重生归来,我要成功 Python 高手--day24 Pandas介绍,属性,方法,数据类型,基本数据操作,排序,算术和逻辑运算,自定义运算
Pandas
df为DataFarme的对象由多个Series组成,而Series是DataFarme的列对象
Series由索引和值组成
创建Series对象的方式:
列表创建:
# 列表转化为创建series对象 s1=pd.Series(['a','b','c']) print(s1) # 自定义索引 s2=pd.Series(['a','b','c'],index=['1','2','3']) print(s2)
字典创建:
# 字典
s=pd.Series({'a':1,'b':2,'c':3})
s元组转化:
# 元组转化 s4=pd.Series((11,22,33,44)) s4
adarry转化:
#adarry转化 s5=pd.Series(np.arange(5)) s5
Series属性:索引和值:
values和index
# 属性 s6=pd.Series(data=[i for i in range(6)],index=[i for i in 'ABCDEF']) s6 # 获取索引和值 print(s6.index) print(s6.values)
根据索引修改值:
# 根据索引修改值 print(s6["C"]) s6["F"]=99 s6
DataFarme:
类似于二维数组或者表格对象:
行索引:横向索引叫index
列索引:纵向索引叫columns
创建DataFarme对象的方式:
1.直接读取文件
df=pd.read_csv("文件路径”,encoding=‘解码集’)
2.字典加列表创建
info={'name':['张三','李四','王五'],'gender':['男','女','男'],'age':[21,22,33],
}df1=pd.DataFrame(info) df1
3.列表加元组
info2=[('张三','男',43),('王五','男',23),('李四','男',53)
]
df2=pd.DataFrame(info2,columns=['name','gender','age'])
df24.ndarry来创建
# ndarry来创建DataFarme对象arr1=np.arange(12).reshape(3,4) df3=pd.DataFrame(arr1,columns=['a','b','c','e']) df3
案例:
# 案例 10行五列拼接 arr2=np.random.randint(40,101,size=(10,5)) #改为对象 df4=pd.DataFrame(arr2)#添加列名(0-4)和索引值(0-9) # 列名: colunm_names=['语文','数学','英语','物理','化学'] # 索引值: index_names=[ '同学'+str(i) for i in range(df4.shape[0])]df4.columns=colunm_names df4.index=index_names df4
DataFrame对象的属性
形状:df.shape
df4.shape
行索引:df.index
df4.index
列索引:df.columns
df4.columns
获取值:df.values
df4.values
转置:(行转列,列转行)df.T
df4.T
对象方法:
获取前多少行:
#前五行 df4.head(5)
获取后多少行:
#后五行 df4.tail(5)
详细信息:
# 查看详情 df4.info()
统计信息:
# 查看统计信息 df4.describe()
重置索引:
drop默认为Fales:添加新的索引原索引添加到表中
True:删除原索引添加新的索引
#重置原索引 df4.reset_index(drop=True)
以某个列为索引:
df4.set_index('语文')Pandas的数据类型:
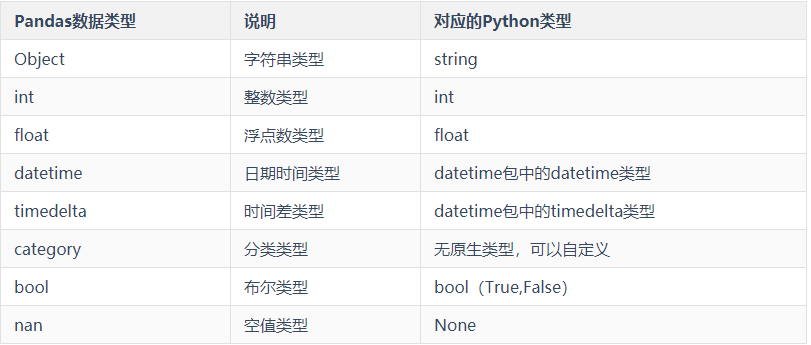
Pandas的基本数据操作:
获取数据:
获取数据必须是先列后行
df['high']['2018-02-27']
使用loc和iloc获取数据
loc:[行索引,列名]
# 结合loc为 行索引,列名 df.loc['2018-02-27','close'] #24.16 # 取范围df.loc['2018-02-27':'2018-02-14','open':'low']
iloc:[行号,列索引]
# 结合iloc 行号,列索引 df.iloc[0:5,0:2]
排序:默认值为升序True False:为降序
值排序:
单值排序:
# 单值排序,True 为升序,false为降序
df.sort_values('close',ascending=False)多值排序:
df.sort_values(['open','high'],ascending=[False,False])
索引排序
#索引排序 df.sort_index(ascending=True)
Series对象的排序:
# Series对象,索引排序 df.open.sort_index(ascending=False)
#值排序 df.open.sort_values(ascending=True)
算数运算:
# 算数运算符 df.close+2
逻辑运算:
# 大于 df[df.open>23]
逻辑运算函数:
并且需要使用” & “符号
df.query:
# open大于23并且小于24
df.query('open>23 & open<24')统计函数:
与numpy相同
# 计算平均值、标准差、最大值、最小值
data.describe()
min(最小值), max(最大值), mean(平均值), median(中位数), var(方差), std(标准差),mode(众数)
自定义运算:
apply(函数名,axis=0) 默认为列
axis=1对行进行操作,axis=0对列进行操作
可以使用lambda表达式:
lambda loc : loc.max()-loc.min()
def func(clo):return clo.max()-clo.min()
df[['open','close']].apply(func)