【论文阅读 | IF 2025 | LFDT-Fusion:潜在特征引导的扩散 Transformer 模型在通用图像融合中的应用】
论文阅读 | IF 2025 | LFDT-Fusion:潜在特征引导的扩散 Transformer 模型在通用图像融合中的应用
- 1&&2. 摘要&&引言
- 3. 预备知识与动机
- 3.1. 扩散模型
- 3.2. 潜在扩散模型
- 3.3. 动机
- 4. 用于图像融合的潜在特征引导扩散Transformer
- 4.1. 潜在特征引导的去噪过程
- 4.3. 损失函数
- 4.4. 改进的训练策略
- 4.4.1. 噪声水平
- 4.4.2. 去噪步骤
- 4.4.3. 扩散采样器
- 5. 实验结果
- 5.1. 实验设置
- 5.1.1. 数据集
- 5.1.2. 对比方法与评估指标
- 5.1.3. 实现细节
- 6. 结论

题目:LFDT-Fusion: A latent feature-guided diffusion Transformer model for general image fusion
期刊:IF(Information Fusion)
论文:paper
代码:code
年份:2025
1&&2. 摘要&&引言
在图像融合任务中,扩散模型在原始分辨率图像上多次迭代以进行特征映射的效率较低。为解决这一问题,本文提出了一种用于通用图像融合的高效潜在特征引导扩散模型。
该模型由像素空间自动编码器和紧凑的基于 Transformer 的扩散网络组成。具体而言,像素空间自动编码器是一种新颖的基于 UNet 的潜在扩散策略,通过下采样将输入压缩到低分辨率潜在空间。同时,跳跃连接将多尺度中间特征从编码器传递到解码器以进行解码,从而保留原始输入的高分辨率信息。
与现有的基于变分自编码器 - 生成对抗网络(VAE-GAN)的潜在扩散策略相比,所提出的基于 UNet 的策略稳定性显著提高,且无需对抗优化就能生成细节丰富的图像。基于 Transformer 的扩散网络由去噪网络和融合头组成:前者捕捉长程扩散依赖关系并学习分层扩散表示,后者促进扩散特征交互以理解复杂的跨域信息。
实验结果表明,无论是在公共数据集还是工业环境中,该方法在定性和定量方面都具有优势。
综上所述,本文的主要贡献如下:
- 提出了一种基于 UNet 架构的潜在扩散模型,该模型在解码过程中通过引入跳跃特征来保留原始输入的高分辨率信息,从而实现融合图像的重建。值得注意的是,与现有的 VAE-GAN 相比,所提出的潜在扩散模型在训练过程中更稳定,且能适应不同的图像融合场景。
- 为提升融合任务的去噪性能,提出采用 Transformer 模型作为潜在扩散的新骨干网络,以捕获长程空间和像素依赖关系。同时,设计了融合头,有效整合来自不同源图像的潜在扩散特征,促进跨域信息交互与融合。
- 开展了全面的对比研究,探究影响图像融合性能的扩散模型因素。研究发现,选择 DPM-solver++ 等采样器不仅能提升计算效率,还能实现更优异的融合性能。大量实验和视觉应用(如目标检测)表明,该方法在多种多模态和数字摄影图像数据集上具有优异的性能和广泛的适用性。
3. 预备知识与动机
3.1. 扩散模型
扩散模型[38,55]旨在学习数据的近似分布,它由前向扩散过程和反向去噪过程组成。在前向过程中,按照方差调度{β1,…,βT}\left\{\beta_{1},\ldots,\beta_{T}\right\}{β1,…,βT},逐步向干净样本x0∼q(x0)x_{0}\sim q\left(x_{0}\right)x0∼q(x0)添加高斯噪声。当时间步长T足够大时,xTx_{T}xT接近纯高斯噪声。前向扩散过程允许在任何时间步t进行采样,公式如下:
q(xt∣xt−1)=N(1−βtxt−1,βtI)q\left(x_{t} \mid x_{t-1}\right)=\mathcal{N}\left(\sqrt{1-\beta_{t}} x_{t-1}, \beta_{t} I\right)q(xt∣xt−1)=N(1−βtxt−1,βtI)
其中t∼{0,…,T}t\sim\{0,\ldots, T\}t∼{0,…,T},αt=1−βt\alpha_{t}=1-\beta_{t}αt=1−βt,αˉt=∏i=1tαi\bar{\alpha}_{t}=\prod_{i=1}^{t}\alpha_{i}αˉt=∏i=1tαi是方差调度,xtx_{t}xt表示时间t的噪声图像。通过使用重参数化技巧:xt=αˉtx0+1−αˉtϵtx_{t}=\sqrt{\bar{\alpha}_{t}} x_{0}+\sqrt{1-\bar{\alpha}_{t}}\epsilon_{t}xt=αˉtx0+1−αˉtϵt,其中ϵt∼N(0,I)\epsilon_{t}\sim\mathcal{N}(0, I)ϵt∼N(0,I),ϵ\epsilonϵ是高斯噪声,可以在任何时间步t重建图像xtx_{t}xt。
在反向扩散过程中,扩散模型被训练来学习逆过程,在预定义的时间步范围内进行迭代去噪[56]。因此,反向扩散过程被定义为一个从p(xT)=N(xT;0,I)p\left(x_{T}\right)=\mathcal{N}\left(x_{T}; 0, I\right)p(xT)=N(xT;0,I)开始的马尔可夫链的联合分布pθ(x0:T)p_{\theta}\left(x_{0: T}\right)pθ(x0:T):
pθ(x0:T)=p(xT)∏t=1Tpθ(xt−1∣xt)p_{\theta}\left(x_{0: T}\right)=p\left(x_{T}\right) \prod_{t=1}^{T} p_{\theta}\left(x_{t-1} \mid x_{t}\right)pθ(x0:T)=p(xT)t=1∏Tpθ(xt−1∣xt)
其中pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),σt2I)p_{\theta}\left(x_{t-1} \mid x_{t}\right)=\mathcal{N}\left(x_{t-1} ; \mu_{\theta}\left(x_{t}, t\right), \sigma_{t}^{2} I\right)pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),σt2I)。通过训练网络ϵθ\epsilon_{\theta}ϵθ从xtx_{t}xt预测噪声ϵ\epsilonϵ,可以计算μθ(xt,t)\mu_{\theta}\left(x_{t}, t\right)μθ(xt,t):
μθ(xt,t)=1αt(xt−βt1−αˉtϵθ(xt,t))\mu_{\theta}\left(x_{t}, t\right)=\frac{1}{\sqrt{\alpha_{t}}}\left(x_{t}-\frac{\beta_{t}}{\sqrt{1-\bar{\alpha}_{t}}} \epsilon_{\theta}\left(x_{t}, t\right)\right)μθ(xt,t)=αt1(xt−1−αˉtβtϵθ(xt,t))
其中ϵ∼N(0,I)\epsilon\sim\mathcal{N}(0, I)ϵ∼N(0,I),σt2\sigma_{t}^{2}σt2通常设置为零方差。此外,ϵθ(xt,t)\epsilon_{\theta}\left(x_{t}, t\right)ϵθ(xt,t)被重新参数化为具有可训练模型参数θ\thetaθ的噪声预测网络μθ(xt,t)\mu_{\theta}\left(x_{t}, t\right)μθ(xt,t)。为此,扩散网络μθ(xt,t)\mu_{\theta}\left(x_{t},t\right)μθ(xt,t)在给定x~0∣t\widetilde{x}_{0\mid t}x0∣t的情况下预测去噪样本xtx_{t}xt。反向扩散过程中的一个时间步表示为:
xt−1=1αt(xt−1−αt1−αˉtϵθ(xt,t))+σtzx_{t-1}=\frac{1}{\sqrt{\alpha_{t}}}\left(x_{t}-\frac{1-\alpha_{t}}{\sqrt{1-\bar{\alpha}_{t}}} \epsilon_{\theta}\left(x_{t}, t\right)\right)+\sigma_{t} zxt−1=αt1(xt−1−αˉt1−αtϵθ(xt,t))+σtz
然后,执行多次去噪迭代,直到生成最终图像x0x_{0}x0: xT→⋯→xt−1→⋯→x_{T}\rightarrow\cdots\rightarrow x_{t-1}\rightarrow\cdots\rightarrowxT→⋯→xt−1→⋯→ →x0\rightarrow x_{0}→x0。
3.2. 潜在扩散模型
潜在扩散模型[51]是一种高效的扩散模型,它在潜在空间而不是像素空间中进行扩散过程。LDM首先使用来自预训练VAE-GAN的编码器E\mathcal{E}E将输入数据样本x0∼q(x0)x_{0}\sim q\left(x_{0}\right)x0∼q(x0)压缩到较低维的潜在代码z=E(x)z=\mathcal{E}(x)z=E(x)。随后,通过两个关键过程——扩散和去噪——来学习数据的分布,类似于DMs。前向过程和反向过程的公式如下:
q(zt∣zt−1):=N(1−βtzt−1,βtI),pθ(zt−1∣zt):=N(μθ(zt,t),σt2I)q\left(z_{t} \mid z_{t-1}\right):=\mathcal{N}\left(\sqrt{1-\beta_{t}} z_{t-1}, \beta_{t} I\right), \quad p_{\theta}\left(z_{t-1} \mid z_{t}\right):=\mathcal{N}\left(\mu_{\theta}\left(z_{t}, t\right), \sigma_{t}^{2} I\right)q(zt∣zt−1):=N(1−βtzt−1,βtI),pθ(zt−1∣zt):=N(μθ(zt,t),σt2I)
其中z是输入数据x在潜在空间中的潜在表示。
3.3. 动机
为了更好地理解去噪扩散过程,本小节分析了LDM基本特性的频谱变化。具体来说,将去噪网络视为线性高斯滤波器。从频率角度来看,随着去噪过程从t = T反向进行到t = 0,参数at从0增加到1,LDM应随时间表现出频谱变化。如图1所示,随着t增加,输入到LDM的训练数据首先失去高频频谱,随后在前向过程中逐渐失去低频信号。这些发现与高斯滤波器的既定特性一致,已知其主要抑制高频成分[57]。相应地,在扩散反向过程的早期阶段,仅恢复负责表示粗略结构的低频分量。随着t减小和at增加,图像中更多的高频成分,例如精细边缘和纹理结构,逐渐恢复。

LDM的频率分析表明,高频信号在扩散过程中比低频信号更容易丢失。特别是在潜在空间内,潜在特征主要包括低频信号,高频信号较少。因此,实现融合图像的高质量建模需要考虑两个关键因素:像素空间自编码器和更容易在扩散过程中丢失的低频信号。(译者注:原文此处句子似乎不完整或表述不清,按字面翻译)用于重建高质量图像。鉴于高斯噪声对信号的衰减效应,潜在空间中的去噪网络应优先保留低频信号。另一方面,像素空间自编码器在将图像从潜在空间映射到像素空间时,应保留原始图像的复杂细节,从而提高图像重建的准确性和保真度。
一种广泛采用的做法是利用VAE-GAN模型[51]作为像素空间自编码器,将输入数据映射到潜在空间。然而,在图像融合任务中,直接使用训练好的VAE-GAN作为压缩模型是不合适的。具体来说,图像融合任务需要多个输入图像和一个输出结果,因此需要多个编码器和一个解码器。VAE-GAN所采用的一对一编码器-解码器结构无法适应这种多输入场景,从而阻碍了其在后续扩散过程中的直接应用。此外,重新训练VAE-GAN需要真实值,但大多数图像融合任务缺乏这样的真实值。第三,尽管为不同类型的融合图像训练多个VAE-GAN是可能的,但这非常耗时,并且融合图像的数据分布会因合并来自不同传感器的数据而发生变化,从而导致解码器解码出的融合结果次优。
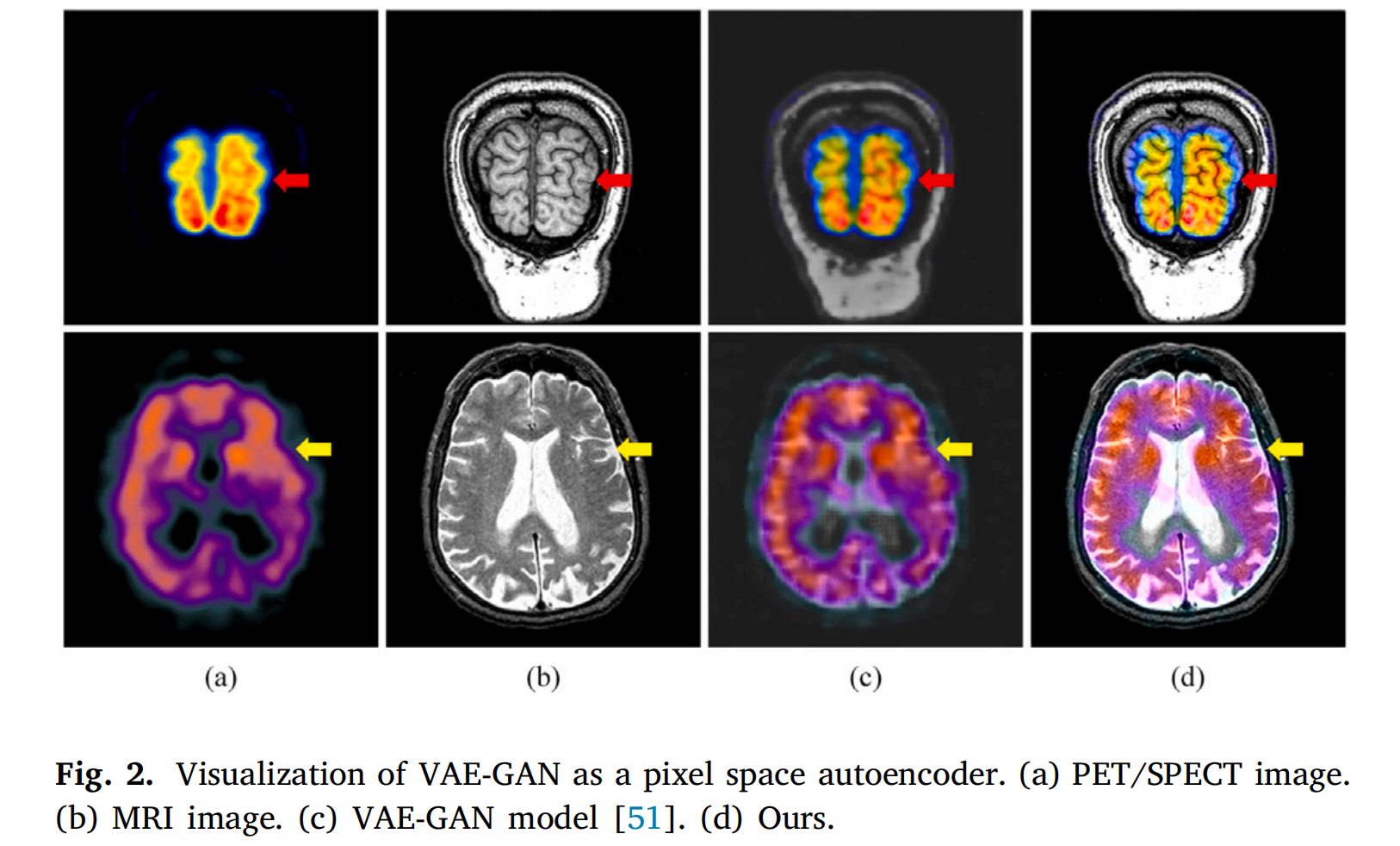
图2展示了一个使用VAE-GAN作为像素空间自编码器进行医学图像融合的示例。在图2中,可以明显看到VAE-GAN的融合结果存在细节丢失和颜色偏移等问题。这归因于合并不同传感器数据导致的融合图像数据分布变化,从而导致解码器解码出次优的融合结果。
目前,基于UNet的去噪网络是扩散技术中最流行的基础模型,它们具有更好的高频信号保留能力。然而,LDM的频率分析表明,潜在空间内的去噪网络应优先保留低频信号。因此,采用UNet作为去噪网络可能会产生次优结果。因此,选择能够更好保留低频信号的基础模型变得至关重要。考虑到Transformer模型[58]能够模拟远程像素依赖关系并表现出优异的低频信号保留能力,它已成为潜在空间内去噪网络基础模型的一个可行选择。总之,利用适当的去噪网络和像素空间自编码器可以减轻信息丢失,并建立高效可靠的扩散过程。
由于扩散模型需要真实值来建立前向过程,而大多数融合任务缺乏真实值,一种有效的方法是使用预训练的扩散模型作为先验信息。然而,自然图像的特征和分布与特定领域图像的特征和分布不同,这可能导致预训练模型在图像融合任务中性能不佳。此外,预训练模型通常需要大量调整才能在新的融合任务中表现良好,消耗额外的计算资源。因此,设计一种基于潜在特征扩散的图像融合方法至关重要。具体来说,潜在特征扩散可以根据不同的输入学习和提取更有效的扩散特征表示。这种方法可以避免因预训练扩散模型的特征分布差异而导致的融合性能下降。此外,潜在特征扩散可以在前向和反向过程中捕获不同尺度和时间步的潜在特征。通过整合这些多尺度和多时间步的潜在特征,融合图像可以更好地保留细节和全局信息的保真度。最后,通过利用源图像的潜在特征进行扩散,减少了对计算资源的需求,从而加速了融合结果的生成。
4. 用于图像融合的潜在特征引导扩散Transformer
4.1. 潜在特征引导的去噪过程
图像融合任务被重新定义为潜在特征引导的去噪过程,该过程通过多次迭代生成最终的融合图像。具体来说,令s1∈RH×W×Cins_{1}\in R^{H\times W\times C_{\text{in}}}s1∈RH×W×Cin和s2∈RH×W×Cins_{2}\in R^{H\times W\times C_{\text{in}}}s2∈RH×W×Cin表示两个配准的源图像,令f∈RH×W×Coutf\in R^{H\times W\times C_{\text{out}}}f∈RH×W×Cout表示融合图像。这里,H,W,CinH, W, C_{\text{in}}H,W,Cin分别表示输入图像的高度、宽度和通道数。CoutC_{\text{out}}Cout是融合图像的通道数,从s1s_{1}s1和s2s_{2}s2提取的潜在特征分别表示为d1=E(s1)d_{1}=\mathcal{E}\left(s_{1}\right)d1=E(s1)和d2=E(s2)d_{2}=\mathcal{E}\left(s_{2}\right)d2=E(s2)。给定来自两个源图像的潜在特征d1d_{1}d1和d2d_{2}d2,融合图像f的后验分布概率表示为pθ(f∣d1,d2)p_{\theta}\left(f\mid d_{1}, d_{2}\right)pθ(f∣d1,d2)。根据贝叶斯定理[59],后验分布分解为pθ(f∣d1,d2)∝pθ(d1,d2∣f)⋅pθ(f)p_{\theta}\left(f\mid d_{1}, d_{2}\right)\propto p_{\theta}\left(d_{1}, d_{2}\mid f\right)\cdot p_{\theta}(f)pθ(f∣d1,d2)∝pθ(d1,d2∣f)⋅pθ(f)。为了找到使后验概率最大化的融合结果f∗f^{*}f∗,采用最大后验概率(MAP)方法[60]:
f∗=argmaxfpθ(f∣d1,d2)=argmaxfpθ(d1,d2∣f)⋅Pθ(f)f^{*}=\underset{f}{\operatorname{argmax}} p_{\theta}\left(f \mid d_{1}, d_{2}\right)=\underset{f}{\operatorname{argmax}} p_{\theta}\left(d_{1}, d_{2} \mid f\right) \cdot \mathcal{P}_{\theta}(f)f∗=fargmaxpθ(f∣d1,d2)=fargmaxpθ(d1,d2∣f)⋅Pθ(f)
其中第一项称为数据项,表示由潜在特征d1d_{1}d1和d2d_{2}d2引导的似然估计过程。第二项是特征项,为前一项编码潜在引导特征。Pθ\mathcal{P}_{\theta}Pθ是一个用于评估融合结果的神经网络。
受LDM近期成功[52-54]的启发,采用扩散过程来隐式学习argmaxfpθ(f∣d1,d2)\operatorname{argmax}_{f} p_{\theta}\left(f\mid d_{1}, d_{2}\right)argmaxfpθ(f∣d1,d2)。具体来说,图像融合任务的前向扩散过程定义为高斯转移,记为q(Dt∣Dt−1):=N(1−βtDt−1,βtI)q\left(D_{t}\mid D_{t-1}\right):=\mathcal{N}\left(\sqrt{1-\beta_{t}} D_{t-1},\beta_{t} I\right)q(Dt∣Dt−1):=N(1−βtDt−1,βtI),其中βt\beta_{t}βt是预定义的方差调度。潜在变量DtD_{t}Dt由公式(2)表示:
q(Dt∣D0)=N(Dt;αˉtD0,(1−αˉt)I)q\left(D_{t} \mid D_{0}\right)=\mathcal{N}\left(D_{t} ; \sqrt{\bar{\alpha}_{t}} D_{0},\left(1-\bar{\alpha}_{t}\right) I\right)q(Dt∣D0)=N(Dt;αˉtD0,(1−αˉt)I)
4.2. 网络架构
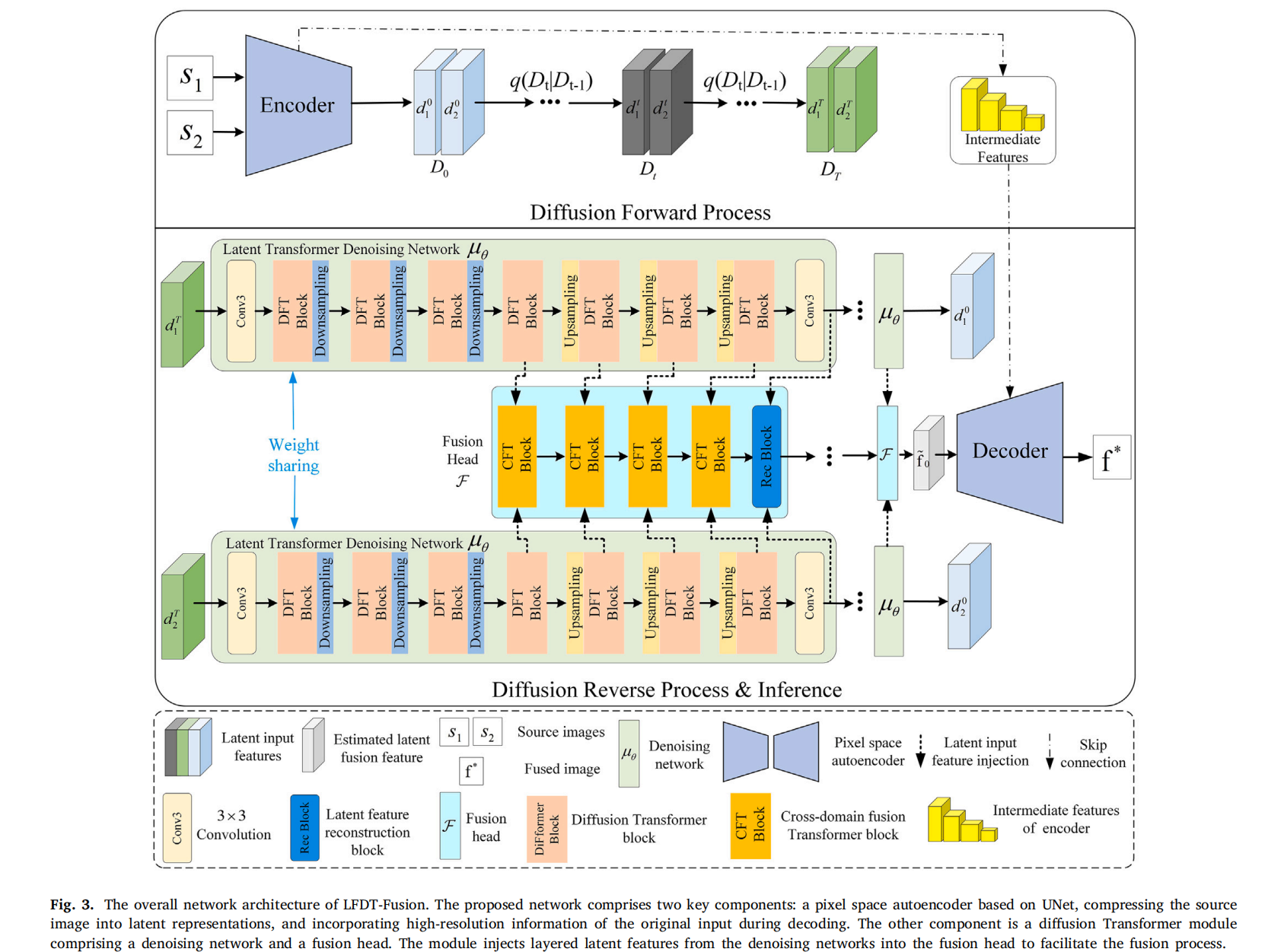
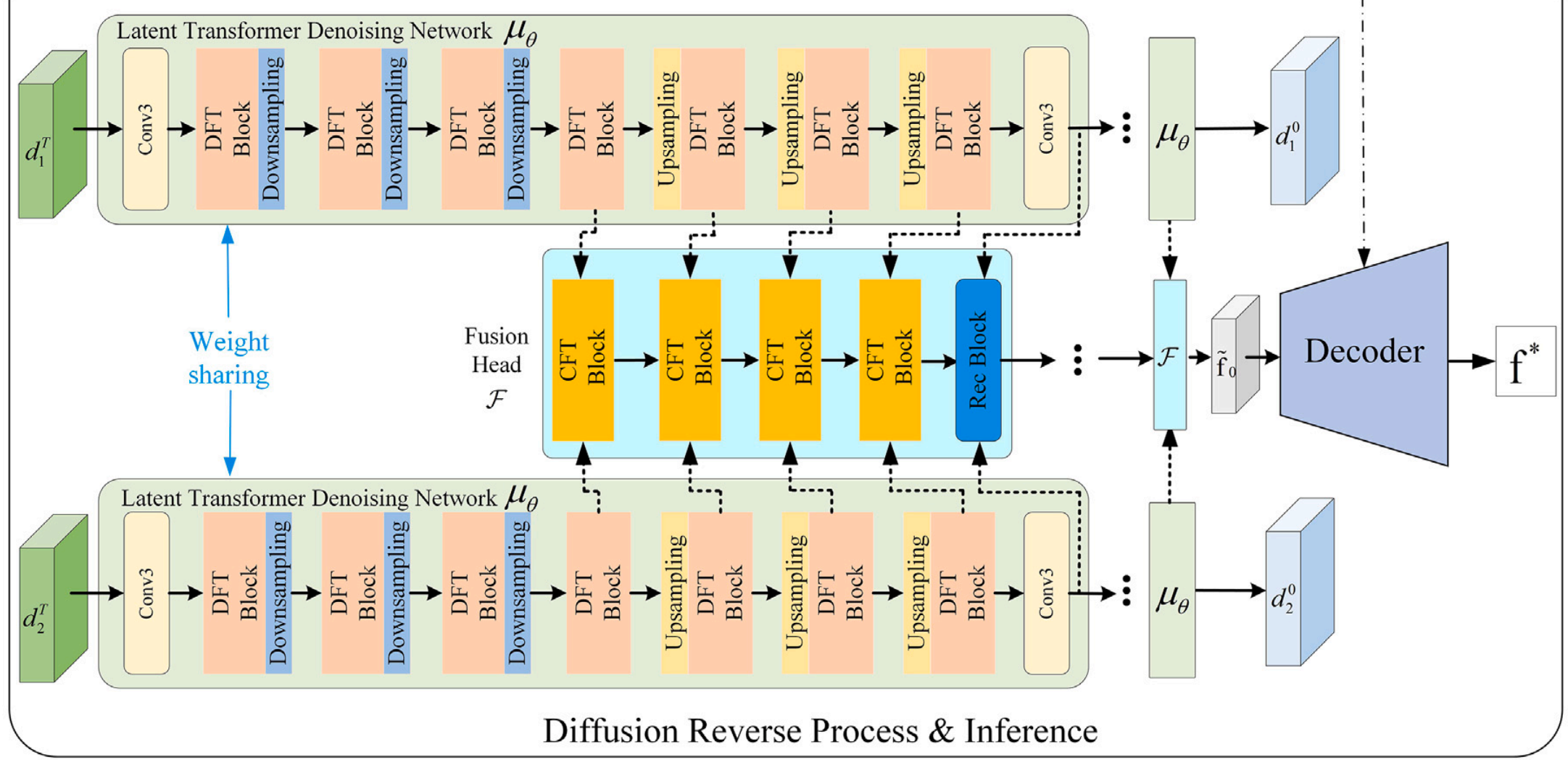
如前一节所述,构建一个自编码器和一个去噪网络对于潜在空间中的扩散过程是必要的。因此,本小节讨论了实现这一目标所需的网络架构设计。所提出方法的流程如图3所示。在前向过程中,空间编码器 E\mathcal{E}E 对输入图像进行下采样,得到潜在空间表示,从而获得源图像 s1s_{1}s1 和 s2s_{2}s2 的潜在特征 d10d_{1}^{0}d10 和 d20d_{2}^{0}d20。随后,逐步向潜在特征 D0={d10,d20}∈RH4×W4×CeD_{0}=\left\{d_{1}^{0}, d_{2}^{0}\right\}\in R^{\frac{H}{4}\times\frac{W}{4}\times C_{e}}D0={d10,d20}∈R4H×4W×Ce 添加噪声,生成一个完全随机的噪声表示 DT∈RH4×W4×CeD_{T}\in R^{\frac{H}{4}\times\frac{W}{4}\times C_{e}}DT∈R4H×4W×Ce,其中 CeC_{e}Ce 是潜在空间嵌入的维度。在反向去噪过程中,噪声表示 DTD_{T}DT 被输入到潜在扩散Transformer网络中进行去噪。同时,潜在特征 d1Td_{1}^{T}d1T 和 d2Td_{2}^{T}d2T 通过去噪网络的解码器进行分层编码,并在不同分辨率下注入到融合头中,以实现特征间的交互和融合。最后,解码器 D 将潜在表示 f~0\tilde{f}_{0}f~0 和编码器的中间特征重构为最终的融合图像 f∗f^{*}f∗。
4.2.1. 像素空间自编码器
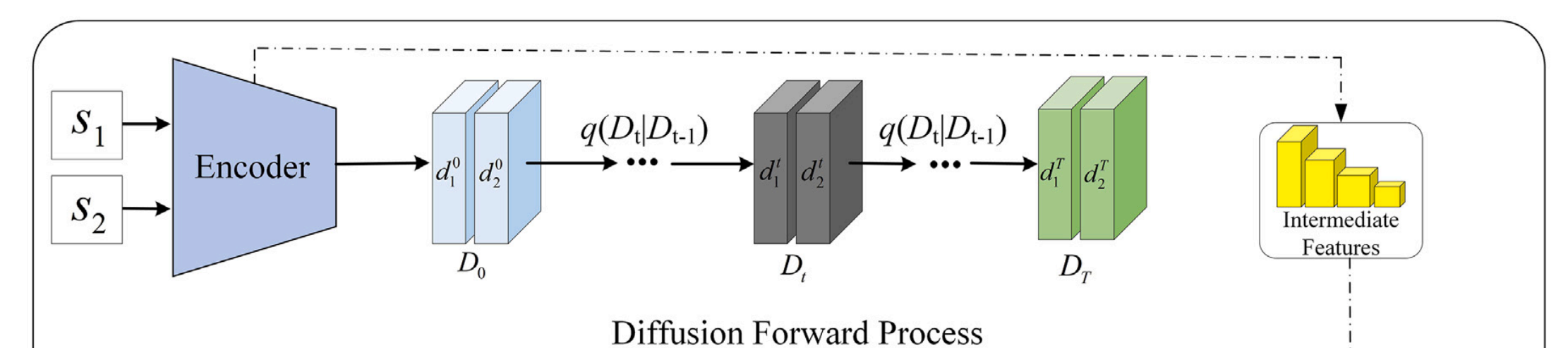

在原始分辨率上迭代运行扩散模型(即使只有几个去噪步骤)通常被认为是耗时的。在低分辨率潜在空间中执行图像融合任务对于降低计算复杂度和提高推理速度至关重要。当采用 VAE-GAN 作为压缩模型时,它们需要进行预训练以适应不同的图像融合任务。因此,本小节提出使用 UNet 模型作为像素空间自编码器来替代 VAE-GAN 模型。与使用 VAE-GAN 作为潜在扩散的压缩模型相比,有两个显著区别。首先,所提出的 UNet 通过跳跃连接(skip connections)将多尺度细节从编码器保留到解码器。这使得能够更好地捕获输入图像信息,并为解码器提供额外的细节以重构更准确的融合图像。其次,它不需要预训练+6;而是作为整体框架的一部分以端到端的方式进行训练。这种训练策略不涉及对抗优化,使得模型训练比潜在扩散训练更稳定。
像素空间自编码器的核心组件包括两个对称的特征编码器 E=(E1,E2)\mathcal{E}=\left(\mathcal{E}_{1},\mathcal{E}_{2}\right)E=(E1,E2) 和一个特征解码器 DDD。特征编码器由四层组成,前三层专用于特征提取,每层包含两个残差块(Resblock)和一个下采样模块。第四层专门用于特征压缩,由单个 Resblock 单元实现。每个 Resblock 由两个卷积层和残差连接组成。下采样模块通过卷积操作降低特征图的空间分辨率。编码器通过特征编码和压缩从输入 s1s_{1}s1 和 s2s_{2}s2 中提取潜在特征 d10d_{1}^{0}d10 和 d20d_{2}^{0}d20。此外,在每个编码器的前三层中会产生中间特征,并通过多个 3×33\times 33×3 卷积层进行聚合,从而生成模态混合的中间特征 hhh。定义如下:
h=Convagg(Concat([E1(1−3)(s1),E2(1−3)(s2)]))h = \text{Conv}_{\text{agg}}(\text{Concat}([\mathcal{E}_{1}^{(1-3)}(s_1), \mathcal{E}_{2}^{(1-3)}(s_2)]))h=Convagg(Concat([E1(1−3)(s1),E2(1−3)(s2)]))
其中 Convagg\text{Conv}_{\text{agg}}Convagg 表示用于聚合的卷积层,Concat\text{Concat}Concat 是拼接操作,Ei(1−3)\mathcal{E}_{i}^{(1-3)}Ei(1−3) 表示第 iii 个编码器的前三层。
特征解码器与特征编码器结构相似,但其第一层专用于特征扩展,随后是三层用于特征解码。具体来说,特征解码器在其第一层扩展潜在融合特征 f~0\widetilde{f}_{0}f0 的维度。然后,将扩展后的特征与中间特征 hhh 拼接,并输入到后续的三层中进行特征解码。定义如下:
f∗=D(Concat([f~0,h]))f^{*} = D(\text{Concat}([\widetilde{f}_0, h]))f∗=D(Concat([f0,h]))
其中 hhh 表示编码器 E\mathcal{E}E 的中间特征,f∗f^{*}f∗ 表示由解码器 D 重构的融合图像。
4.2.2. 扩散Transformer网络
扩散Transformer模块由一个去噪网络和一个融合头组成。前者在潜在空间中执行反向去噪过程,而后者则有效整合多尺度潜在特征的跨域交互。具体来说,去噪网络被视为一个特征提取网络,负责捕获和处理多尺度、多时间步的扩散特征。融合头是一个特征融合网络,整合了去噪网络产生的多尺度扩散特征。融合网络和去噪网络通过动态迭代过程相互优化,以实现高融合性能。细节如下:
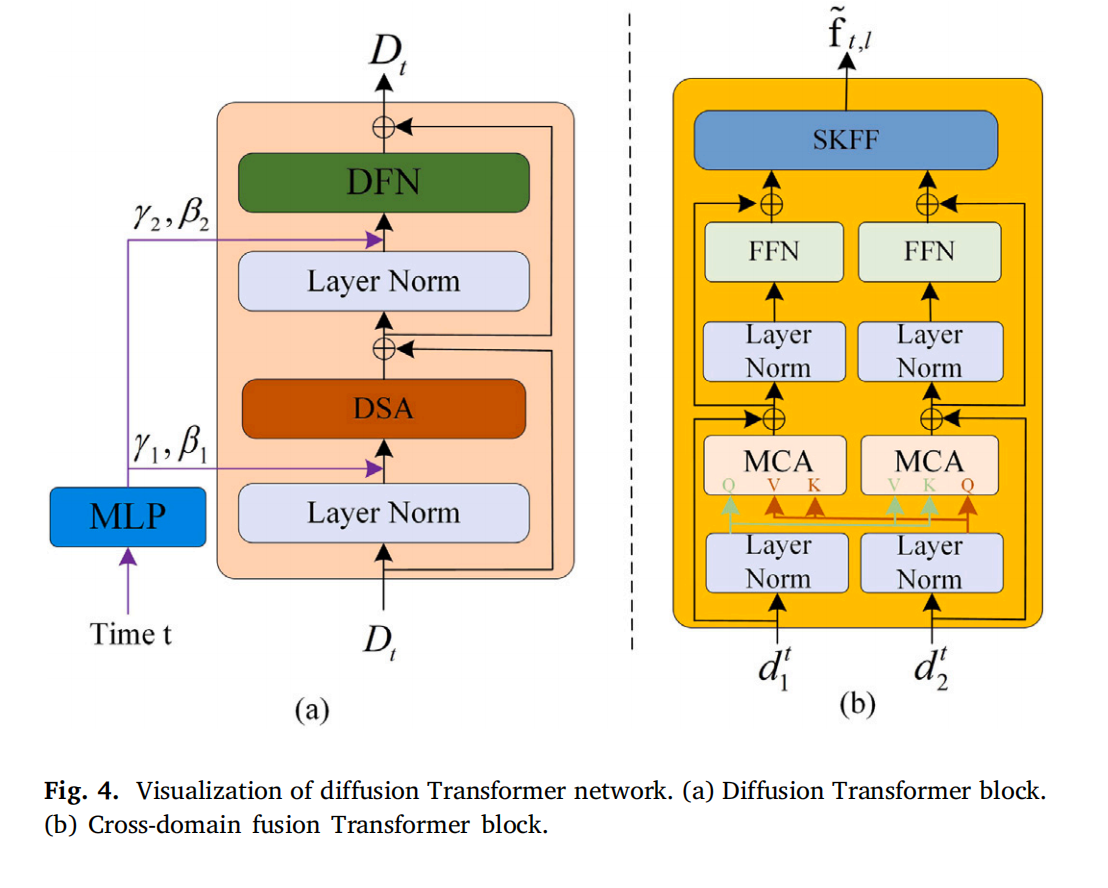
- 去噪网络 (Denoising Network): 去噪网络采用四阶段编码器-解码器架构。每个阶段包含多个扩散Transformer(DFT)块,其中包括一个扩散前馈网络(DFN)、扩散自注意力机制(DSA)和多层感知器(MLP),如图 4(a) 所示。DFN 帮助模型捕获来自不同位置的潜在特征,增强其表示能力。DSA 为不同位置的潜在特征分配注意力权重,捕获像素依赖关系。MLP 通过将时间步 ttt 嵌入为通道尺度 γ\gammaγ 和偏移参数 β\betaβ,将时间集成到 DFT 块中。给定扩散模型的时间步 ttt,MLP 将 ttt 编码为通道尺度 γ={γ1,γ2}∈R1×1×C\gamma=\left\{\gamma_{1},\gamma_{2}\right\}\in R^{1\times 1\times C}γ={γ1,γ2}∈R1×1×C 和偏移参数 β={β1,β2}∈R1×1×C\beta=\left\{\beta_{1},\beta_{2}\right\}\in R^{1\times 1\times C}β={β1,β2}∈R1×1×C。然后,将 γ1\gamma_{1}γ1 和 β1\beta_{1}β1 线性嵌入到给定的输入特征 DtD_{t}Dt 中以进行自注意力计算:
DSA(Dt)=A(Q,K,V)=V⋅Softmax(K⋅Q/α)\text{DSA}(D_t) = \mathcal{A}(Q, K, V) = V\cdot\operatorname{Softmax}(K\cdot Q/\alpha)DSA(Dt)=A(Q,K,V)=V⋅Softmax(K⋅Q/α)
其中 Q=C1(Dt)+β1Q = C_1(D_t) + \beta_1Q=C1(Dt)+β1, K=C1(Dt)+β1K = C_1(D_t) + \beta_1K=C1(Dt)+β1, V=C1(Dt)+β1V = C_1(D_t) + \beta_1V=C1(Dt)+β1(注:原文公式(10)似乎有误或简化,通常Q、K、V由线性变换得到),A\mathcal{A}A 是自注意力机制,α\alphaα 是一个可学习的缩放参数。C1C_{1}C1 和 CdC_{d}Cd 分别表示 1×11\times 11×1 卷积和 3×33\times 33×3 深度卷积。Split 是分割操作;LN(⋅)L N(\cdot)LN(⋅) 表示层归一化。
接下来,将 γ2\gamma_{2}γ2 和 β2\beta_{2}β2 嵌入到潜在特征 DtD_{t}Dt 中,并使用 DFN 生成输出:
DFN(Dt)=ϕ(Cd(C1(Dt))+β2)⋅γ2\text{DFN}(D_t) = \phi(C_d(C_1(D_t)) + \beta_2) \cdot \gamma_2DFN(Dt)=ϕ(Cd(C1(Dt))+β2)⋅γ2
其中 ϕ\phiϕ 表示非线性激活函数 GELU。
- 融合头 (Fusion Head): 融合头网络是一个解码器,由四级跨域融合Transformer(CFT)块组成,旨在整合来自去噪网络解码器的分层潜在特征,并促进特征融合的跨模态交互。其结构与 DFT 块非常相似,不同之处在于 CFT 块使用多头交叉注意力机制(MCA)来引导潜在特征的交互,并采用 SKFF[61] 进行特征聚合,如图 4(b) 所示。具体来说,由于提取的多模态潜在扩散特征存在语义差异,简单地合并多个信息源无法有效建模跨模态不一致性。因此,受 SwinFusion[34] 的启发,引入跨模态 MCA 来捕获多个潜在特征域之间的互补性并实现语义交互。潜在特征 d1td_{1}^{t}d1t 的查询(queries)、键(keys)和值(values)分别表示为 Q1,K1,V1Q_{1}, K_{1}, V_{1}Q1,K1,V1,而潜在特征 d2td_{2}^{t}d2t 的则表示为 Q2,K2,V2Q_{2}, K_{2}, V_{2}Q2,K2,V2。因此,得到的 d~1t\tilde{d}_{1}^{t}d~1t 表示被另一个潜在特征 d2td_{2}^{t}d2t 关注到的潜在特征 d1td_{1}^{t}d1t 的集合:
d~1t=MCA(Q1,K2,V2)\widetilde{d}_{1}^{t} = \text{MCA}(Q_1, K_2, V_2)d1t=MCA(Q1,K2,V2)
类似地,d~2t\widetilde{d}_{2}^{t}d2t 计算如下:
d~2t=MCA(Q2,K1,V1)\widetilde{d}_{2}^{t} = \text{MCA}(Q_2, K_1, V_1)d2t=MCA(Q2,K1,V1)
随后,应用 SKFF[61] 模块来整合由不同分支生成的跨域特征。定义如下:
f~t,l=SKFF(d~1t,d~2t)\widetilde{f}_{t, l} = \text{SKFF}(\widetilde{d}_{1}^{t}, \widetilde{d}_{2}^{t})ft,l=SKFF(d1t,d2t)
其中 f~t,l∈RH4l×W4l×Ce,l={1,2,3,4}\widetilde{f}_{t, l}\in R^{\frac{H}{4 l}\times\frac{W}{4 l}\times C_{e}}, l=\{1,2,3,4\}ft,l∈R4lH×4lW×Ce,l={1,2,3,4} 是通过第 lll 级 CFT 块获得的潜在融合特征。接下来,可以通过上采样和元素相加来聚合多尺度特征,得到 f~t\widetilde{f}_{t}ft:
f~t=f~t,1+U(f~t,2)+U2(f~t,3)+U3(f~t,4)\widetilde{f}_{t} = \widetilde{f}_{t,1} + \text{U}(\widetilde{f}_{t,2}) + \text{U}^2(\widetilde{f}_{t,3}) + \text{U}^3(\widetilde{f}_{t,4})ft=ft,1+U(ft,2)+U2(ft,3)+U3(ft,4)
其中 U 表示将特征 f~t,l+1\widetilde{f}_{t, l+1}ft,l+1 上采样到与 f~t,l\widetilde{f}_{t, l}ft,l 相同的分辨率,Add 是元素相加操作。
最后,将 f~t\widetilde{f}_{t}ft 和 Dt−1={d1t−1,d2t−1}D_{t-1}=\left\{d_{1}^{t-1}, d_{2}^{t-1}\right\}Dt−1={d1t−1,d2t−1} 输入到一个包含 SKFF 模块和 3×33\times 33×3 卷积层的重构块中:
f~0=Tanh(Conv(SKFF(Concat([f~t,Dt−1]))))\widetilde{f}_{0} = \text{Tanh}(\text{Conv}(\text{SKFF}(\text{Concat}([\widetilde{f}_{t}, D_{t-1}]))))f0=Tanh(Conv(SKFF(Concat([ft,Dt−1]))))
其中 Tanh 表示 tanh 激活函数,Conv 是 3×33\times 33×3 卷积,Concat 是拼接操作。Dt−1D_{t-1}Dt−1 表示从去噪网络得到的估计结果:Dt→Dt−1D_{t}\rightarrow D_{t-1}Dt→Dt−1。当 t=1t=1t=1 时,输入 D1D_{1}D1 通过去噪网络处理得到 D0D_{0}D0,记为 D1→D0D_{1}\rightarrow D_{0}D1→D0。f~1\widetilde{f}_{1}f1 使用公式(15)计算。将 f~1\widetilde{f}_{1}f1 和 D0D_{0}D0 代入公式(16)得到潜在融合结果 f~0\widetilde{f}_{0}f0。然后,融合图像 f∗f^{*}f∗ 由解码器 D 通过公式(9)重构。
4.3. 损失函数
为了训练扩散模型,需要对数据分量和噪声分量进行监督。因此,训练目标的主要损失函数包括扩散损失和融合损失,以约束网络:
Ltotal=Ldiff+Lfusion\mathcal{L}_{\text{total}} = \mathcal{L}_{\text{diff}} + \mathcal{L}_{\text{fusion}}Ltotal=Ldiff+Lfusion
在前向扩散过程中,可训练参数主要包括上述定义的潜在去噪模型。因此,通过最小化采样噪声 ϵ\epsilonϵ 和去噪预测 μθ(Dt,t)\mu_{\theta}\left(D_{t}, t\right)μθ(Dt,t) 之间的损失来训练模型:
Ldiff=Et,ϵ[∥ϵ−μθ(Dt,t)∥1]\mathcal{L}_{\text{diff}} = \mathbb{E}_{t, \epsilon} [\| \epsilon - \mu_{\theta}(D_t, t) \|_1]Ldiff=Et,ϵ[∥ϵ−μθ(Dt,t)∥1]
其中 DtD_{t}Dt 是通过公式(6)定义的前向过程获得的,该过程通过多个采样步骤计算。
融合损失项旨在使生成的融合结果在梯度信息、结构和像素强度分布方面更类似于源图像。因此,公式可以表示为:
Lfusion=λ1Lint+λ2Lssim+λ3Lgrad\mathcal{L}_{\text{fusion}} = \lambda_1 \mathcal{L}_{\text{int}} + \lambda_2 \mathcal{L}_{\text{ssim}} + \lambda_3 \mathcal{L}_{\text{grad}}Lfusion=λ1Lint+λ2Lssim+λ3Lgrad
其中 λ1,λ2,λ3\lambda_{1},\lambda_{2},\lambda_{3}λ1,λ2,λ3 是控制每个子损失项权衡的超参数。Lint,Lssim\mathcal{L}_{\text{int}},\mathcal{L}_{\text{ssim}}Lint,Lssim 和 Lgrad\mathcal{L}_{\text{grad}}Lgrad 分别表示像素强度损失、结构相似性损失和梯度损失。它们定义如下:
Lint=∥f∗−M(s1,s2)∥1Lssim=1−sim(f∗,s1)−sim(f∗,s2)Lgrad=∥∇f∗−max(∇s1,∇s2)∥1\begin{aligned} \mathcal{L}_{\text{int}} &= \| f^* - M(s_1, s_2) \|_1 \\ \mathcal{L}_{\text{ssim}} &= 1 - \text{sim}(f^*, s_1) - \text{sim}(f^*, s_2) \\ \mathcal{L}_{\text{grad}} &= \| \nabla f^* - \max(\nabla s_1, \nabla s_2) \|_1 \end{aligned}LintLssimLgrad=∥f∗−M(s1,s2)∥1=1−sim(f∗,s1)−sim(f∗,s2)=∥∇f∗−max(∇s1,∇s2)∥1
其中 sim(⋅)\operatorname{sim}(\cdot)sim(⋅) 表示结构相似性操作,用于衡量两幅图像的相似性。∇\nabla∇ 是 Sobel 梯度算子。∣⋅∣|\cdot|∣⋅∣ 是绝对值操作,∥⋅∥1\|\cdot\|_{1}∥⋅∥1 表示 l1l_{1}l1 范数,max(⋅)\max(\cdot)max(⋅) 表示最大操作。M(⋅)M(\cdot)M(⋅) 是一个逐元素的融合操作,其中 VI-NIR 和 MEF 任务采用逐元素平均,而其他任务采用逐元素最大操作。根据经验,w1w_{1}w1 和 w2w_{2}w2 设置为 0.5。
4.4. 改进的训练策略
本小节研究了影响扩散模型训练过程的几个关键因素,以红外和可见光图像融合任务为例。
4.4.1. 噪声水平
在图像融合任务中,融合图像通常是从包含噪声的源图像重构的,而不是从纯噪声重构的。因此,在考虑扩散模型性能时,噪声水平(即公式(7)中的 σ)在反向去噪过程中起着至关重要的作用[62]。图5(a)比较了三种不同噪声水平(σ=30,50,70)对红外和可见光图像融合任务的影响。SSIM 曲线表明 σ=70 比 σ=30 和 σ=50 更稳定。
4.4.2. 去噪步骤
扩散模型通常在网络权重更新期间使用长步骤(T=1000)。然而,在图像融合任务中,选择适当的去噪步长可以提高采样效率并防止图像质量下降。在红外和可见光融合任务中,选择了10、15和25个去噪步骤进行比较。图5(b)展示了具有三种不同去噪步长的扩散模型的训练曲线。最初,三个步长对应的融合性能相当,但随着训练周期的增加,具有较大去噪步长的模型略优于步长较小的模型。这是因为较大的去噪步长会产生更好的图像重建效果,但代价是降低了样本生成效率。考虑到25个去噪步骤与10个步骤相比没有显著优势,选择10个去噪步骤更为合适。这样的选择不仅保持了良好的性能,而且减少了计算资源,使整个训练过程更加高效。
4.4.3. 扩散采样器
本小节研究了不同扩散采样器对融合任务训练的影响,旨在确定实现最佳训练效果的最佳选择。具体来说,去噪网络在反向扩散过程中需要执行多个推理步骤来生成图像,而扩散采样器是加速图像生成的有效工具。通过比较不同扩散采样器在训练过程中的收敛速度和稳定性,选择合适的扩散采样器以产生更高质量的融合结果。设计快速采样器的最新进展包括 LMS[38]、DDIM[39]、Deis[64]、DPM-solver[65]、DPM-solver++[66] 和 Unipc[67] 采样器。图5©比较了在10个去噪步骤下六种不同采样器的训练曲线。从图中可以看出,DDIM[39]、Deis[64]、DPM-solver++[66] 和 DPM-solver[65] 采样器都表现出令人满意的性能。其中,DPM-solver++[66] 和 Deis[64] 比其他采样器收敛更快,并且训练相对稳定。总之,选择 DPM-solver++[66] 或 Deis[64] 作为所提出方法的扩散采样器。
5. 实验结果
本节提供了相关的实验设置以确保实验的可重复性。接下来,通过与最先进的图像融合方法进行定量和定性比较,对所提出的方法进行全面评估。随后,通过一系列消融研究验证了所提出方法的有效性。最后,将所提出的方法应用于各种图像任务,以进一步验证其在其他计算机视觉应用中的潜在优势。
5.1. 实验设置
5.1.1. 数据集
选择了四个代表性的多模态图像融合任务,包括可见光和红外图像融合(VI-IR)、可见光和近红外图像融合(VI-NIR)、医学图像融合(Med)以及可见光和偏振图像融合(VI-PIF)。此外,还为数码摄影图像融合选择了两个典型任务:多曝光图像融合(MEF)和多焦点图像融合(MFF)。具体来说:
- VI-IR: 对于 VI-IR 任务,在 MSRS 数据集[68] 上进行网络训练,该数据集包含 1083 对图像。训练好的模型在三个数据集上进行评估:MSRS[68](50对)、LLVIP[69](50对)和 M3FD[18](50对)。
- VI-NIR: 在 VI-NIR 任务中,使用公开可用的 VI-NIR 数据集[70] 制作训练和测试数据集。训练集包含 427 对图像,而测试集包含 50 对图像。此外,MCubeS[71] 数据集(50对)被用作额外的测试数据集。
- Med: 对于医学图像融合任务,基于公开的哈佛医学数据集¹ 建立训练和测试数据集。具体来说,选择 249 对图像用于 PET 和 MRI 图像融合训练(Med(PET-MRI)),并保留 20 对用于测试。此外,SPECT 和 MRI 图像融合(Med(SPECT-MRI)) 的训练和测试集分别包含 337 和 20 对图像。
- MEF: MEF 数据集[72] 包含 589 个样本,其中 539 个用于训练。来自 MEF 数据集[72] 的剩余 50 个样本和另一个 MEFB 数据集[73](50对)组成测试数据集。
- MFF: 对于 MFF 任务,使用 RealMFF[74] 数据集对模型进行训练和测试,该数据集包括 660 对训练图像和 50 对测试图像。MFI-WHU[26] 数据集(50对)被引入作为测试数据集。
- VI-PIF: 对于 VI-PIF 任务,选择 RSP 数据集[75](1586对)进行网络训练。测试集包括 RSP 数据集[75](50对)和另一个数据集[76](20对)。
5.1.2. 对比方法与评估指标
总共选择了二十四种对比方法来评估其与所提出方法的性能。这项综合评估涵盖了六种通用的 SOTA 图像融合方法(DIFNet[33]、SwinFusion[34]、U2Fusion[30]、DeFusion[35]、TUFusion[37] 和 MUFusion[36]),以及为每个融合任务选择的多种任务特定的 SOTA 方法。具体来说,对于 VI-IR 任务,使用 DDFM[20]、DiF-fusion[46]、TarDAL[18]、SeAFusion[49] 和 CDDFuse[19] 作为融合方法,而对于 VI-NIR 任务,DehFusion[77] 和 LapFusion[78] 被指定为任务特定的对比方法。医学图像融合任务的任务特定方法包括 DDFM[20]、CDDFuse[19] 和 MATR[21]。在 VI-PIF 任务中,CVT[15]、DTCWT[16] 和 PFNet[23] 被确定为三种选定的融合方法。MEF 任务的各种替代方法包括 IID-MEF[27]、DPE-MEF[28] 和 MEF-GAN[24]。MFF 任务的替代方法包括 SFMD[12]、MFF-GAN[26] 和 Fusiondiff[48]。
此外,选择了五个指标进行定量评估:信息熵(EN)[79]、视觉信息保真度(VIF)[80]、特征互信息(FMI)[81]、基于梯度的相似性测量(QAB/FQ^{AB/F}QAB/F)[82] 和结构相似性(SSIM)[83]。EN[79] 用作融合图像中包含信息的定量度量,而 VIF[80] 从人类视觉感知的角度衡量信息保真度。FMI[81] 和 QAB/FQ^{AB/F}QAB/F[82] 分别测量融合图像中的特征信息和边缘信息。SSIM[83] 反映了与亮度、对比度和结构相关的图像失真。表现出更高 EN[79]、VIF[80]、FMI[81]、QAB/FQ^{AB/F}QAB/F[82] 和 SSIM[83] 值的融合方法展现出更优异的融合性能。
5.1.3. 实现细节
像素自编码器由两个相同的特征编码器和一个特征解码器组成。特征编码器和特征解码器有四层,每层包含[2, 2, 2, 1]个单元,通道数分别为[64, 128, 256, 8]。去噪网络的分层结构由四个级别组成,每个级别的数量为[4, 4, 4, 4],通道数为[32, 64, 128, 256]。融合头也有四个级别,每个级别的数量为[2, 2, 2, 2]。MCA 和 DSA 模块中的注意力头数依次为[1,2,4,8]。表1、2和3依次展示了像素空间自编码器、去噪网络和融合头的架构。
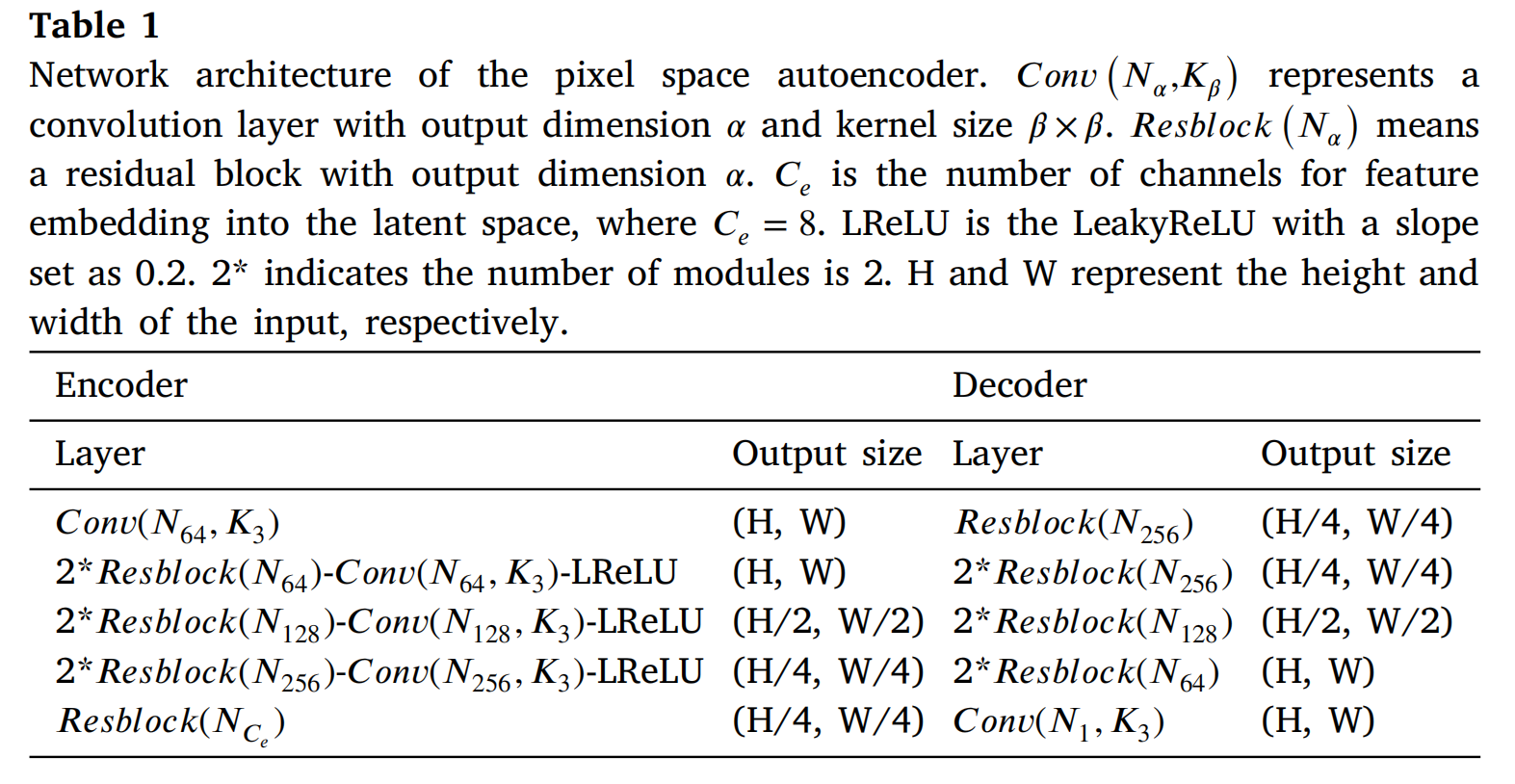
- 表 1: 像素空间自编码器的网络架构。Conv(N,K) 表示输出维度为 α\alphaα、卷积核大小为 β×β\beta\times\betaβ×β 的卷积层。Resblock (Nα)\left(N_{\alpha}\right)(Nα) 表示输出维度为 a 的残差块。CeC_eCe 是嵌入到潜在空间的通道数,其中 Ce=8C_e=8Ce=8。LReLU 是斜率设置为 0.2 的 LeakyReLU。2a 表示模块数量为 2。H 和 W 分别表示输入的高度和宽度。
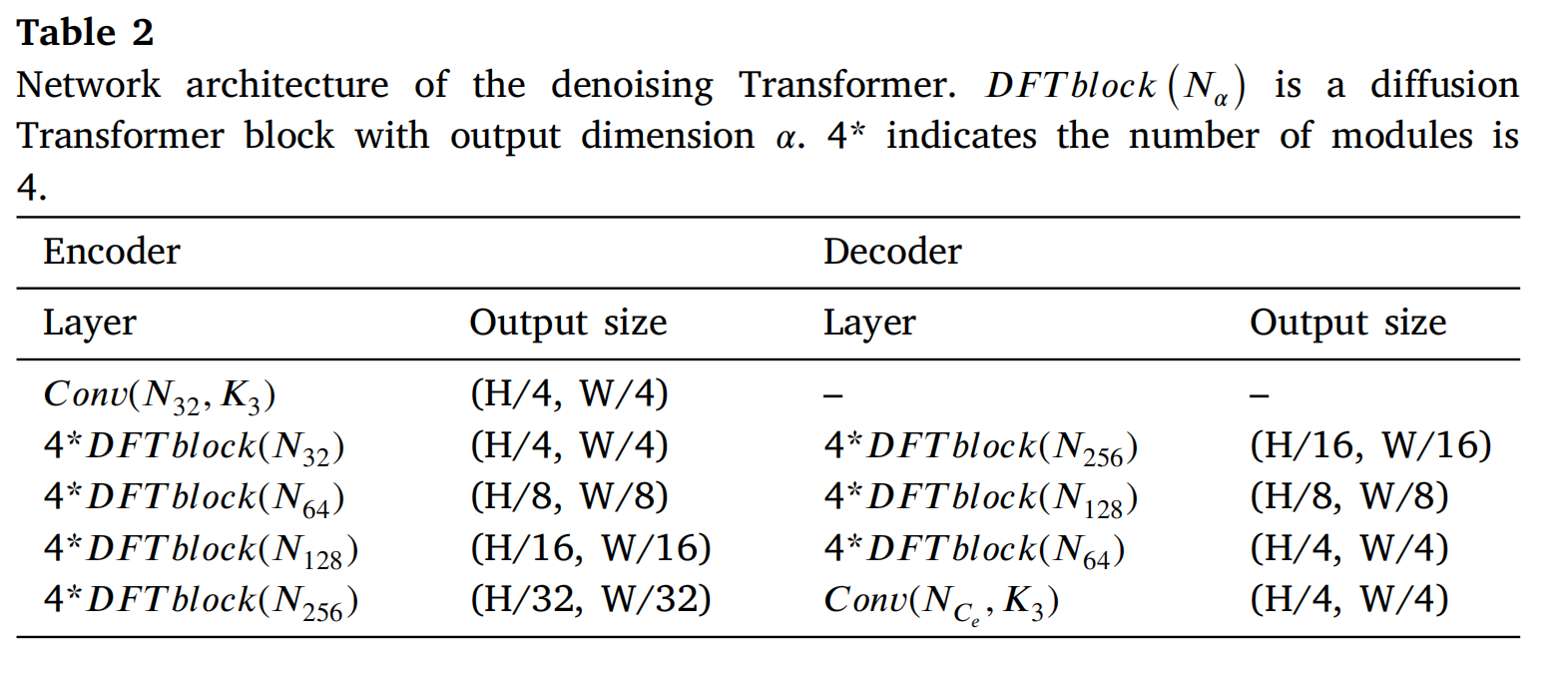
- 表 2: 去噪Transformer的网络架构。DFTblock (Na)\left(N_{a}\right)(Na) 是输出维度为 a 的扩散Transformer块。4* 表示模块数量为 4。

- 表 3: 融合头的网络架构。CFTblock (Na)\left(N_{a}\right)(Na) 表示输出维度为 α\alphaα 的跨域融合Transformer块。SKFF 是用于融合潜在特征 d10d_{1}^{0}d10 和 d20d_{2}^{0}d20 的特征聚合模块。Tanh 表示 Tanh 激活函数。
在扩散训练期间,采样器选择 DPM-solver++ 或 Deis,总时间步长设置为 1000,采样步长为 5。批量大小为 64,每个融合任务需要 60 个训练周期。在每个周期中,训练集中的图像被随机裁剪成 256×256256\times 256256×256 的块,并进行旋转、平移,随后归一化到 [0,1][0,1][0,1] 范围。采用 AdamW 优化器进行参数更新,学习率初始化为 3×10−43\times 10^{-4}3×10−4,并使用余弦退火算法动态调整学习率。在多模态融合任务中,控制融合损失中每个子损失权重的超参数根据经验设置为 λ1=10,λ2=40\lambda_{1}=10,\lambda_{2}=40λ1=10,λ2=40 和 λ3=40\lambda_{3}=40λ3=40。在数码摄影融合任务中,超参数设置为 λ1=10,λ2=20\lambda_{1}=10,\lambda_{2}=20λ1=10,λ2=20 和 λ3=20\lambda_{3}=20λ3=20。所提出的方法在 PyTorch 平台上实现,所有实验均在 NVIDIA GeForce RTX 3090 GPU 和 Intel ®{}^{\circledR}® Core TM^{TM}TM i7 CPU@4.2 GHz CPU 上进行。
为了使用统一模型处理各种图像融合任务,我们将所有 RGB 图像融合任务转换为单通道图像融合任务。首先,将 RGB 图像转换到 YCbCr 颜色空间。鉴于亮度和结构信息主要保留在 Y 通道中,因此选择该通道进行融合。此外,包含色度信息的 Cb 和 Cr 通道通过[34]中的方法进行融合。最后,将这三个通道的融合结果重构为 RGB 图像。
5.2. 多模态图像融合结果
5.2.1. 红外与可见光图像融合
图6展示了在三个数据集上的可视化结果。研究结果表明,DDFM[20] 和 DIFNet[33] 的融合结果倾向于保留热辐射信息,但未能有效呈现可见光图像中的场景细节,例如黑色的天空颜色。此外,TUFusion[37] 和 U2Fusion[30] 可以保留可见光图像中的一些场景细节,但仍然受到热辐射的影响,不同程度地削弱了红外图像中的显著目标。MUFusion[36] 的融合结果容易突出物体,TarDAL[18] 能有效保留红外高亮物体,但容易模糊场景细节。而 DiF-fusion[46]、SwinFusion[34]、SeAFusion[49] 和 CDDFuse[19] 的融合结果虽然显示出更好的视觉效果,但融合图像的强度分布和对比度与原始图像存在偏差。相比之下,我们提出的方法不仅保留了可见光图像中的场景信息,而且突出了显著目标,这得益于扩散Transformer能够通过模态内和模态间的远程建模以及全局融合,自适应地关注红外图像中的显著区域和可见光图像中的背景。
对三个数据集进行了进一步的定量评估,结果如表4、5和6所示。在M3FD和LLVIP数据集上,所提出的方法在VIF、QAB/F、SSIM和FMI等指标上优于其他方法。虽然在M3FD数据集的EN指标上略低于MUFusion[36]和TarDAL[18],但所提出的方法在MSRS数据集的所有指标上均排名第一。这些结果表明,所提出的方法实现了包含更多信息且与源图像保持强相关性的融合结果。
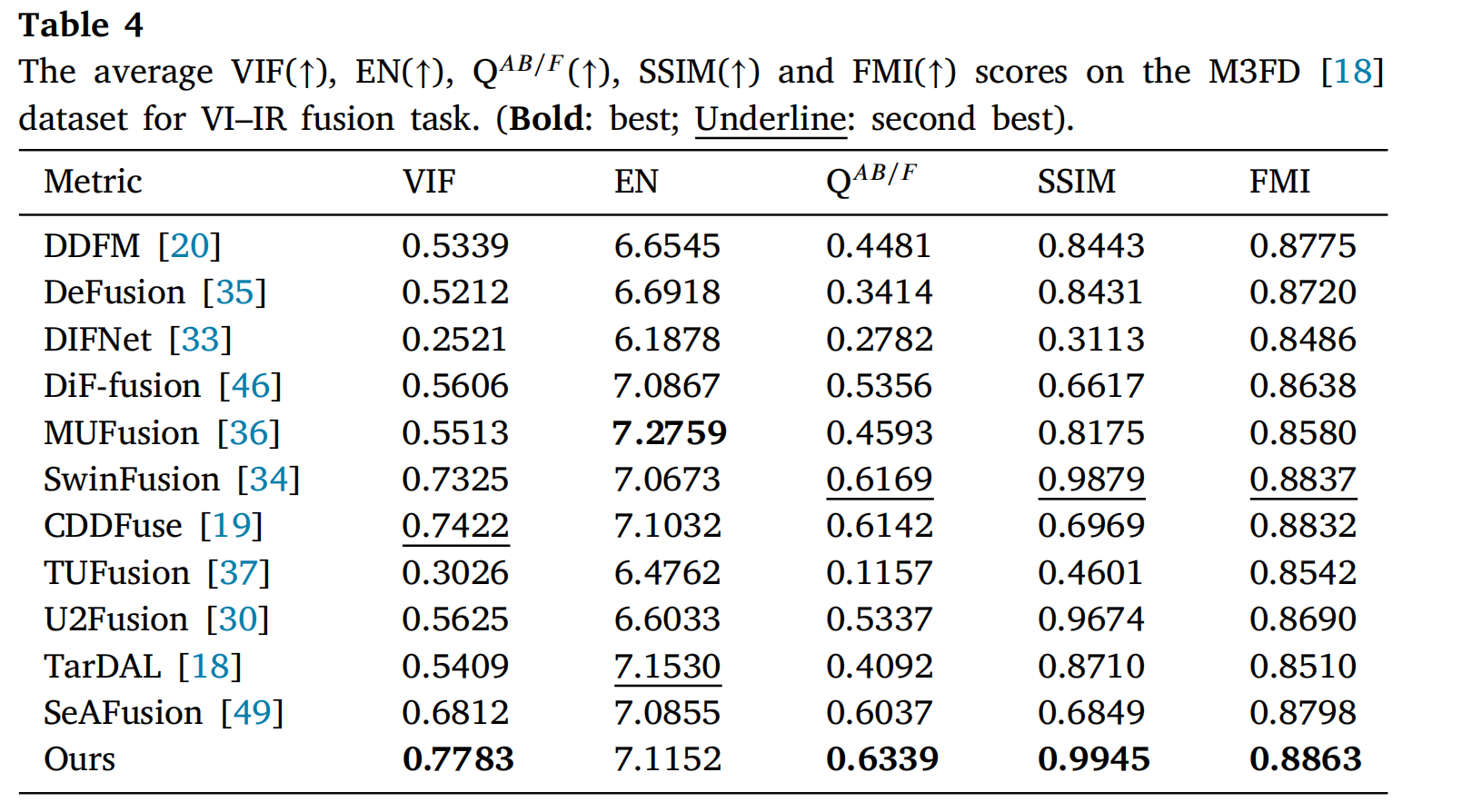
表4: 在M3FD[18]数据集上VI-IR融合任务的平均VIF(↑)、EN(↑)、QAB/F(↑)、SSIM(↑)和FMI(↑)分数。(粗体:最佳;下划线:次佳)
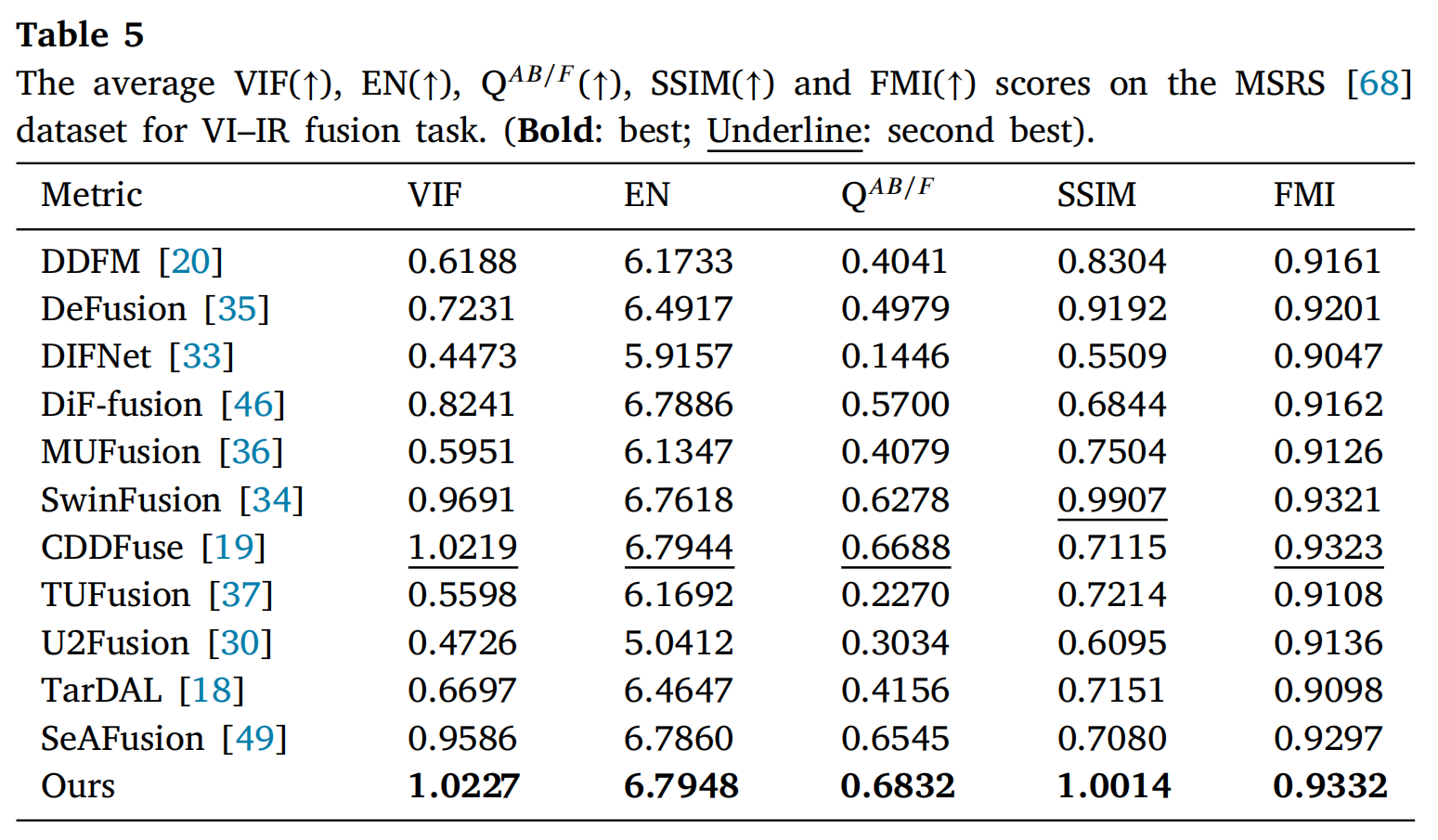
表5: 在MSRS[68]数据集上VI-IR融合任务的平均VIF(↑)、EN(↑)、QAB/F(↑)、SSIM(↑)和FMI(↑)分数。(粗体:最佳;下划线:次佳)
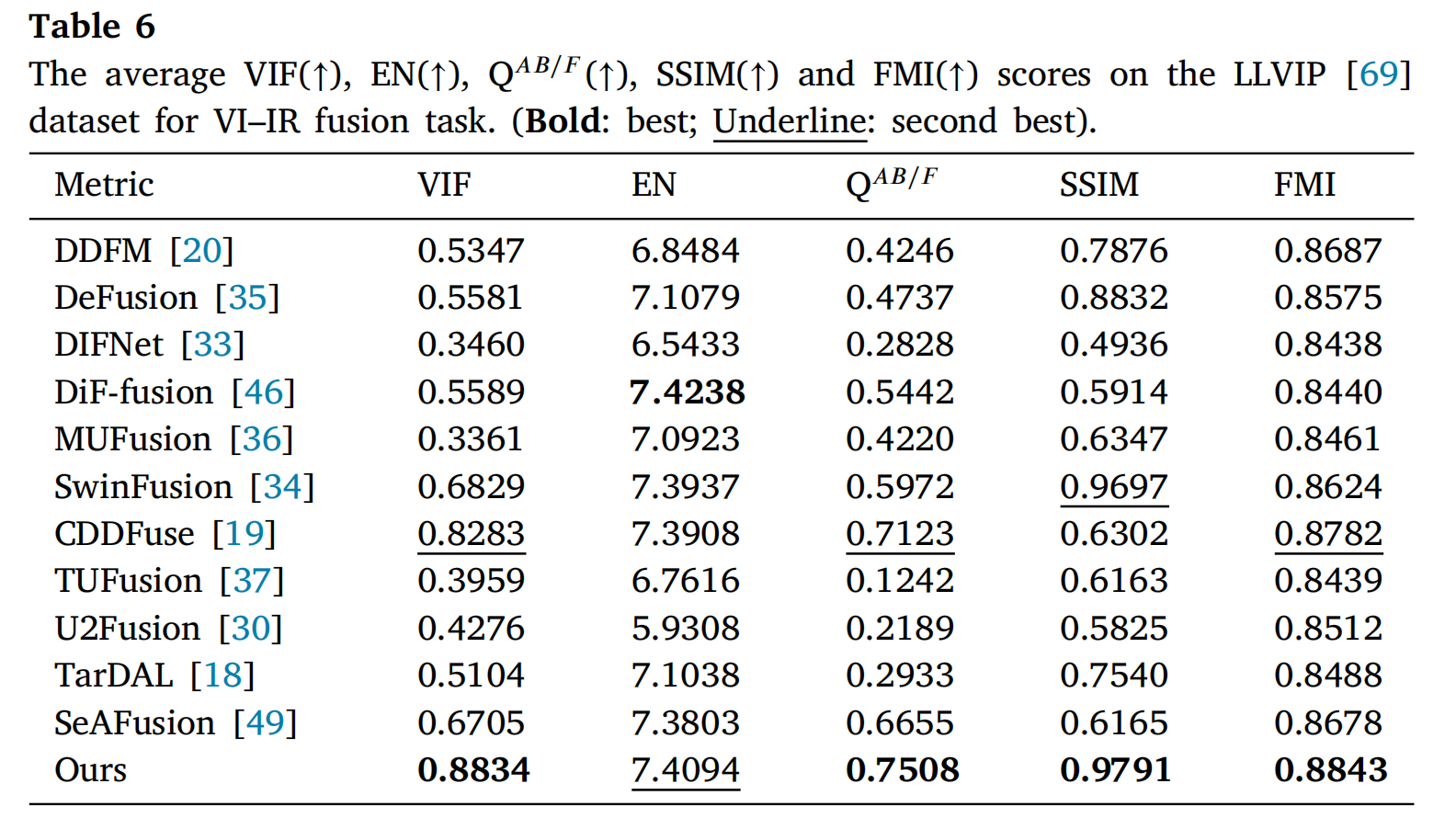
表6: 在LLVIP[69]数据集上VI-IR融合任务的平均VIF(↑)、EN(↑)、QAB/F(↑)、SSIM(↑)和FMI(↑)分数。(粗体:最佳;下划线:次佳)
5.2.2. 医学图像融合
医学图像融合(Med(SPECT-MRI) 和 Med(PET-MRI))的视觉质量比较如图7和图8所示。可以观察到,DeFusion[35]和U2Fusion[30]未能保持源图像的强度分布和对比度,导致颜色偏移并破坏了原始的颜色分布。DIFNet[33]、MUFusion[36]和SwinFusion[34]倾向于过度融合SPECT或PET图像的信息,而保留MRI图像中的软组织细节较少。例如,图7(h)中黄色框区域被无用的黑色信息淹没,并且图8(i)中MRI区域的软组织信息丢失。此外,TUFusion[37]和DDFM[20]缺乏适当的强度控制,常常损害MRI图像中的软组织信息,这在图7(k)和7(h)的绿色框区域中显而易见。尽管CDDFuse[19]和MATR[21]可以突出PET图像中的功能信息,但它们可能在不同程度上削弱MRI图像中的密集结构。总之,大多数融合方法未能有效整合源图像中的互补信息,并且不可避免地削弱了源图像中的基本信息。相比之下,所提出的方法可以减少软组织和解剖信息的丢失,保留MRI图像中的丰富细节,并全面表示PET和SPECT图像中的功能信息。
此外,所提出的方法取得了出色的定量结果。表7和表8分别展示了所提出的方法与最先进方法在SPECT-MRI和PET-MRI数据集上的定量结果。表7显示,所提出的方法在SPECT-MRI数据集的所有指标上均获得了最佳值。所提出的方法在PET-MRI数据集的VIF、QAB/F、SSIM和FMI指标上取得了最优值,尽管EN略低于MUFusion[36](表8)。综合考虑,所提出的方法在医学多模态图像融合领域展现了领先性能。
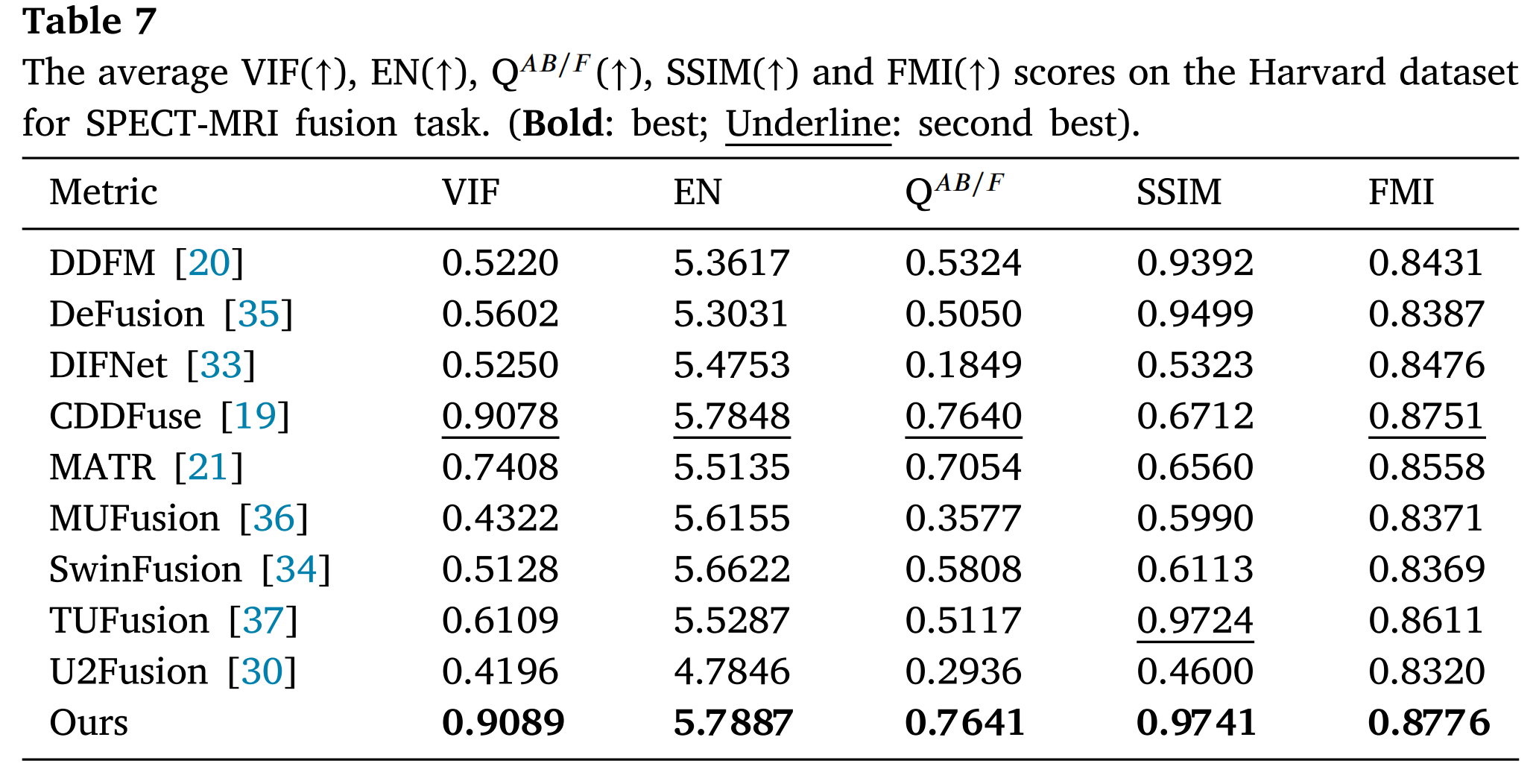
表7: 在哈佛数据集上SPECT-MRI融合任务的平均VIF(↑)、EN(↑)、QAB/F(↑)、SSIM(↑)和FMI(↑)分数。(粗体:最佳;下划线:次佳)
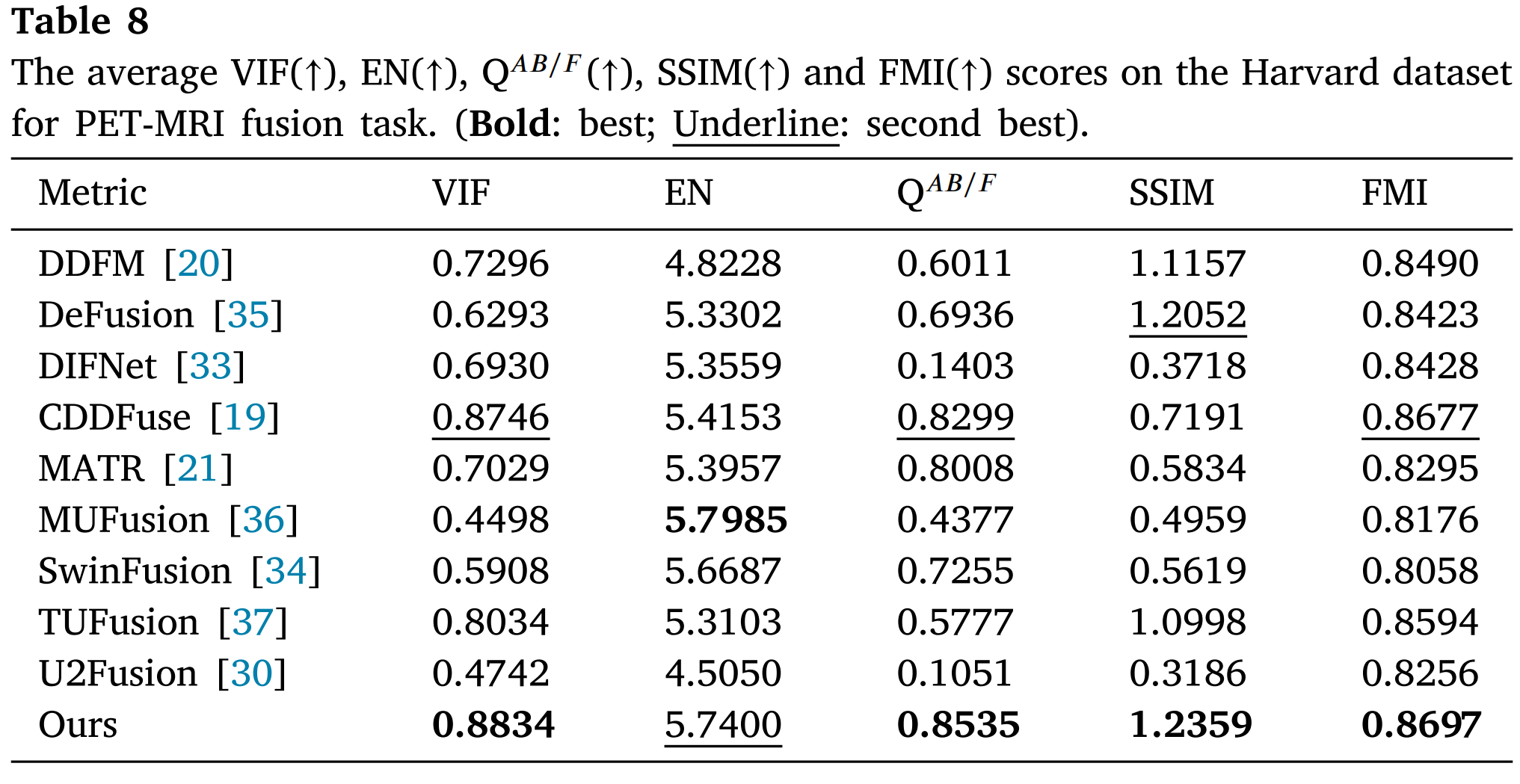
表8: 在哈佛数据集上PET-MRI融合任务的平均VIF(↑)、EN(↑)、QAB/F(↑)、SSIM(↑)和FMI(↑)分数。(粗体:最佳;下划线:次佳)
5.2.3. 可见光与偏振图像融合
在两个VI-PIF图像数据集上进行了定性比较,以直观比较不同方法的融合性能,结果如图9所示。发现所提出的方法有效地保留了可见光图像中的场景信息,呈现出视觉上令人愉悦的结果。例如,图9中红色框突出的瓶子的颜色和亮度更接近可见光图像中的样子。此外,所提出的方法保留了关于物体表面的显著偏振信息,同时抑制了偏振图像中的冗余信息。相比之下,大多数其他方法容易受到偏振图像中冗余信息的干扰,并且难以很好地保留诸如瓶子边缘、盒子和室外场景等物体上的显著偏振信息。总体而言,所提出的方法可以保留来自可见光图像的清晰纹理和物体对比度,同时减少偏振图像中冗余信息的干扰,从而实现更高质量的高对比度物体细节融合。
相应的定量结果如表9和表10所示。在表9中,所提出的方法在数据集[76]上的所有五个指标(VIF、EN、QAB/F、SSIM和FMI)均取得了最高平均值。特别是在SSIM和VIF指标上,所提出方法的分数显著高于其他方法。在表10中,对于RSP数据集,所提出的方法在EN指标上排名第二,而其他指标达到了最优值。综合考虑这些结果,所提出的方法在客观评估中优于其他方法,表明融合结果符合人类视觉系统,并有效地将源图像中的信息和边缘细节传递到了融合图像中。
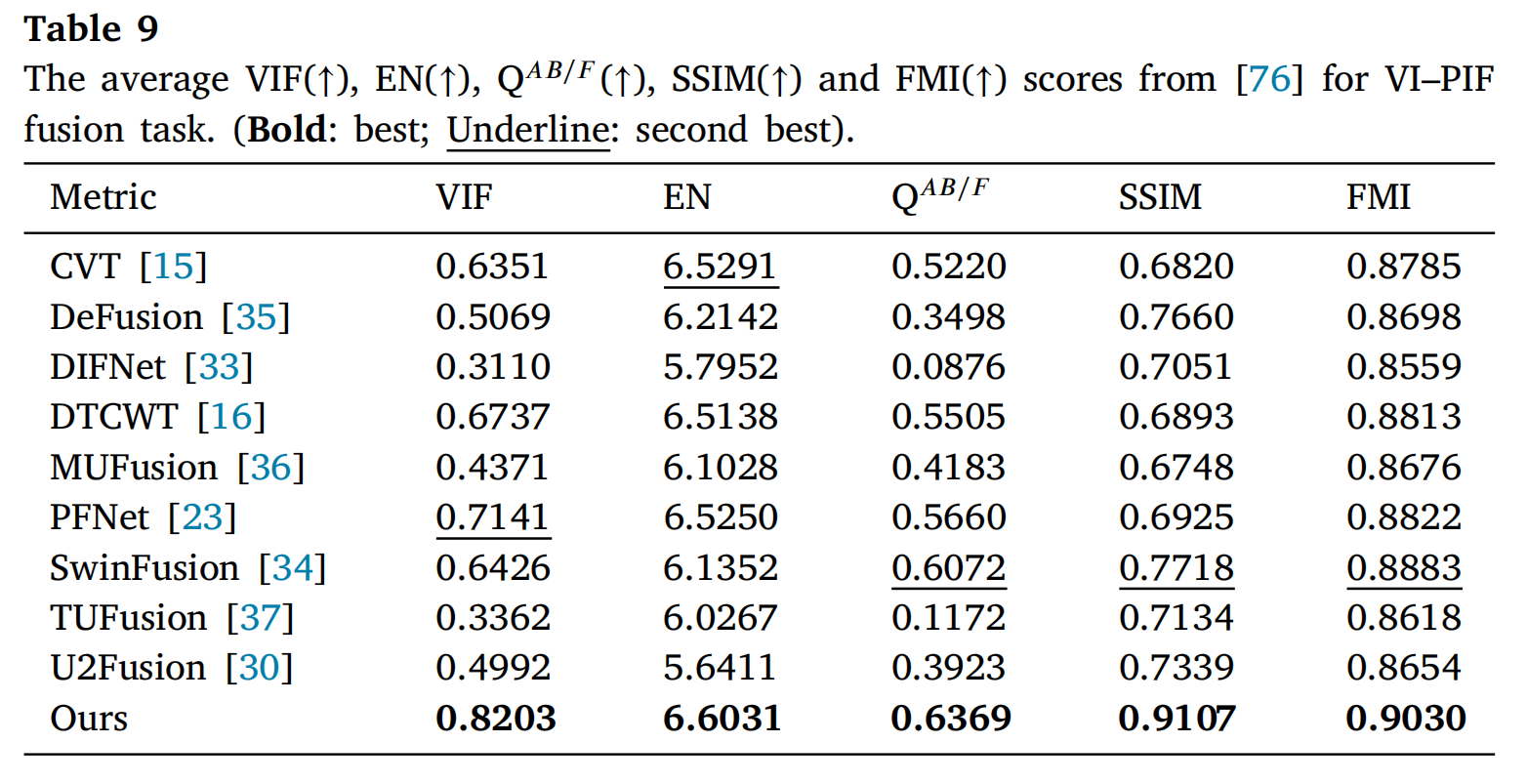
表9: 在[76]数据集上VI-PIF融合任务的平均VIF(↑)、EN(↑)、QAB/F(↑)、SSIM(↑)和FMI(↑)分数。(粗体:最佳;下划线:次佳)
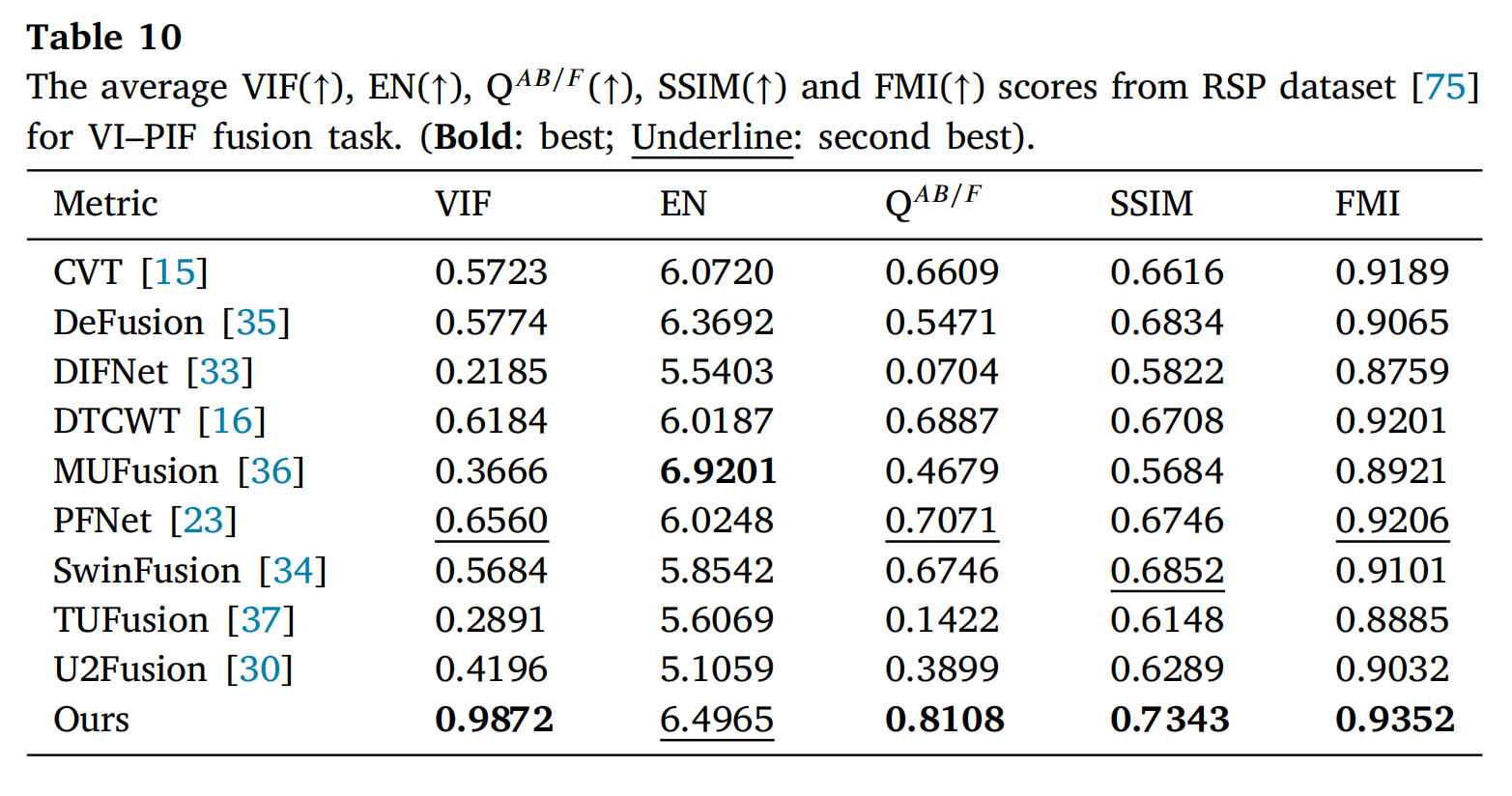
表10: 在RSP数据集[75]上VI-PIF融合任务的平均VIF(↑)、EN(↑)、QAB/F(↑)、SSIM(↑)和FMI(↑)分数。(粗体:最佳;下划线:次佳)
5.2.4. 近红外与可见光图像融合
近红外(NIR)波长有助于通过雾气获取额外的场景信息。因此,目标是将NIR图像中的纹理细节转移到可见光图像中,从而生成高质量的融合图像。图10展示了VI-NIR数据集的定性结果。融合结果显示,TUFusion[37]、LapFusion[78]和Defusion[35]的结果偏离了可见光图像的自然色彩和纹理。尽管MUFusion[36]可以保留更多的场景细节,但融合图像被过度增强,偏离了物体的原始对比度。相反,所提出的方法在保留场景结构和纹理的同时,有效地融合了互补信息。
表11和表12展示了所提出的方法在NIR[70]和MCubeS[71]数据集上的定量结果。结果显示,所提出的方法在两个数据集的VIF、QAB/F和FMI指标上均取得了最佳结果。尽管在EN和SSIM指标上仅位列前两名,但综合考虑所有指标,所提出的方法在VI-NIR任务中表现出显著的竞争力。
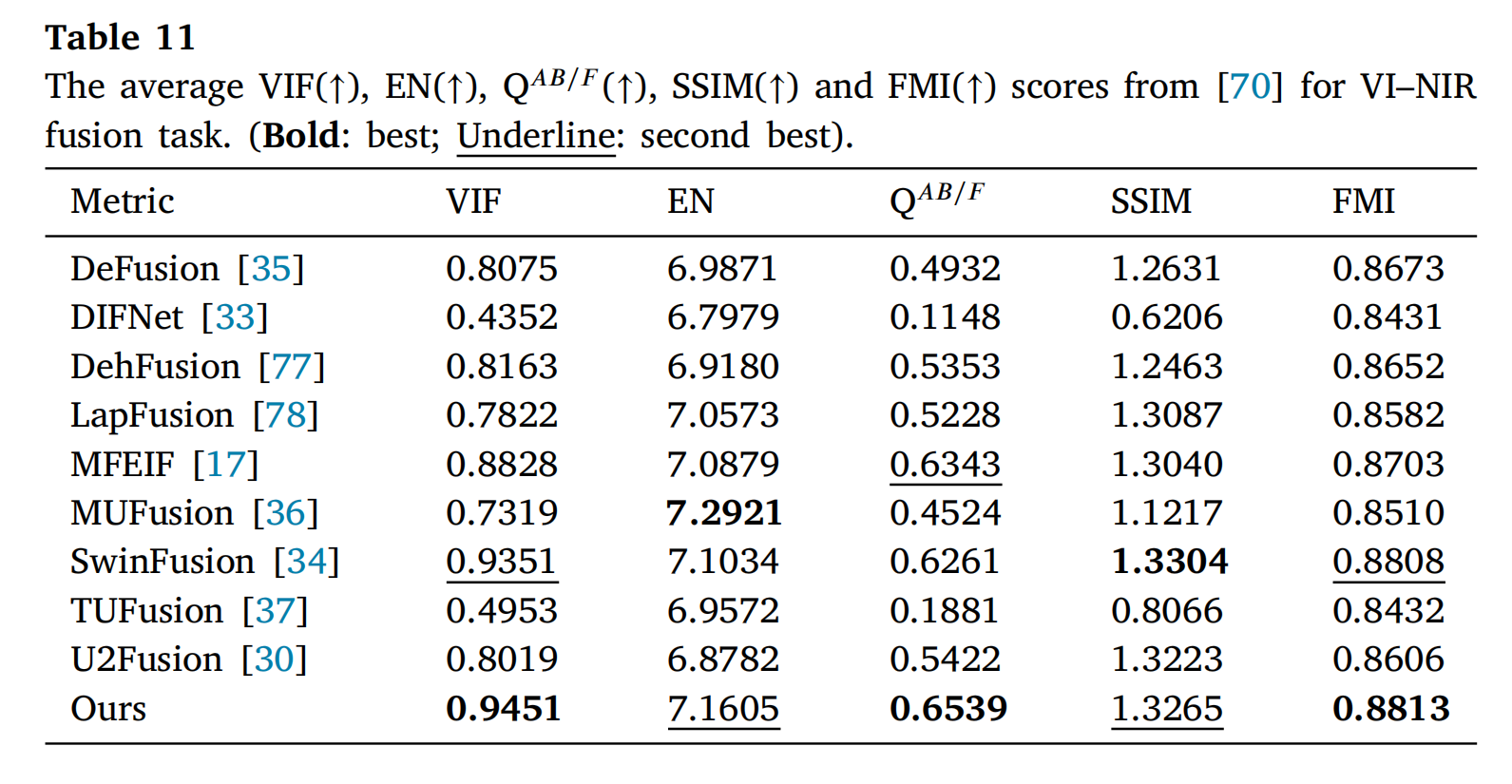
表11: 在[70]数据集上VI-NIR融合任务的平均VIF(↑)、EN(↑)、QAB/F(↑)、SSIM(↑)和FMI(↑)分数。(粗体:最佳;下划线:次佳)
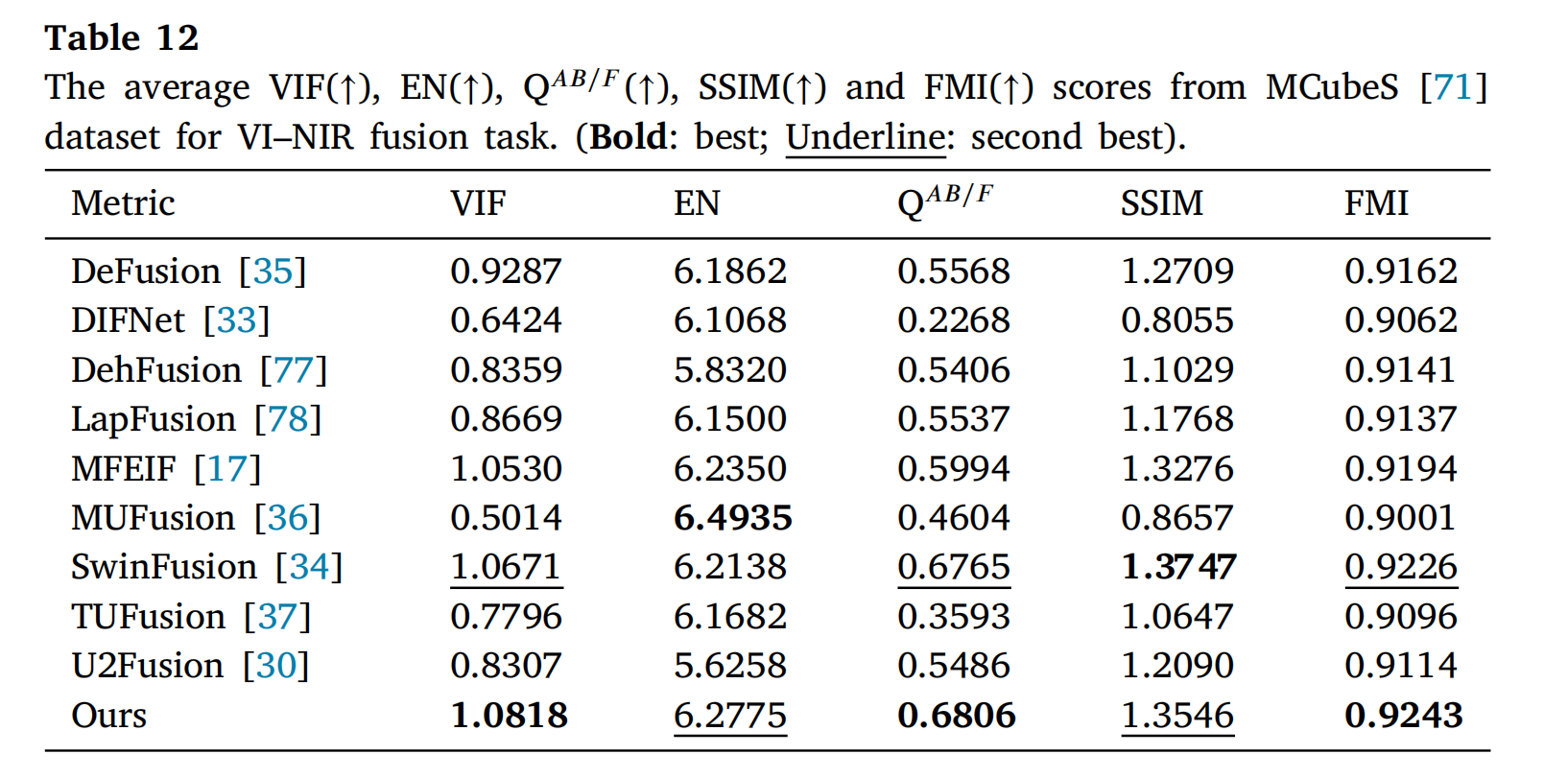
表12: 在MCubeS[71]数据集上VI-NIR融合任务的平均VIF(↑)、EN(↑)、QAB/F(↑)、SSIM(↑)和FMI(↑)分数。(粗体:最佳;下划线:次佳)
5.3. 数码摄影图像融合结果
5.3.1. 多焦点图像融合
图11展示了多焦点图像融合的主观比较结果。所有方法都能够整合来自不同源图像的焦点区域信息,生成完全聚焦的图像。然而,一些竞争对手(如DIFNet[33]、DeFusion[35]和Tufusion[37])在焦点边界周围表现出模糊的边缘,导致房屋和文本等远处物体模糊不清。相比之下,所提出的方法有效避免了这个问题,并获得了更清晰的边缘信息。此外,MFF-GAN[26]、Fusiondiff[48]和U2Fusion[30]未能保持最佳的强度分布。总之,所提出的方法通过全局上下文融合展示了感知自适应焦点区域并保持适当强度分布的能力。
表13和表14展示了RealMFF数据集[74]和MFI-WHU数据集[26]的客观结果。在表13中,除EN指标外,所提出的方法在其他四个指标上均取得了最佳结果。在表14中,所提出的方法在VIF、QAB/F和FMI指标上具有最佳性能,而在EN和SSIM指标上略低。与其他方法相比,所提出的方法在多焦点图像融合任务中显示出明显优势。
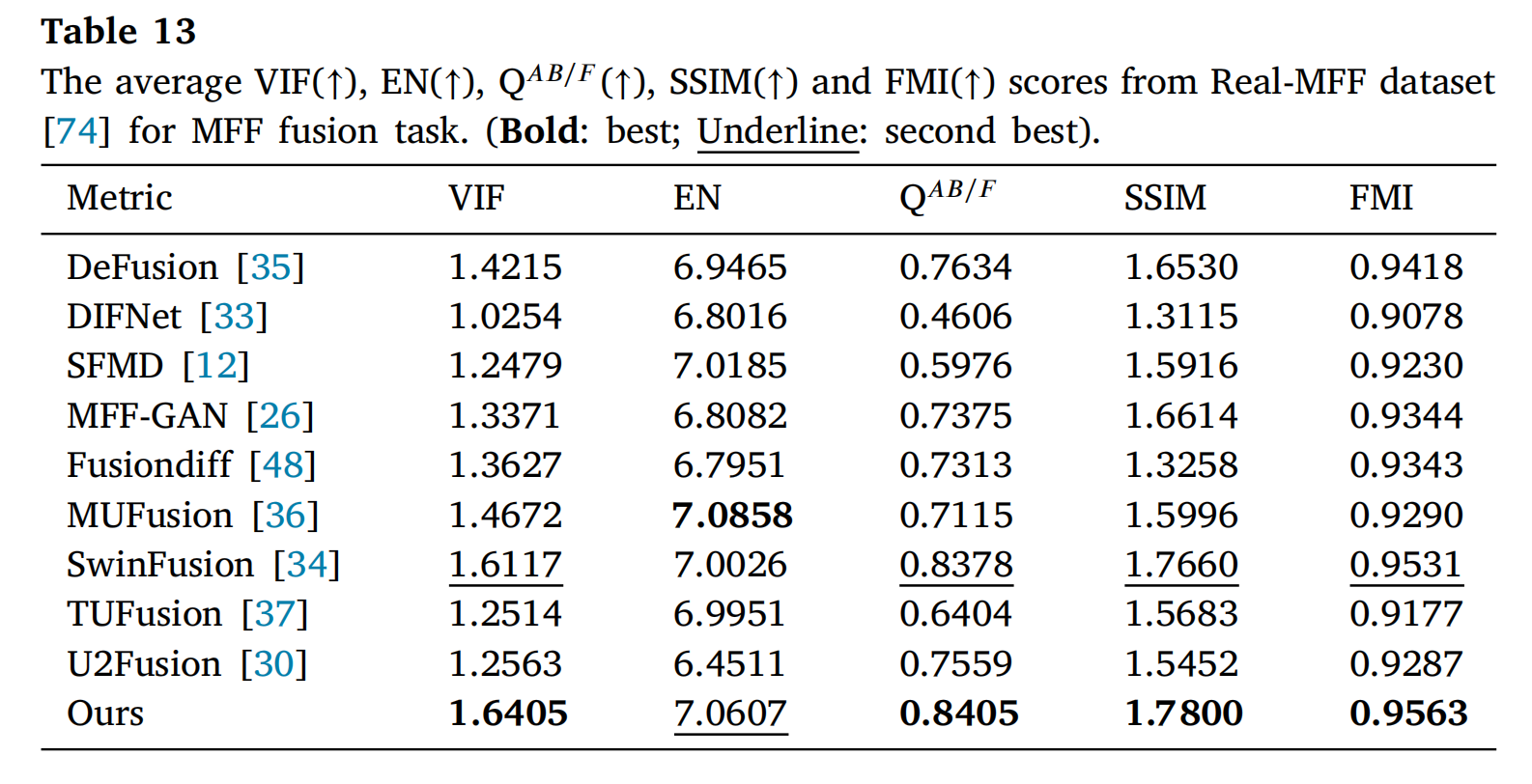
表13: 在Real-MFF数据集[74]上MFF融合任务的平均VIF(↑)、EN(↑)、QAB/F(↑)、SSIM(↑)和FMI(↑)分数。(粗体:最佳;下划线:次佳)
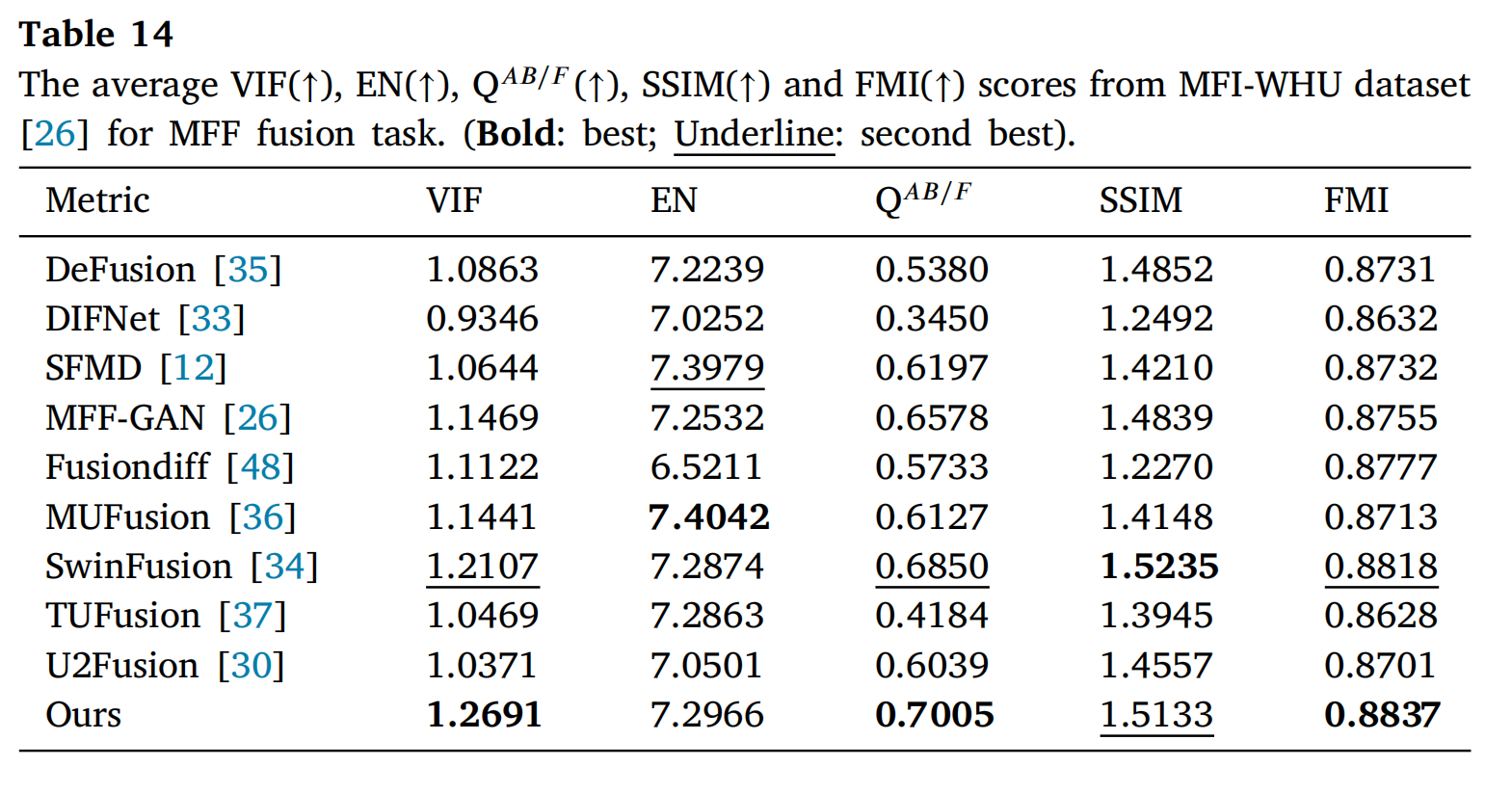
表14: 在MFI-WHU数据集[26]上MFF融合任务的平均VIF(↑)、EN(↑)、QAB/F(↑)、SSIM(↑)和FMI(↑)分数。(粗体:最佳;下划线:次佳)
5.3.2. 多曝光图像融合
图12展示了多曝光图像融合的定性比较。具体来说,IID-MEF[27]和MEF-GAN[24]在融合结果中产生大量伪影,即不自然的颜色和模糊的结构。同时,MUFusion[36]和TUFusion[37]的融合结果倾向于欠曝光图像,导致整体亮度较暗。此外,U2Fusion[30]表现出显著的不稳定性,常常导致过度曝光或曝光不足。SwinFusion[34]和DeFusion[35]未能照亮隐藏在黑暗中的场景信息,导致融合结果缺乏适当的曝光水平。相比之下,所提出的方法有效地合并了源图像中的互补信息,并产生了曝光良好的融合结果。
表15和表16提供了两个数据集的定量结果。表15和表16显示,所提出的方法在四个指标上取得了最优分数:VIF、QAB/F、SSIM和FMI。然而,在两个数据集的EN指标上,它略低于DPE-MEF[28],这主要是因为DPE-MEF[28]包含了一个亮度增强模块来放大欠曝光区域的信息。考虑到这些方面,所提出的方法有效地保留了源图像中的大量边缘,并使它们与人类视觉感知保持一致。
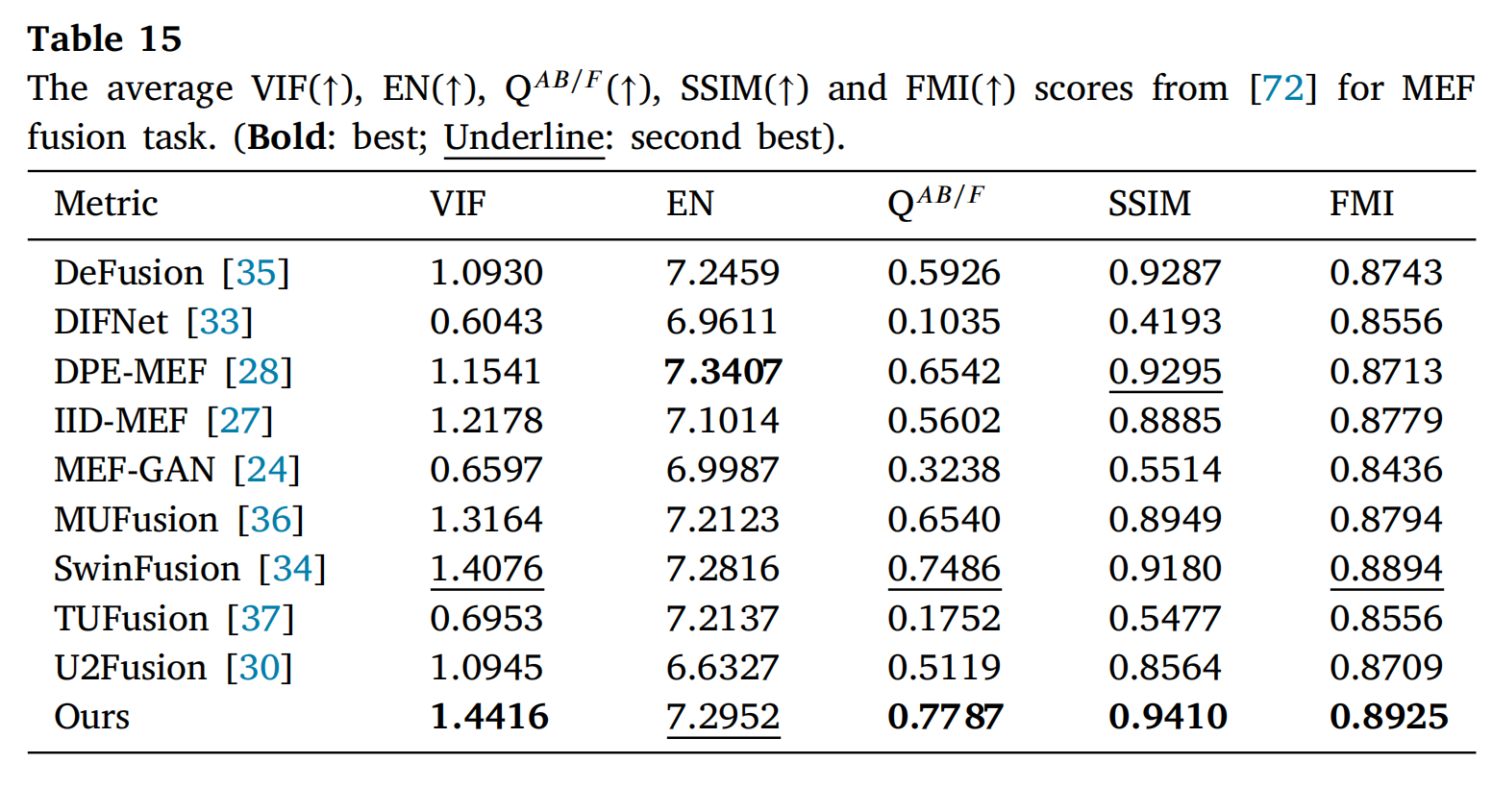
表15: 在[72]数据集上MEF融合任务的平均VIF(↑)、EN(↑)、QAB/F(↑)、SSIM(↑)和FMI(↑)分数。(粗体:最佳;下划线:次佳)
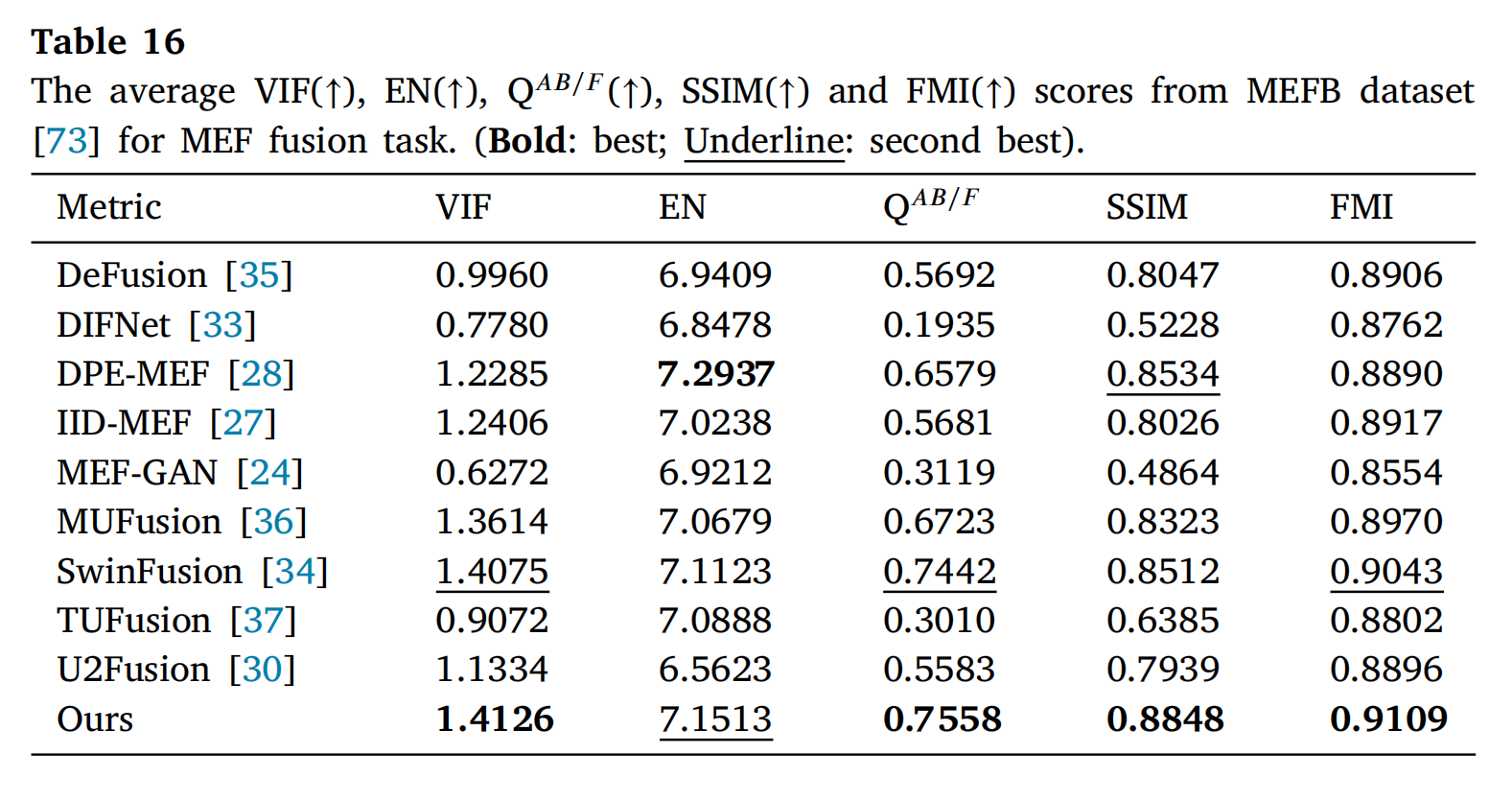
表16: 在MEFB数据集[73]上MEF融合任务的平均VIF(↑)、EN(↑)、QAB/F(↑)、SSIM(↑)和FMI(↑)分数。(粗体:最佳;下划线:次佳)
5.4. 消融研究
LFDT-Fusion的性能依赖于像素空间自编码器和Transformer网络的设计。在本小节中,以多模态图像融合的VI-IR任务和数码摄影图像融合的MEF任务为例,进行了一系列消融研究,以验证各种模块的有效性。
5.4.1. 像素空间自编码器分析
所提出的基于UNet的像素空间自编码器将更丰富的场景细节注入到融合模型中,其关键在于有效整合了原始输入的高分辨率信息。相比之下,使用VAE-GAN作为压缩模型(Pro-I)会导致融合结果出现细节丢失和颜色偏移等问题,如图13©所示。这些问题主要源于融合结果数据分布的变更,导致解码时输出质量较低。
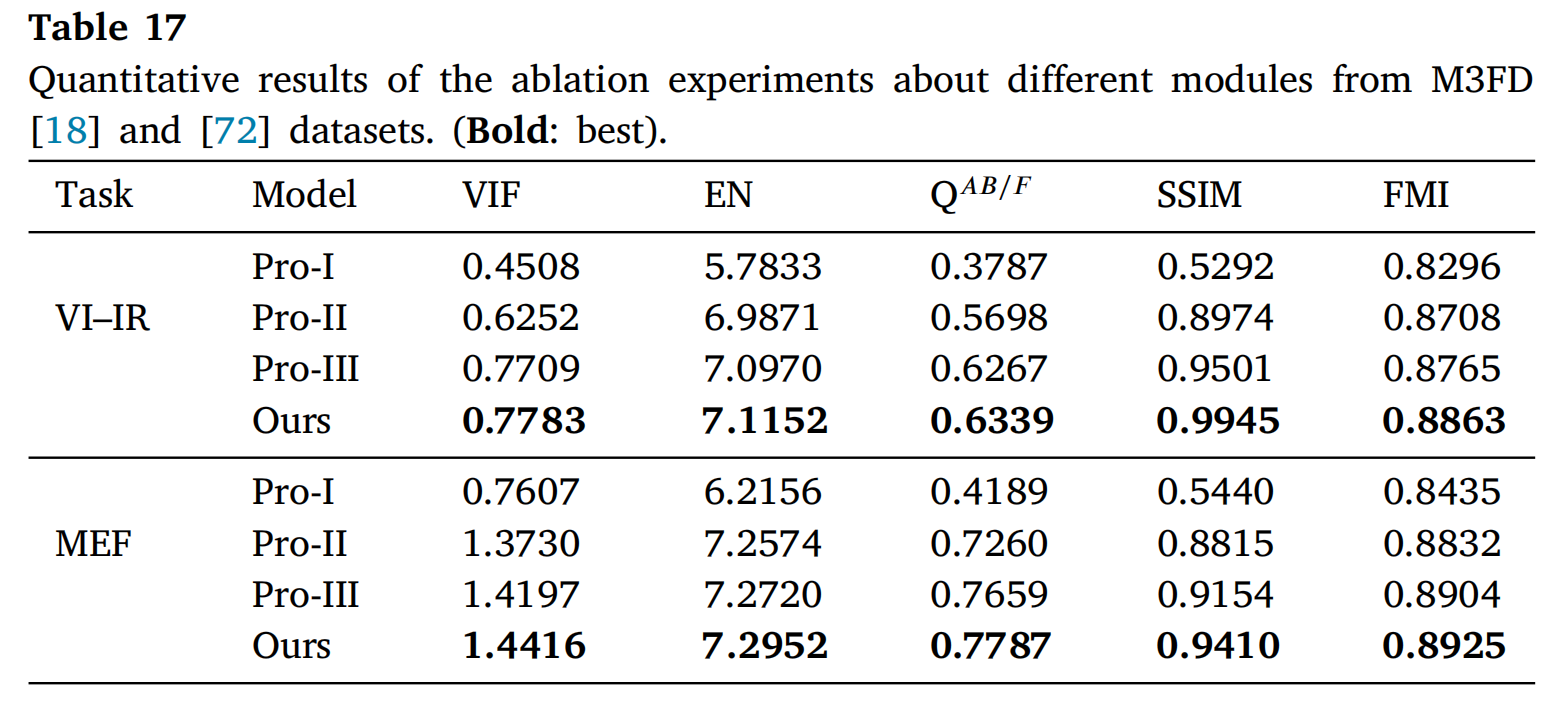
表17展示了与Pro-I方法的定量比较。可以观察到,Pro-I在VIF、QAB/F和SSIM指标上表现明显更差,这表明Pro-I未能有效保留源图像的信息,导致人类视觉感知较差。因此,所提出的自编码器在保留原始细节和提供更准确融合结果方面表现出色。
5.4.2. 扩散模块分析
- 基于Transformer的扩散骨干网络: 基于Transformer的去噪模型采用四阶段编码器-解码器网络,在给定的初始高斯噪声条件下学习远程扩散依赖关系。图13(d)和表17提供了与使用UNet作为扩散骨干网络(Pro-II)的定性和定量比较。图13(d)表明,基于UNet的融合结果在背景中出现伪影,并且未能有效控制融合图像的像素强度。这种现象在多曝光图像融合任务中尤为明显,融合结果无法呈现适当的曝光水平。如表17所示,Pro-II在EN和FMI指标上略差于所提出的方法,但在其他三个指标上明显更差。总之,所提出的方法可以有效地捕获全局信息和像素依赖关系,促进去噪和图像重建过程。
- 跨域融合Transformer模型: 跨域融合Transformer模型由基于交叉注意力的域间融合单元组成,可以充分聚合域内的远程依赖关系和全局交互。将其替换为自注意力(Pro-III)后的可视化结果如图13(e)所示。正如观察到的,替换后的模型无法有效感知全局信息,适当控制像素强度,并自适应地关注突出区域和可见光图像中的背景。此外,表17展示了Pro-III在VI-IR和MEF任务上的定量结果。结果显示,所提出的方法在所有五个指标上都优于Pro-III。
5.4.3. 损失函数分析
为了更好地描述成像场景,采用扩散损失 Ldiff\mathcal{L}_{\text{diff}}Ldiff 和融合损失 Lfusion\mathcal{L}_{\text{fusion}}Lfusion 作为网络的约束。消融研究的定量结果如表18所示。结果表明,移除任何损失约束都会在一定程度上降低融合性能。特别是,当移除融合损失 Lfusion\mathcal{L}_{\text{fusion}}Lfusion 时,在VIF、QAB/F和SSIM等指标上观察到最显著的下降。另一方面,当移除扩散损失 Ldiff\mathcal{L}_{\text{diff}}Ldiff 时,EN指标出现最严重的下降。总体而言,扩散损失倾向于提供更多的场景信息,而融合损失则侧重于整合场景信息。
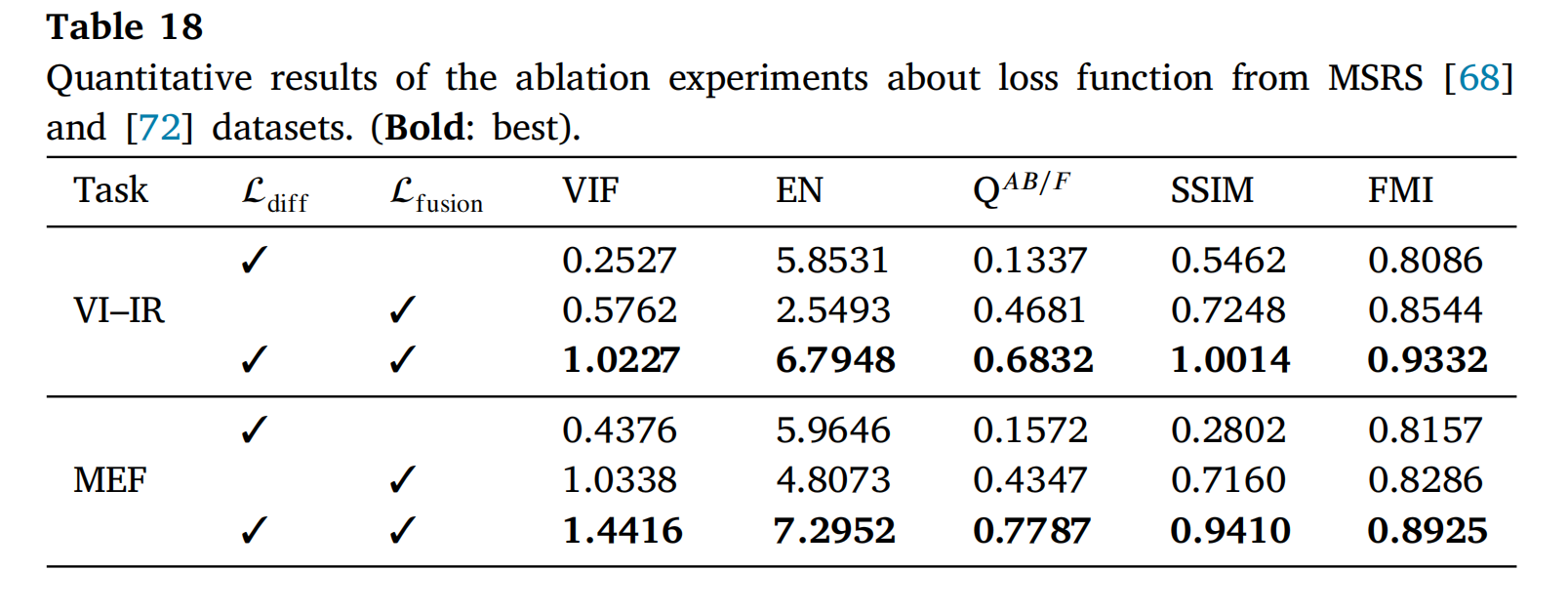
表18: 关于损失函数的消融实验在MSRS[68]和[72]数据集上的定量结果。(粗体:最佳)
5.4.4. 扩散采样器分析
图14和表19展示了六种扩散采样器在MEF任务上的定性和定量结果。在图14的第一行和第三行中,六种采样器生成的融合结果在视觉上非常相似。然而,第二行和第四行中的差异图表明,扩散采样器的小尺度结构和边缘略有不同。这表明扩散采样器不影响融合结果的视觉可见性,但直接影响小尺度纹理结构。例如,与DPM-solver++[66]相比,LMS[38]的结果可能缺乏一些精细细节。如表19所示,DPM-solver++[66]在四个指标上取得了最高分。尽管在SSIM指标上得分低于Deis[64]和DPM-solver[65],但综合考虑所有指标,选择DPM-solver++[66]作为扩散采样器是合理的。
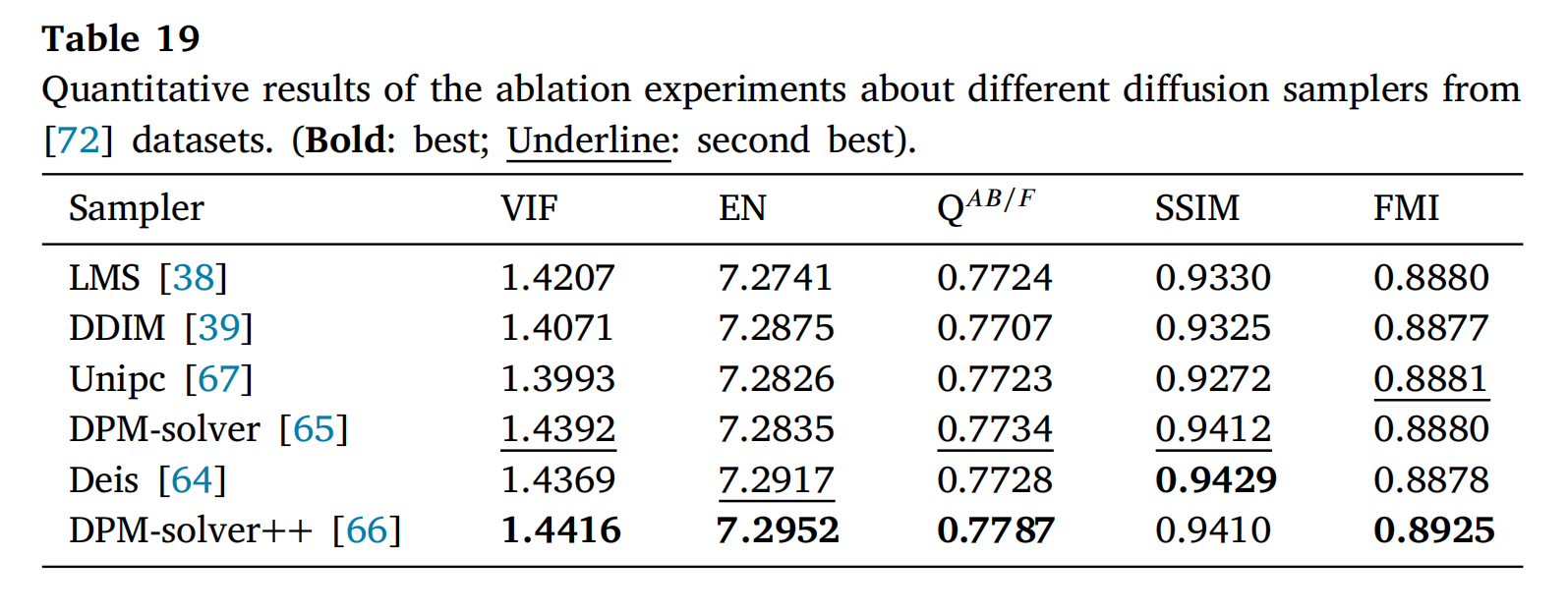
表19: 关于不同扩散采样器的消融实验在[72]数据集上的定量结果。(粗体:最佳;下划线:次佳)
5.5. 应用
5.5.1. 用于目标检测的VI-IR图像融合
图15提供了一些所提出方法用于促进目标检测的示例。采用YOLOv5目标检测方法[84]来检测融合图像中的行人和车辆。SwinFusion[34]和DiF-fusion[46]取得了令人满意的融合结果,但对行人和车辆的检测性能并不理想。DIFNet[33]和DeFusion[35]存在细节丢失问题,使得检测器难以从融合结果中准确识别行人。此外,U2Fusion[30]、MUFusion[36]和DDFM[20]方法表现出颜色偏移,导致检测结果中丢失车辆。尽管CDDFuse[19]在某些情况下可以正确检测大多数行人,但检测的置信度令人担忧。总之,所提出的方法不仅生成了高质量的融合图像,而且展示了令人满意的目标检测性能。
表20提供了MSRS数据集[68]的一些定量比较。具体来说,度量指标包括所有类别的精确率(precision)、召回率(recall)和平均精度均值(mAP)。更高的精确率、召回率和mAP值表示更好的检测性能。mAP@[0.5]表示交并比(IoU)阈值为0.5时的平均精度。mAP@[0.5:0.95]表示IoU阈值从0.5到0.95(步长为0.05)范围内的平均精度。如表20所示,所提出的方法在大多数检测指标上优于其他方法,表明我们的方法能够以更高的精度检测行人和车辆,且误判更少。
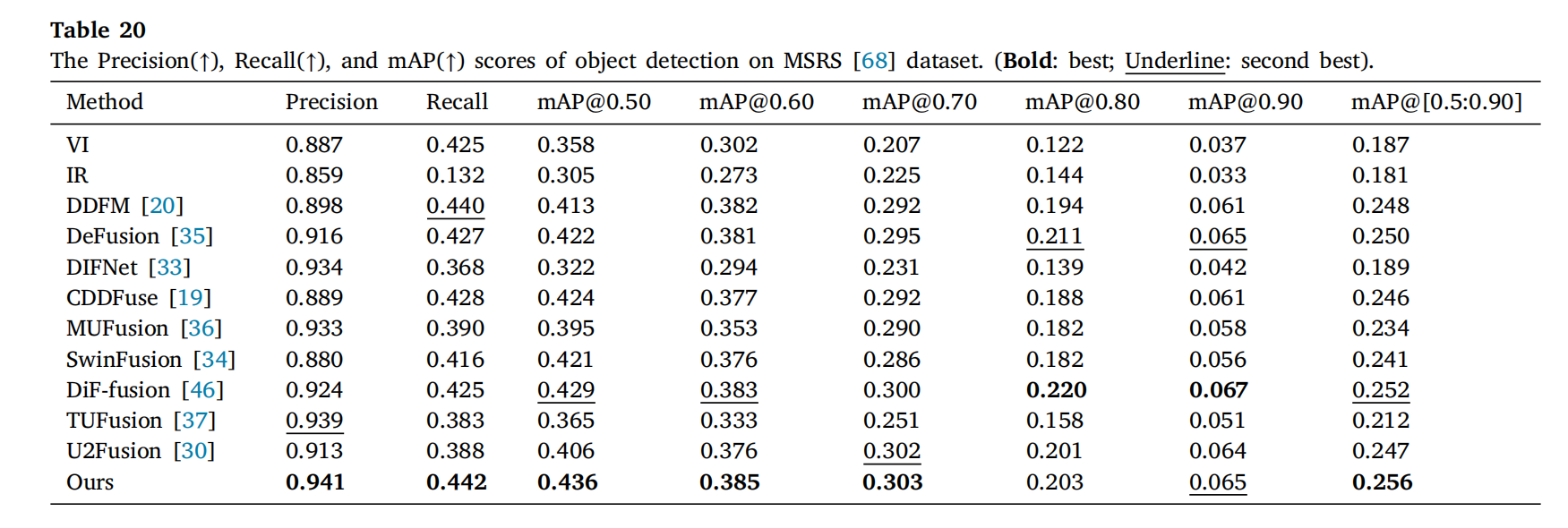
表20: 在MSRS[68]数据集上目标检测的精确率(↑)、召回率(↑)和mAP(↑)分数。(粗体:最佳;下划线:次佳)
5.5.2. 用于图像分割的VI-PIF图像融合
通过融合可见光和偏振图像,减少了表面反射和阴影对图像分割的影响,从而增强了目标与背景之间的区分度,提高了图像分割的准确性。使用[85]中提出的算法对融合结果进行分割,具体结果如图16所示。融合结果的整体对比度和细节特征不可避免地影响图像分割的精度。例如,图16©和(d)中人的头发、图片中的兔子和智能手机屏幕等特征未被有效分割。然而,所提出的方法有效地保留了可见光图像中的场景信息和偏振图像中的偏振信息,从而提高了融合图像中的分割精度。
5.5.3. 用于深度估计的MFF图像融合
多焦点图像可以在不同焦距下为同一场景提供深度信息,从而提供更准确和全面的深度估计结果。图17显示了深度估计结果的可视化。采用ADDS-DepthNet[86]从融合图像中估计高质量密集深度图。如图所示,大多数其他方法未能有效整合场景信息,导致非聚焦区域物体的深度图不准确。相比之下,所提出的方法有效地将场景信息整合到单个全聚焦图像中,并成功地从融合图像中估计出所有物体的密集深度图。
5.5.4. 工业场景中的应用
所提出的方法应用于工业场景中的高质量图像处理。例如,用于融合摇床(shaking table)的闪光/无闪光图像以提取矿物带(MB)信息。摇床[87]是矿业中用于富集高品位矿石的关键设备。在分选过程中,MB信息主要包括分区和轮廓,它能迅速反映工艺条件的变化,并且对于调整控制参数以提高矿石品位至关重要。图18展示了矿石分选中的应用实例。如图所示,所提出的方法产生了具有适当照度的融合结果,并在分割后实现了更高的精度。因此,所提出的方法在工业环境中也表现出优异的泛化能力。
5.6. 计算复杂度分析
表21比较了所提出的方法与基于扩散模型的方法在效率方面的差异。具体来说,使用训练参数(大小)、每秒浮点运算次数(FLOPs)和运行时间(秒)来评估计算效率。使用M3FD[18]数据集中的第一对测试图像计算FLOPs,而使用整个数据集计算运行时间。结果表明,DDFM[20]和Fusiondiff[48]方法处理整个数据集需要更长的运行时间(超过两小时)。原因是这些方法需要20到100个去噪步骤来模拟精确的场景细节。尽管DiF-fusion[46]方法通过采用预训练的扩散模型减少了运行时间,但它在训练和推理过程中也产生了大量的计算资源需求,导致更高的FLOPs。相比之下,所提出的方法在训练参数、FLOPs和运行时间方面实现了更低的成本。
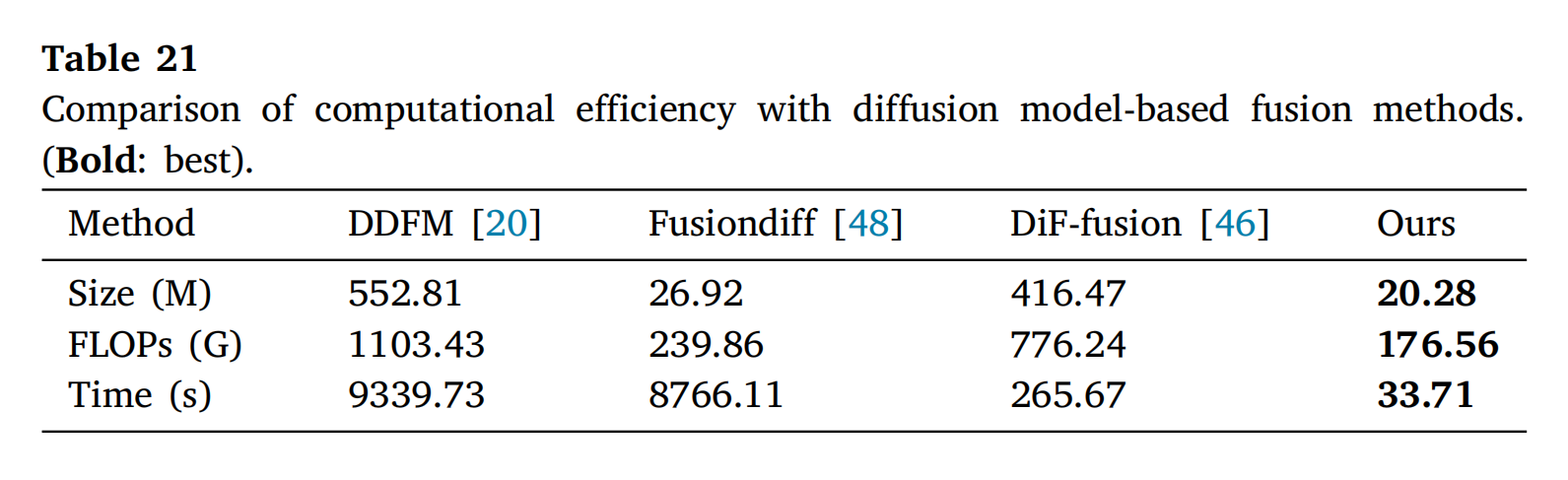
表21: 与基于扩散模型的融合方法的计算效率比较。(粗体:最佳)
表22展示了与六种通用图像融合方法的计算效率比较结果。FLOPs和运行时间的计算方法与表21一致。如表22所示,由于其轻量级网络结构,DIFNet表现出较低的训练参数、FLOPs和运行时间。值得注意的是,尽管我们的方法在训练参数和FLOPs方面并不出色,但它展示了具有竞争力的操作效率。原因是扩散模型在去噪过程中需要高计算成本。我们通过将输入压缩到潜在空间并采用高效的扩散采样器,提高了推理过程中的图像生成速度。然而,仍然需要高昂的计算成本。
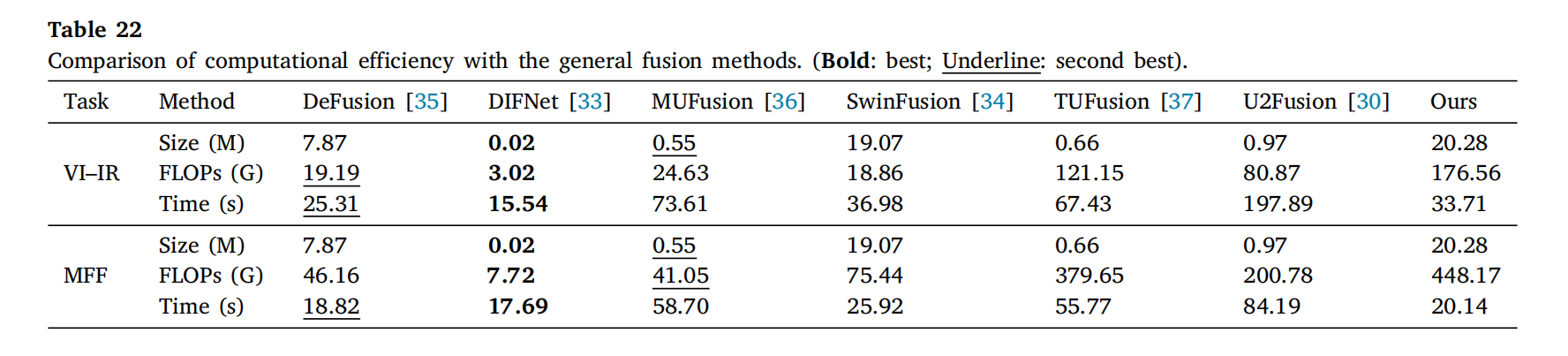
表22: 与通用融合方法的计算效率比较。(粗体:最佳;下划线:次佳)
6. 结论
本文提出了一种基于潜在扩散模型的新型图像融合方法,利用UNet作为像素空间自编码器,并采用基于Transformer的扩散模型来有效学习远程潜在扩散表示,从而实现高质量的图像融合。具体来说,基于UNet的潜在扩散模型将输入压缩到潜在空间,无需依赖对抗优化或需要预训练来适应不同的图像融合任务。基于Transformer的扩散模型提取分层扩散表示,并通过交换来自不同域的潜在特征的查询(queries)、键(keys)和值(values)来实现域间全局特征融合。此外,对扩散模型影响因素的研究表明,当噪声水平为σ=70\sigma=70σ=70、去噪步长为10、且采样器选择DPM-solver++或Deis时,模型可以获得更好的融合性能。在六种图像融合任务上的综合实验表明,所提出的方法在公共数据集的定量和定性方面均优于代表性的图像融合方法。几个具有挑战性的应用,如目标检测、图像分割、深度估计和矿物带信息提取,证明了该框架在高级视觉任务中的潜力。