flash attention2 计算过程的探索和学习
之前初步探索了flash attention相比标准attention性能提升的原因。
https://blog.csdn.net/liliang199/article/details/151789333
这里尝试进一步探索,解析flash attention2相比flash attention的性能提升的原因。
首先了解稳定版softmax、以及基于稳定版softmax的标准attention,然后参考论文,使用公式表示flash attention计算的计算过程,进而引出flash attention2的计算过程。
1 稳定版softmax
考虑到数值过大,指数运算后可能会溢出,针对如下所示的softmax计算过程,一般会减去x中最大元素的值。
处理前后的softmax公式如下
由于是减去x_max后做指数运算,相当于分子和分母同时除以exp(x_max),不改变softmax特性。
2 标准attention
softmax是attention最核心的运算,这里设定seq_len=2,查询Q、键K=[K1, K2]和值V。
针对K1和K2,S1和S2表示如下。
基于稳定版softmax,attention计算过程如下。
3 flash attention
flash attention的计算过程示例如下
如果不考虑减去最大值,flash attention的计算过程如下所示。
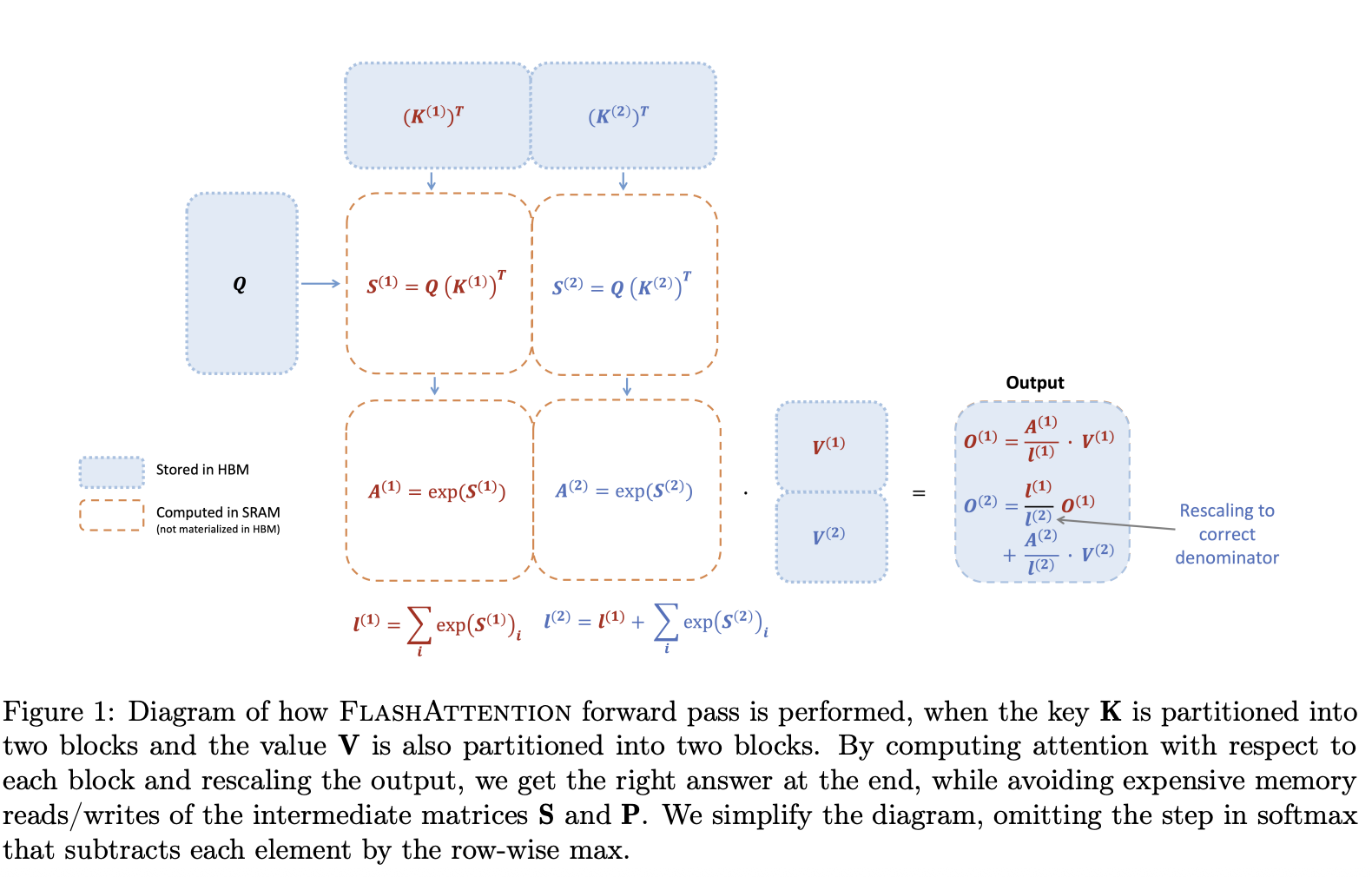
4 flash attention2
flash attention在计算的过程中,每计算一个块,需要使用最新m更新l。
参考softmax公式,l主要是对一化。
flash attention2采用了归一化后移的处理方法,即在计算过程中暂时不做归一化,将其放到最后。
计算过程示例如下。
这种处理方式,有效减少了如此可降低计算复杂程度,减少了中间数据P1的存储需求。
以下是flash attention2的算法示例

附录
1 diag的含义
diag(a,b,c…)表示一个对角矩阵,即除主对角线外的元素都为0,diag有如下特性
示例程序如下
import numpy as np
a = np.arange(1, 4)
diag_a = np.diag(a)
diag_a_reverse = 1 / np.diag(a)
print(f"diag_a: {diag_a}\ndiag_a_reverse: {diag_a_reverse}")输入如下
diag_a: [[1 0 0]
[0 2 0]
[0 0 3]]
diag_a_reverse: [[1. inf inf]
[ inf 0.5 inf]
[ inf inf 0.33333333]]
2 论文1/diag(l1/l2)问题
https://arxiv.org/pdf/2307.08691
flash attention2论文如下所示的公式中1/diag(l1/l2)可能不对,应该为diag(l1/l2),不需要取反。
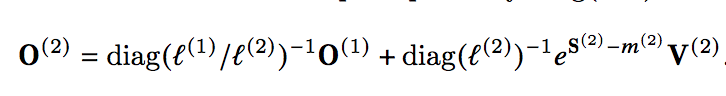
另外,这一步只考虑了分母项的适配,没有考虑分子项的适配,应该还需要乘exp(m1-m2)项。
由于大部分网络资料沿用论文所示公式,所以还需要继续求证。
reference
---
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
https://arxiv.org/pdf/2307.08691
flash attention计算过程的探索和学习
https://blog.csdn.net/liliang199/article/details/151789333
FlashAttention2详解(性能比FlashAttention提升200%)
https://zhuanlan.zhihu.com/p/645376942