LLM学习笔记5——本地部署ComfyUI和Wan2.1-T2V-1.3B文生视频模型
系列文章目录
参考博客
文章目录
- 系列文章目录
- 前言
- 一、ComfyUI安装
- 二、Wan2.1-T2V-1.3B下载
- 1、使用hfd下载器
- 三、clip_vision下载
- 四、text_encoders下载
- 五、vae下载
- 六、工作流下载
- 七、启用ComfyUI
- 总结
前言
ComfyUI 是一个基于节点的 GUI,为 Stable Diffusion 等工作提供了一种更加直观、灵活的方式来操作和管理生成的过程。通过将不同的模块节点组合在一起,可以构建一个图像生成的工作流。就像有一块数字画布,可以通过连接不同的节点来构建自己独特的图像生成工作流,每个节点代表一个特定的功能或操作。
Wan模型是阿里开源的系列视频生成模型,主要基于主流扩散变换器范式,通过新型时空变分自编码器、可扩展预训练策略、大规模数据整理及自动化评估指标等创新,提升了生成能力。Wan具有卓越性能、全面性、消费者级效率和开放性四大特性,其14B参数模型在多基准测试中显著优于现有开源和商业模型,还支持多任务应用,如多种视频生成及编辑等。为提高效率,Wan有1.3B参数的小型版本,适合消费级GPU。此外,Wan是首个能生成中英文视觉文本的模型,实用价值高。论文详细分析了模型设计、训练策略、加速技术和评估方法,并公开训练过程及代码,以推动视频生成技术进步。

一、ComfyUI安装
使用anaconda创建一个独立的虚拟环境:
conda create -n comfyui python=3.10
下载ComfyUI工具:
ComfyUI github地址
解压ComfyUI压缩包并进入ComfyUI文件夹内,打开requirements.txt文件可以看见ComfyUI的依赖库:
comfyui-frontend-package==1.26.13
comfyui-workflow-templates==0.1.81
comfyui-embedded-docs==0.2.6
torch
torchsde
torchvision
torchaudio
numpy>=1.25.0
einops
transformers>=4.37.2
tokenizers>=0.13.3
sentencepiece
safetensors>=0.4.2
aiohttp>=3.11.8
yarl>=1.18.0
pyyaml
Pillow
scipy
tqdm
psutil
alembic
SQLAlchemy
av>=14.2.0#non essential dependencies:
kornia>=0.7.1
spandrel
soundfile
pydantic~=2.0
pydantic-settings~=2.0
对于torch、torchsde、torchvision和torchaudio库可以选择自己手动在虚拟环境中安装,目的是为了明确版本:
cuda 12.1
pytorch 2.5.0
torchaudio 2.5.0
torchsde 0.2.6
torchvision 0.20.0
可以到清华镜像下载对应版本的pytorch包,然后使用以下命令安装:
conda install --offline xxx.tar.bz2
pyav库也可以手动安装,因为使用requirements.txt安装可能会出现以下问题:
error: command '/usr/bin/gcc' failed with exit code 1
[end of output]note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for av
Failed to build av
error: failed-wheel-build-for-install
× Failed to build installable wheels for some pyproject.toml based projects
╰─> av
在虚拟环境中直接使用以下命令安装pyav库:
pip install av==14.2.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
安装完成后,记得在requirements.txt文件中把这几个库注释或者删除,避免重新安装和覆盖:
#torch
#torchsde
#torchvision
#torchaudio
#av>=14.2.0
最后在虚拟环境中直接使用以下命令调用requirements.txt文件安装依赖库:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
安装完成后调用以下命令启动ComfyUI工作流:
python main.py --port 15070 --listen 0.0.0.0
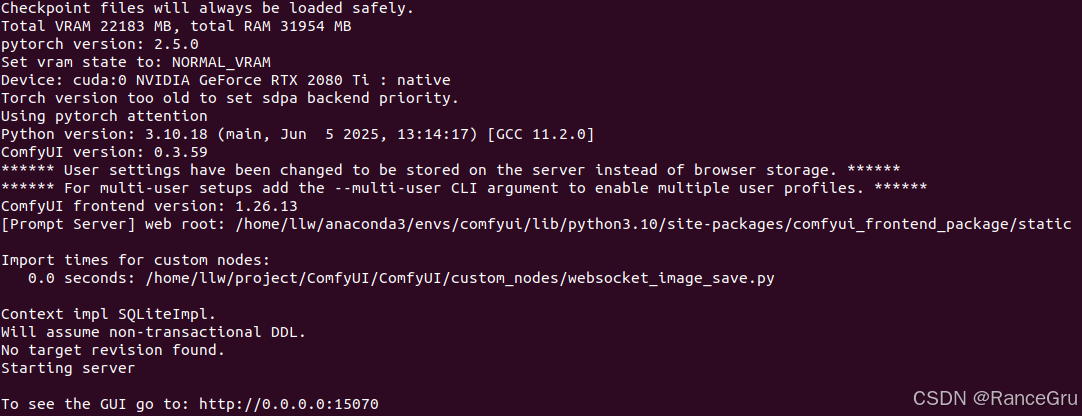
启动成功后,在浏览器访问以下端口:
http://0.0.0.0:15070/
重复启停可能会出现以下报错,尝试启动服务的端口(15070)已被其他进程占用。
error while attempting to bind on address ('0.0.0.0', 15070): address already in use
使用以下命令查看对应15070端口的进程的PID值:
sudo lsof -i :15070

使用终止占用进程命令:
sudo kill -9 <PID>
二、Wan2.1-T2V-1.3B下载
Hugging Face是当前最受欢迎的 AI 模型平台,包含了诸如 LLaMA、GPT、SAM、Diffusers 等前沿模型。但由于其服务器在海外,国内下载 Huggingface 模型经常出现断连、超时、龟速等问题,严重影响开发效率。
所以国内下载模型可以使用HF-Mirror和modelscope。
之前使用了魔搭下载模型,速度很快,这是尝试用HF-Mirror下载模型。
HF-Mirror是一个由国内开发者维护的公益Hugging Face镜像服务站,支持以下特性:
✅ 提供稳定、快速的模型与数据集下载;
✅ 支持 huggingface-cli 命令行;
✅ 支持环境变量无侵入式加速;
✅ 提供基于 aria2 的高速下载工具 hfd;
✅ 支持 Gated Repo 的 token 下载。
1、使用hfd下载器
hfd下载器是HF-Mirror提供的轻量级模型下载脚本,底层基于 aria2 支持断点续传和多线程,非常适合下载大模型。
使用wget命令拉取hfd工具:
wget https://hf-mirror.com/hfd/hfd.sh
修改hfd工具的使用权限:
chmod +x hfd.sh
设置环境变量:
gedit ~/.bashrc
# 在文件最后面写入
export HF_ENDPOINT=https://hf-mirror.com
source ~/.bashrc
使用以下命令下载模型:
./hfd.sh Wan-AI/Wan2.1-T2V-1.3B --local-dir /home/xxx/ComfyUI/models/diffusion_models
hfd下载器以及它底层依赖的aria2都具备强大的断点续传功能,下载中断后是可以恢复的。
如果出现下载中断或者失败的情况,可以直接重新运行之前的下载命令,aria2会自动检查之前已经部分下载的文件,然后从中断的地方继续下载,而不会从头开始。
如果有好的梯子那就直接使用Hugging Face,如果没有梯子那就使用modelscope,如果没有梯子且modelscope也没有该模型那就使用hfd下载器和HF-Mirror。
下载到本地后,移到ComfyUI\models\diffusion_models目录下。
三、clip_vision下载
使用国内的modelscope网站进行下载,Wan_2.1_ComfyUI_repackaged下载地址,可以使用命令下载,也可以直接在网站上下载。
Wan_2.1_ComfyUI_repackaged/split_files/clip_vision/clip_vision_h.safetensors
下载到本地后,移到ComfyUI\models\clip_vision目录下。
四、text_encoders下载
Wan_2.1_ComfyUI_repackaged/split_files/text_encoders/umt5_xxl_fp16.safetensors
Wan_2.1_ComfyUI_repackaged/split_files/text_encoders/umt5_xxl_fp8_e4m3fn_scaled.safetensors
如果显存 > 12G,选择fp16下载。
如果显存 < 12G,选择fp8下载。
下载到本地后,移到ComfyUI\models\text_encoders目录下。
五、vae下载
Wan_2.1_ComfyUI_repackaged/split_files/vae/wan_2.1_vae.safetensors
Wan_2.1_ComfyUI_repackaged/split_files/vae/wan_alpha_2.1_vae_alpha_channel.safetensors
Wan_2.1_ComfyUI_repackaged/split_files/vae/wan_alpha_2.1_vae_rgb_channel.safetensors
下载到本地后,移到ComfyUI\models\vae目录下。
六、工作流下载
Wan_2.1_ComfyUI_repackaged/example workflows_Wan2.1/image_to_video_wan_480p_example.json
Wan_2.1_ComfyUI_repackaged/example workflows_Wan2.1/image_to_video_wan_720p_example.json
Wan_2.1_ComfyUI_repackaged/example workflows_Wan2.1/text_to_video_wan.json
下载到本地后,移到ComfyUI\user\default\workflows目录下。
七、启用ComfyUI
打开终端,进入虚拟环境,调用以下命令启动ComfyUI工作流:
python main.py --port 15070 --listen 0.0.0.0
启动成功后,在浏览器访问以下端口:
http://0.0.0.0:15070/
打开左侧工具栏,选择工具流选项,选择对应文生视频工具流,比如text_to_video_wan.json工具流。
在不同加载器中手动选择正确的模型,比如:
CLIP:umt5 xxl fp16.safetensors
UNet:wan2.1 t2v 1.3B_e20.safetensors
VAE:wan 2.1 vae.safetensors
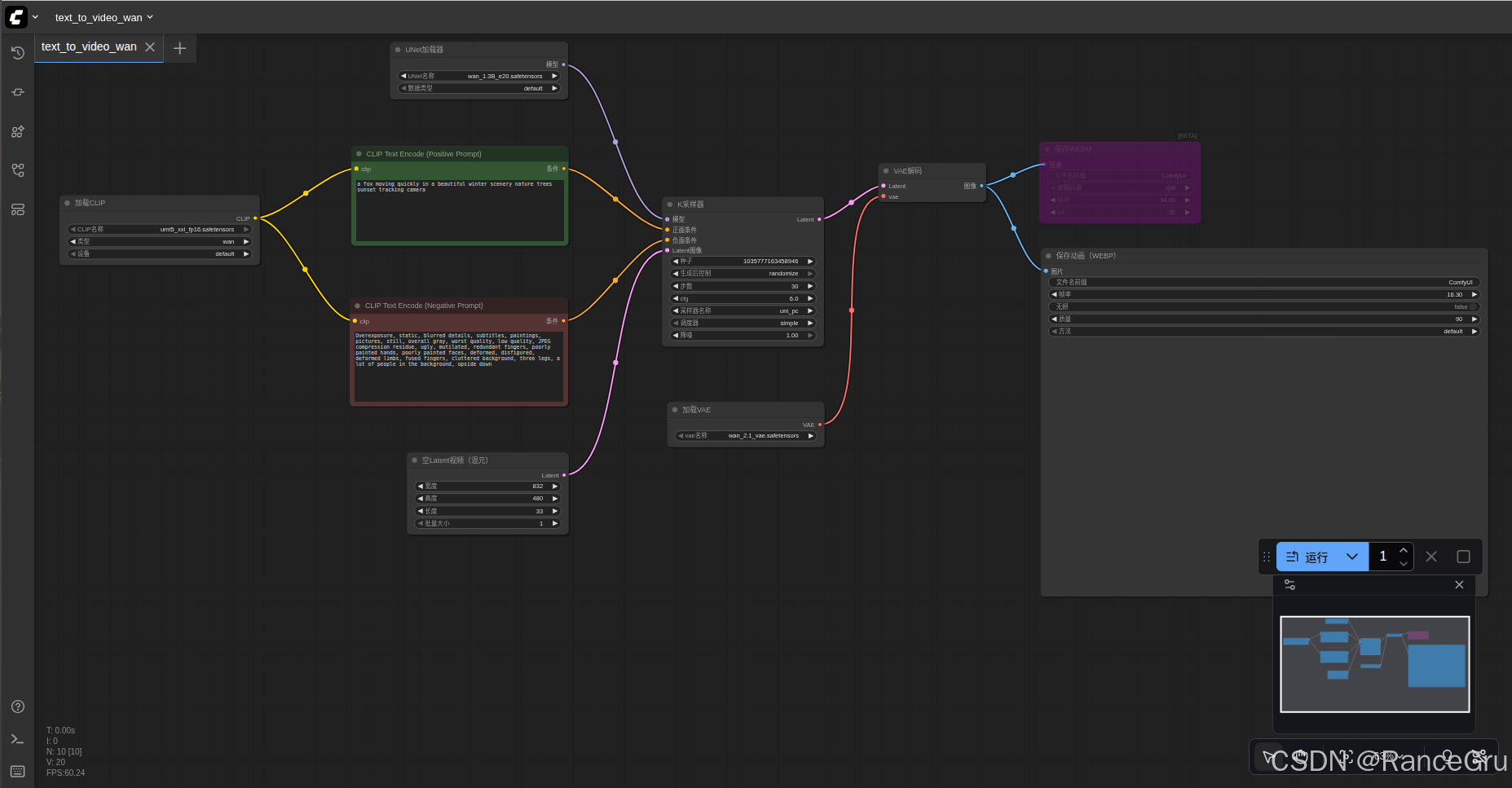
在CLIP Text Encode (Positive Prompt)中输入正提示语句,比如示例:
a fox moving quickly in a beautiful winter scenery nature trees sunset tracking camera
在CLIP Text Encode (Negative Prompt)中输入反提示语句,比如示例:
Overexposure, static, blurred details, subtitles, paintings, pictures, still, overall gray, worst quality, low quality, JPEG compression residue, ugly, mutilated, redundant fingers, poorly painted hands, poorly painted faces, deformed, disfigured, deformed limbs, fused fingers, cluttered background, three legs, a lot of people in the background, upside down
正提示语句可以自由修改,反提示语句除非有明确指令要添加,否则可以不用动,应为是通用的。
写完提示词后直接点解右下角的运行按钮,开始生成视频。
生成的webp文件,会保存在ComfyUI\output文件夹中。

总结
ComfyUI工具的使用还是非常简单,其次Wan2.1-T2V-1.3B文生视频模型比较小,所以生成的视频效果不稳定。