LLaVA-Video论文阅读

2025.6
1.摘要
background
视频大型多模态模型 (Video LMMs) 的发展受到了一个核心瓶颈的制约:难以获取大规模、高质量的视频指令微调数据。与图像数据相比,高质量的视频源更难找,且现有视频数据集存在两大问题:
1.内容静态: 很多视频内容变化不大,与静态图像能提供的信息差异不大,缺乏对模型时间推理能力的锻炼。
2.标注稀疏: 现有方法(如ShareGPT4Video)在为视频生成描述时,帧采样率极低(例如30秒视频只看2帧),导致生成的描述非常概括,无法捕捉细节动作和连续情节,进而导致模型在回答细节问题时产生“幻觉”。
innovation
本文的核心贡献是通过一个精心设计的数据生成管线,创造了一个高质量、大规模的合成视频指令微调数据集,以此来解决上述数据瓶颈问题。
1.高质量合成数据集 (LLaVA-Video-178K): 这是本文最核心的创新。研究者们构建了一个包含17.8万个视频和130万条指令样本的数据集。其高质量体现在:
动态视频源: 从10个主流视频数据集中精心筛选出具有显著动态变化、情节完整的未剪辑视频。
密集帧采样与循环生成: 提出了一个三层级的、循环式的视频描述生成管线。它以1 FPS的密集采样率处理视频,并使用GPT-4o生成描述。在生成后续描述时,会把之前的描述作为历史上下文,从而保证了对长视频情节的连贯理解。
任务多样性: 基于生成的详细描述,进一步使用GPT-4o生成了16种不同类型的开放式问答和多项选择题,覆盖了从基础感知到复杂推理的多种能力。
2.高效的视频表示方法 (LLaVA-Video slowFast): 针对密集采样带来的大量视频帧和显存占用的问题,引入了SlowFast思想。该方法为不同的帧分配不同数量的视觉token,一些关键帧(slow path)保留更多细节,而其他帧(fast path)则高度压缩,从而在有限的显存预算内处理多达3倍的视频帧。
2. 方法 Method
本文的方法论核心在于数据生成,而非模型架构的创新。
总体 Pipeline:
整个流程可以概括为:精选视频 -> 合成高质量指令数据 -> 用新数据微调现有LMM。
输入: 从10个大型视频数据集中筛选出的动态、未剪辑的视频。
输出: 一个经过微调的、具有强大视频理解能力的LLaVA-Video模型。
数据生成 Pipeline (LLaVA-Video-178K):
1.视频源选择与过滤:
从HD-VILA-100M, ActivityNet等10个源头构建视频池。
使用场景检测工具(PySceneDetect)等方法,筛选出场景变化多、内容动态的视频。
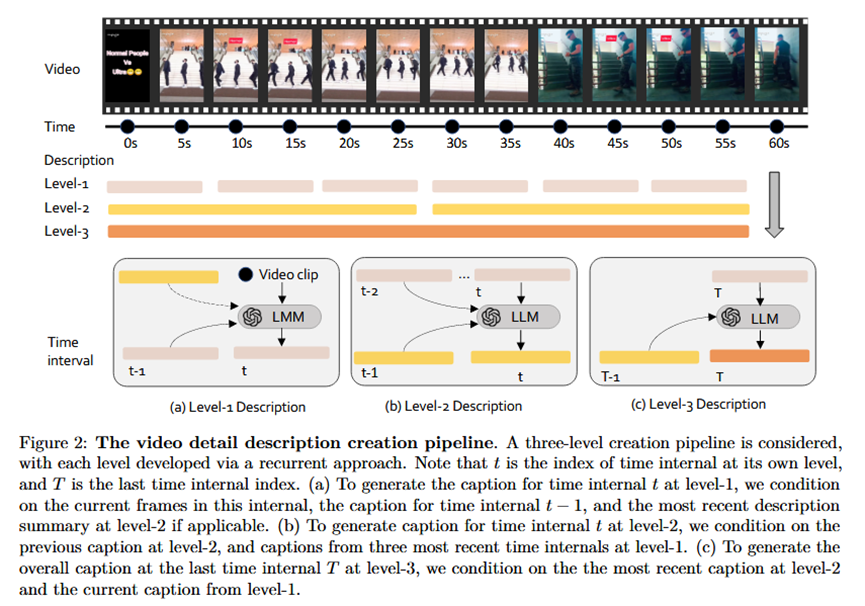
2.三层级循环式详细描述生成:
Level-1 (每10秒): 对当前10秒的视频片段生成描述,输入不仅包括当前帧,还包括最近的Level-1和Level-2描述作为历史上下文。
Level-2 (每30秒): 对过去30秒的内容(即3个Level-1描述)进行总结,形成一个更概括的段落。
Level-3 (视频结束时): 对整个视频进行最终的全面总结。
3.多样化问答对生成:
基于上述生成的详细描述,定义了16种问题类型(如时序、因果、计数、细节描述等)。
为每种类型设计Prompt,让GPT-4o根据视频描述生成相应的开放式问答和多选题。
4.数据过滤: 移除重复的问题和无意义的回答(如“视频未提供信息”)。
模型训练与表示:
1.模型架构: 沿用LLaVA-OneVision的架构,即SigLIP视觉编码器 + Qwen2大语言模型。
2.训练策略: 从一个强大的预训练单图像模型(LLaVA-OneVision SI)的checkpoint开始,用LLaVA-Video-178K及其他一些公开视频QA数据集进行联合微调。
3.视频表示 (LLaVA-Video slowFast):
将视频帧分为“慢帧组”(如每隔s帧选一帧)和“快帧组”(其余帧)。
慢帧组使用较小的池化率(如p x p),保留更多的视觉token。
快帧组使用较大的池化率(如2p x 2p),保留较少的视觉token。
通过这种方式,在总token数量可控的情况下,显著增加了模型能处理的总帧数。
3. 实验 Experimental Results
数据集:
训练: LLaVA-Video-178K (核心贡献), LLaVA-Hound-255K, ActivityNet-QA, NEXT-QA, PerceptionTest, LLaVA-OneVision image data。
评测: 在11个主流视频理解基准上进行评测,包括ActivityNet-QA, MLVU, LongVideoBench, EgoSchema, PerceptionTest, VideoMME等。
实验结论:
1.SOTA性能: LLaVA-Video模型(特别是72B版本)在11个基准中的绝大多数上都取得了开源模型的最佳性能,甚至在多个指标上与顶级的闭源模型Gemini-1.5-Pro相当或更优。这强力证明了高质量合成数据的有效性。
2.数据集消融实验 (Table 3): 实验清晰地显示,在基线模型上仅仅加入LLaVA-Video-178K数据集,就能在各项评测(尤其是需要时间理解的in-domain任务)上带来巨大的性能提升(例如在NExT-QA上提升了31.9%),验证了该数据集是性能提升的关键。
3.数据质量对比实验 (Table 4): 通过控制问答对数量,证明了用LLaVA-Video-178K训练的模型显著优于用LLaVA-Hound和ShareGPT4Video训练的模型。这直接说明了本文数据集因其视频的动态性和标注的密集性而在“质量”上胜出。
4.帧数重要性实验 (Table 8): 实验推翻了以往研究中“超过16帧性能就饱和”的结论。结果表明,对于动态视频和细节标注,随着训练帧数从32帧增加到110帧,模型性能持续稳定提升。这证明了密集采样对于训练强大的视频模型至关重要。
4. 总结 Conclusion
本文的核心观点是高质量的、专为视频动态特性设计的数据是解锁强大视频LMM能力的关键。通过一个创新的、基于密集采样的合成数据管线,可以显著提升模型的视频理解能力,使其在开源领域达到与顶级闭源模型相媲美的水平。同时,研究也证明了对于复杂的视频任务,输入更多的帧数是持续提升性能的有效途径。