C语言自学--文件操作
目录
正文
1、为什么使用文件?
2、 什么是文件?
2.1 程序文件
2.2 数据文件
3、二进制文件和文本文件
4、文件的打开和关闭
5、文件的顺序读写
6、文件的随机读写
7、文件读取结束的判定
8、文件缓冲区
正文
1、为什么使用文件?
程序运行时产生的数据通常存储在内存中,一旦程序退出,内存会被回收,这些数据就会丢失。若要使数据能够长期保存,就需要使用文件进行持久化存储,这样下次运行程序时仍可访问之前的数据。
2、 什么是文件?
从广义上讲,磁盘上的所有文件都属于文件范畴。但在程序设计中,我们主要讨论两种类型的文件:程序文件和数据文件(按功能分类)。
2.1 程序文件
程序文件包括:
- 源程序文件(后缀为.c)
- 目标文件(Windows环境下后缀为.obj)
- 可执行程序(Windows环境下后缀为.exe)
2.2 数据文件
数据文件的内容通常不是程序本身,而是程序运行时需要读取或输出的数据。这类文件可能包含程序运行所需的输入数据,也可能是程序运行后产生的输出结果。本章讨论的是数据文件。 在以前各章所处理数据的输⼊输出都是以终端为对象的,即从终端的键盘输⼊数据,运行结果显示到显示器上。 其实有时候我们会把信息输出到磁盘上,当需要的时候再从磁盘上把数据读取到内存中使用,这里处理的就是磁盘上文件。
2.3 、文件名
每个文件都需要一个唯一的标识符,方便用户识别和引用。完整的文件名由三部分组成:文件路径、主文件名和扩展名。例如:c:\code\test.txt。为简化表达,这个完整标识通常简称为"文件名"。
3、二进制文件和文本文件
根据数据存储方式的不同,文件可分为文本文件和二进制文件。数据在内存中均以二进制形式存储:若直接输出到外部存储设备,则形成二进制文件;若需以ASCII码形式存储,则需预先进行格式转换,这种以ASCII字符存储的文件即为文本文件。
具体到内存中的数据存储方式:
- 字符数据始终采用ASCII形式存储
- 数值型数据可选择ASCII或二进制形式存储
以整数10000为例:
- ASCII存储方式占用5字节(每个字符1字节)
- 二进制存储方式仅需4字节(经VS2019测试验证)

测试代码:
#include <stdio.h>
int main()
{int a = 1000;FILE *PF = fopen("test.txt","wb");fwriter(&a,4,1,pf);fclose(&a);pf=NULL;return 0;} 4、文件的打开和关闭
4.1、流和标准流
-
4.1.1 、流的概念
程序运行时需要与各类外部设备进行数据交换,而不同设备的输入输出操作方式各异。为简化程序员对各类设备的操作,我们引入了"流"这一抽象概念——可以将其形象地理解为流动着字符的河流
在C语言中,无论是文件操作、屏幕显示还是键盘输入,所有数据输入输出操作都是通过流来完成的。通常来说,要向流写入数据或从流读取数据,都需要先打开对应的流再进行操作。
-
4.1.2、标准流
当我们通过键盘输入数据或向屏幕输出数据时,为何不需要手动打开流呢?这是因为C语言程序在启动时,会自动开启三个标准流:
- stdin(标准输入流):通常对应键盘输入,
scanf等函数就是从此流读取数据 - stdout(标准输出流):通常输出到显示器界面,
printf函数将信息输出至此流 - stderr(标准错误流):多数情况下也会输出到显示器界面
这些标准流以FILE*类型(文件指针)存在,C语言正是通过这种文件指针来管理各种流操作的。因此,我们无需额外操作,就能直接使用scanf、printf等函数进行输入输出。
4.2、文件指针
在C语言中,文件指针(FILE*)是一个指向文件流的指针,用于对文件进行读写操作。文件指针的类型是FILE,定义在标准库头文件<stdio.h>中。通过文件指针,可以访问文件的打开、关闭、读取、写入等功能。
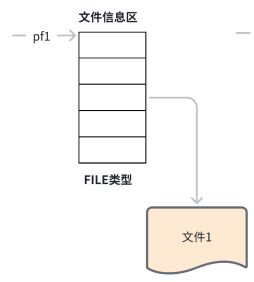
在缓冲文件系统中,"文件指针"(即文件类型指针)是一个核心概念。每个打开的文件都会在内存中分配一个文件信息区,用于存储文件名称、状态和当前位置等相关数据。这些信息被封装在一个名为FILE的结构体变量中,该结构体类型由系统定义。例如,在VS2013编译环境的stdio.h头文件中,可以找到相关的文件类型声明。
struct _iobuf
{char *_ptr;int _cnt;char *_base;int _flag;int _file;int _charbuf;int _bufsiz;char *_tmpfname;
};
typedef struct _iobuf FILE各C编译器的FILE类型实现略有差异,但基本结构相似。在打开文件时,系统会自动创建并初始化一个FILE结构体变量,开发者无需关注其内部细节。通常我们会通过FILE指针来操作该结构体,这样更为便捷。
我们可以创建FILE指针变量:
FILE* pf;//⽂件指针变量定义pf是⼀个指向FILE类型数据的指针变量。可以使pf指向某个⽂件的⽂件信息区(是⼀个结构体变 量)。通过该文件信息区中的信息就能够访问该文件。也就是说,通过文件指针变量能够间接找到与 它关联的文件。
4.3 、文件的打开和关闭
在操作文件时,必须先打开文件才能进行读写操作,使用完毕后应及时关闭文件。编程时,打开文件会返回一个FILE*类型的指针变量,该指针用于建立程序与文件之间的关联。根据ANSIC标准,应使用fopen函数打开文件,fclose函数关闭文件。
//打开⽂件
FILE * fopen ( const char * filename, const char * mode );
//关闭⽂件
int fclose ( FILE * stream );mode表示文件的打开模式,下⾯都是文件的打开模式:
"r":只读模式,文件必须存在。"w":只写模式,文件不存在则创建,存在则清空。"a":追加模式,文件不存在则创建,存在则在末尾追加。"r+":读写模式,文件必须存在。"w+":读写模式,文件不存在则创建,存在则清空。"a+":读写模式,文件不存在则创建,存在则在末尾追加。
#include <stdio.h>
int main ()
{FILE * pFile;//打开⽂件pFile = fopen ("myfile.txt","w");//⽂件操作if (pFile!=NULL){fputs ("fopen example",pFile);//关闭⽂件fclose (pFile);}return 0;
}5、文件的顺序读写
5.1 、顺序读写函数介绍
5.1.1、fread 函数
fread 用于从文件中读取数据块。其函数原型如下:
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);
ptr:指向存储读取数据的内存地址size:每个数据项的字节大小nmemb:要读取的数据项数量stream:文件指针
该函数返回成功读取的数据项数量。若返回值小于nmemb,可能到达文件末尾或发生错误。
5.1.2、fwrite 函数
fwrite 用于向文件写入数据块。其函数原型如下:
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);
ptr:指向待写入数据的内存地址size:每个数据项的字节大小nmemb:要写入的数据项数量stream:文件指针
函数返回成功写入的数据项数量。若返回值小于nmemb,通常表示写入过程中发生错误。
5.1.3、fgets 函数
fgets 用于从文件中读取一行字符串。其函数原型如下:
char *fgets(char *str, int n, FILE *stream);
str:存储读取字符串的缓冲区n:最大读取字符数(包括结尾的空字符)stream:文件指针
函数成功时返回str指针,失败或到达文件末尾时返回NULL。读取的字符串包含换行符(如果存在)。
5.1.4、fputs 函数
fputs 用于向文件写入字符串。其函数原型如下:
int fputs(const char *str, FILE *stream);
str:待写入的字符串stream:文件指针
成功时返回非负值,失败时返回EOF。该函数不会自动添加换行符。
5.1.5、格式化读写函数
fscanf 和 fprintf 提供格式化读写功能:
int fscanf(FILE *stream, const char *format, ...);
int fprintf(FILE *stream, const char *format, ...);
用法与scanf和printf类似,但操作对象是文件流而非标准输入输出。
5.1.6、文件位置指针控制
fseek 用于设置文件位置指针:
int fseek(FILE *stream, long offset, int whence);
whence参数可取:
- SEEK_SET:从文件开头计算偏移
- SEEK_CUR:从当前位置计算偏移
- SEEK_END:从文件末尾计算偏移
ftell 返回当前文件位置:
long ftell(FILE *stream);
rewind 将位置指针重置到文件开头:
void rewind(FILE *stream);
5.2、对比一组函数
5.2.1、scanf/fscanf/sscanf 对比
- 功能差异
- scanf:从标准输入(通常是键盘)读取格式化数据。
- fscanf:从指定文件流(如文件指针)读取格式化数据。
- sscanf:从字符串缓冲区读取格式化数据,适用于字符串解析。
- 参数区别
scanf(format, &var1, &var2...)fscanf(file_ptr, format, &var1, &var2...)sscanf(buffer, format, &var1, &var2...)- 典型应用场景
scanf用于交互式终端输入。fscanf用于读取文件内容(如日志、配置文件)。sscanf解析字符串(如从网络数据包提取字段)。
5.2.2、printf/fprintf/sprintf 对比
- 功能差异
- printf:向标准输出(通常是屏幕)打印格式化数据。
- fprintf:向指定文件流(如文件指针)输出格式化数据。
- sprintf:将格式化数据写入字符串缓冲区,需注意缓冲区溢出风险。
- 参数区别
printf(format, var1, var2...)fprintf(file_ptr, format, var1, var2...)sprintf(buffer, format, var1, var2...)- 典型应用场景
printf用于调试或控制台输出。fprintf用于写入文件(如生成报告)。sprintf构建动态字符串(需搭配snprintf防溢出)。
5.2.3、安全注意事项
sscanf和sprintf可能因缓冲区不足导致安全问题,推荐使用带长度限制的变体(如snprintf)。- 文件操作(
fscanf/fprintf)需检查文件指针有效性。
代码示例:
// sscanf 示例
char str[] = "42 3.14";
int num; float f;
sscanf(str, "%d %f", &num, &f);// sprintf 示例(安全版本)
char buffer[100];
snprintf(buffer, sizeof(buffer), "Value: %d", num);
6、文件的随机读写
6.1、fseek
fseek用于移动文件指针到指定位置,实现随机读写。其函数原型为:
int fseek(FILE *stream, long offset, int origin);
参数说明:
stream:文件指针。offset:偏移量(字节数),可为正(向后移动)或负(向前移动)。origin:基准位置,取值如下:SEEK_SET(文件开头)。SEEK_CUR(当前位置)。SEEK_END(文件末尾)。
示例:
FILE *fp = fopen("test.txt", "r");
fseek(fp, 10, SEEK_SET); // 将指针移动到第10字节处
6.2、ftell
ftell返回文件指针的当前偏移量(相对于文件开头)。其函数原型为:
long ftell(FILE *stream);
示例:
long pos = ftell(fp); // 获取当前指针位置
6.3、rewind
rewind将文件指针重置到文件开头,等价于fseek(fp, 0, SEEK_SET)。其函数原型为:
void rewind(FILE *stream);
示例:
rewind(fp); // 指针回到文件起始位置
6.4、综合应用
以下代码演示随机读写操作:
FILE *fp = fopen("data.dat", "rb+");
fseek(fp, 0, SEEK_END); // 指针移动到文件末尾
long size = ftell(fp); // 获取文件大小
rewind(fp); // 重置指针
7、文件读取结束的判定
7.1、被错误使用的 feof
牢记:在文件读取过程中,不能用feof函数的返回值直接来判断文件的是否结束。
feof 的作用是:当文件读取结束的时候,判断是读取结束的原因是否是:遇到文件尾结束。
7.2、错误使用 feof 的常见问题
许多初学者在文件读取时直接用 feof 判断文件是否结束,这是错误的。feof 只有在文件读取结束后才能判断是否因文件尾而终止,而非用于主动检测文件结束。
7.3、文本文件读取的正确结束判断方法
文本文件通常以字符或行为单位读取,应通过函数返回值判断:
- 使用
fgetc时,检查返回值是否为EOF。 - 使用
fgets时,检查返回值是否为NULL。
示例代码片段:
FILE *file = fopen("example.txt", "r");
if (file) {int ch;while ((ch = fgetc(file)) != EOF) { // 正确判断文本文件结束putchar(ch);}fclose(file);
}
7.4、二进制文件读取的正确结束判断方法
二进制文件通常通过 fread 读取,应检查实际读取的元素数量是否小于请求数量:
FILE *file = fopen("data.bin", "rb");
if (file) {char buffer[1024];size_t bytesRead;while ((bytesRead = fread(buffer, 1, sizeof(buffer), file)) > 0) { // 正确判断二进制文件结束// 处理读取的数据}fclose(file);
}
7.5、何时使用 feof
feof 适用于区分文件结束的具体原因,例如:
if (feof(file)) {printf("文件正常结束\n");
} else if (ferror(file)) {printf("读取时发生错误\n");
}
总结要点
- 文本文件通过
EOF或NULL判断结束。 - 二进制文件通过
fread返回值是否小于请求值判断。 feof仅用于事后检测是否因文件尾结束。
8、文件缓冲区
8.1、ANSI C缓冲文件系统的工作原理
缓冲文件系统通过内存中的缓冲区优化磁盘I/O操作。当数据从内存写入磁盘时,先暂存于缓冲区,待缓冲区填满后一次性写入磁盘。读取数据时,磁盘内容先被批量加载至缓冲区,再逐个传递到程序变量区。
8.2、缓冲区的关键作用
- 减少磁盘访问次数:批量处理数据降低高频小数据量I/O的开销。
- 提升性能:内存操作速度远高于磁盘,缓冲区作为中介显著加速读写流程。
- 自动管理:缓冲区大小由编译器决定,开发者无需手动干预。
8.3、缓冲类型与操作模式
- 全缓冲:缓冲区满时触发实际I/O,通常用于文件操作。
- 行缓冲:遇到换行符或缓冲区满时触发,常见于终端交互。
- 无缓冲:立即执行I/O,如标准错误流
stderr。
8.4、示例:文件读写流程
#include <stdio.h>int main() {FILE *fp = fopen("example.txt", "w");if (fp) {// 写入数据到缓冲区(未立即落盘)fprintf(fp, "Data to buffer");// 强制刷新缓冲区使数据写入磁盘fflush(fp);fclose(fp);}return 0;
}
8.5、缓冲区大小的影响因素
- 编译器实现:不同编译环境可能设置不同默认缓冲区大小。
- 系统资源:内存限制可能动态调整缓冲区容量。
- 手动设置:可通过
setvbuf()函数自定义缓冲区大小和模式。
8.6、注意事项
- 数据一致性:程序异常退出时,缓冲区数据可能未写入磁盘,需定期调用
fflush()。 - 实时性要求:对实时性高的场景可禁用缓冲或缩短刷新间隔。
- 跨平台差异:缓冲区行为可能因操作系统或编译器而异,需针对性测试。