LLMs之Ling:Ling-1T的简介、安装和使用方法、案例应用之详细攻略
LLMs之Ling:Ling-1T的简介、安装和使用方法、案例应用之详细攻略
目录
Ling-1T的简介
1、特点
Ling-1T的安装和使用方法
1、安装
2、使用方法
T1、在线体验 (Try Online)
T2、API 使用 (API Usage)
T3、Hugging Face Transformers
3、部署 (Deployment)
a. vLLM 部署
b. SGLang 部署
Ling-1T的案例应用
Ling-1T的简介
2025年10月3日,inclusionAI发布Ling-1T。Ling-1T 是 Ling 2.0 系列中的第一个旗舰级“非思维”(non-thinking)模型。
>> 参数规模:拥有 1 万亿总参数,每 token 约有 500 亿活跃参数。
>> 架构基础:基于 Ling 2.0 架构构建,旨在推动高效推理和可扩展认知的极限。
>> 预训练数据:经过 20 万亿以上高质量、推理密集型 token 的预训练。
>> 上下文长度:Ling-1T-base 支持高达 128K 的上下文长度(通过 YaRN 扩展)。
>> 优化过程: 在中期训练和后期训练中采用了进化式思维链 (Evo-CoT) 过程,极大地增强了模型的效率和推理深度。
HuggingFace地址:https://huggingface.co/inclusionAI/Ling-1T
1、特点
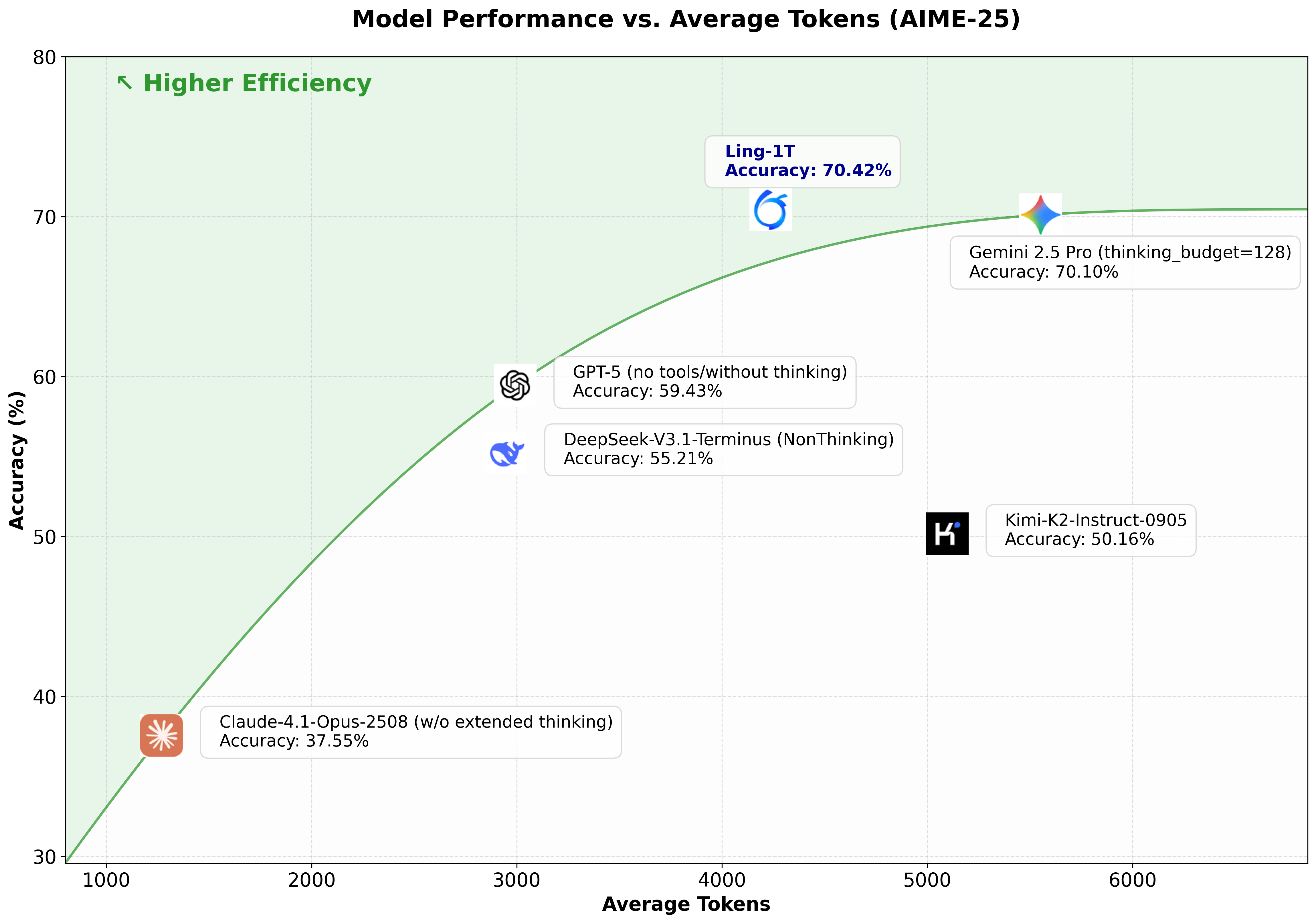
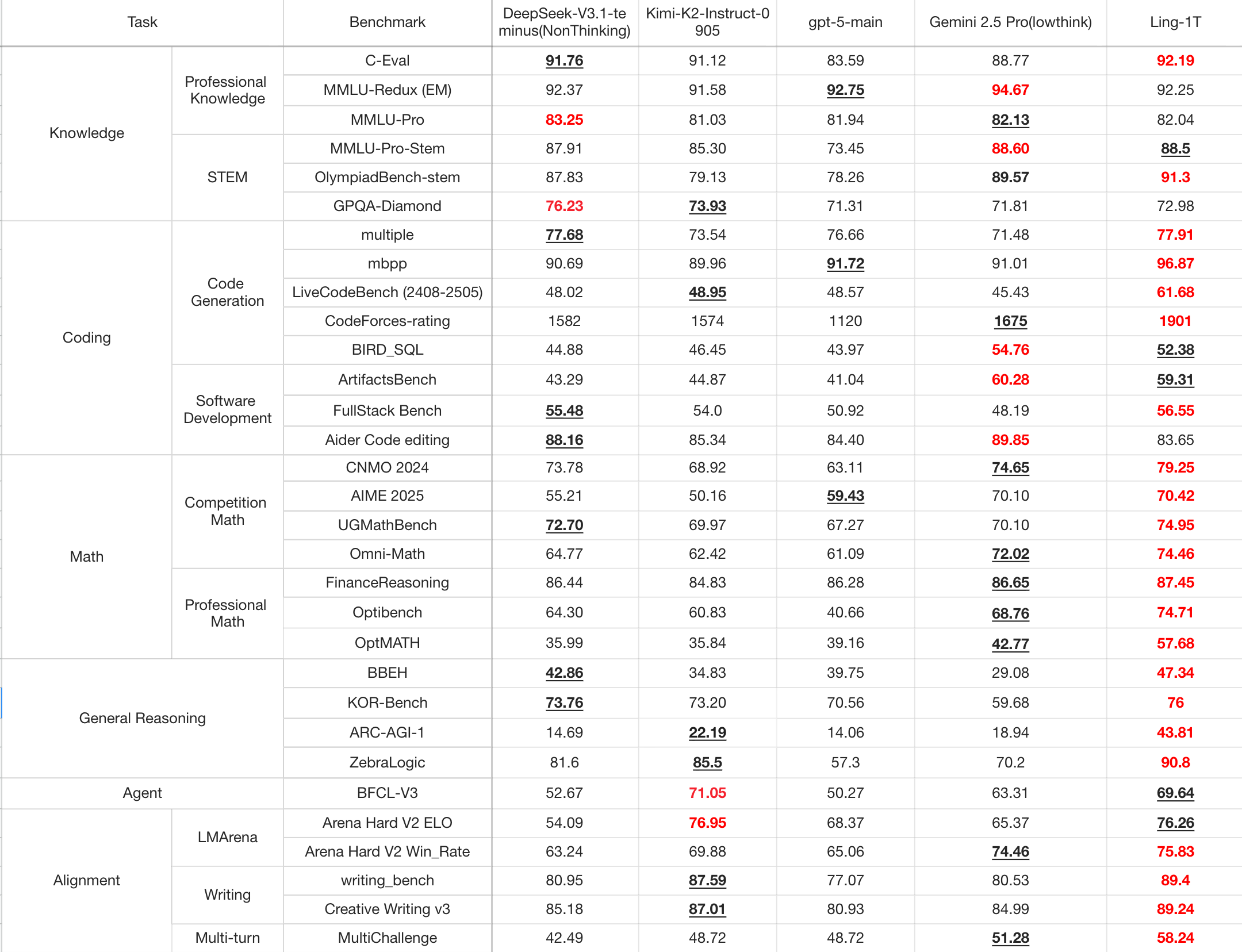
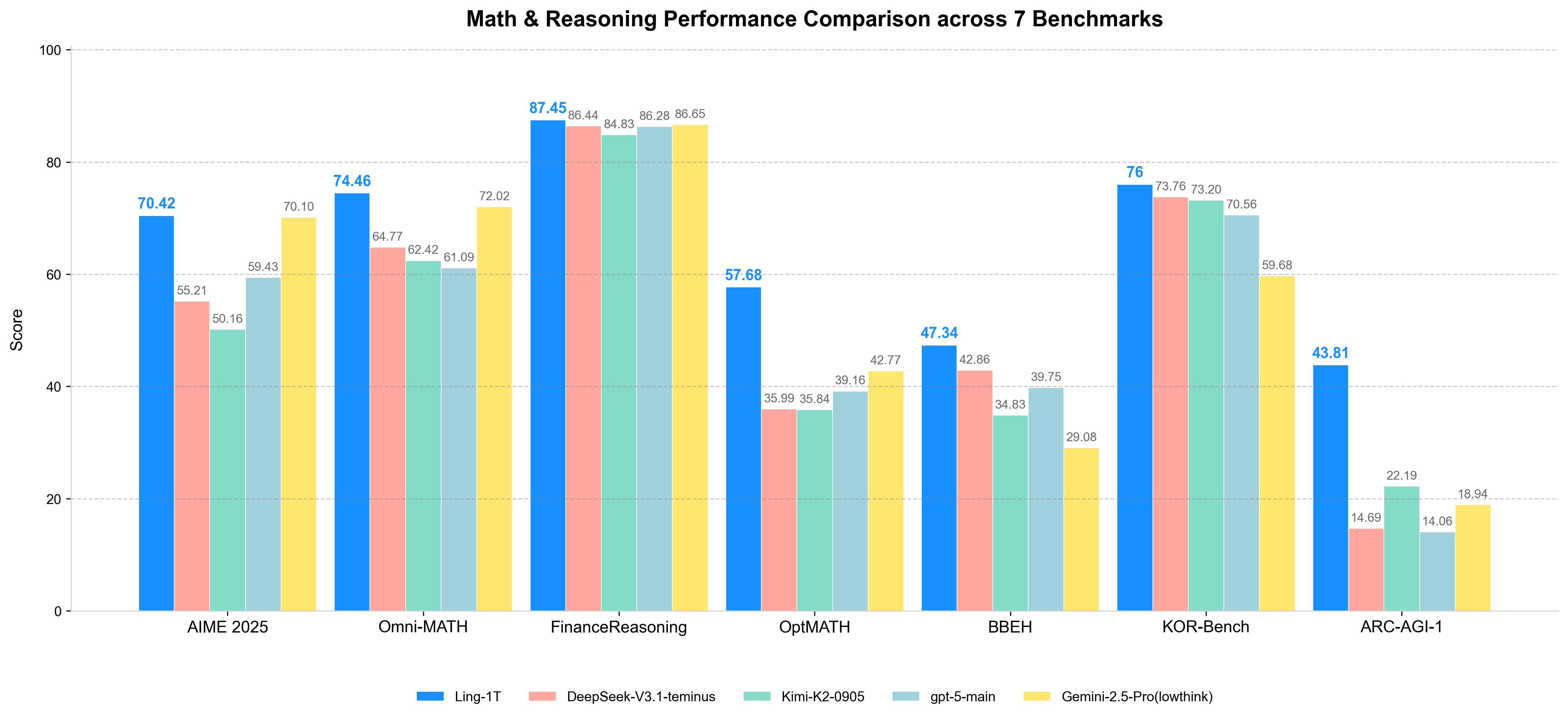
>> 旗舰级高效推理 (Flagship-Level Efficient Reasoning): 在多个复杂推理基准上实现了最先进的性能,平衡了准确性和效率。在代码生成、软件开发、竞赛级数学、专业数学和逻辑推理方面,持续展现出卓越的复杂推理能力和整体优势。在 AIME 25 基准测试中,扩展了推理准确性与推理长度的帕累托前沿,展示了其在“高效思维和精确推理”方面的实力。
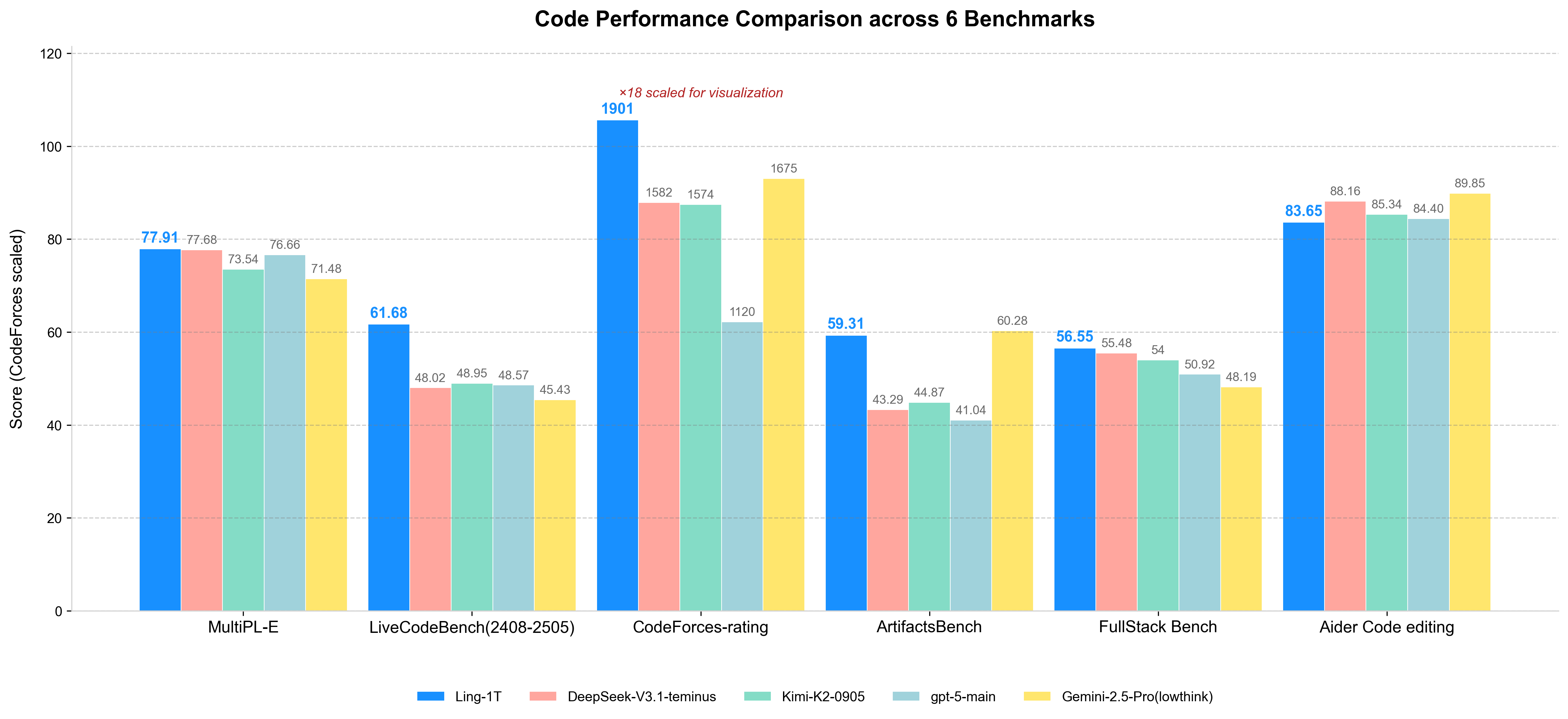
>> 美学理解与前端生成 (Aesthetic Understanding and Front-End Generation): 擅长视觉推理和前端代码生成任务,结合了深度语义理解和精确代码合成。引入了混合的 语法–功能–美学 (Syntax–Function–Aesthetics) 奖励机制,使模型不仅能生成正确和功能性的代码,还能展现出精致的视觉美感。在 ArtifactsBench 上,Ling-1T 在开源模型中排名第一。
>> 万亿规模下的涌现智能 (Emergent Intelligence at Trillion-Scale)
涌现能力: 扩展到万亿参数级别展现出强大的涌现推理和迁移能力。
工具使用: 在 BFCL V3 工具使用基准上,仅通过轻量级的指令调优,就达到了约 70% 的工具调用准确率。
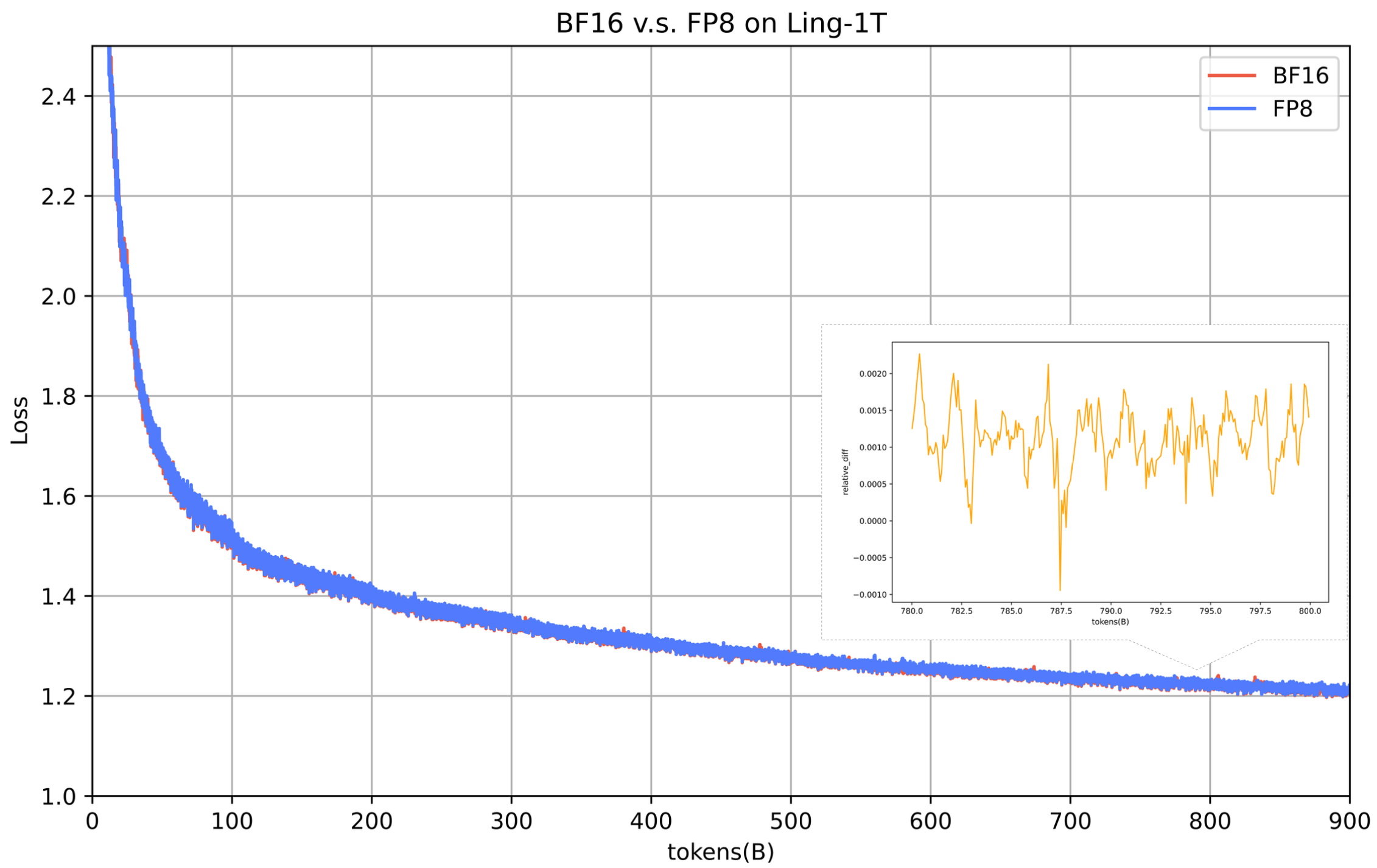
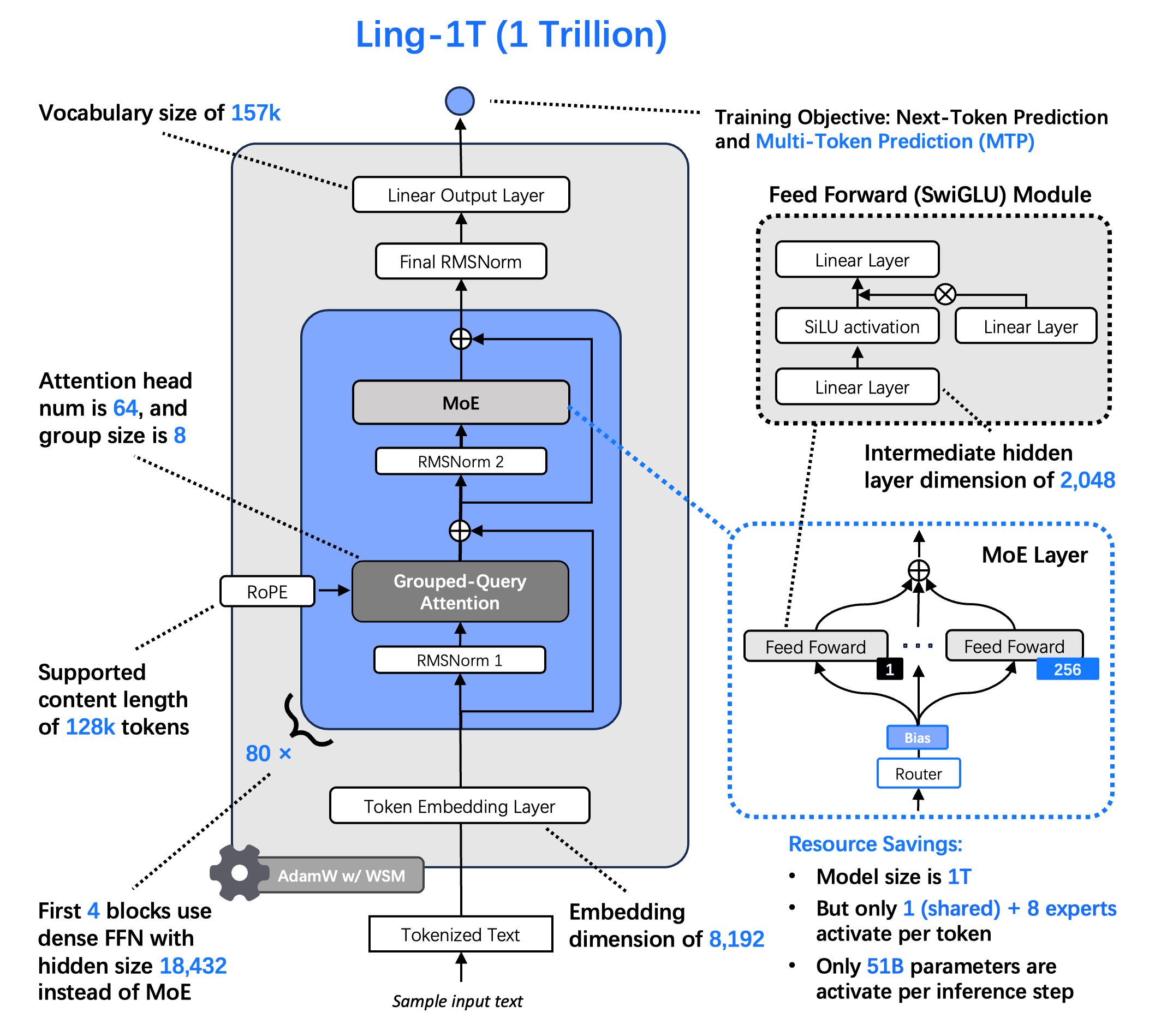
>> 架构与训练创新 (Architecture and Training Innovations): Ling 2.0 架构从头开始设计,以实现万亿规模的效率,遵循 Ling 定律 (Ling Scaling Law, arXiv:2507.17702)。 采用 1T 总参数 / 50B 活跃参数,MoE 激活比例为 1/32。采用 MTP 层以增强组合推理能力;采用无辅助损失 (Aux-loss-free)、Sigmoid 评分的专家路由,并带有零均值更新;采用 QK 归一化以实现完全稳定的收敛。 是迄今为止已知最大的 FP8 训练基础模型。FP8 混合精度训练提供了 15%+ 的端到端加速和改进的内存效率,且在 1T tokens 上与 BF16 的损失偏差保持在 ≤ 0.1%。
>> 优化策略: 采用自定义的 WSM (Warmup–Stable–Merge) 学习率调度器(arXiv:2507.17634),并引入 LPO (Linguistics-Unit Policy Optimization)(一种新颖的句子级策略优化方法),以实现卓越的训练稳定性和泛化能力。
2、架构
3、模型效果
Ling-1T的安装和使用方法
1、安装
HuggingFace地址:https://huggingface.co/inclusionAI
ModelScope地址:https://modelscope.cn/organization/inclusionAI
对于中国大陆用户,官方推荐使用 ModelScope 来加速下载和使用模型。
2、使用方法
T1、在线体验 (Try Online)
可以通过 ZenMux 在线体验 Ling-1T。
地址:https://zenmux.ai/inclusionai/ling-1t?utm_source=hf_inclusionAI
T2、API 使用 (API Usage)
可以使用兼容 OpenAI 的客户端进行 API 调用,将 base_url 指向 ZenMux 端点:https://zenmux.ai/api/v1,模型名称为 "inclusionai/ling-1t"。
from openai import OpenAI# 1. Initialize the OpenAI client
client = OpenAI(# 2. Point the base URL to the ZenMux endpointbase_url="https://zenmux.ai/api/v1",# 3. Replace with the API Key from your ZenMux user consoleapi_key="<your ZENMUX_API_KEY>",
)# 4. Make a request
completion = client.chat.completions.create(# 5. Specify the model to use in the format "provider/model-name"model="inclusionai/ling-1t",messages=[{"role": "user","content": "What is the meaning of life?"}]
)print(completion.choices[0].message.content)
T3、Hugging Face Transformers
使用 transformers 库中的 AutoModelForCausalLM 和 AutoTokenizer 进行推理。
需要设置 model_name = "inclusionAI/Ling-1T",并确保设置 trust_remote_code=True。
from transformers import AutoModelForCausalLM, AutoTokenizermodel_name = "inclusionAI/Ling-1T"model = AutoModelForCausalLM.from_pretrained(model_name,dtype="auto",device_map="auto",trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_name)prompt = "Give me a short introduction to large language models."
messages = [{"role": "system", "content": "You are Ling, an assistant created by inclusionAI"},{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt", return_token_type_ids=False).to(model.device)generated_ids = model.generate(**model_inputs,max_new_tokens=512
)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
3、部署 (Deployment)
a. vLLM 部署
环境准备: pip install vllm==0.11.0。
功能: 支持离线批处理推理或启动兼容 OpenAI 的 API 服务进行在线推理。
长上下文支持 (YaRN):
需要修改模型 config.json 文件,添加 rope_scaling 字段(例如,"factor": 4.0, "original_max_position_embeddings": 32768, "type": "yarn")。
启动 vLLM 服务时,使用额外的参数 --max-model-len 来指定期望的最大上下文长度。
pip install vllm==0.11.0from transformers import AutoModelForCausalLM, AutoTokenizermodel_name = "inclusionAI/Ling-1T"model = AutoModelForCausalLM.from_pretrained(model_name,dtype="auto",device_map="auto",trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_name)prompt = "Give me a short introduction to large language models."
messages = [{"role": "system", "content": "You are Ling, an assistant created by inclusionAI"},{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt", return_token_type_ids=False).to(model.device)generated_ids = model.generate(**model_inputs,max_new_tokens=512
)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]vllm serve inclusionAI/Ling-1T \--tensor-parallel-size 32 \--pipeline-parallel-size 1 \--trust-remote-code \--gpu-memory-utilization 0.90# This is only an example, please adjust arguments according to your actual environment.
b. SGLang 部署
环境准备: pip3 install sglang==0.5.2rc0 sgl-kernel==0.3.7.post1。
支持模型: 支持 BF16 和 FP8 模型。
推理: 可以通过运行 python -m sglang.launch_server 启动服务器,并通过 curl 命令进行客户端调用。MTP(多任务处理)支持基础模型。
pip3 install sglang==0.5.2rc0 sgl-kernel==0.3.7.post1
docker pull lmsysorg/sglang:v0.5.2rc0-cu126python -m sglang.launch_server \--model-path $MODEL_PATH \--host 0.0.0.0 --port $PORT \--trust-remote-code \--attention-backend fa3# This is only an example, please adjust arguments according to your actual environment.curl -s http://localhost:${PORT}/v1/chat/completions \-H "Content-Type: application/json" \-d '{"model": "auto", "messages": [{"role": "user", "content": "What is the capital of France?"}]}'
Ling-1T的案例应用
Ling-1T 的能力形成了通用、协作式人机智能的基础,具体应用包括:
>> 复杂逻辑与推理:解决竞赛级数学、专业数学和逻辑推理问题。
>> 代码生成与软件开发:在代码生成和软件开发任务中表现出色。
>> 视觉与前端生成:解释复杂的自然语言指令。将抽象逻辑转化为功能性的视觉组件。生成跨平台兼容的前端代码。
>> 文本创作:创建风格受控的营销文案和多语言文本。
>> 智能体能力:在工具使用基准中展现出较高的工具调用准确率,具备一定的智能体基础能力。