【论文阅读】Long-VLA:释放视觉语言动作模型在机器人操作中的长时程能力
Long-VLA引入了第一个专为长程机器人操作设计的端到端视觉-语言-动作(VLA)模型,采用相位感知输入遮罩策略来调整感知焦点。该模型显著提高了在模拟和真实世界环境中多步骤任务的成功率,优于现有最先进的方法。
问题陈述与背景
视觉-语言-动作(VLA)模型已成为机器人策略学习的强大范式,它利用大规模多模态数据来开发鲁棒且可扩展的控制系统。然而,当前的VLA框架面临一个显著的局限性:它们主要擅长涉及简单、有限步骤操作的短时任务。这一限制严重阻碍了它们在需要复杂、多步骤顺序操作的真实世界场景中的应用。
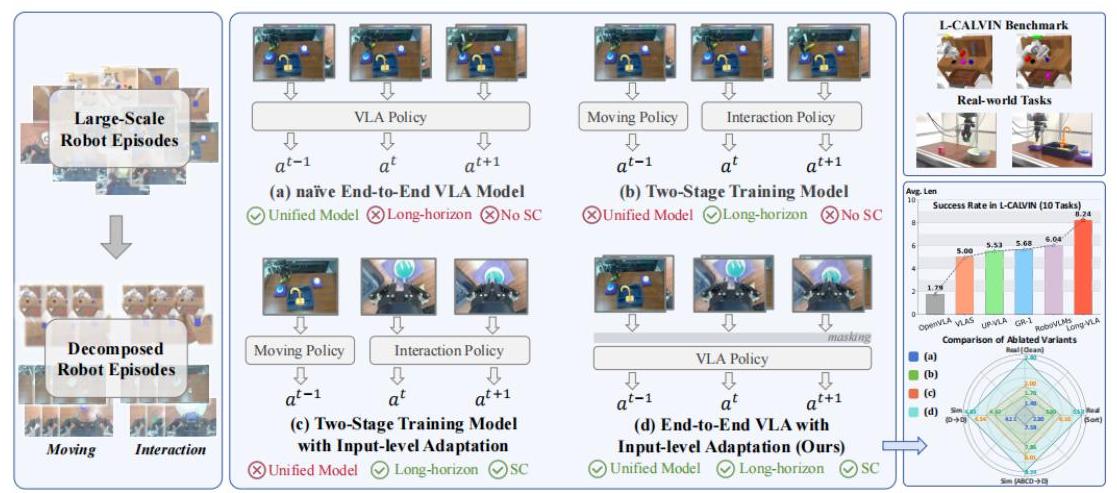
图1:Long-VLA 方法论概述,展示了从大规模机器人片段到分解,再到具有阶段感知输入掩码的统一端到端模型的演变,以及在L-CALVIN基准测试和真实世界任务上的评估结果。
根本挑战在于解决“技能链问题”——在长时操作中管理子任务之间的转换和依赖关系的困难。当机器人尝试执行一系列动作时,错误可能在子任务之间传播并动态耦合,导致连锁故障。解决长时任务的传统方法通常涉及将复杂操作分解为由单独策略管理的更简单的子任务,但这与VLA模型统一的、数据驱动的训练范式产生不兼容。
核心方法论
Long-VLA引入了一种系统性方法,旨在实现长时能力,同时保留VLA模型的可扩展性和数据效率。该方法论围绕三个关键创新:阶段感知分解、通过掩码进行输入级别适应以及统一的端到端训练。
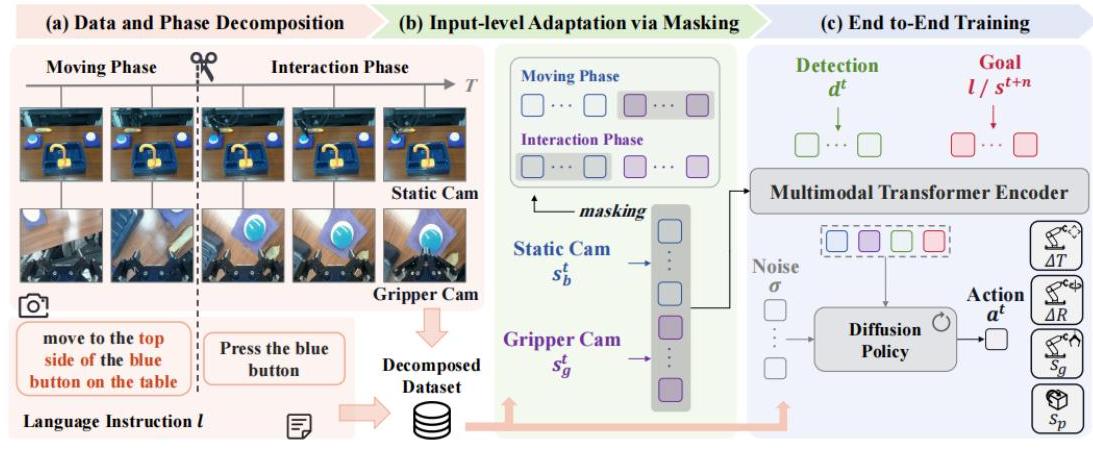
图2:Long-VLA 架构,展示了 (a) 具有移动和交互阶段语言指令的数据和阶段分解,(b) 通过掩码机制进行输入级别适应,以及 (c) 使用多模态Transformer编码器和基于扩散的动作解码器进行的端到端训练。
阶段感知任务分解
作者将每个子任务分解为两个不同的阶段:
- 移动阶段:机器人导航到目标物体,其中第三人称摄像机视图提供最佳的空间感知
- 交互阶段:进行精确操作,其中抓手摄像机视图对于精确控制至关重要
这种分解通过识别机器人轨迹中的“切割点”(通常在物体状态变化前10-15帧)并将动作表示与阶段标识符进行扩充来形式化:
$$
s_{ph} = \begin{cases} -1 & \text{用于移动阶段} \\ 1 & \text{用于交互阶段} \end{cases}
$$
通过掩码进行输入级别适应
Long-VLA没有为每个阶段训练单独的模型,而是采用阶段感知输入掩码策略。这种机制为输入标记分配二进制掩码 $m \in \{0,1\}$,其中只有 $m_i=1$ 的标记参与注意力计算。这使得模型能够:
- 在移动阶段专注于第三人称视图以实现更好的导航
- 在交互阶段强调抓手摄像机输入以实现精确操作
- 保持统一训练,同时动态适应感知
统一训练框架
整个系统使用条件扩散模型进行动作生成,并使用组合损失函数进行训练:
$$
L = L_{diff} + \alpha L_{goal}
$$
其中 $L_{diff}$ 表示动作预测的扩散损失,$L_{goal}$ 是一个InfoNCE损失,确保视觉目标和语言指令之间的语义一致性。
该架构集成了:
- 用于视觉观察的 ResNet-18 编码器
- 基于 CLIP 的目标编码
- 带有 LoRA 微调的 Grounding DINO 用于物体检测
- 用于多模态处理的 GPT-2 风格 Transformer
- 基于扩散的动作解码器
L-CALVIN 基准测试
为了能够严格评估长时程性能,作者们引入了L-CALVIN,这是一个扩展基准,将任务序列长度从5步增加到10步,同时去除了基于类别的限制。这个基准提供了更多样化和具有挑战性的评估场景,能更好地反映现实世界的复杂性。

图3:L-CALVIN基准中10步任务序列的示例,展示了长时程操作任务的复杂性和多样性,每个子任务都被分解为移动和交互阶段。
实验结果
模拟性能
在L-CALVIN基准上,Long-VLA相较于基线方法展现出显著的改进:
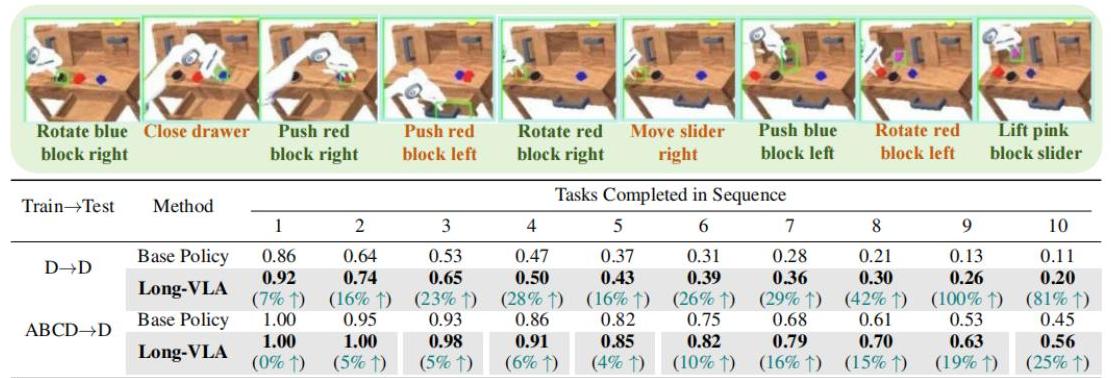
图4:L-CALVIN上的量化结果显示,Long-VLA在不同任务长度下表现出色,在较长的序列上改进尤为显著。
- D→D分割:平均任务长度为4.75,而基础策略为4.11
- ABCD→D分割:平均任务长度为8.24,而基线方法达到5.00-6.04
- 随着序列长度的增加,性能增益变得更加明显
真实世界验证
Long-VLA使用Universal Robots UR5e机械臂在两个真实世界任务上进行了测试:
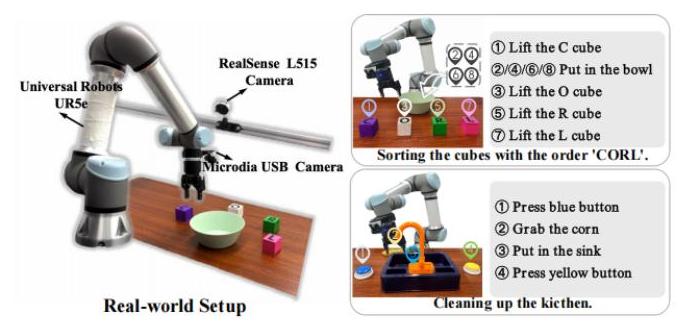
图5:真实世界实验设置,显示了用于分类和清洁场景的机器人平台和任务配置。
分类任务(8步):按特定顺序整理彩色立方体
- 基础策略在第7步后成功率降至零
- Long-VLA在所有8步中保持约25%的成功率
厨房清洁任务(4步):在杂乱环境中进行复杂操作
- 在视觉干扰下:Long-VLA在最后一步的成功率提高了266%
- 证明了对环境变化的鲁棒性
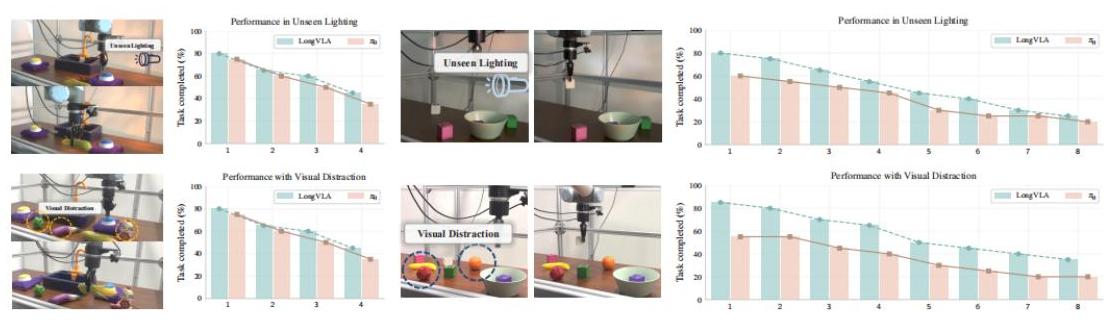
图6:真实世界性能比较,显示Long-VLA在包括未见过光照和视觉干扰在内的各种挑战条件下具有卓越的鲁棒性。
消融分析
作者进行了全面的消融研究,验证了每个组件:
- 分解策略:平均任务长度提高了7.5%
- 输入级适应:通过阶段特定注意力额外提高了7.7%
- 带掩码的统一训练:结合两种方法的优点,实现最佳性能
值得注意的是,使用可学习掩码的实验表明,模型在移动阶段自然学会激活第三人称视角,在交互阶段激活第一人称视角,验证了设计直觉。
意义和影响
Long-VLA通过使VLA模型能够有效处理复杂的多步操作,解决了当前机器人系统中的一个根本限制。主要贡献包括:
首个端到端长时程VLA模型:证明了统一训练可以有效处理序列任务而不牺牲VLA的优势
架构无关解决方案:基于掩码的方法可以集成到现有的VLA框架中,确保广泛适用性
系统评估框架:L-CALVIN为未来的长时程研究提供了严格的基准
真实世界验证:证明了在挑战条件下具有实际适用性和显著的性能改进
这项工作为长周期机器人操纵建立了一个新范式,表明阶段感知适应可以解决技能链问题,同时保持了使VLA模型具有吸引力的可扩展性和数据效率。这一进展使机器人系统更接近于处理在非结构化环境中实际部署所需的复杂、序列化任务。