MinerU与Docling:智能文档处理框架对比
摘要
本文深入分析了两个主流的智能文档处理框架——MinerU和Docling。MinerU是由OpenDataLab开发的基于多模态大模型的PDF文档解析工具,专注于高精度的文档内容提取;Docling是IBM Research开发的企业级文档处理平台,提供多格式文档的统一处理能力。通过对比两个项目的技术架构、功能特性和应用场景,为开发者提供选型参考。
1. 项目定位与使用场景
1.1 MinerU项目定位
MinerU定位为高精度PDF文档解析专家,主要解决以下问题:
- 复杂PDF文档的精确解析:支持学术论文、技术报告、财务报表等复杂版面的文档
- 多模态内容理解:集成OCR、表格识别、公式解析、图像分类等多种AI能力
- 端到端文档处理:从PDF输入到结构化输出的完整流程
核心使用场景:
- 学术文献处理与知识抽取
- 企业文档数字化转换
- RAG系统的文档预处理
- 金融报表自动化分析
1.2 Docling项目定位
Docling定位为企业级多格式文档处理平台,主要解决以下问题:
- 多格式文档统一处理:支持PDF、DOCX、XLSX、HTML、Markdown等多种格式
- 企业级可扩展性:提供插件化架构和批量处理能力
- AI生态系统集成:与LangChain、LlamaIndex等主流AI框架深度集成
核心使用场景:
- 企业文档管理系统
- 多格式文档转换服务
- AI应用的文档预处理管道
- 大规模文档批量处理
2. 技术架构对比
2.1 MinerU技术架构
MinerU采用多模态AI驱动的管道式架构:
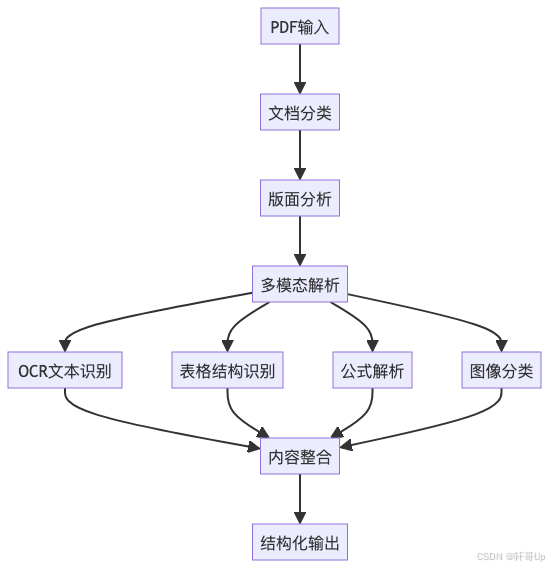
核心技术组件:
- VLM多模态模型(MinerU/mineru/model/vlm_hf_model/modeling_mineru2.py)
-
- 基于Qwen2架构的视觉语言模型
-
- 集成SigLIP视觉编码器
-
- 支持端到端文档理解
- 管道式处理引擎(MinerU/mineru/backend/pipeline/pipeline_analyze.py)
-
- 模块化的处理流程
-
- 支持GPU加速推理
- <