构建模拟人类思维过程的高级智能体检索增强生成(Agentic RAG)流水线模糊性检查、多工具规划、自我修正、因果推理等功能
*大家好,我是AI拉呱,一个专注于人工智领域与网络安全方面的博主,现任资深算法研究员一职,热爱机器学习和深度学习算法应用,拥有丰富的AI项目经验,希望和你一起成长交流。关注AI拉呱一起学习更多AI知识。
构建模拟人类思维过程的高级智能体检索增强生成(Agentic RAG)流水线模糊性检查、多工具规划、自我修正、因果推理等功能
标准的检索增强生成(RAG)系统只能查找并总结事实,无法真正进行“思考”。而智能体检索增强生成(Agentic RAG)在此基础上更进一步——它能阅读、检查、关联信息并进行推理,使其更像一位专家,而非简单的搜索工具。这种改进后的工作流程新增了诸多步骤,模拟人类解决问题的方式,其目标不仅是给出答案,更是真正理解问题本身。
在本文中,我们将构建一条高级智能体检索增强生成流水线,模拟人类阅读和理解问题的过程……
智能体检索增强生成(Agentic RAG)流水线(由法里德·汗创建)
以下是我们的智能体将如何模拟人类分析师进行思考的流程:
- 构建丰富的知识库——智能体并非简单读取文本,而是会仔细解析文档(保留表格和结构),并利用大语言模型(LLM)添加摘要和关键词,形成多层级的理解体系。
- 组建专业工具团队——没有人是全才,智能体也不例外。它依赖各类专业工具:处理文档的“图书管理员(Librarian)”、分析数据库的“分析师(Analyst)”,以及获取实时网络数据的“侦察员(Scout)”。
- 由“守门人(Gatekeeper)”在行动前检查问题——智能体会判断查询是否清晰、具体。若查询模糊,它会请求用户澄清,而非给出笼统或不完整的答案。
- 由“规划师(Planner)”制定有条理的计划——问题通过验证后,规划师会将用户需求拆解为逐步的工具调用步骤,确保流程结构化,避免仓促作答。
- 由“审计师(Auditor)”验证结果——每款工具的输出都会经过质量和一致性审查。若结果质量不佳或存在矛盾,智能体会重新规划并自我修正。
- 由“策略师(Strategist)”建立信息关联——最终回复并非简单的事实罗列。策略师会寻找关联、模式和假设,将原始数据转化为更深入的见解。
- 进行对抗性测试——由“红队机器人(Red Team Bot)”用复杂、误导性或带有偏见的问题挑战系统,确保其在压力下仍能保持稳健性和可信度。
- 持续进化升级——超越简单的问答功能,新增认知记忆(从过往交互中学习)、瞭望塔(主动监控重要事件)、神谕(解读图表等视觉数据)等新能力。
特别感谢优步(Uber)开发团队,他们发布的博客探讨了如何改进智能体检索增强生成技术,为本文提供了宝贵参考。
所有代码均已上传至我的GitHub仓库:
GitHub - FareedKhan-dev/agentic-rag: 实现类人推理的智能体检索增强生成(Agentic RAG)
实现类人推理的智能体检索增强生成(Agentic RAG)。通过创建……为 FareedKhan-dev/agentic-rag 开发贡献力量。
github.com
目录
本文的目录分为以下几个阶段:
第一阶段:构建知识核心
- 下载并整合非结构化数据
- 将原始HTML转换为结构化元素
- 执行结构化感知分块
- 生成深度理解元数据
- 填充向量存储和关系型存储
第二阶段:构建并测试专业智能体工具
- 创建多步骤RAG图书管理员工具
- 用于结构化数据的SQL查询智能体
- 新增趋势分析工具
- 用于实时数据的侦察员智能体
第三阶段:构建高级推理引擎
- 定义主图和增强状态
- 用于模糊性检测的守门人节点
- 规划师节点
- 工具执行器节点
- 用于认知自我修正的审计师节点
- 实现条件路由器
- 具备因果推理功能的策略师节点合成器
- 编译并运行高级图
第四阶段:推理引擎评估核心(Cortex)
- 定量评估(检索质量)
- 定性评估(以LLM为评判者)
- 性能评估(速度与成本)
第五阶段:压力测试(红队测试)
- 推理引擎的主动防御
进一步改进方向
第一阶段:构建知识核心
在构建高级智能体之前,我们需要奠定基础。这一初始阶段的目标是建立一个干净、可复现的环境,并获取为智能体提供“智能”的原始数据——对于任何生产级系统而言,这都是必不可少的第一步。
[外链图片转存中…(img-Vre3X5VV-1758960548603)]
第一阶段工作流程(由法里德·汗创建)
该流水线的目的是模拟人类阅读文档并寻找答案时的思考过程。为应对真实场景,我们必须使用真实数据——因此,我们选择微软(Microsoft)公开的美国证券交易委员会(SEC)文件作为处理对象。
下载并整合非结构化数据
我们将使用sec-edgar-downloader库以编程方式下载这些文档。
from sec_edgar_downloader import Downloader# 初始化下载器。SEC EDGAR API要求提供公司名称和邮箱
dl = Downloader("Archon Corp", "analyst@archon.ai")
COMPANY_TICKER = "MSFT" # 微软的股票代码# 下载10-K年度报告
dl.get("10-K", COMPANY_TICKER, limit=1)# 下载10-Q季度报告
dl.get("10-Q", COMPANY_TICKER, limit=4)# 下载8-K当前报告
dl.get("8-K", COMPANY_TICKER, limit=1)# 下载股东委托书(DEF 14A)
dl.get("DEF 14A", COMPANY_TICKER, limit=1)
代码将开始下载数据。我们在此处传入的“MSFT”是微软的股票代码,“limit”参数定义了要获取的历史季度报告数量(例如,limit=4表示下载最近4份季度报告)。通过代码下载时,还需提供公司联系邮箱(这是API的强制要求);若没有公司邮箱,也可直接访问SEC官网手动下载数据。
接下来,让我们快速了解一下这些数据集:
- 10-K文件:年度报告,包含公司财务状况、风险因素和业务计划的完整概述。
- 10-Q文件:季度报告,包含公司年度内的财务更新和业绩情况。
- 8-K文件:当前报告,包含并购、管理层变动、收益发布等重大事件信息。
- DEF 14A文件:股东委托书,包含高管薪酬、董事会成员及投票事项等面向股东的详细信息。
这些文档篇幅长、结构复杂,正是强大的RAG智能体旨在处理的非结构化数据类型。下面我们验证文件是否已保存到本地目录:
DATA_PATH = f"sec-edgar-filings/{COMPANY_TICKER}/"
all_files = []# 遍历目录,收集所有"full-submission.txt"文件(下载器将完整提交内容保存为包含HTML的TXT文件)
for root, dirs, files in os.walk(DATA_PATH):for file in files:if file == "full-submission.txt":all_files.append(os.path.join(root, file))print(f"找到 {len(all_files)} 个待处理的HTML文件:")
# 为简洁起见,仅打印前5个文件路径
for f in all_files[:5]:print(f"- {f}")
输出结果
找到 7 个待处理的HTML文件:
- sec-edgar-filings/MSFT/10-K/0001564590-23-008262/full-submission.txt
- sec-edgar-filings/MSFT/10-Q/0000950170-24-004388/full-submission.txt
- sec-edgar-filings/MSFT/10-Q/0000950170-24-000573/full-submission.txt
- sec-edgar-filings/MSFT/10-Q/0000950170-23-054944/full-submission.txt
- sec-edgar-filings/MSFT/10-Q/0001564590-23-004926/full-submission.txt
输出结果确认,代码已创建“sec-edgar-filings/”目录,并将下载的文档存入其中。至此,我们的非结构化知识库已准备好进行数据导入。
高级智能体不应局限于单一数据类型。为增强“分析师”智能体的能力,并测试“主管(Supervisor)”智能体选择工具的准确性,我们还需要一个结构化的关系型数据集——这一步至关重要,能迫使主管智能体学习何时使用SQL工具,何时使用文档检索工具。
我们将通过创建一个包含关键财务指标的简单CSV文件来模拟该数据集。在实际场景中,这类数据通常来自金融API或内部数据仓库:
# 定义2022-2023年的营收和净利润数据
revenue_data = {'year': [2023, 2023, 2023, 2023, 2022, 2022, 2022, 2022],'quarter': ['Q4', 'Q3', 'Q2', 'Q1', 'Q4', 'Q3', 'Q2', 'Q1'],'revenue_usd_billions': [61.9, 56.5, 52.9, 52.7, 51.9, 50.1, 49.4, 51.7], # 营收(十亿美元)'net_income_usd_billions': [21.9, 22.3, 17.4, 16.4, 17.6, 16.7, 16.7, 18.8] # 净利润(十亿美元)
}# 从字典创建DataFrame
df = pd.DataFrame(revenue_data)
# 将DataFrame保存为CSV文件
CSV_PATH = "revenue_summary.csv"
df.to_csv(CSV_PATH, index=False)
我们现已创建“revenue_summary.csv”文件,数据获取阶段就此完成。目前,非结构化数据(HTML文件)和结构化数据(CSV文件)均已准备就绪,可进入后续处理环节。
原始数据下载完成后,我们将进入所有RAG系统的初始阶段——构建知识核心(即知识库)。
将原始HTML转换为结构化元素
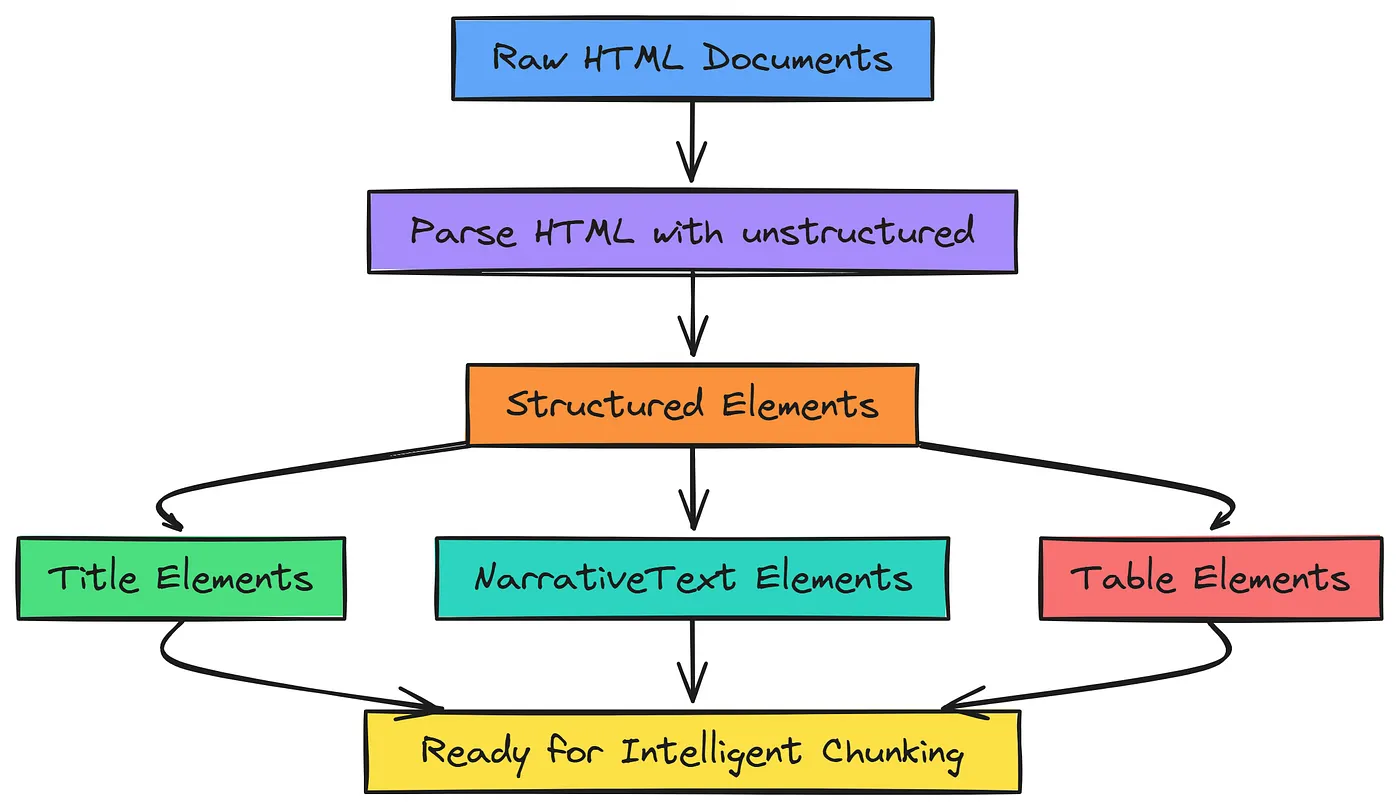
我们的原始数据是结构较为复杂的HTML文档。若采用简单的文本提取方式,会丢失标题、列表,尤其是表格等所有有价值的结构信息,最终将所有内容压缩成一个无差别的文本块。
对于依赖大量结构化和非结构化数据的企业而言,这是一个普遍难题;要在这些数据基础上构建真正智能的体,就必须避免这种情况。
[外链图片转存中…(img-epmXzgn1-1758960548606)]
原始HTML转换(由法里德·汗创建)
我们将使用unstructured库对HTML进行高级解析。与基础方法不同,该库会将文档拆分为“标题(Title)”“叙述文本(NarrativeText)”“表格(Table)”等有意义的元素列表。
保留结构信息是实现智能分块的关键第一步——这让系统能像人类一样“看清”文档的结构。
下面我们创建一个解析函数,并在下载的10-K文件上进行测试:
from typing import List, Dict
from unstructured.partition.html import partition_htmldef parse_html_file(file_path: str) -> List[Dict]:"""使用unstructured库解析HTML文件,并返回元素列表。"""try:# 解析HTML,启用表格结构推断,采用"fast"策略以平衡速度和精度elements = partition_html(filename=file_path, infer_table_structure=True, strategy='fast')# 将元素转换为字典格式返回return [el.to_dict() for el in elements]except Exception as e:print(f"解析 {file_path} 时出错:{e}")return []# 以最近的10-K文件为例进行解析
ten_k_file = [f for f in all_files if "10-K" in f][0]
print(f"正在解析文件:{ten_k_file}...")parsed_elements = parse_html_file(ten_k_file)print(f"\n解析完成,共得到 {len(parsed_elements)} 个元素。")
print("\n--- 元素示例 ---")# 打印部分元素,查看其类型和内容
for i, element in enumerate(parsed_elements[20:25]): # 展示元素的一个切片elem_type = element.get('type', '未知类型')# 截取前100个字符作为文本片段,替换换行符以保持格式整洁text_snippet = element.get('text', '')[:100].replace('\n', ' ') + '...'print(f"元素 {i+20}:[类型:{elem_type}] - 内容:'{text_snippet}'")
parse_html_file函数接收单个文件路径作为输入,内部使用unstructured库的partition_html函数完成核心解析工作。我们设置infer_table_structure=True以确保库会专门识别并处理表格,最终返回这些结构化元素的列表。
运行上述代码,得到以下结果:
输出结果
正在解析文件:sec-edgar-filings/MSFT/10-K/0001564590-23-008262/full-submission.txt...解析完成,共得到 6328 个元素。--- 元素示例 ---
元素 20:[类型:Title] - 内容:'Table of Contents'...
元素 21:[类型:NarrativeText] - 内容:'UNITED STATES SECURITIES AND EXCHANGE COMMISSION Washington, D.C. 20549'...
元素 22:[类型:Title] - 内容:'FORM 10-K'...
元素 23:[类型:NarrativeText] - 内容:'(Mark One)'...
元素 24:[类型:NarrativeText] - 内容:'☒ ANNUAL REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934'...
单个文档已被拆分为6000多个独立元素,更重要的是,示例显示这些元素已被标注类型(如“Title”“NarrativeText”)。这种结构感知能力,正是我们下一步实现智能分块所必需的。
执行结构化感知分块
有了结构化元素后,我们就能解决传统RAG的一大痛点——“破坏性分块”。传统方法(如按固定字符数拆分)不考虑内容逻辑,可能会将句子,甚至更糟的——将表格从中间拆分,导致信息失效。
我们将采用unstructured库的chunk_by_title策略,这种方法更为智能:它会将相关文本归类到对应的标题下,且最重要的是,它会将表格视为不可分割的原子单元进行处理。
按回车键或点击即可查看完整尺寸图片
语义感知分块(由法里德·汗创建)
表格被拆分后会完全失去意义,而这种结构化感知分块方法能防止我们在数据导入过程中破坏关键表格数据。
from unstructured.documents.elements import element_from_dict
from unstructured.chunking.title import chunk_by_title# 将解析得到的字典格式元素转换回unstructured的Element对象
elements_for_chunking = [element_from_dict(el) for el in parsed_elements]# 使用"chunk_by_title"策略对元素进行分块
chunks = chunk_by_title(elements_for_chunking,max_characters=2048, # 每个分块的最大字符数combine_text_under_n_chars=256, # 合并字符数少于256的小文本块new_after_n_chars=1800 # 若当前分块字符数超过1800,则强制开始新分块
)print(f"文档已分块为 {len(chunks)} 个部分。")print("\n--- 分块示例 ---")# 初始化文本分块和表格分块的占位符
text_chunk_sample = None
table_chunk_sample = None# 查找第一个较大的文本分块和第一个表格分块
for chunk in chunks:# 文本分块:元数据中无"text_as_html",且长度超过500字符if 'text_as_html' not in chunk.metadata.to_dict() and text_chunk_sample is None and len(chunk.text) > 500:text_chunk_sample = chunk# 表格分块:元数据中包含"text_as_html"if 'text_as_html' in chunk.metadata.to_dict() and table_chunk_sample is None:table_chunk_sample = chunk# 找到两种分块后退出循环if text_chunk_sample and table_chunk_sample:break# 打印文本分块示例详情
if text_chunk_sample:print("** 文本分块示例 **")print(f"内容:{text_chunk_sample.text[:500]}...") # 预览前500个字符print(f"元数据:{text_chunk_sample.metadata.to_dict()}")# 打印表格分块示例详情
if table_chunk_sample:print("\n** 表格分块示例 **")print(f"HTML内容:{table_chunk_sample.metadata.text_as_html[:500]}...") # 预览HTML内容print(f"元数据:{table_chunk_sample.metadata.to_dict()}")
在此步骤中,我们首先将字典列表转换回unstructured的Element对象,再将其传入chunk_by_title函数。通过参数设置,我们既能控制分块的大致尺寸,又能让算法灵活遵循文档的自然结构边界。
输出结果
文档已分块为 371 个部分。--- 分块示例 ---
** 文本分块示例 **
内容:ITEM 1. BUSINESSGENERALMicrosoft is a technology company whose mission is to empower every person and every organization on the planet to achieve more...
元数据:{'filetype': 'text/html', 'page_number': 1, 'filename': 'full-submission.txt'}** 表格分块示例 **
HTML内容:<table><tr><td align="left" rowspan="2"></td><td align="center" colspan="3">For the Fiscal Year Ended June 30,</td>...
元数据:{'filetype': 'text/html', 'page_number': 3, 'filename': 'full-submission.txt', 'text_as_html': '<table>...</table>'}
这是我们在数据质量上的重大突破:我们已将数千个小元素精简为371个具有逻辑关联、包含上下文的分块。关键亮点体现在表格分块示例中——其元数据包含“text_as_html”键,这表明unstructured库已正确识别并保留了完整表格的结构。至此,我们成功避免了关键信息的损坏。
关注“AI拉呱”一起学习更多AI知识!