面试题:分布式锁要点总结(Redisson)
1.读锁RedissonReadLock的获取读锁逻辑
(1)加读锁的lua脚本逻辑
假设客户端A的线程(UUID1:ThreadID1)作为第一个线程进来加读锁,执行流程如下:
public class RedissonLock extends RedissonBaseLock {...//不带参数的加锁public void lock() {...lock(-1, null, false);...}//带参数的加锁public void lock(long leaseTime, TimeUnit unit) {...lock(leaseTime, unit, false);...}private void lock(long leaseTime, TimeUnit unit, boolean interruptibly) throws InterruptedException {long threadId = Thread.currentThread().getId();Long ttl = tryAcquire(-1, leaseTime, unit, threadId);//加锁成功if (ttl == null) {return;}//加锁失败...}private Long tryAcquire(long waitTime, long leaseTime, TimeUnit unit, long threadId) {return get(tryAcquireAsync(waitTime, leaseTime, unit, threadId));}private <T> RFuture<Long> tryAcquireAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId) {RFuture<Long> ttlRemainingFuture;if (leaseTime != -1) {ttlRemainingFuture = tryLockInnerAsync(waitTime, leaseTime, unit, threadId, RedisCommands.EVAL_LONG);} else {//非公平锁,接下来调用的是RedissonLock.tryLockInnerAsync()方法//公平锁,接下来调用的是RedissonFairLock.tryLockInnerAsync()方法//读写锁中的读锁,接下来调用RedissonReadLock.tryLockInnerAsync()方法ttlRemainingFuture = tryLockInnerAsync(waitTime, internalLockLeaseTime, TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);}//对RFuture<Long>类型的ttlRemainingFuture添加回调监听CompletionStage<Long> f = ttlRemainingFuture.thenApply(ttlRemaining -> {//tryLockInnerAsync()里的加锁lua脚本异步执行完毕,会回调如下方法逻辑://加锁成功if (ttlRemaining == null) {if (leaseTime != -1) {//如果传入的leaseTime不是-1,也就是指定锁的过期时间,那么就不创建定时调度任务internalLockLeaseTime = unit.toMillis(leaseTime);} else {//创建定时调度任务scheduleExpirationRenewal(threadId);}}return ttlRemaining;});return new CompletableFutureWrapper<>(f);}...
}
public class RedissonReadLock extends RedissonLock implements RLock {...@Override<T> RFuture<T> tryLockInnerAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {return evalWriteAsync(getRawName(), LongCodec.INSTANCE, command,//执行命令"hget myLock mode",尝试获取一个Hash值mode"local mode = redis.call('hget', KEYS[1], 'mode'); " +//mode为false则执行加读锁的逻辑"if (mode == false) then " +//hset myLock mode read"redis.call('hset', KEYS[1], 'mode', 'read'); " +//hset myLock UUID1:ThreadID1 1"redis.call('hset', KEYS[1], ARGV[2], 1); " +//set {myLock}:UUID1:ThreadID1:rwlock_timeout:1 1"redis.call('set', KEYS[2] .. ':1', 1); " +//pexpire {myLock}:UUID1:ThreadID1:rwlock_timeout:1 30000"redis.call('pexpire', KEYS[2] .. ':1', ARGV[1]); " +//pexpire myLock 30000"redis.call('pexpire', KEYS[1], ARGV[1]); " +"return nil; " +"end; " +//如果已经有线程加了读锁 或者 有线程加了写锁且是自己加的写锁//所以一个线程如果加了写锁,它是可以重入自己的写锁和自己的读锁的"if (mode == 'read') or (mode == 'write' and redis.call('hexists', KEYS[1], ARGV[3]) == 1) then " +//hincrby myLock UUID2:ThreadID2 1//ind表示重入次数,线程可以重入自己的读锁和写锁,线程后加的读锁可以重入线程自己的读锁或写锁"local ind = redis.call('hincrby', KEYS[1], ARGV[2], 1); " + //key = {myLock}:UUID2:ThreadID2:rwlock_timeout:1"local key = KEYS[2] .. ':' .. ind;" +//set {myLock}:UUID2:ThreadID2:rwlock_timeout:1 1"redis.call('set', key, 1); " +//pexpire myLock 30000"redis.call('pexpire', key, ARGV[1]); " +"local remainTime = redis.call('pttl', KEYS[1]); " +//pexpire {myLock}:UUID2:ThreadID2:rwlock_timeout:1 30000"redis.call('pexpire', KEYS[1], math.max(remainTime, ARGV[1])); " +"return nil; " +"end;" +//执行命令"pttl myLock",返回myLock的剩余过期时间"return redis.call('pttl', KEYS[1]);",//KEYS[1] = myLock//KEYS[2] = {myLock}:UUID1:ThreadID1:rwlock_timeout 或 KEYS[2] = {myLock}:UUID2:ThreadID2:rwlock_timeoutArrays.<Object>asList(getRawName(), getReadWriteTimeoutNamePrefix(threadId)),unit.toMillis(leaseTime),//ARGV[1] = 30000getLockName(threadId),//ARGV[2] = UUID1:ThreadID1 或 ARGV[2] = UUID2:ThreadID2getWriteLockName(threadId)//ARGV[3] = UUID1:ThreadID1:write 或 ARGV[3] = UUID2:ThreadID2:write);}...
}
一.参数说明
KEYS[1] = myLock
KEYS[2] = {myLock}:UUID1:ThreadID1:rwlock_timeout
ARGV[1] = 30000
ARGV[2] = UUID1:ThreadID1
ARGV[3] = UUID1:ThreadID1:write
二.执行lua脚本的获取读锁逻辑
首先执行命令"hget myLock mode",尝试获取一个Hash值mode,也就是从key为myLock的Hash值里获取一个field为mode的value值。但是此时一开始都还没有加锁,所以mode肯定是false。于是就执行如下加读锁的逻辑:设置两个Hash值 + 设置一个字符串。
hsetmyLock mode read
//用来记录当前客户端线程重入锁的次数
hsetmyLock UUID1:ThreadID1 1
//用来记录当前客户端线程第1个重入锁过期时间
set{myLock}:UUID1:ThreadID1:rwlock_timeout:11
pexpire{myLock}:UUID1:ThreadID1:rwlock_timeout:130000
pexpiremyLock 30000
执行完加读锁逻辑后,Redis存在如下结构的数据。其实加读锁的核心在于构造一个递增序列,记录不同线程的读锁和同一个线程不同的重入锁。
field为类似于UUID1:ThreadID1的value值,是用来记录当前客户端线程重入锁次数的。key为类似于{myLock}:UUID1:ThreadID1:rwlock_timeout:1的String,是用来记录当前客户端线程第n个重入锁过期时间的。
假设将key为myLock称为父读锁,key为UUID1:ThreadID1称为子读锁。那么记录每一个子读锁的过期时间,是因为需要根据多个子读锁的过期时间更新父读锁的过期时间。
//1.线程1第一次加读锁
//Hash结构
myLock: {"mode": "read","UUID1:ThreadID1": 1
}
//String结构
{myLock}:UUID1:ThreadID1:rwlock_timeout:1 ==> 1
//2.线程1第二次加读锁
//Hash结构
myLock: {"mode": "read","UUID1:ThreadID1": 2
}
//String结构
{myLock}:UUID1:ThreadID1:rwlock_timeout:1 ==> 1
{myLock}:UUID1:ThreadID1:rwlock_timeout:2 ==> 1
//3.线程1第三次加读锁
//Hash结构
myLock: {"mode": "read","UUID1:ThreadID1": 3
}
//String结构
{myLock}:UUID1:ThreadID1:rwlock_timeout:1 ==> 1
{myLock}:UUID1:ThreadID1:rwlock_timeout:2 ==> 1
{myLock}:UUID1:ThreadID1:rwlock_timeout:3 ==> 1
//4.线程2第一次加读锁
//Hash结构
myLock: {"mode": "read","UUID1:ThreadID1": 3,"UUID2:ThreadID2": 1
}
//String结构
{myLock}:UUID1:ThreadID1:rwlock_timeout:1 ==> 1
{myLock}:UUID1:ThreadID1:rwlock_timeout:2 ==> 1
{myLock}:UUID1:ThreadID1:rwlock_timeout:3 ==> 1
{myLock}:UUID2:ThreadID2:rwlock_timeout:1 ==> 1
//5.线程2第二次加读锁
//Hash结构
myLock: {"mode": "read","UUID1:ThreadID1": 3,"UUID2:ThreadID2": 2
}
//String结构
{myLock}:UUID1:ThreadID1:rwlock_timeout:1 ==> 1
{myLock}:UUID1:ThreadID1:rwlock_timeout:2 ==> 1
{myLock}:UUID1:ThreadID1:rwlock_timeout:3 ==> 1
{myLock}:UUID2:ThreadID2:rwlock_timeout:1 ==> 1
{myLock}:UUID2:ThreadID2:rwlock_timeout:2 ==> 1
(2)WathDog处理读锁过期时间的lua脚本逻辑
假设客户端A的线程(UUID1:ThreadID1)已经成功获取到一个读锁,此时会创建一个WatchDog定时调度任务,10秒后检查该读锁。执行流程如下:
public abstract class RedissonBaseLock extends RedissonExpirable implements RLock {...protected void scheduleExpirationRenewal(long threadId) {ExpirationEntry entry = new ExpirationEntry();ExpirationEntry oldEntry = EXPIRATION_RENEWAL_MAP.putIfAbsent(getEntryName(), entry);if (oldEntry != null) {oldEntry.addThreadId(threadId);} else {entry.addThreadId(threadId);try {//创建一个更新过期时间的定时调度任务renewExpiration();} finally {if (Thread.currentThread().isInterrupted()) {cancelExpirationRenewal(threadId);}}}}//更新过期时间private void renewExpiration() {ExpirationEntry ee = EXPIRATION_RENEWAL_MAP.get(getEntryName());if (ee == null) {return;}//使用了Netty的定时任务机制:HashedWheelTimer + TimerTask + Timeout//创建一个更新过期时间的定时调度任务,下面会调用MasterSlaveConnectionManager.newTimeout()方法//即创建一个定时调度任务TimerTask交给HashedWheelTimer,10秒后执行Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {@Overridepublic void run(Timeout timeout) throws Exception {ExpirationEntry ent = EXPIRATION_RENEWAL_MAP.get(getEntryName());if (ent == null) {return;}Long threadId = ent.getFirstThreadId();if (threadId == null) {return;}//异步执行lua脚本去更新锁的过期时间//对于读写锁,接下来会执行RedissonReadLock.renewExpirationAsync()方法RFuture<Boolean> future = renewExpirationAsync(threadId);future.whenComplete((res, e) -> {if (e != null) {log.error("Can't update lock " + getRawName() + " expiration", e);EXPIRATION_RENEWAL_MAP.remove(getEntryName());return;}//res就是执行renewExpirationAsync()里的lua脚本的返回值if (res) {//重新调度自己renewExpiration();} else {//执行清理工作cancelExpirationRenewal(null);}});}}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);ee.setTimeout(task);}protected void cancelExpirationRenewal(Long threadId) {ExpirationEntry task = EXPIRATION_RENEWAL_MAP.get(getEntryName());if (task == null) {return;}if (threadId != null) {task.removeThreadId(threadId);}if (threadId == null || task.hasNoThreads()) {Timeout timeout = task.getTimeout();if (timeout != null) {timeout.cancel();}EXPIRATION_RENEWAL_MAP.remove(getEntryName());}}...
}
public class RedissonReadLock extends RedissonLock implements RLock {...@Overrideprotected RFuture<Boolean> renewExpirationAsync(long threadId) {String timeoutPrefix = getReadWriteTimeoutNamePrefix(threadId);String keyPrefix = getKeyPrefix(threadId, timeoutPrefix);return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,//执行命令"hget myLock UUID1:ThreadID1",获取当前这个线程是否还持有这个读锁"local counter = redis.call('hget', KEYS[1], ARGV[2]); " +"if (counter ~= false) then " +//指定的线程还在持有锁,那么就执行"pexpire myLock 30000"刷新锁的过期时间"redis.call('pexpire', KEYS[1], ARGV[1]); " +"if (redis.call('hlen', KEYS[1]) > 1) then " +//获取key为myLock的Hash值的所有key"local keys = redis.call('hkeys', KEYS[1]); " + //遍历已被线程获取的所有重入和非重入的读锁"for n, key in ipairs(keys) do " + "counter = tonumber(redis.call('hget', KEYS[1], key)); " + //排除掉key为mode的Hash值"if type(counter) == 'number' then " + //递减拼接重入锁的key,刷新同一个线程的所有重入锁的过期时间"for i=counter, 1, -1 do " + "redis.call('pexpire', KEYS[2] .. ':' .. key .. ':rwlock_timeout:' .. i, ARGV[1]); " + "end; " + "end; " + "end; " +"end; " +"return 1; " +"end; " +"return 0;",//KEYS[1] = myLock//KEYS[2] = {myLock}Arrays.<Object>asList(getRawName(), keyPrefix),internalLockLeaseTime,//ARGV[1] = 30000毫秒getLockName(threadId)//ARGV[2] = UUID1:ThreadID1);}...
}
一.参数说明
KEYS[1] = myLock
KEYS[2] = {myLock}
ARGV[1] = 30000
ARGV[2] = UUID1:ThreadID1
二.执行lua脚本的处理逻辑
执行命令"hget myLock UUID1:ThreadID1",尝试获取一个Hash值,也就是获取指定的这个线程是否还持有这个读锁。如果指定的这个线程还在持有这个锁,那么这里返回的是1,于是就会执行"pexpire myLock 30000"刷新锁的过期时间。
接着执行命令"hlen myLock",判断key为锁名的Hash元素个数是否大于1。如果指定的这个线程还在持有这个锁,那么key为myLock的Hash值就至少有两个kv对。其中一个key是mode,一个key是UUID1:ThreadID1。所以这里的判断是成立的,于是遍历处理key为锁名的Hash值。
在遍历处理key为锁名的Hash值时,需要排除掉key为mode的Hash值。然后根据key为UUID + 线程ID的Hash值,通过递减拼接,进行循环遍历,把每一个不同线程的读锁或同一个线程不同的重入锁,都刷新过期时间。
三.总结
WatchDog在处理读锁时,如果指定的线程还持有读锁,那么就会:刷新读锁key的过期时间为30秒,根据重入读锁的次数进行遍历,对重入读锁对应的key的过期时间也刷新为30秒。
//KEYS[1] = myLock
//KEYS[2] = {myLock}
"if (redis.call('hlen', KEYS[1]) > 1) then " +"local keys = redis.call('hkeys', KEYS[1]); " + //遍历处理key为锁名的Hash值"for n, key in ipairs(keys) do " + "counter = tonumber(redis.call('hget', KEYS[1], key)); " + //排除掉key为mode的Hash值"if type(counter) == 'number' then " + "for i=counter, 1, -1 do " + //递减拼接,把不同线程的读锁或同一个线程不同的重入锁,都刷新过期时间"redis.call('pexpire', KEYS[2] .. ':' .. key .. ':rwlock_timeout:' .. i, ARGV[1]); " + "end; " + "end; " + "end; " +
"end; " +
//Hash结构
myLock: {"mode": "read","UUID1:ThreadID1": 3,"UUID2:ThreadID2": 2
}
//String结构
{myLock}:UUID1:ThreadID1:rwlock_timeout:1 ==> 1
{myLock}:UUID1:ThreadID1:rwlock_timeout:2 ==> 1
{myLock}:UUID1:ThreadID1:rwlock_timeout:3 ==> 1
{myLock}:UUID2:ThreadID2:rwlock_timeout:1 ==> 1
{myLock}:UUID2:ThreadID2:rwlock_timeout:2 ==> 1
2.写锁RedissonWriteLock的获取写锁逻辑
(1)获取写锁的执行流程
假设客户端A的线程(UUID1:ThreadID1)作为第一个线程进来加写锁,执行流程如下:
public class RedissonLock extends RedissonBaseLock {...//不带参数的加锁public void lock() {...lock(-1, null, false);...}//带参数的加锁public void lock(long leaseTime, TimeUnit unit) {...lock(leaseTime, unit, false);...}private void lock(long leaseTime, TimeUnit unit, boolean interruptibly) throws InterruptedException {long threadId = Thread.currentThread().getId();Long ttl = tryAcquire(-1, leaseTime, unit, threadId);//加锁成功if (ttl == null) {return;}//加锁失败...}private Long tryAcquire(long waitTime, long leaseTime, TimeUnit unit, long threadId) {return get(tryAcquireAsync(waitTime, leaseTime, unit, threadId));}private <T> RFuture<Long> tryAcquireAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId) {RFuture<Long> ttlRemainingFuture;if (leaseTime != -1) {ttlRemainingFuture = tryLockInnerAsync(waitTime, leaseTime, unit, threadId, RedisCommands.EVAL_LONG);} else {//非公平锁,接下来调用的是RedissonLock.tryLockInnerAsync()方法//公平锁,接下来调用的是RedissonFairLock.tryLockInnerAsync()方法//读写锁中的读锁,接下来调用RedissonReadLock.tryLockInnerAsync()方法//读写锁中的写锁,接下来调用RedissonWriteLock.tryLockInnerAsync()方法ttlRemainingFuture = tryLockInnerAsync(waitTime, internalLockLeaseTime, TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);}//对RFuture<Long>类型的ttlRemainingFuture添加回调监听CompletionStage<Long> f = ttlRemainingFuture.thenApply(ttlRemaining -> {//tryLockInnerAsync()里的加锁lua脚本异步执行完毕,会回调如下方法逻辑://加锁成功if (ttlRemaining == null) {if (leaseTime != -1) {//如果传入的leaseTime不是-1,也就是指定锁的过期时间,那么就不创建定时调度任务internalLockLeaseTime = unit.toMillis(leaseTime);} else {//创建定时调度任务scheduleExpirationRenewal(threadId);}}return ttlRemaining;});return new CompletableFutureWrapper<>(f);}...
}
public class RedissonWriteLock extends RedissonLock implements RLock {...@Override<T> RFuture<T> tryLockInnerAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {return evalWriteAsync(getRawName(), LongCodec.INSTANCE, command,//执行命令"hget myLock mode",尝试获取一个Hash值mode"local mode = redis.call('hget', KEYS[1], 'mode'); " +//获取不到,说明没有加读锁或者写锁"if (mode == false) then " +"redis.call('hset', KEYS[1], 'mode', 'write'); " +"redis.call('hset', KEYS[1], ARGV[2], 1); " +"redis.call('pexpire', KEYS[1], ARGV[1]); " +"return nil; " +"end; " +//如果加过锁,那么就要看是不是写锁 + 写锁是不是自己加过的(即重入写锁)"if (mode == 'write') then " +"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +//重入写锁"redis.call('hincrby', KEYS[1], ARGV[2], 1); " + "local currentExpire = redis.call('pttl', KEYS[1]); " +"redis.call('pexpire', KEYS[1], currentExpire + ARGV[1]); " +"return nil; " +"end; " +"end;" +//执行命令"pttl myLock",返回myLock的剩余过期时间"return redis.call('pttl', KEYS[1]);",Arrays.<Object>asList(getRawName()),//KEYS[1] = myLockunit.toMillis(leaseTime),//ARGV[1] = 30000getLockName(threadId)//ARGV[2] = UUID1:ThreadID1:write);}...
}
(2)获取写锁的lua脚本逻辑
一.参数说明
KEYS[1] = myLock
ARGV[1] = 30000
ARGV[2] = UUID1:ThreadID1:write
二.执行分析
首先执行命令"hget myLock mode",尝试获取一个Hash值mode,也就是从key为myLock的Hash值里获取一个field为mode的value值。但是此时一开始都还没有加锁,所以mode肯定是false。于是就执行如下加读锁的逻辑:设置两个Hash值。
hsetmyLock mode write
hsetmyLock UUID1:ThreadID1:write 1
pexpiremyLock30000
完成加锁操作后,Redis中存在如下数据:
//Hash结构
myLock: {"mode": "write","UUID1:ThreadID1:write": 1
}
3.读锁RedissonReadLock的读读不互斥逻辑
(1)不同客户端线程读锁与读锁不互斥说明
假设客户端A(UUID1:ThreadID1)对myLock这个锁先加了一个读锁,客户端B(UUID2:ThreadID2)也要对myLock这个锁加一个读锁,那么此时这两个读锁是不会互斥的,客户端B可以加锁成功。
public class RedissonReadLock extends RedissonLock implements RLock {...@Override<T> RFuture<T> tryLockInnerAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {return evalWriteAsync(getRawName(), LongCodec.INSTANCE, command,//执行命令"hget myLock mode",尝试获取一个Hash值mode"local mode = redis.call('hget', KEYS[1], 'mode'); " +//mode为false则执行加读锁的逻辑"if (mode == false) then " +//hset myLock mode read"redis.call('hset', KEYS[1], 'mode', 'read'); " +//hset myLock UUID1:ThreadID1 1"redis.call('hset', KEYS[1], ARGV[2], 1); " +//set {myLock}:UUID1:ThreadID1:rwlock_timeout:1 1"redis.call('set', KEYS[2] .. ':1', 1); " +//pexpire {myLock}:UUID1:ThreadID1:rwlock_timeout:1 30000"redis.call('pexpire', KEYS[2] .. ':1', ARGV[1]); " +//pexpire myLock 30000"redis.call('pexpire', KEYS[1], ARGV[1]); " +"return nil; " +"end; " +//如果已经有线程加了读锁 或者 有线程加了写锁且是自己加的写锁//所以一个线程如果加了写锁,它是可以重入自己的写锁和自己的读锁的"if (mode == 'read') or (mode == 'write' and redis.call('hexists', KEYS[1], ARGV[3]) == 1) then " +//hincrby myLock UUID2:ThreadID2 1//ind表示重入次数,线程可以重入自己的读锁和写锁,线程后加的读锁可以重入线程自己的读锁或写锁"local ind = redis.call('hincrby', KEYS[1], ARGV[2], 1); " + //key = {myLock}:UUID2:ThreadID2:rwlock_timeout:1"local key = KEYS[2] .. ':' .. ind;" +//set {myLock}:UUID2:ThreadID2:rwlock_timeout:1 1"redis.call('set', key, 1); " +//pexpire myLock 30000"redis.call('pexpire', key, ARGV[1]); " +"local remainTime = redis.call('pttl', KEYS[1]); " +//pexpire {myLock}:UUID2:ThreadID2:rwlock_timeout:1 30000"redis.call('pexpire', KEYS[1], math.max(remainTime, ARGV[1])); " +"return nil; " +"end;" +//执行命令"pttl myLock",返回myLock的剩余过期时间"return redis.call('pttl', KEYS[1]);",//KEYS[1] = myLock//KEYS[2] = {myLock}:UUID1:ThreadID1:rwlock_timeout 或 KEYS[2] = {myLock}:UUID2:ThreadID2:rwlock_timeoutArrays.<Object>asList(getRawName(), getReadWriteTimeoutNamePrefix(threadId)),unit.toMillis(leaseTime),//ARGV[1] = 30000getLockName(threadId),//ARGV[2] = UUID1:ThreadID1 或 ARGV[2] = UUID2:ThreadID2getWriteLockName(threadId)//ARGV[3] = UUID1:ThreadID1:write 或 ARGV[3] = UUID2:ThreadID2:write);}...
}
(2)客户端A先加读锁的Redis命令执行过程和结果
参数说明:
KEYS[1] = myLock
KEYS[2] = {myLock}:UUID1:ThreadID1:rwlock_timeout
ARGV[1] = 30000
ARGV[2] = UUID1:ThreadID1
ARGV[3] = UUID1:ThreadID1:write
Redis命令的执行过程:
hset myLock mode read
hset myLock UUID1:ThreadID11
set {myLock}:UUID1:ThreadID1:rwlock_timeout:11
pexpire {myLock}:UUID1:ThreadID1:rwlock_timeout:130000
pexpire myLock 30000
Redis执行结果:
//Hash结构
myLock: {"mode": "read","UUID1:ThreadID1": 1
}
//String结构
{myLock}:UUID1:ThreadID1:rwlock_timeout:1 ==> 1
(3)客户端B后加读锁的Redis命令执行过程和结果
参数说明:
KEYS[1] = myLock
KEYS[2] = {myLock}:UUID2:ThreadID2:rwlock_timeout
ARGV[1] = 30000
ARGV[2] = UUID2:ThreadID2
ARGV[3] = UUID2:ThreadID2:write
Redis命令的执行过程:
hget myLock mode ===> 获取到mode=read,表示此时已经有线程加了读锁
hincrby myLock UUID2:ThreadID21
set {myLock}:UUID2:ThreadID2:rwlock_timeout:11
pexpire myLock 30000
pexpire {myLock}:UUID2:ThreadID2:rwlock_timeout:130000
Redis执行结果:
//Hash结构
myLock: {"mode": "read","UUID1:ThreadID1": 1,"UUID2:ThreadID2": 1
}//String结构
{myLock}:UUID1:ThreadID1:rwlock_timeout:1 ==> 1
{myLock}:UUID2:ThreadID2:rwlock_timeout:1 ==> 1
需要注意的是:多个客户端同时加读锁,读锁与读锁不互斥。会不断在key为锁名的Hash里,自增field为客户端UUID + 线程ID的value值。每个客户端成功加的一次读锁或写锁,都会维持一个WatchDog,不断刷新myLock的生存时间 + 刷新该客户端这次加的锁的过期时间。
加读锁的lua脚本中,ind表示重入次数。线程可重入自己的读锁和写锁。也就是说,线程后加的读锁可以重入线程自己先加的读锁或写锁。
4.RedissonReadLock和RedissonWriteLock的读写互斥逻辑
(1)不同客户端线程先读锁后写锁如何互斥
首先,客户端A(UUID1:ThreadID1)和客户端B(UUID2:ThreadID2)先加读锁,此时Redis中存在如下的数据:
//Hash结构
myLock: {"mode": "read","UUID1:ThreadID1": 1,"UUID2:ThreadID2": 1
}//String结构
{myLock}:UUID1:ThreadID1:rwlock_timeout:1 ==> 1
{myLock}:UUID2:ThreadID2:rwlock_timeout:1 ==> 1
接着,客户端C(UUID3:ThreadID3)来加写锁。
public class RedissonWriteLock extends RedissonLock implements RLock {...@Override<T> RFuture<T> tryLockInnerAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {return evalWriteAsync(getRawName(), LongCodec.INSTANCE, command,//执行命令"hget myLock mode",尝试获取一个Hash值mode"local mode = redis.call('hget', KEYS[1], 'mode'); " +//此时发现mode=read,说明已有线程加了锁了"if (mode == false) then " +"redis.call('hset', KEYS[1], 'mode', 'write'); " +"redis.call('hset', KEYS[1], ARGV[2], 1); " +"redis.call('pexpire', KEYS[1], ARGV[1]); " +"return nil; " +"end; " +//如果加过锁,那么就要看是不是写锁 + 写锁是不是自己加过的(即重入写锁)"if (mode == 'write') then " +"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +//重入写锁"redis.call('hincrby', KEYS[1], ARGV[2], 1); " + "local currentExpire = redis.call('pttl', KEYS[1]); " +"redis.call('pexpire', KEYS[1], currentExpire + ARGV[1]); " +"return nil; " +"end; " +"end;" +//执行命令"pttl myLock",返回myLock的剩余过期时间"return redis.call('pttl', KEYS[1]);",Arrays.<Object>asList(getRawName()),//KEYS[1] = myLockunit.toMillis(leaseTime),//ARGV[1] = 30000getLockName(threadId)//ARGV[2] = UUID3:ThreadID3:write);}...
}
客户端C(UUID3:ThreadID3)加写锁时的参数:
KEYS[1] = myLock
ARGV[1] = 30000
ARGV[2] = UUID3:ThreadID3:write
客户端C(UUID3:ThreadID3)加写锁时:首先执行命令"hget myLock mode"发现mode = read,说明已有线程加了锁了。由于已加的锁不是当前线程加的写锁,而是其他线程加的读锁。所以此时会执行命令"pttl myLock",返回myLock的剩余过期时间。这会导致客户端C加锁失败,会在while循环中阻塞和重试,从而实现先读锁后写锁的互斥。
(2)不同客户端线程先写锁后读锁如何互斥
假设客户端A(UUID1:ThreadID1)先加了一个写锁,此时Redis中存在如下的数据:
//Hash结构
myLock: {"mode": "write","UUID1:ThreadID1:write": 1
}
然后客户端B(UUID2:ThreadID2)再来加读锁。
public class RedissonReadLock extends RedissonLock implements RLock {...@Override<T> RFuture<T> tryLockInnerAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {return evalWriteAsync(getRawName(), LongCodec.INSTANCE, command,//执行命令"hget myLock mode",尝试获取一个Hash值mode"local mode = redis.call('hget', KEYS[1], 'mode'); " +//发现mode=write,说明已有线程加了锁了"if (mode == false) then " +"redis.call('hset', KEYS[1], 'mode', 'read'); " +"redis.call('hset', KEYS[1], ARGV[2], 1); " +"redis.call('set', KEYS[2] .. ':1', 1); " +"redis.call('pexpire', KEYS[2] .. ':1', ARGV[1]); " +"redis.call('pexpire', KEYS[1], ARGV[1]); " +"return nil; " +"end; " +//如果已经有线程加了读锁 或者 有线程加了写锁且是自己加的写锁//所以一个线程如果加了写锁,它是可以重入自己的写锁和自己的读锁的"if (mode == 'read') or (mode == 'write' and redis.call('hexists', KEYS[1], ARGV[3]) == 1) then " +//hincrby myLock UUID2:ThreadID2 1//ind表示重入次数,线程可以重入自己的读锁和写锁,线程后加的读锁可以重入线程自己的读锁或写锁"local ind = redis.call('hincrby', KEYS[1], ARGV[2], 1); " + //key = {myLock}:UUID2:ThreadID2:rwlock_timeout:1"local key = KEYS[2] .. ':' .. ind;" +//set {myLock}:UUID2:ThreadID2:rwlock_timeout:1 1"redis.call('set', key, 1); " +//pexpire myLock 30000"redis.call('pexpire', key, ARGV[1]); " +"local remainTime = redis.call('pttl', KEYS[1]); " +//pexpire {myLock}:UUID2:ThreadID2:rwlock_timeout:1 30000"redis.call('pexpire', KEYS[1], math.max(remainTime, ARGV[1])); " +"return nil; " +"end;" +//执行命令"pttl myLock",返回myLock的剩余过期时间"return redis.call('pttl', KEYS[1]);",//KEYS[1] = myLock//KEYS[2] = {myLock}:UUID2:ThreadID2:rwlock_timeoutArrays.<Object>asList(getRawName(), getReadWriteTimeoutNamePrefix(threadId)),unit.toMillis(leaseTime),//ARGV[1] = 30000getLockName(threadId),//ARGV[2] = UUID2:ThreadID2getWriteLockName(threadId)//ARGV[3] = UUID2:ThreadID2:write);}...
}
客户端B(UUID2:ThreadID2)加读锁时的参数:
KEYS[1] = myLock
KEYS[2] = {myLock}:UUID2:ThreadID2:rwlock_timeout
ARGV[1] = 30000
ARGV[2] = UUID2:ThreadID2
ARGV[3] = UUID2:ThreadID2:write
客户端B(UUID2:ThreadID2)加读锁时:首先执行命令"hget myLock mode"发现mode = write,说明已有线程加了锁了。接下来执行命令"hexists myLock UUID2:ThreadID2:write",发现不存在。也就是说,如果客户端B之前加过写锁,此时B加读锁才能通过判断。但是,之前加写锁的是客户端A,所以这里的判断条件不会通过。于是返回"pttl myLock",导致加读锁失败,会在while循环中阻塞和重试,从而实现先写锁后读锁的互斥。
(3)总结
如果客户端线程A之前先加了写锁,此时该线程再加读锁,可以成功。
如果客户端线程A之前先加了写锁,此时该线程再加写锁,可以成功。
如果客户端线程A之前先加了读锁,此时该线程再加读锁,可以成功。
如果客户端线程A之前先加了读锁,此时该线程再加写锁,不可以成功。
所以写锁可以被自己的写锁重入,也可以被自己的读锁重入。但是读锁可以被任意的读锁重入,不可以被任意的写锁重入。
5.写锁RedissonWriteLock的写写互斥逻辑
(1)不同客户端线程先加写锁的情况
假设客户端A(UUID1:ThreadID1)先加写锁:
//传入参数
KEYS[1] = myLock
ARGV[1] = 30000
ARGV[2] = UUID1:ThreadID1:write
//执行结果
myLock: {"mode": "write","UUID1:ThreadID1:write": 1
}
(2)不同客户端线程再加写锁的情况
假设客户端B(UUID2:ThreadID2)再加写锁:首先执行命令"hget myLock mode"发现mode = write,说明已有线程加了写锁。然后继续执行命令"hexists myLock UUID2:ThreadID2:write",判断已加的写锁是否是当前客户端B(UUID2:ThreadID2)加的。由于已加的写锁是客户端A(UUID1:ThreadID1)加的,所以判断不通过。于是执行"pttl myLock"返回myLock的剩余过期时间。这样会导致客户端B加写锁失败,于是会在while循环阻塞和重试加写锁,从而实现不同客户端线程的写锁和写锁的互斥。
public class RedissonWriteLock extends RedissonLock implements RLock {...@Override<T> RFuture<T> tryLockInnerAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {return evalWriteAsync(getRawName(), LongCodec.INSTANCE, command,//执行命令"hget myLock mode",尝试获取一个Hash值mode"local mode = redis.call('hget', KEYS[1], 'mode'); " +//获取不到,说明没有加读锁或者写锁"if (mode == false) then " +"redis.call('hset', KEYS[1], 'mode', 'write'); " +"redis.call('hset', KEYS[1], ARGV[2], 1); " +"redis.call('pexpire', KEYS[1], ARGV[1]); " +"return nil; " +"end; " +//如果加过锁,那么就要看是不是写锁+写锁是不是自己加过的(即重入写锁)"if (mode == 'write') then " +"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +//重入写锁"redis.call('hincrby', KEYS[1], ARGV[2], 1); " + "local currentExpire = redis.call('pttl', KEYS[1]); " +"redis.call('pexpire', KEYS[1], currentExpire + ARGV[1]); " +"return nil; " +"end; " +"end;" +//执行命令"pttl myLock",返回myLock的剩余过期时间"return redis.call('pttl', KEYS[1]);",Arrays.<Object>asList(getRawName()),//KEYS[1] = myLockunit.toMillis(leaseTime),//ARGV[1] = 30000getLockName(threadId)//ARGV[2] = UUID1:ThreadID1:write 或 ARGV[2] = UUID2:ThreadID2:write);}...
}
6.写锁RedissonWriteLock的可重入逻辑
前面分析了不同客户端线程的四种加锁情况:
情况一:先加读锁再加读锁,不互斥
情况二:先加读锁再加写锁,互斥
情况三:先加写锁再加读锁,互斥
情况四:先加写锁再加写锁,互斥
接下来分析同一个客户端线程的四种加锁情况:
情况一:先加读锁再加读锁,不互斥
情况二:先加读锁再加写锁,互斥
情况三:先加写锁再加读锁,不互斥
情况四:先加写锁再加写锁,不互斥
可以这样理解:写锁优先级高,读锁优先级低。同一个线程如果先加了优先级高的写锁,那就可以继续加优先级低的读锁。同一个线程如果先加了优先级低的读锁,那就不可以再加优先级高的写锁。一般锁可以降级,不可以升级。
(1)同一个客户端线程先加读锁再加读锁
客户端A(UUID1:ThreadID1)先加了一次读锁时:
//传入参数
KEYS[1] = myLock
KEYS[2] = {myLock}:UUID1:ThreadID1:rwlock_timeout ARGV[1] = 30000
ARGV[2] = UUID1:ThreadID1
ARGV[3] = UUID1:ThreadID1:write//执行结果
//Hash结构
myLock: {"mode": "read","UUID1:ThreadID1": 1
}
//String结构
{myLock}:UUID1:ThreadID1:rwlock_timeout:1 ==> 1
客户端A(UUID1:ThreadID1)再加一次读锁时,判断通过可以加成功。
//执行命令
hget myLock mode,发现mode=read,表示已经加过读锁
hincrby myLock UUID1:ThreadID1 1
set {myLock}:UUID1:ThreadID1:rwlock_timeout:2 1
pexpire myLock 30000
pexpire {myLock}:UUID1:ThreadID1:rwlock_timeout:2 30000//执行结果
//Hash结构
myLock: {"mode": "read","UUID1:ThreadID1": 2
}
//String结构
{myLock}:UUID1:ThreadID1:rwlock_timeout:1 ==> 1
{myLock}:UUID1:ThreadID1:rwlock_timeout:2 ==> 1
(2)同一个客户端线程先加读锁再加写锁
客户端A(UUID1:ThreadID1)先加了一次读锁时:
//传入参数
KEYS[1] = myLock
KEYS[2] = {myLock}:UUID1:ThreadID1:rwlock_timeout ARGV[1] = 30000
ARGV[2] = UUID1:ThreadID1
ARGV[3] = UUID1:ThreadID1:write//执行结果
//Hash结构
myLock: {"mode": "read","UUID1:ThreadID1": 1
}
//String结构
{myLock}:UUID1:ThreadID1:rwlock_timeout:1 ==> 1
客户端A(UUID1:ThreadID1)再加一次写锁时,判断不通过,不可以加成功。
//传入参数
KEYS[1] = myLock
ARGV[1] = 30000
ARGV[2] = UUID1:ThreadID1:write
执行命令"hget myLock mode",发现mode = read,不符合加写锁条件。所以同一个客户端线程,先加读锁再加写锁,是会互斥的。
(3)同一个客户端线程先加写锁再加读锁
客户端A(UUID1:ThreadID1)先加了一次写锁时:
//传入参数
KEYS[1] = myLock
ARGV[1] = 30000
ARGV[2] = UUID1:ThreadID1:write//执行结果
myLock: {"mode": "write","UUID1:ThreadID1:write": 1
}
客户端A(UUID1:ThreadID1)再加一次读锁时,判断通过,可以加成功。
//传入参数
KEYS[1] = myLock
KEYS[2] = {myLock}:UUID1:ThreadID1:rwlock_timeout
ARGV[1] = 30000
ARGV[2] = UUID1:ThreadID1
ARGV[3] = UUID1:ThreadID1:write//执行命令
hget myLock mode,发现mode=write,表示已经加过写锁
hexists myLock UUID1:ThreadID1:write,判断写锁是自己加的,条件成立
hincrby myLock UUID1:ThreadID1 1,表示此时加了一个读锁
set {myLock}:UUID1:ThreadID1:rwlock_timeout:1 1
pexpire myLock 30000
pexpire {myLock}:UUID1:ThreadID11:rwlock_timeout:1 30000//执行结果
//Hash结构
myLock: {"mode": "write","UUID1:ThreadID1:write": 1,"UUID1:ThreadID1": 1
}
//String结构
{myLock}:UUID1:ThreadID1:rwlock_timeout:1 ==> 1
可见:如果是同一个客户端线程,先加写锁再加读锁,是可以加成功的。所以默认在线程持有写锁的期间,同样的线程可以多次加读锁。
(4)同一个客户端线程先加写锁再加写锁
客户端A(UUID1:ThreadID1)先加了一次写锁时:
//传入参数
KEYS[1] = myLock
ARGV[1] = 30000
ARGV[2] = UUID1:ThreadID1:write//执行结果
myLock: {"mode": "write","UUID1:ThreadID1:write": 1
}
客户端A(UUID1:ThreadID1)再加一次写锁时,判断通过,可以加成功。
//执行命令
hexists myLock UUID1:ThreadID1:write,判断是否是自己加的写锁
hincrby myLock UUID1:ThreadID1:write 1
pexpire myLock 50000//执行结果
myLock: {"mode": "write","UUID1:ThreadID1:write": 2
}
可见:读写锁也是一种可重入锁。同一个客户端线程多次加写锁,是可以重入加锁的。先加的写锁是可以被读锁重入,先加的读锁则不可以被写锁重入。
7.读锁RedissonReadLock的释放读锁逻辑
(1)RedissonReadLock的释放读锁的流程
释放读锁调用的是RedissonLock的unlock()方法。
在RedissonLock的unlock()方法中,会执行get(unlockAsync())代码。也就是首先调用RedissonBaseLock的unlockAsync()方法,然后调用RedissonObject的get()方法。
其中unlockAsync()方法是异步化执行的方法,释放锁的操作就是异步执行的。而RedisObject的get()方法会通过RFuture同步等待获取异步执行的结果,可以将get(unlockAsync())理解为异步转同步。
在RedissonBaseLock的unlockAsync()方法中:可重入锁会调用RedissonLock.unlockInnerAsync()方法进行异步释放锁,读锁则会调用RedissonReadLock的unlockInnerAsync()方法进行异步释放锁,然后当完成释放锁的处理后,再通过异步去取消定时调度任务。
public class Application {public static void main(String[] args) throws Exception {Config config = new Config();config.useClusterServers().addNodeAddress("redis://192.168.1.110:7001");//读写锁RedissonClient redisson = Redisson.create(config);RReadWriteLock rwlock = redisson.getReadWriteLock("myLock");rwlock.readLock().lock();//获取读锁rwlock.readLock().unlock();//释放读锁rwlock.writeLock().lock();//获取写锁rwlock.writeLock().unlock();//释放写锁...}
}
public class RedissonLock extends RedissonBaseLock {...@Overridepublic void unlock() {...//异步转同步//首先调用的是RedissonBaseLock的unlockAsync()方法//然后调用的是RedissonObject的get()方法get(unlockAsync(Thread.currentThread().getId()));...}...
}
public abstract class RedissonBaseLock extends RedissonExpirable implements RLock {...@Overridepublic RFuture<Void> unlockAsync(long threadId) {//异步执行释放锁的lua脚本RFuture<Boolean> future = unlockInnerAsync(threadId);CompletionStage<Void> f = future.handle((opStatus, e) -> {//取消定时调度任务cancelExpirationRenewal(threadId);if (e != null) {throw new CompletionException(e);}if (opStatus == null) {IllegalMonitorStateException cause = new IllegalMonitorStateException("attempt to unlock lock, not locked by current thread by node id: " + id + " thread-id: " + threadId);throw new CompletionException(cause);}return null;});return new CompletableFutureWrapper<>(f);}protected abstract RFuture<Boolean> unlockInnerAsync(long threadId);...
}public class RedissonReadLock extends RedissonLock implements RLock {...@Overrideprotected RFuture<Boolean> unlockInnerAsync(long threadId) {String timeoutPrefix = getReadWriteTimeoutNamePrefix(threadId);String keyPrefix = getKeyPrefix(threadId, timeoutPrefix);return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,"...",Arrays.<Object>asList(getRawName(), getChannelName(), timeoutPrefix, keyPrefix),LockPubSub.UNLOCK_MESSAGE,getLockName(threadId));}...
}
(2)释放读锁前主要三种情况
情况一:不同客户端线程加了读锁
//Hash结构
myLock: {"mode": "read","UUID1:ThreadID1": 1,"UUID2:ThreadID2": 1,
}
//String结构
{myLock}:UUID1:ThreadID1:rwlock_timeout:1 ==> 1
{myLock}:UUID2:ThreadID2:rwlock_timeout:1 ==> 1
情况二:同一个客户端线程多次重入加读锁
//Hash结构
myLock: {"mode": "read","UUID1:ThreadID1": 2
}
//String结构
{myLock}:UUID1:ThreadID1:rwlock_timeout:1 ==> 1
{myLock}:UUID1:ThreadID1:rwlock_timeout:2 ==> 1
情况一可以和情况二进行合并:
//Hash结构
myLock: {"mode": "read","UUID1:ThreadID1": 2,"UUID2:ThreadID2": 1,
}
//String结构
{myLock}:UUID1:ThreadID1:rwlock_timeout:1 ==> 1
{myLock}:UUID1:ThreadID1:rwlock_timeout:2 ==> 1
{myLock}:UUID2:ThreadID2:rwlock_timeout:1 ==> 1
情况三:同一个客户端线程先加写锁再加读锁
//Hash结构
myLock: {"mode": "write","UUID1:ThreadID1:write": 1,"UUID1:ThreadID1": 1
}
//String结构
{myLock}:UUID1:ThreadID1:rwlock_timeout:1 ==> 1
(3)RedissonReadLock的释放读锁的lua脚本
public class RedissonReadLock extends RedissonLock implements RLock {...@Overrideprotected RFuture<Boolean> unlockInnerAsync(long threadId) {String timeoutPrefix = getReadWriteTimeoutNamePrefix(threadId);String keyPrefix = getKeyPrefix(threadId, timeoutPrefix);return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,//执行命令"hget myLock mode""local mode = redis.call('hget', KEYS[1], 'mode'); " +//如果mode为false就发布一个消息"if (mode == false) then " +"redis.call('publish', KEYS[2], ARGV[1]); " +"return 1; " +"end; " +//执行命令"hexists myLock UUID1:ThreadIdD1",判断当前线程对应的Hash值是否存在"local lockExists = redis.call('hexists', KEYS[1], ARGV[2]); " +"if (lockExists == 0) then " +"return nil;" +"end; " +//执行命令"hincrby myLock UUID1:ThreadID1 -1",递减当前线程对应的Hash值 "local counter = redis.call('hincrby', KEYS[1], ARGV[2], -1); " + "if (counter == 0) then " +"redis.call('hdel', KEYS[1], ARGV[2]); " + "end;" +//例如执行"del {myLock}:UUID1:ThreadId1:rwlock_timeout:2"//删除当前客户端线程UUID1:ThreadId1的一个重入读锁;"redis.call('del', KEYS[3] .. ':' .. (counter+1)); " +//执行命令"hlen myLock > 1",判断Hash里的元素是否超过1个"if (redis.call('hlen', KEYS[1]) > 1) then " +"local maxRemainTime = -3; " + //获取key为锁名的Hash值的所有key"local keys = redis.call('hkeys', KEYS[1]); " + //遍历这些key,获取这些重入和非重入的读锁的最大剩余过期时间"for n, key in ipairs(keys) do " + "counter = tonumber(redis.call('hget', KEYS[1], key)); " + //把key为mode的kv对排除"if type(counter) == 'number' then " + //通过递减拼接重入锁的key"for i=counter, 1, -1 do " + "local remainTime = redis.call('pttl', KEYS[4] .. ':' .. key .. ':rwlock_timeout:' .. i); " + "maxRemainTime = math.max(remainTime, maxRemainTime);" + "end; " + "end; " + "end; " +//找出所有重入的和非重入的读锁的最大剩余过期时间后,就重置锁的过期时间为该时间"if maxRemainTime > 0 then " +"redis.call('pexpire', KEYS[1], maxRemainTime); " +"return 0; " +"end;" + "if mode == 'write' then " + "return 0;" + "end; " +"end; " +//删除锁"redis.call('del', KEYS[1]); " +//发布一个事件"redis.call('publish', KEYS[2], ARGV[1]); " +"return 1; ",//KEYS[1] = myLock,表示锁的名字//KEYS[2] = redisson_rwlock:{myLock},用于Redis的发布订阅用//KEYS[3] = {myLock}:UUID1:ThreadID1:rwlock_timeout//KEYS[4] = {myLock}Arrays.<Object>asList(getRawName(), getChannelName(), timeoutPrefix, keyPrefix),LockPubSub.UNLOCK_MESSAGE,//ARGV[1] = 0,表示发布事件类型getLockName(threadId)//ARGV[2] = UUID1:ThreadID1,表示锁里面的该客户端线程代表的key);}...
}
参数说明:
KEYS[1] = myLock,表示锁的名字
KEYS[2] = redisson_rwlock:{myLock},用于Redis的发布订阅用
KEYS[3] = {myLock}:UUID1:ThreadID1:rwlock_timeout
KEYS[4] = {myLock}
ARGV[1] = 0,表示发布事件类型
ARGV[2] = UUID1:ThreadID1,表示锁里面的该客户端线程代表的key
(4)对合并的情况一和情况二执行lua脚本
一.客户端A(UUID1:ThreadID1)先释放一次读锁
二.客户端A(UUID1:ThreadID1)再释放一次读锁
三.客户端B(UUID2:ThreadID2)再释放一次读锁
//Hash结构
myLock: {"mode": "read","UUID1:ThreadID1": 2,"UUID2:ThreadID2": 1,
}
//String结构
{myLock}:UUID1:ThreadID1:rwlock_timeout:1 ==> 1
{myLock}:UUID1:ThreadID1:rwlock_timeout:2 ==> 1
{myLock}:UUID2:ThreadID2:rwlock_timeout:1 ==> 1
一.客户端A(UUID1:ThreadID1)先释放一次读锁
首先执行命令"hget myLock mode",发现mode = read。然后执行命令"hexists myLock UUID1:ThreadIdD1",发现肯定是存在的,因为这个客户端线程UUID1:ThreadIdD1加过读锁。
接着执行命令"hincrby myLock UUID1:ThreadID1 -1",将这个客户端线程对应的加读锁次数递减1,counter由2变成1。当counter大于1,说明还有线程持有着这个读锁。于是接着执行"del {myLock}:UUID1:ThreadId1:rwlock_timeout:2",也就是删除用来记录当前客户端线程第2个重入锁过期时间的key。
此时myLock锁的数据变成如下:
//Hash结构
myLock: {"mode": "read","UUID1:ThreadID1": 1,"UUID2:ThreadID2": 1,
}
//String结构
{myLock}:UUID1:ThreadID1:rwlock_timeout:1 ==> 1
{myLock}:UUID2:ThreadID2:rwlock_timeout:1 ==> 1
于是接着执行命令"hlen myLock",判断Hash里的元素是否超过1个。如果超过1,那么就遍历已被线程获取的所有重入和非重入的读锁,即遍历所有类似"{myLock}:UUID2:ThreadID2:rwlock_timeout:1"的key。
然后接着执行命令"pttl {myLock}:UUID1:ThreadID1:rwlock_timeout:1"。即获取每一个重入读锁和非重入读锁的剩余过期时间,并找出其中最大的。执行"pexpire myLock"重置读锁的过期时间,为最大的剩余过期时间。
二.客户端A(UUID1:ThreadID1)再释放一次读锁
首先执行命令"hincrby myLock UUID1:ThreadID1 -1",将这个客户端线程对应的加读锁次数递减1,counter由1变成0。当counter=0时,就执行命令"hdel myLock UUID1:ThreadID1",即删除用来记录当前客户端线程重入锁次数的key。
然后接着执行命令"del {myLock}:UUID1:ThreadID1:rwlock_timeout:1",即删除用来记录当前客户端线程第1个重入锁过期时间的key。最后获取每个重入读锁和非重入读锁的剩余过期时间,并找出其中最大的。执行"pexpire myLock"重置读锁的过期时间,为最大的剩余过期时间。
此时myLock锁的数据变成如下:
//Hash结构
myLock: {"mode": "read","UUID2:ThreadID2": 1,
}
//String结构
{myLock}:UUID2:ThreadID2:rwlock_timeout:1 ==> 1
三.客户端B(UUID2:ThreadID2)再释放一次读锁
首先执行命令"hincrby myLock UUID2:ThreadID2 -1",将这个客户端线程对应的加读锁次数递减1,counter由1变成0。然后执行命令"hdel myLock UUID2:ThreadID2",即删除用来记录当前客户端线程重入锁次数的key。接着执行命令"del {myLock}:UUID1:ThreadID1:rwlock_timeout:1",即删除用来记录当前客户端线程第1个重入锁过期时间的key。
此时myLock锁的数据变成如下:
//Hash结构
myLock: {"mode": "read"
}
此时继续执行命令"hlen myLock",发现为1,判断不通过,于是执行"del myLock"。也就是当没有线程再持有这个读锁时,就会彻底删除这个读锁,然后发布一个事件出去。
(5)对情况三执行lua脚本
这种情况是:同一个客户端线程先加写锁再加读锁。此时myLock锁的数据如下:
//Hash结构
myLock: {"mode": "write","UUID1:ThreadID1:write": 1,"UUID1:ThreadID1": 1
}
//String结构
{myLock}:UUID1:ThreadID1:rwlock_timeout:1 ==> 1
首先执行命令"hincrby myLock UUID1:ThreadID1 -1",将这个客户端线程对应的加读锁次数递减1,counter由1变成0。然后执行命令"hdel myLock UUID1:ThreadID1",即删除用来记录当前客户端线程重入锁次数的key。接着执行"del {myLock}:UUID1:ThreadID1:rwlock_timeout:1",即删除用来记录当前客户端线程第1个重入锁过期时间的key。
此时myLock锁的数据变成如下:
//Hash结构
myLock: {"mode": "write","UUID1:ThreadID1:write": 1
}
接着执行命令"hlen myLock > 1",判断Hash里的元素是否超过1个。发现判断通过,但由于没有了读锁,所以最后会判断mode如果是write,就返回0。
8.写锁RedissonWriteLock的释放写锁逻辑
(1)释放写锁前主要有两种情况
情况一:同一个客户端线程多次重入加写锁
情况二:同一个客户端线程先加写锁再加读锁
这两种情况的锁数据可以合并为如下:
//Hash结构
myLock: {"mode": "write","UUID1:ThreadID1:write": 2,"UUID1:ThreadID1": 1
}
//String结构
{myLock}:UUID1:ThreadID1:rwlock_timeout:1 ==> 1
接下来以这种锁数据为前提进行lua脚本分析。
(2)RedissonWriteLock的释放写锁的lua脚本
public class RedissonWriteLock extends RedissonLock implements RLock {...@Overrideprotected RFuture<Boolean> unlockInnerAsync(long threadId) {return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,//首先执行命令"hget myLock mode",发现mode=write"local mode = redis.call('hget', KEYS[1], 'mode'); " +"if (mode == false) then " +"redis.call('publish', KEYS[2], ARGV[1]); " +"return 1; " +"end;" +"if (mode == 'write') then " +//然后执行命令"hexists myLock UUID1:ThreadIdD1:write",发现存在"local lockExists = redis.call('hexists', KEYS[1], ARGV[3]); " +"if (lockExists == 0) then " +"return nil;" +"else " +//于是接着执行命令"hincrby myLock UUID1:ThreadID1:write -1""local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " +"if (counter > 0) then " +//当counter大于0,说明还有线程持有写锁,那么就重置锁的过期时间"redis.call('pexpire', KEYS[1], ARGV[2]); " +"return 0; " +"else " +//当counter为0,就执行命令"hdel myLock UUID1:ThreadID1:write""redis.call('hdel', KEYS[1], ARGV[3]); " +//判断key为锁名的Hash里元素是否超过1个"if (redis.call('hlen', KEYS[1]) == 1) then " +//如果只有1个,则说明没有线程持有锁了,此时可以删除掉锁对应的key"redis.call('del', KEYS[1]); " +"redis.call('publish', KEYS[2], ARGV[1]); " + "else " +//如果有超过1个,则说明还有线程持有读锁,此时需要将写锁转读锁"redis.call('hset', KEYS[1], 'mode', 'read'); " +"end; " +"return 1; "+"end; " +"end; " +"end; " +"return nil;",//KEYS[1] = myLock,KEYS[2] = redisson_rwlock:{myLock}Arrays.<Object>asList(getRawName(), getChannelName()),LockPubSub.READ_UNLOCK_MESSAGE,//ARGV[1] = 0internalLockLeaseTime,//ARGV[2] = 30000getLockName(threadId)//ARGV[3] = UUID1:ThreadID1:write);}...
}
(3)执行释放写锁的lua脚本
一.参数说明
KEYS[1] = myLock
KEYS[2] = redisson_rwlock:{myLock}
ARGV[1] = 0
ARGV[2] = 30000
ARGV[3] = UUID1:ThreadID1:write
二.lua脚本执行分析
首先执行命令"hget myLock mode",发现mode = write。然后执行命令"hexists myLock UUID1:ThreadIdD1:write",发现存在。于是接着执行命令"hincrby myLock UUID1:ThreadID1:write -1",也就是将这个客户端线程对应的加写锁次数递减1,counter由2变成1。当counter大于0,说明还有线程持有写锁,那么就重置锁的过期时间。当counter为0,就执行命令"hdel myLock UUID1:ThreadID1:write",即删除用来记录当前客户端线程重入写锁次数的key。
删除后,myLock的锁数据如下:
//Hash结构
myLock: {"mode": "write","UUID1:ThreadID1": 1
}
//String结构
{myLock}:UUID1:ThreadID1:rwlock_timeout:1 ==> 1
接着执行命令"hlen myLock",判断key为锁名的Hash里元素是否超过1个。如果只有1个,则说明没有线程持有锁了,此时可以删除掉锁对应的key。如果有超过1个,则说明还有线程持有读锁,此时需要将写锁转读锁。
因此,最后myLock的锁数据如下:
//Hash结构
myLock: {"mode": "read","UUID1:ThreadID1": 1
}
//String结构
{myLock}:UUID1:ThreadID1:rwlock_timeout:1 ==> 1
9.Redisson联锁MultiLock的加锁与释放锁
(1)联锁的获取(超时时间限制 + 加锁失败数限制)
一.RedissonMultiLock的lockInterruptibly()方法每次while循环获取所有锁
加锁的时候,首先会调用RedissonMultiLock的lock()方法,接着会调用RedissonMultiLock的lockInterruptibly()方法
在RedissonMultiLock的lockInterruptibly()方法中,会先根据联锁的个数来计算获取锁时的等待时间waitTime,然后通过while循环不停地尝试调用tryLock()方法去获取所有的锁。只有获取到所有的锁,while循环才会退出。
二.RedissonMultiLock的tryLock()方法获取锁有超时时间限制 + 加锁失败数限制
在RedissonMultiLock的tryLock()方法中,会依次遍历需要获取的锁,然后调用RLock的tryLock()方法尝试获取每个锁。比如调用可重入锁RedissonLock的tryLock()方法来尝试获取每个锁。
假设传入的leaseTime = -1,waitTime = 4500,计算出remainTime = 4500。那么传入RedissonLock的tryLock()方法中的参数waitTime为4500,即指定了获取每个锁时的等待超时时间为4500毫秒。如果在4500毫秒内获取不到这个锁,就退出并标记为获取锁失败。此外传入RedissonLock的tryLock()方法中的参数newLeaseTime为-1。表示获取到锁之后,这个锁在多长时间内会自动释放。由于leaseTime是-1,所以newLeaseTime也是-1。所以如果获取到了锁,会启动一个WatchDog在10秒之后去检查锁的持有情况。
在RedissonMultiLock的tryLock()方法的遍历获取锁的for循环中,有两个限制。
限制一:超时时间限制
当获取锁成功时,就将该锁实例添加到一个列表。但不管获取锁成功还是失败,都会递减remainTime。其实remainTime就是获取MultiLock的超时时间,默认每个锁1500毫秒。当发现remainTime小于0,则表示此次获取联锁失败,需释放获取的锁。此时RedissonMultiLock的tryLock()方法便会返回false,继续下一轮尝试。
限制二:加锁失败数限制
当获取锁失败时,先判断是否达到加锁成功的最少数量。如果达到,就可以退出循环,并进行返回。如果还没达到,就对failedLocksLimit递减。当发现failedLocksLimit为0,则表示此次获取联锁失败,需释放获取的锁,同时重置failedLocksLimit的值+清空acquiredLocks+复位锁列表的迭代器,为下一次尝试获取全部锁做准备。也就是RedissonMultiLock.tryLock()方法会返回false,继续下一轮尝试。
三.RedisonMultiLock的tryLock()方法获取所有锁失败会继续重试
当RedissonMultiLock的tryLock()方法返回false时,在RedissonMultiLock的lockInterruptibly()方法的while循环中,会再次调用RedissonMultiLock的tryLock()方法来尝试获取联锁。
四.总结
假设要获取的联锁中有n把锁,那么可能会循环很多次去尝试获取这n把锁。默认情况下,每次获取这n把锁的时候,会有一个超时时间为1500n毫秒。也就是说,如果第一次获取这n把锁时,在1500n毫秒内无法获取这n把锁。那么就会继续调用tryLock方法进行下一次尝试,重新再来获取这n把锁。直到某一次成功在1500*n毫秒内获取到这n把锁,那么就会退出循环。
public class RedissonMultiLock implements RLock {final List<RLock> locks = new ArrayList<>();public RedissonMultiLock(RLock... locks) {...this.locks.addAll(Arrays.asList(locks));}@Overridepublic void lock() {...lockInterruptibly();...}@Overridepublic void lockInterruptibly() throws InterruptedException {lockInterruptibly(-1, null);}@Overridepublic void lockInterruptibly(long leaseTime, TimeUnit unit) throws InterruptedException {//根据联锁的个数来计算获取锁时的等待时间waitTime//此时MutiLock中有3个锁,leaseTime=-1,baseWaitTime=4500,waitTime=4500long baseWaitTime = locks.size() * 1500;long waitTime = -1;if (leaseTime == -1) {//传入的leaseTime为-1,将baseWaitTime赋值给waitTimewaitTime = baseWaitTime;} else {...}//不停地尝试去获取所有的锁while (true) {//只有获取到所有的锁,while循环才会退出if (tryLock(waitTime, leaseTime, TimeUnit.MILLISECONDS)) {return;}}}@Overridepublic boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {//此时传入的leaseTime=-1,waitTime=4500,计算出remainTime=4500long newLeaseTime = -1;...//time=当前时间long time = System.currentTimeMillis();long remainTime = -1;if (waitTime != -1) {//remainTime=4500remainTime = unit.toMillis(waitTime);}//RedissonRedLock会重载calcLockWaitTime()方法,缩短了获取每个小锁的超时时间//比如RedissonRedLock.calcLockWaitTime()方法返回1500//RedissonMultiLock.calcLockWaitTime()方法返回4500long lockWaitTime = calcLockWaitTime(remainTime);//RedissonRedLock会重载failedLocksLimit()方法,返回可以允许最多有多少个锁获取失败//比如RedissonMultiLock.failedLocksLimit()方法返回0,表示不允许存在某个锁获取失败int failedLocksLimit = failedLocksLimit();//acquiredLocks用来保存已获取到的锁List<RLock> acquiredLocks = new ArrayList<>(locks.size());//依次遍历要获取的锁for (ListIterator<RLock> iterator = locks.listIterator(); iterator.hasNext();) {RLock lock = iterator.next();boolean lockAcquired;...if (waitTime == -1 && leaseTime == -1) {lockAcquired = lock.tryLock();} else {//awaitTime=4500long awaitTime = Math.min(lockWaitTime, remainTime);//获取锁的核心方法RLock.tryLock(),比如RedissonLock.tryLock()方法//如果在awaitTime=4500毫秒内获取不到这个锁,就退出并标记为获取锁失败lockAcquired = lock.tryLock(awaitTime, newLeaseTime, TimeUnit.MILLISECONDS);}...if (lockAcquired) {//成功获取锁,就将锁实例添加到acquiredLocksacquiredLocks.add(lock);} else {if (locks.size() - acquiredLocks.size() == failedLocksLimit()) {break;}//获取锁失败,就对failedLocksLimit递减,直到failedLocksLimit为0就返回falseif (failedLocksLimit == 0) {//此次获取联锁失败,需释放获取的锁unlockInner(acquiredLocks);if (waitTime == -1) {return false;}//重置failedLocksLimit的值,为下一次尝试获取全部锁做准备failedLocksLimit = failedLocksLimit();//清空acquiredLocks,为下一次尝试获取全部锁做准备acquiredLocks.clear();//复位锁列表的迭代器while (iterator.hasPrevious()) {iterator.previous();}} else {//递减failedLocksLimitfailedLocksLimit--;}}//递减remainTime,如果remainTime小于0,表示获取联锁失败if (remainTime != -1) {remainTime -= System.currentTimeMillis() - time;time = System.currentTimeMillis();//如果发现remainTime小于0,则表示此次获取联锁失败if (remainTime <= 0) {unlockInner(acquiredLocks);return false;}}}if (leaseTime != -1) {acquiredLocks.stream().map(l -> (RedissonLock) l).map(l -> l.expireAsync(unit.toMillis(leaseTime), TimeUnit.MILLISECONDS)).forEach(f -> f.toCompletableFuture().join());}return true;}...
}
(2)联锁的释放(依次释放锁 + 同步等待锁释放完毕)
释放锁就是依次调用每个锁的释放逻辑,同步等待每个锁释放完毕才返回。
public class RedissonMultiLock implements RLock {...@Overridepublic void unlock() {List<RFuture<Void>> futures = new ArrayList<>(locks.size());//依次调用每个锁的释放逻辑for (RLock lock : locks) {futures.add(lock.unlockAsync());}for (RFuture<Void> future : futures) {//同步等待每个锁释放完毕future.toCompletableFuture().join();}}...
}
10.Redisson红锁RedLock的实现
(1)RedLock算法的具体流程
步骤一:客户端先获取当前时间戳T1。
步骤二:客户端依次向这5个节点发起加锁请求,且每个请求都会设置超时时间。超时时间是毫秒级的,要远小于锁的有效时间,而且一般是几十毫秒。如果某一个节点加锁失败,包括网络超时、锁被其它线程持有等各种情况,那么就立即向下一个Redis节点申请加锁。
步骤三:如果客户端从3个以上(过半)节点加锁成功,则再次获取当前时间戳T2。如果T2 - T1 < 锁的过期时间,则认为客户端加锁成功,否则加锁失败。
步骤四:如果加锁失败,要向全部节点发起释放锁的请求。如果加锁成功,则去操作共享资源。
(2)RedLock算法的四个要点总结
一.客户端在多个Redis节点上申请加锁
二.必须保证大多数节点加锁成功
三.大多数节点加锁的总耗时 < 锁设置的过期时间
四.释放锁时要向全部节点发起释放锁的请求
(3)RedLock的使用简介
//红锁
RedissonClient redissonInstance1 = Redisson.create(config);
RedissonClient redissonInstance2 = Redisson.create(config);
RedissonClient redissonInstance3 = Redisson.create(config);
RLock lock1 = redissonInstance1.getLock("lock1");
RLock lock2 = redissonInstance2.getLock("lock2");
RLock lock3 = redissonInstance3.getLock("lock3");
RedissonRedLock lock = new RedissonRedLock(lock1, lock2, lock3);//同时加锁:lock1 lock2 lock3
//红锁在大部分节点上加锁成功就算成功
lock.lock();
lock.unlock();
//给lock1、lock2、lock3加锁;如果没有主动释放锁的话,10秒后将会自动释放锁
lock.lock(10, TimeUnit.SECONDS);//加锁等待最多是100秒;加锁成功后如果没有主动释放锁的话,锁会在10秒后自动释放
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
lock.unlock();
(4)RedLock的实现
RedissonRedLock锁的实现非常简单,因为RedissonRedLock是RedissonMultiLock的一个子类,所以RedLock的算法是依赖MultiLock的机制来实现的。
RedissonRedLock主要会通过方法的重载,来改变RedissonMultiLock中的几个特殊行为。
一.RedissonRedLock重载了RedissonMultiLock的failedLocksLimit()方法
failedLocksLimit()方法会返回允许最多有多少个锁获取失败。其中failedLocksLimit()方法会调用minLocksAmount()方法,而minLocksAmount()方法便会返回加锁成功的最少数量,即过半数。锁的总数减去加锁成功的最少数量,便是允许最多有多少个锁获取失败。
RedissonMultiLock的failedLocksLimit()方法是返回0的,即RedissonMultiLock是不允许存在某个锁获取失败。
具体的处理就是在RedissonMultiLock的tryLock()方法中,当获取锁失败时,先判断是否达到加锁成功的最少数量。如果达到,就可以退出循环,并进行返回。如果还没达到,就对failedLocksLimit递减。当发现failedLocksLimit为0,则表示此次获取联锁失败,需要释放获取的锁,同时重置failedLocksLimit的值 + 清空acquiredLocks + 复位锁列表的迭代器,为下一次尝试获取全部锁做准备。也就是RedissonMultiLock的tryLock()方法会返回false,继续下一轮尝试。
二.RedissonRedLock重载了RedissonMultiLock的calcLockWaitTime()方法
calcLockWaitTime()方法会返回对每个lock进行加锁时的超时时间。例如当waitTime = 4500毫秒、remainTime = 4500毫秒时:RedissonMultiLock的calcLockWaitTime()方法会返回4500,RedissonRedLock的calcLockWaitTime()方法会返回1500。
RedissonMultiLock中对每个lock尝试加锁的超时时间为4500毫秒,RedissonRedLock中对每个lock尝试加锁的超时时间为1500毫秒。如果在超时时间内没获取到锁,那么就认为对lock的加锁失败。
public class RedissonRedLock extends RedissonMultiLock {public RedissonRedLock(RLock... locks) {super(locks);}//可以允许最多有多少个锁获取失败@Overrideprotected int failedLocksLimit() {return locks.size() - minLocksAmount(locks);}//获取锁成功的数量最少要多少个:过半protected int minLocksAmount(final List<RLock> locks) {return locks.size()/2 + 1;}@Overrideprotected long calcLockWaitTime(long remainTime) {return Math.max(remainTime / locks.size(), 1);}@Overridepublic void unlock() {unlockInner(locks);}
}
public class RedissonMultiLock implements RLock {...@Overridepublic void lockInterruptibly(long leaseTime, TimeUnit unit) throws InterruptedException {//根据联锁的个数来计算获取锁时的等待时间waitTime//此时MutiLock中有3个锁,leaseTime=-1,baseWaitTime=4500,waitTime=4500long baseWaitTime = locks.size() * 1500;long waitTime = -1;if (leaseTime == -1) {//传入的leaseTime为-1,将baseWaitTime赋值给waitTimewaitTime = baseWaitTime;} else {...}//不停地尝试去获取所有的锁while (true) {//只有获取到所有的锁,while循环才会退出if (tryLock(waitTime, leaseTime, TimeUnit.MILLISECONDS)) {return;}}}@Overridepublic boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {//此时传入的leaseTime=-1,waitTime=4500,计算出remainTime=4500long newLeaseTime = -1;...//time=当前时间long time = System.currentTimeMillis();long remainTime = -1;if (waitTime != -1) {//remainTime=4500remainTime = unit.toMillis(waitTime);}//RedissonRedLock会重载calcLockWaitTime()方法,缩短了获取每个小锁的超时时间//比如RedissonRedLock.calcLockWaitTime()方法返回1500//RedissonMultiLock.calcLockWaitTime()方法返回4500long lockWaitTime = calcLockWaitTime(remainTime);//RedissonRedLock会重载failedLocksLimit()方法,返回可以允许最多有多少个锁获取失败//比如RedissonMultiLock.failedLocksLimit()方法返回0,表示不允许存在某个锁获取失败int failedLocksLimit = failedLocksLimit();//acquiredLocks用来保存已获取到的锁List<RLock> acquiredLocks = new ArrayList<>(locks.size());//依次遍历要获取的锁for (ListIterator<RLock> iterator = locks.listIterator(); iterator.hasNext();) {RLock lock = iterator.next();boolean lockAcquired;...if (waitTime == -1 && leaseTime == -1) {lockAcquired = lock.tryLock();} else {//awaitTime=4500long awaitTime = Math.min(lockWaitTime, remainTime);//获取锁的核心方法RLock.tryLock(),比如RedissonLock.tryLock()方法//如果在awaitTime=4500毫秒内获取不到这个锁,就退出并标记为获取锁失败lockAcquired = lock.tryLock(awaitTime, newLeaseTime, TimeUnit.MILLISECONDS);}...if (lockAcquired) {//成功获取锁,就将锁实例添加到acquiredLocksacquiredLocks.add(lock);} else {//如果达到加锁成功的最少数量,就可以退出循环,进行返回了if (locks.size() - acquiredLocks.size() == failedLocksLimit()) {break;}//获取锁失败,就对failedLocksLimit递减,直到failedLocksLimit为0就返回falseif (failedLocksLimit == 0) {//此次获取联锁失败,需释放获取的锁unlockInner(acquiredLocks);if (waitTime == -1) {return false;}//重置failedLocksLimit的值,为下一次尝试获取全部锁做准备failedLocksLimit = failedLocksLimit();//清空acquiredLocks,为下一次尝试获取全部锁做准备acquiredLocks.clear();//复位锁列表的迭代器while (iterator.hasPrevious()) {iterator.previous();}} else {//递减failedLocksLimitfailedLocksLimit--;}}//递减remainTime,如果remainTime小于0,表示获取联锁失败if (remainTime != -1) {remainTime -= System.currentTimeMillis() - time;time = System.currentTimeMillis();//如果发现remainTime小于0,则表示此次获取联锁失败if (remainTime <= 0) {unlockInner(acquiredLocks);return false;}}}if (leaseTime != -1) {acquiredLocks.stream().map(l -> (RedissonLock) l).map(l -> l.expireAsync(unit.toMillis(leaseTime), TimeUnit.MILLISECONDS)).forEach(f -> f.toCompletableFuture().join());}return true;}...
}
public class RedissonMultiLock implements RLock {...protected int failedLocksLimit() {return 0;}protected long calcLockWaitTime(long remainTime) {return remainTime;}@Overridepublic void unlock() {List<RFuture<Void>> futures = new ArrayList<>(locks.size());for (RLock lock : locks) {futures.add(lock.unlockAsync());}for (RFuture<Void> future : futures) {future.toCompletableFuture().join();}}protected void unlockInner(Collection<RLock> locks) {locks.stream().map(RLockAsync::unlockAsync).forEach(f -> {f.toCompletableFuture().join();});}...
}
(5)RedissonRedLock的源码总结
针对多个lock进行加锁,每个lock都有一个1500毫秒的加锁超时时间。
如果在1500*n毫秒内,成功对n / 2 + 1个lock加锁成功了。那么就可以认为这个RedLock加锁成功,不要求所有的lock都加锁成功。
问题:RedLock本应该是一个锁,只不过是在不同的Master节点上进行加锁。但是Redisson的RedLock实现中却通过合并多个小lock来实现,这是否与RedLock的设计不一致了?
当使用Redis Cluster时,其实是一样的。假设有3个Master实例,那么就使用lock1、lock2、lock3三个key去加锁。这3个锁key会按照CRC16得出Hash值然后再取模分布到这3个Master节点,效果等同于让各个Master节点使用名为lock的这个key进行加锁。
RedLock相当于一把锁。虽然利用了MultiLock包裹了多个小锁,但这些小锁并不对应多个资源,而是每个小锁的key对应一个Redis实例。只要大多数的Redis实例加锁成功,就可以认为RedLock加锁成功。RedLock的健壮性要比其他普通锁要好。
但是RedLock也有一些场景无法保证正确性,当然RedLock只要求部署主库。比如客户端A尝试向5个Master实例加锁,但仅仅在3个Maste中加锁成功。不幸的是此时3个Master中有1个Master突然宕机了,而且锁key还没同步到该宕机Master的Slave上,此时Salve切换为Master。于是在这5个Master中,由于其中有一个是新切换过来的Master,所以只有2个Master是有客户端A加锁的数据,另外3个Master是没有锁的。但继续不幸的是,此时客户端B来加锁,那么客户端B就很有可能成功在没有锁数据的3个Master上加到锁,从而满足了过半数加锁的要求,最后也完成了加锁,依然发生重复加锁。
11.Curator的可重入锁的实现逻辑
(1)InterProcessMutex获取分布式锁
public class Demo {public static void main(String[] args) throws Exception {RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);CuratorFramework client = CuratorFrameworkFactory.newClient("127.0.0.1:2181", 5000, 3000, retryPolicy);client.start();System.out.println("已经启动Curator客户端");//获取分布式锁InterProcessMutex lock = new InterProcessMutex(client, "/locks/myLock");lock.acquire();Thread.sleep(1000);lock.release();}
}
(2)InterProcessMutex的初始化
设置锁的节点路径basePath + 初始化一个LockInternals对象实例。
public class InterProcessMutex implements InterProcessLock, Revocable<InterProcessMutex> {private final LockInternals internals;private final String basePath;private static final String LOCK_NAME = "lock-";...public InterProcessMutex(CuratorFramework client, String path) {this(client, path, new StandardLockInternalsDriver());}public InterProcessMutex(CuratorFramework client, String path, LockInternalsDriver driver) {this(client, path, LOCK_NAME, 1, driver);}//初始化InterProcessMutexInterProcessMutex(CuratorFramework client, String path, String lockName, int maxLeases, LockInternalsDriver driver) {//1.设置锁的节点路径basePath = PathUtils.validatePath(path);//2.初始化一个LockInternals对象实例internals = new LockInternals(client, driver, path, lockName, maxLeases);}
}
public class LockInternals {private final LockInternalsDriver driver;private final String lockName;private volatile int maxLeases;private final WatcherRemoveCuratorFramework client;private final String basePath;private final String path;...LockInternals(CuratorFramework client, LockInternalsDriver driver, String path, String lockName, int maxLeases) {this.driver = driver;this.lockName = lockName;this.maxLeases = maxLeases;this.client = client.newWatcherRemoveCuratorFramework();this.basePath = PathUtils.validatePath(path);this.path = ZKPaths.makePath(path, lockName);}...
}
(3)InterProcessMutex.acquire()尝试获取锁
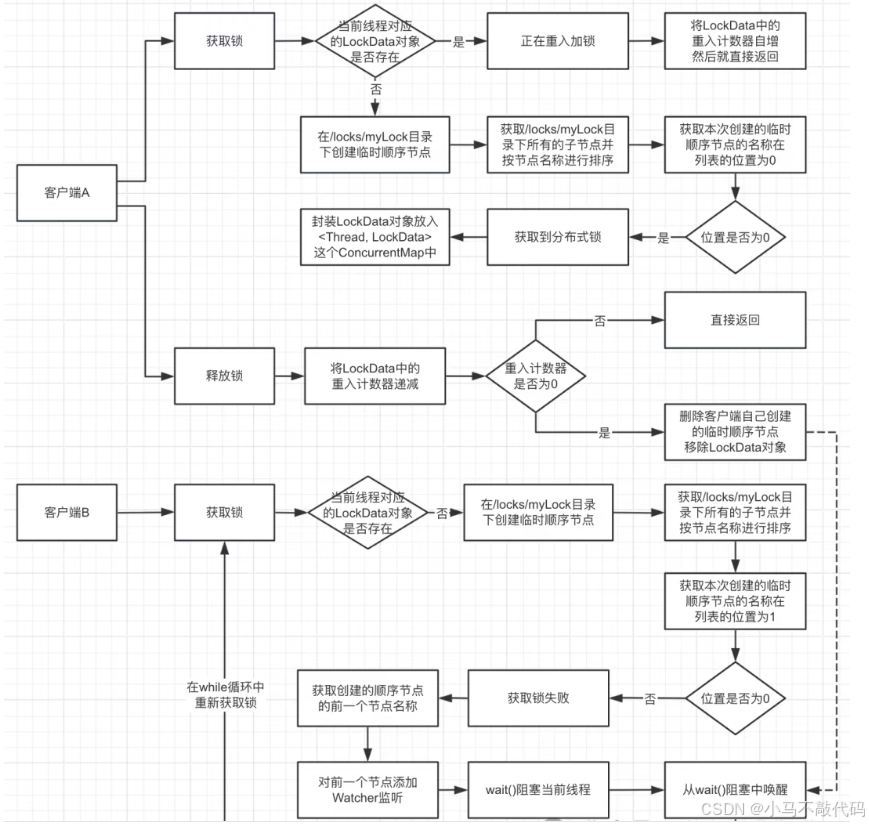
LockData是InterProcessMutex的一个静态内部类。一个线程对应一个LockData实例对象,用来描述线程持有的锁的具体情况。多个线程对应的LockData存放在一个叫threadData的ConcurrentMap中。LockData中有一个原子变量lockCount,用于锁的重入次数计数。
在执行InterProcessMutex的acquire()方法尝试获取锁时:首先会尝试取出当前线程对应的LockData数据,判断是否存在。如果存在,则说明锁正在被当前线程重入,重入次数自增后直接返回。如果不存在,则调用LockInternals的attemptLock()方法尝试获取锁。默认情况下,attemptLock()方法传入的等待获取锁的时间time = -1。
public class InterProcessMutex implements InterProcessLock, Revocable<InterProcessMutex> {private final LockInternals internals;private final String basePath;private static final String LOCK_NAME = "lock-";//一个线程对应一个LockData数据对象private final ConcurrentMap<Thread, LockData> threadData = Maps.newConcurrentMap();...//初始化InterProcessMutexInterProcessMutex(CuratorFramework client, String path, String lockName, int maxLeases, LockInternalsDriver driver) {//设置锁的路径basePath = PathUtils.validatePath(path);//初始化LockInternalsinternals = new LockInternals(client, driver, path, lockName, maxLeases);}@Overridepublic void acquire() throws Exception {//获取分布式锁,会一直阻塞等待直到获取成功//相同的线程可以重入锁,每一次调用acquire()方法都要匹配一个release()方法的调用if (!internalLock(-1, null)) {throw new IOException("Lost connection while trying to acquire lock: " + basePath);}}private boolean internalLock(long time, TimeUnit unit) throws Exception {//获取当前线程Thread currentThread = Thread.currentThread();//获取当前线程对应的LockData数据LockData lockData = threadData.get(currentThread);if (lockData != null) {//可重入计算lockData.lockCount.incrementAndGet();return true;}//调用LockInternals.attemptLock()方法尝试获取锁,默认情况下,传入的time=-1,表示等待获取锁的时间String lockPath = internals.attemptLock(time, unit, getLockNodeBytes());if (lockPath != null) {//获取锁成功,将当前线程 + 其创建的临时顺序节点路径,封装成一个LockData对象LockData newLockData = new LockData(currentThread, lockPath);//然后把该LockData对象存放到InterProcessMutex.threadData这个Map中threadData.put(currentThread, newLockData);return true;}return false;}//LockData是InterProcessMutex的一个静态内部类private static class LockData {final Thread owningThread;final String lockPath;final AtomicInteger lockCount = new AtomicInteger(1);//用于锁的重入次数计数private LockData(Thread owningThread, String lockPath) {this.owningThread = owningThread;this.lockPath = lockPath;}}protected byte[] getLockNodeBytes() {return null;}...
}
(4)LockInternals.attemptLock()尝试获取锁
先创建临时节点,再判断是否满足获取锁的条件。
步骤一:首先调用LockInternalsDriver的createsTheLock()方法创建一个临时顺序节点。其中creatingParentContainersIfNeeded()表示级联创建,forPath(path)表示创建的节点路径名称,withMode(CreateMode.EPHEMERAL_SEQUENTIAL)表示临时顺序节点。
步骤二:然后调用LockInternals的internalLockLoop()方法检查是否获取到了锁。在LockInternals的internalLockLoop()方法的while循环中,会先获取排好序的客户端线程尝试获取锁时创建的临时顺序节点名称列表。然后获取当前客户端线程尝试获取锁时创建的临时顺序节点的名称,再根据名称获取在节点列表中的位置 + 是否可以获取锁 + 前一个节点的路径,也就是获取一个封装好这些信息的PredicateResults对象。
具体会根据节点名称获取当前线程创建的临时顺序节点在节点列表的位置,然后会比较当前线程创建的节点的位置和maxLeases的大小。其中maxLeases代表了同时允许多少个客户端可以获取到锁,默认是1。如果当前线程创建的节点的位置小,则表示可以获取锁。如果当前线程创建的节点的位置大,则表示获取锁失败。
获取锁成功,则会中断LockInternals的internalLockLoop()方法的while循环,然后向外返回当前客户端线程创建的临时顺序节点路径。接着在InterProcessMutex的internalLock()方法中,会将当前线程 + 其创建的临时顺序节点路径,封装成一个LockData对象,然后把该LockData对象存放到InterProcessMutex.threadData这个Map中。
获取锁失败,则通过PredicateResults对象先获取前一个节点路径名称。然后通过getData()方法获取前一个节点路径在zk的信息,并添加Watcher监听。该Watcher监听主要是用来唤醒在LockInternals中被wait()阻塞的线程。添加完Watcher监听后,便会调用wait()方法将当前线程挂起。
所以前一个节点发生变化时,便会通知添加的Watcher监听。然后便会唤醒阻塞的线程,继续执行internalLockLoop()方法的while循环。while循环又会继续获取排序的节点列表 + 判断当前线程是否已获取锁。
public class LockInternals {private final LockInternalsDriver driver;LockInternals(CuratorFramework client, LockInternalsDriver driver, String path, String lockName, int maxLeases) {this.driver = driver;this.path = ZKPaths.makePath(path, lockName);//生成要创建的临时节点路径名称...}...String attemptLock(long time, TimeUnit unit, byte[] lockNodeBytes) throws Exception {//获取当前时间final long startMillis = System.currentTimeMillis();//默认情况下millisToWait=nullfinal Long millisToWait = (unit != null) ? unit.toMillis(time) : null;//默认情况下localLockNodeBytes也是nullfinal byte[] localLockNodeBytes = (revocable.get() != null) ? new byte[0] : lockNodeBytes;int retryCount = 0;String ourPath = null;boolean hasTheLock = false;//是否已经获取到锁boolean isDone = false;//是否正在获取锁while (!isDone) {isDone = true;//1.这里是关键性的加锁代码,会去级联创建一个临时顺序节点ourPath = driver.createsTheLock(client, path, localLockNodeBytes);//2.检查是否获取到了锁hasTheLock = internalLockLoop(startMillis, millisToWait, ourPath);}if (hasTheLock) {return ourPath;}return null;}private final Watcher watcher = new Watcher() {@Overridepublic void process(WatchedEvent event) {//唤醒LockInternals中被wait()阻塞的线程client.postSafeNotify(LockInternals.this);}};//检查是否获取到了锁private boolean internalLockLoop(long startMillis, Long millisToWait, String ourPath) throws Exception {boolean haveTheLock = false;boolean doDelete = false;...while ((client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock) {//3.获取排好序的各个客户端线程尝试获取分布式锁时创建的临时顺序节点名称列表List<String> children = getSortedChildren();//4.获取当前客户端线程尝试获取分布式锁时创建的临时顺序节点的名称String sequenceNodeName = ourPath.substring(basePath.length() + 1); // +1 to include the slash//5.获取当前线程创建的节点在节点列表中的位置 + 是否可以获取锁 + 前一个节点的路径名称PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);if (predicateResults.getsTheLock()) {//获取锁成功//返回truehaveTheLock = true;} else {//获取锁失败//获取前一个节点路径名称String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch();synchronized(this) {//use getData() instead of exists() to avoid leaving unneeded watchers which is a type of resource leak//通过getData()获取前一个节点路径在zk的信息,并添加watch监听client.getData().usingWatcher(watcher).forPath(previousSequencePath);//默认情况下,millisToWait = nullif (millisToWait != null) {millisToWait -= (System.currentTimeMillis() - startMillis);startMillis = System.currentTimeMillis();if (millisToWait <= 0) {doDelete = true;//timed out - delete our nodebreak;}wait(millisToWait);//阻塞} else {wait();//阻塞}}}}...return haveTheLock;}List<String> getSortedChildren() throws Exception {//获取排好序的各个客户端线程尝试获取分布式锁时创建的临时顺序节点名称列表return getSortedChildren(client, basePath, lockName, driver);}public static List<String> getSortedChildren(CuratorFramework client, String basePath, final String lockName, final LockInternalsSorter sorter) throws Exception {//获取各个客户端线程尝试获取分布式锁时创建的临时顺序节点名称列表List<String> children = client.getChildren().forPath(basePath);//对节点名称进行排序List<String> sortedList = Lists.newArrayList(children);Collections.sort(sortedList,new Comparator<String>() {@Overridepublic int compare(String lhs, String rhs) {return sorter.fixForSorting(lhs, lockName).compareTo(sorter.fixForSorting(rhs, lockName));}});return sortedList;}...
}
public class StandardLockInternalsDriver implements LockInternalsDriver {...//级联创建一个临时顺序节点@Overridepublic String createsTheLock(CuratorFramework client, String path, byte[] lockNodeBytes) throws Exception {String ourPath;//默认情况下传入的lockNodeBytes=nullif (lockNodeBytes != null) {ourPath = client.create().creatingParentContainersIfNeeded().withProtection().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(path, lockNodeBytes);} else {//创建临时顺序节点ourPath = client.create().creatingParentContainersIfNeeded().withProtection().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(path);}return ourPath;}//获取当前线程创建的节点在节点列表中的位置以及是否可以获取锁@Overridepublic PredicateResults getsTheLock(CuratorFramework client, List<String> children, String sequenceNodeName, int maxLeases) throws Exception {//根据节点名称获取当前线程创建的临时顺序节点在节点列表中的位置int ourIndex = children.indexOf(sequenceNodeName);validateOurIndex(sequenceNodeName, ourIndex);//maxLeases代表的是同时允许多少个客户端可以获取到锁//getsTheLock为true表示可以获取锁,getsTheLock为false表示获取锁失败boolean getsTheLock = ourIndex < maxLeases;//获取当前节点需要watch的前一个节点路径String pathToWatch = getsTheLock ? null : children.get(ourIndex - maxLeases);return new PredicateResults(pathToWatch, getsTheLock);}...
}
(5)不同客户端线程获取锁时的互斥实现
maxLeases代表了同时允许多少个客户端可以获取到锁,默认值是1。能否获取锁的判断就是:线程创建的节点的位置outIndex < maxLeases。当线程1创建的节点在节点列表中排第一时,满足outIndex = 0 < maxLeases = 1,可以获取锁。当线程2创建的节点再节点列表中排第二时,不满足outIndex = 1 < maxLeases = 1,所以不能获取锁。从而实现线程1和线程2获取锁时的互斥。
(6)同一客户端线程可重入加锁的实现
客户端线程重复获取锁时,会重复调用InterProcessMutex的internalLock()方法。在InterProcessMutex的internalLock()方法中:线程第一次获取锁成功会创建一个LockData对象,并存放在一个Map中。线程第二次获取锁时,便会从这个Map中取出这个LockData对象,并对LockData对象中的重入计数器lockCount进行递增,接着就返回true。以此实现可重入加锁。
(7)客户端线程释放锁的实现
客户端线程释放锁时会调用InterProcessMutex的release()方法。
首先对LockData里的重入计数器进行递减。当重入计数器大于0时,直接返回。当重入计数器为0时才执行下一步删除节点的操作。
然后删除客户端线程创建的临时顺序节点,client.delete().guaranteed().forPath(ourPath)。
public class InterProcessMutex implements InterProcessLock, Revocable<InterProcessMutex> {private final LockInternals internals;private final ConcurrentMap<Thread, LockData> threadData = Maps.newConcurrentMap();...@Overridepublic void release() throws Exception {//获取当前线程Thread currentThread = Thread.currentThread();//获取当前线程对应的LockData对象LockData lockData = threadData.get(currentThread);if (lockData == null) {throw new IllegalMonitorStateException("You do not own the lock: " + basePath);}//1.首先对LockData里的重入计数器lockCount进行递减int newLockCount = lockData.lockCount.decrementAndGet();if (newLockCount > 0) {//当重入计数器大于0时,直接返回return;}if (newLockCount < 0) {throw new IllegalMonitorStateException("Lock count has gone negative for lock: " + basePath);}try {//2.当重入计数器为0时执行删除节点的操作internals.releaseLock(lockData.lockPath);} finally {threadData.remove(currentThread);}}...
}
public class LockInternals {...final void releaseLock(String lockPath) throws Exception {client.removeWatchers();revocable.set(null);deleteOurPath(lockPath);}private void deleteOurPath(String ourPath) throws Exception {//删除节点client.delete().guaranteed().forPath(ourPath);}...
}
(8)客户端线程释放锁后其他线程获取锁的实现
由于在节点列表里排第二的节点对应的线程会监听排第一的节点,而当持有锁的客户端线程释放锁后,排第一的节点会被删除掉。所以在节点列表里排第二的节点对应的客户端,便会收到zk的通知。于是会回调执行该线程添加的Watcher的process()方法,也就是唤醒该线程,让其继续执行while循环获取锁。
public class LockInternals {...private final Watcher watcher = new Watcher() {@Overridepublic void process(WatchedEvent event) {//唤醒LockInternals中被wait()阻塞的线程client.postSafeNotify(LockInternals.this);}};//检查是否获取到了锁private boolean internalLockLoop(long startMillis, Long millisToWait, String ourPath) throws Exception {boolean haveTheLock = false;boolean doDelete = false;...while ((client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock) {//3.获取排好序的各个客户端线程尝试获取分布式锁时创建的临时顺序节点名称列表List<String> children = getSortedChildren();//4.获取当前客户端线程尝试获取分布式锁时创建的临时顺序节点的名称String sequenceNodeName = ourPath.substring(basePath.length() + 1); // +1 to include the slash//5.获取当前线程创建的节点在节点列表中的位置+是否可以获取锁+前一个节点的路径名称PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);if (predicateResults.getsTheLock()) {//获取锁成功//返回truehaveTheLock = true;} else {//获取锁失败//获取前一个节点路径名称String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch();synchronized(this) {//use getData() instead of exists() to avoid leaving unneeded watchers which is a type of resource leak//通过getData()获取前一个节点路径在zk的信息,并添加watch监听client.getData().usingWatcher(watcher).forPath(previousSequencePath);//默认情况下,millisToWait = nullif (millisToWait != null) {millisToWait -= (System.currentTimeMillis() - startMillis);startMillis = System.currentTimeMillis();if (millisToWait <= 0) {doDelete = true;//timed out - delete our nodebreak;}wait(millisToWait);//阻塞} else {wait();//阻塞}}}}...return haveTheLock;}...
}
(9)InterProcessMutex就是一个公平锁
因为所有客户端线程都会创建一个顺序节点,然后按申请锁的顺序进行排序。最后会依次按自己所在的排序来尝试获取锁,实现了所有客户端排队获取锁。
12.Curator的非可重入锁的实现逻辑
(1)Curator的非可重入锁InterProcessSemaphoreMutex的使用
非可重入锁:同一个时间只能有一个客户端线程获取到锁,其他线程都要排队,而且同一个客户端线程是不可重入加锁的。
public class Demo {public static void main(String[] args) throws Exception {RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);final CuratorFramework client = CuratorFrameworkFactory.newClient("127.0.0.1:2181",//zk的地址5000,//客户端和zk的心跳超时时间,超过该时间没心跳,Session就会被断开3000,//连接zk时的超时时间retryPolicy);client.start();System.out.println("已经启动Curator客户端,完成zk的连接");//非可重入锁InterProcessSemaphoreMutex lock = new InterProcessSemaphoreMutex(client, "/locks");lock.acquire();Thread.sleep(3000);lock.release();}
}
(2)Curator的非可重入锁InterProcessSemaphoreMutex的源码
Curator的非可重入锁是基于Semaphore来实现的,也就是将Semaphore允许获取Lease的客户端线程数设置为1,从而实现同一时间只能有一个客户端线程获取到Lease。
public class InterProcessSemaphoreMutex implements InterProcessLock {private final InterProcessSemaphoreV2 semaphore;private final WatcherRemoveCuratorFramework watcherRemoveClient;private volatile Lease lease;public InterProcessSemaphoreMutex(CuratorFramework client, String path) {watcherRemoveClient = client.newWatcherRemoveCuratorFramework();this.semaphore = new InterProcessSemaphoreV2(watcherRemoveClient, path, 1);}@Overridepublic void acquire() throws Exception {//获取非可重入锁就是获取Semaphore的Leaselease = semaphore.acquire();}@Overridepublic boolean acquire(long time, TimeUnit unit) throws Exception {Lease acquiredLease = semaphore.acquire(time, unit);if (acquiredLease == null) {return false;}lease = acquiredLease;return true;}@Overridepublic void release() throws Exception {//释放非可重入锁就是释放Semaphore的LeaseLease lease = this.lease;Preconditions.checkState(lease != null, "Not acquired");this.lease = null;lease.close();watcherRemoveClient.removeWatchers();}
}
13.Curator的可重入读写锁的实现逻辑
(1)Curator的可重入读写锁InterProcessReadWriteLock的使用
public class Demo {public static void main(String[] args) throws Exception {RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);final CuratorFramework client = CuratorFrameworkFactory.newClient("127.0.0.1:2181",//zk的地址5000,//客户端和zk的心跳超时时间,超过该时间没心跳,Session就会被断开3000,//连接zk时的超时时间retryPolicy);client.start();System.out.println("已经启动Curator客户端,完成zk的连接");//读写锁InterProcessReadWriteLock lock = new InterProcessReadWriteLock(client, "/locks");lock.readLock().acquire();lock.readLock().release();lock.writeLock().acquire();lock.writeLock().release();}
}
(2)Curator的可重入读写锁InterProcessReadWriteLock的初始化
读锁和写锁都是基于可重入锁InterProcessMutex的子类来实现的。读锁和写锁的获取锁和释放锁逻辑,就是使用InterProcessMutex的逻辑。
public class InterProcessReadWriteLock {private final InterProcessMutex readMutex;//读锁private final InterProcessMutex writeMutex;//写锁//must be the same length. LockInternals depends on itprivate static final String READ_LOCK_NAME = "__READ__";private static final String WRITE_LOCK_NAME = "__WRIT__";...//InterProcessReadWriteLock的初始化public InterProcessReadWriteLock(CuratorFramework client, String basePath, byte[] lockData) {lockData = (lockData == null) ? null : Arrays.copyOf(lockData, lockData.length);//写锁的初始化writeMutex = new InternalInterProcessMutex(client,basePath,WRITE_LOCK_NAME,//写锁的lockName='__WRIT__'lockData,1,//写锁的maxLeasesnew SortingLockInternalsDriver() {@Overridepublic PredicateResults getsTheLock(CuratorFramework client, List<String> children, String sequenceNodeName, int maxLeases) throws Exception {return super.getsTheLock(client, children, sequenceNodeName, maxLeases);}});//读锁的初始化readMutex = new InternalInterProcessMutex(client,basePath,READ_LOCK_NAME,//读锁的lockName='__READ__'lockData,Integer.MAX_VALUE,//读锁的maxLeasesnew SortingLockInternalsDriver() {@Overridepublic PredicateResults getsTheLock(CuratorFramework client, List<String> children, String sequenceNodeName, int maxLeases) throws Exception {return readLockPredicate(children, sequenceNodeName);}});}private static class InternalInterProcessMutex extends InterProcessMutex {private final String lockName;private final byte[] lockData;InternalInterProcessMutex(CuratorFramework client, String path, String lockName, byte[] lockData, int maxLeases, LockInternalsDriver driver) {super(client, path, lockName, maxLeases, driver);this.lockName = lockName;this.lockData = lockData;}...}public InterProcessMutex readLock() {return readMutex;}public InterProcessMutex writeLock() {return writeMutex;}...
}
(3)InterProcessMutex获取锁的源码
private final LockInternals internals;private final String basePath;private static final String LOCK_NAME = "lock-";//一个线程对应一个LockData数据对象private final ConcurrentMap<Thread, LockData> threadData = Maps.newConcurrentMap();...//初始化InterProcessMutexInterProcessMutex(CuratorFramework client, String path, String lockName, int maxLeases, LockInternalsDriver driver) {//设置锁的路径basePath = PathUtils.validatePath(path);//初始化LockInternalsinternals = new LockInternals(client, driver, path, lockName, maxLeases);}@Overridepublic void acquire() throws Exception {//获取分布式锁,会一直阻塞等待直到获取成功//相同的线程可以重入锁,每一次调用acquire()方法都要匹配一个release()方法的调用if (!internalLock(-1, null)) {throw new IOException("Lost connection while trying to acquire lock: " + basePath);}}private boolean internalLock(long time, TimeUnit unit) throws Exception {//获取当前线程Thread currentThread = Thread.currentThread();//获取当前线程对应的LockData数据LockData lockData = threadData.get(currentThread);if (lockData != null) {//可重入计算lockData.lockCount.incrementAndGet();return true;}//调用LockInternals.attemptLock()方法尝试获取锁,默认情况下,传入的time=-1,表示等待获取锁的时间String lockPath = internals.attemptLock(time, unit, getLockNodeBytes());if (lockPath != null) {//获取锁成功,将当前线程 + 其创建的临时顺序节点路径,封装成一个LockData对象LockData newLockData = new LockData(currentThread, lockPath);//然后把该LockData对象存放到InterProcessMutex.threadData这个Map中threadData.put(currentThread, newLockData);return true;}return false;}//LockData是InterProcessMutex的一个静态内部类private static class LockData {final Thread owningThread;final String lockPath;final AtomicInteger lockCount = new AtomicInteger(1);//用于锁的重入次数计数private LockData(Thread owningThread, String lockPath) {this.owningThread = owningThread;this.lockPath = lockPath;}}protected byte[] getLockNodeBytes() {return null;}...
}
public class LockInternals {private final LockInternalsDriver driver;LockInternals(CuratorFramework client, LockInternalsDriver driver, String path, String lockName, int maxLeases) {this.driver = driver;this.path = ZKPaths.makePath(path, lockName);//生成要创建的临时节点路径名称...}...String attemptLock(long time, TimeUnit unit, byte[] lockNodeBytes) throws Exception {//获取当前时间final long startMillis = System.currentTimeMillis();//默认情况下millisToWait=nullfinal Long millisToWait = (unit != null) ? unit.toMillis(time) : null;//默认情况下localLockNodeBytes也是nullfinal byte[] localLockNodeBytes = (revocable.get() != null) ? new byte[0] : lockNodeBytes;int retryCount = 0;String ourPath = null;boolean hasTheLock = false;//是否已经获取到锁boolean isDone = false;//是否正在获取锁while (!isDone) {isDone = true;//1.这里是关键性的加锁代码,会去级联创建一个临时顺序节点ourPath = driver.createsTheLock(client, path, localLockNodeBytes);//2.检查是否获取到了锁hasTheLock = internalLockLoop(startMillis, millisToWait, ourPath);}if (hasTheLock) {return ourPath;}return null;}private final Watcher watcher = new Watcher() {@Overridepublic void process(WatchedEvent event) {//唤醒LockInternals中被wait()阻塞的线程client.postSafeNotify(LockInternals.this);}};//检查是否获取到了锁private boolean internalLockLoop(long startMillis, Long millisToWait, String ourPath) throws Exception {boolean haveTheLock = false;boolean doDelete = false;...while ((client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock) {//3.获取排好序的各个客户端线程尝试获取分布式锁时创建的临时顺序节点名称列表List<String> children = getSortedChildren();//4.获取当前客户端线程尝试获取分布式锁时创建的临时顺序节点的名称String sequenceNodeName = ourPath.substring(basePath.length() + 1); // +1 to include the slash//5.获取当前线程创建的节点在节点列表中的位置 + 是否可以获取锁 + 前一个节点的路径名称PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);if (predicateResults.getsTheLock()) {//获取锁成功//返回truehaveTheLock = true;} else {//获取锁失败//获取前一个节点路径名称String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch();synchronized(this) {//use getData() instead of exists() to avoid leaving unneeded watchers which is a type of resource leak//通过getData()获取前一个节点路径在zk的信息,并添加watch监听client.getData().usingWatcher(watcher).forPath(previousSequencePath);//默认情况下,millisToWait = nullif (millisToWait != null) {millisToWait -= (System.currentTimeMillis() - startMillis);startMillis = System.currentTimeMillis();if (millisToWait <= 0) {doDelete = true;//timed out - delete our nodebreak;}wait(millisToWait);//阻塞} else {wait();//阻塞}}}}...return haveTheLock;}List<String> getSortedChildren() throws Exception {//获取排好序的各个客户端线程尝试获取分布式锁时创建的临时顺序节点名称列表return getSortedChildren(client, basePath, lockName, driver);}public static List<String> getSortedChildren(CuratorFramework client, String basePath, final String lockName, final LockInternalsSorter sorter) throws Exception {//获取各个客户端线程尝试获取分布式锁时创建的临时顺序节点名称列表List<String> children = client.getChildren().forPath(basePath);//对节点名称进行排序List<String> sortedList = Lists.newArrayList(children);Collections.sort(sortedList,new Comparator<String>() {@Overridepublic int compare(String lhs, String rhs) {return sorter.fixForSorting(lhs, lockName).compareTo(sorter.fixForSorting(rhs, lockName));}});return sortedList;}...
}
public class StandardLockInternalsDriver implements LockInternalsDriver {...//级联创建一个临时顺序节点@Overridepublic String createsTheLock(CuratorFramework client, String path, byte[] lockNodeBytes) throws Exception {String ourPath;//默认情况下传入的lockNodeBytes=nullif (lockNodeBytes != null) {ourPath = client.create().creatingParentContainersIfNeeded().withProtection().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(path, lockNodeBytes);} else {//创建临时顺序节点ourPath = client.create().creatingParentContainersIfNeeded().withProtection().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(path);}return ourPath;}//获取当前线程创建的节点在节点列表中的位置以及是否可以获取锁@Overridepublic PredicateResults getsTheLock(CuratorFramework client, List<String> children, String sequenceNodeName, int maxLeases) throws Exception {//根据节点名称获取当前线程创建的临时顺序节点在节点列表中的位置int ourIndex = children.indexOf(sequenceNodeName);validateOurIndex(sequenceNodeName, ourIndex);//maxLeases代表的是同时允许多少个客户端可以获取到锁//getsTheLock为true表示可以获取锁,getsTheLock为false表示获取锁失败boolean getsTheLock = ourIndex < maxLeases;//获取当前节点需要watch的前一个节点路径String pathToWatch = getsTheLock ? null : children.get(ourIndex - maxLeases);return new PredicateResults(pathToWatch, getsTheLock);}...
}
(4)先获取读锁 + 后获取读锁的情形分析
当线程创建完临时顺序节点,并获取到排好序的节点列表children后,执行LockInternalsDriver的getsTheLock()方法获取能否成功加锁的信息时,会执行到InterProcessReadWriteLock的readLockPredicate()方法。
由于此时firstWriteIndex = Integer.MAX_VALUE,所以无论多少线程尝试获取读锁,都能满足ourIndex < firstWriteIndex,也就是getsTheLock的值会为true,即表示可以获取读锁。
所以读读不互斥。
public class InterProcessReadWriteLock {...//sequenceNodeName是当前线程创建的临时顺序节点的路径名称private PredicateResults readLockPredicate(List<String> children, String sequenceNodeName) throws Exception {if (writeMutex.isOwnedByCurrentThread()) {return new PredicateResults(null, true);}int index = 0;int firstWriteIndex = Integer.MAX_VALUE;int ourIndex = -1;for (String node : children) {if (node.contains(WRITE_LOCK_NAME)) {firstWriteIndex = Math.min(index, firstWriteIndex);} else if (node.startsWith(sequenceNodeName)) {//找出当前线程创建的临时顺序节点在节点列表中的位置,用ourIndex表示ourIndex = index;break;}++index;}StandardLockInternalsDriver.validateOurIndex(sequenceNodeName, ourIndex);boolean getsTheLock = (ourIndex < firstWriteIndex);String pathToWatch = getsTheLock ? null : children.get(firstWriteIndex);return new PredicateResults(pathToWatch, getsTheLock);}...
}
(5)先获取读锁 + 后获取写锁的情形分析
一.假设客户端线程1首先成功获取了读锁
那么在/locks目录下,此时已经有了如下这个读锁的临时顺序节点。
/locks/43f3-4c2f-ba98-07a641d351f2-__READ__0000000004
二.然后另一个客户端线程2过来尝试获取写锁
于是该线程2会也会先在/locks目录下创建出如下写锁的临时顺序节点:
/locks/9361-4fb7-8420-a8d4911d2c99-__WRIT__0000000005
接着该线程会获取/locks目录的当前子节点列表并进行排序,结果如下:
[43f3-4c2f-ba98-07a641d351f2-__READ__0000000004,
9361-4fb7-8420-a8d4911d2c99-__WRIT__0000000005]
然后会执行StandardLockInternalsDriver的getsTheLock()方法。由于初始化写锁时,设置了其maxLeases是1,而在StandardLockInternalsDriver的getsTheLock()方法中,判断线程能成功获取写锁的依据是:ourIndex < maxLeases。即如果要成功获取写锁,那么线程创建的节点在子节点列表里必须排第一。
而此时,由于之前已有线程获取过一个读锁,而后来又有其他线程往里面创建一个写锁的临时顺序节点。所以写锁的临时顺序节点在子节点列表children里排第二,ourIndex是1。所以index = 1 < maxLeases = 1,条件不成立。
因此,此时客户端线程2获取写锁失败。于是该线程便会给前一个节点添加一个监听器,并调用wait()方法把自己挂起。如果前面一个节点被删除释放了锁,那么该线程就会被唤醒,从而再次尝试判断自己创建的节点是否在当前子节点列表中排第一。如果是,那么就表示获取写锁成功。
public class StandardLockInternalsDriver implements LockInternalsDriver {...//获取当前线程创建的节点在节点列表中的位置以及是否可以获取锁@Overridepublic PredicateResults getsTheLock(CuratorFramework client, List<String> children, String sequenceNodeName, int maxLeases) throws Exception {//根据节点名称获取当前线程创建的临时顺序节点在节点列表中的位置int ourIndex = children.indexOf(sequenceNodeName);validateOurIndex(sequenceNodeName, ourIndex);//maxLeases代表的是同时允许多少个客户端可以获取到锁//getsTheLock为true表示可以获取锁,getsTheLock为false表示获取锁失败boolean getsTheLock = ourIndex < maxLeases;//获取当前节点需要watch的前一个节点路径String pathToWatch = getsTheLock ? null : children.get(ourIndex - maxLeases);return new PredicateResults(pathToWatch, getsTheLock);}...
}
(6)先获取写锁 + 后获取读锁的情形分析
一.假设客户端线程1先获取了写锁
那么在/locks目录下,此时已经有了如下这个写锁的临时顺序节点。
/locks/4383-466e-9b86-fda522ea061a-__WRIT__0000000006
二.然后另一个客户端线程2过来尝试获取读锁
于是该线程2会也会先在/locks目录下创建出如下读锁的临时顺序节点:
/locks/5ba2-488f-93a4-f85fafd5cc32-__READ__0000000007
接着该线程会获取/locks目录的当前子节点列表并进行排序,结果如下:
[4383-466e-9b86-fda522ea061a-__WRIT__0000000006,
5ba2-488f-93a4-f85fafd5cc32-__READ__0000000007]
然后会执行LockInternalsDriver的getsTheLock()方法获取能否加锁的信息,也就是会执行InterProcessReadWriteLock的readLockPredicate()方法。
public class InterProcessReadWriteLock {...//sequenceNodeName是当前线程创建的临时顺序节点的路径名称private PredicateResults readLockPredicate(List<String> children, String sequenceNodeName) throws Exception {//如果是同一个客户端线程,先加写锁,再加读锁,是可以成功的,不会互斥if (writeMutex.isOwnedByCurrentThread()) {return new PredicateResults(null, true);}int index = 0;int firstWriteIndex = Integer.MAX_VALUE;int ourIndex = -1;for (String node : children) {if (node.contains(WRITE_LOCK_NAME)) {firstWriteIndex = Math.min(index, firstWriteIndex);} else if (node.startsWith(sequenceNodeName)) {//找出当前线程创建的临时顺序节点在节点列表中的位置,用ourIndex表示ourIndex = index;break;}++index;}StandardLockInternalsDriver.validateOurIndex(sequenceNodeName, ourIndex);boolean getsTheLock = (ourIndex < firstWriteIndex);String pathToWatch = getsTheLock ? null : children.get(firstWriteIndex);return new PredicateResults(pathToWatch, getsTheLock);}...
}
在InterProcessReadWriteLock的readLockPredicate()方法中,如果是同一个客户端线程,先获取写锁,再获取读锁,是不会互斥的。如果是不同的客户端线程,线程1先获取写锁,线程2再获取读锁,则互斥。因为线程2执行readLockPredicate()方法在遍历子节点列表(children)时,如果在子节点列表(children)中发现了一个写锁,会设置firstWriteIndex=0。而此时线程2创建的临时顺序节点的ourIndex=1,所以不满足ourIndex(1) < firstWriteIndex(0),于是线程2获取读锁失败。
总结,获取读锁时,在当前线程创建的节点前面:如果还有写锁对应的节点,那么firstWriteIndex就会被重置为具体位置。如果没有写锁对应的节点,那么firstWriteIndex就是MAX_VALUE。而只要firstWriteIndex为MAX_VALUE,那么就可以不断允许获取读锁。
(7)先获取写锁 + 再获取写锁的情形分析
如果客户端线程1先获取了写锁,然后后面客户端线程2来获取这个写锁。此时线程2会发现自己创建的节点排在节点列表中的第二,不是第一。于是获取写锁失败,进行阻塞挂起。等线程1释放了写锁后,才会唤醒线程2继续尝试获取写锁。