【自然语言处理与大模型】RAG发展过程中的三个范式
近年来,随着大语言模型(LLM)在自然语言处理领域的广泛应用,检索增强生成(RAG) 成为解决模型幻觉问题、提升回答准确性和事实一致性的重要技术手段。RAG通过结合外部知识库的检索能力与生成模型的强大表达能力,实现了信息获取与内容生成的深度融合。
RAG系统经历了三个主要发展阶段:
- 初级 RAG(Naive RAG)
- 高级 RAG(Advanced RAG)
- 模块化 RAG(Modular RAG)
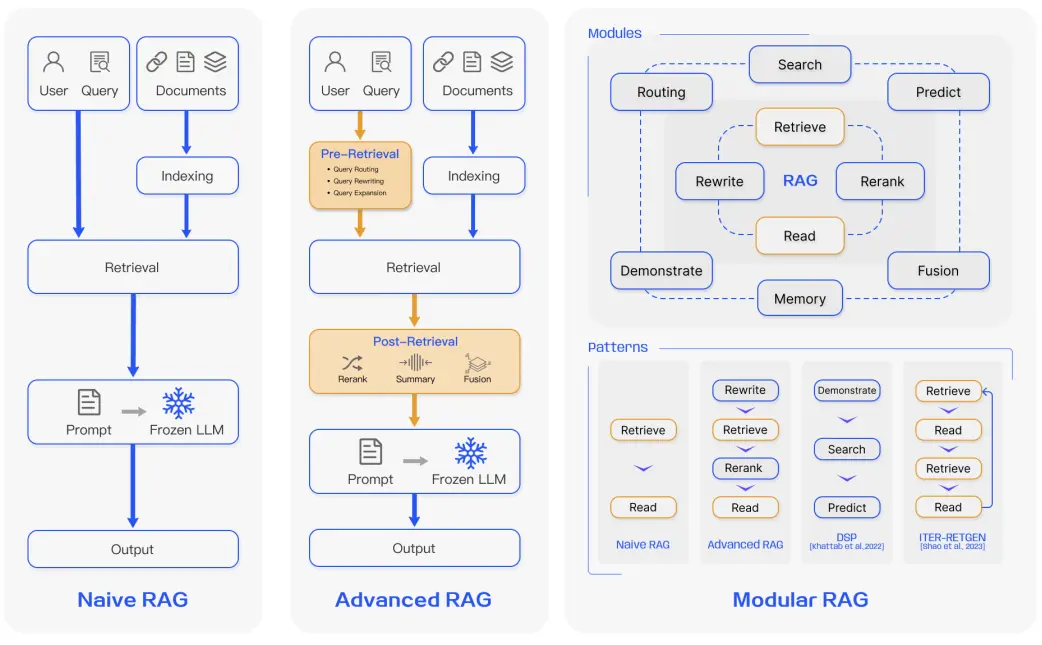
一、Naive RAG
初级 RAG 采用了一个传统过程,包括索引建立、文档检索和内容生成。简单来说,系统根据用户的输入查询相关文档,然后将这些文档和一个提示语结合起来,交给模型生成最终的回答。如果涉及到多轮对话,还可以将对话历史整合到提示语中。初级 RAG 是最基础的实现方式,其工作流程如下:
- 索引:将文档切分为片段并生成嵌入向量,存储于向量数据库中。
- 检索:根据用户查询,在向量空间中查找语义相似的文档片段。
- 增强:将检索结果拼接至提示模板中,形成输入。
- 生成:大语言模型基于提示生成最终答案。
优点:结构简单、易于部署,适用于静态知识问答场景。
| 缺点 | 描述 |
|---|---|
| 低精确度 | 检索返回的内容可能不完全相关,导致生成错误信息。 |
| 低召回率 | 难以覆盖所有相关信息,尤其当查询复杂或多义时。 |
| 信息过时风险 | 若知识库未及时更新,模型可能引用陈旧数据。 |
| 幻觉 | 模型可能基于不完整或无关信息虚构答案。 |
| 冗余与重复 | 多个相似文档被同时检索,造成内容重复。 |
| 风格不一致 | 不同来源的文档风格差异大,影响输出连贯性。 |
二、Advanced RAG
为克服初级 RAG 的缺陷,高级 RAG 引入了一系列端到端优化策略,聚焦于检索前(Pre-retrieval)、检索中(During retrieval)和检索后(Post-retrieval) 的全流程改进。
(1)检索前优化
- Query Routing(查询路由):判断查询类型,选择合适的数据源或子系统。
- Query Rewriting(查询改写):将原始查询转化为更具体、语义更明确的形式。
- Query Expansion(查询扩展):添加同义词、相关概念等,提高召回率。
(2)检索过程优化
- 嵌入模型微调(Fine-tuned Embedding Models):使用领域特定数据训练嵌入模型,提升语义匹配精度。
- 动态嵌入(Dynamic Embeddings):如 OpenAI 的
embeddings-ada-02支持上下文感知的编码。 - 混合检索(Hybrid Search):结合关键词搜索(BM25)与语义搜索(向量检索),兼顾准确性与召回率
(3)检索后优化
- 重排序(Re-ranking):对初步检索结果按相关性重新排序,常用方法包括 Cross-Encoder、ColBERT。
- 摘要融合(Summary & Fusion):
- 使用 LLM 对多个文档进行摘要合并;
- 或采用 Maximal Marginal Relevance (MMR) 实现多样性与相关性的平衡。
- 提示压缩(Prompt Compression):去除冗余文本,避免上下文窗口溢出。
三、Modular RAG
模块化 RAG 是当前 RAG 架构发展的前沿方向,它将整个系统解耦为一系列可插拔、可组合的功能模块,从而实现高度灵活的任务适配。其核心理念是允许开发者根据任务需求自由组合不同功能模块,支持多种执行路径(patterns),满足多样化应用场景,各模块独立开发、测试与迭代。上图中的关键模块分类的解释如下表:
| 模块 | 功能说明 |
|---|---|
| Search | 执行实际的检索操作,支持多种检索算法。 |
| Retrieve | 从数据库中提取候选文档片段。 |
| Rewrite | 改写查询或文档以增强匹配效果。 |
| Rerank | 对检索结果进行再排序。 |
| Read | 解析文档内容,提取关键信息。 |
| Fusion | 合并多个来源的信息,避免重复。 |
| Memory | 存储对话历史或长期记忆,支持多轮交互。 |
| Routing | 判断查询应由哪个子系统处理。 |
| Predict | 基于已有信息预测答案或引导推理路径。 |
| Demonstrate | 提供示例或思维链,辅助模型推理。 |
典型模式(patterns)
| 模式 | 流程 | 应用场景 |
|---|---|---|
| Naive RAG | Retrieve → Read | 简单问答系统 |
| Advanced RAG | Rewrite → Retrieve → Rerank → Read | 高精度知识检索 |
| DSP(Demonstration-based Prompting) | Demonstrate → Search → Predict | 推理类任务 |
| ITER-RETGEN | Retrieve → Read → Retrieve → Read | 复杂问题分步求解 |