论文阅读:arxiv 2025 Scaling Laws for Differentially Private Language Models
总目录 大模型相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
https://arxiv.org/pdf/2501.18914
https://www.doubao.com/chat/23868523227442434
VaultGemma:谷歌开源的首个隐私保护大模型,意味着什么?
VaultGemma: The world’s most capable differentially private LLM
速览
这篇论文核心是解决“带隐私保护的大语言模型该怎么训练才高效”的问题:
我们都知道大语言模型(比如GPT、BERT)越练越好用,背后有一套“ scaling laws(缩放规律)”——比如模型参数越多、训练数据越多、算力投入越大,效果通常越好,这套规律能帮我们少走弯路,不用瞎试超参数。但这里有个麻烦:训练模型的很多数据是用户的敏感信息(比如聊天记录、个人内容),直接用会泄露隐私,所以得加“差分隐私(DP)”保护——简单说就是给训练过程加适量“ noise(噪声)”,让模型学不到具体个人的数据,但又能学到整体规律。
可问题来了:加了差分隐私后,之前那套“缩放规律”就不管用了。比如非隐私训练时“模型越大越好”,但加了隐私保护后,模型太大反而可能效果差、算力浪费;而且隐私训练还多了新变量——比如“隐私预算(ε,噪声加多少)”“数据预算(多少用户的数据)”,这些都得和“算力预算”一起考虑,之前没人搞清楚这里面的规律。
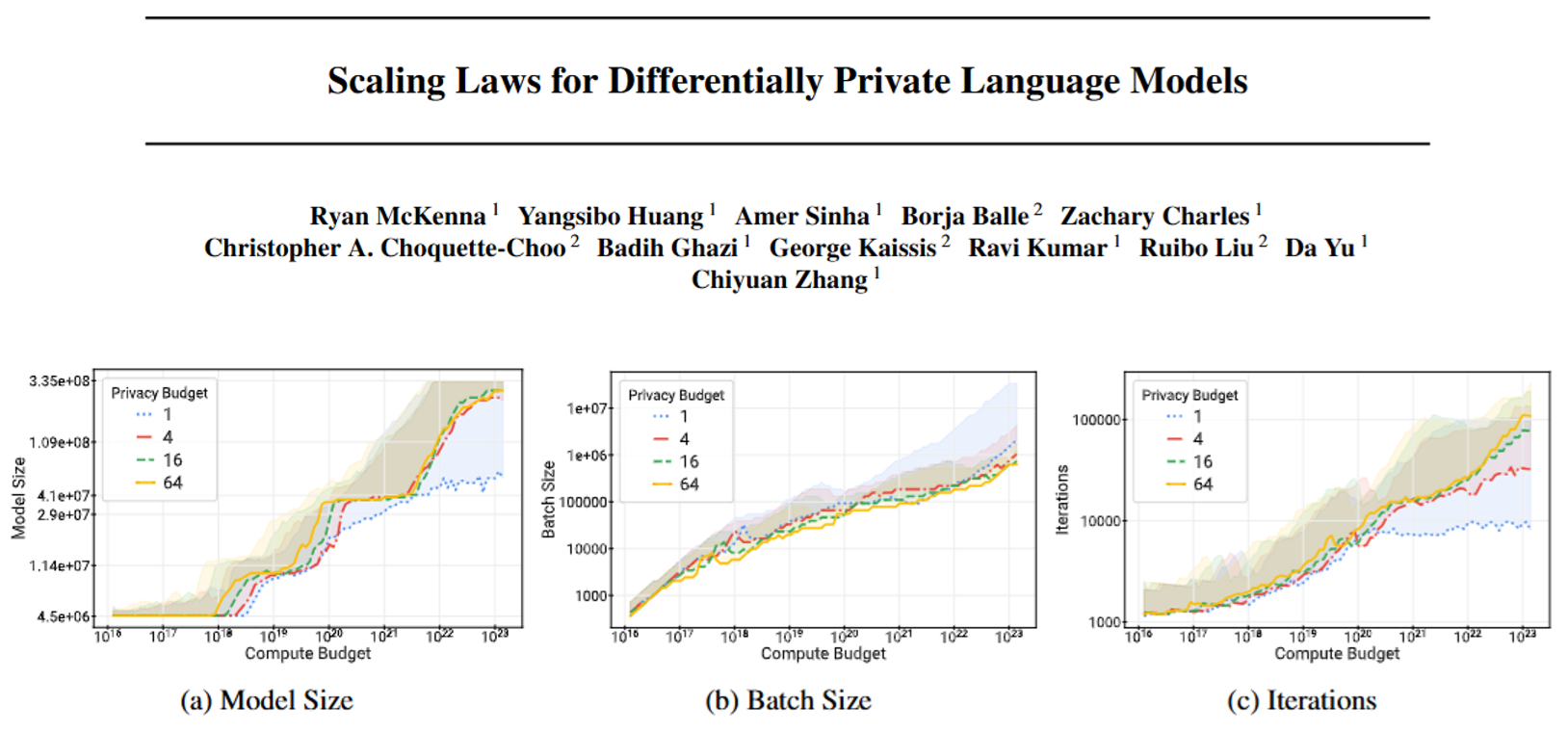
所以这篇论文干的事,就是重新搞一套“带隐私保护的缩放规律”,帮大家搞明白:在有隐私要求的情况下,该怎么分配算力(比如模型做多大、每次训练用多少数据 batch、练多少轮)、隐私预算、数据预算,才能让模型效果好、隐私不泄露、还不浪费算力。
他们具体做了这些事,也发现了几个关键结论:
-
非隐私的规律在隐私训练里完全不适用:哪怕给的隐私预算很宽松(比如噪声很少),按非隐私那套来分配算力(比如搞个超大模型),效果也会差很多,必须用新规律。
-
能找到“最优训练配置”,算力能省5~100倍:比如同样的隐私保护水平和效果,按他们找的规律来调(比如模型做小一点、batch 调大一点、训练轮次调整),比瞎试的“ baseline(基础方案)”能少用5到100倍的算力。
-
带隐私的模型,最优大小比不带隐私的小很多:比如非隐私训练时可能最优是100亿参数,带隐私保护后,最优可能只有10亿参数——这也解释了为啥现在带隐私的大模型最多就几亿参数,很难做到几十亿、几百亿,因为大了反而不划算。
-
算力不是加得越多越好,得配着隐私和数据一起加:非隐私训练时,只要算力够,一直加总能提升效果;但带隐私时,光加算力没用——比如隐私预算没给够、数据量没跟上,就算堆再多显卡,模型效果也不会变好,会遇到“瓶颈”。
为了搞出这套规律,他们还做了具体实验:用不同大小的BERT模型(从450万参数到7.78亿参数),试了18种不同的噪声强度、3种学习率、固定batch大小,再用数据处理和数学模型拟合出规律,最后还验证了——按这套规律调出来的模型,确实比之前的基础方案更省算力、效果更好。
总结一下:这篇论文相当于给“带隐私保护的大语言模型训练”画了一张“攻略图”,告诉大家在有隐私要求时,该怎么平衡“效果、隐私、算力”,不用再盲目试参数,也为以后练更大的隐私模型(比如几十亿参数)铺了路。