SHAP可视化代码详细讲解
SHAP可视化代码详细讲解
目录
- 代码概述
- 环境准备与导入
- 数据生成
- 模型训练
- SHAP值计算
- 可视化图表详解
- 交互特征分析
- 总结与应用建议
1. 代码概述
本代码是一个完整的SHAP (SHapley Additive exPlanations) 分析示例,展示了如何:
- 生成模拟数据集
- 训练机器学习模型(随机森林)
- 计算SHAP值来解释模型预测
- 生成19种不同类型的SHAP可视化图表
SHAP的核心作用:解释"黑盒"机器学习模型的预测结果,量化每个特征对预测的贡献程度。
2. 环境准备与导入
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import shap
关键库说明:
- numpy/pandas:数据处理
- matplotlib:图表绘制
- sklearn:机器学习模型
- shap:SHAP值计算和可视化(需要安装:
pip install shap)
3. 数据生成
3.1 创建特征
X = pd.DataFrame({'feature_1': np.random.randn(n_samples), # 标准正态分布'feature_2': np.random.randn(n_samples), # 标准正态分布'feature_3': np.random.randn(n_samples), # 标准正态分布'feature_4': np.random.uniform(0, 10, n_samples), # 0-10均匀分布'feature_5': np.random.choice([0,1,2,3], n_samples), # 分类变量'N_dist': np.random.uniform(1.10, 1.30, n_samples), # 距离特征'N_d': np.random.choice(range(11), n_samples) # 离散特征
})
特征设计说明:
- 连续特征(feature_1-4):模拟实数值特征
- 分类特征(feature_5):模拟类别数据
- N_dist:模拟化学中的原子间距离(单位:埃Å)
- N_d:模拟离散的配位数或计数特征
3.2 构建目标变量
y = (2 * X['feature_1'] + # 线性关系3 * X['feature_2']**2 + # 非线性关系X['feature_3'] * X['feature_4'] + # 交互效应np.sin(X['N_dist'] * 10) * 5 + # 周期性关系X['N_d'] * 0.5 + # 线性关系np.random.randn(n_samples) * 0.5) # 随机噪声
关系类型:
- 线性:feature_1, N_d
- 非线性:feature_2(平方关系)
- 交互:feature_3 × feature_4
- 周期性:N_dist(正弦函数)
这种复杂关系使得SHAP分析更有意义!
4. 模型训练
rf_model = RandomForestRegressor(n_estimators=100, # 100棵决策树max_depth=10, # 最大深度10random_state=42, # 随机种子n_jobs=-1 # 使用所有CPU核心
)
rf_model.fit(X_train, y_train)
模型选择理由:
- 随机森林能捕捉非线性和交互关系
- SHAP的TreeExplainer对树模型进行了优化,计算速度快
- R²分数用于评估模型质量(接近1表示拟合良好)
5. SHAP值计算
explainer = shap.TreeExplainer(rf_model)
shap_values = explainer(X_test)
核心概念:
- explainer.expected_value:基准预测值(所有特征未知时的平均预测)
- shap_values:每个样本每个特征的SHAP值
- SHAP值解读:
- 正值:特征使预测值增大
- 负值:特征使预测值减小
- 绝对值大小:影响程度
数学原理:
预测值 = 基准值 + SHAP值1 + SHAP值2 + ... + SHAP值n
6. 可视化图表详解
图1: Summary Plot (点图)
shap.summary_plot(shap_values, X_test, show=False)
功能:整体特征重要性可视化
- Y轴:特征名称(按重要性降序排列)
- X轴:SHAP值(影响大小)
- 颜色:特征值高低(红色=高,蓝色=低)
- 解读:可看出哪些特征最重要,以及特征值高低如何影响预测
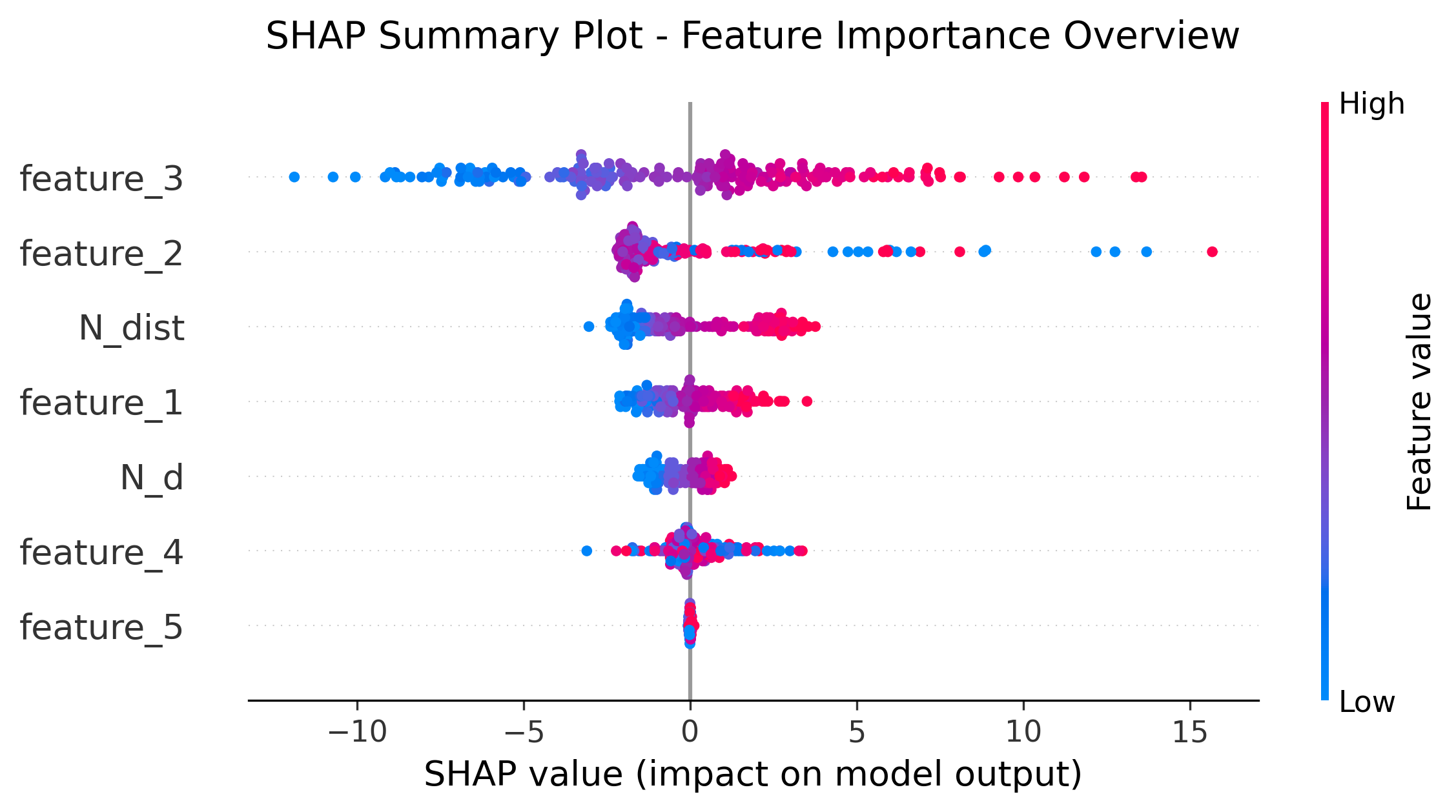
图2: Summary Plot (柱状图)
shap.summary_plot(shap_values, X_test, plot_type="bar", show=False)
功能:平均绝对SHAP值排名
- 显示每个特征的平均影响程度
- 快速识别最重要的特征
- 注意:只显示重要性大小,不显示正负方向
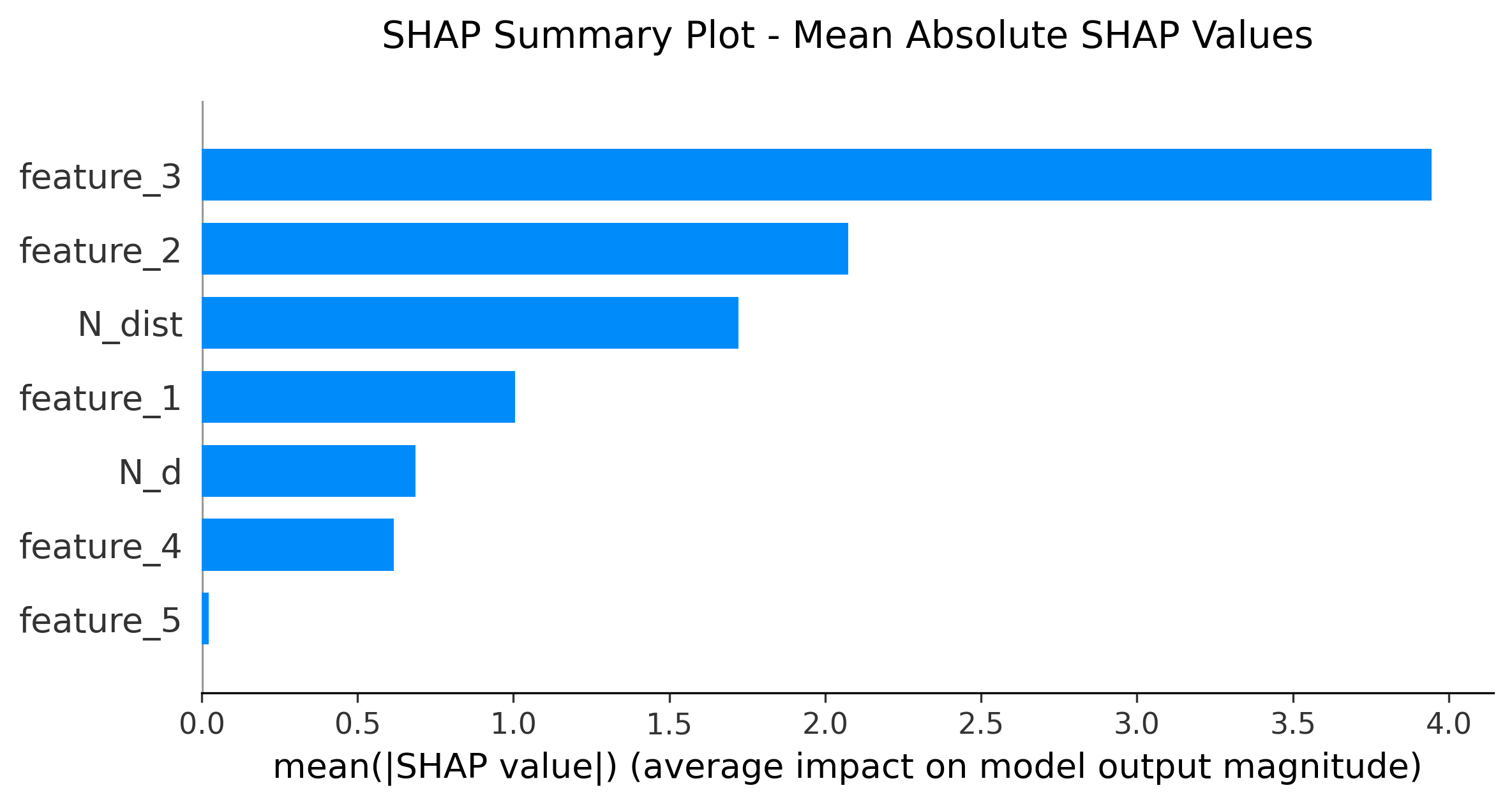
图3: Waterfall Plot (瀑布图)
shap.plots.waterfall(shap_values[0], show=False)
功能:单个样本的预测解释
- 从基准值开始,逐步展示每个特征的贡献
- 红色箭头:增加预测值
- 蓝色箭头:减少预测值
- 最终到达实际预测值
应用场景:解释某个具体预测结果给业务人员
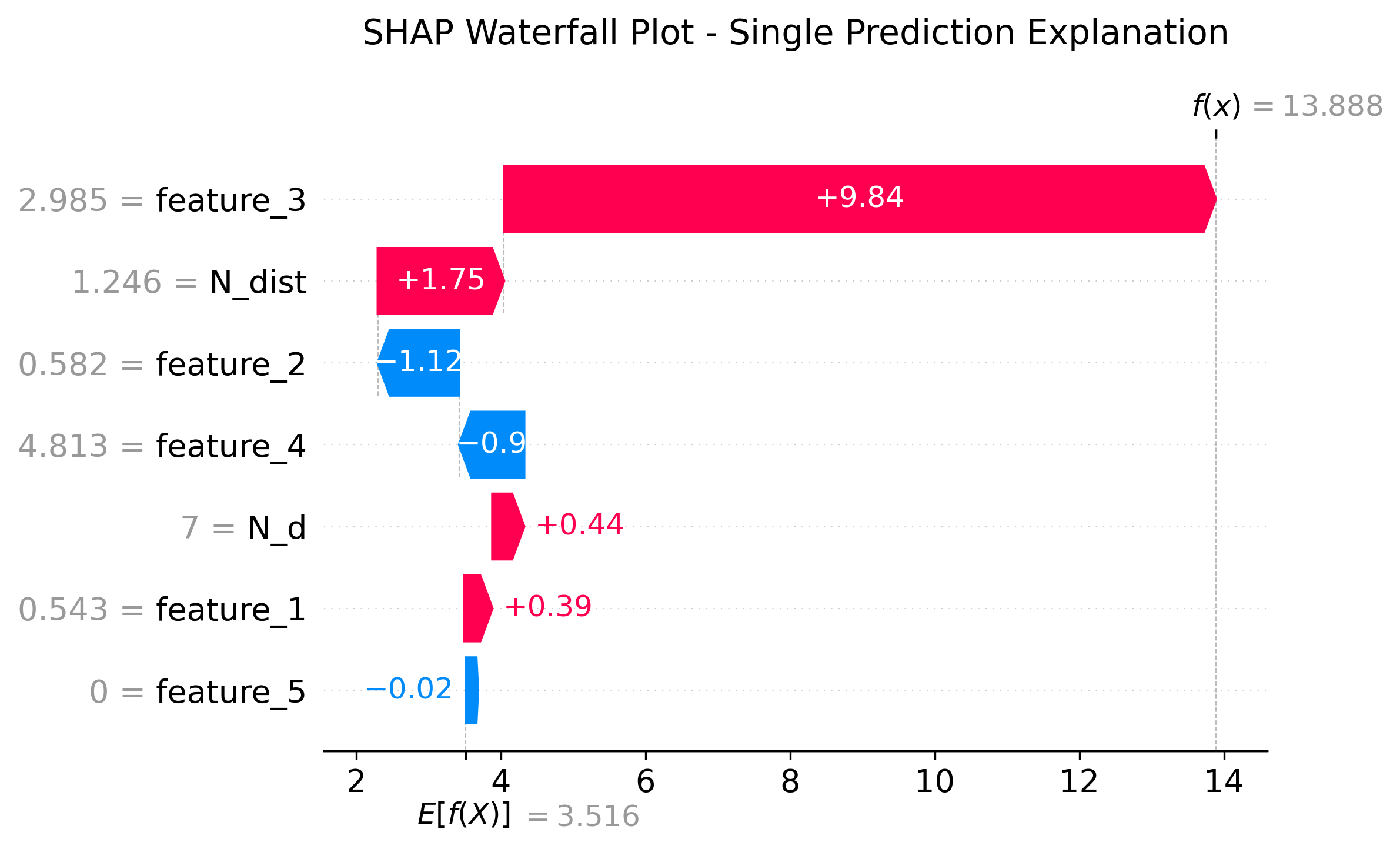
图4: Force Plot (力图)
shap.plots.force(shap_values[0], matplotlib=True, show=False)
功能:紧凑型单样本解释
- 红色区域:推高预测值的特征
- 蓝色区域:降低预测值的特征
- 区域宽度=影响大小
优势:适合快速浏览多个预测

图5: Decision Plot (决策图)
shap.decision_plot(explainer.expected_value,shap_values.values[:50],X_test.iloc[:50],show=False
)
功能:多个样本的决策路径可视化
- 每条线代表一个样本
- 从基准值(底部)到最终预测(顶部)
- 可以看出不同样本的相似决策路径
适用:比较多个预测的差异
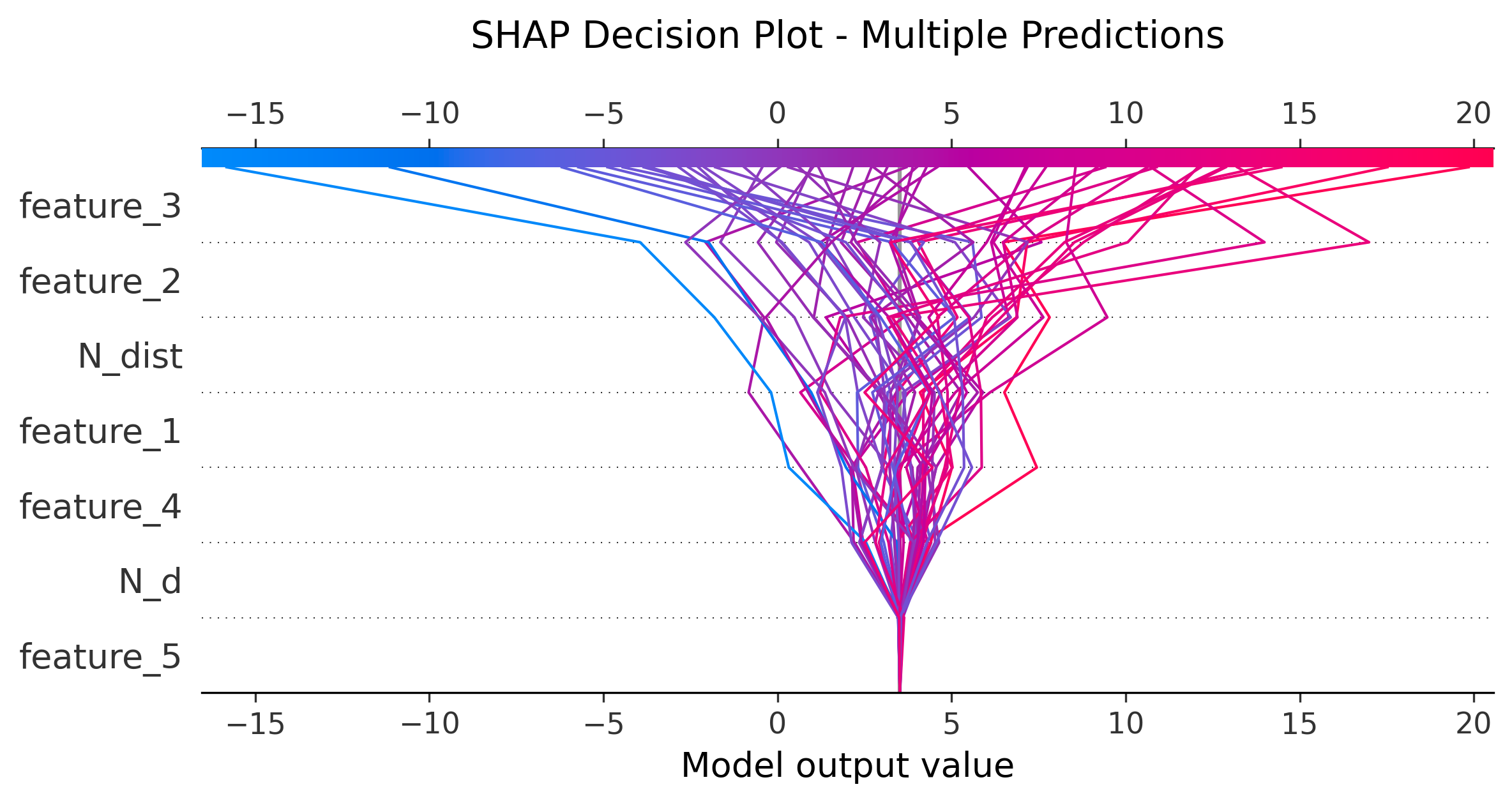
图6-12: Dependence Plot (依赖图)
for feature in X_test.columns:shap.plots.scatter(shap_values[:, feature], show=False)
功能:单特征与SHAP值的关系
- X轴:特征值
- Y轴:该特征的SHAP值
- 颜色:自动选择交互最强的另一个特征
关键发现:
- 线性关系:点呈直线分布
- 非线性关系:点呈曲线或其他模式
- 交互效应:不同颜色的点有不同趋势
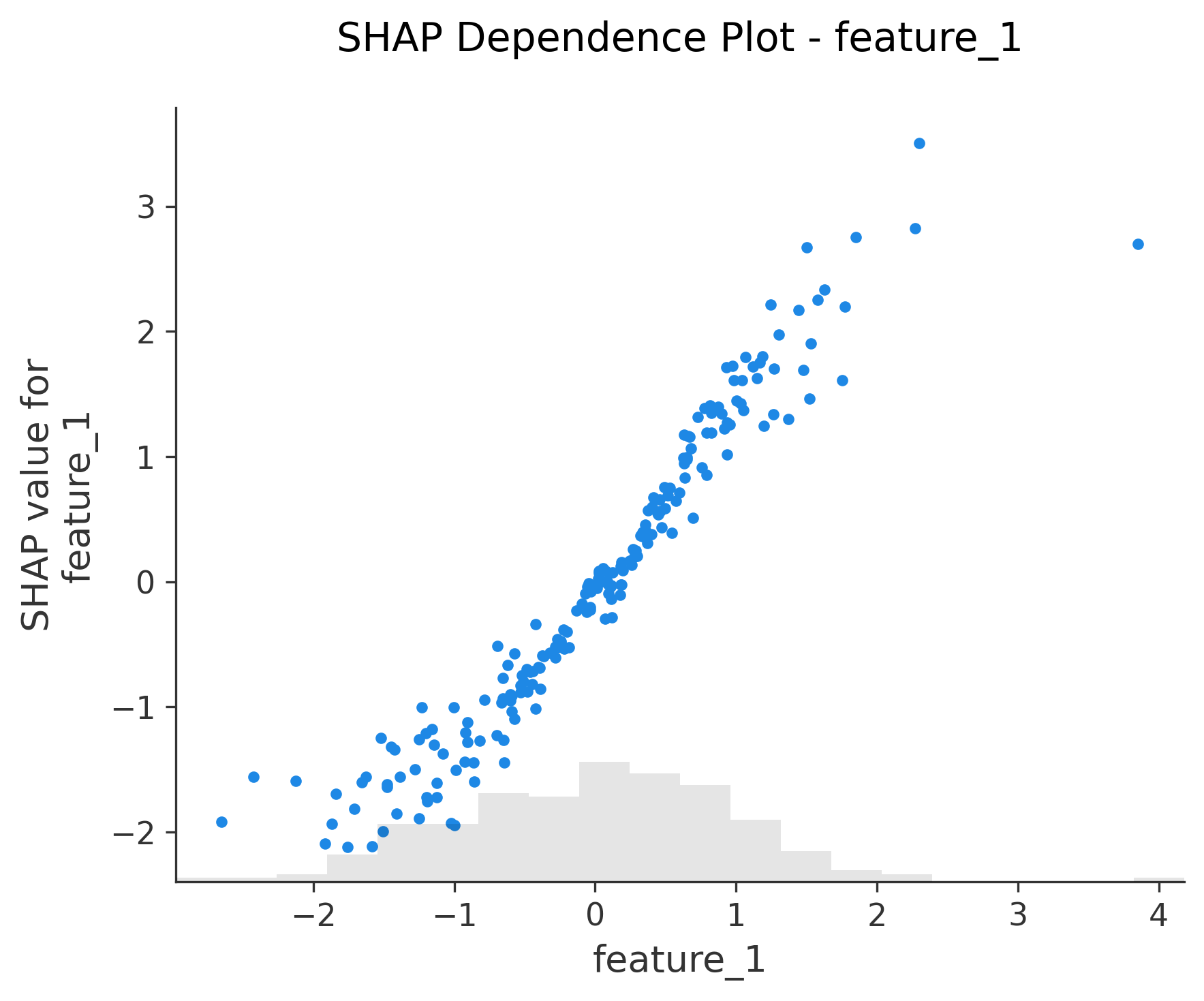
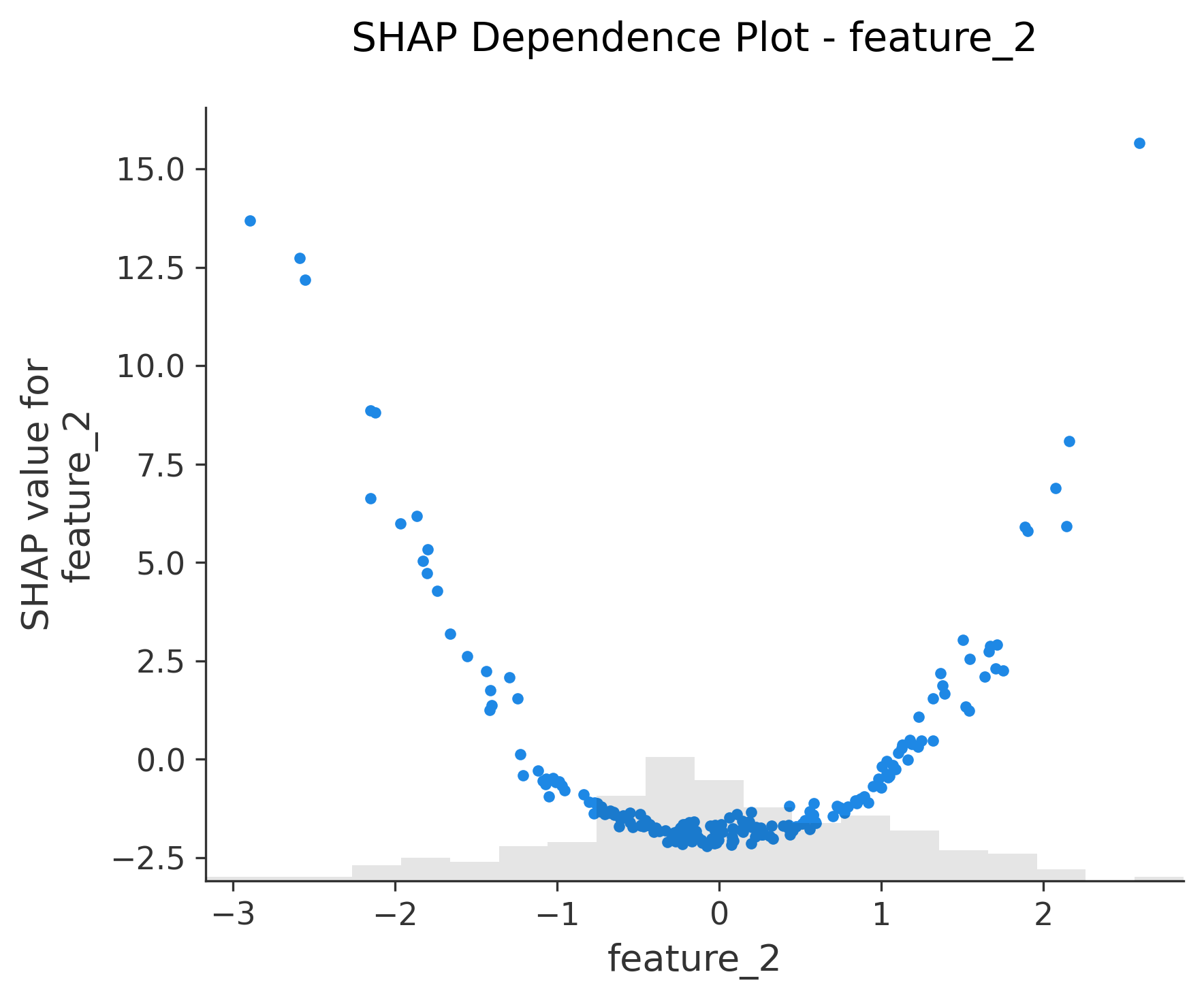
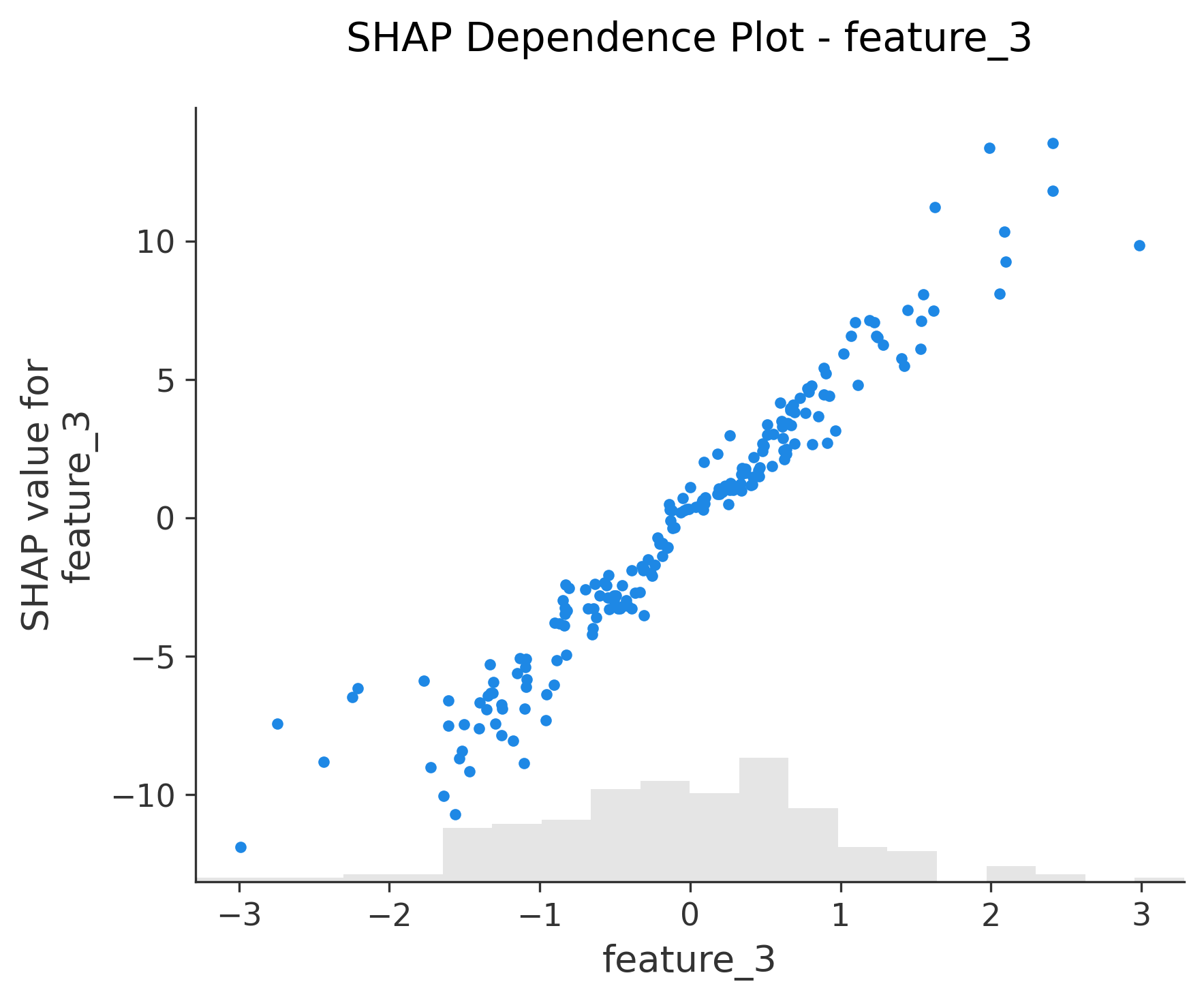
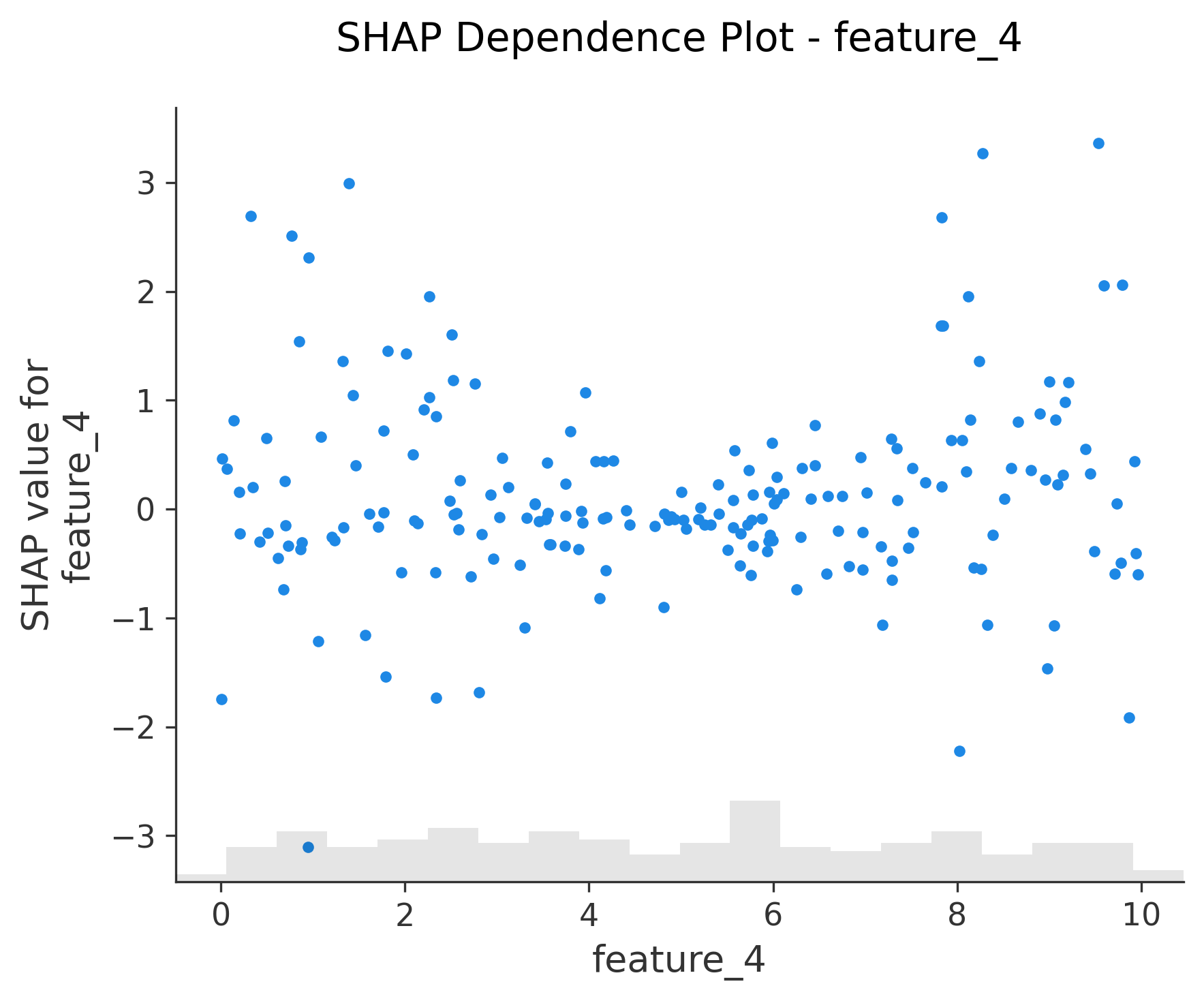
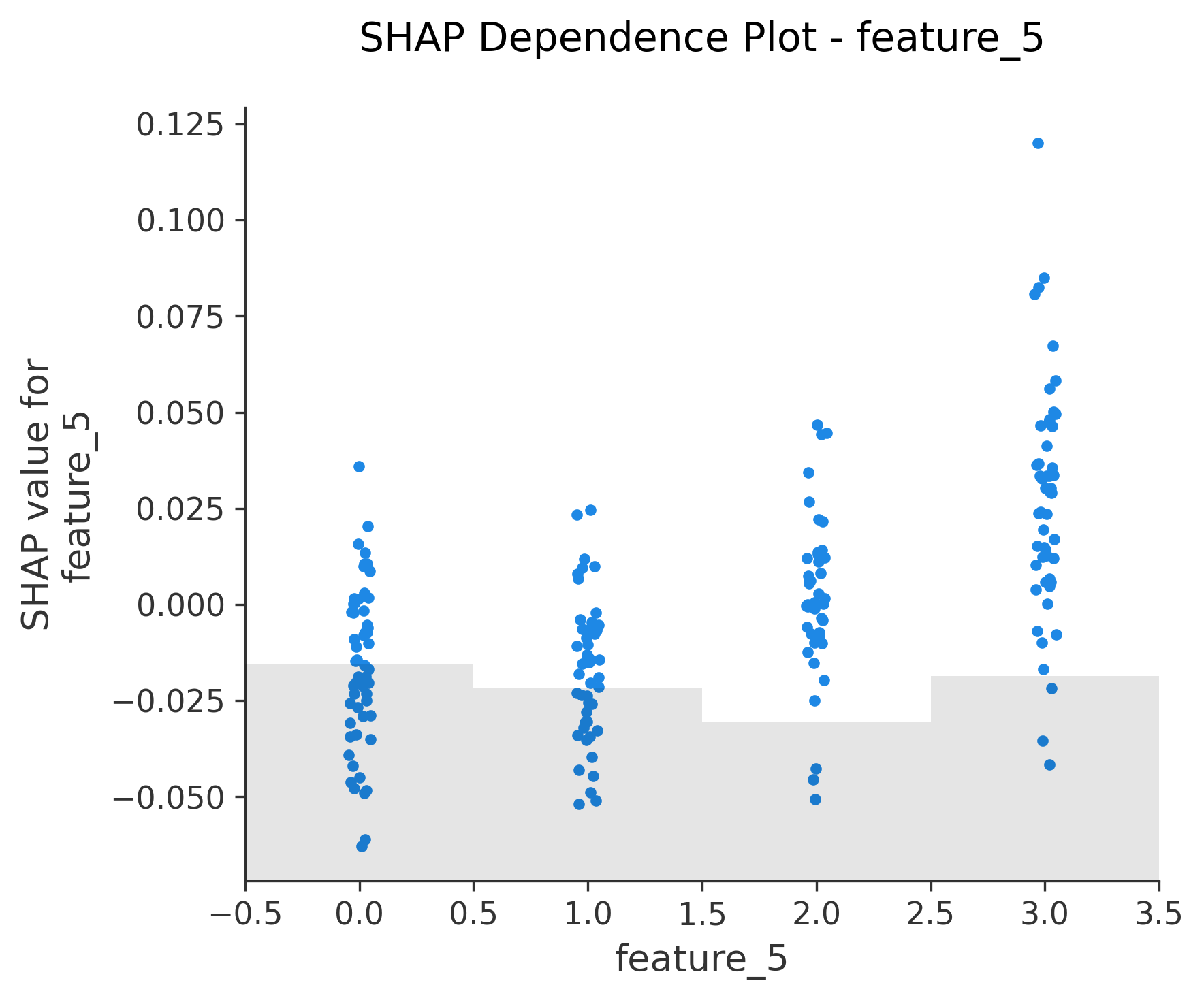
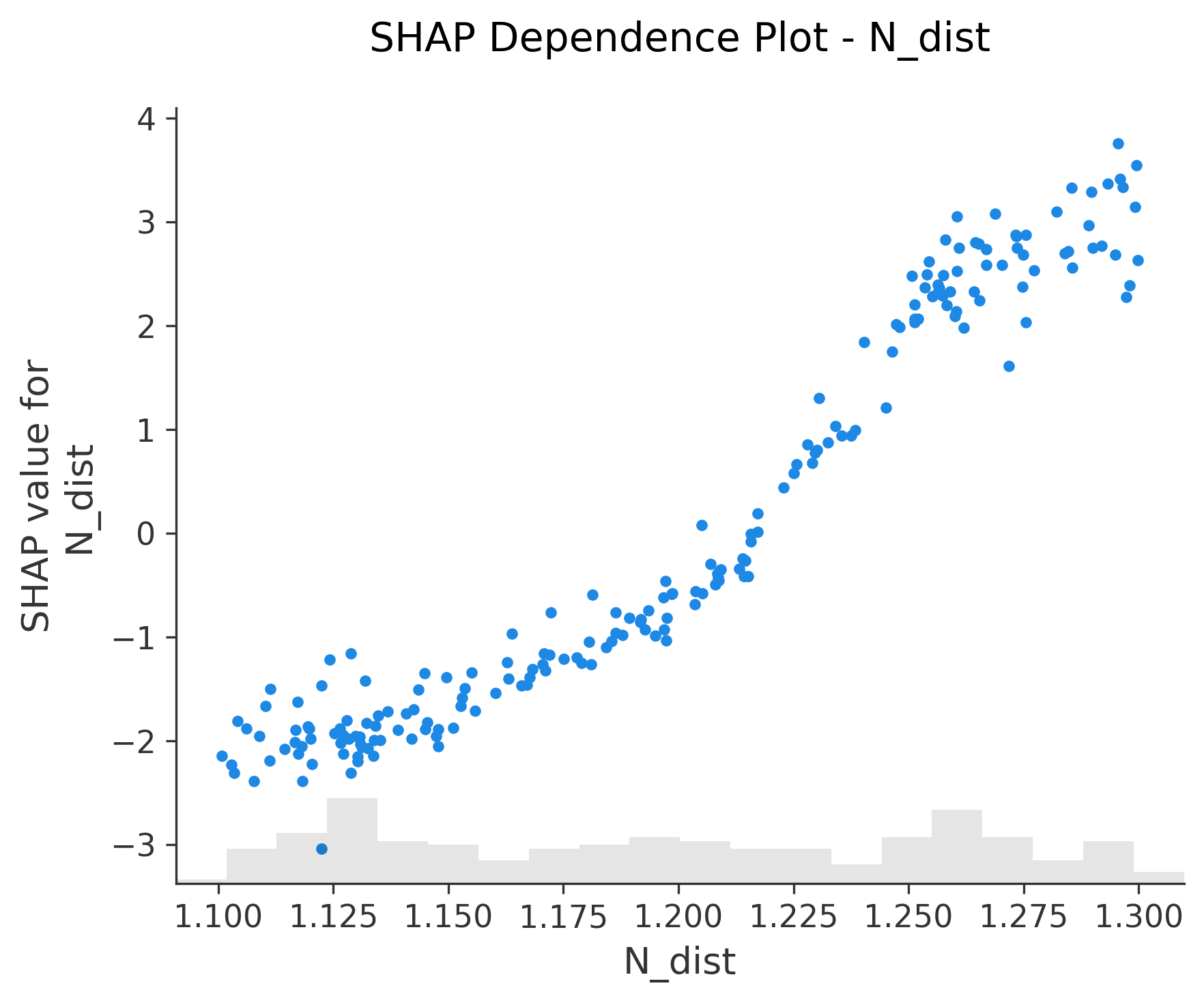
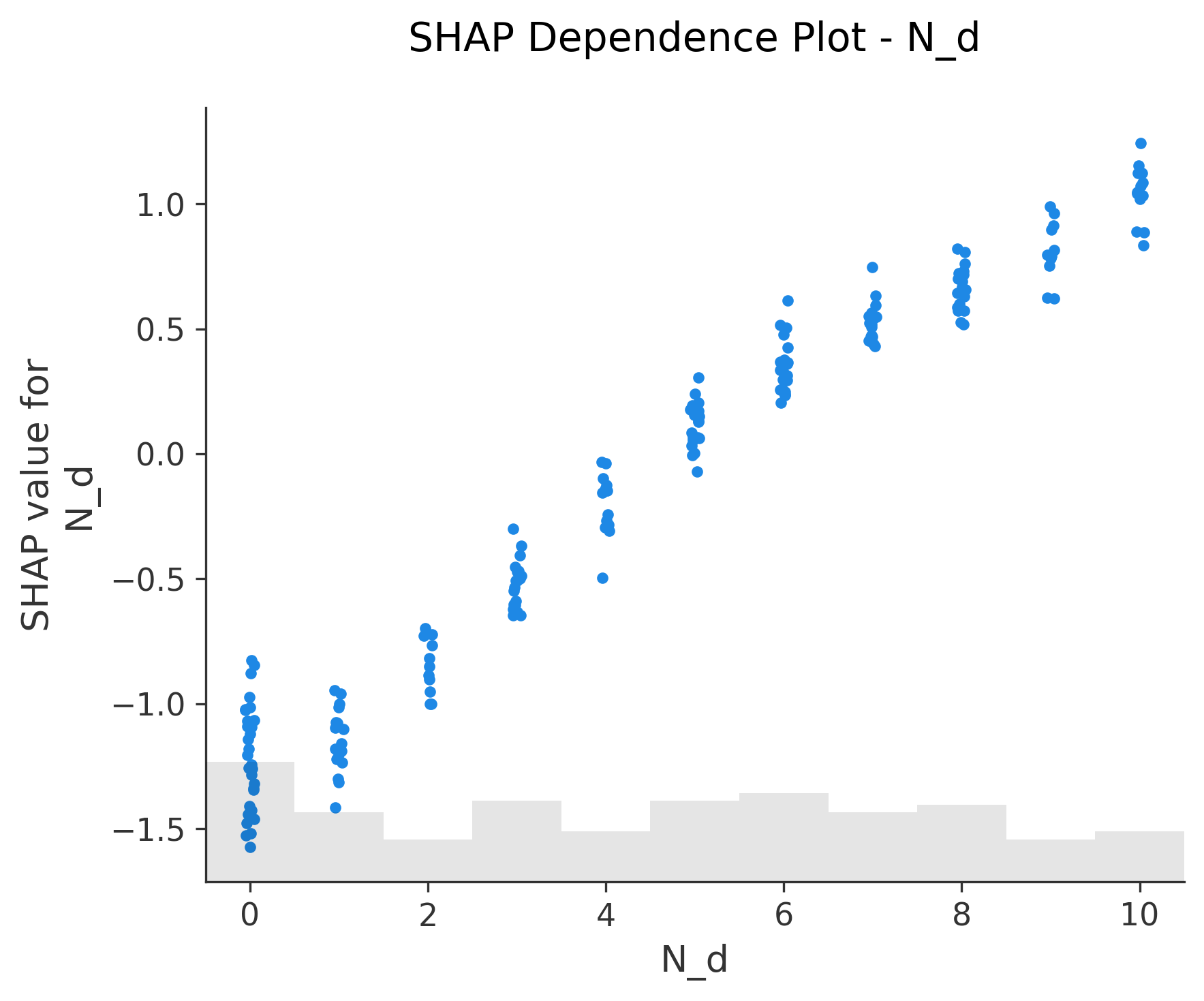
图13-14: 自定义散点图
# 图13: N_dist特征
ax.scatter(X_test['N_dist'].values, shap_values.values[:, feature_idx],c='blue', alpha=0.6)
ax.set_xlabel('N≡N (Å)')
ax.set_ylabel('SHAP value for N≡N')
目的:
- 自定义样式(颜色、标签、格式)
- 适配特定领域需求(如化学、物理)
- 添加参考线、背景色等辅助元素
图14:类似处理离散特征N_d,用红色表示
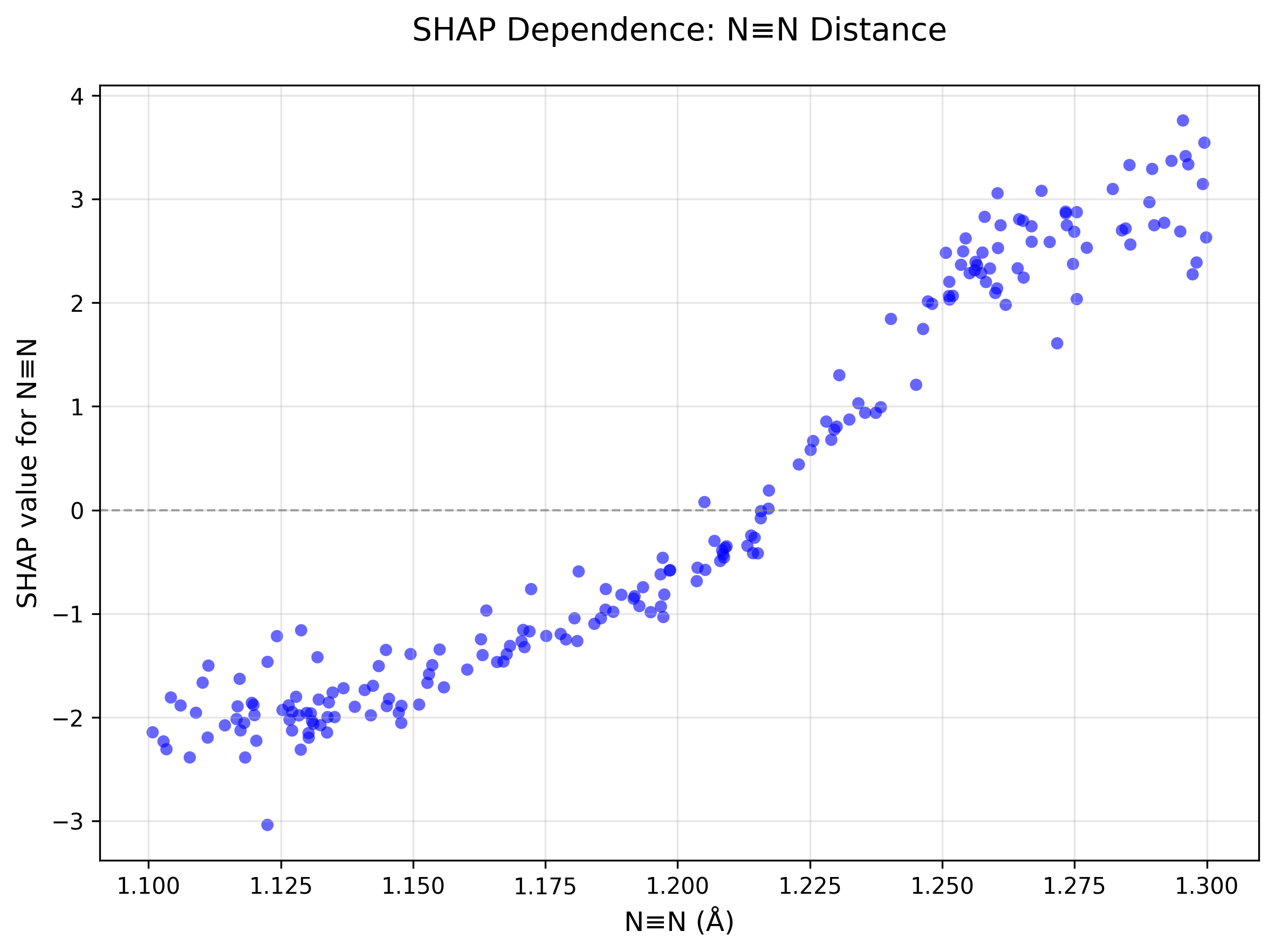
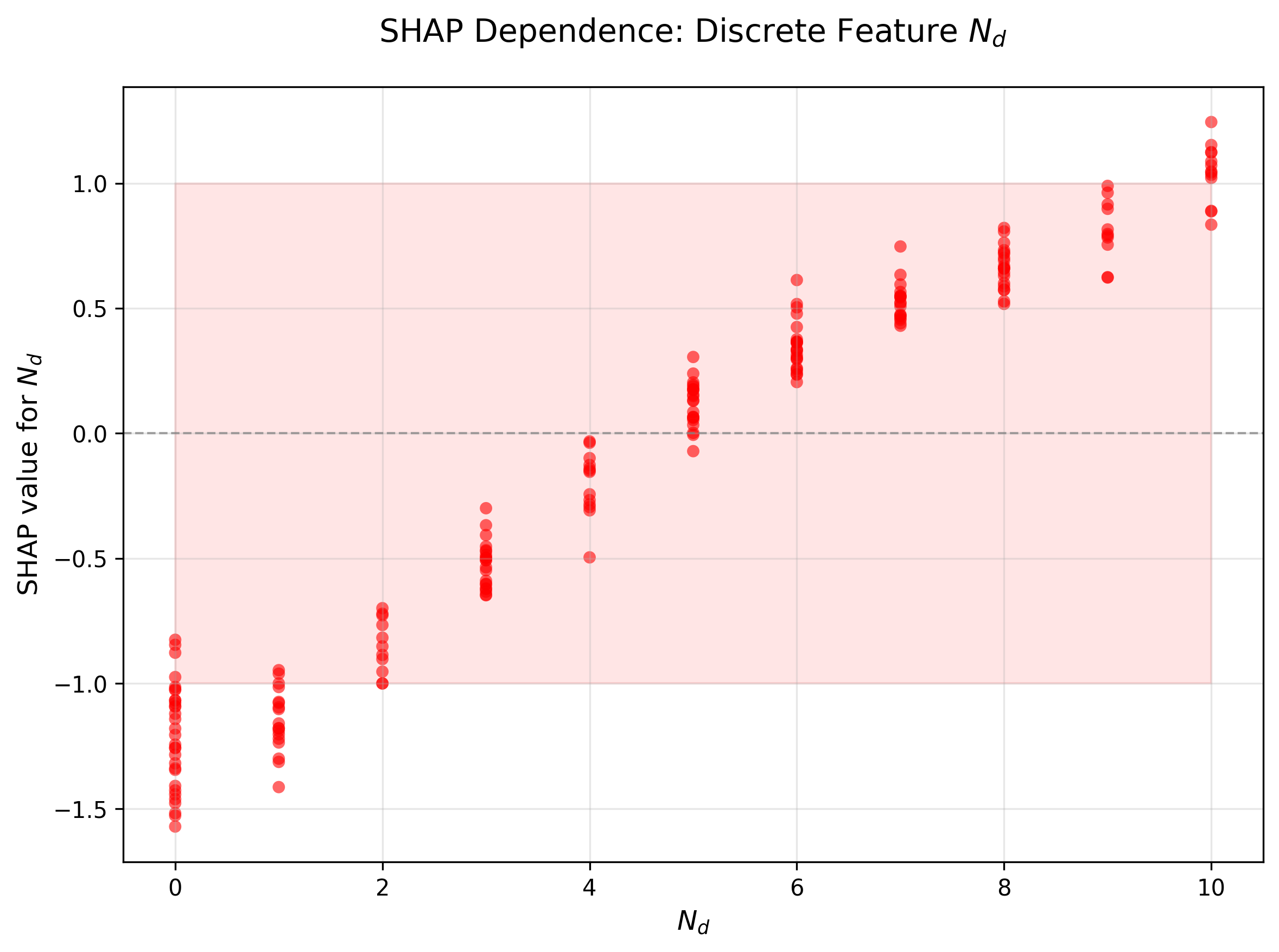
图15: Interaction Scatter Plot
shap.plots.scatter(shap_values[:, "feature_3"],color=shap_values[:, "feature_4"],show=False
)
功能:探索两个特征的交互
- 查看feature_3的SHAP值如何受feature_4影响
- 颜色深浅表示feature_4的SHAP值
应用:发现特征间的协同或拮抗效应
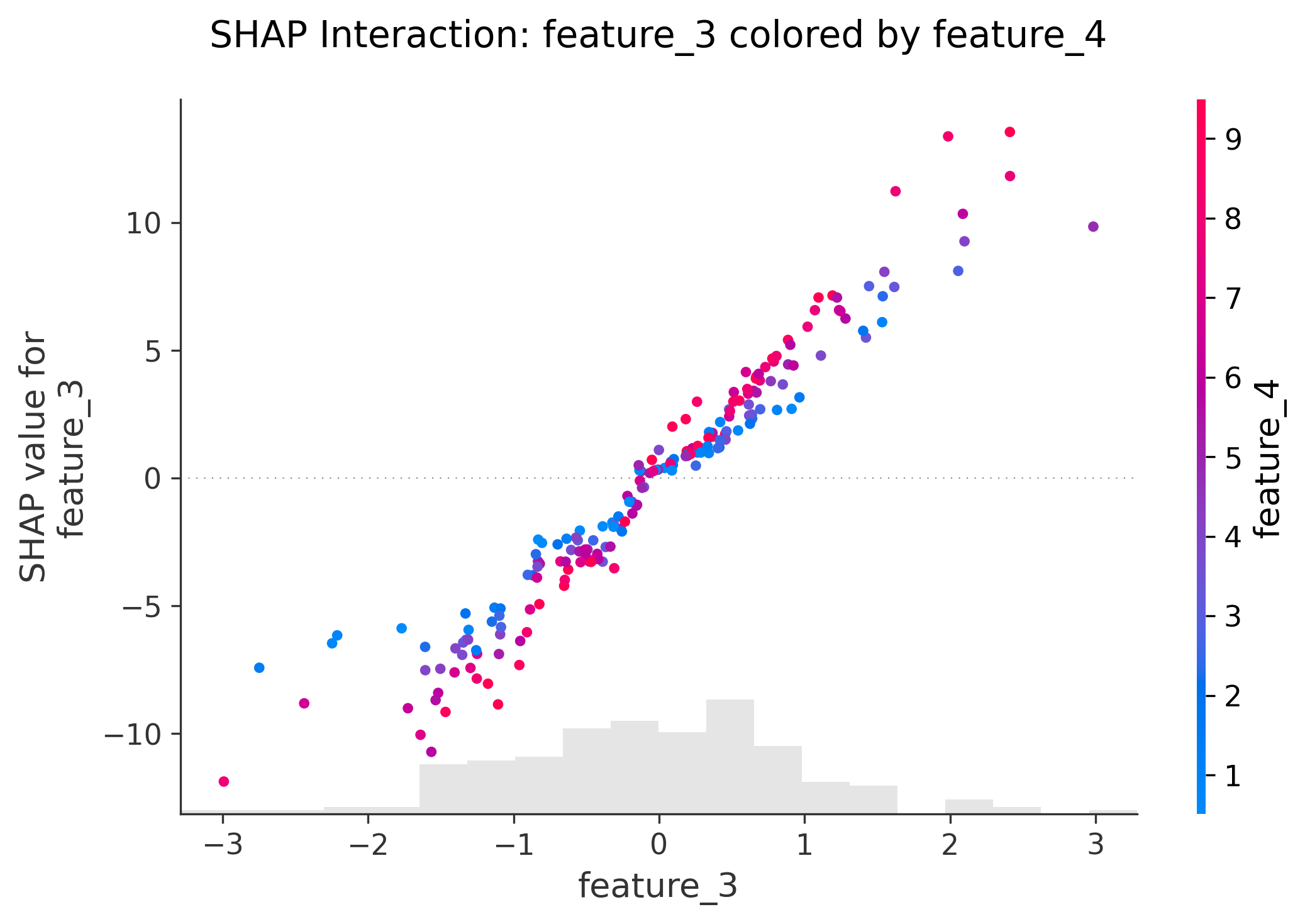
图16: Beeswarm Plot (蜂群图)
shap.plots.beeswarm(shap_values, show=False)
功能:改进版的summary plot
- 更清晰的点分布
- 避免点重叠
- 保留summary plot的所有信息
推荐:替代传统summary plot,视觉效果更好
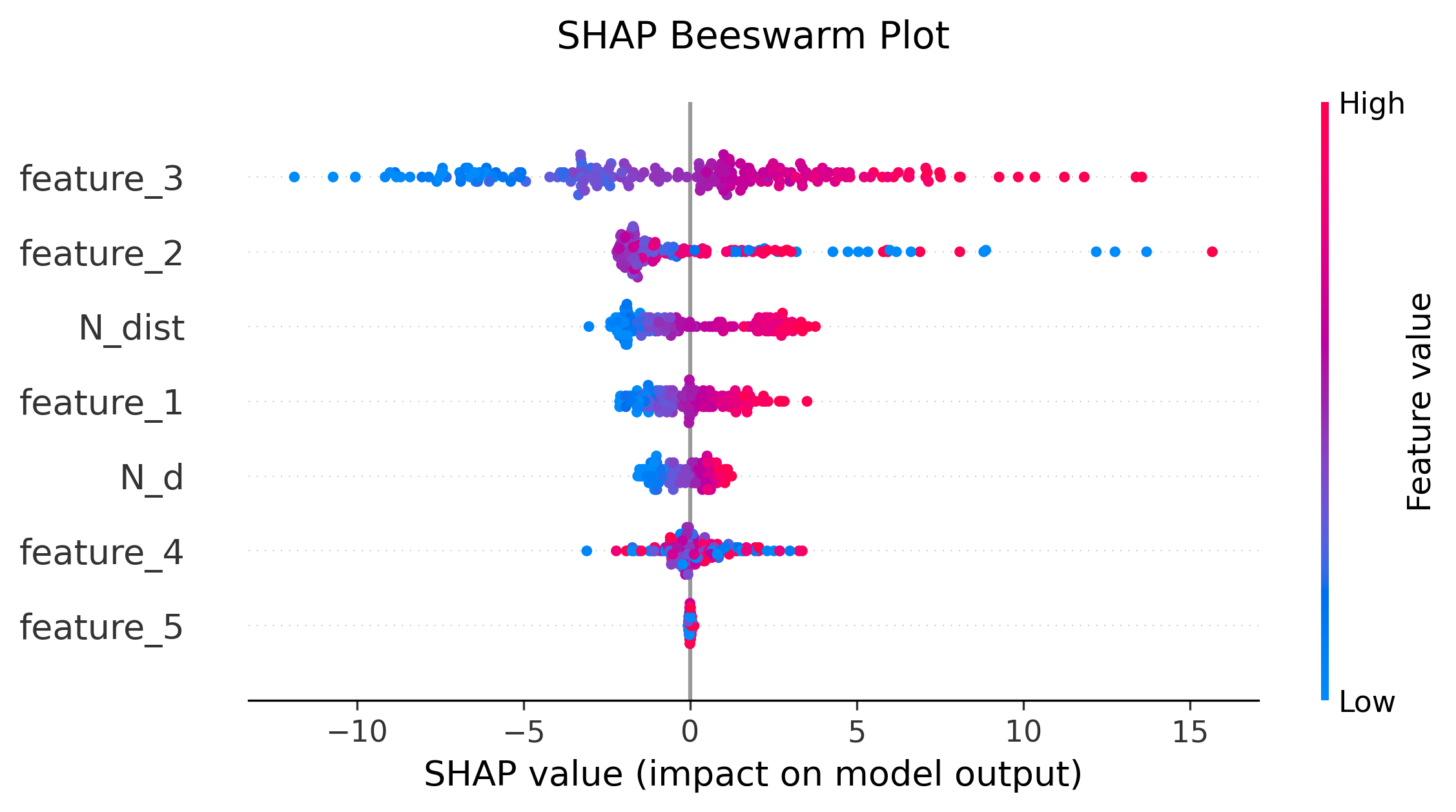
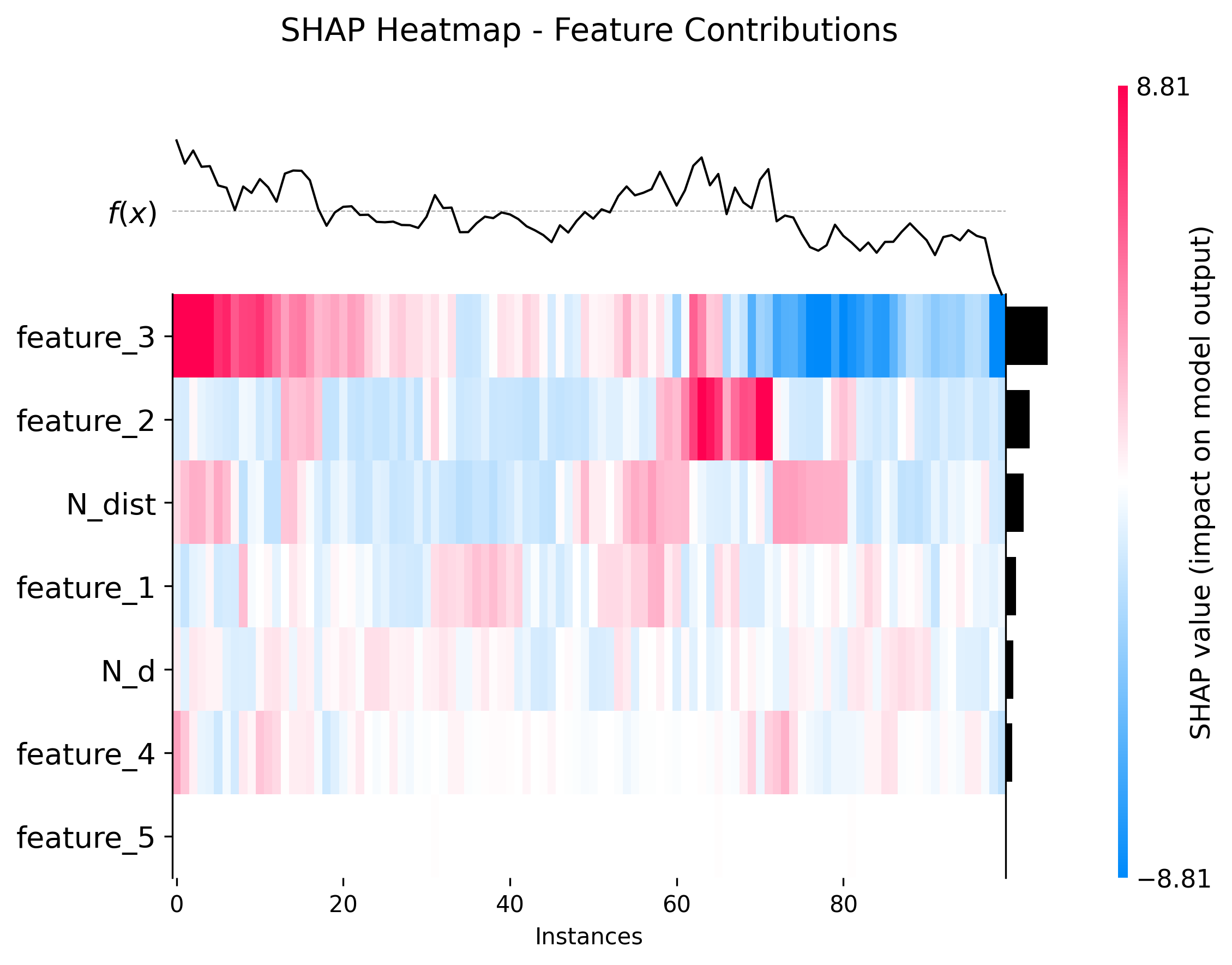
图17: Heatmap Plot (热力图)
shap.plots.heatmap(shap_values[:100], show=False)
功能:样本-特征SHAP值矩阵
- 行:样本
- 列:特征
- 颜色:SHAP值大小
用途:
- 识别样本聚类
- 发现特征模式
- 适合大规模分析
7. 交互特征分析
7.1 计算交互值
shap_interaction_values = explainer.shap_interaction_values(X_test[:100])
注意:
- 计算量大,建议用小样本(这里用100个)
- 返回3D数组:[样本, 特征i, 特征j]
[i, j]位置表示特征i和特征j的交互效应
图18: Interaction Summary
shap.summary_plot(shap_interaction_values[:, :, :],X_test.iloc[:100],show=False
)
功能:交互特征重要性总览
- 显示哪些特征对之间交互最强
- 帮助理解复杂的非线性关系
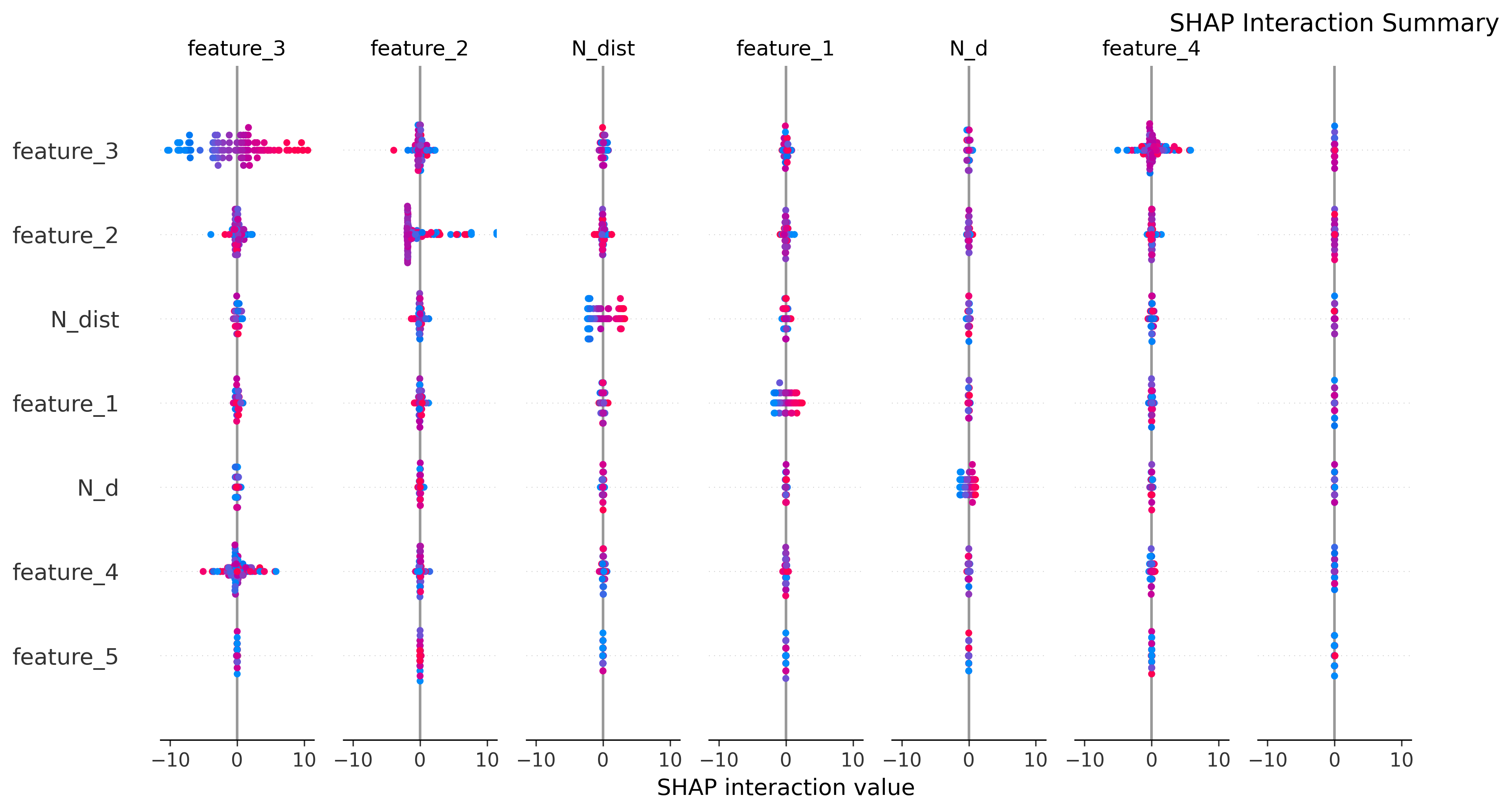
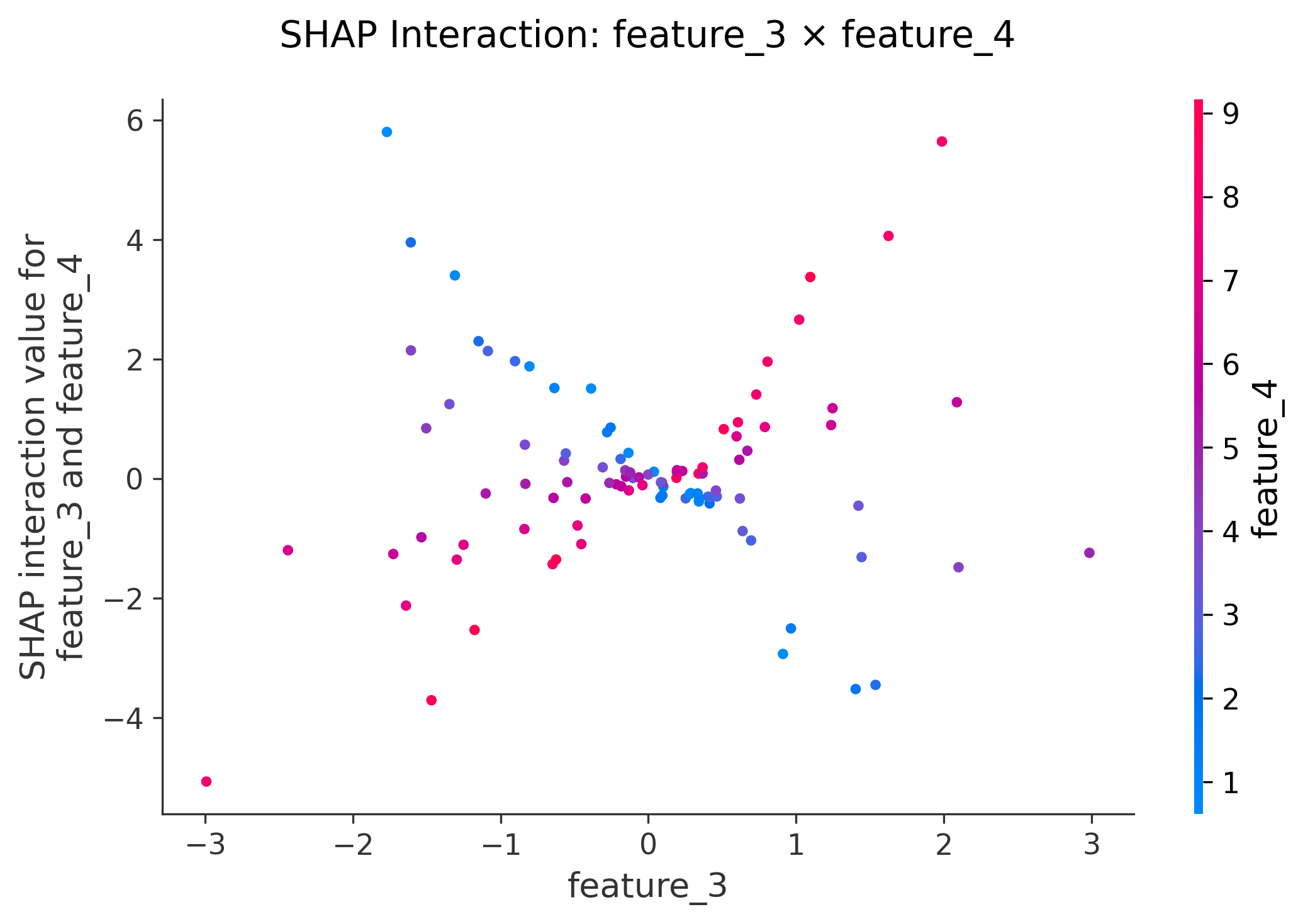
图19: Specific Interaction Dependence
shap.dependence_plot(("feature_3", "feature_4"),shap_interaction_values,X_test.iloc[:100],show=False
)
功能:查看特定特征对的交互
- 专门研究feature_3和feature_4的协同效应
- 验证数据生成时设计的交互关系
8. 总结与应用建议
8.1 核心要点
- SHAP值是可加的:所有特征SHAP值之和 + 基准值 = 预测值
- 公平性:基于博弈论的Shapley值,保证公平分配贡献
- 一致性:如果改变模型使某特征影响增大,其SHAP值绝对值也增大
8.2 图表选择指南
| 目的 | 推荐图表 |
|---|---|
| 整体特征重要性 | Summary Plot / Beeswarm Plot |
| 单个预测解释 | Waterfall Plot / Force Plot |
| 特征-预测关系 | Dependence Plot |
| 多样本比较 | Decision Plot / Heatmap |
| 交互效应探索 | Interaction plots |
8.3 实际应用场景
医疗诊断:解释为什么模型判断某患者高风险
金融风控:说明为什么拒绝某笔贷款申请
推荐系统:展示为什么推荐某商品
科学研究:发现物理/化学变量间的关系
8.4 注意事项
- 计算成本:交互值计算很慢,先用小样本测试
- 模型依赖:TreeExplainer适合树模型,其他模型用KernelExplainer
- 解读谨慎:SHAP显示相关性,不一定是因果关系
- 数据质量:垃圾进垃圾出,确保训练数据质量
8.5 扩展学习
- SHAP官方文档:https://shap.readthedocs.io
- 原始论文:Lundberg & Lee (2017) - “A Unified Approach to Interpreting Model Predictions”
- 进阶:SHAP在深度学习中的应用(DeepExplainer)
代码运行要求
# 安装依赖
pip install numpy pandas matplotlib scikit-learn shap# 运行代码
python shap画图.py# 输出结果
# - 19张PNG图片
# - 控制台统计信息
预期输出时间:1-3分钟(取决于硬件配置)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import shap# 设置随机种子
np.random.seed(42)# ==================== 1. 生成模拟数据 ====================
n_samples = 1000# 创建特征
X = pd.DataFrame({'feature_1': np.random.randn(n_samples),'feature_2': np.random.randn(n_samples),'feature_3': np.random.randn(n_samples),'feature_4': np.random.uniform(0, 10, n_samples),'feature_5': np.random.choice([0, 1, 2, 3], n_samples), # 分类变量'N_dist': np.random.uniform(1.10, 1.30, n_samples), # 类似附件(c)图的距离特征'N_d': np.random.choice(range(11), n_samples) # 类似附件(d)图的离散特征
})# 创建目标变量(带有非线性关系和交互效应)
y = (2 * X['feature_1'] +3 * X['feature_2']**2 +X['feature_3'] * X['feature_4'] + # 交互效应np.sin(X['N_dist'] * 10) * 5 +X['N_d'] * 0.5 +np.random.randn(n_samples) * 0.5)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42
)# ==================== 2. 训练随机森林模型 ====================
print("训练随机森林模型...")
rf_model = RandomForestRegressor(n_estimators=100,max_depth=10,random_state=42,n_jobs=-1
)
rf_model.fit(X_train, y_train)print(f"训练集 R² Score: {rf_model.score(X_train, y_train):.4f}")
print(f"测试集 R² Score: {rf_model.score(X_test, y_test):.4f}")# ==================== 3. 计算SHAP值 ====================
print("\n计算SHAP值...")
# 使用TreeExplainer(专为树模型优化)
explainer = shap.TreeExplainer(rf_model)
shap_values = explainer(X_test)# ==================== 4. 绘制所有SHAP图 ====================
plt.style.use('default')# ------------------------ 图1: Summary Plot (点图) ------------------------
print("\n绘制图1: Summary Plot (特征重要性概览)...")
plt.figure(figsize=(10, 6))
shap.summary_plot(shap_values, X_test, show=False)
plt.title("SHAP Summary Plot - Feature Importance Overview", fontsize=14, pad=20)
plt.tight_layout()
plt.savefig('shap_1_summary_plot.png', dpi=300, bbox_inches='tight')
plt.show()# ------------------------ 图2: Summary Plot (柱状图) ------------------------
print("绘制图2: Summary Plot (平均绝对SHAP值)...")
plt.figure(figsize=(10, 6))
shap.summary_plot(shap_values, X_test, plot_type="bar", show=False)
plt.title("SHAP Summary Plot - Mean Absolute SHAP Values", fontsize=14, pad=20)
plt.tight_layout()
plt.savefig('shap_2_summary_bar.png', dpi=300, bbox_inches='tight')
plt.show()# ------------------------ 图3: Waterfall Plot (单样本) ------------------------
print("绘制图3: Waterfall Plot (单个预测解释)...")
plt.figure(figsize=(10, 6))
shap.plots.waterfall(shap_values[0], show=False)
plt.title("SHAP Waterfall Plot - Single Prediction Explanation", fontsize=14, pad=20)
plt.tight_layout()
plt.savefig('shap_3_waterfall.png', dpi=300, bbox_inches='tight')
plt.show()# ------------------------ 图4: Force Plot (单样本) ------------------------
print("绘制图4: Force Plot (单个预测)...")
plt.figure(figsize=(14, 3))
shap.plots.force(shap_values[0], matplotlib=True, show=False)
plt.title("SHAP Force Plot - Single Prediction", fontsize=14, pad=20)
plt.tight_layout()
plt.savefig('shap_4_force_plot.png', dpi=300, bbox_inches='tight')
plt.show()# ------------------------ 图5: Decision Plot ------------------------
print("绘制图5: Decision Plot (多个样本决策路径)...")
plt.figure(figsize=(10, 8))
shap.decision_plot(explainer.expected_value,shap_values.values[:50],X_test.iloc[:50],show=False
)
plt.title("SHAP Decision Plot - Multiple Predictions", fontsize=14, pad=20)
plt.tight_layout()
plt.savefig('shap_5_decision_plot.png', dpi=300, bbox_inches='tight')
plt.show()# ------------------------ 图6-12: Dependence Plot (每个特征) ------------------------
print("绘制图6-12: Dependence Plots (单特征依赖图)...")
for i, feature in enumerate(X_test.columns):plt.figure(figsize=(10, 6))shap.plots.scatter(shap_values[:, feature], show=False)plt.title(f"SHAP Dependence Plot - {feature}", fontsize=14, pad=20)plt.tight_layout()plt.savefig(f'shap_6_{i}_dependence_{feature}.png', dpi=300, bbox_inches='tight')plt.show()# ------------------------ 图13: 自定义散点图 ------------------------
print("绘制图13: 自定义散点图")
fig, ax = plt.subplots(figsize=(8, 6))# 获取N_dist特征的索引
feature_idx = list(X_test.columns).index('N_dist')# 绘制散点图
scatter = ax.scatter(X_test['N_dist'].values,shap_values.values[:, feature_idx],c='blue',alpha=0.6,s=30,edgecolors='none'
)# 添加参考线
ax.axhline(y=0, color='gray', linestyle='--', linewidth=1, alpha=0.7)# 设置标签和标题
ax.set_xlabel('N≡N (Å)', fontsize=12)
ax.set_ylabel('SHAP value for N≡N', fontsize=12)
ax.set_title('SHAP Dependence: N≡N Distance', fontsize=14, pad=20)
ax.grid(True, alpha=0.3)plt.tight_layout()
plt.savefig('shap_13_custom_N_dist.png', dpi=300, bbox_inches='tight')
plt.show()# ------------------------ 图14: 自定义散点图 ------------------------
print("绘制图14: 自定义散点图")
fig, ax = plt.subplots(figsize=(8, 6))# 获取N_d特征的索引
feature_idx = list(X_test.columns).index('N_d')# 绘制散点图
scatter = ax.scatter(X_test['N_d'].values,shap_values.values[:, feature_idx],c='red',alpha=0.6,s=30,edgecolors='none'
)# 添加参考线
ax.axhline(y=0, color='gray', linestyle='--', linewidth=1, alpha=0.7)# 添加背景色渐变(可选)
ax.fill_between([X_test['N_d'].min(), X_test['N_d'].max()],-1, 1,alpha=0.1,color='red'
)# 设置标签和标题
ax.set_xlabel('$N_d$', fontsize=12)
ax.set_ylabel('SHAP value for $N_d$', fontsize=12)
ax.set_title('SHAP Dependence: Discrete Feature $N_d$', fontsize=14, pad=20)
ax.grid(True, alpha=0.3)plt.tight_layout()
plt.savefig('shap_14_custom_N_d.png', dpi=300, bbox_inches='tight')
plt.show()# ------------------------ 图15: Interaction Scatter Plot ------------------------
print("绘制图15: 交互特征散点图...")
# 选择两个可能有交互的特征
fig, ax = plt.subplots(figsize=(10, 6))
shap.plots.scatter(shap_values[:, "feature_3"],color=shap_values[:, "feature_4"],show=False
)
plt.title("SHAP Interaction: feature_3 colored by feature_4", fontsize=14, pad=20)
plt.tight_layout()
plt.savefig('shap_15_interaction_scatter.png', dpi=300, bbox_inches='tight')
plt.show()# ------------------------ 图16: Beeswarm Plot ------------------------
print("绘制图16: Beeswarm Plot...")
plt.figure(figsize=(10, 6))
shap.plots.beeswarm(shap_values, show=False)
plt.title("SHAP Beeswarm Plot", fontsize=14, pad=20)
plt.tight_layout()
plt.savefig('shap_16_beeswarm.png', dpi=300, bbox_inches='tight')
plt.show()# ------------------------ 图17: Heatmap Plot ------------------------
print("绘制图17: Heatmap Plot...")
plt.figure(figsize=(12, 8))
shap.plots.heatmap(shap_values[:100], show=False)
plt.title("SHAP Heatmap - Feature Contributions", fontsize=14, pad=20)
plt.tight_layout()
plt.savefig('shap_17_heatmap.png', dpi=300, bbox_inches='tight')
plt.show()# ==================== 5. 交互特征分析 ====================
print("\n计算SHAP交互值(这可能需要一些时间)...")
# 注意:交互值计算较慢,建议使用较小的样本集
shap_interaction_values = explainer.shap_interaction_values(X_test[:100])# ------------------------ 图18: Interaction Summary ------------------------
print("绘制图18: 交互特征重要性汇总...")
plt.figure(figsize=(10, 8))
shap.summary_plot(shap_interaction_values[:, :, :],X_test.iloc[:100],show=False
)
plt.title("SHAP Interaction Summary", fontsize=14, pad=20)
plt.tight_layout()
plt.savefig('shap_18_interaction_summary.png', dpi=300, bbox_inches='tight')
plt.show()# ------------------------ 图19: Specific Interaction Dependence ------------------------
print("绘制图19: 特定交互依赖图...")
# 查看feature_3和feature_4的交互
fig, ax = plt.subplots(figsize=(10, 6))
shap.dependence_plot(("feature_3", "feature_4"),shap_interaction_values,X_test.iloc[:100],show=False
)
plt.title("SHAP Interaction: feature_3 × feature_4", fontsize=14, pad=20)
plt.tight_layout()
plt.savefig('shap_19_specific_interaction.png', dpi=300, bbox_inches='tight')
plt.show()# ==================== 6. 打印统计信息 ====================
print("\n" + "="*60)
print("SHAP分析统计信息")
print("="*60)
print(f"样本数量: {len(X_test)}")
print(f"特征数量: {X_test.shape[1]}")
print(f"基准值 (Expected Value): {explainer.expected_value:.4f}")
print("\n特征SHAP值统计:")
print("-"*60)for i, feature in enumerate(X_test.columns):mean_abs_shap = np.mean(np.abs(shap_values.values[:, i]))print(f"{feature:15s} - 平均绝对SHAP值: {mean_abs_shap:.4f}")print("\n所有SHAP图已生成完毕!")
print("="*60)