李宏毅机器学习笔记18
目录
摘要
Abstract
1.Self attention
输入是什么
输出是什么
2.Self attention如何运作
摘要
本篇文章继续学习李宏毅老师2025春季机器学习课程,学习内容是Self attention相关概念及其计算方法。
Abstract
This article continues the study of Prof. Hung-yi Lee's 2025 Spring Machine Learning Course, focusing on the Self-attention mechanism, related concepts, and its computational methods.
1.Self attention
输入是什么
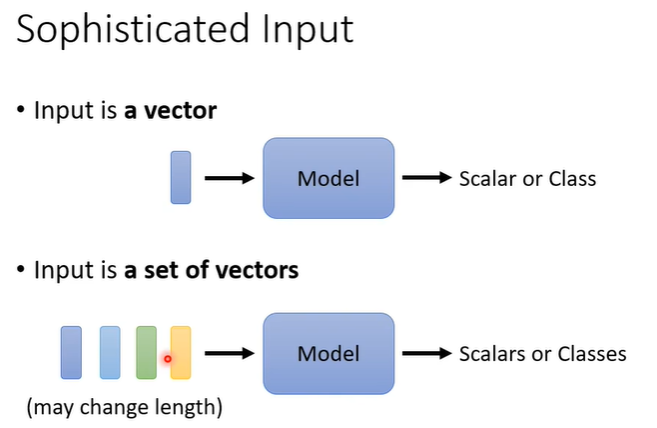
之前我们学习的network的输入都是一个向量,假设遇到更复杂的问题,我们的输入是一排向量,而且输入的向量数目也可能改变,这种时候我们如何处理?
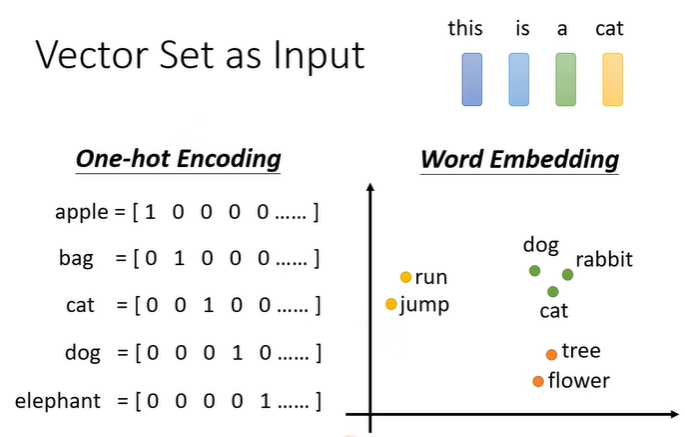
用文字处理作为例子,每个句子的长度都不同,如果把句子里的每一个词汇描述成向量,那我们的输入就会变成不固定数目的一组向量,将词汇变成向量有很多种方法,如上图所示的one-hot encoding,word embedding等。
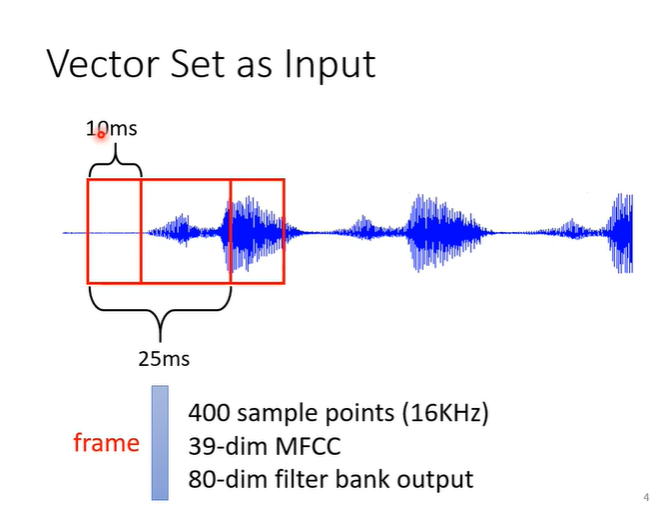
声音处理也可以作为例子,一段声音讯号其实是一排向量,把一段声音取一个范围(windows),把范围内的资讯描述成一个向量(frame),要处理整个声音就把windows向右挪动。
输出是什么
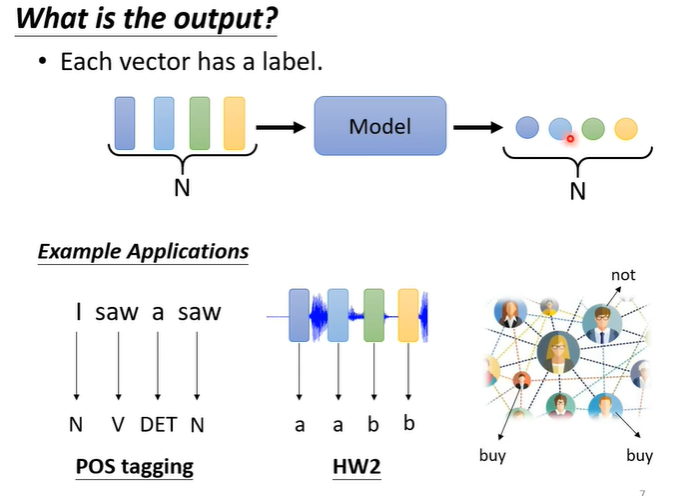
第一种可能是,每一个向量有一个对应的输出,假设输入四个向量,输出可能有四个数值或者是class,在文字处理上可能会用到,例如词性标注等
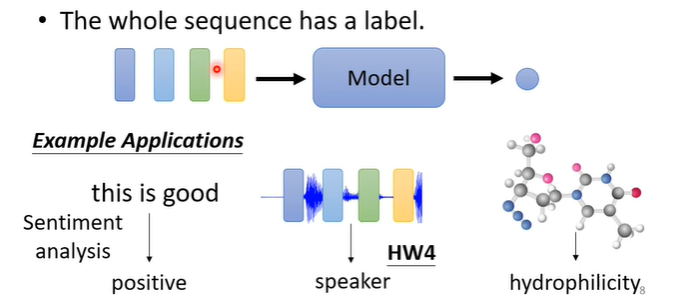
第二种可能是,我们只需要一个输出,无论输入多少个向量,输出只有一个,例如sentiment analysis(分析句子情感是正面或负面),或者是语言辨别,判断是谁说的话等
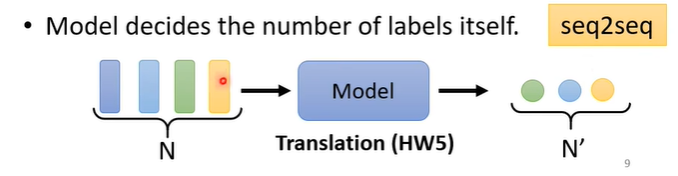
还有第三种可能,我们不知道输出多少,由机器自行判断。输入可能有N个,输出则不固定,例如翻译句子,语言转变为文字等
2.Self attention如何运作
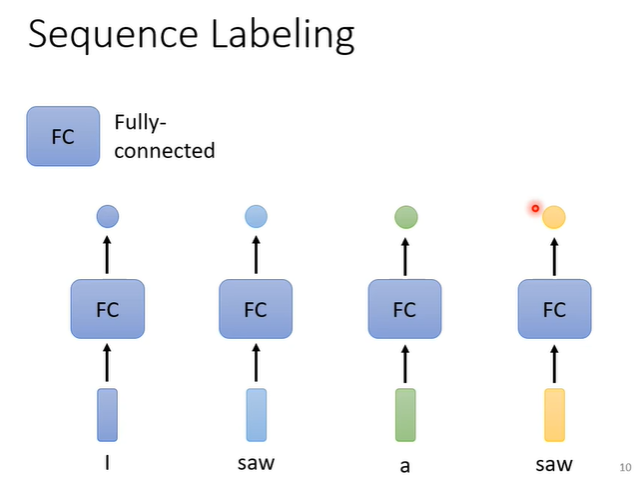
我们着重学习第一种类型,即输入每有一个向量,则有一个对应的输出。对句子中的每一个向量都给它一个label。例如在词性标注时,用fully-connected network处理,但此方法有一个问题,如上图中两个部分输入都为“saw”时,他们的输出是一致的,与我们期望的一个“v”(动词),一个“n”(名词)不相符。
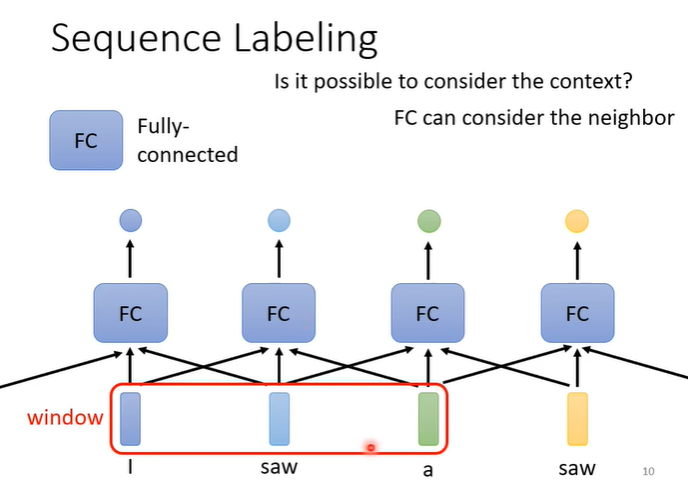
为了避免上面这些问题,我们需要联系上下文,所以可以给FC设置窗口与,将附近的其他向量一起作为输入,增加上下文联系。但是这样仍有一个问题,假设我们需要考虑整个句子,此时窗口无法起作用,这时就需要用到Self attention。
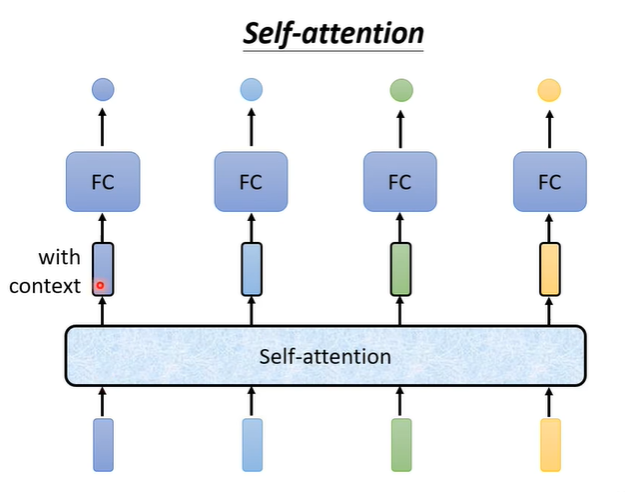
Self attention会把句子的词汇全部作为输入,输出有几个向量,就输出几个向量。他的输出会考虑句子中的每一个输入,再把处理后的输出作为FC的输入,这样FC就不是只考虑部分,而是考虑整个句子。
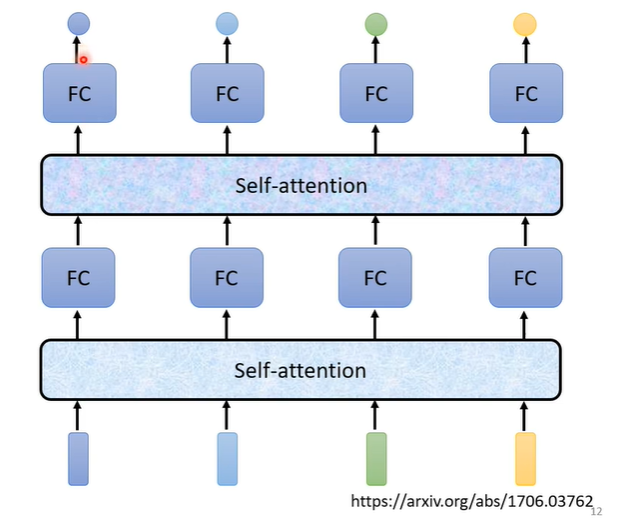
Self attention不是只能用一次,可以用一次Self attention输入FC后再用一次Self attention,再丢到另一个FC中,最后输出结果。
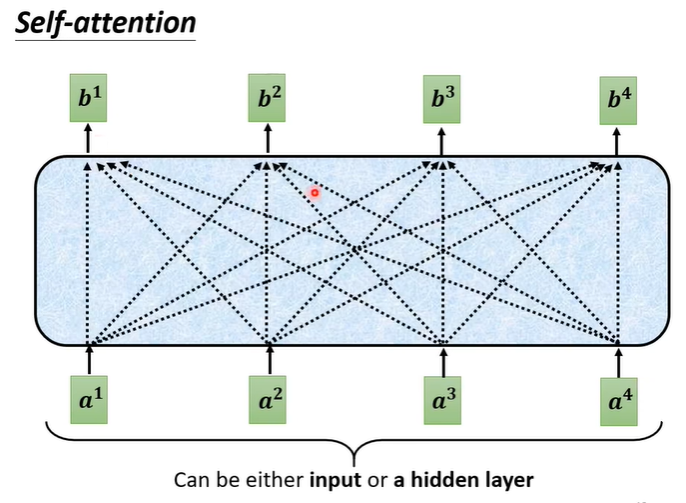
Self attention的每一个输出b都是考虑了每一个输入a的。
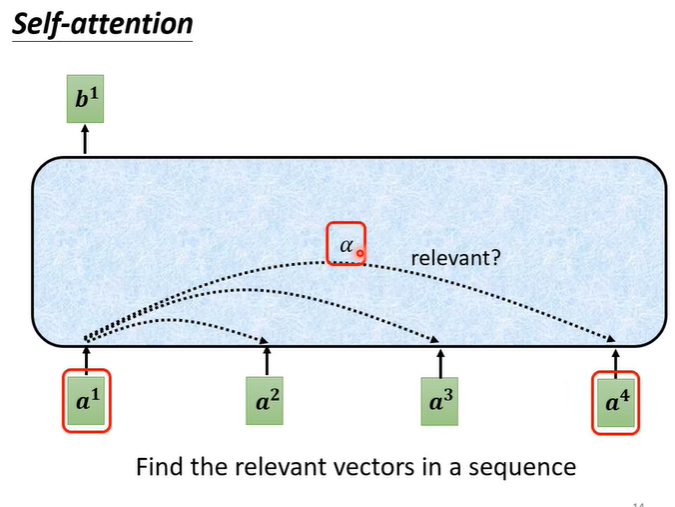
Self attention首先找到a1相关的向量,对于所有输入的向量判断他们的关联度。
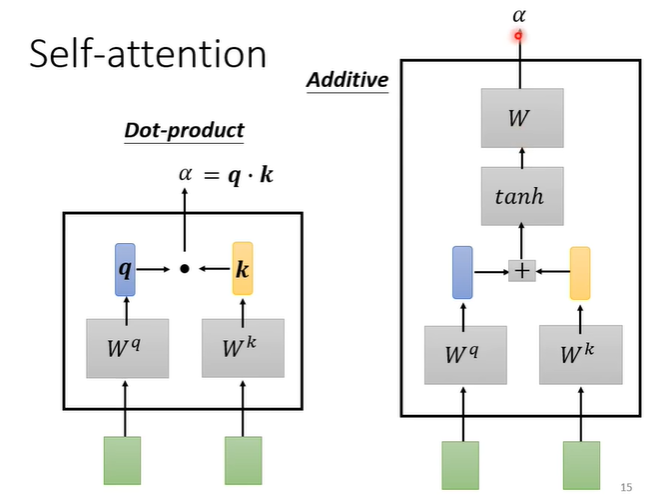
关联度如何计算?常见的做法有Dot-product,将输入的两个向量分别乘上不同的矩阵,假设得到q,k两个向量,然后做点乘;另一种方法是Additive,同样将输入的两个向量分别乘上不同的矩阵,假设得到q,k两个向量,将他们相加后,过一个function再过一个transformer。
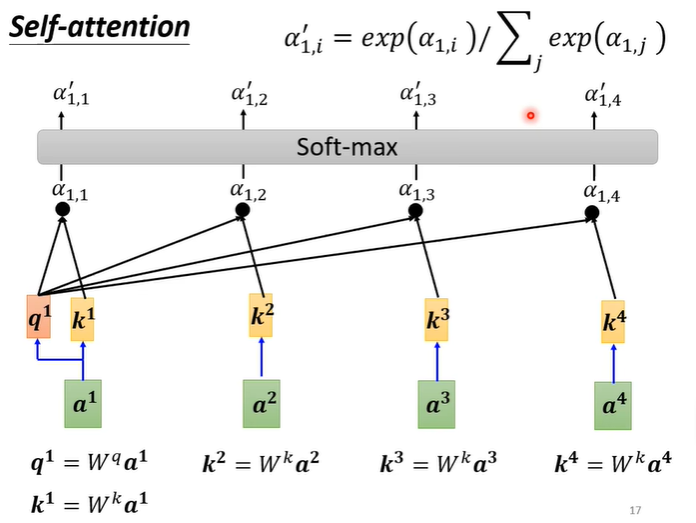
用Dot-product计算a1与其他输入的关联度,计算后需要经soft-max处理,得到。
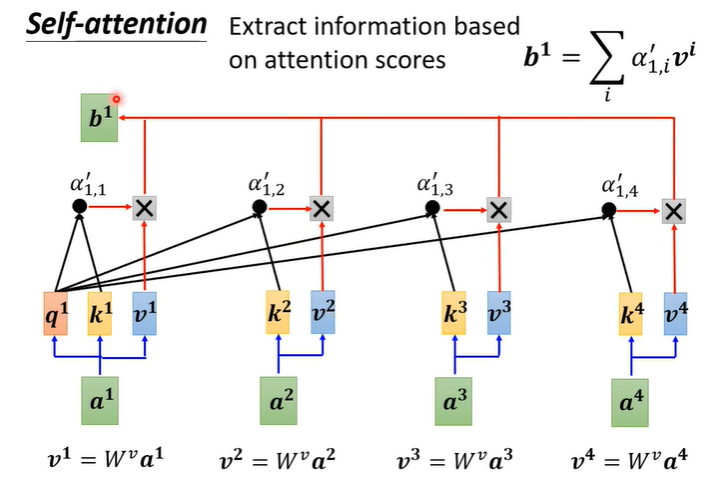
根据关联性抽取重要资讯,将每个输入a乘上得到新的向量v,将v与
相乘,再将所有的向量加起来,谁的关联性
越高,最终的b1就越接近谁的向量v。