借助SFTTrainer进行微调 (109)
借助SFTTrainer进行微调
内容预告
在本节中,我们将:
- 理解为何在训练过程中往往难以避免内存不足(out-of-memory)错误的发生
- 探究一系列配置设置,这些设置可帮助你最大限度利用GPU内存(RAM)
- 使用trl库中的SFTTrainer类对模型进行微调
- 探讨内存高效型注意力机制实现方案(如Flash Attention 2和PyTorch的SDPA)的优势
Jupyter笔记本
与第5节对应的Jupyter笔记本[21]是GitHub上官方“大型语言模型微调”(Fine-Tuning LLMs)代码仓库的一部分。你也可以在Google Colab[22]中直接运行该笔记本。
https://colab.research.google.com/github/dvgodoy/FineTuningLLMs/blob/main/Chapter5.ipynb
导入(Imports)
为保证代码结构清晰,某一节所用代码中需要的所有库,都会在该节代码的最开头进行导入。本节需导入以下库:
import numpy as np
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from datasets import load_dataset, Dataset
from peft import get_peft_model, prepare_model_for_kbit_training, LoraConfig, \
AutoPeftModelForCausalLM
from transformers import Trainer, TrainingArguments, AutoTokenizer, AutoModelForCausalLM,\
BitsAndBytesConfig
from trl import SFTTrainer, SFTConfig, setup_chat_format, DataCollatorForCompletionOnlyLM
目标
我们会突破所有限制,将基础模型、适配器(adapters)、优化器以及一个迷你批次(mini-batch)数据全部装入GPU内存(RAM),同时预留出足够空间,以容纳计算出的激活值(activations)和梯度(gradients)。为实现这一目标,我们采用“以计算换内存”的方式(梯度检查点技术,gradient checkpointing)、延迟参数更新(梯度累积,gradient accumulation),并使用内存高效型的注意力机制实现方案(闪电注意力,Flash Attention,或PyTorch的缩放点积注意力,SDPA),最终确保系统正常运行。
前置要求
为更好地理解我们即将采取的“操作技巧”——即将大型语言模型(LLMs)装入消费级GPU进行训练,我们需要重新回顾基础训练循环(training loop)的相关知识,包括前向传播(forward pass)、反向传播(backward pass)以及优化器(optimizer)的作用。作为从业者,你可能已熟悉这些概念,但本节内容将作为实用复习,帮助你巩固要点。
我们将围绕训练循环中的关键步骤展开讨论:
- 在前向传播过程中计算激活值
- 在反向传播过程中计算梯度
- 让优化器利用这些梯度更新模型参数(即模型权重,weights)
每当我们将一个迷你批次数据输入模型时,都会触发一系列连锁过程,我们称之为“前向传播”。在前向传播中,每一层的输出会成为下一层的输入。这些中间输出被称为“激活值”,它们承载着反向传播所需的关键信息。
中间输出的数量由迷你批次大小(mini-batch size)和序列长度(sequence length)共同决定。迷你批次中每个序列的每个标记(token)都会生成各自的激活值。尽管这些激活值的生命周期较短,但它们会占用大量GPU内存,必须予以重点考虑。
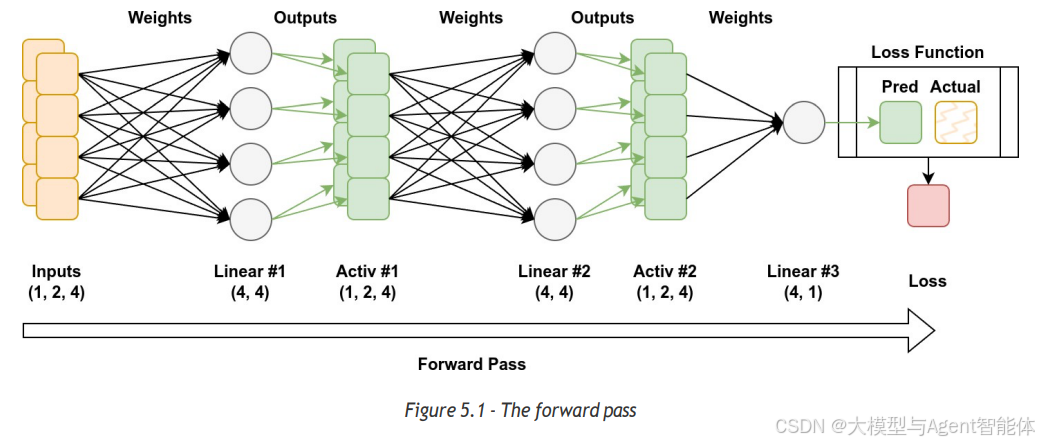
当模型的前向传播(forward pass)执行到最后一层时,其最终输出是我们熟知的结果——模型的预测值(predictions)。至此,前向传播过程结束。我们会将这些预测值与实际目标值(actual target values)进行对比,以计算损失值(loss)。损失值能够反映出预测值的误差大小或偏离程度。
反向传播(backward pass)以损失值为起点,从模型的最后一层逐层向前传播,直至第一层。在每一层中,反向传播会计算梯度(gradients),而梯度则用于表示权重(weights)的变化对模型输出的影响程度。
需要注意的是,计算梯度时,我们必须用到前向传播过程中生成的激活值(activations)。而且,这些梯度会与激活值一同存储在GPU内存(RAM)中。
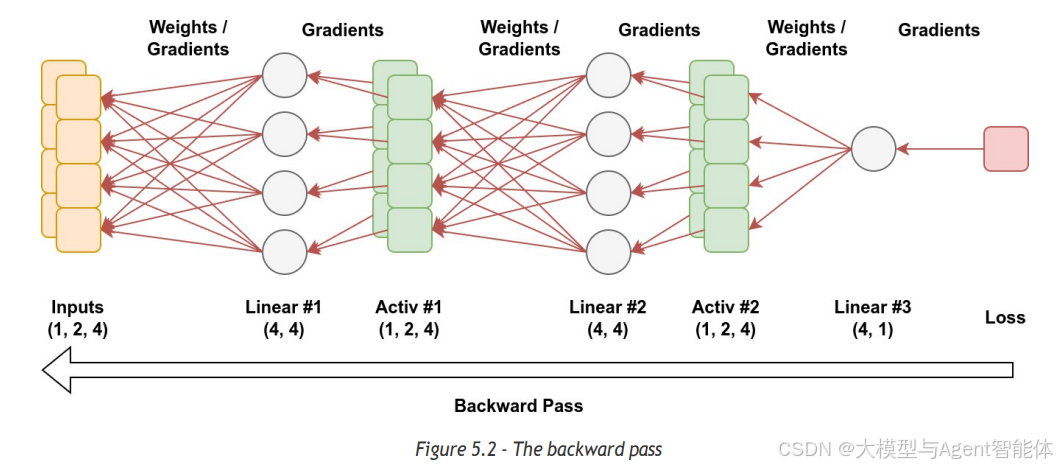
一旦梯度计算完成,我们就可以丢弃激活值(从而释放部分内存),但此时训练流程仍未结束。接下来轮到优化器(optimizer)登场:优化器会利用梯度,并结合学习率(learning rate)进行缩放,以此更新模型的权重(weights)。目前广泛使用的 Adam 优化器会对这一过程进行优化 —— 它为每个权重维护两个滑动统计量(running statistics)来平滑梯度,进而提升训练稳定性。不过,这需要额外的内存来存储这些统计量,有时还需要存储一份权重副本。
当优化器完成权重更新后,会将对应权重的梯度重置为零,随后我们回到训练循环的第一步,开始下一轮迭代。
总而言之,训练循环(training loop)包含三个核心步骤:前向传播(计算激活值与预测值)、反向传播(利用激活值计算梯度),以及优化器步骤(更新权重)。在硬件资源有限的情况下处理大型模型时,高效的内存管理至关重要。
《大型语言模型微调》前情回顾
在“精简总结(TL;DR)”章节中,我们创建了配置类(SFTConfig)和训练器类(SFTTrainer)的实例。我们将最大序列长度设置为较小值(但仍符合我们的使用场景需求),并同时采用了梯度累积(gradient accumulation)和梯度检查点(gradient checkpointing)技术,以在训练过程中最大限度利用GPU内存(RAM)。这些设置能在训练循环(training loop)的关键阶段显著降低内存需求。
听起来很不错,对吧?但这些设置具体是如何发挥作用的呢?
训练流程简概
训练一个模型需要经历以下几个基础阶段:
- 阶段0:加载模型(Load the model)。
- 阶段1:加载一个迷你批次(mini-batch)的数据,执行前向传播(forward pass)以生成预测结果。
- 阶段2:计算梯度(通过反向传播,即PyTorch中的backward()方法)。
- 阶段3:使用优化器(通常是Adam或其变体)更新模型参数。
- 阶段4:将梯度重置为零。
- 阶段5:重复上述流程(返回至阶段1)。
训练过程中,随着每个阶段的推进,内存需求会逐渐增加;但阶段4和阶段5不需要额外的内存。
术语说明:
- TL;DR:全称为“Too Long; Didn’t Read”,中文常译为“精简总结”“核心要点”,是内容摘要的常用标识,此处保留原缩写并补充中文释义,符合技术文档表述习惯。
- SFTConfig/SFTTrainer:均为trl(Transformer Reinforcement Learning)库中的核心类,分别对应“监督微调配置”“监督微调训练器”,保留类名不译,符合AI领域代码与文档的表述规范。
- Mini-batch:译为“迷你批次”,指训练时将数据集分割成的小批量数据块,是深度学习中平衡训练效率与内存消耗的关键策略,简称“批次”,此处完整译出便于理解。
- Adam:一种常用的自适应学习率优化器,全称为“Adaptive Moment Estimation”,通常保留英文原名“Adam”并补充“优化器”以明确属性,是行业通用译法。
- Forward pass/Backward pass:深度学习领域核心流程术语,分别译为“前向传播”“反向传播”,前者指数据从输入层到输出层的计算过程,后者指基于损失值反向计算梯度以更新参数的过程,为行业通用译法。
- Loss:译为“损失值”,是衡量模型预测结果与真实结果差异的指标,简称“损失”,此处补充“值”字以明确其数值属性,便于理解。
- Gradients:译为“梯度”,在模型训练中代表参数变化对损失值的影响方向和程度,是优化器更新权重的核心依据,为数学与AI领域标准术语。
-
Adapters:模型适配器,是微调中用于适配基础模型与特定任务的轻量级组件,通常无需修改基础模型权重,此处保留英文术语“adapters”并补充中文释义,符合AI领域表述习惯。
-
Mini-batch:迷你批次,指训练时将数据集分割成的小批量数据块,是深度学习中常用的训练数据处理方式,中文简称“批次”,此处完整译出并保留英文原词便于对照。
-
Gradient Checkpointing:梯度检查点技术,通过牺牲少量计算量,减少激活值的存储量,从而节省GPU内存,是大模型训练中常用的内存优化手段。
-
SDPA:全称为“Scaled Dot-Product Attention”,即“缩放点积注意力”,是PyTorch框架内置的注意力机制实现,此处首次出现时补充全称及中文译法,确保理解准确。
-
SFTTrainer:全称为“Supervised Fine-Tuning Trainer”,即“监督微调训练器”,是trl(Transformer Reinforcement Learning,Transformer强化学习)库中用于实现模型监督微调的核心类,此处保留类名不译,符合技术文档表述习惯。
-
Flash Attention 2:一种高效的注意力计算优化技术,中文常译为“闪电注意力2”,此处保留原名以体现技术专有性,若需补充可标注“(闪电注意力2)”。
-
SDPA:全称为“Scaled Dot-Product Attention”,即“缩放点积注意力”,是PyTorch框架中内置的注意力机制实现,此处先保留缩写,首次出现时可补充全称及中文译法。
-
Jupyter Notebook/Google Colab:均为常用的交互式编程工具,前者常译为“Jupyter笔记本”,后者为Google旗下产品,通常保留原名“Google Colab”。