【AGI使用教程】Meta 开源视觉基础模型 DINOv3(1)下载与使用
欢迎关注【AGI使用教程】 专栏
【AGI使用教程】GPT-OSS 本地部署
【AGI使用教程】Meta 开源视觉基础模型 DINOv3
【AGI使用教程】Meta 开源视觉基础模型 DINOv3
- 1. Meta DINOv3 介绍
- 1.1 DINOv3 功能概览
- 1.2 DINOv3 下载地址
- 2. DINOv3 预训练模型
- 2.1 下载 DINOv3 预训练模型
- 2.2 预训练主干网络(通过 PyTorch Hub 加载)
- 2.3 通过 Hugging Face 提供的预训练主干网络
- 2.4 图像变换
- 2.5 预训练检测器
- 2.5.1 在ImageNet 数据集训练的图像分类检测器
- 2.5.2 在 Coco2017 数据集训练的目标检测器
- 2.5.3 在 ADE20K 数据集训练的语义分割检测器
- 2.5.4 基于 dino.txt 的零样本任务检测器
- 3. 安装与使用 DINOv3
- 3.1 安装 DINOv3
- 3.2 快速使用 DINOv3
- 4. DINOv3 模型训练、蒸馏与评估
- 4.1 DINOv3 模型训练
- 4.2 DINOv3 模型蒸馏
- 4.3 DINOv3 模型评估
- 5. DINOv3 官方报道
- 引用标注
1. Meta DINOv3 介绍
2025年8月14日,Meta 重磅发布 DINOv3。
DINOv3 是 Meta 推出的通用的、SOTA 级的视觉基础模型。模型通过无标注数据训练,生成高质量的高分辨率视觉特征,适用图像分类、语义分割、目标检测等多任务。DINOv3 拥有 70 亿参数,训练数据量达 17 亿张图像,性能全面超越弱监督模型,模型支持多种模型变体适应不同计算需求。DINOv3 开源的训练代码和预训练模型,为计算机视觉研究和应用开发提供强大支持。

1.1 DINOv3 功能概览
DINOv3的主要功能
- 高分辨率视觉特征提取:生成高质量、高分辨率的视觉特征,支持精细的图像解析与多种视觉任务。
- 无需微调的多任务支持:单次前向传播可同时支持多个下游任务,无需微调,显著降低推理成本。
- 广泛的适用性:适用网络图像、卫星图像、医学影像等多领域,支持标注稀缺场景。
- 多样化的模型变体:提供多种模型变体(如ViT-B、ViT-L及ConvNeXt架构),适应不同计算资源需求。
DINOv3的技术原理
- 自监督学习(SSL):用自监督学习技术,无需标注数据即可训练模型。通过对比学习,模型从大量无标注图像中学习到通用的视觉特征。大幅降低数据准备的成本和时间,同时提高模型的泛化能力。
- Gram Anchoring 策略:引入 Gram Anchoring 策略,有效缓解密集特征的坍缩问题,生成更清晰、更语义一致的特征图,使模型在高分辨率图像任务中表现更为出色。
- 旋转位置编码(RoPE):用旋转位置编码(RoPE),避免固定位置编码的限制,能天然适应不同分辨率的输入,让模型在处理不同尺度的图像时更加灵活和高效。
- 模型蒸馏:基于模型蒸馏技术,将大型模型(如 ViT-7B)的知识迁移到更小的模型变体中(如 ViT-B 和 ViT-L)。保留大型模型的性能,提高模型的部署效率,适用不同的计算资源需求。
1.2 DINOv3 下载地址
项目地址:https://ai.meta.com/dinov3/
代码路径:github-dinov3,huggingface-dinov3
研究论文:arXiv-DINOv3,meta-DINOv3

2. DINOv3 预训练模型
2.1 下载 DINOv3 预训练模型
ℹ️ 请通过下方链接申请获取所有模型权重:获批后,系统将发送一封电子邮件,内含指向全部可用权重(含主干网络与适配器)的完整 URL 列表。获得这些 URL 后,您可:
- 将模型或适配器权重下载至本地文件系统,再通过 weights 或 backbone_weights 参数将 torch.hub.load() 指向这些本地权重;
- 也可直接调用 torch.hub.load(),通过 weights 或 backbone_weights 参数从 URL 在线下载并加载主干网络或适配器。
⚠️ 请使用 wget 而非网页浏览器下载权重。
- 基于网络数据集(LVD-1689M)预训练的 ViT 模型:
| Model | Parameters | PretrainingDataset | Download |
|---|---|---|---|
| ViT-S/16 distilled | 21M | LVD-1689M | link |
| ViT-S+/16 distilled | 29M | LVD-1689M | link |
| ViT-B/16 distilled | 86M | LVD-1689M | link |
| ViT-L/16 distilled | 300M | LVD-1689M | link |
| ViT-H+/16 distilled | 840M | LVD-1689M | link |
| ViT-7B/16 | 6,716M | LVD-1689M | link |
- 基于网络数据集(LVD-1689M)预训练的 ConvNeXt 模型:
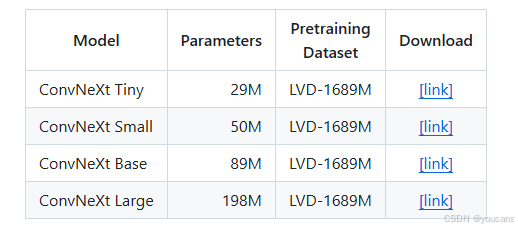
- 基于卫星数据集(SAT-493M)预训练的 ViT 模型:
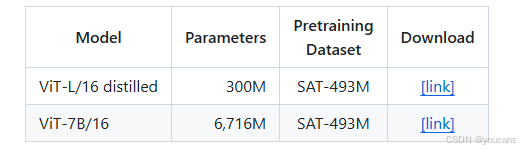
2.2 预训练主干网络(通过 PyTorch Hub 加载)
请按照此处说明安装 PyTorch(加载模型所需的唯一依赖)。强烈建议安装支持 CUDA 的 PyTorch。
import torchREPO_DIR = <PATH/TO/A/LOCAL/DIRECTORY/WHERE/THE/DINOV3/REPO/WAS/CLONED># DINOv3 ViT models pretrained on web images
dinov3_vits16 = torch.hub.load(REPO_DIR, 'dinov3_vits16', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_vits16plus = torch.hub.load(REPO_DIR, 'dinov3_vits16plus', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_vitb16 = torch.hub.load(REPO_DIR, 'dinov3_vitb16', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_vitl16 = torch.hub.load(REPO_DIR, 'dinov3_vitl16', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_vith16plus = torch.hub.load(REPO_DIR, 'dinov3_vith16plus', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_vit7b16 = torch.hub.load(REPO_DIR, 'dinov3_vit7b16', source='local', weights=<CHECKPOINT/URL/OR/PATH>)# DINOv3 ConvNeXt models pretrained on web images
dinov3_convnext_tiny = torch.hub.load(REPO_DIR, 'dinov3_convnext_tiny', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_convnext_small = torch.hub.load(REPO_DIR, 'dinov3_convnext_small', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_convnext_base = torch.hub.load(REPO_DIR, 'dinov3_convnext_base', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_convnext_large = torch.hub.load(REPO_DIR, 'dinov3_convnext_large', source='local', weights=<CHECKPOINT/URL/OR/PATH>)# DINOv3 ViT models pretrained on satellite imagery
dinov3_vitl16 = torch.hub.load(REPO_DIR, 'dinov3_vitl16', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_vit7b16 = torch.hub.load(REPO_DIR, 'dinov3_vit7b16', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
2.3 通过 Hugging Face 提供的预训练主干网络
所有主干网络均已发布在 Hugging Face Hub 的 DINOv3 集合中,并通过 Hugging Face Transformers 库提供支持(所需版本 ≥4.56.0)。有关用法请参阅官方文档;以下为简要示例,演示如何借助 [Pipeline] 或 [AutoModel] 类获取图像嵌入。
from transformers import pipeline
from transformers.image_utils import load_imageurl = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
image = load_image(url)feature_extractor = pipeline(model="facebook/dinov3-convnext-tiny-pretrain-lvd1689m",task="image-feature-extraction",
)
features = feature_extractor(image)
import torch
from transformers import AutoImageProcessor, AutoModel
from transformers.image_utils import load_imageurl = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = load_image(url)pretrained_model_name = "facebook/dinov3-convnext-tiny-pretrain-lvd1689m"
processor = AutoImageProcessor.from_pretrained(pretrained_model_name)
model = AutoModel.from_pretrained(pretrained_model_name, device_map="auto",
)inputs = processor(images=image, return_tensors="pt").to(model.device)
with torch.inference_mode():outputs = model(**inputs)pooled_output = outputs.pooler_output
print("Pooled output shape:", pooled_output.shape)
其中,上文中的 model 与 pretrained_model_name 可从下列选项中任选其一:
facebook/dinov3-vits16-pretrain-lvd1689m
facebook/dinov3-vits16plus-pretrain-lvd1689m
facebook/dinov3-vitb16-pretrain-lvd1689m
facebook/dinov3-vitl16-pretrain-lvd1689m
facebook/dinov3-vith16plus-pretrain-lvd1689m
facebook/dinov3-vit7b16-pretrain-lvd1689m
facebook/dinov3-convnext-base-pretrain-lvd1689m
facebook/dinov3-convnext-large-pretrain-lvd1689m
facebook/dinov3-convnext-small-pretrain-lvd1689m
facebook/dinov3-convnext-tiny-pretrain-lvd1689m
facebook/dinov3-vitl16-pretrain-sat493m
facebook/dinov3-vit7b16-pretrain-sat493m
2.4 图像变换
对于使用 LVD-1689M 权重(基于网络图像预训练)的模型,请采用以下变换(标准 ImageNet 评估变换):
import torchvision
from torchvision.transforms import v2def make_transform(resize_size: int = 256):to_tensor = v2.ToImage()resize = v2.Resize((resize_size, resize_size), antialias=True)to_float = v2.ToDtype(torch.float32, scale=True)normalize = v2.Normalize(mean=(0.485, 0.456, 0.406),std=(0.229, 0.224, 0.225),)return v2.Compose([to_tensor, resize, to_float, normalize])
对于使用 SAT-493M 权重(基于卫星影像预训练)的模型,请采用以下变换:
import torchvision
from torchvision.transforms import v2def make_transform(resize_size: int = 256):to_tensor = v2.ToImage()resize = v2.Resize((resize_size, resize_size), antialias=True)to_float = v2.ToDtype(torch.float32, scale=True)normalize = v2.Normalize(mean=(0.430, 0.411, 0.296),std=(0.213, 0.156, 0.143),)return v2.Compose([to_tensor, resize, to_float, normalize])
2.5 预训练检测器
2.5.1 在ImageNet 数据集训练的图像分类检测器
| Backbone | PretrainingDataset | HeadDataset | Download |
|---|---|---|---|
| ViT-7B/16 | LVD-1689M | ImageNet | link |
ViT-7B/16 LVD-1689M ImageNet [link]
完整的分类器模型可通过 PyTorch Hub 加载:
import torch# DINOv3
dinov3_vit7b16_lc = torch.hub.load(REPO_DIR, 'dinov3_vit7b16_lc', source="local", weights=<DEPTHER/CHECKPOINT/URL/OR/PATH>, backbone_weights=<BACKBONE/CHECKPOINT/URL/OR/PATH>)2.5.2 在 Coco2017 数据集训练的目标检测器
| Backbone | PretrainingDataset | HeadDataset | Download |
|---|---|---|---|
| ViT-7B/16 | LVD-1689M | COCO2017 | link |
detector = torch.hub.load(REPO_DIR, 'dinov3_vit7b16_de', source="local", weights=<DETECTOR/CHECKPOINT/URL/OR/PATH>, backbone_weights=<BACKBONE/CHECKPOINT/URL/OR/PATH>)
2.5.3 在 ADE20K 数据集训练的语义分割检测器
| Backbone | PretrainingDataset | HeadDataset | Download |
|---|---|---|---|
| ViT-7B/16 | LVD-1689M | ADE20K | link |
segmentor = torch.hub.load(REPO_DIR, 'dinov3_vit7b16_ms', source="local", weights=<SEGMENTOR/CHECKPOINT/URL/OR/PATH>, backbone_weights=<BACKBONE/CHECKPOINT/URL/OR/PATH>)
图像上语义分割器的完整示例代码如下。
import sys
sys.path.append(REPO_DIR)from PIL import Image
import torch
from torchvision import transforms
import matplotlib.pyplot as plt
from matplotlib import colormaps
from functools import partial
from dinov3.eval.segmentation.inference import make_inferencedef get_img():import requestsurl = "http://images.cocodataset.org/val2017/000000039769.jpg"image = Image.open(requests.get(url, stream=True).raw).convert("RGB")return imagedef make_transform(resize_size: int | list[int] = 768):to_tensor = v2.ToImage()resize = v2.Resize((resize_size, resize_size), antialias=True)to_float = v2.ToDtype(torch.float32, scale=True)normalize = v2.Normalize(mean=(0.485, 0.456, 0.406),std=(0.229, 0.224, 0.225),)return v2.Compose([to_tensor, resize, to_float, normalize])segmentor = torch.hub.load(REPO_DIR, 'dinov3_vit7b16_ms', source="local", weights=<SEGMENTOR/CHECKPOINT/URL/OR/PATH>, backbone_weights=<BACKBONE/CHECKPOINT/URL/OR/PATH>)img_size = 896
img = get_img()
transform = make_transform(img_size)
with torch.inference_mode():with torch.autocast('cuda', dtype=torch.bfloat16):batch_img = transform(img)[None]pred_vit7b = segmentor(batch_img) # raw predictions # actual segmentation mapsegmentation_map_vit7b = make_inference(batch_img,segmentor,inference_mode="slide",decoder_head_type="m2f",rescale_to=(img.size[-1], img.size[-2]),n_output_channels=150,crop_size=(img_size, img_size),stride=(img_size, img_size),output_activation=partial(torch.nn.functional.softmax, dim=1),).argmax(dim=1, keepdim=True)
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.imshow(img)
plt.axis("off")
plt.subplot(122)
plt.imshow(segmentation_map_vit7b[0,0].cpu(), cmap=colormaps["Spectral"])
plt.axis("off")
2.5.4 基于 dino.txt 的零样本任务检测器
| Backbone | Download |
|---|---|
| ViT-L/16 distilled | link |
完整的 dino.txt 模型可通过 PyTorch Hub 加载:
import torch
# DINOv3
dinov3_vitl16_dinotxt_tet1280d20h24l, tokenizer = torch.hub.load(REPO_DIR, 'dinov3_vitl16_dinotxt_tet1280d20h24l', weights=<SEGMENTOR/CHECKPOINT/URL/OR/PATH>, backbone_weights=<BACKBONE/CHECKPOINT/URL/OR/PATH>)
3. 安装与使用 DINOv3
3.1 安装 DINOv3
训练与评估代码要求 PyTorch 版本 ≥2.7.1,并依赖若干第三方软件包。请注意,代码仅在指定版本下经过测试,且需运行 Linux 环境。如需为训练与评估配置全部依赖,请按以下步骤操作:
micromamba(推荐)——克隆仓库后,使用提供的环境定义文件创建并激活 dinov3 conda 环境:
micromamba env create -f conda.yaml
micromamba activate dinov3
3.2 快速使用 DINOv3
我们提供了若干 Jupyter Notebook 以帮助快速上手 DINOv3 的应用:
- 块特征 PCA:在前景物体上可视化 DINOv3 块特征的主成分分析(论文中的彩虹图)
在 Google Colab 运行 - 前景分割:基于 DINOv3 特征训练一个线性前景分割模型
在 Google Colab 运行 - 稠密与稀疏匹配:利用 DINOv3 特征在两幅图像的物体块之间进行匹配
在 Google Colab 运行 - 分割跟踪:采用基于 DINOv3 特征的非参数方法进行视频分割跟踪
在 Google Colab 运行
4. DINOv3 模型训练、蒸馏与评估
4.1 DINOv3 模型训练
- 快速配置:在 ImageNet-1k 上训练 DINOv3 ViT-L/16
在配备 submitit 的 SLURM 集群环境中,使用 4 个 H100-80GB 节点(共 32 块 GPU)运行 DINOv3 预训练:
PYTHONPATH=${PWD} python -m dinov3.run.submit dinov3/train/train.py \--nodes 4 \--config-file dinov3/configs/train/vitl_im1k_lin834.yaml \--output-dir <PATH/TO/OUTPUT/DIR> \train.dataset_path=ImageNet22k:root=<PATH/TO/DATASET>:extra=<PATH/TO/DATASET>
训练时间约14小时,所得检查点应在k-NN评估上达到82.0%,在线性评估上达到83.5%。
训练代码每12 500次迭代将教师模型的权重保存在eval文件夹中,以供评估使用。
- DINOv3 精确配置:训练 DINOv3 ViT-7B/16
DINOv3 ViT-7B/16 在私有数据集上训练,训练流程分为 3 个阶段:
- Pretraining
- Gram anchoring
- High resolution adaptation
在配备 submitit 的 SLURM 集群环境中,使用 32 个节点(共 256 块 GPU)启动 DINOV3 ViT-7B/16 预训练。
4.2 DINOv3 模型蒸馏
PYTHONPATH=${PWD} python -m dinov3.run.submit dinov3/train/train.py \--nodes 1 \--config-file dinov3/configs/train/multi_distillation_test.yaml \--output-dir <PATH/TO/OUTPUT/DIR> \--multi-distillation \train.dataset_path=<DATASET>:root=<PATH/TO/DATASET>:extra=<PATH/TO/DATASET>
4.3 DINOv3 模型评估
训练代码定期保存教师权重。为评估模型,请在单节点上运行以下评估:
- ImageNet-1k 上的逻辑回归分类
PYTHONPATH=${PWD} python -m dinov3.run.submit dinov3/eval/log_regression.py \model.config_file=<PATH/TO/OUTPUT/DIR>/config.yaml \model.pretrained_weights=<PATH/TO/OUTPUT/DIR>/teacher_checkpoint.pth \output_dir=<PATH/TO/OUTPUT/DIR> \train.dataset=ImageNet:split=TRAIN:root=<PATH/TO/DATASET>:extra=<PATH/TO/DATASET> \eval.test_dataset=ImageNet:split=VAL:root=<PATH/TO/DATASET>:extra=<PATH/TO/DATASET>
- ImageNet-1k 上的 k-NN 分类
PYTHONPATH=${PWD} python -m dinov3.run.submit dinov3/eval/knn.py \model.config_file=<PATH/TO/OUTPUT/DIR>/config.yaml \model.pretrained_weights=<PATH/TO/OUTPUT/DIR>/teacher_checkpoint.pth \output_dir=<PATH/TO/OUTPUT/DIR> \train.dataset=ImageNet:split=TRAIN:root=<PATH/TO/DATASET>:extra=<PATH/TO/DATASET> \eval.test_dataset=ImageNet:split=VAL:root=<PATH/TO/DATASET>:extra=<PATH/TO/DATASET>
- ImageNet-1k 上的带数据增强线性分类
PYTHONPATH=${PWD} python -m dinov3.run.submit dinov3/eval/linear.py \model.config_file=<PATH/TO/OUTPUT/DIR>/config.yaml \model.pretrained_weights=<PATH/TO/OUTPUT/DIR>/teacher_checkpoint.pth \output_dir=<PATH/TO/OUTPUT/DIR> \train.dataset=ImageNet:split=TRAIN:root=<PATH/TO/DATASET>:extra=<PATH/TO/DATASET> \train.val_dataset=ImageNet:split=VAL:root=<PATH/TO/DATASET>:extra=<PATH/TO/DATASET>
- 在 DINOv3 上使用 dino.txt 的文本对齐
PYTHONPATH=${PWD} python -m dinov3.run.submit dinov3/eval/text/train_dinotxt.py \--nodes 4 \# An example config for text alignment is here: dinov3/eval/text/configs/dinov3_vitl_text.yaml \ trainer_config_file="<PATH/TO/DINOv3/TEXT/CONFIG>" \output-dir=<PATH/TO/OUTPUT/DIR>
上述命令将在 4 个节点上启动文本对齐训练,每个节点配备 8 张 GPU(共 32 张 GPU)。请注意,DINOv3 论文中的文本对齐模型是在私有数据集上训练的,此处我们仅在 dinov3/eval/text/configs/dinov3_vitl_text.yaml 中提供了一个基于 CocoCaptions 数据集的示例配置,供演示之用。请据此适配所提供的 CocoCaptions 数据集类,数据集可在此处获取
5. DINOv3 官方报道
- 我们推出 DINOv3,将图像自监督学习扩展以构建通用视觉骨干网络,在包括网络图像与卫星影像在内的多元领域均取得领先性能。
- DINOv3 骨干网络生成强大且高分辨率的图像特征,使得轻量级适配器的训练极为便捷,从而在图像分类、语义分割、视频目标跟踪等众多下游视觉任务上表现出卓越性能。
- 我们发布体积更小、却全面优于同类 CLIP 衍生模型的版本,以及为资源受限场景提供的替代 ConvNeXt 架构,进一步提升了 DINOv3 的通用性。
- 我们以商业许可证形式发布 DINOv3 的训练代码与预训练骨干网络,以助力计算机视觉与多模态生态系统的创新与进步。
自监督学习(SSL)——即人工智能模型可在无需人类监督的情况下独立学习的理念——已成为现代机器学习的主导范式。它推动了大型语言模型的崛起,这些模型通过对海量文本语料进行预训练而获得通用表征。然而,计算机视觉领域的进展相对滞后,因为当前最强大的图像编码模型在训练时仍严重依赖人类生成的元数据,例如网络图像说明文字。
今天,我们发布 DINOv3,一个采用 SSL 训练的通用型、最前沿计算机视觉模型,能够生成卓越的高分辨率视觉特征。首次实现单个冻结视觉骨干在多个长期存在的稠密预测任务(包括目标检测与语义分割)上超越专用解决方案。
DINOv3 的突破性能源于创新的 SSL 技术,这些技术摒弃了对标注数据的需求——大幅降低了训练所需的时间和资源,并使我们将训练数据规模扩展至 17 亿张图像,模型规模扩展至 70 亿参数。这种无需标签的方法适用于标注稀缺、昂贵或无法获取的场景。例如,我们的研究表明,在卫星影像上预训练的 DINOv3 骨干在冠层高度估计等下游任务上实现了卓越性能。
我们相信,DINOv3 将加速既有用例并解锁全新场景,推动医疗、环境监测、自动驾驶、零售与制造等行业的进步——实现大规模更准确、更高效的视觉理解。
我们以商业许可证发布 DINOv3,并提供一整套开源骨干网络,包括在 MAXAR 影像上训练的卫星骨干。我们还将共享部分下游评估头,供社区复现结果并在此基础上继续研究。此外,我们提供示例 notebook,为社区提供详尽文档,帮助其即刻开始使用 DINOv3 进行构建。
以自监督学习解锁高影响力应用
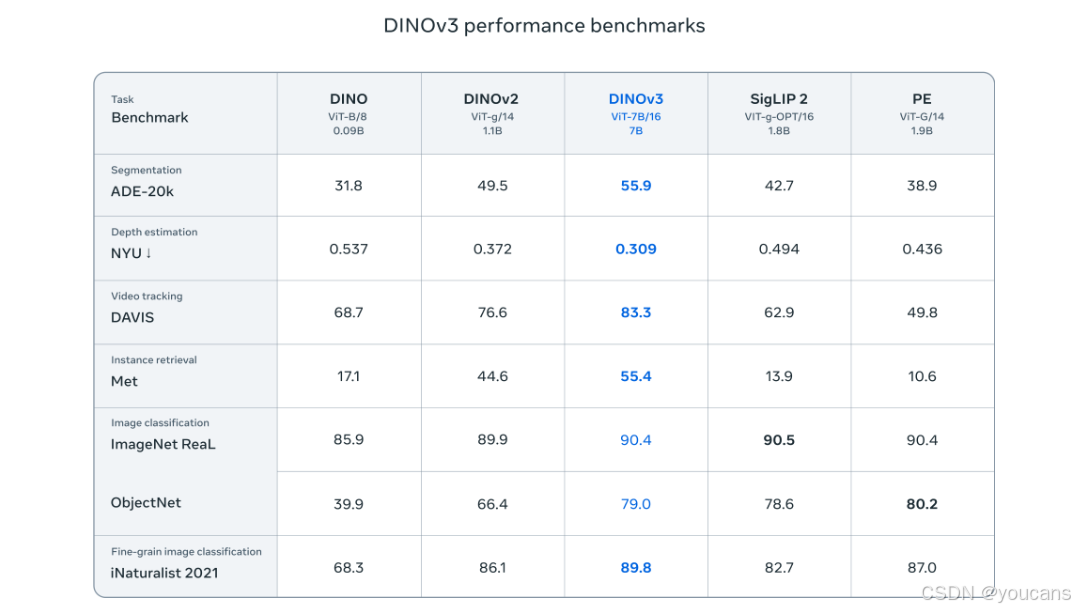
DINOv3 首次证明,SSL 模型在广泛任务中能够全面超越弱监督模型,从而达成新的里程碑。尽管先前的 DINO 模型在分割与单目深度估计等稠密预测任务中已确立显著领先优势,DINOv3 仍超越这些成就。我们的模型在众多图像分类基准上媲美或超越 SigLIP 2、Perception Encoder 等近期最强模型,同时显著拉大在稠密预测任务上的性能差距。
DINOv3 建立在突破性的 DINO 算法之上,无需任何元数据输入,仅消耗相较于先前方法极小部分的训练计算量,仍能提供极其强大的视觉基础模型。DINOv3 引入的新颖改进在权重冻结的严苛约束下,于目标检测等竞争性下游任务上达到最先进性能。这消除了研究人员与开发者针对特定任务微调模型的需求,使更广泛且高效的应用成为可能。
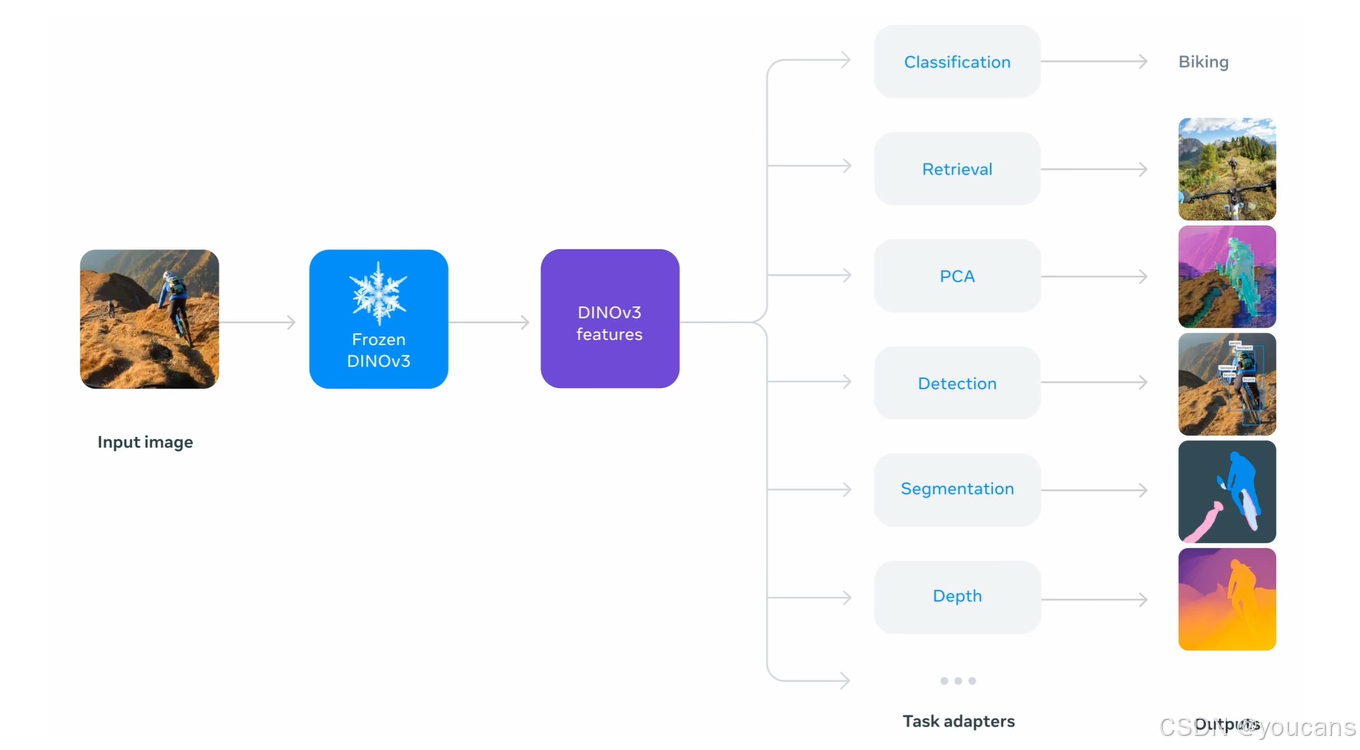
最后,由于 DINO 方法并非针对任何特定图像模态而设计,同一算法可应用于网络图像之外、标注成本极高或难以获取的其他领域。DINOv2 已利用海量无标注数据,支持组织学、内窥镜及医学影像中的诊断与研究工作。在卫星与航空影像领域,数据体量和复杂程度使得人工标注不切实际。借助 DINOv3,我们得以利用这些丰富数据集训练单一主干网络,并跨卫星类型通用,从而为环境监测、城市规划与灾害响应等应用提供支撑。
DINOv3 已在现实场景产生切实影响。世界资源研究所(WRI)正采用我们最新模型监测森林砍伐并支持生态修复,协助当地群体保护脆弱生态系统。WRI 利用 DINOv3 分析卫星影像,检测受威胁生态系统中的树木损失与土地利用变化。DINOv3 带来的精度提升,可通过核验修复成果实现气候资金支付的自动化,降低交易成本并加速向小型地方群体拨付资金。例如,相较于 DINOv2,DINOv3 在卫星与航空影像上训练后,将肯尼亚某区域树冠高度测量的平均误差从 4.1 米降至 1.2 米。WRI 现可更高效地扩展对数千名农户及保护项目的支持。
无需微调的可扩展高效视觉建模
我们通过在比前代 DINOv2 大 12 倍的数据集上训练 7 倍更大的模型,构建了 DINOv3。为展示模型通用性,我们在 15 项多样化视觉任务及 60 余项基准上对其进行评估。DINOv3 主干网络在所有稠密预测任务中表现尤为突出,展现出对场景布局与底层物理规律的卓越理解。
丰富稠密的特征以浮点向量形式表示图像中每个像素的可测属性或特征,能够将物体解析为更精细的部件,甚至跨实例与类别泛化。这种稠密表征能力使得在 DINOv3 之上仅需极少标注即可训练轻量级适配器——仅需少量标注与线性模型即可获得鲁棒的稠密预测。更进一步,采用更复杂的解码器,我们证明无需微调主干即可在经典核心计算机视觉任务上达到最先进性能,涵盖目标检测、语义分割与相对深度估计。
由于无需微调主干即可获得最先进结果,单次前向传播即可同时服务多个应用,主干网络的推理成本可在任务间共享,这对需同时运行多项预测的端侧应用尤为关键。DINOv3 的通用性与高效性使其成为此类部署场景的理想选择,NASA 喷气推进实验室(JPL)已采用 DINOv2 构建火星探测机器人,以极低算力实现多项视觉任务,即为明证。
部署友好的模型族
将 DINOv3 扩展至 7 B 参数充分展现了 SSL 的潜力,然而 7 B 模型对众多下游应用并不现实。应社区反馈,我们构建了一组覆盖广泛推理算力需求的模型,以赋能不同场景的研究者与开发者。通过将 ViT-7B 模型蒸馏为更小的 ViT-B 与 ViT-L 等高性能变体,DINOv3 在全面评测套件上全面超越同类 CLIP 基模型。此外,我们还推出由 ViT-7B 蒸馏而来的 ConvNeXt 架构替代方案(T、S、B、L),可适配不同算力约束;并同步开源蒸馏管线,供社区在此基础上继续拓展。
即刻获取我们的预训练模型、代码与社区资源
过去四年,DINO 与 DINOv2 在各行各业产生深远影响,我们欣喜地以 DINOv3 延续这一动能。早期 DINOv3 合作伙伴已分享出色成果,我们期待开源社区基于我们迄今为止最强大的模型开发出更多有意义的新技术。一如既往,我们将与合作伙伴紧密协作,倾听反馈并持续迭代,让模型惠及所有人。
引用标注
@misc{simeoni2025dinov3,title={{DINOv3}},author={Sim{\'e}oni, Oriane and Vo, Huy V. and Seitzer, Maximilian and Baldassarre, Federico and Oquab, Maxime and Jose, Cijo and Khalidov, Vasil and Szafraniec, Marc and Yi, Seungeun and Ramamonjisoa, Micha{\"e}l and Massa, Francisco and Haziza, Daniel and Wehrstedt, Luca and Wang, Jianyuan and Darcet, Timoth{\'e}e and Moutakanni, Th{\'e}o and Sentana, Leonel and Roberts, Claire and Vedaldi, Andrea and Tolan, Jamie and Brandt, John and Couprie, Camille and Mairal, Julien and J{\'e}gou, Herv{\'e} and Labatut, Patrick and Bojanowski, Piotr},year={2025},eprint={2508.10104},archivePrefix={arXiv},primaryClass={cs.CV},url={https://arxiv.org/abs/2508.10104},
}
版权声明:
youcans@qq.com 原创作品,转载必须标注原文链接:
【AGI使用教程】Meta 开源视觉基础模型 DINOv3
Copyright@youcans 2025
Crated:2025-10