GAN(Generative Adversarial Nets)生成对抗网络论文笔记
GAN(Generative Adversarial Networks,生成对抗网络)是 2014 年由人工智能学者Ian Goodfellow提出的一种生成式 AI 模型,核心思想是通过两个神经网络(生成器与判别器)的对抗博弈,让模型学会生成与真实数据高度相似的 “假数据”。它彻底改变了生成模型的发展方向,至今仍是 AI 领域 “创造力” 的核心技术之一。
一、Abstract(GAN在做什么)
这里介绍会用两个生成模型,一个是生成模型G用来捕捉数据分布,一个是辨别模型D用来估计一个样本到底是从(真实)训练数据来的还是从G生成来的。G的任务就是尽量让D犯错。如果G和D是一个MLP的话就可以通过误差反传来进行训练,并且不需要用到马尔可夫链。
二、Introduction(大致原理)
深度学习更多的是对数据分布的一个表示,深度神经网络是其中的一个手段。深度学习在生成模式上进展不多。在框架里面有两类模型:生成模型和判别模型,相当于假币商和鉴定师,两者互相学习,最后希望造假者能赢,这样就可以生成近似真实的数据。在框架下生成模型是MLP,输入是一个随机噪音,把噪音的分布(通常是高斯分布)可以映射到任何一个我们想去拟合的分布。同样道理判别模型也是MLP的情况下,在这个框架下的特里叫AN,因为两个模型都基于MLP,所以训练可以通过误差的反向传递,在计算上有优势。
区别与传统的直接把分布学出来,GAN学习一个模型近似结果,VAEs和NCE也做了类似工作。
训练D的同时也会训练G,去最小化log(1-D(G(z))),对于这一项,z是随机噪音,然后放到G里面就会生成一个数据,假设D的辨别能力很强,那么判断G(z)的结果是0,那么整体就是0,反之如果判断不出来G(z)是假数据,极端情况D会判断为1(真实),那么这个log(...)就会很小。简单说就是训练G让D犯错。
三、Adversarial nets (算法)
在每一步里采样m个噪音样本和m个真实样本,组成一个2m大小的小批量,放进价值函数里面求梯度来更新辨别器:
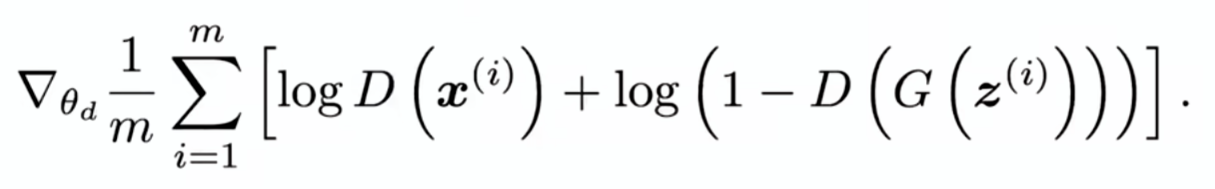
做完k步上述操作后我们再采样m个噪音样本,然后放进上面公式的第二项里面更新生成器:
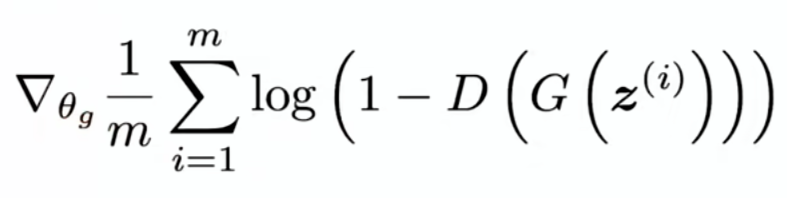
这样就完成了一次迭代,每一次都是更新辨别器再更新生成器。
整体来说GAN的收敛是很不稳定的,所以后来有很多工作针对此进行改进。因为刚开始G的造假能力不行,所以可以把一开始的目标函数改为最大化logD(G(z))。
补充
GAN不直接建模真实数据的概率分布,“真实数据” 代表 “现实世界中客观存在的数据集合”,“概率分布” 代表 “这些数据在不同取值 / 特征上的‘出现概率规律’”。生成模型的核心目标是 “生成与真实数据‘看起来一样’的假数据”,而这个目标的本质,就是让 “生成数据的分布 G” 尽可能接近 “真实数据的分布 P”。
GAN由两个核心组件构成:对于生成器G来说,G的目标是学习真实数据的分布,生成以假乱真的数据,输入是随机噪声(潜在向量);对于判别器D来说,目标是区分输入数据是真实数据还是假数据,输入是真实数据/生成器输出的数据,输出是0~1的概率值。
潜在向量:一段随机的高维向量(比如100维的随机数),生成器会通过学习,将这段无意义的随机数映射为有意义的、与真实数据分布一致的输出。
四、理论上的结果
目标函数仅当生成数据的分布和真实数据分布一样时有最优解。
结论1:当G固定,最优的辨别器D是这么算出来的:
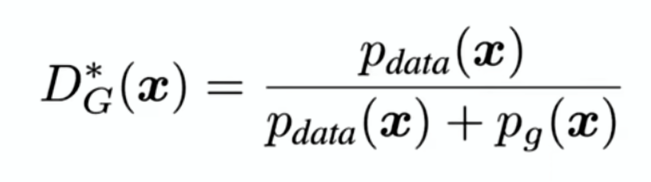
值在0到1之间,不管对什么,最优是二分之一。