TeR-TSF 论文解读
论文:Text Reinforcement for Multimodal Time Series Forecasting
现有工作、问题、解决方法
1.利用历史数值数据,挖掘周期性和多分辨率——固有模态的瓶颈,需要其他信息补充——文本
2.加入文本的方法: 图注意力;基于transformer的图注意力——难以捕捉细微文本表示——llm更好编码事件与文本信息 llm——将时间序列视作固定输入,忽略随机波动性——整合概率模型 整合概率框架(扩散模型等)的多模态时间学列框架(TSF)——文本的缺失、与时序没有对齐——数据增强
3.数据增强方法 传统的插值、噪声注入、生成模型——增强单模态时间序列具有局限性;依赖静态增强策略;无法生成与数值观测数据有动态关联性的文本——llm自适应生成对应文本 llm——无法判断生成文本对下游时间序列预测的辅助效果——用间接评价指标,可以通过强化学习
4.强化学习 聚焦于模型层面 聚焦于数据增强技术 主要集中在时间序列数据的增强上
文本往往缺失、稀疏或与数值不对齐,论文提出把文本视为可以被强化的模态
方法
本文中的方法:基于强化学习的方法增强文本信息
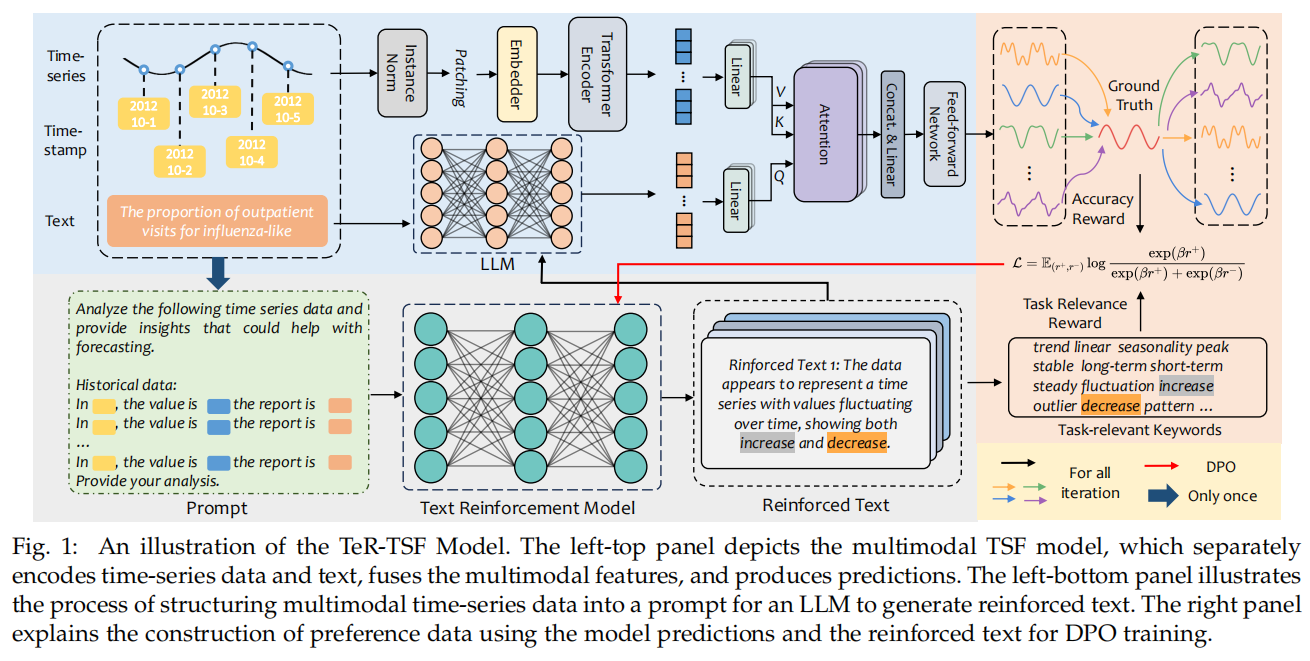
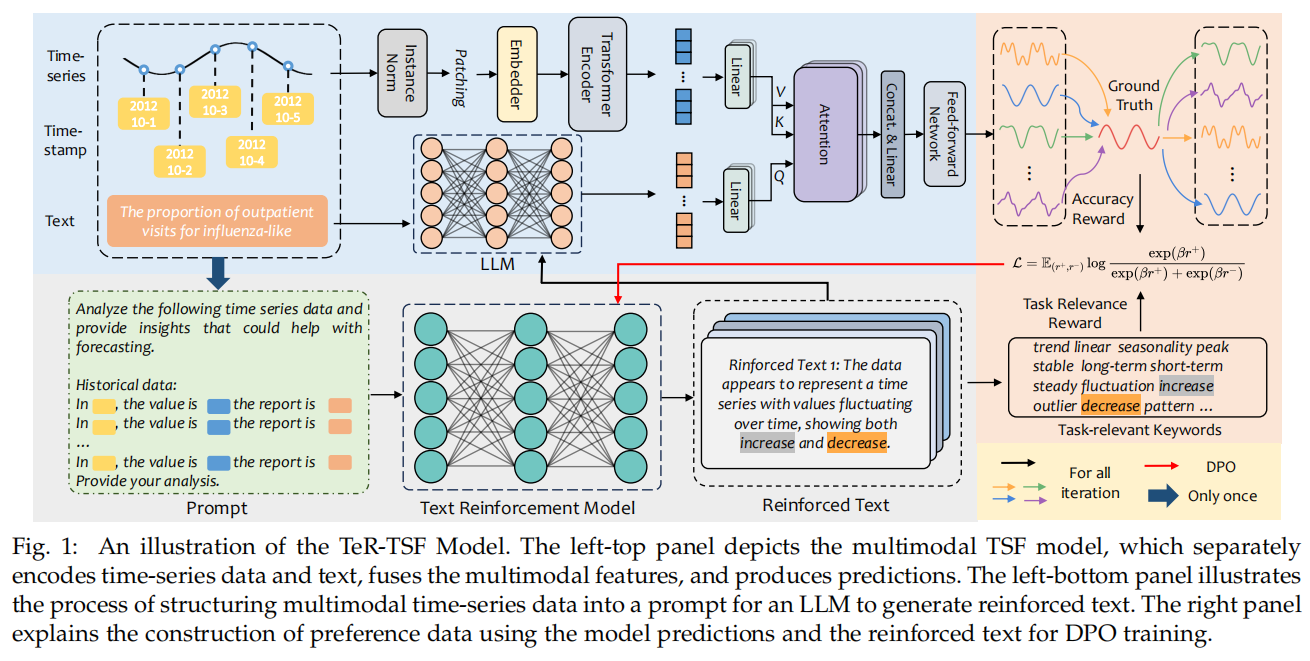
核心是一个闭环的文本强化—评估—偏好优化流程。 先把历史数值转成可读文本(Stxt)并拼上原始文本 E 与任务提示 P,喂给 LLM(TeR)生成若干候选的“强化文本” E_aug;把每个候选与时间序列一起输入多模态 TSF(时间序列用 patch token 化的 Transformer 编码,文本做 embedding 并通过 cross-attention 融合)得到预测,再用双重 reward评估每个候选: 一是基于下游预测效果的奖励(r1 = −MSE),二是基于任务相关关键词覆盖的奖励(r2)。按综合 reward 排序取最优与最差作为偏好对,使用 DPO(Direct Preference Optimization) 直接微调 LLM,使其更倾向生成高 reward 的文本。生成—评估—DPO 按轮迭代 m 次,并在 TSF 侧用选出的强化文本重训练/评估,形成闭环自我改进。
动机:把下游目标直接反馈给文本生成器(避免盲目生成)、通过关键词约束保证可解释性、用 DPO 避开复杂不稳定的 RL 套路同时保留偏好式优化信号。

实验
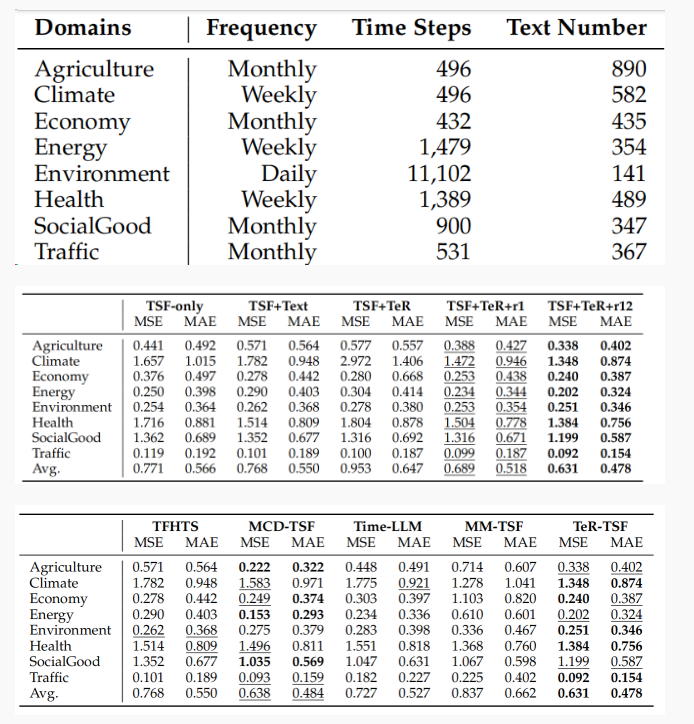
1. 在 Time-MMD(覆盖 Agriculture/Climate/Economy/… 共 8 个领域)上做了全面实证比较和消融试验。与多种基线(仅 TSF、直接把文本拼入的 TFHTS、仅生成但不 RL 的变体、只用 r1、以及多种 SOTA 多模态方法)比较,TeR-TSF(采用 r1+r2 的双奖励并用 DPO 微调生成器)在平均 MSE/MAE 上取得最低或次低误差,表格与实验结果显示整体平均误差明显优于不优化文本质量的方案;
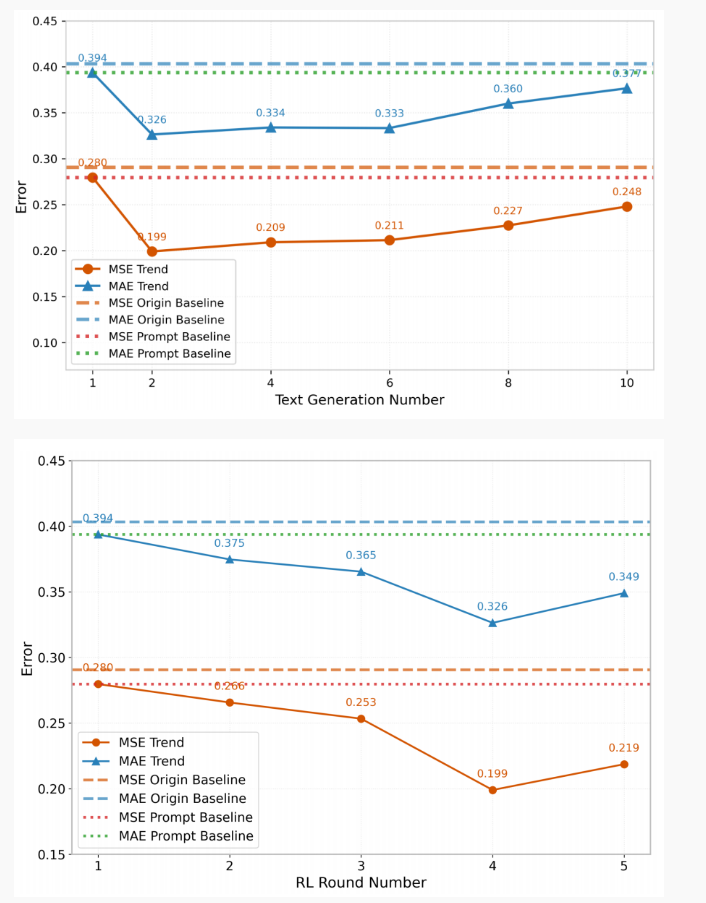
2. 消融实验显示生成候选数 k 从 1 增到 2 带来收益但过大反而降效,RL 迭代轮数 m 有最佳区间,LLM 大小也有“适中最好、过大易过拟合”的现象
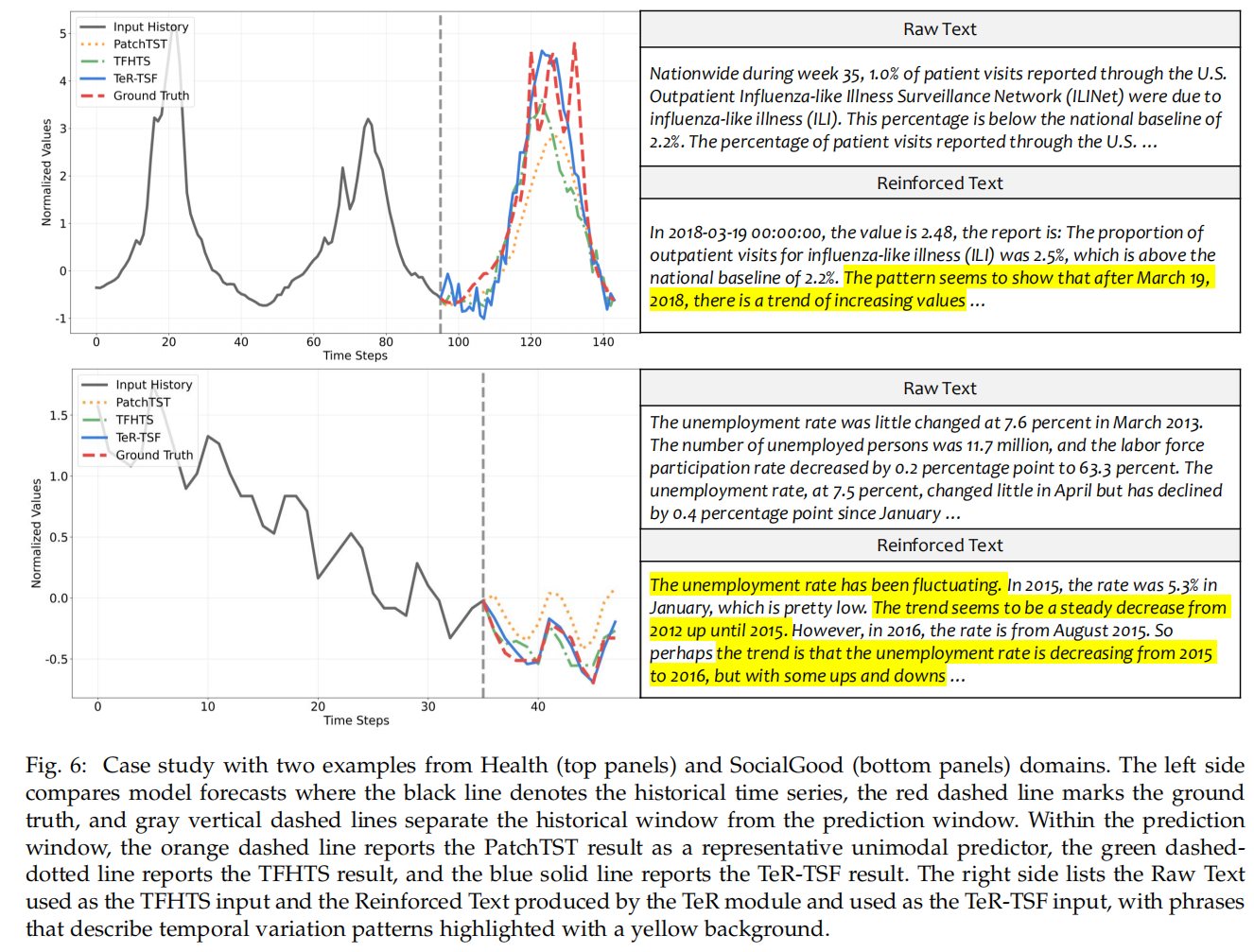
3. t-SNE 和 case study 展示了强化文本在语义上更集中于“trend/seasonality/peak”等时序相关词,从机制上解释了为什么生成的文本更有助预测。 局限:方法依赖生成器质量且计算开销(多候选生成 + 下游评估 + 多轮微调)高,若 LLM 严重幻觉也会带来风险。
启发
1.辅助文本数据可能提升TSF精度,但其优势仍受限于领域特定文本质量的差异。
2.仅使用语言模型生成文本(TSF+TeR)的TSF模型比TSF+文本和纯TSF模型都产生更高误差。这一结果表明,未经特定指导的语言模型生成文本常会引入与预测目标无关的内容,或遗漏原始数据中的关键信息。这种文本效用的下降直接削弱了预测效果。
3.通过预测精度奖励机制引导的强化学习,能使LLM生成真正有利于时间序列预测的文本。补充的任务相关性奖励能有效引导LLM输出更精准、更符合上下文的文本生成。