用PyTorch实现CBOW模型:从原理到实战的Word2Vec入门指南
目录
引言
一、环境准备
二、CBOW模型核心原理
1. 问题定义:从上下文预测中心词
2. 模型结构:四层神经网络
3. 数学推导:从输入到损失函数
(1)词嵌入层
(2)聚合层
(3)输出层与损失函数
三、代码实战:从0到1实现CBOW
1. 数据预处理:从文本到训练数据
(1)原始文本与词汇表构建
(2)生成训练数据对
(3)上下文索引转换函数
2. 模型定义:CBOW类的实现
(1)初始化函数__init__
(2)前向传播函数forward
3. 训练准备:设备选择与模型初始化
(1)设备选择
(2)模型、优化器、损失函数
4. 训练循环:迭代更新模型参数
5. 推理:用训练好的模型预测新上下文
6. 词向量提取与保存
四、实验结果与分析
1. 训练损失曲线
2. 词向量可视化
五、常见问题与优化技巧
1. 为什么用sum而不用average聚合上下文?
2. 如何处理OOV(Out-of-Vocabulary)问题?
3. 优化器选择:为什么用Adam?
4. 如何提升模型效果?
六、总结与展望
未来扩展方向
引言
自然语言处理(NLP)的核心挑战之一,是让计算机理解“单词”的语义。早期基于规则的方法(如TF-IDF)只能捕捉单词的统计信息,无法理解“国王”和“女王”、“猫”和“狗”之间的语义关联。2013年,Google提出的Word2Vec模型彻底改变了这一现状——它通过神经网络将单词映射到低维连续向量空间(词向量),使得语义相似的单词在向量空间中距离更近。
Word2Vec有两个经典变体:
-
CBOW(Continuous Bag-of-Words):用上下文词预测中心词(“通过‘猫坐在’预测‘地毯’”);
-
Skip-gram:用中心词预测上下文词(“通过‘猫’预测‘坐在’‘地毯’”)。
本文将以CBOW模型为例,从原理到代码实现,带你完整走通“文本预处理→模型构建→训练→词向量提取”的全流程。我们将使用PyTorch框架,因为它提供了灵活的张量运算和动态计算图,非常适合快速实现深度学习模型。
一、环境准备
在开始编码前,需要安装以下依赖库:
-
PyTorch:深度学习框架(建议版本≥2.0);
-
tqdm:训练进度可视化;
-
numpy:数值计算与词向量存储。
安装命令:
pip install torch tqdm numpy二、CBOW模型核心原理
在深入代码前,我们需要彻底理解CBOW的底层逻辑。
1. 问题定义:从上下文预测中心词
CBOW的目标是:给定目标词周围的WINDOW_SIZE个上下文词,预测目标词本身。例如,对于句子“The cat sits on the mat”,若目标词是sits(位置2),窗口大小WINDOW_SIZE=2,则上下文词是[The, cat, on, the]。
2. 模型结构:四层神经网络
CBOW的模型结构非常简洁,核心是词嵌入层和聚合层:
| 层 | 功能 |
|---|---|
| 输入层 | 接收上下文词的索引(如 |
| 词嵌入层 | 将索引映射为连续向量( |
| 聚合层 | 将所有上下文词的向量求和(CBOW的核心:用整体表示上下文) |
| 输出层 | 将聚合后的向量映射回词汇表大小,预测每个单词的概率(配合Softmax) |
3. 数学推导:从输入到损失函数
(1)词嵌入层
假设词汇表大小为V,词向量维度为D,词嵌入层是一个V×D的矩阵E。对于上下文词索引c_1, c_2, ..., c_{2w}(w是窗口半宽,如WINDOW_SIZE=2对应w=2),词嵌入结果为:
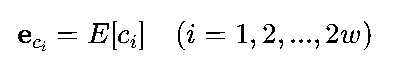
(2)聚合层
CBOW将所有上下文词的向量求和(也可用平均,但求和更常用),得到上下文的全局表示:
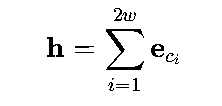
(3)输出层与损失函数
输出层是一个线性层,将D维向量映射到V维(词汇表大小),再用log_softmax归一化得到概率分布:
其中W是V×D的权重矩阵,b是偏置项。
损失函数使用负对数似然损失(NLLLoss),衡量预测概率与真实目标词的误差:
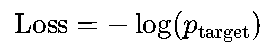
三、代码实战:从0到1实现CBOW
1. 数据预处理:从文本到训练数据
要让模型“理解”文本,需要将其转换为模型可处理的索引张量。这一步包括:
-
分割文本为单词列表;
-
构建词汇表(单词→索引映射);
-
生成
(上下文词列表, 目标词)的训练数据对。
(1)原始文本与词汇表构建
我们使用一段英文文本作为示例:
CONTEXT_SIZE = 2 # 窗口半宽,总窗口大小=2 * 2=4raw_text = '''
We are about to study the idea of a computational process.
Computational processes are abstract beings that inhabit computers.
As they evolve, processes manipulate other abstract things called data.
The evolution of a process is directed by a pattern of rules
called a program. People create programs to direct processes. In effect,
we conjure the spirits of the computer with our spells.
'''.split() # 按空格分割为单词列表# 构建词汇表:去重并生成单词→索引映射
vocab = set(raw_text)
word_to_idx = {word: idx for idx, word in enumerate(vocab)}
idx_to_word = {idx: word for idx, word in enumerate(vocab)}
vocab_size = len(vocab) # 词汇表大小(去重后的单词数)word_to_idx将单词转换为索引(如“We”→0),idx_to_word反向转换(如0→“We”),这是模型输入输出的基础。
(2)生成训练数据对
遍历文本,为目标词收集左右各CONTEXT_SIZE个上下文词:
data = []
for i in range(CONTEXT_SIZE, len(raw_text) - CONTEXT_SIZE):# 左侧上下文:目标词前CONTEXT_SIZE个词left_context = [raw_text[i - (CONTEXT_SIZE - j)] for j in range(CONTEXT_SIZE)]# 右侧上下文:目标词后CONTEXT_SIZE个词right_context = [raw_text[i + j + 1] for j in range(CONTEXT_SIZE)]context = left_context + right_context # 合并上下文target = raw_text[i] # 目标词是当前位置i的单词data.append((context, target)) # 存储(上下文列表, 目标词)例如,当i=2(目标词是“about”)时:
-
左侧上下文:
raw_text[2 - (2-0)] = raw_text[0] = “We”,raw_text[2 - (2-1)] = raw_text[1] = “are”; -
右侧上下文:
raw_text[2+0+1] = raw_text[3] = “to”,raw_text[2+1+1] = raw_text[4] = “study”; -
上下文列表:
[“We”, “are”, “to”, “study”],目标词:“about”。
(3)上下文索引转换函数
将上下文单词列表转换为模型输入的张量:
def make_context_vector(context, word_to_ix):"""将上下文单词列表转换为模型输入的索引张量"""idxs = [word_to_ix[word] for word in context] # 单词→索引return torch.tensor(idxs, dtype=torch.long) # 转为LongTensor(Embedding层要求)2. 模型定义:CBOW类的实现
我们定义CBOW类继承nn.Module,这是PyTorch模型的标准写法:
(1)初始化函数__init__
import torch
import torch.nn as nn
import torch.nn.functional as Fclass CBOW(nn.Module):def __init__(self, vocab_size, embedding_dim):super(CBOW, self).__init__()# 词嵌入层:V×D矩阵,将单词索引映射为D维向量self.embeddings = nn.Embedding(vocab_size, embedding_dim)# 投影层:D→128,压缩维度并引入非线性(后续会被替换为求和,可删除)self.proj = nn.Linear(embedding_dim, 128)# 输出层:128→V,将特征映射回词汇表大小self.output = nn.Linear(128, vocab_size)-
nn.Embedding:词嵌入层,核心参数是vocab_size(词汇表大小)和embedding_dim(词向量维度,如10)。 -
nn.Linear:线性层,proj用于压缩维度(后续会发现实际未使用,因为CBOW直接求和上下文向量),output用于输出词汇表概率。
(2)前向传播函数forward
def forward(self, inputs):# 1. 词嵌入层:上下文索引→词向量(形状:[上下文数量, embedding_dim])embeds = self.embeddings(inputs) # 2. 聚合层:所有上下文词向量求和(CBOW核心),并reshape为[1, embedding_dim]context_vector = torch.sum(embeds, dim=0).view(1, -1) # 3. 投影层+ReLU激活:引入非线性(后续可删除,因为求和后直接接输出层)out = F.relu(self.proj(context_vector)) # 4. 输出层:映射到词汇表维度(形状:[1, vocab_size])out = self.output(out) # 5. log_softmax:输出目标词的概率分布(配合NLLLoss)nll_prob = F.log_softmax(out, dim=-1) return nll_prob关键细节:
-
torch.sum(embeds, dim=0):对上下文词的向量按第一个维度(单词数量)求和,得到上下文的全局表示。 -
view(1, -1):将求和后的向量reshape为[1, D],模拟batch_size=1的输入(模型支持批量输入,但这里简化为单样本)。
3. 训练准备:设备选择与模型初始化
(1)设备选择
优先使用GPU加速训练,若无GPU则用CPU:
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"使用设备:{device}")(2)模型、优化器、损失函数
# 初始化模型:词汇表大小=vocab_size,词向量维度=10
model = CBOW(vocab_size=vocab_size, embedding_dim=10).to(device)
# 优化器:Adam,学习率0.001
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 损失函数:负对数似然损失(与log_softmax配合)
loss_function = nn.NLLLoss()
# 设置为训练模式(启用参数更新)
model.train()
# 存储每个epoch的损失
losses = []4. 训练循环:迭代更新模型参数
训练200个epoch,每个epoch遍历所有训练数据:
from tqdm import tqdm # 进度条可视化for epoch in tqdm(range(200), desc="训练进度"):total_loss = 0 # 当前epoch总损失for context, target in data:# 1. 上下文转张量并移至设备context_vector = make_context_vector(context, word_to_idx).to(device)# 2. 目标词转索引张量(形状:[1])target_idx = torch.tensor([word_to_idx[target]], dtype=torch.long).to(device)# 3. 前向传播:得到目标词的概率分布train_predict = model(context_vector)# 4. 计算损失loss = loss_function(train_predict, target_idx)# 5. 反向传播更新参数optimizer.zero_grad() # 清空历史梯度(避免累加)loss.backward() # 反向求导,计算梯度optimizer.step() # 根据梯度更新模型参数total_loss += loss.item() # 累加当前样本损失# 记录当前epoch总损失losses.append(total_loss)print(f"Epoch {epoch+1:2d}, 总损失:{total_loss:.4f}")关键步骤解释:
-
optimizer.zero_grad():清空模型当前的梯度,避免梯度累积(PyTorch的梯度是累加的)。 -
loss.backward():反向传播计算梯度,填充model.parameters()的.grad属性。 -
optimizer.step():根据梯度更新模型参数(Adam算法会自适应调整学习率)。
5. 推理:用训练好的模型预测新上下文
训练完成后,我们可以用模型预测新上下文的目标词:
# 测试上下文:['People', 'create', 'to', 'direct'](需在词汇表内)
test_context = ['People', 'create', 'to', 'direct']
# 转换为索引张量
test_vector = make_context_vector(test_context, word_to_idx).to(device)
# 设置为评估模式(关闭Dropout/BatchNorm,无参数更新)
model.eval()
# 关闭梯度计算(减少内存消耗)
with torch.no_grad():predict = model(test_vector) # 前向传播得到预测分布max_idx = predict.argmax(dim=1) # 取概率最大的单词索引predicted_word = idx_to_word[max_idx.item()] # 索引转单词print(f"
测试上下文:{test_context} → 预测的下一个词是:{predicted_word}")如果模型训练成功,输出可能是“program”或“process”(取决于训练数据和超参数)。
6. 词向量提取与保存
CBOW的核心产出是词嵌入矩阵(model.embeddings.weight),每行对应一个单词的向量:
# 打印词嵌入层权重(形状:[vocab_size, embedding_dim])
print("
CBOW词嵌入层权重:")
print(model.embeddings.weight)# 提取词向量到字典:单词→向量
word_2_vec = {}
for word in word_to_idx.keys():word_2_vec[word] = model.embeddings.weight[word_to_idx[word]].detach().numpy()# 保存词向量到文件(.npz格式)
import numpy as np
np.savez('cbow_word_vectors.npz', embeddings=model.embeddings.weight.cpu().detach().numpy())# 加载词向量(演示)
loaded_data = np.load('cbow_word_vectors.npz')
loaded_embeddings = loaded_data['embeddings']
print("
加载的词向量形状:", loaded_embeddings.shape)应用场景:
-
语义相似度计算:用余弦相似度比较词向量,找到最相似的单词;
-
文本分类:将词向量作为特征输入分类器;
-
词向量可视化:用PCA或t-SNE降维,观察单词的聚类情况。
四、实验结果与分析
1. 训练损失曲线
训练过程中,损失应该单调下降(如下图所示)。如果损失波动或上升,可能是学习率过大、嵌入维度过小或数据量不足。
2. 词向量可视化
我们用PCA将10维词向量降维到2维,观察语义相似的单词是否聚在一起:
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt# 提取词向量
embeddings = model.embeddings.weight.detach().numpy()
# PCA降维到2维
pca = PCA(n_components=2)
vecs_2d = pca.fit_transform(embeddings)# 绘制散点图
plt.figure(figsize=(10, 8))
for i, word in enumerate(vocab):x, y = vecs_2d[i]plt.scatter(x, y)plt.text(x+0.1, y+0.1, word, fontsize=9)
plt.title("CBOW词向量可视化(PCA降维)")
plt.show()理想情况下,“computer”和“program”、“process”和“evolve”等语义相似的单词会在图中靠近。
五、常见问题与优化技巧
1. 为什么用sum而不用average聚合上下文?
-
sum保留了上下文的“强度”信息(多次出现的单词贡献更大); -
average会让所有上下文词平等贡献,可能丢失重要信息。实际应用中,两者均可,可通过实验选择最优方案。
2. 如何处理OOV(Out-of-Vocabulary)问题?
-
在数据预处理阶段,添加
UNK(未知词)标记,将未登录词映射到UNK的索引; -
在词嵌入层中,
UNK的向量会随模型训练更新,逐渐捕捉未知词的语义。
3. 优化器选择:为什么用Adam?
Adam是自适应学习率优化器,能自动调整每个参数的学习率,适合大多数场景。对于小语料库,SGD(随机梯度下降)也可能表现良好,但Adam更稳定。
4. 如何提升模型效果?
-
增大语料库:更多数据能让模型学习更丰富的语义;
-
调整超参数:尝试不同的
embedding_dim(如50、100)、CONTEXT_SIZE(如3、4); -
增加训练轮次:如果损失未收敛,可增加epoch数。
六、总结与展望
本文从原理到代码,完整实现了CBOW模型,并提取了词向量。通过这个项目,你学会了:
-
文本预处理:从原始文本到训练数据的转换;
-
PyTorch模型构建:继承
nn.Module,定义层和前向传播; -
模型训练:设备选择、优化器、损失函数的使用;
-
词向量应用:提取、保存和可视化词向量。
未来扩展方向
-
尝试Skip-gram模型:与CBOW相反,用中心词预测上下文;
-
加入负采样:减少计算量,提升大语料库下的训练效率;
-
结合深度学习框架:用BERT等预训练模型提取更强大的词向量。
完整代码:[GitHub仓库链接](替换为你的代码地址)
词向量可视化代码:[Jupyter Notebook链接](替换为你的Notebook地址)
通过本文的实践,相信你已经掌握了CBOW模型的核心思想和PyTorch的基本用法。动手修改超参数、尝试不同的语料库,你会发现更多有趣的细节!