【线程池】——实用场景
深入剖析线程池应用场景与并发控制技术
在现代高并发、大数据的系统架构中,线程池和相关的并发控制技术是保障应用性能、稳定性和可伸缩性的基石。本文将深入探讨线程池的几个典型使用场景,并详细解释如何控制方法并发量以及ThreadLocal的核心原理。
一、 线程池使用场景深度解析

代码示例:

1. 场景一:ES数据批量导入

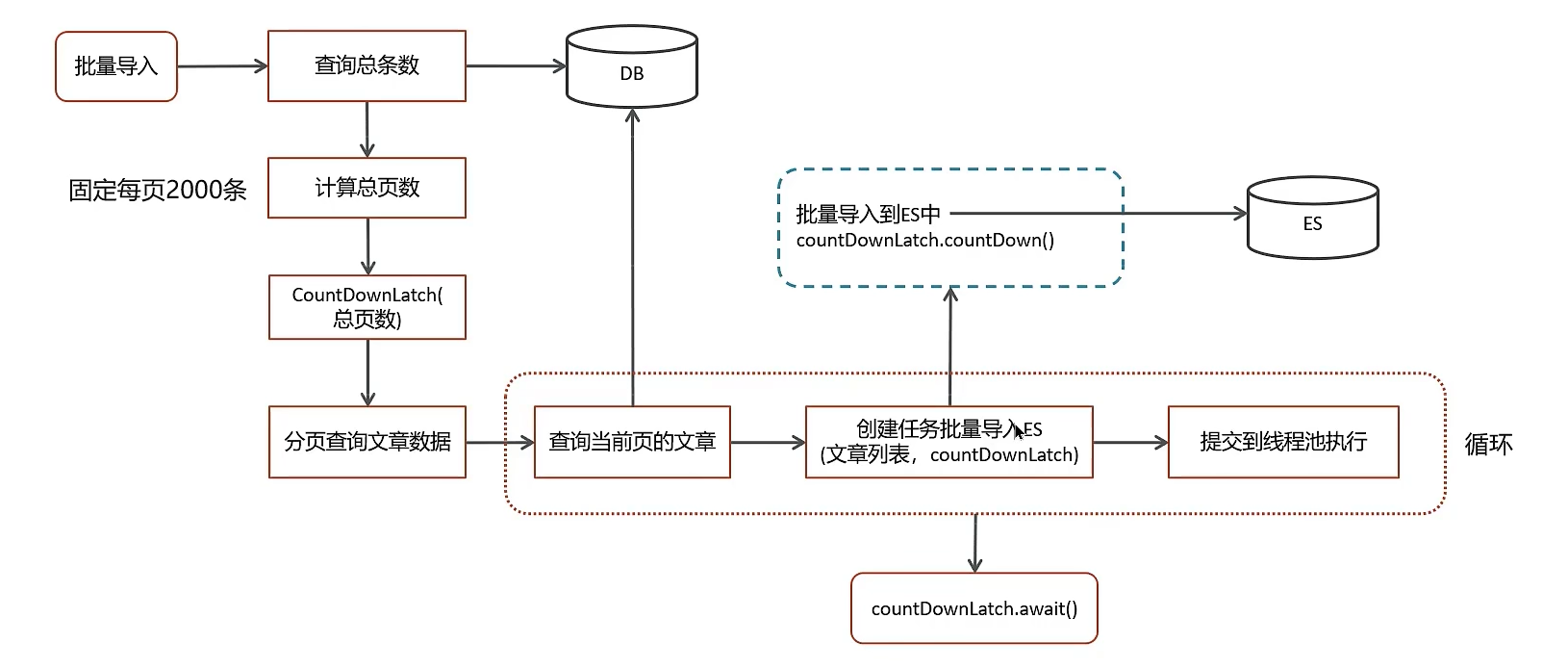
业务痛点:需要将海量数据(如数据库中的历史订单、日志数据)高效地导入到Elasticsearch中以便提供全文检索服务。单线程逐条插入性能极差,无法利用现代多核CPU的优势,导入过程耗时极长。
解决方案:使用线程池进行批量(Bulk) 并发导入。
技术实现:
- 创建线程池:这是一个典型的IO密集型任务,因为线程大部分时间在等待网络IO(与ES集群的交互)。线程数建议设置为
2 * CPU核心数或更高,具体需要通过压测找到最优值。务必使用有界队列并指定合理的拒绝策略。 - 数据分片:将源数据划分为多个小批次(Batches)。例如,从数据库分页查询,每页500条记录。
- 任务提交:将每个批次的数据包装成一个
Runnable或Callable任务,提交给线程池。每个任务的任务是构建一个ES Bulk请求,并执行一次网络调用。 - 结果处理:使用
Future或CompletionService来获取每个批次的执行结果,统计成功和失败的数量,进行必要的重试或日志记录。
- 创建线程池:这是一个典型的IO密集型任务,因为线程大部分时间在等待网络IO(与ES集群的交互)。线程数建议设置为
核心优势:
- 极大提升吞吐量:并行处理多个批量请求,将网络IO等待时间重叠起来,充分压榨网络和ES集群的带宽和处理能力。
- 资源可控:通过线程池参数防止创建过多线程,耗尽客户端或ES集群的资源。
注意事项:
- 并非线程数越多越好,需要监控ES集群的负载,避免将其压垮。
- 批量的大小(Batch Size)需要调优,太小则网络开销占比高,太大则可能导致内存压力和请求超时。
2. 场景二:数据汇总
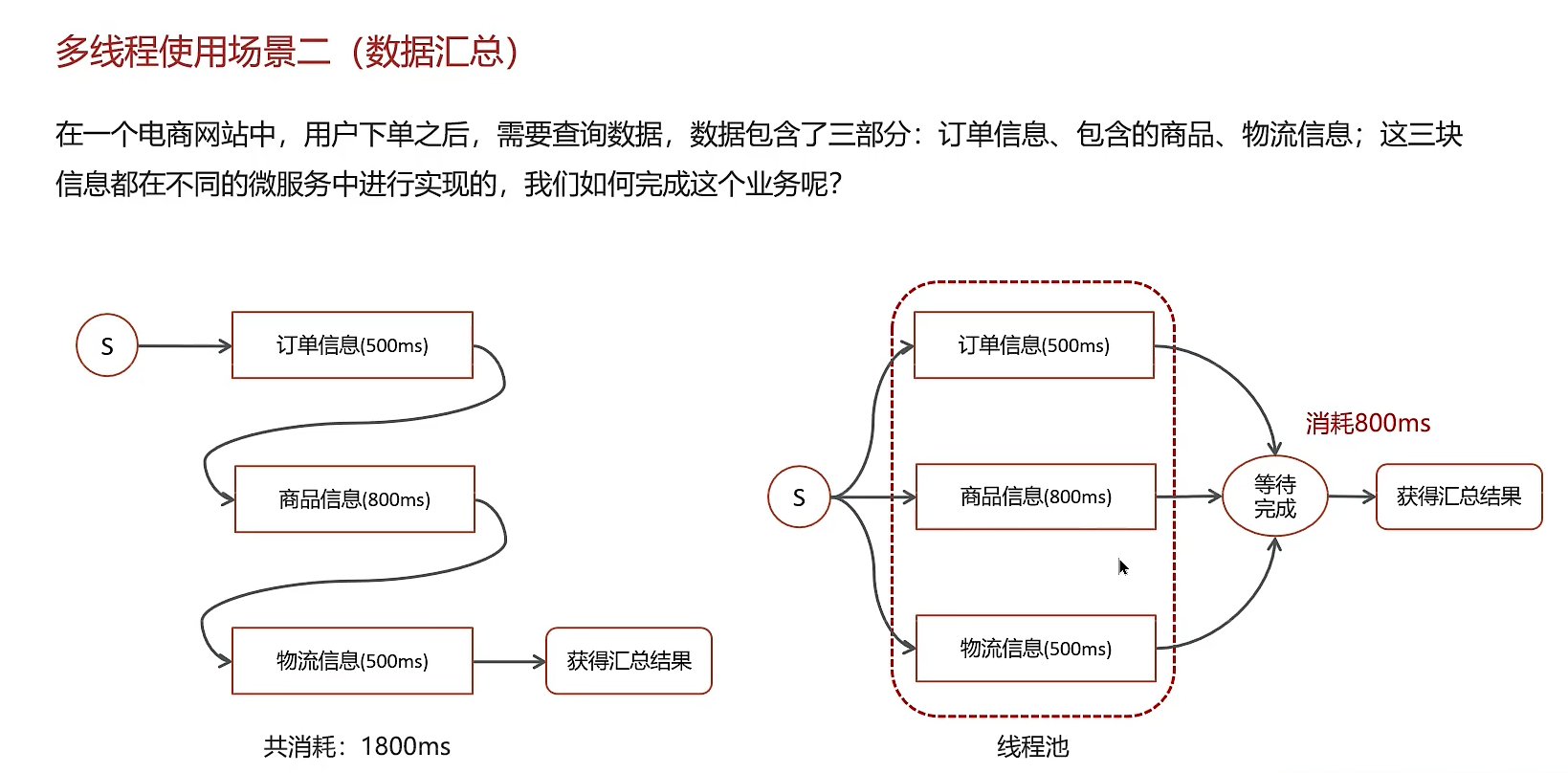
业务痛点:需要从多个不同的数据源(如多个微服务、多个数据库表)获取数据,然后聚合得到一个最终结果。如果串行调用,总耗时为所有调用耗时之和。
解决方案:使用线程池进行并行数据采集。
技术实现:
- 创建线程池:根据数据源的数量和类型(IO密集型或计算密集型)配置线程池。通常源之间无依赖,线程数可设置为数据源的数量。
- 并行调用:为每个数据源的调用创建一个
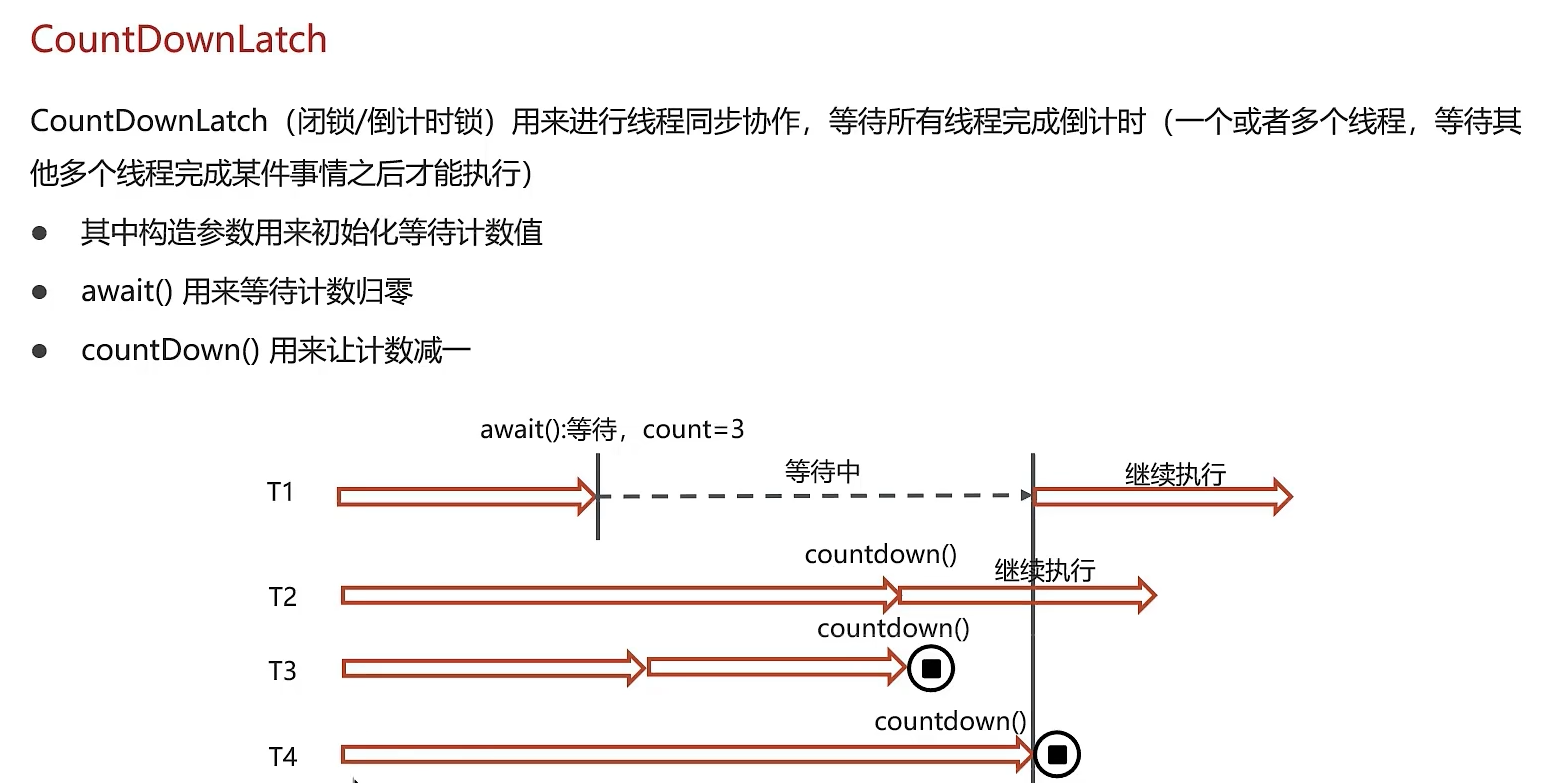
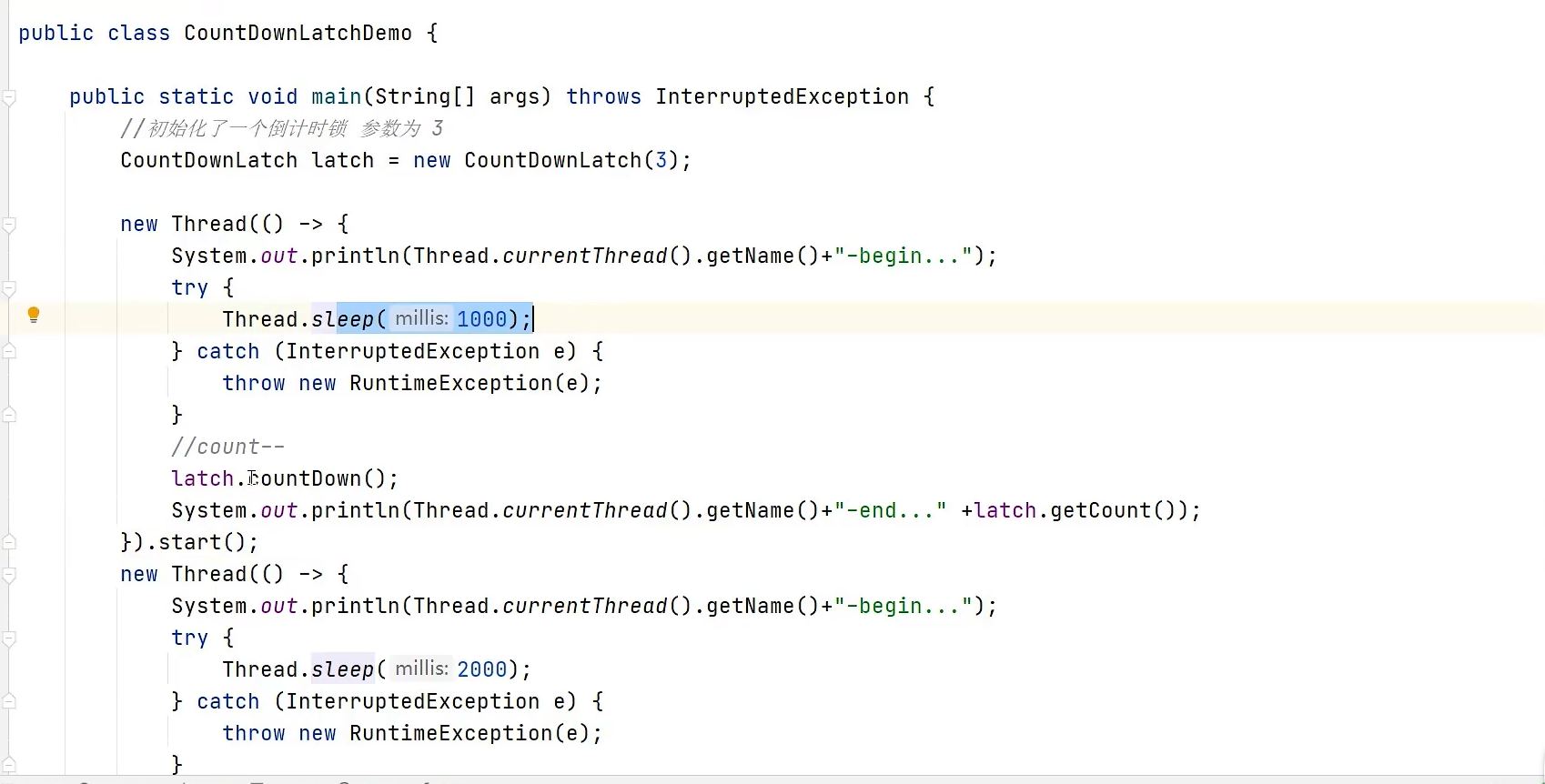
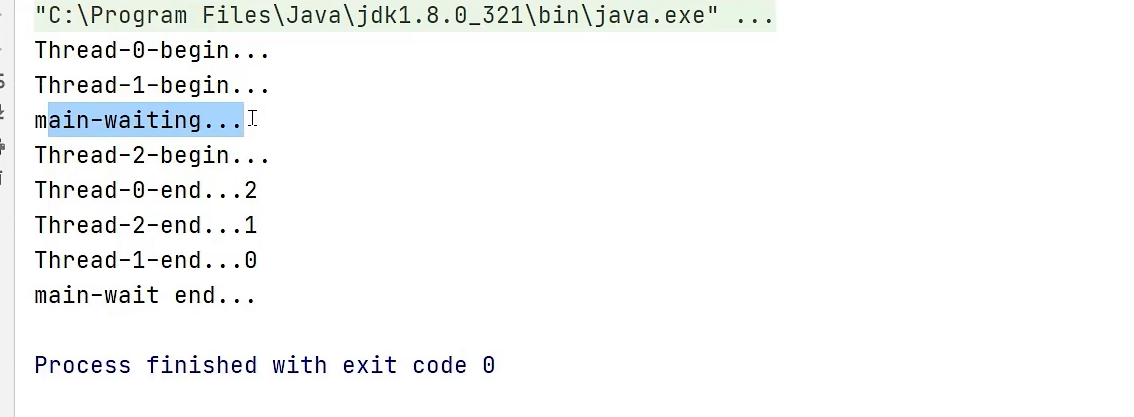
Callable任务提交到线程池。例如,一个任务调用用户服务获取用户信息,另一个任务调用订单服务获取订单列表,第三个任务调用风控服务获取评分。 - 同步等待:使用
CountDownLatch或更灵活的Future来启动所有任务并等待它们全部完成。 - 结果聚合:待所有任务执行完毕后,在主线程中汇总各个任务返回的结果,组装成最终响应。
核心优势:
- 显著降低延迟:总耗时从各调用耗时之和变为最慢的那个调用的耗时,极大提升了接口响应速度。
- 清晰的任务边界:每个数据源的处理逻辑被封装在独立的任务中,代码结构清晰。
注意事项:
- 必须设置合理的超时时间,防止某个慢任务拖死整个汇总流程。
- 妥善处理个别任务失败的情况,是整体失败、重试还是返回部分数据,需要根据业务决定。
3. 场景三:异步处理
业务痛点:主流程中的一些非核心、耗时操作(如发送短信、推送消息、记录操作日志、清理临时文件)阻塞了主线程,导致请求响应时间变长。
解决方案:使用线程池进行异步解耦。
技术实现:
- 创建线程池:为不同的异步任务类别创建不同的线程池,实现资源隔离。例如,
SmsThreadPool、LogThreadPool。这样即使发送短信的任务被阻塞,也不会影响记录日志的功能。 - 任务提交:在主流程(如Controller中)中,将需要异步执行的操作封装成任务,提交给对应的线程池后立即返回,无需等待其完成。
- 结果处理:对于不关心结果的操作(如日志),使用
Runnable即可。对于需要知道结果进行后续处理的(如发送短信的状态),可使用Future进行轮询或回调。
- 创建线程池:为不同的异步任务类别创建不同的线程池,实现资源隔离。例如,
核心优势:
- 加速主流程响应:将耗时操作剥离,使得主请求能够快速返回,提升用户体验。
- 模块解耦:业务逻辑与辅助逻辑分离,代码可维护性更强。
- 功能削峰填谷:突发流量产生的任务可以在线程池队列中排队,被后台线程逐步消化,保护系统。
小结:

二、 如何控制某个方法允许并发访问线程的数量

有时我们需要限制某个具体方法或资源块的并发访问数,而不是控制整个线程池的规模。这时,线程池显得过重,更轻量级的 Semaphore(信号量) 是完美选择。

结果展示:
实现原理:
Semaphore维护了一个许可证集合。线程要执行受保护的方法,必须先从Semaphore中获取(acquire)一个许可证。- 如果还有剩余许可证,线程获取成功并继续执行。
- 当许可证已被拿完,其他尝试获取的线程将被阻塞,直到有线程执行完方法后释放(
release)许可证。 - 这有效地将方法的并发访问数控制在了许可证总数以内。
代码示例:
public class ResourcePool {// 创建一个拥有10个许可证的信号量,代表允许10个线程并发访问private final Semaphore semaphore = new Semaphore(10);public void limitedMethod() {try {semaphore.acquire(); // 获取一个许可证,如果没有则阻塞// ... 受保护的临界区代码(需要控制并发数的方法体)} catch (InterruptedException e) {Thread.currentThread().interrupt();} finally {semaphore.release(); // 在finally块中释放许可证,确保必然执行}}}- 与线程池的区别:
- 线程池:控制的是工作线程的总数,适用于管理任务的执行。
- 信号量:控制的是对特定资源或代码块的访问线程数,这些线程可能来自任何地方(不同的线程池或线程),适用于限流和资源池化(如数据库连接池)。

三、 谈谈你对ThreadLocal的理解
ThreadLocal 是Java提供的一个用于保存线程局部变量的工具类。它解决了变量在线程间的隔离问题,实现了同一个变量,每个线程都有自己独立的副本。
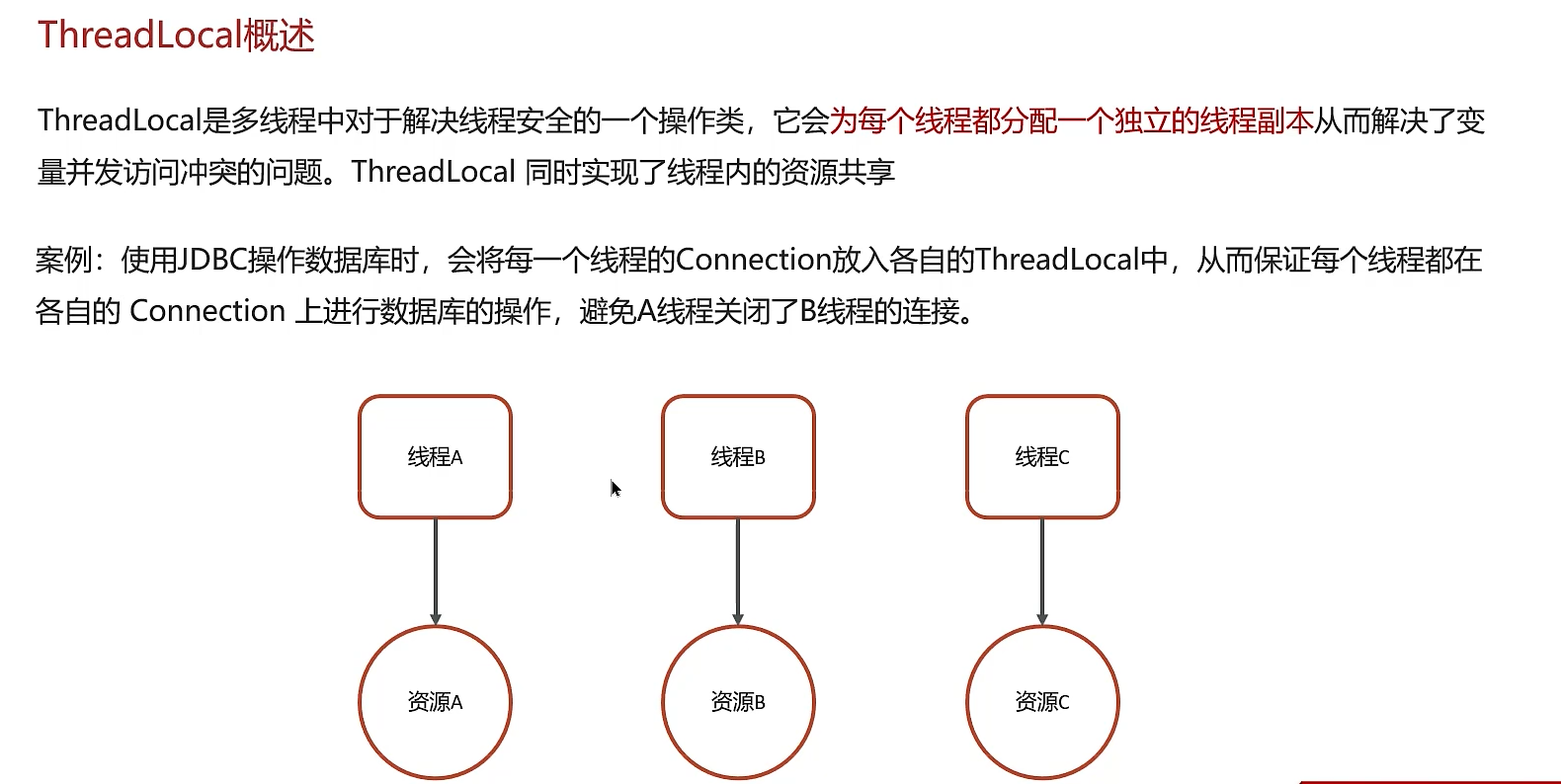
threadlocal基本使用:

1. 核心原理:

- 数据结构:每个
Thread对象内部都有一个ThreadLocalMap的实例变量(可以看作一个特殊的Map)。 - 存储方式:
ThreadLocal本身并不存储值,它只是一个键(Key)。当我们调用threadLocal.set(value)时,实际上是以当前Thread为引用,以ThreadLocal实例自身为Key,将值存储到了当前线程的ThreadLocalMap中。 
- 取值方式:调用
threadLocal.get()时,同样是先获取当前线程的ThreadLocalMap,然后以自身为Key去查找对应的值。 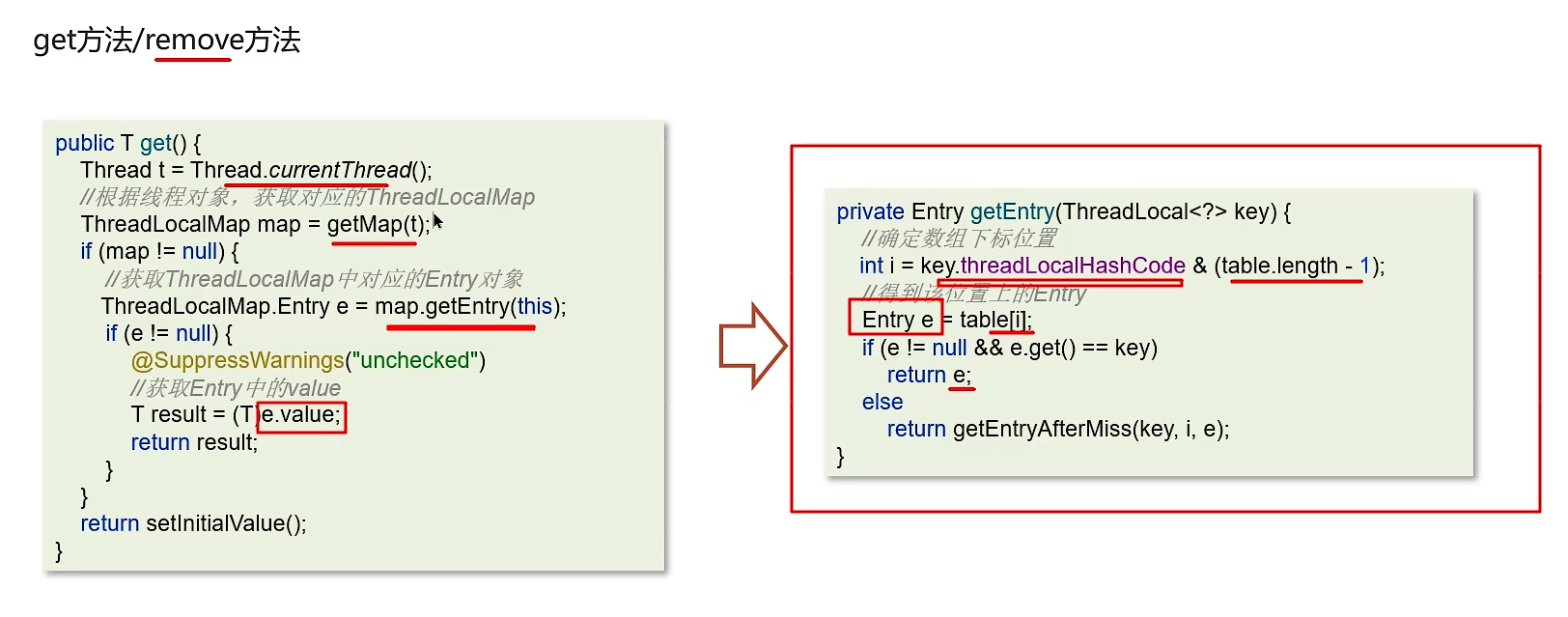
remove方法:在Entry e = table[i]时把table[i]改成null,源码类似get方法
简单来说,数据是存储在每个线程自身的口袋里,而 ThreadLocal 只是一把用来从自己口袋存取数据的钥匙。 这种设计不存在多线程竞争,因此是绝对线程安全的。
2. 经典使用场景:
- 用户会话信息管理:在Web应用或RPC框架中,可以将一次请求链路上的用户ID、权限等信息存入ThreadLocal。在整个处理过程的任何地方,都可以轻松获取,无需在方法参数中显式传递。例如,Spring的
@Transactional事务管理就用它来保证同一个线程使用同一个数据库连接。 - 全局参数传递:避免在函数调用链的每一层都传递一些通用参数(如TraceId用于全链路日志追踪)。
- 线程安全的工具类:例如,
SimpleDateFormat是非线程安全的,但如果每个线程都通过ThreadLocal拥有一个自己的副本,就避免了同步开销和线程安全问题。
3. 注意事项与内存泄漏风险:
这是理解ThreadLocal的关键和难点。
内存模型:
Thread -> ThreadLocalMap -> Entry(Key: ThreadLocal, Value: Object)。其中,Key(即ThreadLocal实例)是一个弱引用,而Value是强引用。
风险根源:当我们将一个ThreadLocal变量置为null(
threadLocal = null)时,由于ThreadLocalMap的Key是弱引用,它会在下一次GC时被回收。然而,对应的Value由于是强引用,只要创建它的线程没有结束(例如,是线程池中的线程,会复用不会结束),这个Value就会一直存在于线程的ThreadLocalMap中,但却永远无法被访问到(因为Key没了),从而造成内存泄漏。
小结:

最佳实践:
- 总是主动清理:在每次使用完ThreadLocal后,必须调用其
remove()方法,手动将当前线程的Value删除。 - 将其声明为
private static:static的生命周期与类相同,可以避免重复创建多个ThreadLocal实例。但这并非为了避免内存泄漏,而是为了规范和效率。 - 配合线程池使用时尤其小心:因为线程会复用,如果前一个任务set了值但没有remove,后一个任务可能会读到这个脏数据,造成严重bug。因此,在任务执行的 finally 块中调用
remove()是必须的操作。
- 总是主动清理:在每次使用完ThreadLocal后,必须调用其
// 使用模板
private static final ThreadLocal<User> USER_CONTEXT = new ThreadLocal<>();try {User user = getCurrentUser();USER_CONTEXT.set(user); // 将用户信息绑定到当前线程// ... 执行后续业务逻辑,任何地方都可以USER_CONTEXT.get()
} finally {USER_CONTEXT.remove(); // 至关重要!清理当前线程的变量
}总结 线程池是并发编程中的“重型武器”,用于高效管理任务执行,其应用场景广泛,从数据批处理、并行查询到异步解耦都不可或缺。而 Semaphore 则是“精细手术刀”,用于控制对特定资源的并发访问数。ThreadLocal 提供了优雅的线程内数据隔离方案,但必须理解其内存模型并遵循 remove 的最佳实践以防止内存泄漏。熟练掌握这些工具,并根据具体场景选择最合适的方案,是构建高性能、高可用Java应用的必备技能。