C语言字符串安全查找三剑客:strchr_s、strrchr_s、strstr_s解析
在 C 语言开发中,字符串操作是安全漏洞的 “重灾区”—— 传统函数(如
strchr、strrchr、strstr)缺乏边界检查,若输入字符串未正确以\0结尾,极易触发缓冲区溢出,导致程序崩溃或被恶意利用(如注入攻击)。为解决这一问题,C11 标准(ISO/IEC 9899:2011) 引入 “边界检查接口”(Bounds-checking interfaces),其中
strchr_s、strrchr_s、strstr_s便是传统查找函数的安全增强版本。它们通过增加长度参数、明确错误处理,从根源上降低安全风险,成为安全关键型应用(如嵌入式系统、金融软件)的首选工具。
目录
一、安全字符串函数概述
二、strchr_s:安全的正向字符查找
三、strrchr_s:安全的反向字符查找
四、strstr_s:安全的子串查找
五、安全函数与传统函数的差异对比
六、经典面试题
一、安全字符串函数概述
strchr_s、strrchr_s、strstr_s保留了传统函数的核心查找功能,同时新增以下安全特性:
- 强制传入字符串长度参数,限制操作范围,防止越界访问;
- 通过返回值(错误码)报告异常,而非依赖 “未定义行为”;
- 主动校验无效参数(如空指针、超范围长度);
- 检查字符串是否在指定长度内正确终止(避免处理不完整字符串)。
注:使用这些函数需先定义宏
__STDC_WANT_LIB_EXT1__(通常在包含<string.h>前),以启用 C11 标准的安全接口。
二、strchr_s:安全的正向字符查找
1. 函数简介
strchr_s用于在字符串中从左到右查找第一个匹配字符,核心优势是通过 “长度参数 + 错误校验”,确保查找不超出缓冲区边界。
2. 函数原型
errno_t strchr_s(char const* str, rsize_t strsz, int c, char const** result);| 参数名 | 说明 |
|---|---|
str | 待查找的源字符串指针(需以\0结尾,且非空) |
strsz | 源字符串的最大长度(含\0,通常用sizeof(str)获取数组长度) |
c | 目标字符(虽为int类型,实际会被转换为char,兼容EOF) |
result | 输出参数:存储查找结果(成功则指向匹配字符,失败则为NULL) |
返回值:
- 成功(找到 / 未找到字符):返回
0; - 失败(参数无效 / 长度异常):返回非零错误码(如
EINVAL、ESPACE)。
错误码含义:
EINVAL:str或result为NULL(无效指针);ESPACE:strsz为0、超过RSIZE_MAX(通常为SIZE_MAX/2),或字符串未在strsz内终止。
3. 实现逻辑(伪代码)
function strchr_s(str: const char*, strsz: rsize_t, c: int, result: const char**) -> errno_t:// 1. 校验无效指针if str == NULL or result == NULL:return EINVAL// 2. 校验长度合法性if strsz == 0 or strsz > RSIZE_MAX:*result = NULLreturn ESPACE// 3. 转换目标字符(int→char)c_char = (char)c// 4. 正向遍历查找for i from 0 to strsz - 1:if str[i] == c_char:*result = &str[i] // 找到匹配,记录位置return 0if str[i] == '\0':break // 已达字符串实际结尾,停止遍历// 5. 未找到字符(非错误,返回0)*result = NULLreturn 04. 工作流程示意图
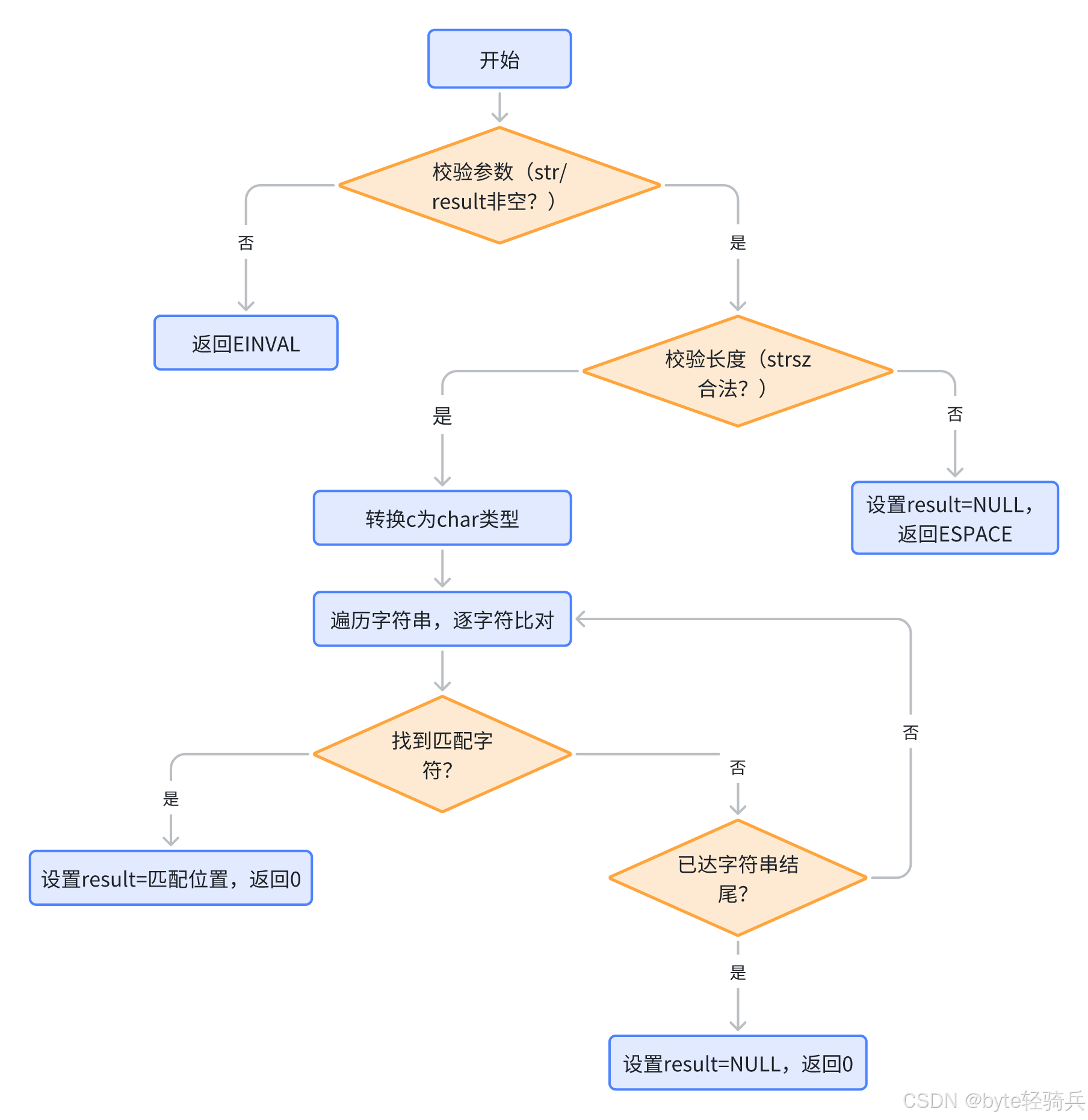
5. 使用场景
strchr_s适用于所有需查找单个字符的场景,尤其适合:
- 处理不可信输入(如用户输入的邮箱、配置项);
- 验证字符串格式(如检查邮箱是否含
@、路径是否含分隔符); - 分割字符串(如按
:分割键值对"name:zhangsan")。
6. 示例代码
#define __STDC_WANT_LIB_EXT1__ 1 // 启用C11安全函数
#include <stdio.h>
#include <string.h>
#include <errno.h>int main() {// 场景1:验证邮箱格式(查找@)char email[] = "user@example.com";const char* result;errno_t err; // 存储错误码// 调用strchr_s查找@err = strchr_s(email, sizeof(email), '@', &result);// 错误处理if (err != 0) {printf("查找失败!错误码:%d\n", err);return 1;}// 结果处理if (result != NULL) {printf("找到'@',位置(索引):%td\n", result - email);printf("邮箱用户名:%.*s\n", (int)(result - email), email); // 截取用户名printf("邮箱域名:%s\n", result + 1); // 截取域名} else {printf("未找到'@',邮箱格式非法!\n");}// 场景2:查找超出字符串长度的字符(边界测试)char buffer[10] = "test"; // 缓冲区大小10,实际字符串长度4(含\0)err = strchr_s(buffer, 10, 'x', &result);if (err == 0 && result == NULL) {printf("\n在buffer中未找到'x'(边界检查生效)\n");}return 0;
}运行结果:
找到'@',位置(索引):4
邮箱用户名:user
邮箱域名:example.com
在buffer中未找到'x'(边界检查生效)
7 注意事项
- 长度参数必须含
\0:strsz需包含字符串的终止符\0,如char str[] = "abc"的strsz应为4(而非3); - 错误码优先校验:不能仅通过
result是否为NULL判断成功 —— 需先检查err是否为0(如err=EINVAL时result也为NULL); c的类型转换:c为int是为兼容EOF(值为-1),函数内部会转为char,无需手动处理;- 查找
\0的特殊情况:若c='\0',函数会返回指向字符串末尾\0的指针(符合 C11 标准)。
三、strrchr_s:安全的反向字符查找
1. 函数简介
strrchr_s是strchr_s的反向版本,用于从字符串末尾(右→左)查找最后一个匹配字符。同样通过边界检查,避免越界访问,核心场景是 “提取最右侧字符相关内容”(如文件名、后缀)。
2. 函数原型
errno_t strrchr_s(char const* str, rsize_t strsz, int c, char const** result);参数、返回值、错误码与strchr_s完全一致,仅查找方向不同。
3. 实现逻辑(伪代码)
function strrchr_s(str: const char*, strsz: rsize_t, c: int, result: const char**) -> errno_t:// 1. 校验无效指针if str == NULL or result == NULL:return EINVAL// 2. 校验长度合法性if strsz == 0 or strsz > RSIZE_MAX:*result = NULLreturn ESPACE// 3. 转换目标字符c_char = (char)c// 4. 第一步:定位字符串实际结尾(找到\0)str_end = NULLfor i from 0 to strsz - 1:if str[i] == '\0':str_end = &str[i]breakif str_end == NULL: // 字符串未在strsz内终止*result = NULLreturn ESPACE// 5. 第二步:从结尾反向查找current = str_end - 1 // 从\0的前一个字符开始while current >= str:if *current == c_char:*result = currentreturn 0current = current - 1// 6. 特殊情况:查找\0if c_char == '\0':*result = str_endreturn 0// 7. 未找到字符*result = NULLreturn 04. 工作流程示意图
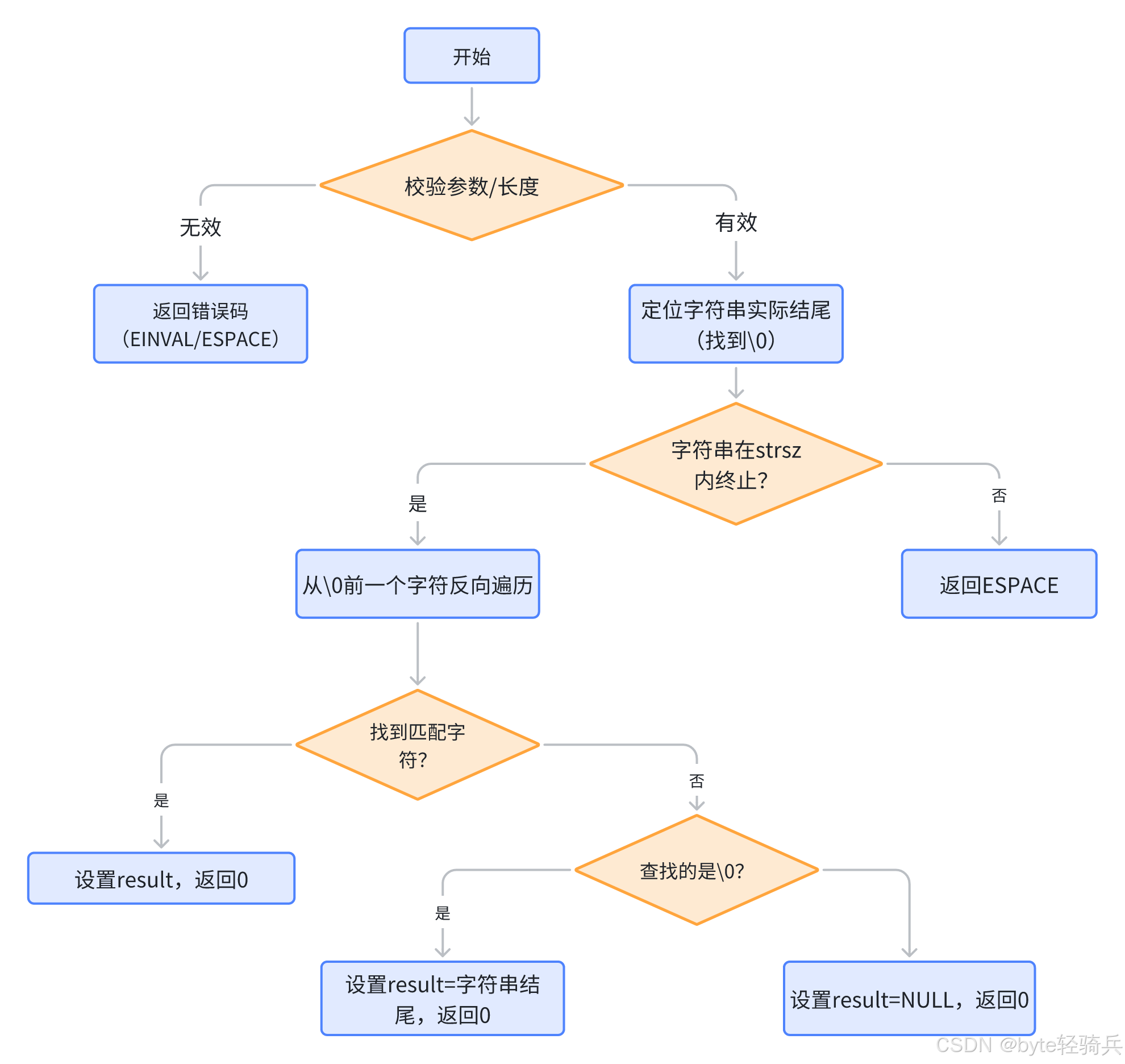
5. 使用场景
strrchr_s的核心场景是 “提取最右侧字符后的内容”,典型案例:
- 从文件路径中提取文件名(如
"/home/user/test.c"→"test.c",查找最后一个/); - 获取文件后缀(如
"image.png"→".png",查找最后一个.); - 分割带重复分隔符的字符串(如
"a,b,c,d"→"d",查找最后一个,)。
6. 示例代码(提取文件名与后缀)
#define __STDC_WANT_LIB_EXT1__ 1
#include <stdio.h>
#include <string.h>
#include <errno.h>// 安全提取文件名(支持/和\路径分隔符)
const char* get_filename_s(const char* path, rsize_t path_len) {const char* result;errno_t err;// 第一步:查找最后一个/err = strrchr_s(path, path_len, '/', &result);if (err != 0) return NULL; // 参数错误,返回空if (result != NULL) {return result + 1; // 跳过/,返回文件名起始位置}// 第二步:若未找到/,查找最后一个\(Windows路径)err = strrchr_s(path, path_len, '\\', &result);if (err != 0) return NULL;return (result != NULL) ? (result + 1) : path; // 无分隔符则返回原路径
}int main() {// 测试不同路径格式char path1[] = "/home/user/documents/report.pdf"; // Linux路径char path2[] = "C:\\Users\\user\\photos\\vacation.jpg"; // Windows路径char path3[] = "readme.txt"; // 无路径(仅文件名)// 提取文件名const char* filename1 = get_filename_s(path1, sizeof(path1));const char* filename2 = get_filename_s(path2, sizeof(path2));const char* filename3 = get_filename_s(path3, sizeof(path3));printf("路径1的文件名:%s\n", filename1);printf("路径2的文件名:%s\n", filename2);printf("路径3的文件名:%s\n", filename3);// 提取文件后缀(查找最后一个.)const char* ext;errno_t err = strrchr_s(filename1, strlen(filename1) + 1, '.', &ext);if (err == 0 && ext != NULL) {printf("\n文件1的后缀:%s\n", ext);}return 0;
}运行结果:
路径1的文件名:report.pdf
路径2的文件名:vacation.jpg
路径3的文件名:readme.txt文件1的后缀:.pdf7 注意事项
- 路径以分隔符结尾的处理:若路径为
"/home/user/docs/"(末尾为/),result会指向该/,此时result+1为\0(空字符串),需额外判断; - 性能对比:
strrchr_s需先遍历到字符串结尾,再反向查找,效率略低于strchr_s,但安全性无差异; - 与
strchr_s的共性问题:同样需注意长度参数含\0、错误码优先校验、c的类型转换。
四、strstr_s:安全的子串查找
1. 函数简介
strstr_s用于在主串(haystack)中查找子串(needle)的首次出现位置,是strstr的安全版本。它通过同时校验主串和子串的长度,防止 “子串越界” 或 “主串未终止” 导致的安全问题,核心场景是 “多字符匹配”(如关键词搜索、协议解析)。
2. 函数原型
errno_t strstr_s(char const* haystack, rsize_t haystacksz, char const* needle, rsize_t needlesz, char const** result);| 参数名 | 说明 |
|---|---|
haystack | 主串(待查找的字符串,需以\0结尾) |
haystacksz | 主串的最大长度(含\0) |
needle | 子串(目标查找内容,需以\0结尾) |
needlesz | 子串的最大长度(含\0) |
result | 输出参数:成功则指向主串中子串的起始位置,失败则为NULL |
返回值与错误码:
- 成功(找到 / 未找到子串):返回
0;- 失败:返回非零错误码(
EINVAL/ESPACE/EILSEQ)。
新增错误码EILSEQ:子串长度(实际长度)大于主串长度,不可能匹配。
3. 实现逻辑(伪代码:朴素算法)
strstr_s的核心是 “主串遍历 + 子串逐字符比对”,以下为易理解的朴素实现(标准库通常用 KMP/BM 算法优化,时间复杂度从O(n*m)降至O(n+m)):
function strstr_s(haystack: const char*, haystacksz: rsize_t,needle: const char*, needlesz: rsize_t,result: const char**) -> errno_t:// 1. 校验无效指针if haystack == NULL or needle == NULL or result == NULL:return EINVAL// 2. 校验长度合法性if haystacksz == 0 or haystacksz > RSIZE_MAX orneedlesz == 0 or needlesz > RSIZE_MAX:*result = NULLreturn ESPACE// 3. 计算主串/子串的实际长度(不含\0)haystack_len = 0while haystack_len < haystacksz and haystack[haystack_len] != '\0':haystack_len += 1if haystack_len == haystacksz and haystack[haystack_len-1] != '\0':*result = NULLreturn ESPACE // 主串未终止needle_len = 0while needle_len < needlesz and needle[needle_len] != '\0':needle_len += 1if needle_len == needlesz and needle[needle_len-1] != '\0':*result = NULLreturn ESPACE // 子串未终止// 4. 特殊情况:子串为空(返回主串起始位置)if needle_len == 0:*result = haystackreturn 0// 5. 子串长于主串(直接返回未找到)if needle_len > haystack_len:*result = NULLreturn 0// 6. 朴素查找:主串遍历+子串比对max_pos = haystack_len - needle_len // 主串遍历的最大位置for i from 0 to max_pos:match = true// 逐字符比对子串for j from 0 to needle_len - 1:if haystack[i+j] != needle[j]:match = falsebreakif match:*result = &haystack[i]return 0// 7. 未找到子串*result = NULLreturn 04. 工作流程示意图
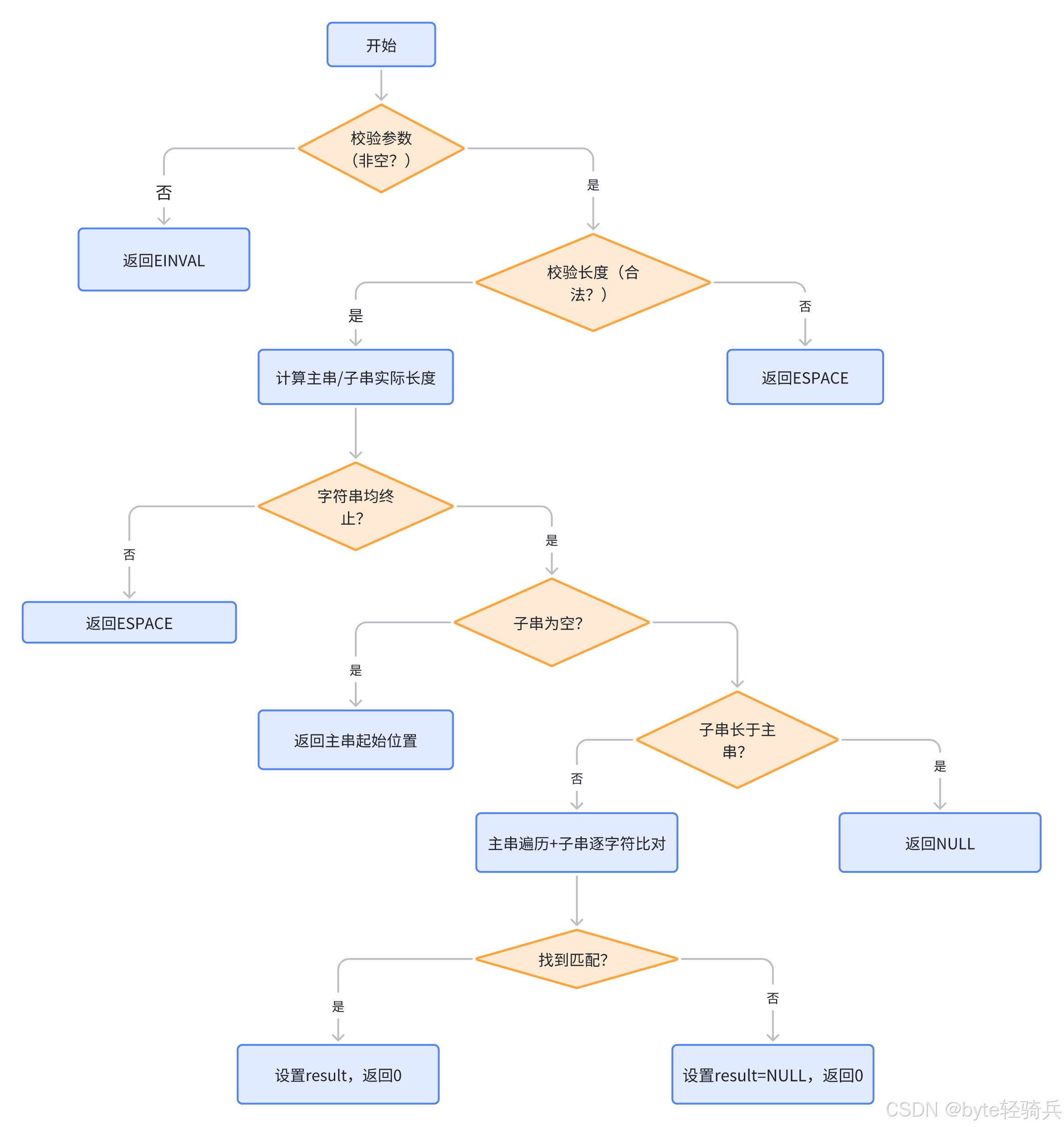
5. 使用场景
strstr_s是多字符匹配的核心工具,典型场景:
- 文本关键词搜索(如日志中查找 “error”“warning”);
- 协议解析(如从
"HTTP/1.1 200 OK"中提取 “200” 状态码); - URL 处理(如从
"https://github.com"中提取"github.com"); - 敏感词过滤(如用户输入中检测违规词汇)。
6. 示例代码(敏感词检测与 URL 解析)
#define __STDC_WANT_LIB_EXT1__ 1
#include <stdio.h>
#include <string.h>
#include <errno.h>// 安全检测文本是否含敏感词
int check_sensitive_word(const char* text, rsize_t text_len,const char* word, rsize_t word_len) {const char* result;errno_t err = strstr_s(text, text_len, word, word_len, &result);if (err != 0) {printf("检测失败!错误码:%d\n", err);return -1; // 错误标识}return (result != NULL) ? 1 : 0; // 1=含敏感词,0=不含
}// 安全提取URL域名(支持http/https)
const char* get_url_domain(const char* url, rsize_t url_len) {const char* result;errno_t err;// 先查找"https://"(长度8)err = strstr_s(url, url_len, "https://", 9, &result); // 9=8+1(含\0)if (err == 0 && result != NULL) {return result + 8;}// 再查找"http://"(长度7)err = strstr_s(url, url_len, "http://", 8, &result); // 8=7+1if (err == 0 && result != NULL) {return result + 7;}return url; // 非HTTP/HTTPS协议,返回原URL
}int main() {// 场景1:敏感词检测char log[] = "2024-06-01: user input contains 'badword'";char sensitive[] = "badword";int has_sensitive = check_sensitive_word(log, sizeof(log), sensitive, sizeof(sensitive));if (has_sensitive == 1) {printf("日志含敏感词:%s\n", sensitive);} else if (has_sensitive == 0) {printf("日志无敏感词\n");}// 场景2:URL域名提取char url1[] = "https://github.com";char url2[] = "http://www.baidu.com";char url3[] = "ftp://ftp.example.com"; // 非HTTP协议const char* domain1 = get_url_domain(url1, sizeof(url1));const char* domain2 = get_url_domain(url2, sizeof(url2));const char* domain3 = get_url_domain(url3, sizeof(url3));printf("\nURL1域名:%s\n", domain1);printf("URL2域名:%s\n", domain2);printf("URL3域名:%s\n", domain3);return 0;
}运行结果:
日志含敏感词:badwordURL1域名:github.com
URL2域名:www.baidu.com
URL3域名:ftp://ftp.example.com7. 注意事项
- 双长度参数需同步校验:
haystacksz和needlesz均需包含各自的\0,如子串"abc"的needlesz应为4; - 子串为空的特殊处理:根据 C11 标准,若
needle为空(""),result会返回主串起始位置(而非NULL); - 大小写敏感:
strstr_s区分大小写(如"ABC"≠"abc"),如需不敏感匹配,需先将主串 / 子串统一转为大写 / 小写; - 性能优化:朴素算法在 “主串 / 子串均为 AAAAA...B” 时效率低,实际开发中可优先使用标准库实现(如 GCC 的
strstr_s用 KMP 优化)。
五、安全函数与传统函数的差异对比
为清晰区分strchr_s/strrchr_s/strstr_s与传统函数,下表从核心特性维度对比:
| 对比维度 | strchr(传统) | strchr_s(安全) | strstr(传统) | strstr_s(安全) |
|---|---|---|---|---|
| 函数原型 | char* strchr(const char*, int) | errno_t strchr_s(..., rsize_t, ..., **) | char* strstr(const char*, const char*) | errno_t strstr_s(..., rsize_t, ..., rsize_t, **) |
| 返回值含义 | 直接返回查找结果(指针 / NULL) | 返回错误码(0 = 成功),结果通过输出参数获取 | 直接返回查找结果(指针 / NULL) | 返回错误码(0 = 成功),结果通过输出参数获取 |
| 长度参数 | 无(依赖\0终止) | 有(strsz,强制边界检查) | 无(依赖\0终止) | 有(haystacksz+needlesz) |
| 错误处理 | 未定义(如空指针会崩溃) | 明确错误码(EINVAL/ESPACE) | 未定义(如子串未终止会越界) | 明确错误码(EINVAL/ESPACE/EILSEQ) |
| 空指针处理 | 程序崩溃或不可预测行为 | 返回 EINVAL,result=NULL | 程序崩溃或不可预测行为 | 返回 EINVAL,result=NULL |
| 未终止字符串处理 | 越界访问(缓冲区溢出风险) | 返回 ESPACE,拒绝处理 | 越界访问(缓冲区溢出风险) | 返回 ESPACE,拒绝处理 |
| 适用场景 | 信任输入的简单场景 | 不可信输入、安全关键场景 | 信任输入的简单场景 | 不可信输入、安全关键场景 |
| 标准依赖 | C89 及以后(所有编译器支持) | C11 及以后(需定义__STDC_WANT_LIB_EXT1__) | C89 及以后(所有编译器支持) | C11 及以后(需定义__STDC_WANT_LIB_EXT1__) |
六、经典面试题
问:
strchr_s在什么情况下会返回EINVAL错误?请列举至少三种情况。
答:
-
当
str参数为NULL但strsz不为 0 时 -
当
result输出参数为NULL指针时 -
当
strsz参数为 0 但str不为NULL时(部分实现) -
当任何参数不满足前置条件,如指针对齐问题等
问:在处理网络数据包时,为什么
strstr_s比strstr更安全?请从攻击者角度分析。
答: 攻击者可以构造特殊数据包:
-
发送不含
\0终止符的长字符串,导致strstr越界读取 -
精心设计偏移使查找操作跨越缓冲区边界
-
利用越界读取获取敏感信息或导致程序崩溃
strstr_s通过 destsz和 srcsz双重限制,确保搜索在预定边界内进行,即使面对恶意数据也能安全处理。
问:如果项目需要同时支持 Windows 和 Linux,如何实现安全字符串函数的跨平台兼容?
答: 推荐三种方案:
-
特性检测宏:使用
#ifdef __STDC_LIB_EXT1__检测编译器支持 -
适配层封装:实现统一接口,底层调用平台相关实现
-
第三方库:引入
safeclib等跨平台兼容库
最佳实践是创建项目内的安全字符串包装层,集中处理平台差异,为业务代码提供统一接口。
问:将传统函数
strchr的调用代码迁移为strchr_s,需注意哪些关键步骤?请举例说明。
答:迁移需围绕 “参数适配”“错误处理”“结果获取” 三个核心步骤,具体如下:
步骤 1:启用 C11 安全函数
在包含<string.h>前定义宏__STDC_WANT_LIB_EXT1__,确保编译器启用安全接口:
#define __STDC_WANT_LIB_EXT1__ 1
#include <string.h>步骤 2:调整函数参数(新增长度参数与输出参数)
- 传统
strchr调用:char* pos = strchr(str, 'a'); - 安全
strchr_s需新增:① 长度参数(strsz);② 输出参数(result指针)。
步骤 3:新增错误处理逻辑
传统函数不返回错误码,迁移后需先校验err是否为0,再处理result(避免将 “参数错误” 与 “未找到” 混淆)。
步骤 4:调整结果获取方式
strchr_s的结果通过输出参数result获取,而非直接返回。
迁移示例(从strchr到strchr_s):
传统代码:
#include <stdio.h>
#include <string.h>int main() {char str[] = "name:zhangsan";// 传统调用:直接返回结果char* pos = strchr(str, ':');if (pos != NULL) {printf("找到':',后续内容:%s\n", pos + 1);} else {printf("未找到':'\n");}return 0;
}迁移后代码:
#define __STDC_WANT_LIB_EXT1__ 1 // 步骤1:启用安全函数
#include <stdio.h>
#include <string.h>
#include <errno.h> // 步骤1:包含错误码头文件int main() {char str[] = "name:zhangsan";const char* result; // 步骤2:新增输出参数errno_t err; // 步骤2:新增错误码变量// 步骤2:调用strchr_s,新增长度参数sizeof(str)err = strchr_s(str, sizeof(str), ':', &result);// 步骤3:优先处理错误if (err != 0) {printf("查找错误!错误码:%d\n", err);return 1;}// 步骤4:通过result获取结果if (result != NULL) {printf("找到':',后续内容:%s\n", result + 1);} else {printf("未找到':'\n");}return 0;
}关键注意点:
- 长度参数必须包含
\0(如sizeof(str)而非strlen(str)); - 错误码
err的校验优先级高于result(如err=EINVAL时result也为NULL,但属于参数错误,需单独处理)。
strchr_s、strrchr_s、strstr_s是 C11 标准为解决传统字符串函数安全问题而设计的核心工具,它们通过 “强制长度参数 + 明确错误处理”,从根源上规避了缓冲区溢出等风险。
开发实践中,需根据场景选择函数:
- 简单信任输入场景:传统函数(
strchr等)更简洁; - 不可信输入(如用户输入、网络数据)或安全关键模块:必须使用安全函数(
strchr_s等)。
掌握安全函数的使用与迁移方法,不仅能提升代码健壮性,更是 C 语言开发者应对安全面试的核心考点。