【ProtoBuffer】简介与安装
目录
前言
一.在window下安装ProtoBuf
二.在Ubuntu下的安装ProtoBuf
2.1.安装依赖
2.2.下载源代码
2.3.编译源代码
2.3.1.第一步:执行 autogen.sh
2.3.2.第二步:执行 configure
2.3.3.第三步:编译
2.3.4.第四步:验证编译结果
2.3.5.第五步:安装到系统目录
2.3.6.第六步:修改相关配置文件
2.3.7.第七步:验证是否安装成功
前言
一,序列化和反序列化
想象一下,一个在内存中活生生的“对象”,它拥有复杂的数据结构(如嵌套的类、列表、字典等)和状态(属性的值)。这个对象存在于特定的程序运行时环境中,无法直接“搬运”或“邮寄”。
-
序列化:其本质是一个编码 过程。它将内存中这个结构化的对象,“拍平”并转换成一个可以独立存储或传输的字节序列。这个过程就像将一辆复杂的汽车拆解,打包进一个标准规格的集装箱里。
-
反序列化:其本质是一个解码 过程。它将接收到的字节序列,按照约定的规则,重新“组装”并重建为一个在内存中可用的对象。这就好比在目的地接收集装箱,并将其重新组装成一辆可以驾驶的汽车。
这个“字节序列”可以是二进制格式,也可以是特定的文本格式(如JSON、XML)。
二、为什么需要序列化?核心应用场景
序列化技术是实现数据持久化和网络通信的基石。
-
数据持久化
-
目的:将程序运行时的瞬时状态转化为永久状态。
-
场景:
-
保存到文件:将用户的应用程序设置、游戏存档等对象直接保存到本地文件。
-
存入数据库:将对象存储到数据库的BLOB(二进制大对象)字段中。
-
缓存:将数据库查询结果或复杂计算的结果对象序列化后存入Redis、Memcached等缓存系统,下次需要时直接反序列化,避免重复计算或查询。
-
-
-
网络传输
-
目的:实现跨进程、跨网络的对象交换。
-
场景:
-
Socket网络编程:正如您提到的,在TCP/UDP套接字通信中,只能传输字节流。发送方必须将对象序列化,接收方再反序列化。
-
远程过程调用(RPC) 和 微服务架构:这是序列化最重要的应用领域之一。当服务A调用另一个进程或机器上的服务B时,需要将调用的参数(对象)序列化后通过网络传给服务B,服务B执行后,再将结果(对象)序列化返回给服务A。高性能的序列化协议是RPC框架(如gRPC, Dubbo)的核心。
-
消息队列:在分布式系统中,服务之间通过消息队列(如Kafka, RabbitMQ)进行异步通信。发送到队列的消息体,也需要是序列化后的字节序列。
-
-
-
深拷贝对象
-
通过先将对象序列化,再立即反序列化,可以方便地创建一个该对象的完整副本(深拷贝),而不是仅仅复制引用。
-
三、如何实现序列化?常见协议与技术对比
在选择序列化协议时,您通常需要在性能、可读性、跨语言能力、数据体积这几个核心维度之间进行权衡。不同的场景需要不同的解决方案,以下是主流协议的详细剖析:
1. XML:严谨但冗长的元老
作为一种标记语言,XML采用纯文本格式,通过大量的标签来定义数据。这种结构赋予了它极佳的可读性和自描述性,无需预定义Schema即可理解其内容。然而,正是这些繁复的标签导致了其数据冗余度高、解析性能较差的缺点。尽管在当今的新系统中已较少被选为序列化方案,但由于其标准严格、支持复杂数据结构,它在许多遗留企业系统及配置文件(如Spring的Bean配置)中依然占有一席之地。
2. JSON:Web时代的通用语
JSON是当前最流行、应用最广泛的文本序列化格式。它同样采用轻量级的、人类可读的文本格式,但相比于XML,其语法更为简洁,数据体积更小。JSON与JavaScript的天然集成使其成为Web前端与后端API通信的事实标准。如今,几乎所有现代编程语言都提供了高效的原生或第三方库来支持JSON的解析与生成,其出色的可读性和易用性是它最大的优势。
3. Protocol Buffers:高性能通信的标杆
由Google开发的Protocol Buffers是一种高性能的二进制序列化协议。与JSON和XML不同,使用protobuf需要预先严格地定义一个.proto文件来描述数据结构。这种强Schema依赖性是它高性能的基石:序列化后的数据体积非常小,且编码与解析速度极快。此外,protobuf天生具备良好的向前、向后兼容性,非常适合在微服务架构、服务间RPC调用等对性能和带宽有严苛要求的场景中使用。代价是序列化后的字节序列几乎不可读,必须依赖原始的.proto文件才能正确解析。
4. Java Serialization:应谨慎使用的内置方案
这是Java语言原生的序列化机制。它的主要优势在于使用简单,无需引入任何第三方库。然而,它存在着显著的弊端:性能低下、序列化后产生的字节流体积庞大,并且最关键的是,它严重绑定于Java语言,无法实现跨语言交互。因此,在生产环境,尤其是在分布式系统和网络通信中,通常不推荐使用Java原生序列化。
5. Apache Avro:大数据领域的紧凑选择
Avro是另一个高性能的二进制序列化系统,它也强烈依赖于一个外部的Schema定义。Avro的一个独特之处在于,在序列化时,数据本身不携带字段名称等元信息,仅存储具体的值。这使得它的序列化结果比protobuf更加紧凑。在反序列化时,消费者必须使用与序列化时完全相同的Schema才能正确还原数据。Avro的设计非常适合海量数据存储和批量处理,因此它在Hadoop生态系统中得到了广泛的应用。
总结与选型建议:
-
若您追求极致的开发效率和可读性,尤其是在Web API领域,JSON是安全且通用的首选。
-
若您的场景对性能、吞吐量和带宽极为敏感,例如微服务间的内部通信,Protocol Buffers通常是更优的选择。
-
若您深耕大数据领域,需要处理海量数据存储,Apache Avro因其极致的紧凑性而备受青睐。
-
对于全新的项目,除非有特殊的历史原因,否则应尽量避免使用XML和Java原生序列化。
四,ProtoBuf 是什么
Protocol Buffers(简称 ProtoBuf)是 Google 提出的一种跨语言、跨平台、可扩展的结构化数据序列化方案,广泛应用于通信协议、数据存储等场景。
与 XML 类似,Protocol Buffers 提供了一种灵活、高效且支持自动化代码生成的序列化机制。但其在设计上更为轻量,具备更小的数据体积、更快的处理速度以及更简洁的开发体验。
使用 ProtoBuf 时,用户首先需要定义数据的结构描述文件(.proto)。随后,通过配套的编译器生成对应编程语言的源代码,从而轻松实现结构数据在不同数据流中的读写操作。Protocol Buffers 还支持数据结构的平滑升级,可在不破坏向后兼容性的前提下更新结构,确保已部署的程序仍能正常读取旧版本数据。
概括来说,ProtoBuf 作为一种现代化的序列化方法,具备如下核心优势:
-
语言无关、平台无关
支持多种开发语言(如 Java、C++、Python、Go 等),可在多种操作系统与环境中使用,便于跨系统数据交换。 -
编码高效
采用二进制编码格式,数据体积小,序列化/反序列化速度快,性能优于 XML 等文本格式。 -
良好的扩展性与兼容性
通过清晰的版本机制和字段规则,能够在迭代数据结构时保持向后与前向兼容,避免对现有代码造成破坏。 -
支持代码自动生成
提供官方工具链,可根据.proto文件自动生成数据访问类,减少手写代码工作量,提升开发效率。
五,Protocol Buffers 的使用特点
Protocol Buffers(简称 ProtoBuf)是一种由 Google 开发的、语言无关、平台无关的结构化数据序列化机制。其核心使用流程如下:
1. 定义数据结构
首先,开发者需要编写 .proto 文件,用于定义一种或多种“消息”(message)类型以及每个消息中所包含的字段。这些消息实际上就是结构化数据的模式(Schema),类似于面向对象中的类,用于明确数据格式。
2. 编译生成代码
编写好 .proto 文件后,需要使用 Protocol Buffers 提供的编译器 protoc 对其进行编译。编译后,protoc 会根据所选的目标编程语言(如 C++、Java、Python 等),生成对应的头文件和源代码文件。
3. 使用生成的接口
这些自动生成的文件中包含了一系列与所定义消息对应的接口方法,主要包括:
-
各个字段的 getter 和 setter 方法。
-
整个消息对象的序列化(Serialization)方法,即将对象转换成二进制字节流。
-
整个消息对象的反序列化(Deserialization)方法,即从二进制字节流重建对象。
4. 集成至业务代码
最后,在具体的业务代码中,只需引入(#include 或 import)这些生成的头文件或类,便可以:
-
方便地设置或获取消息中每个字段的值。
-
调用生成的序列化方法,将消息对象转换为紧凑的二进制格式,用于网络传输或数据存储。
-
调用反序列化方法,将接收到的二进制数据重新转换回可操作的消息对象。
一.在window下安装ProtoBuf
下载地址:Releases · protocolbuffers/protobuf · GitHub

我们往后面找
点进去之后往下翻
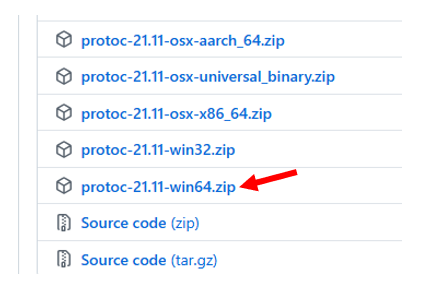
然后我们点击下载
其实是一个安装包
我们把它放到一个文件夹里面进行解压,解压之后就是下面这样子
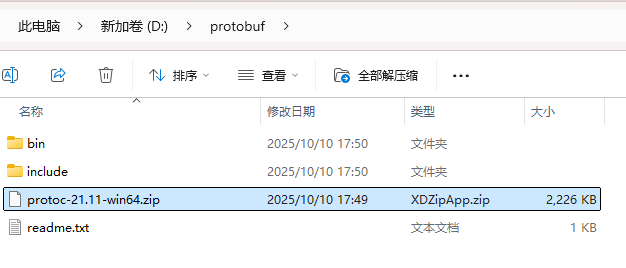
我们点击这个bin目录
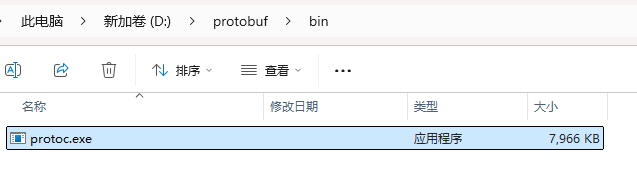
我们把这个目录D:\protobuf\bin配置到我们的系统的环境变量中
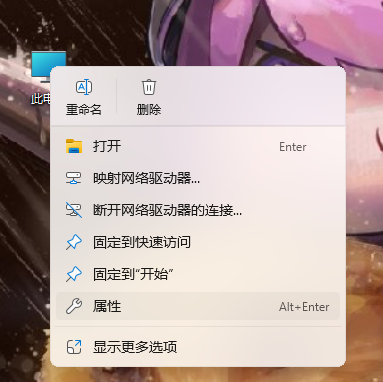
我们右键此电脑,点击属性
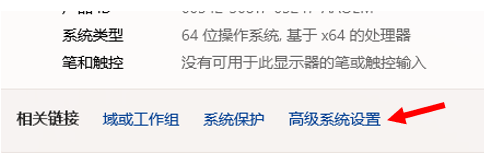
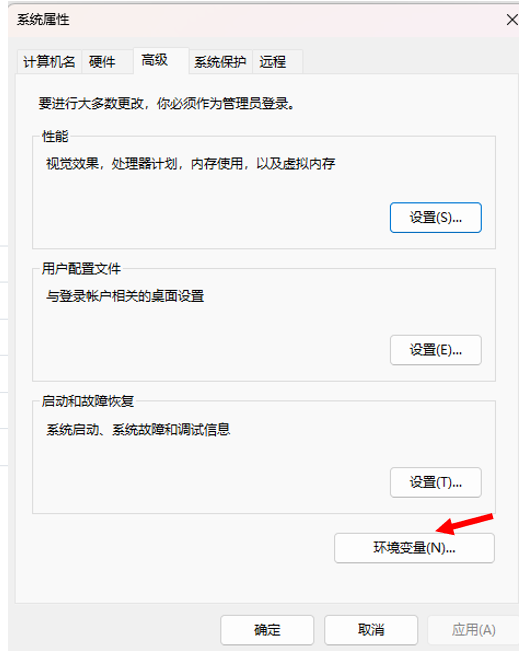
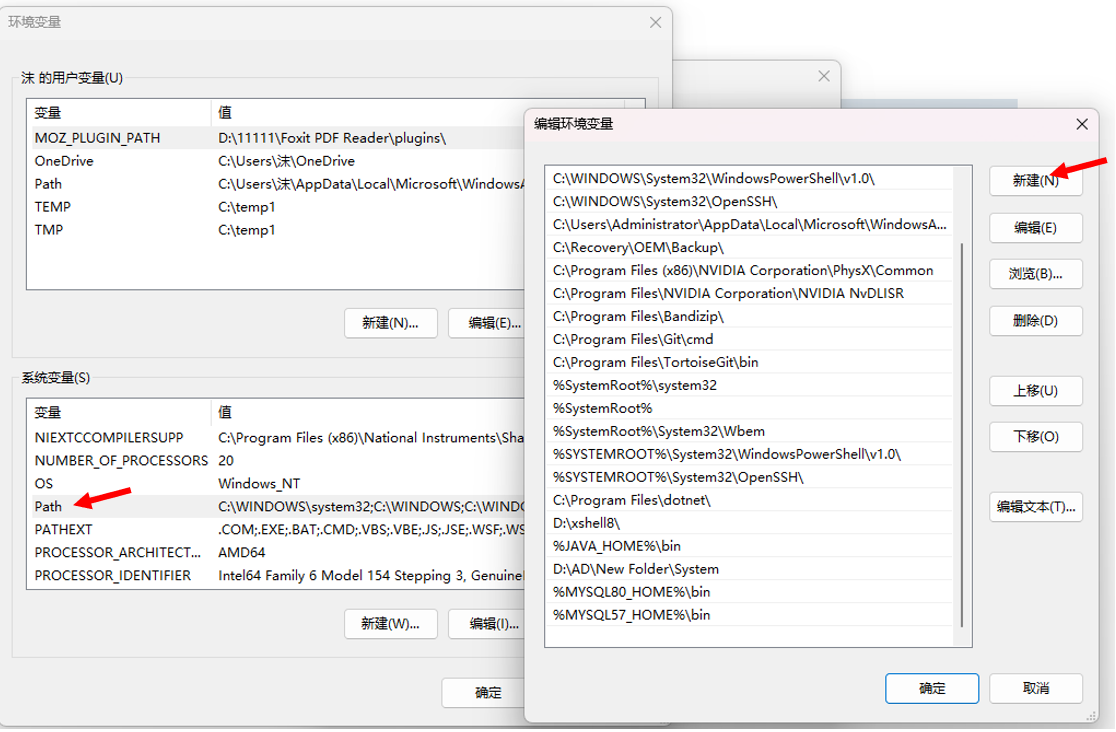
然后我们把我们的bin目录复制进去
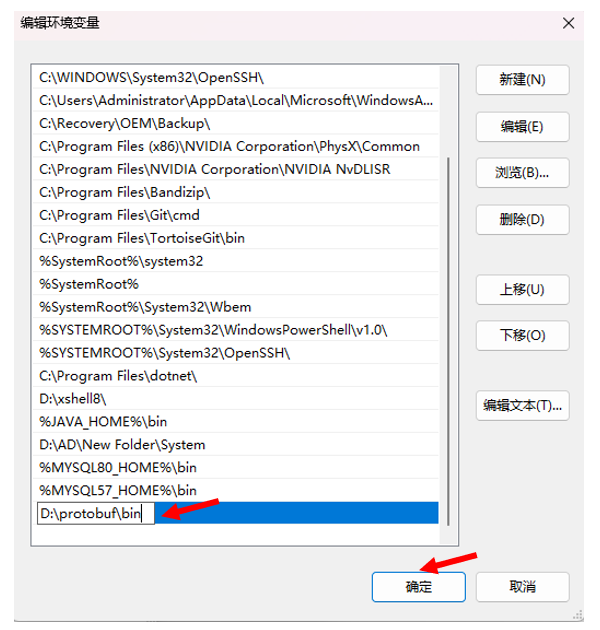
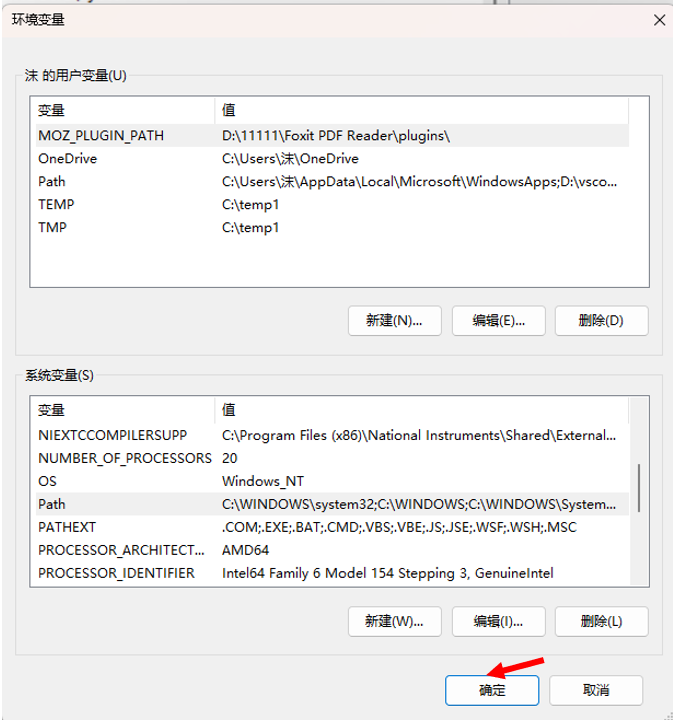
现在环境变量就算是配置好了。
我们现在就来验证一下
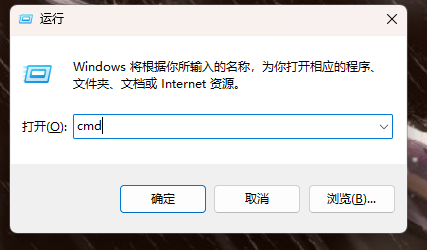
输入protoc --version,如果打印了版本号,就算是安装成功了。
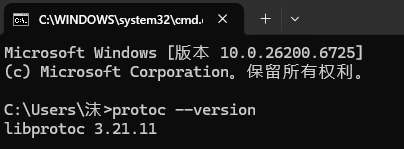
现在就算是安装完成了
二.在Ubuntu下的安装ProtoBuf
2.1.安装依赖
在安装 ProtoBuf(Protocol Buffers)之前,请确保系统中已安装所需的依赖库,包括 autoconf、automake、libtool、curl、make、g++ 和 unzip。这些工具是编译和安装 ProtoBuf 的基础构建环境,缺少任一依赖都可能导致安装失败。
如果您尚未安装这些依赖,可以根据您的操作系统选择以下对应命令进行安装。
Ubuntu / Debian 用户请执行:
sudo apt-get update
sudo apt-get install autoconf automake libtool curl make g++ unzip -y安装完成后,建议再次确认所有依赖已正确安装,之后即可继续下载并编译 ProtoBuf。如有问题,可参考 ProtoBuf 官方文档或对应 Linux 发行版的软件包管理指南。
2.2.下载源代码
接下来我们需要去ProtoBuf下载地址:Releases · protocolbuffers/protobuf
这个下载地址和上面那个是一模一样的
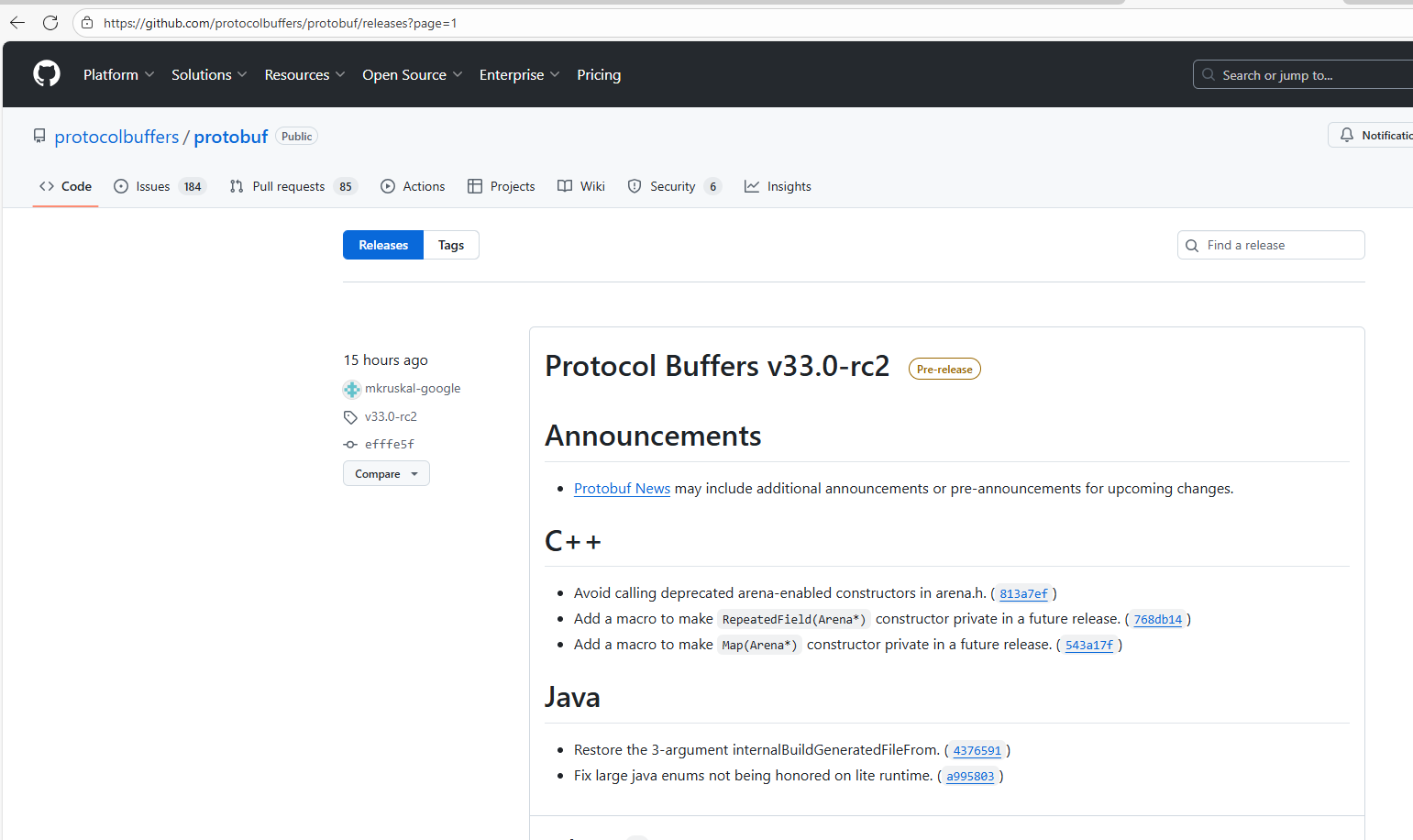
可以不⽤下载最新版本,以v21.11为例,具体的下载根据⾃⼰电脑情况选择。
点进去我们可以看到
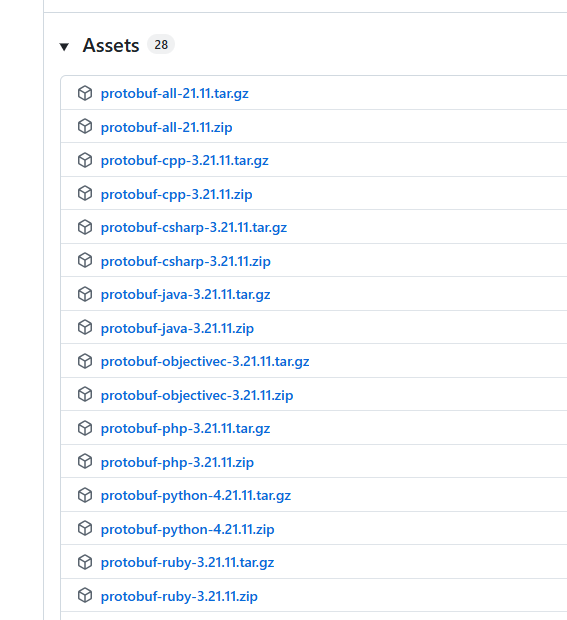
- 如果要在C++下使⽤ProtoBuf,可以选择cpp.zip;
- 如果要在JAVA下使⽤ProtoBuf,可以选择java.zip;
- 其他语⾔选择对应的链接即可。
- 希望⽀持全部语⾔,选择all.zip。
我们这里就选择all
我们直接点击下载
接着我们登陆我们的服务器
执行rz命令
接下来我们进行解压
unzip protobuf-all-21.11.zip解压之后

这个目录就是protobuf的源码
我们需要进行编译一下
2.3.编译源代码
进入解压后的文件目录,按顺序执行以下命令:
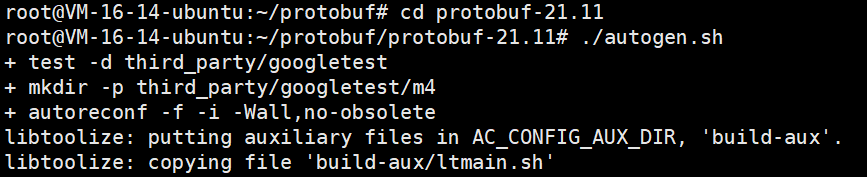
2.3.1.第一步:执行 autogen.sh
运行以下脚本:
./autogen.sh⚠️ 注意:如果你下载的是针对某一特定语言的预编译版本,则无需执行此步骤。
……
2.3.2.第二步:执行 configure
有两种配置方式,请任选其中一种即可:
-
默认安装
将 protobuf 默认安装到/usr/local目录,此时库文件、二进制文件等会分散在该目录下相应子目录中:./configure -
自定义安装目录
将所有内容统一安装到指定目录,如/usr/local/protobuf:./configure --prefix=/usr/local/protobuf
为了统一,我们就使用自定义安装目录方式

……
执行完之后,我们就会发现当前目录下就会有
这意味着我们可以直接运行make
2.3.3.第三步:编译
配置完成后,执行以下命令:
make # 编译源码建议在执行 make check 时耐心等待,该步骤会运行一系列测试以确保编译正确完成。
我们先执行make
等待15min……
2.3.4.第四步:验证编译结果
我们需要验证我们也没有编译成功,所以我们需要执行下面这个
make check # 验证编译结果(可选,约需15分钟)我们执行make check
等待15min……
整个过程中,会出现很多警告,但是只要不出现红色字体,就没有任何问题。
如果说你出现了下面这个问题的话
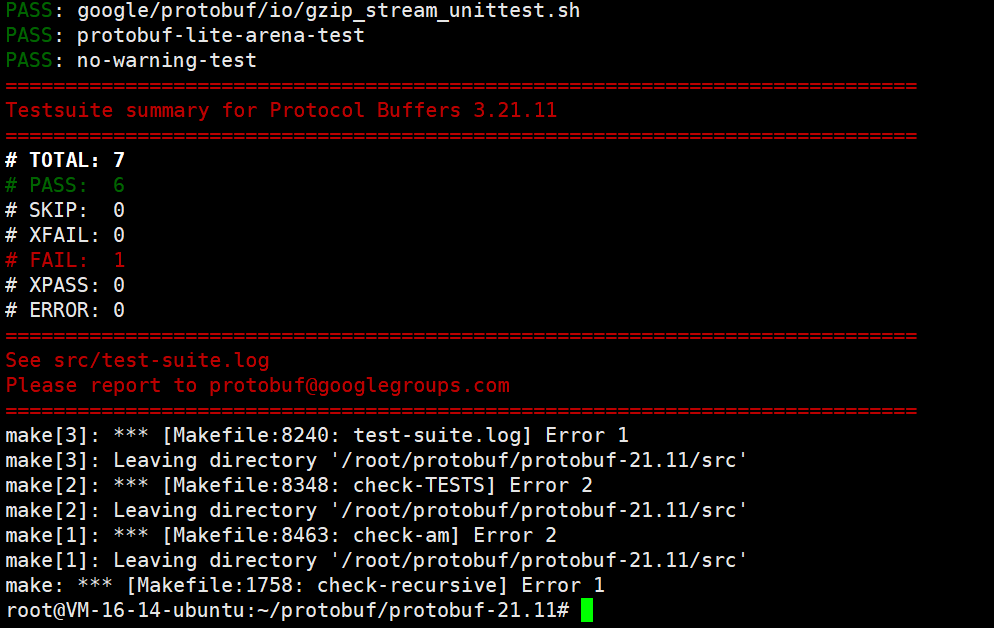
出现以上错误的原因是test的模块⾥⾯有⾮常多的测试⽤例,这些⽤例对服务器环境要求特别严格,需 要增⼤下swap分区,具体操作可参考下面:
- 步骤一:检查当前 SWAP 状态
在开始之前,请先使用命令检查您的 Ubuntu 系统的SWAP 分区
sudo swapon --show这个命令会显示当前已激活的 SWAP 分区信息,如果没有任何输出,说明系统尚未配置 SWAP。
- 步骤二:创建 swap 的文件
分配 1G 的swap分区大小
sudo fallocate -l 1G /swapfile如果在创建 SWAP 文件时遇到 fallocate failed: Text file busy 错误,说明系统资源正被占用。
此时需要:
-
关闭所有 SWAP 分区:
sudo swapoff -a -
重新创建 SWAP 文件:
sudo fallocate -l 1G /swapfile
- 步骤三:配置 SWAP 文件权限
为确保安全性,将 SWAP 文件权限设置为仅 root 用户可读写:
sudo chmod 600 /swapfile- 步骤四:创建 SWAP 区域
使用 mkswap 实用程序在文件上设置 Linux SWAP 区域:
sudo mkswap /swapfile- 步骤五:激活和使用 SWAP
使用以下命令激活 swap 文件:
sudo swapon /swapfile验证 SWAP 状态
再次运行以下命令确认 SWAP 已成功激活:
sudo swapon --show或者使用:
free -h- 步骤六:永久化配置
备份原 fstab 文件
在进行系统配置修改前,建议先备份重要文件:
sudo cp /etc/fstab /etc/fstab.bak添加 SWAP 到系统配置
将 SWAP 文件信息添加到 /etc/fstab 文件中,确保系统重启后自动启用:
echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab(建议可以先扩⼤3G,再执⾏ check ) 执⾏ make check 。
如果还是报错,再扩⼤到5G重新执⾏ make check 后,出现以下内容就可以执⾏ make sudo make install 。
现在我们来实验一下扩大3G

看到您系统已经有一个1.9G的swap文件。
那么我们可以另外创建一个3G的
# 创建额外的3G swap文件(与现有swap共存)
sudo fallocate -l 3G /swapfile2
sudo chmod 600 /swapfile2
sudo mkswap /swapfile2
sudo swapon /swapfile2# 验证总swap大小(现在应该有约4.9G)
free -h
sudo swapon --show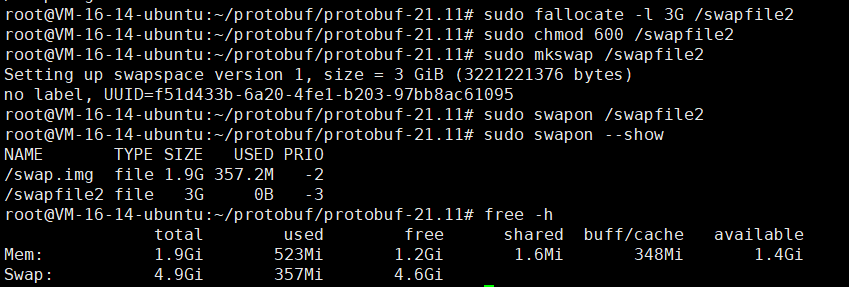
我们这就算是成功了,我们现在重新执行这个make check
cd /root/protobuf/protobuf-21.11
make check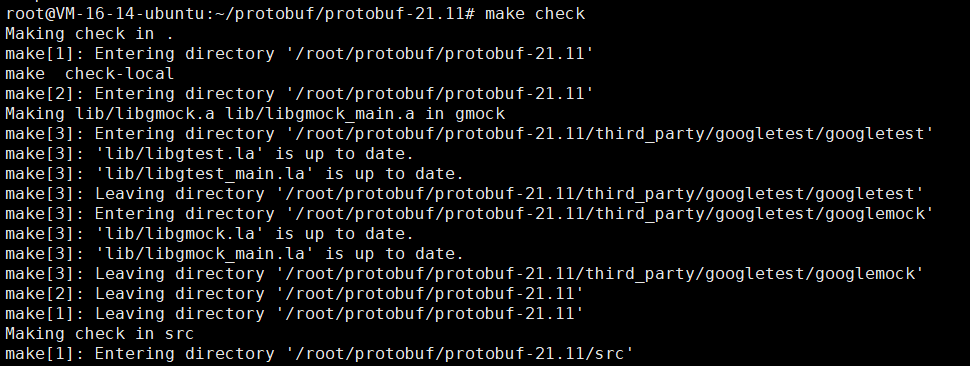
……等待
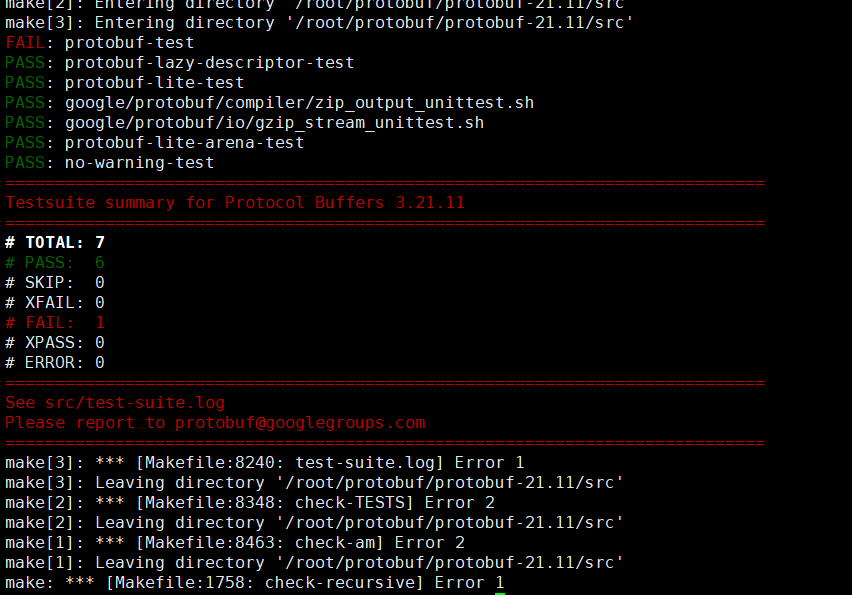
我们发现还是报错,就说明3G的不行,我们换成5G的看看
# 1. 禁用当前的额外swap
sudo swapoff /swapfile2# 2. 删除3G文件,创建5G文件
sudo rm -f /swapfile2
sudo fallocate -l 5G /swapfile2
sudo chmod 600 /swapfile2
sudo mkswap /swapfile2
sudo swapon /swapfile2# 3. 验证新的swap配置
free -h
sudo swapon --show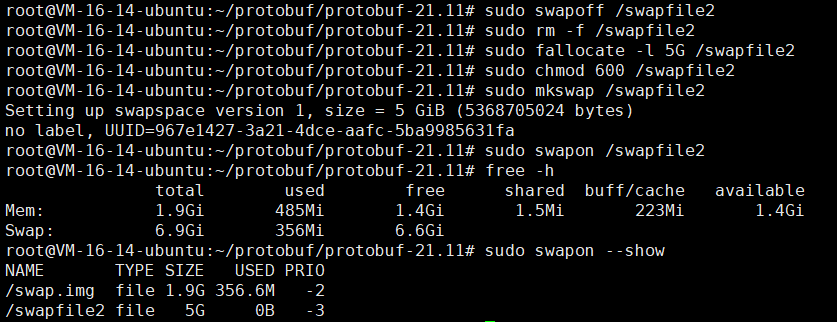
这个时候我们就来再次make check看看
# 再次执行make check
cd /root/protobuf/protobuf-21.11
make check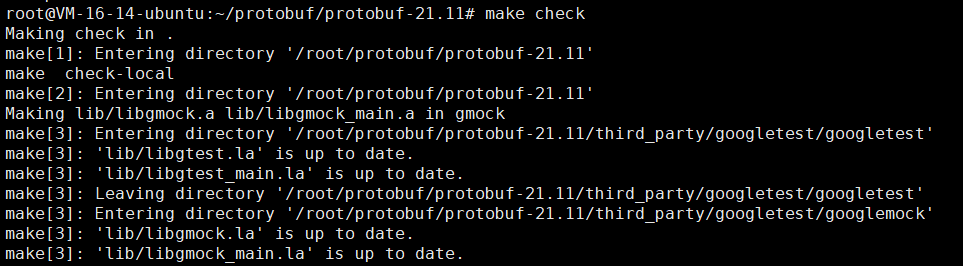
等待……
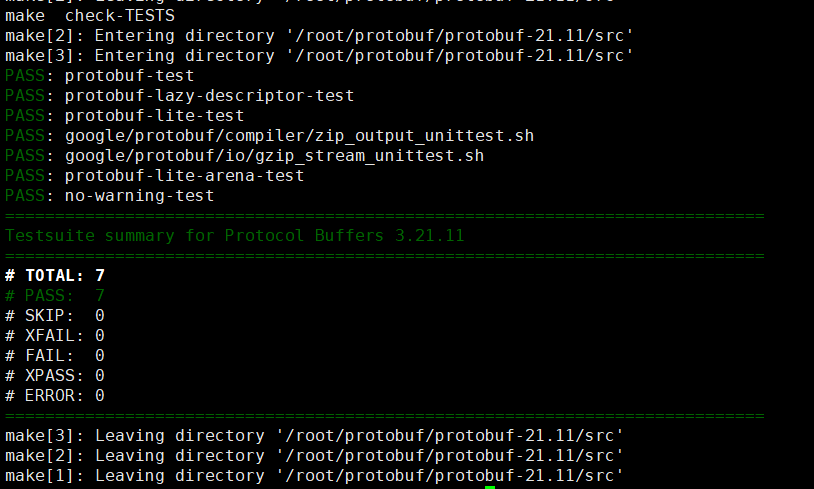
这样子就算是成功了。当然了,我们不需要去持久化。
2.3.5.第五步:安装到系统目录
验证完了之后,我们就需要将它安装到系统目录里面去
sudo make install # 安装到系统目录这个过程是很快的。
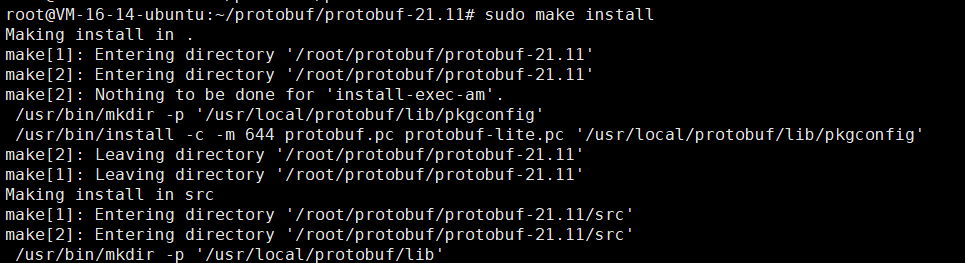
……

2.3.6.第六步:修改相关配置文件
到此,需要你回忆⼀下在第二步:执⾏configure时,如果当时选择了第⼀种执⾏⽅式,也就是 ./configure ,那么到这就可以正常使⽤protobuf了。
如果选择了第⼆种执⾏⽅式,即修改了安装⽬录,那么还需要在/etc/profile中添加⼀些内容:
sudo vim /etc/profile
在末尾添加下面这些内容
# 动态库搜索路径(运行时)
# 指定程序在加载运行期间查找动态链接库的路径,除了系统默认路径外
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/protobuf/lib/# 静态库搜索路径(编译时)
# 指定程序在编译期间查找静态库的路径
export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/protobuf/lib/# 可执行程序搜索路径
# 指定系统在哪些目录中查找可执行文件
export PATH=$PATH:/usr/local/protobuf/bin/# C 程序头文件搜索路径
# 指定 C 编译器查找头文件(.h 文件)的目录
export C_INCLUDE_PATH=$C_INCLUDE_PATH:/usr/local/protobuf/include/# C++ 程序头文件搜索路径
# 指定 C++ 编译器查找头文件(.h/.hpp 文件)的目录
export CPLUS_INCLUDE_PATH=$CPLUS_INCLUDE_PATH:/usr/local/protobuf/include/# pkg-config 工具搜索路径
# 指定 pkg-config 查找 .pc 配置文件的目录,用于获取编译和链接参数
export PKG_CONFIG_PATH=/usr/local/protobuf/lib/pkgconfig/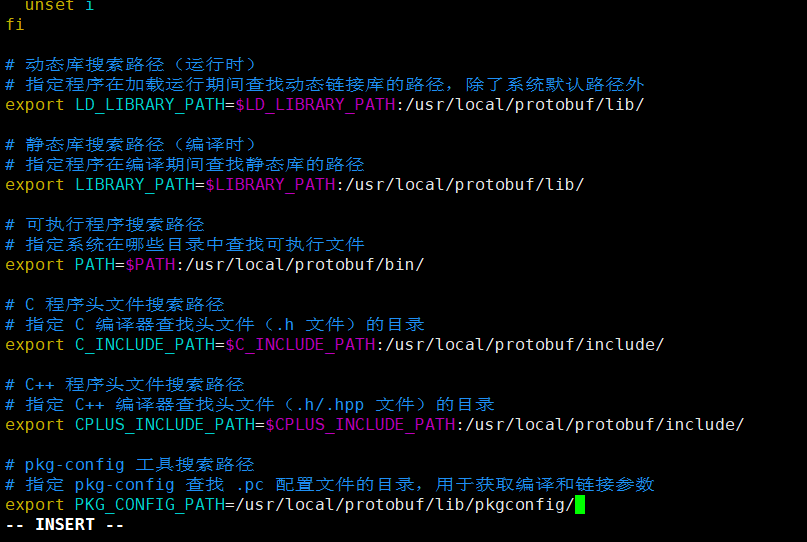
保存退出
最后⼀步,重新执⾏/etc/profile⽂件:
source /etc/profile![]()
2.3.7.第七步:验证是否安装成功
我们来验证是否安装成功
protoc --version![]()
这就算是安装成功了。