DeepSeek-V3.1最终版,DeepSeek-V3.1-Terminus来了!
当一个版本以 “终点”(Terminus,拉丁语意为 “终点”)命名,往往意味着它承载着为某个系列画上完美句号的使命。9 月 22 日,悄然发布的 Terminus 版本,正是 V3.1 系列的 “收官之作”。不同于以往追求激进的功能新增,这次 Terminus 将重心放在了 V3.1 用户痛点修复与核心能力强化上。接下来,我们通过 3 组真实场景对比,一起看看这个新版本究竟 “强在哪、好用在哪”。
一、告别 V3.1 的尴尬时刻
用过 V3.1 的朋友,想必都遭遇过这些糟心情况:分析《红楼梦》时,文中突然冒出 “metaphor” 这样的英文单词,画风瞬间跑偏;调试代码时,满屏乱跳 “极” 字,严重影响生产环境部署。这两大 “槽点”,让不少用户头疼不已。
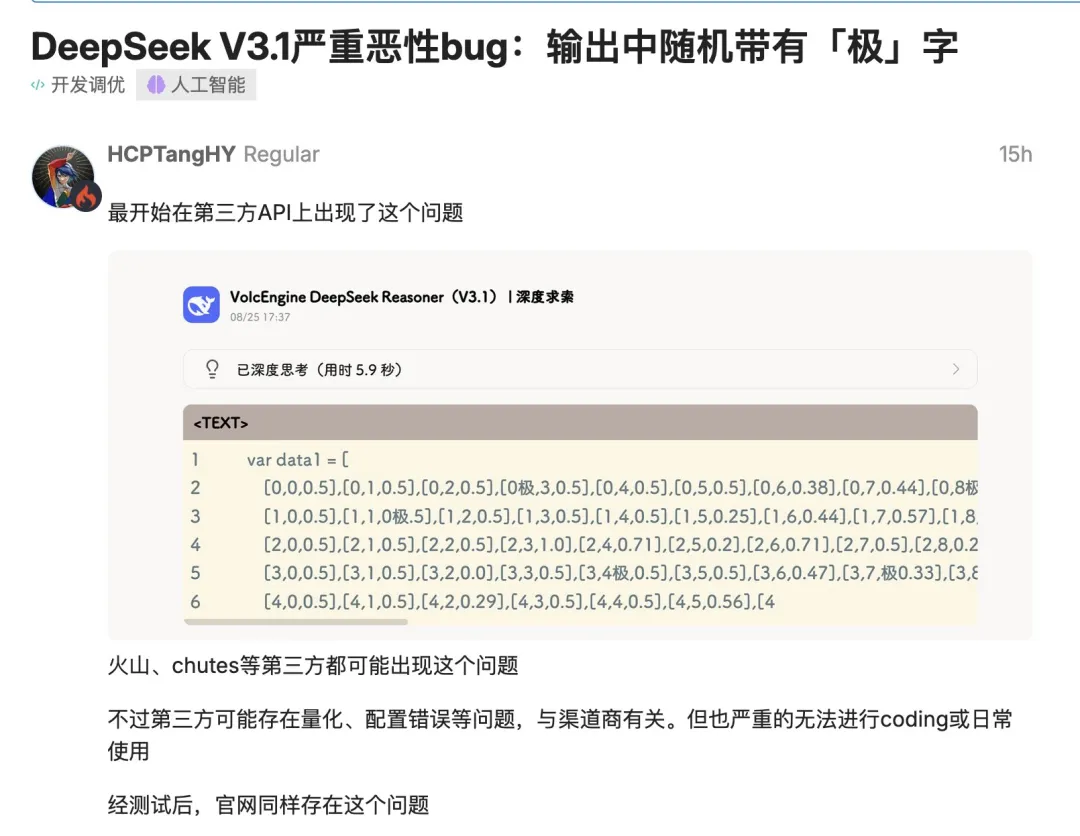
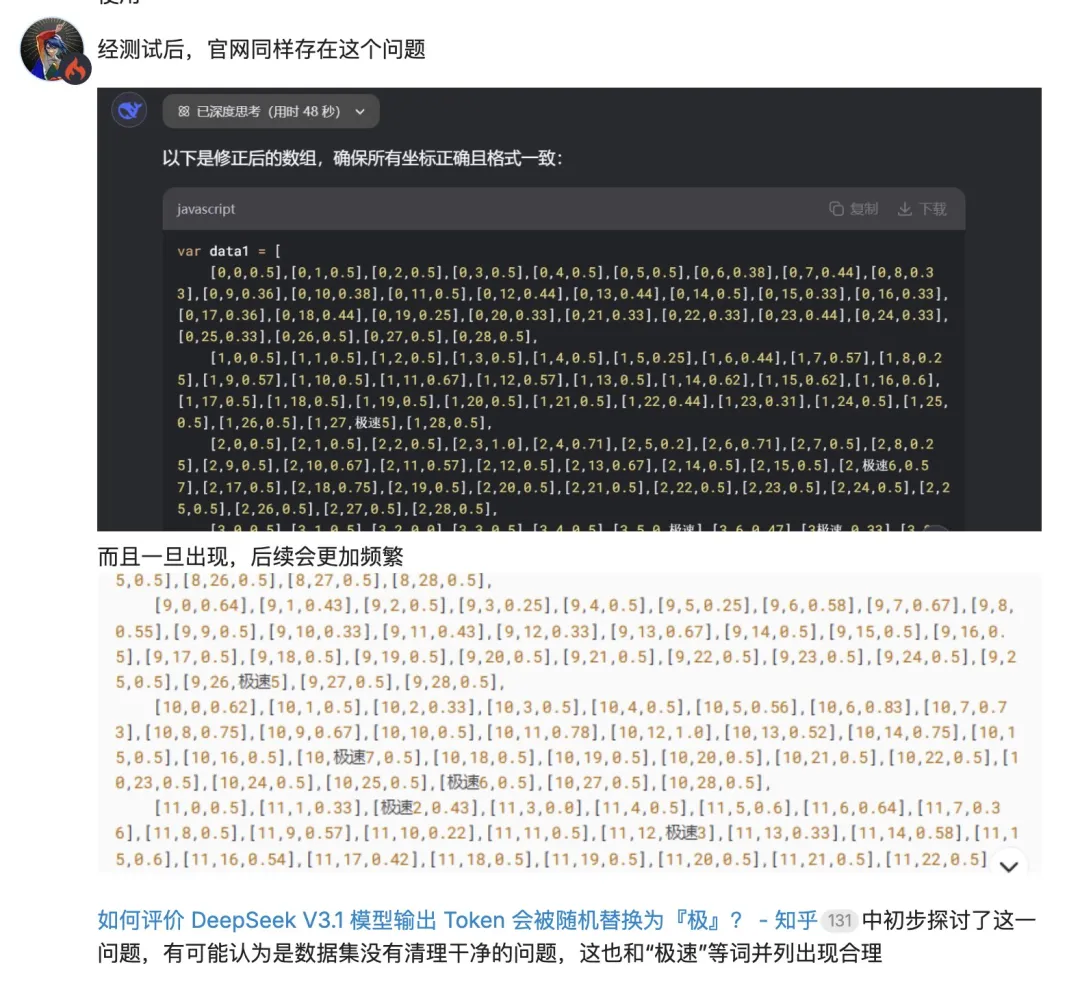
而 Terminus 版本带来了彻底的改变。它通过优化 tokenizer 逻辑、进行动态语言对齐训练,并新增 token 序列校验这一系列技术突破,成功解决了语言一致性问题。数据不会说谎,经过升级后,中英文混杂率从 12.7% 大幅降至 0.8%,异常字符减少 90% 以上。现在,无论是撰写跨境报告,还是进行小语种翻译,都不会再出现让人 “出戏” 的情况,体验感直线上升。
二、Agent 从 “嘴炮” 变 “实干家”
在核心功能方面,Terminus 版本让 Agent 实现了从 “嘴炮” 到 “实干家” 的华丽转身,尤其是 Code Agent 和 Search Agent 的表现,让人眼前一亮。
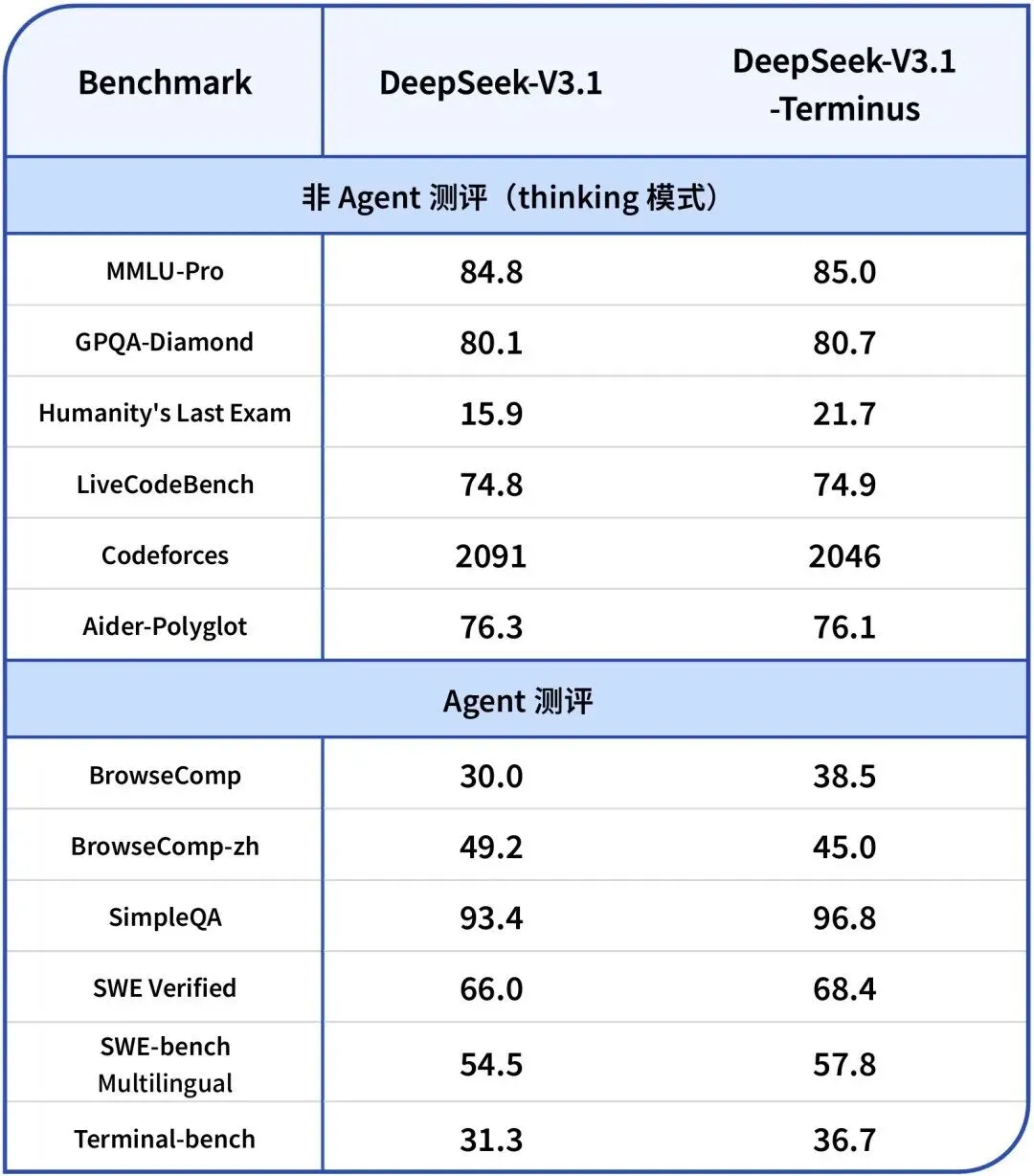
先看 Code Agent,以前 V3.1 版本的它,语法错误多,面对复杂逻辑拆解能力也差。但 Terminus 版本的 Code Agent,SWE-bench 得分从 44.6 飙升至 66.0,能修复 66% 的真实漏洞。举个例子,同样是写小球弹跳代码,V3.1 版本写出的代码缺失物理逻辑,根本无法使用;而 Terminus 版本生成的代码,是可直接部署的完整方案,专业度堪比资深开发者。
再说说 Search Agent,V3.1 版本的它在多条件搜索时,很容易出现漏检情况,对信源的辨别能力也较弱。Terminus 版本对其进行升级后,多条件验证准确率提升 45%。
三、一个模型两种 “人格”
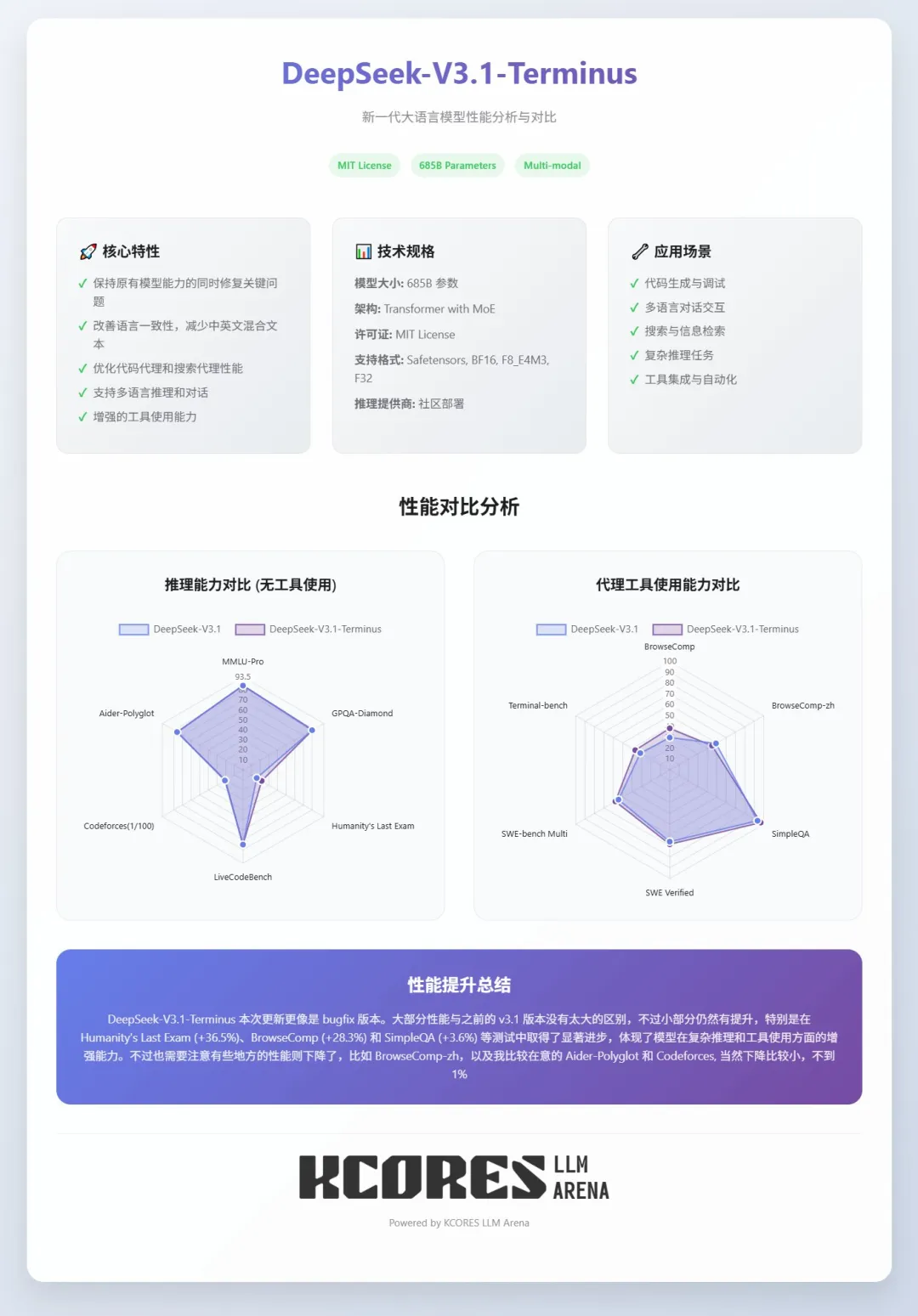
Terminus 版本创新采用双模式架构,让一个模型拥有了两种 “人格”,比 V3.1 更懂不同场景的需求。
快速模式(deepseek-chat)保持了秒答的高效率,同时输出更加规范;深度模式(deepseek-reasoner)新增了隐性推理功能,面对复杂问题时,准确率大幅跃升。
在处理能力上,Terminus 也实现了翻番。上下文从 V3.1 的 64K 扩展至 128K,这意味着现在可以一次性读取 50 万字文档,而 V3.1 仅能读取 25 万字;输出长度方面,深度模式最大可达 64K,远超 V3.1 的上限。性能跑分上,HLE 测试提升 36.5%,跃居全球第三,效率提升显而易见。
四、更新为V3.1-Terminus
开源版本下载地址如下:
Hugging Face:
https://huggingface.co/deepseek-ai/DeepSeek-V3.1-Terminus
ModelScope:
https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.1-Terminus
