数据库回表查询解析:从原理到实战优化
我的原文:技术广场
回表查询是数据库性能优化中一个至关重要且常见的概念,尤其在大型数据量和高并发场景下,理解并优化回表操作能带来显著的性能提升。本文将深入解析回表查询的原理、分析真实案例,并提供切实可行的解决方案。
1. 什么是回表查询?
要理解回表查询,首先需要了解数据库索引的基本结构。以 MySQL InnoDB 引擎为例:
- 聚簇索引(Clustered Index):每个表有且仅有一个聚簇索引(通常是主键),其叶子节点直接存储完整的行数据。数据行实际按聚簇索引的顺序物理存储。
- 二级索引(Secondary Index,或称非聚簇索引):除聚簇索引外的其他索引都是二级索引。其叶子节点仅存储索引字段的值和对应数据行的主键值。
回表查询就是指:当使用二级索引进行查询时,如果所需的数据字段未能完全被该二级索引覆盖(即部分字段不在索引中),数据库引擎就需要先通过二级索引找到对应的主键值,然后再根据这个主键值回到聚簇索引中去查找完整的行数据,以获取其他所需字段的过程。
简单来说,它需要两次索引查找:第一次在二级索引,第二次在聚簇索引,故得名“回表”。
2. 回表查询有何影响?
回表操作对数据库性能的负面影响主要体现在以下几个方面:
- 额外的 I/O 开销:每次回表都意味着至少额外的磁盘寻道和数据页读取(如果目标数据页不在内存缓冲区中)。对于需要回表大量行的查询,这些随机 I/O 操作会急剧增加查询响应时间。
- 增加 CPU 和内存压力:更多的数据页被读入缓冲池(Buffer Pool),可能会挤出其他常用数据,影响整体缓存命中率。同时,处理更多的数据行也需要更多的 CPU 资源。
- 响应延迟:上述因素共同导致查询延迟增加,在高并发场景下,可能成为系统瓶颈。
3. 一个真实的案例:用户查询优化
背景
假设我们有一张用户表 Customer_Customer,包含大量字段,如用户ID、手机号、密码、昵称、状态标识、企业ID等数十个字段。
问题查询
一个非常高频的查询是根据手机号(CKCCPhone)获取用户信息。
SELECT [CKCCId], [CKCCPhone], [CKCCPassword], [CKCCLogo], ... -- 数十个字段
FROM Customer_Customer]
WHERE [CKCCPhone] = '13800138000' AND [CKCCIsDel] = 0 AND [CKCCState] = 1 AND [EnterpriseId] = 0;(注:为保护隐私,手机号已做模糊化处理)
性能瓶颈
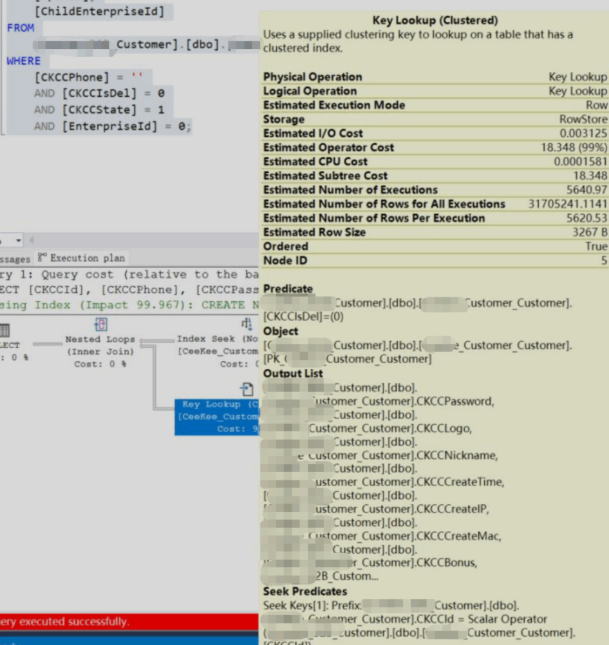
尽管已经在 [CKCCPhone]、[CKCCIsDel]、[CKCCState]上建立了联合索引,但该查询的执行计划显示:
- 索引查找(Index Seek):成本占比 0%,数据库利用联合索引快速定位到了符合条件的行。
- 键查找(Key Lookup):成本占比 99%,为了获取
SELECT子句中要求的数十个未包含在索引中的字段,数据库需要对索引找到的每一行(例如约5600行)执行一次回表操作。
这总计约5600次的回表操作,成为了整个查询的性能瓶颈。
4. 解决方案:如何避免回表查询?
优化回表查询的核心思路是创建覆盖索引(Covering Index) 和优化查询语句。
方案一:创建覆盖索引(推荐)
覆盖索引是指一个索引包含了查询所需要的所有字段(包括 WHERE子句中的条件和 SELECT子句中需要返回的字段)。这样,数据库引擎只需扫描索引就能获得全部所需数据,无需回表。
针对上述案例,可以创建如下索引:
CREATE NONCLUSTERED INDEX [IX_Customer_Covering]
ON [dbo].[CeeKee_Customer_Customer]
([CKCCPhone], [CKCCIsDel], [CKCCState],[EnterpriseId] -- 查询条件中涉及的字段放在键列
)
INCLUDE
([CKCCId], [CKCCPassword], [CKCCLogo],[CKCCNickname],... -- 将SELECT中需要返回的其他所有字段都放入INCLUDE子句
)优点:
- 性能提升巨大:彻底消除回表操作,查询速度可能有数量级的提升。
- 一劳永逸:对于该特定查询,性能优化到极致。
缺点:
- 索引体积更大:因为包含了非常多的字段,会占用更多的磁盘空间。
- 写操作开销增加:每次
INSERT、UPDATE、DELETE操作时,维护这个大型索引的代价更高。
方案二:精简查询字段(性价比高)
如果业务上并非真的需要返回所有字段,应严格遵循“只取所需”的原则。
优化后的查询:
-- 假设业务场景其实只需要手机号、昵称和头像
SELECT [CKCCId], [CKCCPhone], [CKCCNickname], [CKCCLogo]
FROM [CeeKee_Customer_Customer]
WHERE [CKCCPhone] = '13800138000' AND [CKCCIsDel] = 0 AND [CKCCState] = 1 AND [EnterpriseId] = 0;然后,可以创建一个只覆盖这些字段的、更轻量的覆盖索引:
CREATE NONCLUSTERED INDEX [IX_Customer_Covering_Light]
ON [dbo].[CeeKee_Customer_Customer]
([CKCCPhone], [CKCCIsDel], [CKCCState],[EnterpriseId]
)
INCLUDE
([CKCCId], [CKCCNickname], [CKCCLogo] -- 只包含真正需要的字段
)优点:
- 显著减少回表:即使不能完全覆盖,需要回表的数据量也大大减少。
- 索引更小,维护开销更低。
- 网络传输量更小,对应用程序也有好处。
缺点:
- 如果业务确实需要返回大量字段,此方法不适用。
方案对比与选择
| 特性 | 创建覆盖索引 | 精简查询字段 |
|---|---|---|
| 性能提升 | 极致,彻底消除回表 | 显著,大幅减少回表或网络传输 |
| 适用场景 | 高频、核心、且需返回多字段的查询 | 业务允许只返回部分字段 |
| 存储开销 | 较大 | 较小 |
| 写操作开销 | 较高 | 较低 |
| 推荐度 | ⭐⭐⭐⭐⭐ (针对核心接口) | ⭐⭐⭐⭐ (首选检查项) |
决策建议:
- 首先检查:是否真的需要
SELECT *?精简字段永远是第一步,也是最经济有效的优化。 - 必要时创建:如果所有字段都必需,且该查询是高频核心接口,那么创建覆盖索引是带来最大性能收益的方案,即使付出一些存储代价也是值得的。
5. 如何诊断回表查询?
在日常开发中,如何快速判断一个查询是否发生了回表?
- 使用
EXPLAIN分析执行计划(MySQL 或 PostgreSQL):- 如果
Extra字段中出现 Using index condition 或 Using where ,通常意味着在索引查找后可能需要进行回表。 - 理想情况下,使用覆盖索引时,
Extra字段会显示 Using index ,这表示所有数据都可以从索引中获取,没有回表。
- 如果
- 关注
TYPE列:如果type为ref或range(表示使用了二级索引),但并未出现Using index,则很可能需要回表。
总结
回表查询是一个常见的数据库性能杀手,但其优化思路非常明确:创建覆盖索引和精简查询字段。
- 理解原理:回表是由于二级索引不包含所需全部数据,需绕道聚簇索引获取,引发额外I/O。
- 诊断问题:善用
EXPLAIN命令查看执行计划,识别键查找(Key Lookup)操作。 - 优先精简:永远避免使用
SELECT *,只获取业务真正需要的字段。 - 终极方案:为最核心、最频繁且需返回多字段的查询创建覆盖索引,虽然会增加存储开销,但能换来极致的查询性能。
数据库优化是一种权衡艺术,总是在读取性能、写入性能、存储空间之间做出取舍。理解了回表,你就能更好地做出这些决策,从而设计出更高效、更稳定的数据库应用。
