 扣钱但 B 没到账” 的情况。 | 无事务保障:操作是 “原子性” 的(如写文件要么成功要么失败),但无法关联多个文件 / 操作的一致性。例:用两个 TXT 文件分别存储 A、B 的余额,转账时先改 A 的文件、再改 B 的文件,若中间断电,会出现 “A 扣钱但 B 没到账” 的不一致。 |
| 5. 数据冗余控制 | 支持冗余规避:通过 “主键约束”“外键关联”“范式设计” 减少冗余。例:用户信息(姓名、手机号)只存一次,订单表通过 “用户 ID” 关联用户表,无需重复存储用户信息,避免 “同一用户信息在多个订单中不一致”。 | 冗余无法控制:数据冗余完全依赖人工管理,易出现 “同一数据多份存储且不一致”。例:多个 Excel 文件中都存了 “用户张三的手机号”,修改其中一个后,其他文件的手机号不会自动更新,导致数据冲突。 |
| 6. 安全性 | 精细化权限控制:支持 “库级、表级、字段级” 权限(如 “普通员工只能查看用户表的姓名 / 手机号,无法查看密码”),且支持数据加密(如 MySQL 的字段加密)、操作日志审计(记录谁修改了数据)。 | 基础权限控制:仅支持 “文件 / 目录级” 权限(如 Linux 的rwx权限:读、写、执行),无法控制文件内具体数据的访问(如无法让用户 “只能看 Excel 的 A 列,不能看 B 列”),且无操作审计能力。 |
| 7. 数据备份与恢复 | 专业备份机制:支持 “全量备份”“增量备份”“时间点恢复”(PITR),可恢复到任意历史时刻的数据。例:MySQL 通过mysqldump做全量备份,结合二进制日志实现 “恢复到昨天 14:30 的数据”。 | 基础备份:需手动复制文件(如复制D:\data目录到 U 盘),仅能恢复到 “备份时刻” 的状态,无法恢复中间的增量数据。例:若每天凌晨备份 Excel 文件,中午误删数据,只能恢复到凌晨的版本,丢失当天上午的数据。 |
| 8. 性能优化 | 多层优化能力:支持 “索引”(如 B + 树索引,加速查询)、“查询优化器”(自动优化 SQL 执行计划)、“缓存”(如 MySQL 的 InnoDB 缓存,减少磁盘 IO)。例:给用户表的phone字段加索引后,查询 “手机号 = 138XXXX1234” 的速度从秒级提升到毫秒级。 | 基础性能优化:仅依赖操作系统的 “文件缓存”(将常用文件加载到内存),无针对数据内容的优化。例:查询大 Excel 文件中的某一行数据,需从磁盘读取整个文件到内存,再逐行扫描,效率随文件大小线性下降。 |
| 9. 扩展性 | 支持横向 / 纵向扩展:纵向扩展(升级服务器 CPU / 内存 / 磁盘);横向扩展(如 MySQL 主从复制、分库分表,支持千万 / 亿级数据)。 | 扩展性有限:仅能通过 “扩大磁盘容量” 纵向扩展,无法应对 “海量文件” 场景(如存储 1000 万个小文件时,目录查询会变慢)。 |
| 10. 易用性 | 需学习成本:需掌握专用工具(如 MySQL 的 Navicat)和查询语言(如 SQL),适合有技术基础的用户。 | 零学习成本:通过操作系统的 “文件管理器”(如 Windows 资源管理器、Linux 的ls/cd)即可操作,适合普通用户。 |
三、适用场景对比(实例说明)
1. 优先用数据库的场景(需结构化管理、复杂查询、高一致性)
- 业务系统核心数据:电商平台的订单、用户、商品数据(需并发下单、关联查询 “用户 - 订单 - 商品”、保障库存不超卖);
- 金融数据:银行的账户、转账记录(需事务保障,避免 “单边账”);
- 企业管理系统:ERP 的采购、销售、库存数据(需多条件筛选、统计分析,如 “查询季度销售额 TOP10 的产品”)。
2. 优先用文件系统的场景(非结构化数据、简单存储、无需复杂查询)
- 非结构化文件存储:图片(如用户头像)、视频(如短视频)、文档(如 PDF 合同)(这些数据无法用表格结构化,且只需 “存储 - 读取”,无需复杂查询);
- 个人日常数据:普通用户的 Excel 报表、TXT 笔记(数据量小,仅个人使用,无需并发和一致性保障);
- 临时数据存储:程序运行产生的日志文件(如 Nginx 的访问日志,按文件按天存储,无需关联查询)。
四、总结
- 文件系统是 “存储文件的抽屉”:只负责把文件放进抽屉(目录),不管文件里写了什么,找文件只能按 “抽屉路径”;
- 数据库是 “管理数据的智能仓库”:不仅存储数据,还会给数据 “分类(表格)、贴标签(索引)、雇保安(权限)、做审计(日志)”,能快速找到 “符合特定条件的数据”,并保障多人间使用不冲突。
1.3 数据库分类
按 “数据存储结构” 可分为两大主流类型,适用场景差异极大:
1. 关系型数据库(RDBMS)—— 最常用的类型
- 特点:数据以 “表格(Table)” 形式存储,表格之间通过 “关联字段” 建立关系(比如 “订单表” 的 “用户 ID” 关联 “用户表” 的 “用户 ID”,可通过订单找到对应的用户)。
- 代表产品:MySQL(开源免费,广泛用于互联网公司,如抖音、淘宝)、Oracle(收费,用于金融、政府等核心系统)、SQL Server(微软产品,常用于 Windows 环境)。
- 适用场景:需要 “数据强一致性” 的场景(比如转账、订单支付、用户认证),因为支持事务、复杂查询和关联逻辑。
2. 非关系型数据库(NoSQL)—— 应对海量数据场景
- 特点:不依赖 “表格 + 关联” 结构,存储格式更灵活(如键值对、文档、列族、图结构),主打 “高并发、海量数据存储、易扩展”,但弱化了事务和关联能力。
- 代表产品:
- Redis(键值对存储,用于缓存,比如 APP 首页数据缓存,加快访问速度);
- MongoDB(文档存储,用于存储非结构化数据,比如朋友圈内容、商品详情页);
- HBase(列族存储,用于海量数据存储,比如日志、监控数据)。
- 适用场景:数据量大、查询简单、对一致性要求不高的场景(比如缓存、日志存储、社交 APP 的动态数据)。
1.4 关系型数据库概述
关系型数据库(Relational Database,简称 RDB)是基于关系模型(由数学家埃德加・科德于 1970 年提出)设计的数据库类型,核心是用 “表格(Table)” 组织数据,通过 “关联关系” 建立不同表格间的联系,并用结构化查询语言(SQL)实现数据操作。它是目前全球最主流的数据库类型,广泛应用于金融、电商、政务等对数据一致性要求高的场景(如银行转账、电商订单、用户认证系统)。
一、核心基础:关系模型的三大要素
关系型数据库的 “关系” 并非简单的 “数据关联”,而是严格遵循关系模型的三大核心要素,这也是它区别于非关系型数据库的本质:
1. 数据结构:以 “表格(Table)” 为载体
所有数据都存储在二维表格中,表格结构需提前定义(即 “Schema 模式”),每个表格包含:
- 行(Row):也称 “记录(Record)”,代表一条具体的数据(如 “用户表” 中的一行对应一个用户);
- 列(Column):也称 “字段(Field)”,代表数据的属性(如 “用户表” 的 “id”“姓名”“手机号” 列),每个列需指定数据类型(如整数、字符串、日期),确保数据格式统一;
- 表头(Header):列的名称,用于标识每列的含义(如 “id” 列代表用户唯一标识)。
示例:用户表(user)的结构与数据
| id(整数,主键) | name(字符串) | phone(字符串,唯一) | create_time(日期) |
|---|---|---|---|
| 1 | 张三 | 138XXXX1234 | 2024-01-01 |
| 2 | 李四 | 139XXXX5678 | 2024-01-02 |
2. 关系规则:通过 “键(Key)” 建立表间关联
不同表格间通过 “键” 实现逻辑关联,避免数据冗余,核心是主键(Primary Key) 和外键(Foreign Key):
- 主键(PK):表格中唯一标识一条记录的列(或列组合),不可重复、不可为空(如 “用户表” 的
id列,每个用户的id唯一); - 外键(FK):表格中引用其他表格主键的列,用于建立表间关联(如 “订单表” 的
user_id列,引用 “用户表” 的id列,通过user_id可找到该订单对应的用户)。
示例:订单表(order)与用户表的关联
| order_id(PK) | user_id(FK,关联 user.id) | goods_name | price |
|---|---|---|---|
| 1001 | 1 | 手机 | 5999 |
| 1002 | 2 | 电脑 | 7999 |
通过order.user_id = user.id,可快速查询 “张三(id=1)的所有订单”,无需在订单表中重复存储张三的姓名、手机号等信息。 |
3. 约束规则:保证数据完整性
通过预设约束确保数据的准确性和一致性,常见约束包括:
- 主键约束:确保主键唯一且非空;
- 唯一约束(Unique):确保列值不重复(如 “用户表” 的
phone列,避免同一手机号注册多个账户); - 非空约束(Not Null):确保列值不能为空(如 “用户表” 的
name列,不允许创建 “无姓名” 的用户); - 外键约束:确保外键值必须在引用的主键列中存在(如 “订单表” 的
user_id不能为 “3”,因为 “用户表” 中没有id=3的用户); - 检查约束(Check):限制列值的范围(如 “订单表” 的
price列需满足price > 0,避免出现 “负价格” 订单)。
二、关系型数据库的核心优势
数据一致性强支持事务(Transaction),遵循 ACID 原则,确保一组操作 “要么全部成功,要么全部失败”,是金融、支付等核心场景的刚需:
- 原子性(Atomicity):事务中的操作不可分割(如转账时 “扣钱” 和 “到账” 必须同时完成);
- 一致性(Consistency):事务执行前后数据符合业务规则(如转账前后,A、B 账户总余额不变);
- 隔离性(Isolation):多个事务并发执行时,互不干扰(如 A、B 同时给 C 转账,不会出现 “金额计算错误”);
- 持久性(Durability):事务成功后,数据修改永久生效(如转账成功后,即使服务器断电,数据也不会丢失)。
结构化查询能力强支持SQL(结构化查询语言),可实现复杂的数据分析和多表关联查询,例如:
- 多表关联:查询 “2024 年 1 月北京用户的订单,包含用户名、商品名、订单金额”;
- 聚合统计:计算 “2024 年第一季度各商品的销售额 TOP10”;
- 条件筛选:查询 “注册时间在 2024 年,且手机号以 138 开头的用户”。
数据冗余低通过 “主键 - 外键” 关联和 “范式设计”(如第三范式),避免数据重复存储。例如:用户信息只在 “用户表” 存一次,“订单表”“收货地址表” 仅通过
user_id引用,无需重复存储用户姓名、手机号,减少数据冲突(如修改用户手机号时,只需改 “用户表”,其他表自动关联最新值)。工具链成熟拥有完善的管理工具(如 MySQL 的 Navicat、Oracle 的 SQL Developer)、备份恢复工具(如 MySQL 的
mysqldump、PostgreSQL 的pg_dump)和监控工具(如 Prometheus+Grafana 监控数据库性能),降低运维成本。
三、主流关系型数据库产品
不同产品的定位和适用场景差异较大,选择时需结合业务规模、成本、技术栈:
| 产品名称 | 特点 | 适用场景 |
|---|---|---|
| MySQL | 开源免费,轻量级,性能优秀,社区活跃,支持主从复制、分库分表 | 互联网公司(如电商、社交 APP)、中小型企业系统,是目前使用最广泛的关系型数据库 |
| Oracle | 商业收费,功能强大(支持分布式、高并发、海量数据),稳定性极强 | 金融、政府、大型企业核心系统(如银行的核心交易系统、电信的计费系统) |
| SQL Server | 微软产品,与 Windows 系统、.NET 技术栈兼容性好,易用性高 | 基于 Windows 环境的企业系统(如企业 ERP、内部管理系统) |
| PostgreSQL | 开源,支持复杂数据类型(如 JSON、数组、地理信息),扩展性强,兼容 SQL 标准 | 对数据类型有特殊需求的场景(如地理信息系统、数据分析平台) |
| SQLite | 嵌入式数据库(无服务器,数据存储在单个文件中),轻量级,无需安装配置 | 移动 APP(如 Android/iOS 本地数据存储)、小型工具(如桌面软件的配置存储) |
四、关系型数据库的局限性
扩展性较弱纵向扩展(升级 CPU、内存、磁盘)有上限,横向扩展(多服务器集群)复杂度高(如 MySQL 分库分表需解决 “数据分片”“分布式事务” 等问题),难以应对 “亿级数据、千万级并发” 的超大规模场景(如抖音的用户行为日志、淘宝双 11 的实时订单峰值)。
灵活性不足数据结构(Schema)需提前定义,修改成本高(如给 “用户表” 新增 “性别” 列,需执行
ALTER TABLE语句,若表中已有千万级数据,可能导致锁表,影响业务),不适合 “数据结构频繁变化” 的场景(如社交 APP 的动态内容,字段可能随功能迭代新增)。读写性能瓶颈虽然支持索引优化,但在 “高并发读写” 场景下(如秒杀活动,每秒上万次订单提交),单库单表的性能易达到瓶颈,需通过主从复制(主库写、从库读)、分库分表等方案缓解,增加了架构复杂度。
五、适用场景总结
关系型数据库是 “刚需强一致性、结构化数据、复杂查询” 场景的首选,典型场景包括:
- 金融支付:银行账户、转账记录、订单支付;
- 电商核心:用户信息、商品库存、订单管理;
- 企业管理:ERP 系统、CRM 客户管理、OA 办公系统;
- 政务系统:社保数据、户籍信息、政务审批记录。
若场景满足 “数据结构灵活、并发量极高、一致性要求低”(如缓存、日志存储、社交动态),则更适合非关系型数据库(NoSQL),二者并非对立关系,实际架构中常结合使用(如电商平台:MySQL 存订单 / 用户,Redis 存缓存,MongoDB 存商品详情)。
1.5 mysql组成结构介绍
MySQL 是一款开源的关系型数据库管理系统(RDBMS),其组成结构可分为核心组件和辅助工具两部分,各组件协同工作,实现数据的存储、管理、查询和安全控制。以下是 MySQL 的详细组成结构解析:
一、核心组件(MySQL Server 核心)
这些组件是 MySQL 服务运行的基础,负责处理客户端请求、数据存储、查询执行等核心功能。
1. 连接管理器(Connection Manager)
- 作用:负责接收客户端(如 Java 程序、Navicat 工具)的连接请求,管理连接池,验证用户身份(账号密码、权限)。
- 细节:
- 客户端通过 TCP/IP(默认端口 3306)、命名管道等方式连接 MySQL;
- 连接建立后,分配一个线程(或线程池中的线程)处理该客户端的后续请求;
- 验证失败(如密码错误、无权限)时,直接拒绝连接。
2. SQL 接口(SQL Interface)
- 作用:接收客户端发送的 SQL 语句(如
SELECT、INSERT、UPDATE),并返回执行结果。 - 支持的 SQL 操作:
- 数据查询(
SELECT); - 数据操纵(
INSERT/UPDATE/DELETE); - 数据定义(
CREATE TABLE/ALTER TABLE); - 数据控制(
GRANT/REVOKE权限)。
- 数据查询(
3. 解析器(Parser)
- 作用:对 SQL 语句进行语法分析和语义检查,生成 “解析树”(Parse Tree)。
- 工作流程:
- 语法检查:验证 SQL 语句是否符合语法规则(如
SELECT关键字是否正确、括号是否匹配); - 语义检查:验证 SQL 中涉及的表、字段是否存在(如查询
user表的name列,需确认user表和name列真实存在); - 生成解析树:将合法的 SQL 语句转换为 MySQL 可理解的内部结构(类似 “抽象语法树”)。
- 语法检查:验证 SQL 语句是否符合语法规则(如
4. 查询优化器(Optimizer)
- 作用:对解析树进行优化,生成 “最优执行计划”(Execution Plan),确保查询高效执行。
- 优化方式:
- 选择最优索引(如从多个可用索引中选一个查询效率最高的);
- 调整表连接顺序(多表关联查询时,按 “小表驱动大表” 原则优化);
- 简化表达式(如
WHERE a + 1 = 5优化为WHERE a = 4); - 消除冗余条件(如
WHERE id > 10 AND id > 5优化为WHERE id > 10)。
5. 存储引擎接口(Storage Engine API)
- 作用:MySQL 的 “插件式存储引擎” 架构的核心,定义了数据存储和检索的标准接口,使不同存储引擎可无缝接入。
- 特点:
- 客户端可针对不同表选择不同存储引擎(如
user表用 InnoDB,logs表用 MyISAM); - 存储引擎接口屏蔽了底层数据存储的差异,上层组件(如 SQL 接口)无需关心数据如何存储。
- 客户端可针对不同表选择不同存储引擎(如
6. 存储引擎(Storage Engines)
- 作用:负责数据的实际存储、读取、索引管理和事务处理,是 MySQL 数据持久化的核心。
- 主流存储引擎及特点:
存储引擎 特点 适用场景 InnoDB(默认) 支持事务(ACID)、行级锁、外键约束,崩溃恢复能力强,适合高并发读写 核心业务表(如订单表、用户表) MyISAM 不支持事务和行级锁,支持表级锁,查询速度快,占用空间小 只读或写少读多的表(如日志表、静态数据报表) Memory 数据存储在内存中,速度极快,但重启后数据丢失 临时数据缓存(如会话数据、临时计算结果) Archive 高压缩比,适合存储大量历史归档数据,仅支持插入和查询 日志归档、历史数据存储
7. 物理文件(Physical Files)
- 作用:存储实际数据的磁盘文件,由存储引擎管理,不同存储引擎的文件格式不同。
- InnoDB 主要文件:
.ibd:表数据和索引文件(每个表一个,启用innodb_file_per_table时);ibdata1:系统表空间文件,存储共享数据字典、未开启独立表空间的表数据;ib_logfile0/ib_logfile1: redo 日志文件,用于事务崩溃恢复;
- MyISAM 主要文件:
.MYD:表数据文件;.MYI:索引文件;.frm:表结构定义文件(所有存储引擎通用)。
二、辅助工具(命令行与图形化工具)
这些工具用于数据库的日常管理、备份、恢复等操作。
1. 命令行工具
- mysql:交互式客户端,用于执行 SQL 语句(如
mysql -u root -p登录后执行SELECT * FROM user;); - mysqldump:逻辑备份工具,生成 SQL 格式的备份文件(如
mysqldump -u root -p dbname > backup.sql); - mysqladmin:管理工具,用于启停服务、查看状态(如
mysqladmin -u root -p status查看服务状态); - mysqlimport:数据导入工具,批量导入文本文件数据(如
mysqlimport -u root -p dbname data.txt); - mysqld:MySQL 服务进程(守护进程),启动数据库的核心命令(如
systemctl start mysqld)。
2. 图形化工具(第三方或官方)
- MySQL Workbench:官方图形化工具,支持数据库设计、SQL 编写、性能分析;
- Navicat for MySQL:主流第三方工具,可视化管理数据库,支持备份、数据同步;
- DBeaver:开源跨平台工具,支持多种数据库(包括 MySQL),适合开发和运维。
三、日志系统(监控与恢复)
MySQL 的日志用于记录数据库的运行状态、错误信息和用户操作,是问题排查和数据恢复的关键。
- 错误日志(Error Log):记录 MySQL 启动、关闭、运行中的错误信息(如启动失败原因);
- 查询日志(General Log):记录所有客户端执行的 SQL 语句(默认关闭,开启会影响性能);
- 慢查询日志(Slow Query Log):记录执行时间超过阈值(如 2 秒)的 SQL 语句,用于优化慢查询;
- 二进制日志(Binary Log):记录数据修改操作(
INSERT/UPDATE/DELETE),用于主从复制和时间点恢复; - 中继日志(Relay Log):从库接收的主库二进制日志副本,用于主从同步;
- redo 日志(Redo Log):InnoDB 引擎特有,记录事务的修改操作,确保事务持久性(崩溃后可恢复);
- undo 日志(Undo Log):InnoDB 引擎特有,记录事务修改前的数据,用于事务回滚(
ROLLBACK)。
四、核心架构总结
MySQL 的架构体现了 “分层设计” 和 “插件化” 的特点:
- 连接层:连接管理、身份验证;
- SQL 层:解析 SQL、优化查询、生成执行计划;
- 存储引擎层:通过统一接口调用不同存储引擎,实现数据的物理存储;
- 文件层:存储实际数据和日志文件。
1.6 mysql常用命令
MySQL 的常用命令可分为连接管理、数据库操作、表操作、数据操作、权限管理等类别,以下是高频使用的核心命令及示例:
一、连接与退出 MySQL
# 本地连接(默认端口 3306)
mysql -u 用户名 -p
# 示例:用 root 用户登录,回车后输入密码
mysql -u root -p# 远程连接(指定 IP 和端口)
mysql -h 服务器IP -P 端口 -u 用户名 -p
# 示例:连接 192.168.1.100 的 3306 端口
mysql -h 192.168.1.100 -P 3306 -u root -p# 退出 MySQL
exit; 或 quit;
二、数据库操作
1. 查看所有数据库
show databases;
2. 创建数据库
create database 数据库名 [charset 字符集];
# 示例:创建 testdb 数据库,指定 UTF-8 字符集
create database testdb charset utf8mb4;
3. 切换数据库(进入数据库)
use 数据库名;
# 示例:进入 testdb 数据库
use testdb;
4. 删除数据库(谨慎使用!)
drop database 数据库名;
# 示例:删除 testdb 数据库
drop database testdb;
5. 查看当前数据库
select database();
三、数据表操作
(需先执行 use 数据库名; 进入目标数据库)
1. 查看当前数据库的所有表
show tables;
2. 创建表
create table 表名 (字段1 数据类型 [约束],字段2 数据类型 [约束],...[主键/外键约束]
);# 示例:创建 user 表(id 为主键,自增;name 非空)
create table user (id int auto_increment,name varchar(50) not null,age int,phone varchar(20) unique,primary key (id)
);
- 常用数据类型:
int(整数)、varchar(长度)(字符串)、datetime(日期时间)、decimal(10,2)(小数)。 - 常用约束:
not null(非空)、unique(唯一)、auto_increment(自增)、primary key(主键)。
3. 查看表结构
desc 表名; 或 describe 表名;
# 示例:查看 user 表结构
desc user;
4. 修改表(添加 / 修改 / 删除字段)
# 添加字段
alter table 表名 add 字段名 数据类型 [约束];
# 示例:给 user 表添加 email 字段
alter table user add email varchar(100) unique;# 修改字段(类型/约束)
alter table 表名 modify 字段名 新数据类型 [新约束];
# 示例:修改 age 字段为非空
alter table user modify age int not null;# 删除字段
alter table 表名 drop 字段名;
# 示例:删除 phone 字段
alter table user drop phone;
5. 删除表(谨慎使用!)
drop table 表名;
# 示例:删除 user 表
drop table user;
四、数据操作(CRUD)
1. 插入数据(Create)
insert into 表名 (字段1, 字段2, ...) values (值1, 值2, ...);# 示例1:指定字段插入
insert into user (name, age, email) values ('张三', 20, 'zhangsan@test.com');# 示例2:不指定字段(需按表结构顺序插入所有字段,自增主键可省略)
insert into user values (null, '李四', 22, 'lisi@test.com');
2. 查询数据(Read)
select 字段1, 字段2 from 表名 [where 条件] [order by 字段] [limit 数量];# 示例1:查询所有字段和数据
select * from user;# 示例2:查询指定字段(name、age),条件:age > 18
select name, age from user where age > 18;# 示例3:按 age 降序排序,取前2条
select * from user order by age desc limit 2;# 示例4:模糊查询(name 含“张”)
select * from user where name like '%张%';
3. 更新数据(Update)
sql
update 表名 set 字段1=值1, 字段2=值2 where 条件;# 示例:将 id=1 的用户年龄改为 21
update user set age=21 where id=1;# 警告:若省略 where 条件,将更新表中所有数据!
4. 删除数据(Delete)
delete from 表名 where 条件;# 示例:删除 id=2 的用户
delete from user where id=2;# 警告:若省略 where 条件,将删除表中所有数据(表结构保留)!
五、索引操作
# 创建索引(普通索引)
create index 索引名 on 表名(字段);
# 示例:给 user 表的 email 字段创建索引
create index idx_email on user(email);# 创建唯一索引(字段值必须唯一)
create unique index 索引名 on 表名(字段);# 查看表的索引
show index from 表名;# 删除索引
drop index 索引名 on 表名;
六、权限管理
# 创建用户(允许从本地登录)
create user '用户名'@'localhost' identified by '密码';
# 示例:创建 user1,密码 123456
create user 'user1'@'localhost' identified by '123456';# 授权(所有权限)
grant all privileges on 数据库名.表名 to '用户名'@'登录主机';
# 示例:授权 user1 操作 testdb 所有表的权限
grant all privileges on testdb.* to 'user1'@'localhost';# 刷新权限
flush privileges;# 查看用户权限
show grants for '用户名'@'登录主机';# 撤销权限
revoke all privileges on 数据库名.表名 from '用户名'@'登录主机';# 删除用户
drop user '用户名'@'登录主机';
七、其他常用命令
# 查看 MySQL 版本
select version();# 查看当前用户
select user();# 查看表的创建语句(含索引、约束等)
show create table 表名;# 清空表数据(保留表结构,速度比 delete 快)
truncate table 表名;
说明
- 所有 SQL 命令需以分号
;结尾; - 关键字(如
select、create)不区分大小写,但建议大写以提高可读性; - 操作前建议备份数据,尤其是
drop、delete、truncate等危险命令。
1.7mysql 备份管理
MySQL 备份管理是保障数据安全的核心环节,通过合理的备份策略可有效应对数据误删、硬件故障、黑客攻击等风险。以下是 MySQL 备份的核心方法、操作步骤及最佳实践:
一、备份类型与适用场景
MySQL 备份按 “数据获取方式” 和 “恢复能力” 可分为以下几类,需根据业务需求选择:
| 备份类型 | 原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 逻辑备份 | 通过 SQL 语句导出数据(如 mysqldump),生成文本文件 | 跨平台、可编辑、体积小(压缩后) | 备份 / 恢复速度慢(尤其大数据量) | 中小数据量、需跨版本 / 跨平台恢复 |
| 物理备份 | 直接复制数据库物理文件(如 .ibd、ibdata1) | 备份 / 恢复速度快,适合海量数据 | 不可编辑、跨平台性差(依赖文件系统) | 大数据量、同版本 / 同环境恢复 |
| 二进制日志备份 | 备份 binlog 日志(记录所有数据修改操作) | 支持 “时间点恢复”(PITR),体积小 | 需配合全量备份使用,单独无法恢复 | 全量备份 + 增量恢复(精确到秒级) |
二、逻辑备份:mysqldump 工具(最常用)
mysqldump 是 MySQL 官方提供的逻辑备份工具,通过导出 SQL 语句实现备份,支持全库、单库、单表备份,以及排除指定表。
1. 全库备份(含所有数据库)
# 备份所有数据库(包括系统库),并压缩
mysqldump -u root -p --all-databases | gzip > /backup/all_db_$(date +%Y%m%d).sql.gz
--all-databases:备份所有数据库;gzip:压缩备份文件(减少存储空间);$(date +%Y%m%d):生成带日期的文件名(如all_db_20241006.sql.gz)。
2. 单库备份(指定数据库)
# 备份 testdb 数据库
mysqldump -u root -p --databases testdb | gzip > /backup/testdb_$(date +%Y%m%d).sql.gz
--databases testdb:仅备份testdb数据库(包含建库语句)。
3. 单表备份(指定表)
# 备份 testdb 数据库中的 user 表
mysqldump -u root -p testdb user | gzip > /backup/testdb_user_$(date +%Y%m%d).sql.gz
- 格式:
mysqldump -u 用户名 -p 数据库名 表名 > 备份文件。
4. 恢复逻辑备份
# 恢复全库备份(先解压,再导入)
gunzip < /backup/all_db_20241006.sql.gz | mysql -u root -p# 恢复单库备份(需先创建数据库,或备份文件含建库语句)
gunzip < /backup/testdb_20241006.sql.gz | mysql -u root -p testdb# 恢复单表备份(需确保表结构存在)
gunzip < /backup/testdb_user_20241006.sql.gz | mysql -u root -p testdb
5. 高级选项(提升备份安全性 / 效率)
- 添加锁表选项(确保备份期间数据一致性,InnoDB 可省略):
mysqldump -u root -p --databases testdb --lock-tables | gzip > /backup/testdb_lock_20241006.sql.gz - 排除指定表(如备份
testdb但排除logs表):mysqldump -u root -p testdb --ignore-table=testdb.logs | gzip > /backup/testdb_no_logs.sql.gz - 仅备份表结构(不含数据):
mysqldump -u root -p testdb --no-data > /backup/testdb_struct.sql
三、物理备份:xtrabackup 工具(海量数据首选)
xtrabackup 是 Percona 公司开发的开源物理备份工具,支持 InnoDB 引擎的热备份(备份时不锁表),速度远快于 mysqldump,适合 TB 级数据。
1. 安装 xtrabackup
# CentOS 安装(需添加 Percona 源)
yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm
yum install percona-xtrabackup-80 # 对应 MySQL 8.0
2. 全量物理备份
# 备份所有数据到 /backup/xtra_full_20241006 目录
xtrabackup --user=root --password=123456 --backup --target-dir=/backup/xtra_full_20241006
--backup:开启备份模式;--target-dir:指定备份文件存储目录。
3. 恢复物理备份
# 1. 准备备份(合并日志,确保数据一致性)
xtrabackup --user=root --password=123456 --prepare --target-dir=/backup/xtra_full_20241006# 2. 停止 MySQL 服务
systemctl stop mysqld# 3. 清空原数据目录(默认 /var/lib/mysql)
rm -rf /var/lib/mysql/*# 4. 恢复备份到数据目录
xtrabackup --user=root --password=123456 --copy-back --target-dir=/backup/xtra_full_20241006# 5. 修复目录权限(MySQL 运行用户为 mysql)
chown -R mysql:mysql /var/lib/mysql# 6. 启动 MySQL
systemctl start mysqld
四、二进制日志(binlog)备份与时间点恢复
binlog 记录了所有数据修改操作(INSERT/UPDATE/DELETE),结合全量备份可实现 “精确到秒” 的恢复。
1. 开启 binlog(需在 my.cnf 中配置)
[mysqld]
server-id=1 # 唯一标识(主从复制必需)
log_bin=/var/log/mysql/binlog # binlog 存储路径
expire_logs_days=7 # 日志保留7天(自动清理)
重启 MySQL 生效:systemctl restart mysqld
2. 备份 binlog
# 手动复制 binlog 文件(或配置定时任务)
cp /var/log/mysql/binlog.000001 /backup/binlog/
3. 时间点恢复(PITR)示例
假设场景:
- 全量备份时间:2024-10-06 00:00(
full_backup.sql); - 误删数据时间:2024-10-06 10:00;
- 需恢复到 2024-10-06 09:59(误删前)。
操作步骤:
# 1. 先恢复全量备份
mysql -u root -p < /backup/full_backup.sql# 2. 查看 binlog 日志列表,找到包含误删操作的日志
mysqlbinlog --base64-output=decode-rows -v /var/log/mysql/binlog.000001 | grep -i "delete"# 3. 提取全量备份后到误删前的 binlog 事件(假设从位置 100 到 2000)
mysqlbinlog --start-position=100 --stop-position=2000 /var/log/mysql/binlog.000001 | mysql -u root -p
--start-position/--stop-position:按日志位置截取;- 也可按时间截取:
--start-datetime="2024-10-06 00:00:00" --stop-datetime="2024-10-06 09:59:00"。
五、备份策略与最佳实践
混合备份策略
- 每周一次全量物理备份(
xtrabackup); - 每日一次增量逻辑备份(
mysqldump单库); - 实时备份
binlog(配合定时任务复制)。
- 每周一次全量物理备份(
备份存储与验证
- 备份文件需异地存储(如云存储、另一台服务器),避免本地故障;
- 定期验证备份有效性(如每月恢复一次到测试环境)。
自动化备份编写脚本并通过
crontab定时执行(示例):# 脚本:/backup/mysql_backup.sh #!/bin/bash BACKUP_DIR=/backup DATE=$(date +%Y%m%d) # 备份 testdb 并压缩 mysqldump -u root -p123456 testdb | gzip > $BACKUP_DIR/testdb_$DATE.sql.gz # 保留30天备份 find $BACKUP_DIR -name "testdb_*.sql.gz" -mtime +30 -delete# 添加执行权限 chmod +x /backup/mysql_backup.sh# 定时任务(每天凌晨2点执行) crontab -e 0 2 * * * /backup/mysql_backup.sh注意事项
- 避免在业务高峰期备份(影响性能);
- 敏感数据备份需加密(如
mysqldump ... | gpg -c > backup.sql.gz.gpg); - 记录备份日志,便于排查问题(如
>> /backup/backup.log 2>&1)。
六、总结
MySQL 备份管理的核心是 “全量备份 + 增量备份 + 时间点恢复” 的组合策略:
- 小数据量用
mysqldump逻辑备份,灵活且跨平台; - 大数据量用
xtrabackup物理备份,高效且适合热备份; - 配合
binlog实现时间点恢复,应对误操作等场景。通过自动化脚本和定期验证,可最大化保障数据安全性和可恢复性。
2.Mysql集群
2.1主从备份
MySQL 主从备份(主从复制)是通过异步复制机制实现的数据备份与读写分离方案,主库(Master)处理写操作并记录二进制日志(binlog),从库(Slave)实时同步主库日志并应用到本地,从而保持数据一致。以下是主从备份的详细配置步骤、验证方法及运维要点:
一、主从备份核心原理
主库(Master):
- 开启二进制日志(binlog),记录所有数据修改操作(
INSERT/UPDATE/DELETE); - 当从库连接时,主库创建二进制日志 dump 线程,发送 binlog 给从库。
- 开启二进制日志(binlog),记录所有数据修改操作(
从库(Slave):
- 启动 I/O 线程:连接主库,接收 binlog 并写入本地中继日志(relay log);
- 启动 SQL 线程:读取中继日志,执行日志中的 SQL 语句,同步数据到从库。
核心优势:
- 数据备份:从库作为主库的实时副本,主库故障时可切换到从库;
- 读写分离:主库负责写操作,从库负责读操作,提升系统性能。
二、环境准备
| 角色 | IP 地址 | 数据库版本 | 操作系统 |
|---|---|---|---|
| 主库 | 192.168.88.10 | MySQL 8.0 | CentOS 7 |
| 从库 | 192.168.88.20 | MySQL 8.0 | CentOS 7 |
前置条件:
- 主从库 MySQL 版本一致(避免兼容性问题);
- 主从库网络互通(关闭防火墙或开放 3306 端口);
- 主库已开启 binlog(配置见下文)。
三、主库(Master)配置步骤
步骤 1:修改 MySQL 配置文件(my.cnf 或 mysqld.cnf)
vim /etc/my.cnf
添加以下配置:
[mysqld]
server-id = 1 # 主库唯一标识(非0整数,与从库不同)
log_bin = /var/log/mysql/mysql-bin # 开启binlog,指定存储路径
binlog_do_db = testdb # 仅记录testdb库的binlog(可选,不配置则记录所有库)
binlog_ignore_db = mysql # 忽略mysql系统库的binlog(可选)
expire_logs_days = 7 # binlog自动保留7天(避免磁盘占满)
步骤 2:重启 MySQL 服务
systemctl restart mysqld
步骤 3:创建主从同步专用用户
登录主库 MySQL,创建允许从库连接的用户(如 repl):
mysql -u root -p-- 创建用户(允许从库192.168.88.20连接)
CREATE USER 'repl'@'192.168.88.20' IDENTIFIED BY '123456';-- 授予复制权限
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'192.168.88.20';-- 刷新权限
FLUSH PRIVILEGES;
步骤 4:查看主库 binlog 状态
-- 锁表(防止备份时数据变化,InnoDB可省略)
FLUSH TABLES WITH READ LOCK;-- 查看主库状态(记录File和Position,从库配置需要)
SHOW MASTER STATUS;
输出示例:
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 154 | testdb | mysql | |
+------------------+----------+--------------+------------------+-------------------+
- 记录关键信息:
File=mysql-bin.000001,Position=154。
步骤 5:解锁表(完成备份后)
UNLOCK TABLES;
四、从库(Slave)配置步骤
步骤 1:修改 MySQL 配置文件
vim /etc/my.cnf
添加以下配置:
[mysqld]
server-id = 2 # 从库唯一标识(与主库不同)
relay_log = /var/log/mysql/mysql-relay-bin # 中继日志路径
log_slave_updates = 1 # 允许从库将同步的数据写入自己的binlog(级联复制用)
read_only = 1 # 从库设为只读(仅影响普通用户,root不受限)
步骤 2:重启 MySQL 服务
systemctl restart mysqld
步骤 3:从库连接主库并开启同步
登录从库 MySQL,配置主库信息:
mysql -u root -p-- 配置主库连接参数(替换为实际值)
CHANGE MASTER TO
MASTER_HOST='192.168.88.10', # 主库IP
MASTER_USER='repl', # 同步用户
MASTER_PASSWORD='123456', # 同步密码
MASTER_LOG_FILE='mysql-bin.000001', # 主库binlog文件名(步骤4记录)
MASTER_LOG_POS=154; # 主库binlog位置(步骤4记录)-- 启动从库同步进程
START SLAVE;
步骤 4:查看从库同步状态
SHOW SLAVE STATUS\G;
关键参数验证(需均为 Yes):
Slave_IO_Running: Yes # I/O线程运行正常(接收binlog)
Slave_SQL_Running: Yes # SQL线程运行正常(执行中继日志)
五、主从同步验证
验证 1:数据同步测试
主库创建测试库和表:
CREATE DATABASE testdb; USE testdb; CREATE TABLE user (id INT, name VARCHAR(50)); INSERT INTO user VALUES (1, '张三');从库查看数据:
USE testdb; SELECT * FROM user;输出应与主库一致:
1 张三,说明同步成功。
验证 2:增量同步测试
主库修改数据:
UPDATE user SET name='李四' WHERE id=1;从库查看更新结果:
SELECT * FROM user;输出应为
1 李四,验证增量同步有效。
验证 3:故障场景验证(可选)
主库删除数据:
DELETE FROM user WHERE id=1;从库查看结果:
SELECT * FROM user;表应为空,验证删除操作同步正常。
六、主从同步常见问题与解决
Slave_IO_Running: Connecting故障- 原因:网络不通、主库 IP / 端口错误、同步用户密码错误、主库防火墙拦截。
- 解决:
- 测试网络:
ping 192.168.88.10; - 验证用户权限:在从库执行
mysql -urepl -p123456 -h192.168.88.10,能否登录主库; - 开放防火墙:主库执行
firewall-cmd --add-port=3306/tcp --permanent && firewall-cmd --reload。
- 测试网络:
Slave_SQL_Running: No故障- 原因:从库执行中继日志时发生错误(如主从表结构不一致、主键冲突)。
- 解决:
- 查看错误日志:
cat /var/log/mysqld.log,定位具体错误; - 跳过错误(临时方案):
sql
STOP SLAVE; SET GLOBAL sql_slave_skip_counter = 1; # 跳过一个错误 START SLAVE; - 根本解决:修复主从数据 / 表结构一致性(如重新备份主库数据到从库)。
- 查看错误日志:
七、主从备份运维最佳实践
定期验证同步状态编写脚本监控
Slave_IO_Running和Slave_SQL_Running状态,异常时告警(如邮件、短信)。主从数据一致性检查使用
pt-table-checksum工具(Percona Toolkit)定期检查主从数据是否一致:# 安装 Percona Toolkit yum install percona-toolkit # 检查 testdb 库一致性 pt-table-checksum --user=root --password=123456 h=192.168.88.10,D=testdb主库 binlog 管理
- 配置
expire_logs_days自动清理旧日志,避免磁盘占满; - 定期备份 binlog(配合主库全量备份,实现时间点恢复)。
- 配置
读写分离配置
- 应用程序写操作连接主库(192.168.88.10),读操作连接从库(192.168.88.20);
- 复杂场景可使用中间件(如 MyCat、ProxySQL)自动路由读写请求。
主从切换演练定期模拟主库故障,手动将从库提升为主库,确保故障时可快速切换:
-- 从库停止同步 STOP SLAVE; -- 从库重置为主库(可选) RESET MASTER;
2.2 主主与一主多从备份
MySQL 集群的 “主主备份” 和 “一主多从备份” 是两种常见的高可用架构,分别适用于不同的业务场景。前者侧重双向互备和负载均衡,后者侧重数据分发和读写分离,以下是两种架构的详细实现、对比及适用场景:
一、主主备份(双主互备)
主主备份(Master-Master)是指两台服务器互为主从,彼此同步对方的数据:Server A 是 Server B 的主库,同时 Server B 也是 Server A 的主库。任何一台服务器的写入操作都会同步到另一台,实现双向备份和负载均衡。
1. 核心原理
- 两台服务器均开启 binlog 和 relay log;
- 每台服务器既是主库(接收对方的同步请求),也是从库(同步对方的 binlog);
- 通过 “自增主键偏移” 避免双写冲突(如 A 服务器自增 ID 为奇数,B 服务器为偶数)。
2. 配置步骤(基于前文主从备份基础)
假设服务器:A(192.168.88.10)、B(192.168.88.20)
步骤 1:修改两台服务器的 my.cnf 配置
Server A 配置:
[mysqld]
server-id = 1
log_bin = /var/log/mysql/mysql-bin
relay_log = /var/log/mysql/mysql-relay-bin
auto_increment_increment = 2 # 自增步长为2(每隔1个增长)
auto_increment_offset = 1 # 自增起始值为1(生成1,3,5...)
log_slave_updates = 1 # 允许从库同步的数据写入自身binlog
Server B 配置:
[mysqld]
server-id = 2
log_bin = /var/log/mysql/mysql-bin
relay_log = /var/log/mysql/mysql-relay-bin
auto_increment_increment = 2 # 自增步长为2
auto_increment_offset = 2 # 自增起始值为2(生成2,4,6...)
log_slave_updates = 1
重启两台 MySQL 服务:systemctl restart mysqld
步骤 2:互为从库配置
在 Server A 上配置同步 Server B:
-- 先在 Server B 执行 SHOW MASTER STATUS 获取 File 和 Position CHANGE MASTER TO MASTER_HOST='192.168.88.20', MASTER_USER='repl', # 需在 Server B 提前创建 repl 用户(同主从配置) MASTER_PASSWORD='123456', MASTER_LOG_FILE='mysql-bin.000001', # Server B 的 binlog 文件名 MASTER_LOG_POS=154; # Server B 的 binlog 位置START SLAVE;在 Server B 上配置同步 Server A:
-- 先在 Server A 执行 SHOW MASTER STATUS 获取 File 和 Position CHANGE MASTER TO MASTER_HOST='192.168.88.10', MASTER_USER='repl', # 需在 Server A 提前创建 repl 用户 MASTER_PASSWORD='123456', MASTER_LOG_FILE='mysql-bin.000001', # Server A 的 binlog 文件名 MASTER_LOG_POS=154; # Server A 的 binlog 位置START SLAVE;
步骤 3:验证主主同步
在 Server A 插入数据:
CREATE DATABASE testdb; USE testdb; CREATE TABLE t (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50)); INSERT INTO t (name) VALUES ('A数据'); -- id=1(A的自增规则)在 Server B 插入数据:
USE testdb; INSERT INTO t (name) VALUES ('B数据'); -- id=2(B的自增规则)验证同步结果:两台服务器均执行
SELECT * FROM t;,应同时显示id=1和id=2的数据,说明双向同步成功。
3. 主主备份的优势与局限
- 优势:
- 高可用:一台服务器故障,另一台可直接接管(无需手动切换主从);
- 负载均衡:读写操作可分配到两台服务器(需应用层配合路由)。
- 局限:
- 复杂度高:需处理自增主键冲突、循环复制等问题;
- 数据一致性风险:双写场景下可能出现同步延迟导致的短暂不一致。
二、一主多从备份(Master-Multi Slave)
一主多从备份是指一台主库(Master)对应多台从库(Slave),主库写入数据后同步到所有从库,从库仅负责读操作。适用于 “读多写少” 场景(如电商商品详情页、新闻网站)。
1. 核心原理
- 主库开启 binlog,记录所有写操作;
- 每台从库通过 I/O 线程获取主库 binlog,通过 SQL 线程执行同步;
- 从库可水平扩展(增加从库数量),分担主库的读压力。
2. 配置步骤(基于单主从扩展)
假设:主库 M(192.168.88.10),从库 S1(192.168.88.20)、S2(192.168.88.30)
步骤 1:主库 M 配置(同单主从的主库配置)
[mysqld]
server-id = 1
log_bin = /var/log/mysql/mysql-bin
binlog_do_db = testdb
创建同步用户(所有从库共用):
CREATE USER 'repl'@'192.168.88.%' IDENTIFIED BY '123456'; # 允许192.168.88网段连接
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'192.168.88.%';
FLUSH PRIVILEGES;
步骤 2:从库 S1 和 S2 配置
S1 和 S2 配置相同:
[mysqld]
server-id = 2 # S1用2,S2用3(唯一即可)
relay_log = /var/log/mysql/mysql-relay-bin
read_only = 1 # 只读(普通用户)
重启 MySQL 后,分别在 S1 和 S2 配置同步主库 M:
CHANGE MASTER TO
MASTER_HOST='192.168.88.10',
MASTER_USER='repl',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='mysql-bin.000001', # 主库M的binlog文件名
MASTER_LOG_POS=154; # 主库M的binlog位置START SLAVE;
步骤 3:验证一主多从同步
主库 M 插入数据:
USE testdb; INSERT INTO t (name) VALUES ('主库数据');从库 S1 和 S2 验证:均执行
SELECT * FROM t;,应看到主库插入的数据,说明多从库同步成功。
3. 一主多从的优势与局限
- 优势:
- 读写分离:主库写、从库读,提升整体吞吐量(如 1 主 3 从可分担 3 倍读压力);
- 数据分发:从库可用于不同场景(如 S1 供 APP 查询,S2 用于数据分析);
- 简单易维护:架构清晰,新增从库只需重复配置步骤。
- 局限:
- 主库压力集中:所有写操作依赖主库,主库故障会导致整体写服务中断;
- 同步延迟:从库数量过多可能导致主库 binlog 发送延迟。
三、两种架构对比与适用场景
| 维度 | 主主备份(双主互备) | 一主多从备份 |
|---|---|---|
| 架构复杂度 | 高(需处理双向同步冲突) | 低(单向同步,架构清晰) |
| 可用性 | 高(单节点故障不影响服务) | 中(主库故障则写服务中断) |
| 读写能力 | 支持双向读写(负载均衡) | 主库写、从库读(读扩展能力强) |
| 数据一致性 | 存在短暂不一致风险(同步延迟) | 从库数据略滞后于主库(可接受) |
| 适用场景 | 写操作频繁、需高可用的场景(如交易系统) | 读多写少、需扩展读能力的场景(如电商) |
| 扩展难度 | 难(需保持双主平衡) | 易(直接新增从库) |
四、最佳实践建议
主主备份注意事项:
- 避免双写冲突:严格通过 “自增主键偏移” 或应用层路由控制写入(如固定写入其中一台);
- 监控同步状态:确保两台服务器的
Slave_IO_Running和Slave_SQL_Running均为Yes。
一主多从优化建议:
- 从库分级:部分从库用于实时查询,部分从库用于非实时分析(减轻主库压力);
- 主库性能:主库需配置高性能硬件(如 SSD、多核 CPU),避免成为瓶颈;
- 延迟控制:通过
show slave status监控Seconds_Behind_Master(延迟秒数),超过阈值时告警。
混合架构:大型系统可结合两种架构(如 “双主 + 多从”):双主保证高可用,从库扩展读能力,兼顾可用性和性能。
五、总结
- 主主备份适合高可用优先、需要双向读写的场景,通过互备实现故障自动切换;
- 一主多从适合读压力大、架构简单的场景,通过扩展从库提升读性能;
- 实际架构选择需结合业务量(读写比例)、可用性要求和运维成本,核心目标是 “数据安全 + 系统稳定 + 性能达标”。
2.3 多主一从
MySQL 集群的 “多主一从” 架构是指多个主库(Master)共享一个从库(Slave),从库同时同步多个主库的数据,适用于 “分散写入、集中备份 / 分析” 的场景(如多区域业务数据汇总、分布式系统日志收集)。以下是该架构的实现原理、配置步骤及适用场景分析:
一、多主一从架构核心原理
数据流向:多个主库(如 Master1、Master2、Master3)各自处理写操作并记录 binlog,从库(Slave)同时连接所有主库,分别同步每个主库的 binlog 并应用到本地,最终从库聚合所有主库的数据。
关键技术:
- 从库通过
CHANGE MASTER TO多次配置,建立与每个主库的同步关系(MySQL 5.7+ 支持多源复制,即一个从库可同时同步多个主库); - 每个主库需配置唯一
server-id,避免 binlog 冲突; - 从库通过
channel区分不同主库的同步线程(每个主库对应一个独立 channel)。
- 从库通过
核心价值:
- 数据集中:将分散在多个主库的数据汇总到从库,便于统一查询、备份或数据分析;
- 节省资源:无需为每个主库单独配置从库,减少硬件成本。
二、多主一从配置步骤(MySQL 5.7+)
假设环境:
- 主库 1(M1):192.168.88.10,
server-id=10 - 主库 2(M2):192.168.88.11,
server-id=11 - 从库(S):192.168.88.20,
server-id=20
步骤 1:配置所有主库(M1、M2)
1. 修改主库配置文件(my.cnf)
M1 和 M2 配置类似,仅 server-id 不同:
[mysqld]
server-id = 10 # M1用10,M2用11(必须唯一)
log_bin = /var/log/mysql/mysql-bin # 开启binlog
binlog_do_db = appdb # 仅同步appdb库(可选)
log_slave_updates = 0 # 多主一从中主库无需将同步数据写入自身binlog
重启主库:systemctl restart mysqld
2. 主库创建同步用户
在 M1 和 M2 上分别创建允许从库 S 连接的用户:
-- M1 执行
CREATE USER 'repl'@'192.168.88.20' IDENTIFIED BY '123456';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'192.168.88.20';
FLUSH PRIVILEGES;-- M2 执行(同上,用户名密码需一致)
CREATE USER 'repl'@'192.168.88.20' IDENTIFIED BY '123456';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'192.168.88.20';
FLUSH PRIVILEGES;
3. 记录主库 binlog 状态
在 M1 和 M2 上分别执行 SHOW MASTER STATUS;,记录 File 和 Position(从库配置需要):
- M1 输出示例:
File=mysql-bin.000001,Position=154 - M2 输出示例:
File=mysql-bin.000001,Position=154
步骤 2:配置从库(S)
1. 修改从库配置文件(my.cnf)
[mysqld]
server-id = 20 # 唯一标识,与所有主库不同
relay_log = /var/log/mysql/mysql-relay-bin # 中继日志路径
read_only = 1 # 从库设为只读(避免误写)
重启从库:systemctl restart mysqld
2. 从库配置多主同步(多源复制)
登录从库 S,分别配置与 M1、M2 的同步关系(通过 FOR CHANNEL 指定通道名,区分不同主库):
配置同步 M1:
CHANGE MASTER TO
MASTER_HOST='192.168.88.10', # M1的IP
MASTER_USER='repl',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='mysql-bin.000001', # M1的binlog文件名
MASTER_LOG_POS=154 # M1的binlog位置
FOR CHANNEL 'master1'; # 通道名(自定义,如master1)
配置同步 M2:
CHANGE MASTER TO
MASTER_HOST='192.168.88.11', # M2的IP
MASTER_USER='repl',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='mysql-bin.000001', # M2的binlog文件名
MASTER_LOG_POS=154 # M2的binlog位置
FOR CHANNEL 'master2'; # 通道名(如master2)
3. 启动多主同步
-- 启动所有通道的同步(或指定通道:START SLAVE FOR CHANNEL 'master1';)
START SLAVE;
4. 查看同步状态
-- 查看所有通道状态
SHOW SLAVE STATUS FOR CHANNEL 'master1'\G;
SHOW SLAVE STATUS FOR CHANNEL 'master2'\G;
验证关键参数(均需为 Yes):
Slave_IO_Running: Yes # 对应主库的I/O线程正常
Slave_SQL_Running: Yes # 对应主库的SQL线程正常
步骤 3:验证多主一从同步
1. 主库写入测试数据
M1 插入数据:
CREATE DATABASE appdb; USE appdb; CREATE TABLE logs (id INT AUTO_INCREMENT PRIMARY KEY, content VARCHAR(100), source VARCHAR(20)); INSERT INTO logs (content, source) VALUES ('M1的业务数据', 'master1');M2 插入数据:
USE appdb; # 需与M1库名一致,否则从库会生成两个appdb(需提前确保库表结构一致) INSERT INTO logs (content, source) VALUES ('M2的业务数据', 'master2');
2. 从库验证数据汇总
从库 S 执行:
USE appdb;
SELECT * FROM logs;
输出应包含两条数据(分别来自 M1 和 M2),说明多主数据已同步到从库:
+----+-----------------+---------+
| id | content | source |
+----+-----------------+---------+
| 1 | M1的业务数据 | master1 |
| 1 | M2的业务数据 | master2 | # 注意:id可能重复,需业务层避免或使用全局唯一ID
+----+-----------------+---------+
三、多主一从架构的关键问题与解决
表结构不一致导致同步失败
- 问题:若 M1 和 M2 的表结构不同(如 M1 有
col1,M2 无),从库执行同步时会报错。 - 解决:提前统一所有主库的表结构,通过脚本定期检查主库表结构一致性。
- 问题:若 M1 和 M2 的表结构不同(如 M1 有
主键冲突(如自增 ID 重复)
- 问题:M1 和 M2 若使用自增主键(
AUTO_INCREMENT),会导致从库中出现重复 ID(如上例)。 - 解决:
- 主库使用全局唯一 ID(如 UUID)代替自增 ID;
- 为不同主库分配自增 ID 段(如 M1 用 1-10000,M2 用 10001-20000)。
- 问题:M1 和 M2 若使用自增主键(
从库压力集中
- 问题:所有主库的同步压力集中在一个从库,若主库数量过多(如 10+),从库可能因 SQL 线程繁忙导致延迟。
- 解决:
- 从库配置高性能硬件(如多核 CPU、大内存);
- 拆分从库(如按业务线分多个从库,每个从库同步部分主库)。
主库故障不影响其他主库同步
- 特性:某一主库(如 M1)故障时,从库仅停止 M1 对应的同步通道(
master1),不影响 M2 的同步,故障恢复后重启通道即可:sql
START SLAVE FOR CHANNEL 'master1'; # M1恢复后重启同步
- 特性:某一主库(如 M1)故障时,从库仅停止 M1 对应的同步通道(
四、适用场景与局限性
适用场景
- 分布式业务数据汇总:多区域业务(如北京、上海分公司)各自使用独立主库,从库集中同步所有区域数据,供总部统一分析。
- 日志 / 监控数据收集:多台应用服务器的本地主库记录日志,从库汇总后用于集中监控或审计。
- 低成本备份方案:对多个低写入量的主库,共用一个从库作为备份,减少服务器资源投入。
局限性
- 不适合核心业务读写分离:从库聚合了多主数据,无法单独对应某一主库的读请求,不适合 “主写从读” 的传统读写分离场景。
- 数据一致性要求低:若主库间存在业务关联(如跨主库的事务),多主一从无法保证事务一致性,可能出现数据冲突。
- 扩展受限:从库性能上限限制了主库数量,无法无限扩展主库节点。
2.4 读写分离
MySQL 集群读写分离是通过分离读操作和写操作到不同节点的架构设计,解决单库 “读写冲突” 和 “性能瓶颈” 问题。核心思想是:主库(Master)负责写操作(INSERT/UPDATE/DELETE),从库(Slave)负责读操作(SELECT),通过中间件或应用层路由实现请求分发,提升整体吞吐量。
一、读写分离核心原理
数据流向:
- 写操作→主库:所有数据修改操作发送到主库,主库通过 binlog 记录变更;
- 主库→从库:从库通过主从复制机制同步主库的 binlog,保持数据一致;
- 读操作→从库:查询请求分发到从库,减轻主库压力。
关键组件:
- 主从集群:1 主 N 从(一主多从架构),主从通过 binlog 同步数据;
- 路由层:决定请求发送到主库还是从库(如中间件、ORM 框架);
- 监控层:监控从库延迟、节点状态,确保读请求路由到可用节点。
二、读写分离实现方式
根据路由逻辑的位置,分为应用层路由和中间件路由两种方案,各有优劣:
1. 应用层路由(轻量方案)
在应用程序中通过代码或 ORM 框架区分读写请求,直接连接主库或从库。
实现示例(Python + SQLAlchemy):
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker# 主库(写操作)
master_engine = create_engine("mysql+pymysql://user:pass@192.168.88.10:3306/testdb")
MasterSession = sessionmaker(bind=master_engine)# 从库(读操作)
slave_engine = create_engine("mysql+pymysql://user:pass@192.168.88.20:3306/testdb")
SlaveSession = sessionmaker(bind=slave_engine)# 写操作:使用主库
def create_user(name):session = MasterSession()session.execute("INSERT INTO user (name) VALUES (:name)", {"name": name})session.commit()session.close()# 读操作:使用从库
def get_user(name):session = SlaveSession()result = session.execute("SELECT * FROM user WHERE name = :name", {"name": name})user = result.fetchone()session.close()return user
优势:
- 架构简单,无需额外组件;
- 性能损耗低(无中间件转发)。
局限:
- 代码侵入性强(读写逻辑耦合在应用中);
- 不易扩展(新增从库需修改应用配置);
- 无法处理从库故障自动切换。
2. 中间件路由(企业级方案)
通过专用中间件(如 MyCat、ProxySQL、ShardingSphere)统一接收请求,自动路由到主库或从库,对应用透明。
以 MyCat 为例的架构:
- 应用→MyCat(连接端口 8066):应用只需连接 MyCat,无需关心后端主从;
- MyCat→主库 / 从库:MyCat 根据 SQL 类型(读 / 写)自动转发:
- 写 SQL(
INSERT/UPDATE)→主库; - 读 SQL(
SELECT)→从库(支持负载均衡,如轮询、权重)。
- 写 SQL(
MyCat 核心配置(schema.xml):
<!-- 定义逻辑库 -->
<schema name="testdb" checkSQLschema="false" sqlMaxLimit="100"><table name="user" dataNode="dn1" /> <!-- 逻辑表关联到数据节点dn1 -->
</schema><!-- 定义数据节点(关联物理库) -->
<dataNode name="dn1" dataHost="host1" database="testdb" /><!-- 定义数据主机(主从配置) -->
<dataHost name="host1" maxCon="1000" minCon="10" balance="1"><!-- 写主机(主库) --><writeHost host="master" url="192.168.88.10:3306" user="root" password="123456"><!-- 读主机(从库) --><readHost host="slave1" url="192.168.88.20:3306" user="root" password="123456" /><readHost host="slave2" url="192.168.88.30:3306" user="root" password="123456" /></writeHost>
</dataHost>
balance="1":开启读负载均衡(从库轮询)。
优势:
- 对应用透明(应用无需修改代码);
- 支持从库故障自动切换、负载均衡;
- 易于扩展(新增从库只需修改中间件配置)。
局限:
- 增加架构复杂度(需维护中间件);
- 存在一定性能损耗(中间件转发开销)。
三、关键问题与解决方案
1. 主从同步延迟(读不到刚写入的数据)
问题:主库写入数据后,从库同步存在延迟(如 100ms),若此时读从库可能获取旧数据(如刚下单后立即查询订单,从库尚未同步)。
解决方案:
- 强制读主库:对实时性要求高的读请求(如订单详情),通过中间件或应用层路由到主库;
sql
-- MyCat 中可通过注解强制走主库 /*!mycat:db_type=master*/ SELECT * FROM order WHERE id=100; - 优化主从同步:
- 主库使用 SSD 减少 binlog 写入延迟;
- 从库开启
relay_log_purge=0避免中继日志清理延迟; - 调整
innodb_flush_log_at_trx_commit=1(主库)和sync_binlog=1确保 binlog 及时刷盘。
2. 从库故障处理
问题:从库宕机或同步异常时,读请求路由到故障节点会导致查询失败。
解决方案:
- 中间件自动检测:MyCat/ProxySQL 定期检测从库心跳(如执行
SELECT 1),故障时自动剔除该从库; - 从库冗余:部署多个从库(如 2+),单个故障不影响整体读服务。
3. 读写权限控制
问题:从库若被误写,会导致主从数据不一致。
解决方案:
- 从库配置
read_only=1(普通用户只读,root 不受限); - 为从库创建专用只读用户(仅授予
SELECT权限):-- 从库创建只读用户 CREATE USER 'read_user'@'%' IDENTIFIED BY 'read_pass'; GRANT SELECT ON *.* TO 'read_user'@'%';
四、读写分离最佳实践
从库数量规划:根据读压力确定从库数量(如主库写 QPS 1000,读 QPS 10000,可配置 3-5 个从库)。
监控指标:
- 主从延迟:
Seconds_Behind_Master(从库延迟秒数,需 < 1s); - 节点状态:主从库 CPU、内存、连接数(避免单节点过载);
- 中间件性能:MyCat/ProxySQL 的转发延迟、连接数。
- 主从延迟:
数据一致性验证:定期使用
pt-table-checksum检查主从数据一致性,发现差异及时修复:bash
pt-table-checksum --user=root --password=123456 h=192.168.88.10,D=testdb读写分离与分库分表结合:超大规模业务(如千万级 TPS)可同时使用读写分离和分库分表(如 ShardingSphere),既分散读写压力,又拆分海量数据。
五、适用场景总结
读写分离适合 **“读多写少”** 的业务场景(如电商商品页、新闻网站、APP 列表页),核心价值是:
- 减轻主库压力(避免读操作占用主库资源);
- 提升读吞吐量(通过增加从库扩展读能力);
- 提高系统可用性(从库故障不影响写服务)。