ICRA-2025 | 机器人具身探索导航新策略!CTSAC:基于课程学习Transformer SAC算法的目标导向机器人探索
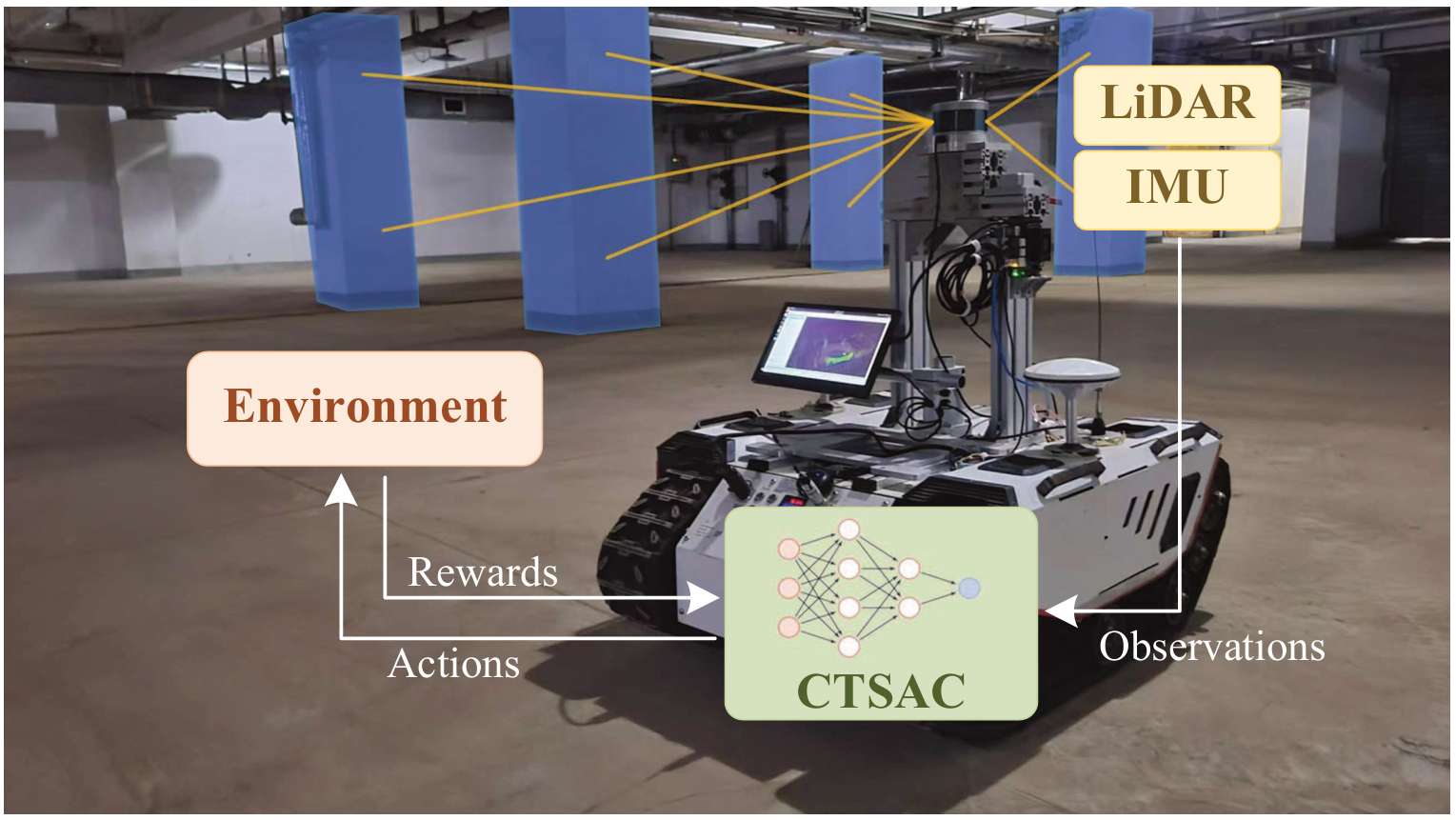
- 作者: Chunyu Yang, Shengben Bi, Yihui Xu, Xin Zhang
- 单位:中国矿业大学信息与控制工程学院
- 论文标题:CTSAC: Curriculum-Based Transformer Soft Actor-Critic for Goal-Oriented Robot Exploration
- 论文链接:https://arxiv.org/pdf/2503.14254v1
- 代码链接:https://github.com/ShengbenBi/CTSAC
主要贡献
- 提出了基于课程学习的 Transformer 强化学习算法(CTSAC),用于提高目标导向机器人探索的效率和迁移性能。
- 将 Transformer 集成到soft actor - critic(SAC)框架的感知网络中,使机器人能够利用历史信息,增强策略的远见性,从而解决机器人缺乏长期视野以及容易陷入循环的问题。
- 引入了基于定期复习的课程学习策略,提高了训练效率,同时减轻了课程转换过程中的灾难性遗忘问题。
- 对激光雷达聚类进行了优化,减少了Sim-To-Real的差距,并在 ROS - Gazebo 连续机器人仿真平台上进行了训练,通过实验验证了 CTSAC 算法在成功率和成功率加权探索时间方面优于现有的非学习和基于学习的算法,且在现实世界实验中展现了强大的 S2R 迁移能力。
研究背景
- 自主导航探索(Autonomous Exploration,AE)使机器人能够在未知环境中感知周围环境、规划路径、避开障碍物并到达目标点,在太空探索、搜索救援和侦察等领域具有重要意义。
- 传统的非学习方法(如基于信息论的方法、基于边界的探索方法和基于随机抽样的方法等)通常依赖于对环境和任务的强假设,随着环境的逐渐揭示,这些方法生成的最优路径往往会变得次优,导致传统探索算法效率低下。
- 强化学习为自主机器人探索提供了一种有前景的替代方案,但现有基于 RL 的探索算法存在环境推理能力有限、收敛速度慢以及在仿真到现实(S2R)迁移方面面临巨大挑战等问题。
任务描述
问题概述
- 自主探索(Autonomous Exploration,AE)本质上是一种序列决策问题。由于探索发生在未知环境中,机器人无法观察到全局状态,只能通过传感器获取部分信息。
- 因此,AE 可以被描述为以下马尔可夫决策过程(Markov Decision Process,MDP)。
马尔可夫决策过程的定义
- 状态(State):令 sts_tst 表示机器人在时间 ttt 的状态,包括以下信息:
- 从预处理后的激光雷达观测 l1,…,ldl_1, \dots, l_dl1,…,ld 中获得的周围障碍物信息。
- 机器人的线速度 vrv_rvr 和角速度 ωr\omega_rωr。
- 目标点与机器人之间的相对距离 dtd_tdt 和角度 θt\theta_tθt。
- 动作(Action):基于策略 π\piπ,机器人选择一个动作 ata_tat,包括线速度 vcv_cvc 和角速度 ωc\omega_cωc,且这些动作在机器人的运动学限制内。
- 奖励(Reward):环境根据机器人的动作 ata_tat 提供奖励 rtr_trt,随后机器人状态转移到下一个状态 st+1s_{t+1}st+1。这个过程不断重复,直到机器人达到预设的目标状态。
CTSAC 方法
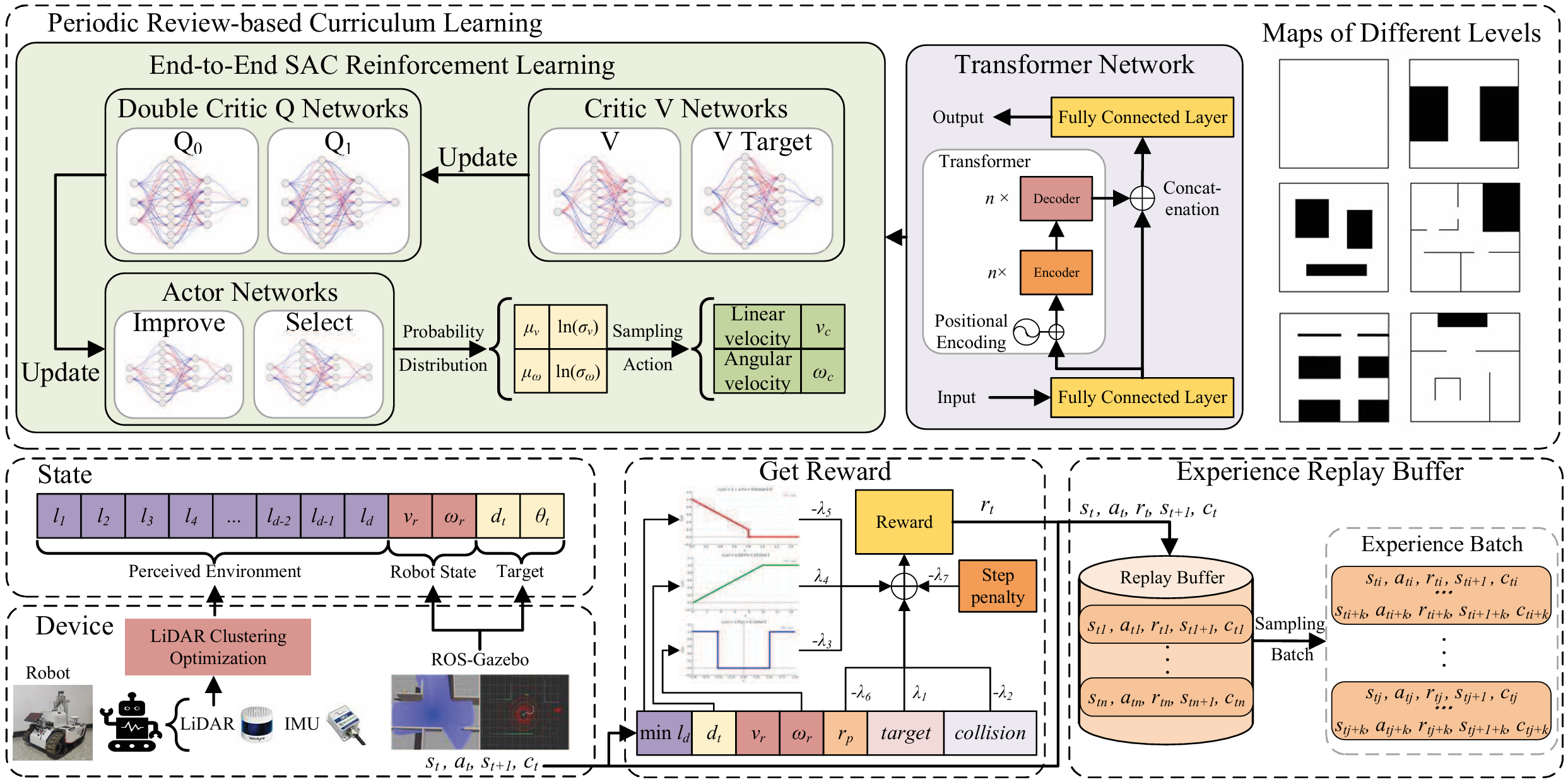
端到端目标导向机器人探索框架
- 系统架构:机器人配备激光雷达(LiDAR)和惯性测量单元(IMU),用于环境感知和状态估计。
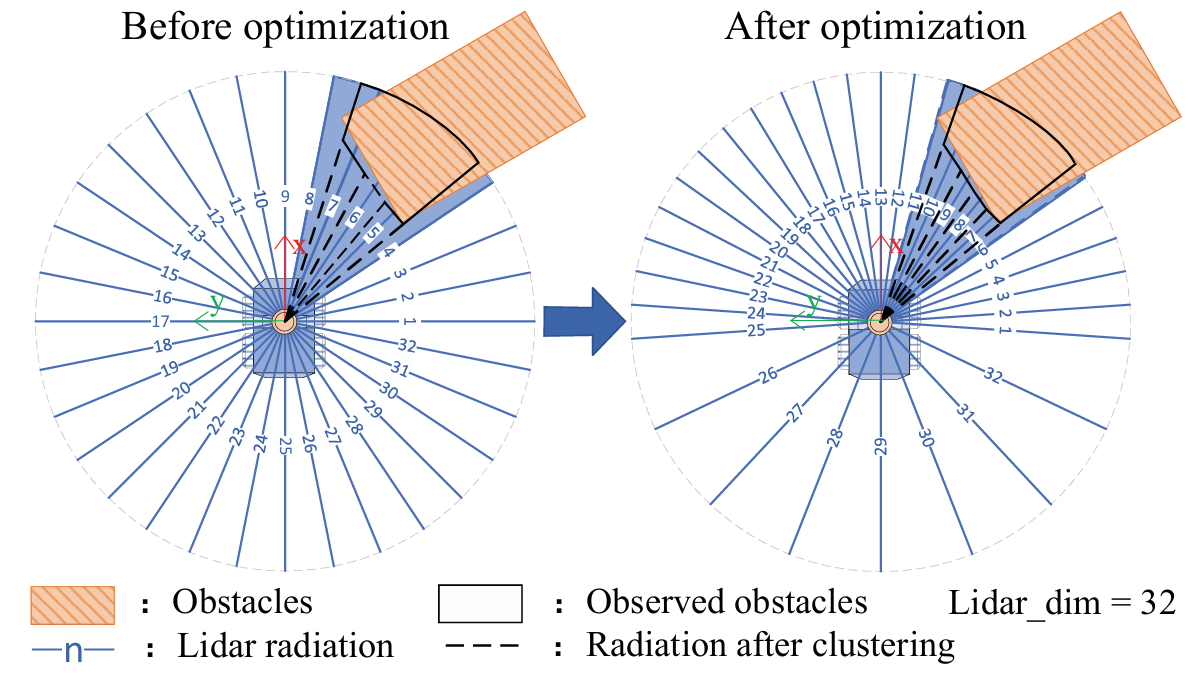
- 激光雷达数据预处理:对激光雷达数据进行预处理,根据其维度特性将扫描区域划分为多个段,并对每个段内的激光雷达数据进行聚类。与传统的均匀分割方法相比,本文优化了分割方法,使其与机器人的运动方向相关,增强了机器人在前进方向上的感知能力,并减少了网络的决策时间。
- 奖励函数设置:奖励函数由多个部分组成,包括目标到达奖励、碰撞惩罚、转弯惩罚、目标接近奖励、障碍物接近惩罚、徘徊惩罚和步数惩罚等。这些奖励和惩罚机制共同引导机器人高效、安全地完成探索任务。
基于 Transformer 的SAC算法
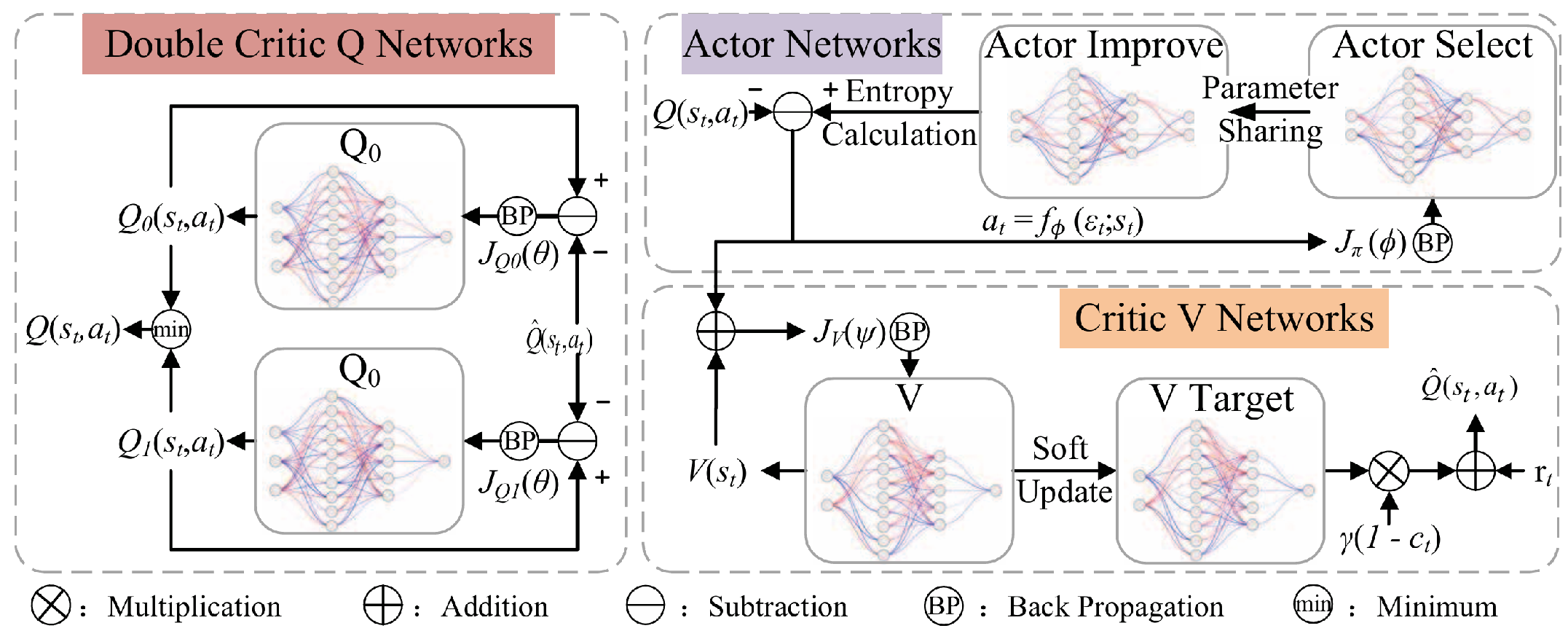
- 在 SAC 框架中引入 Transformer,代替传统深度强化学习中的全连接层。设计了包含 Transformer 层的actor网络(分为actor选择网络和actor改进网络)、价值网络和双critic Q 网络。
- actor网络:actor选择网络在决策过程中使用,其输入为机器人在环境中多步的状态信息,经过 Transformer 层处理后生成动作的均值和对数标准差;actor改进网络在策略改进过程中使用,接收经验回放缓冲区中的经验序列,生成序列化的动作数据供 Q 网络学习。
- 价值网络:由两个部分组成,一个用于估计当前状态值 V(st)V(s_t)V(st),另一个用于计算目标状态值 V(st+1)V(s_{t+1})V(st+1)。价值目标网络的参数通过从价值网络进行soft 更新得到。
- 双critic Q 网络:包含两个结构相同但参数独立的 Q 网络,最终的 Q 值取两个网络输出的最小值。Q 网络的输入是状态和动作的拼接,其余结构与价值网络相同。
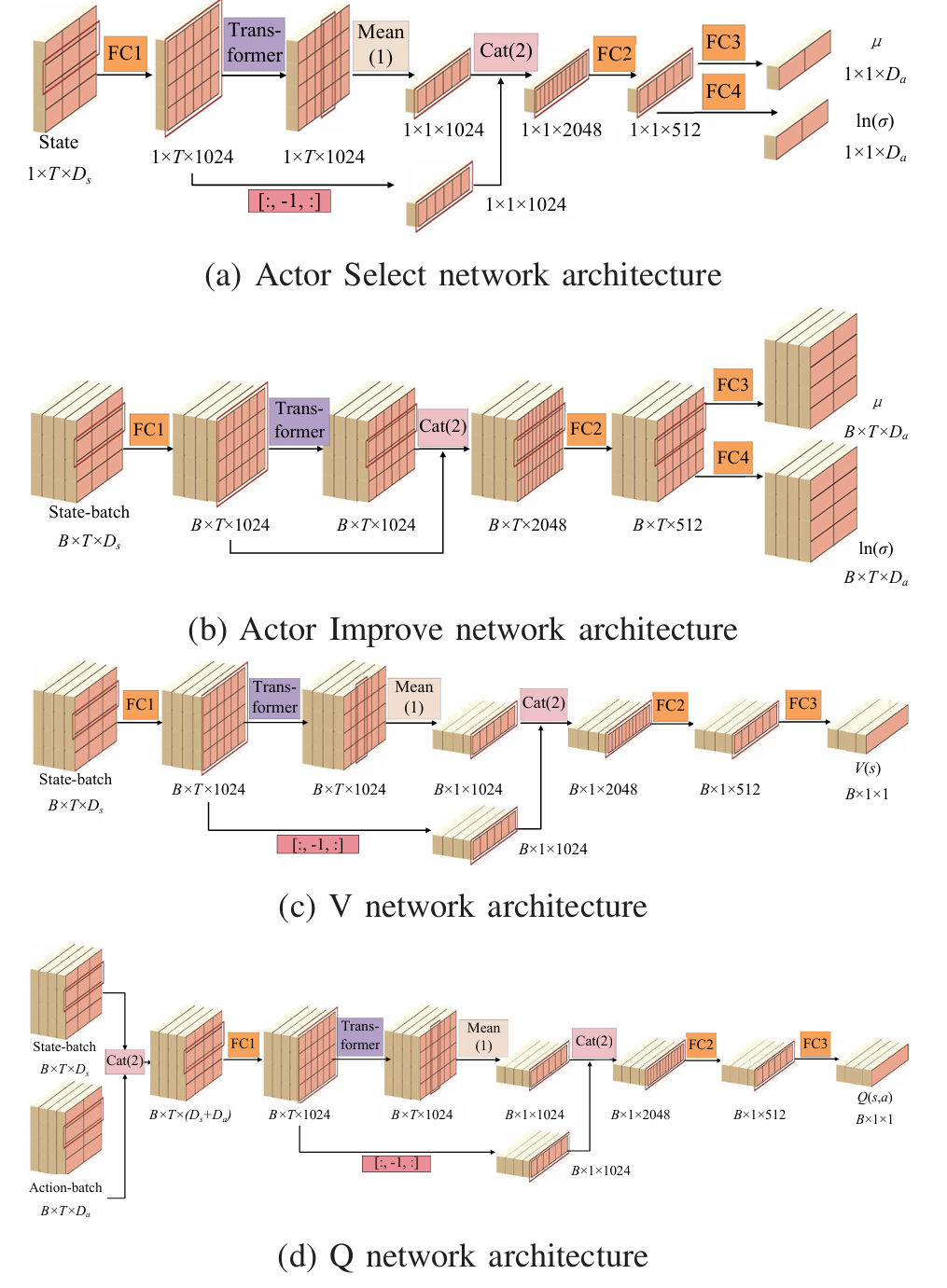
- 训练参数设置:
- 在训练过程中,每两步更新一次神经网络,学习率为 5×10−45 \times 10^{-4}5×10−4,折扣因子 γ\gammaγ 为 0.98,经验回放缓冲区大小为 1×1051 \times 10^51×105,批量大小为 256,随机种子为 1。
- 使用 Adam 优化器优化神经网络参数,并在 Transformer 结构中应用了 dropout 和权重衰减技术以防止过拟合。
- Transformer 层的嵌入维度设置为 1024,包含 2 个编码器块和 2 个解码器块,每个块包含 8 个注意力头。
基于定期复习的课程学习策略
- 课程学习机制:
- 采用基于定期复习的课程学习方法来训练基于 Transformer 的soft actor - critic(TSAC),以加速训练速度和稳定性,防止陷入局部最优导致训练发散,并缓解课程学习中常见的灾难性遗忘问题。
- 在每个训练阶段,定期回顾之前的任务,以确保在新环境中成功学习的同时有效保留早期阶段获得的知识。
- 环境设置与算法流程:
- 设计了不同难度级别的训练环境,包括死胡同、各种大小的障碍物、随机出现的动态障碍物以及可能因随机障碍物而被阻塞的路径等情况。
- 课程学习包含六个阶段,随着阶段的推进,环境容器会添加相应难度的世界。下图展示了课程学习的伪代码,其中详细描述了如何在不同阶段采样环境并进行训练,以及如何根据成功率进行阶段切换。

实验与讨论
仿真实验
实验设置
- 平台:使用 Ubuntu 20.04 系统,配备 Intel i5 12400 处理器和 NVIDIA RTX 4080 GPU。

- 仿真环境:在 Gazebo 中进行,场景大小为 20m×20m,使用 TurtleBot3 机器人,线速度范围为 [0, 1] m/s,角速度范围为 [−1, 1] rad/s,配备 Velodyne VLP16 激光雷达,检测范围为 6m,扫描角度为 360°。
- 测试世界:设计了六个测试世界,这些世界未包含在训练数据集中,用于评估算法的泛化能力。
- 评价指标:成功率(Success Rate, SR)和成功率加权探索时间(Success Rate - Weighted Exploration Time, SET)。
- 对比算法:
- 非学习方法:Far Planner, FP 和 Rapidly-Exploring Random Tree, RRT* 结合 Dynamic Window Approach, DWA
- 基于学习的方法:Twin Delayed Deep Deterministic Policy Gradient, TD3。
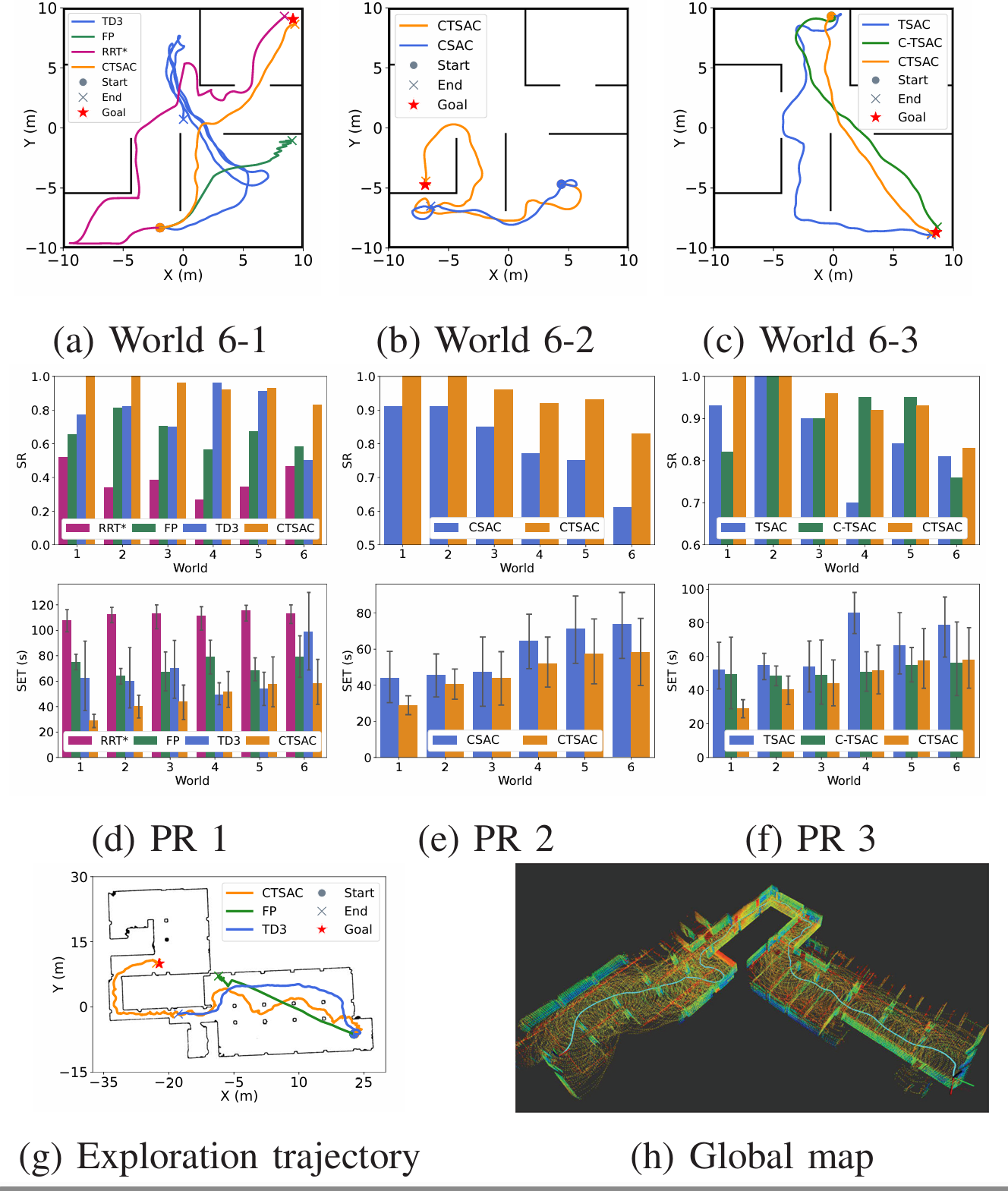
实验结果
- 轨迹图:上图(a)显示了在 World 6-1 中的轨迹图,CTSAC 能够快速到达目标,而 TD3 由于前端检测精度有限而难以找到狭窄入口,FP 因缺乏对环境的理解而陷入死胡同,RRT* 沿墙行走,存在安全问题。
- 性能对比:上图(d) 显示了在不同测试世界中的性能对比。TD3 在 World 4 中表现最佳,但缺乏泛化能力。CTSAC 在所有环境中都实现了高成功率和较短的探索时间,表现出最优的性能。基于学习的方法尽管方差较大,但展示了更大的灵活性和泛化能力。
消融实验
Transformer 的验证
- 实验设置:将 CTSAC 与没有 Transformer 的 SAC 算法(CSAC)进行比较,两者在相同的设置下进行训练。
- 实验结果:
- 轨迹图:上图(b) 显示了在 World 6-2 中的轨迹图,CTSAC 成功绕过了障碍物,而 CSAC 继续徘徊。CTSAC 通过 Transformer 的自注意力机制有效利用了长期历史信息,从而能够做出更准确的决策并避免停滞。
- 性能对比:上图(e) 显示了在不同测试世界中的性能对比,CTSAC 的 SR 和 SET 比 CSAC 高出 10%,这表明 CTSAC 不仅提高了任务的成功率,还通过减少冗余行为优化了探索效率。在更复杂的环境中,性能差距更加明显。
课程学习的验证
- 实验设置:比较了 CTSAC、传统的基于切换的课程学习方法(C-TSAC)和没有课程学习的 TSAC 在测试世界的泛化性能以及对遗忘效应的缓解能力。所有算法都基于 Transformer 的 SAC,并在相同的设置下进行训练。
- 实验结果:
- 轨迹图:上图© 显示了在 World 6-3 中的轨迹图,CTSAC 在所有环境中都保持了稳定的成功率。
- 性能对比:上图(f) 显示了在不同测试世界中的性能对比。TSAC 由于仅在最终世界中进行训练,泛化性能较差。C-TSAC 通过在不同世界中学习展现出了一定的泛化能力,但在较简单的 World 1 中仍然出现了一些遗忘现象。CTSAC 在所有环境中都保持了稳定的成功率,比 C-TSAC 在 World 1 中高出 20%,在更复杂环境中性能差距较小。这表明 CTSAC 通过其基于定期复习的课程学习机制,有效地缓解了遗忘效应,并在各种环境中展现出了增强的泛化性能。
现实世界实验
- 实验设置:
- 测试场地:选择了一个面积为 45m×60m 的地下停车场,该环境有柱子、狭窄通道、可能打开或关闭的门以及行人。
- 机器人:使用 AgileX Bunker 机器人,配备 NVIDIA Jetson Orin NX 和 Velodyne VLP16 激光雷达。
- 对比算法:与 FP 和 TD3 进行比较。
- 测试次数:每个算法测试 40 次。
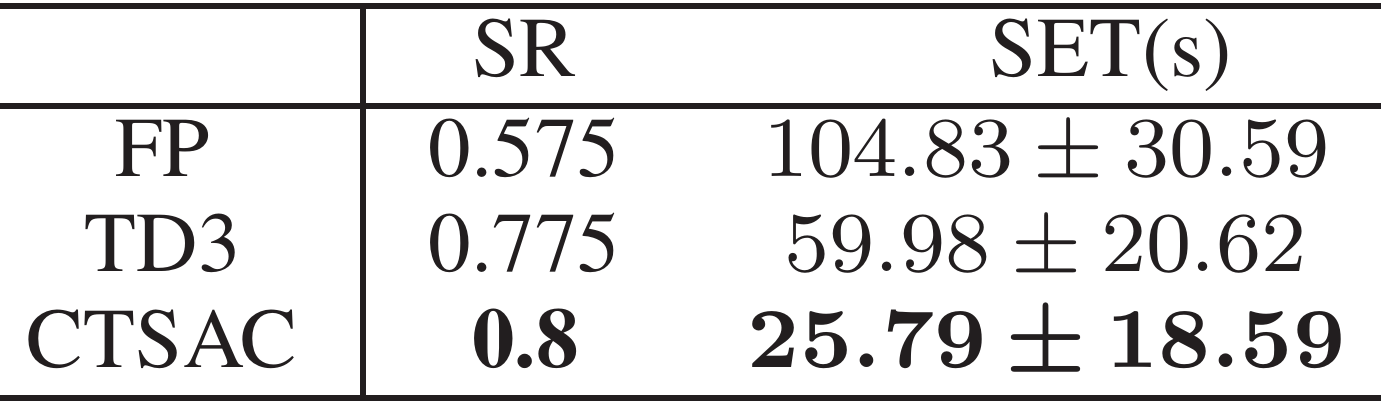
- 结果与分析:
- 性能对比:上表显示了实验结果,CTSAC 实现了最高的成功率 0.8,比 FP 高出 22%,与 TD3 相当。然而,CTSAC 展示了更短的探索时间,表明其路径规划效率更高。
- 轨迹图:图(g) 显示了在现实世界中的轨迹图,CTSAC 成功从 FP 卡住的局部最优中逃脱,通过狭窄通道到达目标。相比之下,TD3 由于观察性能差而未能通过狭窄通道。
- CTSAC 在现实世界中的表现验证了其从仿真到现实(S2R)的迁移能力。尽管机器人在实验中出现了打滑现象,表明速度跟踪控制器未能有效跟踪命令,这需要在未来的工作中加以解决。
结论与未来工作
- 结论:
- 本文提出的 CTSAC 方法通过将 Transformer 集成到 SAC 中,使机器人能够利用历史信息,增强了对环境的推理能力并提高了决策质量。
- 同时,引入的基于定期复习的课程学习方法优化了切换机制,减轻了灾难性遗忘,从而提高了模型的泛化性能。
- 此外,通过在现实世界中的实验验证了 CTSAC 从仿真到现实的出色迁移性能,这归功于探索框架、连续的训练环境和激光雷达聚类优化。
- 未来工作:
- 将从大规模模型和具身智能方法中汲取灵感,以进一步提高模型在自主探索中的性能。
