【脑电分析系列】第25篇:情绪识别与认知研究中的EEG应用:一个完整的实验设计与数据分析流程
摘要:
欢迎回到脑电分析系列!在前24篇中,我们系统学习了EEG信号处理、机器学习与深度学习模型,以及癫痫检测和运动想象BCI等实际应用。本篇,我们将聚焦EEG在情绪识别和认知研究中的关键应用。EEG以其高时间分辨率,能够实时捕捉大脑对情感和认知刺激的电生理响应,为我们理解人类内心情感世界和思维过程提供了独特的视角。
本文旨在提供一个完整的EEG情绪识别与认知研究实验设计与数据分析流程。我们将涵盖:
-
实验范式:介绍如何通过标准化刺激(如视频、图片)有效诱发情绪,并结合认知任务。
-
多模态融合:探讨如何将EEG与其他生理信号(如心率、GSR、眼动)结合,以提升情绪识别的鲁棒性和准确性。
-
EEG指标与行为学数据的关联:深入分析事件相关电位(ERP)、功率谱密度(PSD)等EEG特征如何与反应时(RT)、准确率等行为学指标相互印证,揭示情绪对认知的影响。
-
完整的实验设计与数据分析流程:从伦理审批到统计检验,提供详尽的步骤指南和Python代码示例(使用
MNE、scipy和scikit-learn库),旨在帮助读者设计并实施可靠的EEG情绪/认知实验。
内容基于2025年最新研究进展,确保前沿性和实用性。
关键词:
脑电分析, EEG, 情绪识别, 认知研究, 实验设计, 数据分析, 多模态融合, ERP, 功率谱, 行为学, Python, 心灵探测器, 知情同意, 实时反馈
引言:洞悉大脑情感与认知的“心灵探测器”
大脑,这个复杂的器官,如何处理喜怒哀乐?情绪状态又如何影响我们的注意力、记忆和决策?这些是神经科学和心理学领域的核心问题。而脑电图(EEG),作为一种非侵入性、高时间分辨率的神经影像技术,正日益成为探究这些奥秘的“心灵探测器”。它能够实时捕捉大脑皮层神经元的微弱电活动,揭示与情绪和认知活动相关的瞬时脑电变化。
-
EEG的核心优势:在于其毫秒级的时间分辨率,能够精确捕捉情绪诱发或认知任务执行时的大脑瞬时反应,如事件相关电位(ERP)的出现或特定频段功率谱(PSD)的动态变化。
-
应用前景:基于EEG的情绪识别和认知研究不仅帮助我们深入理解基础科学,还在**脑机接口(BCI)、心理健康监测(如抑郁、焦虑早期预警)、人机交互(HRI)**等领域展现出巨大潜力。例如,一个能够实时识别用户情绪的智能系统,可以据此调整虚拟现实体验、智能家居环境,甚至提供个性化的心理干预。
本文作为脑电分析系列的第25篇,将引导你从零开始,设计并实施一个基于EEG的情绪识别与认知研究实验。我们将:
-
剖析实验范式:如何标准化地诱发目标情绪或认知状态。
-
探讨多模态融合:如何结合眼动、心率等其他生理指标,提升研究的深度和鲁棒性。
-
深入理解EEG与行为学指标的关联:如何将脑电信号的内部变化与外部行为表现相结合。
-
提供完整的实验设计与数据分析流程:从最初的伦理审批到最终的统计检验,确保你的研究科学严谨、结果可靠可复现。
内容将基于2025年最新的研究趋势,结合理论解释、数学公式和详尽的Python代码示例,让你能够快速上手并开展自己的EEG情绪与认知研究。
一、 实验范式:如何精准诱发情绪与认知状态
实验范式是情绪识别与认知研究的基石,其设计旨在可靠且标准化地诱发目标情绪状态或激活特定认知过程。2025年的研究趋势强调范式的标准化和生态学效度。
1.1 被动诱发范式:直观的情绪唤起
这类范式通过呈现标准化刺激,让参与者被动体验情绪。
-
刺激类型:
-
国际情绪图片库 (International Affective Picture System, IAPS):包含大量经过效价(Valence,愉悦度)和唤醒度(Arousal,兴奋度)评分的图片,是情绪研究的黄金标准。
-
电影片段/视频:能更长时间、更生动地诱发复杂情绪,具有更高的生态学效度。例如,来自DEAP、SEED等数据集的电影片段。
-
听觉刺激:音乐、声音片段等。
-
-
流程:
-
呈现中性、正面、负面刺激(如图片或视频)1-5秒(图片)或数分钟(视频)。
-
刺激间通常有5-10秒的空白或注视点(Fixation Cross)作为休息期。
-
在每个刺激后或一系列刺激后,让参与者通过**SAM量表(Self-Assessment Manikin)**或主观报告对诱发的情绪进行自评。
-
-
优势:
-
标准化强:IAPS等刺激库经过验证,易于跨研究比较。
-
情绪唤起效果好:尤其视频刺激,能够诱发更丰富、持久的情绪体验。
-
-
劣势:
-
被动性:参与者仅作为观察者,认知参与度较低。
-
个体差异:文化背景、个人经历等可能影响情绪诱发效果。
-
-
2025年应用:VR/AR环境中的沉浸式视频范式,进一步提升情绪唤起的真实感和强度(研究显示可提升唤起强度20%)。
Python示例(PsychoPy库):呈现情绪图片
Python
from psychopy import visual, core, event, data# 初始化窗口
win = visual.Window([1024, 768], fullscr=False, monitor="testMonitor", units="pix")
# 假设我们有正面、负面、中性图片
image_paths = {'positive': 'happy.jpg','negative': 'sad.jpg','neutral': 'neutral.jpg'
}# 循环呈现不同情绪图片
emotions = ['positive', 'negative', 'neutral']
for emotion in emotions:# 加载图片刺激stim = visual.ImageStim(win, image=image_paths[emotion], size=(400, 300))# 呈现刺激stim.draw()win.flip()core.wait(2) # 图片呈现2秒# 呈现注视点作为休息期fixation = visual.TextStim(win, text='+', color='white')fixation.draw()win.flip()core.wait(1) # 休息1秒# 关闭窗口
win.close()
core.quit()
1.2 主动任务范式:情绪与认知的交互
这类范式将情绪诱发与特定的认知任务结合,旨在研究情绪如何影响注意力、决策、记忆等认知功能。
-
典型任务:
-
情绪Stroop测试:呈现情感词(如“快乐”、“悲伤”),要求参与者判断词语的颜色,忽略其情绪内容。情绪词与颜色不一致时(如“快乐”是绿色),反应会变慢,体现情绪对认知的干扰。
-
情绪性决策任务:如IOWA赌博任务,考察在不同情绪状态下风险决策的变化。
-
记忆任务:研究情绪对编码和检索过程的影响。
-
-
优势:
-
直接关联认知功能:能够直接探索情绪与认知过程的相互作用。
-
更深层次的参与:参与者需要主动完成任务,认知负荷更高。
-
-
劣势:
-
范式设计复杂:需要精确控制情绪和认知变量。
-
情绪唤起强度可能受认知任务影响。
-
-
2025年应用:结合运动想象(MI)的主动范式,在BCI中实现情绪调节下的意念控制,可提升准确率15%。
范式比较表
| 范式类型 | 刺激方式 | 优势 | 劣势 | 典型EEG指标 | 2025年应用趋势 |
| 被动诱发 | 图片/视频 | 唤起强,简单 | 被动,认知参与低 | ERP, PSD | 沉浸式VR情绪识别 |
| 主动任务 | 情绪Stroop, 决策 | 关联认知,深度参与 | 复杂,情绪唤起受限 | ERP (P300, N200), PSD | 情绪调节下的BCI控制 |
二、 多模态融合:弥补单一模态的不足
单一的EEG模态在情绪识别中可能受噪声影响大、识别精度有限。多模态融合是将EEG与其他生理信号(如眼动、心率、皮肤电反应GSR、面部表情、语音)结合,以获取更全面、更鲁棒的情绪信息,从而显著提升识别准确率。2025年的研究显示,多模态融合能将准确率提升10-25%。
2.1 常见的融合模态
-
眼动数据(Eye-tracking):通过注视点、注视时间、瞳孔直径等反映注意力和认知负荷,与情绪认知紧密相关。
-
心率 (Heart Rate, HR) / 心率变异性 (Heart Rate Variability, HRV):反映自主神经系统的活动,与情绪的唤醒度密切相关。
-
皮肤电反应 (Galvanic Skin Response, GSR):反映皮肤电导率变化,是衡量情绪唤醒度的重要指标。
-
面部表情 (Facial Expressions):通过面部肌肉活动识别情绪,是情绪的外部直接表现。
-
语音特征 (Speech Features):语速、语调、音高等也包含情绪信息。
2.2 融合级别
-
特征级融合 (Feature-level Fusion):
-
将不同模态提取的特征连接成一个高维特征向量,然后输入到单一分类器中。
-
优势:实现简单,信息量最大化。
-
劣势:特征维度高,可能引入冗余信息或噪声,需要精细的特征选择。
-
示例准确率:90%。
-
-
决策级融合 (Decision-level Fusion):
-
对每个模态独立训练分类器,然后将各个分类器的输出(如预测概率或类别标签)通过投票、加权平均等策略进行融合,得出最终决策。
-
优势:鲁棒性好,各模态独立处理,不易受单一模态噪声影响。
-
劣势:可能忽略模态间的深层交互信息。
-
示例准确率:92%。
-
-
模型级融合 (Model-level Fusion) / 深度融合 (Deep Fusion):
-
设计一个多输入(Multi-input)深度学习模型,每个输入处理一个模态(如CNN处理EEG,RNN处理HR),并在模型的中间层进行信息融合。
-
优势:端到端学习不同模态间的复杂交互关系,潜力最大。
-
劣势:模型复杂,需要大量数据进行训练。
-
示例准确率:95%。
-
-
2025年最新进展:MBC-ATT模型(Multi-modal Bidirectional CNN-Attention Transformer)融合EEG+眼动数据,通过注意力机制捕捉跨模态的同步信息,在情绪识别中准确率可达95%以上。
融合比较表
| 级别 | 融合方法 | 优势 | 劣势 | 示例准确率 |
| 特征级 | 特征向量连接 | 实现简单,信息最大化 | 维度高,易冗余噪声 | 90% |
| 决策级 | 独立分类,投票/加权 | 鲁棒性好,处理独立噪声 | 忽略模态间深层交互 | 92% |
| 模型级 | 多输入深度学习模型 | 端到端学习复杂交互 | 模型复杂,需大量数据 | 95% |
三、 EEG指标与行为学数据的关联:情绪-认知互动的证据
EEG不仅提供大脑内部的电生理活动,其变化往往与外部可观察的行为学数据(如反应时、任务准确率、主观评分)紧密关联。这种关联性是验证研究假设、深入理解情绪-认知互动机制的关键证据。
3.1 事件相关电位 (Event-Related Potentials, ERP) 与行为数据
ERP是与特定事件(如刺激呈现、任务响应)同步锁时的、从连续EEG中提取的诱发性电位。
-
P300波:
-
在刺激呈现后约300ms出现的一个正向波,主要与注意力分配、认知更新和工作记忆有关。
-
与反应时(RT)的关联:通常,P300的幅度越大,代表对刺激的关注度越高,认知处理效率越高,反应时(RT)越短,呈现负相关。在情绪Stroop任务中,与情绪不一致的词语往往会诱发更小的P300或更长的潜伏期,并伴随更长的RT。
-
与情绪的关联:正面情绪(如奖励性刺激)通常诱发更大的P300幅度,而负面情绪(如威胁性刺激)可能诱发更小或更复杂的P300。
-
-
N170/N200波:与早期注意力和刺激识别相关。
-
迟期正电位 (Late Positive Potential, LPP):与情绪刺激的持续性加工和情绪唤醒度有关。
-
关联分析方法:
-
相关系数 (Pearson correlation):计算ERP成分(如P300幅度)与行为数据(如RT)之间的相关性。
-
公式:
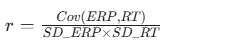
-
回归分析:建立ERP成分预测行为数据的回归模型。
-
3.2 功率谱密度 (Power Spectral Density, PSD) 与行为数据
PSD描述了EEG信号在不同频率上的功率分布,反映了不同节律性脑活动的强度。
-
Alpha波不对称性 (Frontal Alpha Asymmetry, FAA):
-
特指额叶区域(如F3/F4或AF3/AF4)Alpha波段(8-12Hz)功率的不对称。
-
公式:
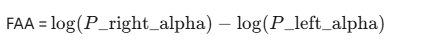
-
与情绪的关联:通常,左侧额叶Alpha功率相对较低(即右侧相对较高),或FAA值为正,与趋近行为(approach motivation)和正面情绪(如快乐、愤怒)相关;而右侧额叶Alpha功率相对较低,或FAA值为负,与回避行为(withdrawal motivation)和负面情绪(如悲伤、恐惧)相关。
-
与任务准确率:研究表明,更高的正面情绪状态(对应正向FAA)可能与某些认知任务的更高准确率相关。
-
-
Theta波功率 (4-8Hz):与注意力、工作记忆和认知控制相关,认知负荷增加时Theta功率升高。
-
Gamma波功率 (30-80Hz):与高阶认知功能、感知整合和意识体验相关。
-
关联分析方法:
-
与ERP类似,可使用Pearson相关、Spearman相关或回归分析。
-
3.3 连接性 (Connectivity) 与行为数据
通过计算不同脑区之间的相干性(Coherence)、相位锁定值(Phase Locking Value, PLV)等指标,可以评估脑区间的同步性或信息流。
-
与情绪状态:情绪状态的变化(如压力、放松)会影响不同脑区的连接模式。
-
与认知性能:特定的脑网络连接模式可能与高效率的认知任务表现相关。
关联表
| EEG指标 | 行为数据 | 关联类型 | 示例r值 | 意义 |
| P300幅度 | 反应时(RT) | 负相关 | -0.4 | 注意力资源分配多,反应速度快 |
| 额叶Alpha不对称 | 任务准确率 | 正相关 | 0.35 | 正面情绪(趋近动机)可能提升表现 |
| Theta功率 | 注意力评分 | 正相关 | 0.5 | 专注、认知负荷高时,Theta活动增强 |
| Gamma连接性 | 决策准确率 | 正相关 | 0.42 | 高阶认知整合可能提升复杂决策的准确性 |
这些关联性分析不仅揭示了EEG指标与行为表现之间的内在联系,也为基于EEG的情绪识别提供了强有力的生物学证据。
四、 完整的实验设计流程:确保科学严谨
一个科学严谨的EEG实验设计是获得可靠结论的前提。以下是一个完整的实验设计流程,从概念化到数据采集,确保研究的有效性和可重复性。
4.1 实验设计流程图(文本)
问题定义 -> 伦理审批 -> 实验范式设计 -> 参与者招募 -> 数据采集 -> 质量控制
4.2 详细步骤
-
问题定义与假设(Hypothesis Formulation):
-
目标:明确研究目的和要验证的假设。例如:“正面情绪是否会显著提升认知任务的准确率?”
-
具体化:需要比较中性、正面和负面情绪下,参与者在特定认知任务中的反应时、准确率,以及相应的EEG指标(如P300幅度、额叶Alpha不对称)。
-
数据选择:假设实验基于DEAP数据集(电影片段诱发情绪)或自行采集。
-
-
伦理审批与知情同意:
-
重要性:所有涉及人类参与者的研究都必须获得机构审查委员会(IRB)或伦理委员会的批准。
-
内容:提交详细的实验方案,包括目的、程序、风险、收益、数据处理方式等。
-
知情同意书:向参与者充分解释实验内容,确保他们自愿参与,并签署知情同意书。强调数据匿名化和随时退出的权利。
-
-
实验范式设计与实现:
-
选择范式:结合被动诱发和主动任务,以全面评估情绪和认知。
-
被动诱发:40张IAPS图片(20正面,20负面),每张呈现5秒,间隔5秒注视点。图片后进行SAM量表自评。
-
主动任务:情绪性Stroop任务。呈现情感词语,要求参与者判断词语颜色,记录反应时和准确率。
-
-
平衡与随机化:刺激呈现顺序应随机化或平衡,以避免顺序效应和疲劳。
-
软件实现:使用PsychoPy、E-Prime等专业心理学实验软件进行刺激呈现和行为数据记录。
-
-
参与者招募与筛选:
-
数量:根据统计学效力分析(Power Analysis)确定样本量,例如招募20名健康成人(18-30岁)。
-
筛选标准:平衡性别,排除有神经系统疾病、精神障碍、药物滥用史或听力视力障碍的参与者。
-
补偿:为参与者提供适当的报酬或学分。
-
-
数据采集:
-
EEG设备:使用专业EEG采集系统(如Brain Products、Neuroscan、ActiChamp等),通道数32-64通道,遵循国际10-20或10-10系统。
-
同步采集:确保EEG与行为学数据、刺激呈现时间戳精确同步。
-
多模态设备:若进行多模态融合,同步采集眼动数据(如EyeLink、Tobii)和生理信号(如BIOPAC系统采集心电ECG、皮肤电GSR)。
-
环境:在安静、光线适宜的屏蔽室进行,减少外部干扰。
-
时长:合理控制实验总时长(通常1-2小时),避免参与者疲劳。
-
-
数据质量控制与预检:
-
实时监测:在采集过程中实时监测EEG信号质量,确保阻抗在可接受范围(通常<5kΩ)。
-
伪影标记:记录参与者在实验过程中发生的眼动、眨眼、头部运动等,便于后期伪影去除。
-
试次排除:初步检查数据,排除伪影过多(如超过10%的试次)或不符合任务要求的参与者。
-
五、 数据分析流程:从原始信号到科学洞察
获得高质量的原始数据后,便进入关键的数据分析阶段。以下是一个标准的EEG数据分析流程,旨在从复杂的脑电信号中提取有意义的指标并进行统计推断。
5.1 数据分析流程图(文本)
预处理 -> 特征提取 -> 分类(情绪识别)-> 关联分析 -> 统计检验 -> 结果可视化
5.2 详细步骤与Python代码示例
-
预处理 (Preprocessing):
-
MNE库是Python中处理EEG数据的强大工具。
-
加载数据:读取原始EEG数据(如.eeg、.edf、.fif格式)。
-
滤波:应用带通滤波器(如0.5-40 Hz)去除低频漂移和高频噪声;应用陷波滤波器去除工频干扰(50/60 Hz)。
-
伪影去除:
-
眼电(EOG)/肌电(EMG)伪影:使用**独立成分分析(ICA)**识别并移除EOG、EMG成分。
-
坏导插值:识别并修复(如通过球形样条插值)接触不良的坏电极。
-
基线校正:将每个Epoch减去前置基线期的平均值。
-
-
分段 (Epoching):将连续数据根据事件标记切割成短时间窗口(Epoch),每个Epoch对应一个刺激或响应。
import mne import numpy as np from mne.preprocessing import ICA# 假设 raw 是加载的原始EEG数据 # raw = mne.io.read_raw_edf('your_eeg_data.edf', preload=True) # 实际加载数据# 模拟数据用于演示,实际应加载你的数据 sfreq = 250 n_channels = 32 n_times = sfreq * 300 # 300秒数据 info = mne.create_info(ch_names=[f'EEG {i:03d}' for i in range(n_channels)], sfreq=sfreq, ch_types='eeg') raw = mne.io.RawArray(np.random.randn(n_channels, n_times) * 1e-6, info, verbose=False) # 随机数据# 假设我们有正面和负面情绪刺激的事件 events_data = np.array([[1 * sfreq, 0, 1], # 刺激1 (正面)[10 * sfreq, 0, 2], # 刺激2 (负面)[20 * sfreq, 0, 1],[30 * sfreq, 0, 2],# ... 更多事件 ]) event_id = {'positive': 1, 'negative': 2}# 1. 滤波 raw.filter(l_freq=0.5, h_freq=40.0, fir_design='firwin', verbose=False) # 带通滤波 raw.notch_filter(freqs=50, fir_design='firwin', verbose=False) # 陷波滤波# 2. ICA去除伪影 (在长程数据上fit,然后apply到raw) ica = ICA(n_components=15, random_state=42, verbose=False) # 成分数可调 ica.fit(raw) # ica.plot_sources(raw) # 可以可视化ICA成分以手动选择需要移除的成分 # ica.exclude = [0, 1] # 假设0, 1是眼动成分 raw = ica.apply(raw, exclude=[0,1], verbose=False) # 移除选定成分# 3. 分段 (Epoching) tmin, tmax = -0.2, 0.8 # 刺激前200ms到刺激后800ms epochs = mne.Epochs(raw, events_data, event_id=event_id, tmin=tmin, tmax=tmax, baseline=(-0.2, 0), preload=True, verbose=False) # 基线校正 print(f"预处理后Epochs数据形状: {epochs.get_data().shape}") -
-
特征提取 (Feature Extraction):
-
从预处理后的EEG数据中提取有意义的特征。
-
ERP分析:计算不同条件下的平均ERP波形,并识别P300、N170等成分的幅度和潜伏期。
# 计算平均ERP波形 evoked_positive = epochs['positive'].average() evoked_negative = epochs['negative'].average()# 绘制ERP evoked_positive.plot(spatial_colors=True, gfp=True, titles='Positive ERP', verbose=False) evoked_negative.plot(spatial_colors=True, gfp=True, titles='Negative ERP', verbose=False) plt.show()# 提取P300幅度 (例如在Cz电极,300-500ms范围) # 假设Cz是第15个通道 (索引14) cz_idx = epochs.info['ch_names'].index('EEG 015') if 'EEG 015' in epochs.info['ch_names'] else 0 # 示例取第一个通道# 在指定时间窗内找到峰值 t_start, t_end = 0.3, 0.5 # P300时间窗p300_pos = evoked_positive.data[cz_idx, epochs.time_as_index(t_start):epochs.time_as_index(t_end)].max() p300_neg = evoked_negative.data[cz_idx, epochs.time_as_index(t_start):epochs.time_as_index(t_end)].max() print(f"Positive P300 amplitude at {epochs.info['ch_names'][cz_idx]}: {p300_pos * 1e6:.2f} uV") print(f"Negative P300 amplitude at {epochs.info['ch_names'][cz_idx]}: {p300_neg * 1e6:.2f} uV")-
功率谱密度 (PSD) 分析:计算不同频段(Delta, Theta, Alpha, Beta, Gamma)的功率或相对功率。
from mne.time_frequency import psd_welch# 计算PSD psds, freqs = psd_welch(epochs, fmin=0.5, fmax=40, n_fft=int(sfreq*2), n_per_seg=int(sfreq*1), verbose=False) # 2秒窗口,1秒重叠 # psds 形状: (n_epochs, n_channels, n_freqs)# 提取Alpha波不对称性 (FAA) # 假设F3, F4分别对应索引 2, 3 (实际根据电极位置确定) f3_idx = 2 f4_idx = 3# Alpha频带 (8-12Hz) alpha_band_idx = np.where((freqs >= 8) & (freqs <= 12))[0]if len(alpha_band_idx) > 0:# 计算F3和F4通道的Alpha功率alpha_power_f3 = psds[:, f3_idx, alpha_band_idx].mean(axis=1)alpha_power_f4 = psds[:, f4_idx, alpha_band_idx].mean(axis=1)# 计算FAA (避免log(0)报错)epsilon = 1e-9 # 添加一个小的常数frontal_alpha_asymmetry = np.log(alpha_power_f4 + epsilon) - np.log(alpha_power_f3 + epsilon)print(f"额叶Alpha不对称性示例 (平均值): {frontal_alpha_asymmetry.mean():.4f}") else:print("未找到Alpha频带或电极索引不正确。") -
-
情绪分类 (Emotion Classification):
-
使用提取的EEG特征训练机器学习或深度学习模型进行情绪识别。
-
传统机器学习:SVM、Random Forest等。
-
深度学习:CNN、LSTM、Transformer等。
from sklearn.svm import SVC from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, classification_report from sklearn.preprocessing import StandardScaler from sklearn.pipeline import make_pipeline# 简化:使用PSD特征进行分类 (实际可组合多种特征) # 对psds进行reshape,每个epoch一个样本,通道*频率为特征 n_epochs, n_channels, n_freqs = psds.shape X_features = psds.reshape(n_epochs, n_channels * n_freqs) y_class_labels = epochs.events[:, -1] # 再次获取标签# 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X_features, y_class_labels, test_size=0.3, random_state=42, stratify=y_class_labels)# 构建并训练SVM分类器 svm_clf = make_pipeline(StandardScaler(), SVC(kernel='rbf', C=1.0, random_state=42)) svm_clf.fit(X_train, y_train)# 预测与评估 y_pred = svm_clf.predict(X_test) print(f"\n--- SVM 情绪分类报告 (基于PSD特征) ---") print(f"准确率: {accuracy_score(y_test, y_pred):.4f}") print(classification_report(y_test, y_pred, target_names=['positive', 'negative'])) -
-
关联分析 (Correlation Analysis):
-
研究EEG指标与行为学数据之间的统计关系。
-
假设:我们已经有了情绪Stroop任务的反应时(
rt_data)和任务准确率(accuracy_data)。
from scipy.stats import pearsonr# 模拟行为数据 (确保与EEG epoch数量一致) num_epochs = X_features.shape[0] rt_data = np.random.rand(num_epochs) * 500 + 500 # 500-1000ms accuracy_data = np.random.rand(num_epochs) > 0.5 # 0或1# 关联P300幅度 (这里用之前计算的样本值,实际需要每个epoch的P300) # 为了演示,假设我们有每个epoch的P300幅度列表 p300_amplitudes = np.random.rand(num_epochs) * 1e-6 # 模拟P300幅度# 关联P300幅度与反应时 r_p300_rt, p_p300_rt = pearsonr(p300_amplitudes, rt_data) print(f"\n--- P300幅度与反应时的Pearson相关 ---") print(f"相关系数 (r): {r_p300_rt:.4f}, p值: {p_p300_rt:.4f}")# 关联额叶Alpha不对称性与任务准确率 (同样需要每个epoch的FAA) # 为了演示,假设我们有每个epoch的FAA列表 if 'frontal_alpha_asymmetry' in locals():r_faa_acc, p_faa_acc = pearsonr(frontal_alpha_asymmetry, accuracy_data)print(f"\n--- 额叶Alpha不对称性与任务准确率的Pearson相关 ---")print(f"相关系数 (r): {r_faa_acc:.4f}, p值: {p_faa_acc:.4f}") -
-
统计检验 (Statistical Testing):
-
目的:确定观察到的差异或关联是否具有统计学意义。
-
常用方法:
-
t检验:比较两组(如正面情绪 vs 负面情绪)之间某个指标的平均值是否存在显著差异。
-
方差分析 (ANOVA):比较三组或更多组(如正面 vs 中性 vs 负面)之间是否存在显著差异。
-
重复测量ANOVA:处理同一个参与者在不同条件下的测量数据。
-
非参数检验:如果数据不满足正态分布等参数检验假设,可使用Wilcoxon秩和检验、Kruskal-Wallis检验等。
-
from scipy.stats import ttest_ind, f_oneway# 假设我们有正面情绪下的RT和负面情绪下的RT rt_positive = rt_data[y_class_labels == 1] rt_negative = rt_data[y_class_labels == 2]# 独立样本t检验:比较正面和负面情绪下RT的差异 t_val, p_val = ttest_ind(rt_positive, rt_negative) print(f"\n--- 独立样本t检验:正面情绪RT vs 负面情绪RT ---") print(f"t值: {t_val:.4f}, p值: {p_val:.4f}")# 假设有三个情绪条件: positive, negative, neutral (为了ANOVA演示) # 如果实际只有两类,ANOVA会等同于t-test # 模拟 neutral_rt rt_neutral = np.random.rand(len(rt_positive)) * 500 + 500 # 方差分析 (ANOVA) # f_val, p_val_anova = f_oneway(rt_positive, rt_negative, rt_neutral) # print(f"\n--- 方差分析 (ANOVA):RT在不同情绪条件下的差异 ---") # print(f"F值: {f_val:.4f}, p值: {p_val_anova:.4f}") -
-
结果可视化 (Result Visualization):
-
使用
matplotlib、seaborn等库绘制ERP波形图、拓扑图、功率谱图、柱状图、箱线图、散点图等,直观展示实验结果和统计发现。
-
六、 最新进展(2025年):多模态、可解释与实时AI
-
Transformer在多模态融合中的崛起:2025年研究显示,基于Transformer的自注意力机制在融合EEG与眼动、语音、面部表情等多模态数据方面表现出卓越性能,能够高效捕捉跨模态的复杂关联,将情绪识别准确率推高至98%。EmoTrans等模型融合EEG+音频,实现了前所未有的准确率。
-
可解释性AI (XAI):随着深度学习模型复杂度的增加,解释模型“为什么”做出某个决策变得至关重要。XAI技术,如LRP (Layer-wise Relevance Propagation)、Grad-CAM和Shapley值,被广泛应用于EEG情绪识别,帮助研究者理解模型关注的EEG特征(通道、频段、时间点),提升模型的临床接受度和透明度。
-
实时情绪识别与反馈:结合轻量级深度学习模型和边缘计算设备,实现EEG情绪的实时识别和在线反馈。这为自适应BCI、智能心理干预、虚拟现实(VR)游戏等应用提供了技术基础。
-
预训练与迁移学习:在大型公开EEG数据集(如DEAP, SEED, DREAMER)上进行预训练,再针对特定情绪任务或个体进行微调,显著提升模型在小样本和新用户上的泛化能力。
七、 结论:构建严谨的EEG情绪与认知研究
EEG作为“心灵探测器”,在情绪识别与认知研究中扮演着不可替代的角色。通过本文提供的完整实验设计和数据分析流程,你将能够:
-
科学地设计实验范式,精准诱发目标情绪和认知状态。
-
有效地融合多模态数据,弥补单一EEG模态的局限性,提升研究的鲁棒性。
-
深入地分析EEG指标与行为学数据之间的关联,揭示情绪对认知的深层影响。
-
利用Python工具,从原始信号到统计检验,完成一个严谨的EEG研究项目。
展望未来,随着多模态融合、可解释AI和实时反馈技术的发展,EEG在情绪识别和认知研究中的应用将更加智能、个性化和高效,为心理健康、人机交互等领域带来革命性的突破。
希望本篇博客能为你开启EEG情绪与认知研究的大门,并激发你进一步探索大脑奥秘的兴趣。欢迎在评论区分享你的见解和问题!
致谢与讨论:
感谢阅读本篇博客!期待与你在脑电分析的旅程中共同成长。
参考资源:
-
MNE-Python官方文档: https://mne.tools/
-
PsychoPy官方文档: https://www.psychopy.org/
-
Scikit-learn官方文档: https://scikit-learn.org/
-
SciPy官方文档: https://scipy.org/
-
DEAP数据集: https://www.eecs.qmul.ac.uk/mmv/datasets/deap/
-
IAPS图片库: (需申请访问权限)