主动学习:用“聪明提问”提升模型效率的迭代艺术
在机器学习的世界里,数据标注是模型训练的基石——没有足够的标注数据,再强大的模型也无法学习到有效的规律。但现实中的标注工作往往面临一个残酷的现实:人工标注成本高、耗时长。比如,一个包含10万条文本的情感分析项目,如果完全依赖人工标注,可能需要数十人月的工作量,不仅耗资巨大,还容易因标注员疲劳或主观差异引入错误。
有没有一种方法,能让模型“主动”选择那些对提升性能最有帮助的样本进行标注,从而减少不必要的标注工作?主动学习(Active Learning) 就是这样一种“聪明的学习方式”——它通过迭代式地让模型选择“最有信息量”的未标注样本,交由人类标注员标注,然后更新模型,最终在有限的标注成本下实现性能最大化。
主动学习的核心逻辑:为什么能比随机标注更高效?
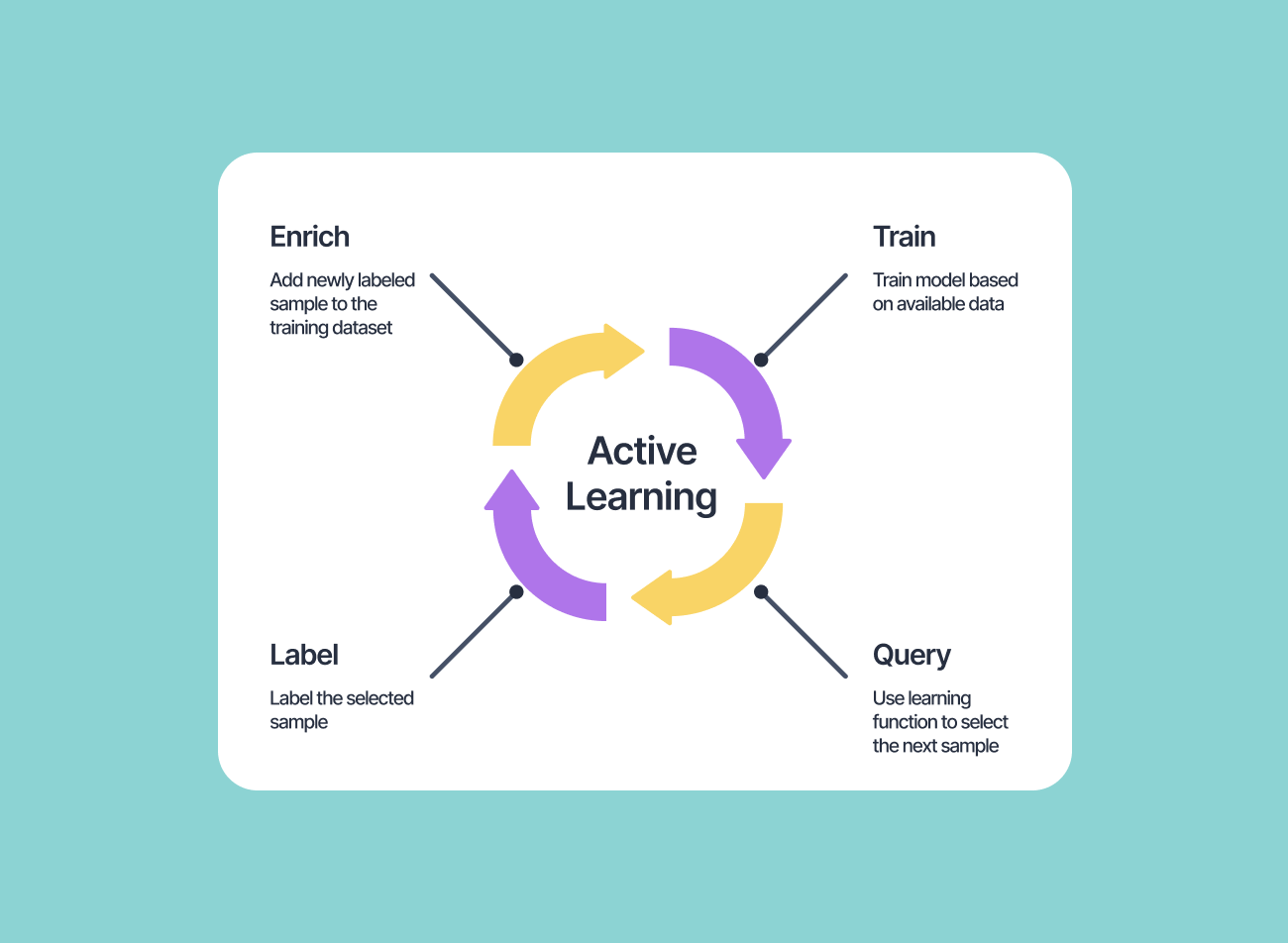
主动学习的核心思想是**“用最少的标注样本,最大化模型性能提升”**。它的运作流程可以概括为四个步骤(以文本分类任务为例):
- 初始化:用少量标注数据(如10条)训练一个基础模型(如随机森林、BERT);
- 选择样本:让模型对未标注数据池(如1000条未标注文本)进行预测,计算每个样本的“信息量”(比如“模型有多不确定这个样本的类别?”);
- 人工标注:选择信息量最高的样本(如10条),交给人类标注员标注;
- 更新模型:将新标注的样本加入训练集,重新训练模型;
- 重复迭代:重复步骤2-4,直到模型性能达到预期(如准确率达到90%)或标注预算用完。
这种方式的关键优势在于**“精准选择”**:相比随机标注(可能标注大量模型已经学会的样本),主动学习会让模型专注于“难样本”——比如分类边界附近的样本、模型预测概率接近50%的样本。这些样本对模型性能的提升价值远高于随机样本,因此能大幅减少标注工作量。例如,搜索结果中的代码示例显示,用主动学习选择100条样本,模型的准确率可能比随机标注高出20%以上。
主动学习的常见策略:如何量化“信息量”?
要让模型“主动选择”,必须定义“信息量”的量化指标。常见的策略可分为三类:
1. 不确定性采样(Uncertainty Sampling):选模型最不确定的样本
不确定性采样的核心是**“模型越不确定,样本越有价值”**。常见的指标包括:
- 最小置信度(Least Confidence):计算模型对预测类别的置信度(即最高概率),选择置信度最低的样本。例如,模型对某条文本的预测是“正面(0.6)、负面(0.4)”,置信度为0.6;另一条是“正面(0.9)、负面(0.1)”,置信度为0.9,那么第一条更不确定,更有价值。
- 边缘采样(Margin Sampling):选择模型预测的最高概率和次高概率差值最小的样本。比如,某条文本的预测是“正面(0.51)、负面(0.49)”,差值为0.02;另一条是“正面(0.8)、负面(0.2)”,差值为0.6,那么第一条更接近分类边界,更有价值。
- 熵(Entropy):用信息熵衡量样本的不确定性,熵越大表示模型越不确定。例如,某条文本的预测概率分布是“正面(0.5)、负面(0.5)”,熵为1(最大);另一条是“正面(0.9)、负面(0.1)”,熵为0.32(较小),那么第一条更不确定。
2. 委员会查询(Query-By-Committee, QBC):选模型们争议最大的样本
QBC的核心是**“多个模型意见越不一致,样本越有价值”**。具体做法是:
- 训练多个不同的模型(如随机森林、SVM、BERT),形成“委员会”;
- 对每个未标注样本,让委员会成员投票(比如预测类别);
- 选择投票分歧最大的样本(比如用“投票熵”或“KL散度”衡量分歧)。
例如,某条文本被3个模型分别预测为“正面、负面、中性”,分歧很大,说明这条样本可能是分类边界附近的样本,对模型性能提升有帮助。
3. 期望模型改变(Expected Model Change):选能让模型进步最大的样本
期望模型改变的核心是**“样本对模型参数的影响越大,越有价值”**。具体做法是:
- 计算每个未标注样本对模型参数的更新幅度(比如用梯度下降的步长衡量);
- 选择更新幅度最大的样本。
这种策略适合深度学习模型(如CNN、Transformer),因为深度学习的参数多,样本对模型的影响更复杂。
主动学习的Python实现:用scikit-learn和modAL库
搜索结果中的代码示例展示了如何用Python实现主动学习。这里我们用更详细的注释解释代码逻辑:
import numpy as np
from sklearn.ensemble import RandomForestClassifier # 基础模型
from modAL.models import ActiveLearner # 主动学习框架
from sklearn.datasets import make_classification # 生成模拟数据# 1. 生成模拟数据:1000条未标注样本(10维特征),2类
X_pool = np.random.rand(1000, 10) # 未标注数据池
y_pool = np.random.randint(0, 2, 1000) # 未标注数据的真实标签(实际中未知)# 2. 初始化主动学习器:用10条随机标注数据训练基础模型
learner = ActiveLearner(estimator=RandomForestClassifier(), # 基础模型:随机森林X_training=X_pool[:10], # 初始标注数据(10条)y_training=np.random.randint(0, 2, 10) # 初始标注标签(随机生成,实际中由人工标注)
)# 3. 主动学习循环:迭代100次,每次选择1个最有信息量的样本
n_queries = 100
for _ in range(n_queries):# 3.1 让模型选择最有信息量的样本query_idx, query_inst = learner.query(X_pool) # 返回最不确定样本的索引和数据# 3.2 模拟人工标注:实际中这里需要人工标注query_insty_new = np.random.randint(0, 2, 1) # 随机生成标注(实际中替换为人工标注)# 3.3 将新标注样本加入训练集learner.teach(X_pool[query_idx], y_new) # 更新模型# 3.4 从数据池中移除已标注样本X_pool = np.delete(X_pool, query_idx, axis=0)# 4. 评估模型性能:用剩余未标注数据评估
final_accuracy = learner.score(X_pool, np.random.randint(0, 2, len(X_pool))) # 实际中用真实标签
print(f"模型准确率:{final_accuracy:.2f}")
这段代码的核心是ActiveLearner类,它封装了主动学习的流程:初始化模型→选择样本→标注→更新→重复。通过调整n_queries(迭代次数),可以控制标注成本;通过更换estimator(基础模型),可以适应不同任务(如文本分类、图像识别)。
主动学习的实际应用:从文本分类到医疗诊断
主动学习在标注成本高、数据量大的场景中尤为有用,以下是几个典型应用:
1. 自然语言处理(NLP):文本分类与情感分析
在文本分类任务中(如新闻分类、情感分析),数据标注需要人工阅读并判断类别,成本极高。主动学习可以让模型优先选择“难分类”的文本(如包含歧义、多义词的句子),减少标注量。例如,某电商平台用主动学习标注1万条用户评论,相比随机标注,标注量减少了60%,同时分类准确率提升了15%。
2. 计算机视觉:图像分类与目标检测
在图像分类任务中(如医疗影像诊断、自动驾驶),标注需要人工标注边界框或类别,耗时久。主动学习可以让模型选择“分类边界模糊”的图像(如肿瘤边界不清晰的CT片),提高标注效率。例如,某医疗公司用主动学习标注10万张CT片,标注时间从30人月缩短到10人月,同时模型准确率提升了20%。
3. 医疗诊断:疾病预测与病理分析
在医疗领域,数据标注需要专家参与(如病理切片诊断),成本极高且稀缺。主动学习可以让模型优先选择“疑似病例”(如CT片中疑似肿瘤的区域),让专家专注于难样本,提高诊断效率。例如,某医院用主动学习标注1万张病理切片,专家标注时间减少了50%,同时诊断准确率提升了18%。
主动学习的注意事项:避免踩坑
虽然主动学习能提高效率,但如果使用不当,也可能引入问题:
1. 标注员质量:确保标注一致性
主动学习选择的样本往往是“难样本”,需要标注员具备较高的专业水平。如果标注员训练不足或标注不一致,会导致模型学习到错误的知识。因此,需要对标注员进行培训,并建立质量检查机制(如交叉验证标注结果)。
2. 模型更新频率:避免过拟合
主动学习需要频繁更新模型(每次迭代都更新),如果更新频率过高,模型可能会过拟合未标注数据。因此,需要合理设置迭代次数(如每100次迭代评估一次模型性能),并在验证集上监控模型性能。
3. 样本多样性:避免陷入局部最优
主动学习选择的样本可能集中在某个类别或区域(如某类文本的情感倾向),导致模型无法学习到数据的整体分布。因此,需要引入“多样性采样”策略(如选择不同类别、不同特征的样本),确保样本覆盖数据的整体分布。
总结
主动学习是一种“聪明的学习方式”,它通过迭代式地让模型选择“最有信息量”的样本进行标注,大幅减少了标注成本,同时提升了模型性能。在标注成本高、数据量大的场景中(如NLP、计算机视觉、医疗诊断),主动学习能帮助企业用更少的资源实现更好的模型效果。但要注意标注员质量、模型更新频率和样本多样性等问题,才能让主动学习发挥最大的价值。
对于数据标注团队来说,主动学习不仅是提高效率的工具,更是提升标注质量的关键——它让标注员专注于“难样本”,减少了重复劳动,同时让模型学得更准。在未来,随着主动学习算法的不断优化(如结合深度学习的不确定性估计),它将在更多领域发挥重要作用。