深度学习之模型的部署、web框架 服务端及客户端案例
目录
简介
一、模型部署的介绍
1、模型部署的定义与目的
2、模型部署的步骤
3、模型部署的方式
二、web框架对比
1、Django
2、Pyramid
3、Flask
三、代码实现
简介
在深度学习技术落地的全链路中,“模型部署” 是连接算法研发与实际应用的关键桥梁 —— 即便拥有精度卓越的模型,若无法高效、稳定地集成到生产环境,其价值也难以真正释放。本文将聚焦深度学习模型部署的核心环节,结合 Web 技术栈,从服务端架构设计到客户端交互实现,用案例驱动的方式拆解全流程实践。
一、模型部署的介绍
1、模型部署的定义与目的
模型部署是指将模型运行在专属的计算资源上,使模型在独立的运行环境中高效、可靠地运行,并为业务应用提供推理服务。其目标是将机器学习模型应用于实际业务中,使最终用户或系统能够利用模型的输出,从而发挥其作用。
2、模型部署的步骤
- 导出模型:将训练好的模型导出为可部署的格式。
- 部署模型:将导出的模型部署到生产环境中,通常是以一个服务或一个库的形式。
- 测试模型:在生产环境中对模型进行测试,以确保其能够正常工作,并且输出结果符合预期。
- 监控模型:在生产环境中对模型进行监控,以便及时发现并解决问题。
3、模型部署的方式
模型的部署方式多种多样,可以根据具体的应用场景和需求而定。以下是一些常见的模型部署方式:
云端部署:将模型部署到云端服务器上,通过API接口提供服务,实现远程调用。这种方式可以实现大规模的分布式计算和存储,同时提供高可用性和可扩展性。在云端部署中,需要考虑数据的安全性和隐私保护,以及模型的并发处理能力。
嵌入式设备部署:将模型部署到嵌入式设备中,如智能手机、智能音箱、智能家居等。这种方式可以实现本地化的智能化应用,具有实时性、低延迟的优点。在嵌入式设备部署中,需要考虑设备的计算能力、存储空间等限制,以及模型的轻量化设计。
边缘计算部署:将模型部署到边缘设备上,如路由器、摄像头等。这种方式可以实现本地数据的实时处理和智能化分析,减少数据传输的延迟和成本。在边缘计算部署中,需要考虑设备的计算能力和数据处理能力,以及模型的实时性要求。
移动端部署:将模型部署到移动端设备上,如智能手机、平板电脑等。这种方式可以实现移动设备的智能化应用,提高用户体验。在移动端部署中,需要考虑设备的功耗和性能限制,以及模型的轻量化设计。
FPGA和GPU部署:FPGA(Field-Programmable Gate Array)部署是将深度学习模型部署到FPGA芯片上,实现高效的硬件加速,提高模型的运行速度和效率。GPU(Graphics Processing Unit)部署是将深度学习模型部署到GPU上,利用GPU的并行计算能力,提高模型的运行速度和效率。这两种方式适用于对计算性能要求较高的场景,如实时图像处理、视频分析等。
二、web框架对比
Django、Pyramid和Flask都是Python中流行的Web框架,它们各自具有独特的优点和缺点。以下是它们各自优缺点的详细比
1、Django
Django 优点: 功能全面:Django是一个“全包式”的框架,提供了丰富的内置功能,如ORM(对象关系映射)、用户认证、内容管理等,非常适合快速开发。 文档完善:Django的官方文档非常详细,易于理解,对于新手来说非常友好。 社区支持强大:Django拥有一个庞大的社区和大量的第三方包可供选择,这使得开发者能够轻松地找到解决方案和支持。 安全性高:Django具有集成的安全功能,如防止跨站请求伪造(CSRF)和SQL注入攻击的机制,能够最大程度地保护系统的安全性。
缺点: 学习曲线较陡:对于初学者来说,Django提供的功能可能会显得过于复杂,需要一定的时间去学习和掌握。 灵活性较低:由于Django的全包式设计,它在一些情况下可能不如其他框架灵活。 性能问题:在处理高负载应用程序时,Django的性能可能不如一些轻量级的框架。
2、Pyramid
优点: 灵活性和可扩展性:Pyramid的设计哲学是“尽可能少地强制开发人员做出选择”,它提供了一组基本的工具和功能,但允许开发人员根据项目需求选择使用的组件和库。 高性能:Pyramid在设计上注重性能,采用了一些优化技术,如延迟加载和缓存机制,以提供快速响应和高并发处理能力。 适用于大型应用程序:由于Pyramid的灵活性和可扩展性,它非常适合构建大型和复杂的Web应用程序。
缺点: 社区及资源相对较少:与Django和Flask相比,Pyramid的社区和第三方资源可能较少。 学习曲线:虽然Pyramid提供了灵活的选择,但对于初学者来说,可能需要更多的时间来理解和选择适合项目的组件和库。
3、Flask
优点: 轻量级:Flask是一个轻量级的框架,代码量少,灵活性高,适合快速开发小型应用程序。 简单易学:Flask的设计理念简洁明了,入门相对容易,对于初学者来说非常友好。 可扩展性强:Flask提供了丰富的扩展库,开发者可以根据需求选择合适的扩展来扩展功能。 社区支持良好:Flask有一个庞大的社区,提供了丰富的资源和支持。
缺点: 功能相对较少:相比于一些大型框架如Django,Flask的功能相对较少,需要依赖扩展库来实现一些功能。 安全性考虑:由于Flask的轻量级特性,安全性方面的考虑需要开发者自行关注。 不适合大型应用:由于Flask的轻量级特性,它可能不适合开发大型复杂的应用程序。 综上所述,Django、Pyramid和Flask各有其优缺点,选择哪个框架取决于项目的具体需求、开发者的偏好和经验水平。
三、代码实现
我从网上找到人家用残差网络(ResNet)训练好的关于花朵识别的模型并下载了他训练好的权重文件
一共包含102种花朵的种类的识别
部署模型我们分为客户端和服务端
服务端就是我们把模型部署在服务器里面,这样用户就可以通过客户端访问,经过模型预测就可以得到识别的结果
客户端就是用户访问服务器传入图片进行检测等待识别的花朵
flask_server.py
import io
import flask
import torch
import torch.nn.functional as F
from PIL import Image
from torch import nn
from torchvision import transforms, models, datasetsapp = flask.Flask(__name__) # 创建一个新的Flask应用程序实例
# __name__参数通常被传递给Flask应用程序来定位应用程序的根路径,这样FlasK就可以知道在哪里找到模板、静态文件等。
# 总体来说app = flask.Flask(__name_)是Flask应用程序的起点。它初始化了一个新的Flask应用程序实例。为后续添加路由、配置model = None
use_gpu = False# 加载模型进来
def load_model():global modelmodel = models.resnet18() # 导入残差网络模型18层num_ftrs = model.fc.in_features # 返回原模型最后一层全连接层的输入特征数量model.fc = nn.Sequential(nn.Linear(num_ftrs, 102)) # 替换原模型最后一层,为一个线性层,输出层为102个类别,因为总的类别有102中checkpoints = torch.load('best.pth') # 加载训练好的模型权重model.load_state_dict(checkpoints['state_dict']) # 将加载好的权重应用到模型上,model.eval() # 模型设置为测试模式if use_gpu: # 如果为Truemodel.cuda() # 将模型传入GPU# 数据预处理
def prepare_image(image, target_size): # 输入图像、以及指定尺寸# 针对不同模型,image的格式不同,但需要统一到RGB格式if image.mode != 'RGB': # 判断图像是不是RGB彩色图image = image.convert('RGB') # 如果不是,将其转化为RGB格式# 按照所使用的模型将输入图片的尺寸修改,并转为tensorimage = transforms.Resize(target_size)(image) # 调整图像大小为指定尺寸image = transforms.ToTensor()(image) # 将图像转化为PyTorch,同时图像像素值变成0-1.0之间# 对图像进行标准化,第一个列表为RGB三通道均值,第二个为标准差image = transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])(image)# 增加一个维度,用于按batch测试image = image[None]if use_gpu:image = image.cuda()return torch.tensor(image)# 是一个装饰器,用于将指定的URL路径(在这个例子中是/predict)与一个函数关联起来,并指定该函数响应的HTTP方法(在这个例子中是POST方注
@app.route('/predict', methods=['POST'])
def predict():# 做一个标志,刚开始无图像传入时为false,传入图像时为truedata = {"success": False}if flask.request.method == "POST":if flask.request.files.get('image'): # 判断是否为图像image = flask.request.files["image"].read() # 将收到的图像进行读取,内容为二进制image = Image.open(io.BytesIO(image)) # io.BytesIO是Python标准库io模块中的一个类,它提供了一个在内存中读写bytes的缓冲区,既可以作为二进制数据的输入源(类似于文件),也可以作为输出目标。# 当io.BytesIO(image)被调用时,它创建了一个内存中的二进制流,并将原始的image bytes数据写入这个流中。# 然后,Image.open(io.BytesIO(image))打开这个内存中的二进制流,就像打开一个实际的图像文件一样,并返回一个可用于进一步处理的图像对象。# 利用上面的预处理函数将读入的图像进行预处理image = prepare_image(image, target_size=(224, 224))preds = F.softmax(model(image), dim=1) # 得到各个类别的概率results = torch.topk(preds.cpu().data, k=3, dim=1) # 概率最大的前3个结果# torch.topk用于返回输入张量中每行最大的k个元素及其对应的索引results = (results[0].cpu().numpy(), results[1].cpu().numpy())# 将data字典增加一个key,value,其中value为ist格式data['predictions'] = list()for prob, label in zip(results[0][0], results[1][0]):# Label name =idx2labellstr(label)]r = {"label": str(label), "probability": float(prob)}# 将预测结果添加至data字典data['predictions'].append(r)# Indicate that the reguest was a success.data["success"] = Truereturn flask.jsonify(data) # 将最后结果以json格式文件传出if __name__ == '__main__':print("Loading PyTorch model and Flask starting server ...")print('Please wait until server has fully started')load_model() # 先加载模型# 再开启服务app.run(host='192.168.2.5', port=5012) # 用自己的电脑,端口号为5012 这个程序。服务器,进入了聆听状态,等待客户发送请求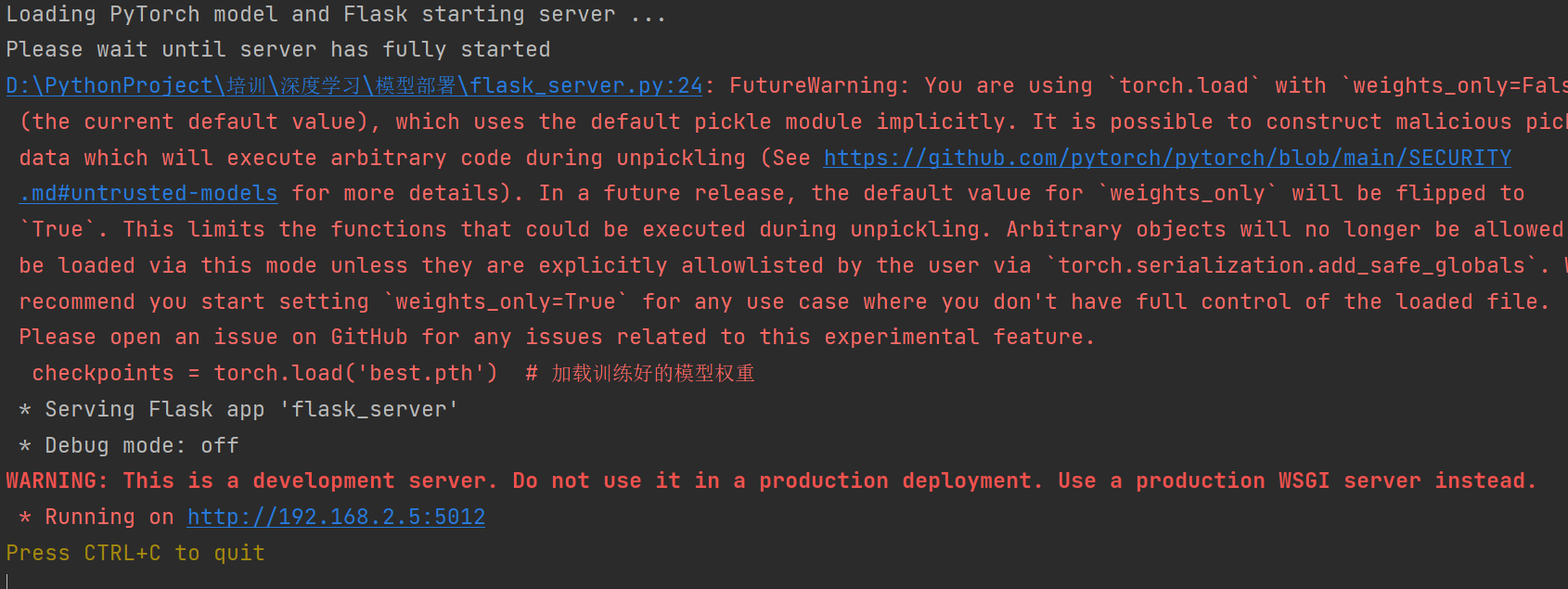
这样就是启动了服务端在等待传入信息
flask_predict.py
import requestsflask_url = 'http://192.168.2.116:5012/predict' # 设置需要读取的服务器地址def predict_result(image_path):image = open(image_path, 'rb').read()payload = {'image': image}r = requests.post(flask_url, files=payload).json() # 发送post请求,输入当前ip和图片,然后返回的结果转化为json大字符串类型# print(r)if r['success']:for (i, result) in enumerate(r['predictions']):print("{}.预测类别为{}:的概率:{}".format(i + 1, result['label'], result['probability']))else:print("request failed")if __name__ == '__main__':predict_result('./flower_data/val_filelist/image_00059.jpg')# predict_result('train/6/image_07168.jpg')
我们从客户端传入一张图片,得到的结果(这里我设置的是返回最高的三个,不难看出来第一个的概率远远大于后面)