阜宁网站制作公司报价视频制作报价表
目录
一、logistic回归基本概念
1.1 定义
1.2 分类原理
1.3 与线性回归的区别
线性回归预测连续值,适用于回归任务
logistic回归预测概率,适用于分类任务
二、损失函数与优化
2.1 损失函数
2.2 优化方法
2.2.1 批量梯度下降(BGD)
过程
优点
缺点
2.2.2 随机梯度下降(SGD)
过程
缺点
2.2.3 小批量梯度下降(MGD)
过程
三、正则化
3.1 L1正则化
3.2 L2正则化
四、Logistic回归应用实例:基于二维数据集的分类实践
数据集:包含两个特征 (x1, x2) 和一个二分类标签 (y, 0 或 1)
代码实现
一、logistic回归基本概念
1.1 定义
Logistic回归是一种用于解决二分类问题(也可扩展到多分类)的监督学习算法,预测结果是 概率值(0到1之间)。
通过Sigmoid函数将线性组合映射到概率,公式为
其中
- w是权重
- b是偏置
- X是输入特征
1.2 分类原理
根据概率值设定阈值(通常为0.5)进行分类
预测值 > 阈值 正类
预测值 < 阈值 负类
1.3 与线性回归的区别
线性回归预测连续值,适用于回归任务
logistic回归预测概率,适用于分类任务
二、损失函数与优化
2.1 损失函数
logistic回归适用对数损失函数(也称交叉熵损失)
其中 是真实标签(0或1),
是预测概率,m是样本数
2.2 优化方法
梯度下降:通过迭代更新权重w和偏置b最小化损失函数
梯度推导:损失函数对权重和偏置的偏导数
- 权重更新
其中
表示第i个样本的第j个特征值
i:样本索引,范围从1到m(总样本数)
j:特征索引,范围从1到n(特征数)
- 偏置更新
2.2.1 批量梯度下降(BGD)
每次迭代时使用整个数据集来计算损失函数的梯度,并更新模型参数
其中
- m为样本总数
是学习率
是预测概率
学习率 是一个超参数,用于控制模型参数在每次迭代中更新的步长,决定了参数向梯度反方向移动的距离。
过程
- 1.计算整个数据集的损失函数梯度
- 2.根据梯度更新所有权重和偏置
- 3.重复直到收敛
优点
- 收敛稳定性:由于使用整个数据集,梯度估计准确,更新方向稳定,易收敛到全局最优
- 适合小数据集:当数据集较小时,计算成本可接受,性能较好
缺点
- 计算成本高:每次迭代需要遍历整个数据集,时间复杂度为O(m),对是大数据集效率低
- 内存需求大:需要将整个数据集加载到内存,适合小型数据集
2.2.2 随机梯度下降(SGD)
每次迭代时随机选择一个样本来计算梯度,并更新模型参数
其中 i是随机选取的样本索引
过程
- 1.从训练集中随机抽取一个样本
- 2.计算该样本的损失函数梯度
- 3.更新权重和偏置
- 4.重复直到收敛或者达到最大迭代次数
优点
- 计算效率高:每次迭代只要处理一个样本,时间复杂度为O(1),适合大数据集
缺点
- 梯度噪声大:仅基于单个样本的梯度计算,可能导致更新方向不稳定,收敛路径震荡
2.2.3 小批量梯度下降(MGD)
每次迭代时使用一小部分样本计算梯度并更新参数,结合了BGD和SGD的特点
其中n为批次大小
过程
- 1.将数据集随机划分为多个小批量(mini-batch)
- 2.对每个小批量计算损失函数的梯度
- 3.更新权重和偏置
- 4.遍历所有小批量,重复直到收敛

三、正则化
目的:防止过拟合,提高模型泛化能力
3.1 L1正则化
添加权重绝对值之和,易产生稀疏解
稀疏解是指在模型的参数向量(如权重w)中,许多元素为0的解
特点:
参数向量中0占主导,非零元素少
对应模型中,只有少数特征起预测作用
3.2 L2正则化
添加权重平方和,使得权重趋向于小值但不完全为0
其中 为正则化参数
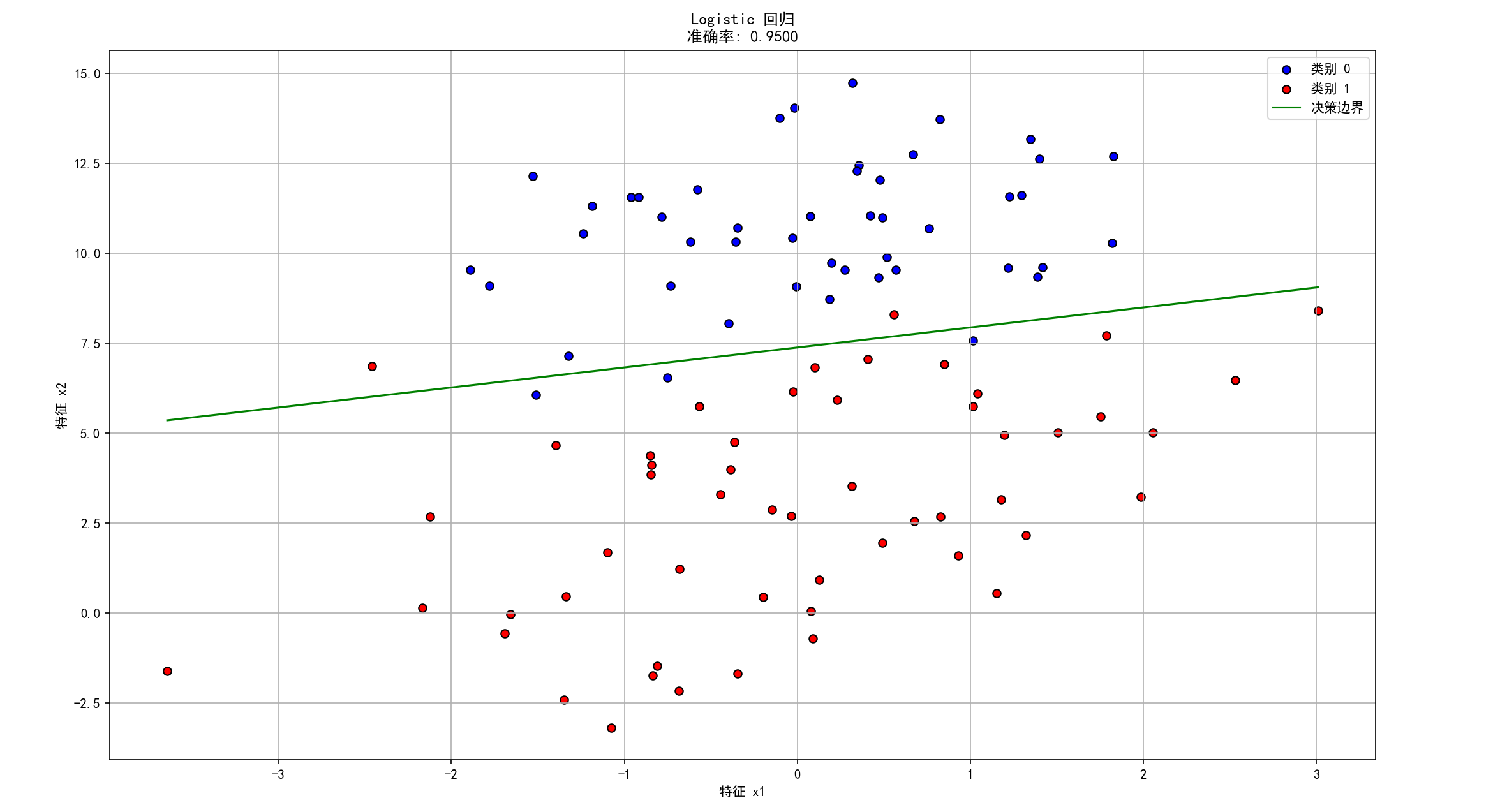
四、Logistic回归应用实例:基于二维数据集的分类实践
数据集:包含两个特征 (x1, x2) 和一个二分类标签 (y, 0 或 1)
-0.017612 14.053064 0
-1.395634 4.662541 1
-0.752157 6.538620 0
-1.322371 7.152853 0
0.423363 11.054677 0
0.406704 7.067335 1
0.667394 12.741452 0
-2.460150 6.866805 1
0.569411 9.548755 0
-0.026632 10.427743 0
0.850433 6.920334 1
1.347183 13.175500 0
1.176813 3.167020 1
-1.781871 9.097953 0
-0.566606 5.749003 1
0.931635 1.589505 1
-0.024205 6.151823 1
-0.036453 2.690988 1
-0.196949 0.444165 1
1.014459 5.754399 1
1.985298 3.230619 1
-1.693453 -0.557540 1
-0.576525 11.778922 0
-0.346811 -1.678730 1
-2.124484 2.672471 1
1.217916 9.597015 0
-0.733928 9.098687 0
-3.642001 -1.618087 1
0.315985 3.523953 1
1.416614 9.619232 0
-0.386323 3.989286 1
0.556921 8.294984 1
1.224863 11.587360 0
-1.347803 -2.406051 1
1.196604 4.951851 1
0.275221 9.543647 0
0.470575 9.332488 0
-1.889567 9.542662 0
-1.527893 12.150579 0
-1.185247 11.309318 0
-0.445678 3.297303 1
1.042222 6.105155 1
-0.618787 10.320986 0
1.152083 0.548467 1
0.828534 2.676045 1
-1.237728 10.549033 0
-0.683565 -2.166125 1
0.229456 5.921938 1
-0.959885 11.555336 0
0.492911 10.993324 0
0.184992 8.721488 0
-0.355715 10.325976 0
-0.397822 8.058397 0
0.824839 13.730343 0
1.507278 5.027866 1
0.099671 6.835839 1
-0.344008 10.717485 0
1.785928 7.718645 1
-0.918801 11.560217 0
-0.364009 4.747300 1
-0.841722 4.119083 1
0.490426 1.960539 1
-0.007194 9.075792 0
0.356107 12.447863 0
0.342578 12.281162 0
-0.810823 -1.466018 1
2.530777 6.476801 1
1.296683 11.607559 0
0.475487 12.040035 0
-0.783277 11.009725 0
0.074798 11.023650 0
-1.337472 0.468339 1
-0.102781 13.763651 0
-0.147324 2.874846 1
0.518389 9.887035 0
1.015399 7.571882 0
-1.658086 -0.027255 1
1.319944 2.171228 1
2.056216 5.019981 1
-0.851633 4.375691 1
-1.510047 6.061992 0
-1.076637 -3.181888 1
1.821096 10.283990 0
3.010150 8.401766 1
-1.099458 1.688274 1
-0.834872 -1.733869 1
-0.846637 3.849075 1
1.400102 12.628781 0
1.752842 5.468166 1
0.078557 0.059736 1
0.089392 -0.715300 1
1.825662 12.693808 0
0.197445 9.744638 0
0.126117 0.922311 1
-0.679797 1.220530 1
0.677983 2.556666 1
0.761349 10.693862 0
-2.168791 0.143632 1
1.388610 9.341997 0
0.317029 14.739025 0代码实现
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression# 1. 加载数据集
data = pd.read_csv('Logistic_testSet.txt', sep='\t', header=None, names=['x1', 'x2', 'y'])
X = data[['x1', 'x2']].values
y = data['y'].values# 2. 训练 Logistic 回归模型
model = LogisticRegression(penalty='l2', C=1.0, solver='lbfgs')
model.fit(X, y)# 3. 评估模型准确率
accuracy = model.score(X, y)
print(f"模型准确率: {accuracy:.4f}")# 4. 设置中文支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 5. 可视化
# 绘制数据点
plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], c='blue', label='类别 0', edgecolors='k')
plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], c='red', label='类别 1', edgecolors='k')# 计算并绘制决策边界直线
w = model.coef_[0] # 权重 [w1, w2]
b = model.intercept_[0] # 偏置
x1_min, x1_max = X[:, 0].min(), X[:, 0].max()
x1_line = np.array([x1_min, x1_max])
x2_line = -(w[0] * x1_line + b) / w[1] # 决策边界: w1*x1 + w2*x2 + b = 0
plt.plot(x1_line, x2_line, 'g-', label='决策边界')# 设置图表属性
plt.xlabel('特征 x1')
plt.ylabel('特征 x2')
plt.title(f'Logistic 回归\n准确率: {accuracy:.4f}')
plt.legend()
plt.grid(True)
plt.show()模型初始化:model = LogisticRegression(penalty='l2', C=1.0, solver='lbfgs')
- penalty='l2':指定正则化类型为L2正则化
- C=1.0 (C=
) ,控制正则化的程度
- solver=‘lbfgs’指定优化算法为L-BFGS
模型训练:model.fit(X, y) 使用输入数据X和标签y训练模型,优化权重w和偏置b
可视化