Tensorflow基础——数据类型、计算图
Tensorflow,tensor(张量)是基本的数据结构,可以理解成多维数组;flow(流)指计算图中数据的流动方式。
它的核心与NumPy非常相似,但支持GPU。
它支持分布式计算(跨多个设备和服务器)。·
它包含一种即时(JIT)编译器,可使其针对速度和内存使用情况来优化计算。它的工作方式是从Python函数中提取计算图,然后进行优化(通过修剪未使用的节点),最后有效地运行它(通过自动并行运行相互独立的操作)。
计算图可以导出为可移植格式,因此可以在一个环境中(例如在Linux上使用Python)训练TensorFlow模型,然后在另一个环境中(例如在Android设备上使用Java)运行TensorFlow模型。
它实现了反向模式的自动微分(autodiff) 并提供了一些优秀的优化器,例如RMSProp和Nadam,因此可以轻松地最小化各种损失函数。
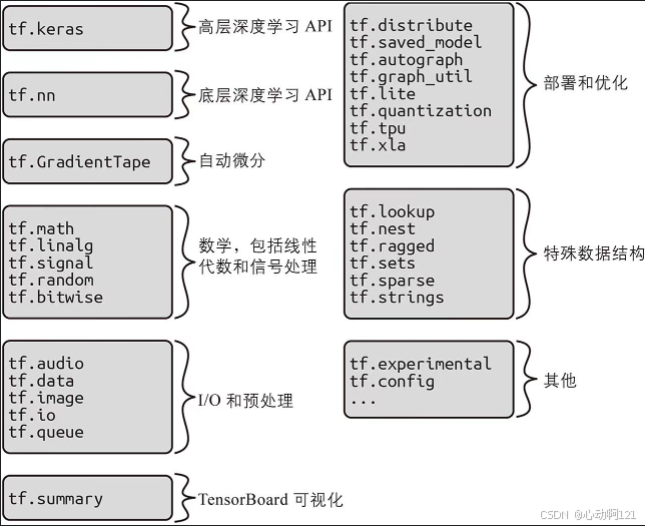
TensorFlow在这些核心功能的基础上提供了更多功能:最重要的当然是Keras, 但它还具有数据加载和预处理操作(tf.data、tf.io等),以及图像处理操作(tf.image)和信号处理操作(tf.signal)
一、基本数据类型
基础数据类型是对应python、numpy中的原生类型,一般使用tf.constant创建。
| TensorFlow 类型 | Python类型 | 描述 | NumPy类型 |
|---|---|---|---|
tf.float32 | float | 32位单精度浮点数。最常用,在精度和性能之间取得了良好平衡。 | np.float32 |
tf.float64 | float | 64位双精度浮点数。计算精度高,但占用内存更多,计算更慢。 | np.float64 |
tf.int32 | int | 32位有符号整数。常用于表示索引、尺寸等。 | np.int32 |
tf.int64 | int | 64位有符号整数。 | np.int64 |
tf.string | str | 可变长度的字节数组。用于存储文本或序列化数据。 | np.object_ |
tf.bool | bool | 布尔型。用于逻辑运算和掩码(mask)。 | np.bool_ |
tf.complex64 | complex | 64位复数,由两个32位浮点数(实部和虚部)组成。 | np.complex64 |
tf.uint8 | int | 8位无符号整数。常用于表示图像数据(像素值范围0-255)。 | np.uint8 |
tf.int16 | int | 16位有符号整数。有时用于音频等数据。 | np.int16 |
类型转换:可以使用 tf.cast() 函数进行数据类型转换。
1、字符串(tf.string)
虽然是基本类型,但是由它组成的张量在处理文本时非常特殊。可以存储任意长度的字节序列,使得tensorflow能够原生的处理字符串数据。
tf.constant("hello world")
tf.constant(b"hello world") # 二进制编码后的字符串
tf.constant([ord(c) for c in "诞生于1996,梦想做说唱领袖"]) # 将字符转成Unicode编码
b=tf.strings.unicode_encode(u, "UTF-8") # 将整数列表转化成二进制文本
tf.strings.length(b, unit="UTF8_CHAR")
tf.strings.unicode_decode(b, "UTF-8") # 将二进制编码转成整数编码2、变量(tf.Variable)
使用tf.constant创建的tensor值是不变的,无法修改。这意味着不能使用常规张量在神经网络中表示权重,因为需要反向传播进行调整。因此,需要使用tf.Varibale创建变量。
tf.Variable的行为与tf.Tensor的行为非常相似:可以使用它执行相同的操作,它在NumPy中也可以很好地发挥作用,并且对类型也很挑剔。但是,它也可以使用assign()方法(或assign_add()与assign_sub(),给变量增加或减少给定值)进行修改。
还可以通过单元(或切片)的assign()方法(直接指定将不起作用)或者使用scatter_update()或scatter_nd_update()方法来修改单个单元(或切片),但直接赋值将不起作用
v = tf.Variable([[1.,2.,3.], [4.,5.,6.]])
# 变量赋值
v.assign(2*v) # 每个元素都乘2
v[0,1].assign(42) # 将[0,1]位置的数值改为42
v.scatter_nd_update(indices=[[0,0], [1,2]], updates=[100., 200.]) # 将[0,0], [1,2]位置的分别改为100和200
二、特殊数据类型
1、张量的创建和基础运算
在 TensorFlow 中,张量是一个多维数组,具有统一的数据类型(dtype) 和固定的维度(shape)。你可以将它看作是任何数据的标准表示形式。在tensorflow中所有的输入和输出数据都是张量。
张量使用tf.constant()进行创建,其有三个关键属性:shape数据形状(用元组表示),dtype数据类型(tf.float32、tf.int32、tf.string等),name名字和图形引用。
| 维度 | 数学名称 | Python 例子 | TensorFlow 张量形状(shape) |
|---|---|---|---|
| 0 | 标量 (Scalar) | s = 5 | () (空元组) |
| 1 | 向量 (Vector) | v = [1, 2, 3] | (3,) |
| 2 | 矩阵 (Matrix) | m = [[1, 2], [3, 4]] | (2, 2) |
| 3 | 3阶张量 | t = [[[1], [2]], [[3], [4]]] | (2, 2, 1) |
| n | n阶张量 | ... | (d1, d2, ..., dn) |
# tf.squeeze, tf.reduce_mean, tf.reduce_sum, tf.reduce_max, tf.math.log
# 构造一个简单的张量
x = tf.constant([[1.0, 2.0, 3.0],[4.0, 5.0, 6.0]])print("原始张量 x:")
print(x.numpy())# 1. tf.squeeze:去掉维度为1的维度
x_expand = tf.expand_dims(x, axis=0) # shape (1, 2, 3)
print("\n扩展后张量形状:", x_expand.shape)
print("squeeze之后:", tf.squeeze(x_expand).shape) # (2,3)# 2. tf.reduce_mean:求均值
mean_all = tf.reduce_mean(x) # 所有元素的平均值
mean_axis0 = tf.reduce_mean(x, axis=0) # 按列求均值
print("\nreduce_mean 所有元素:", mean_all.numpy())
print("reduce_mean 按列:", mean_axis0.numpy())
#
# 3. tf.reduce_sum:求和
sum_all = tf.reduce_sum(x)
sum_axis1 = tf.reduce_sum(x, axis=1) # 按行求和
print("\nreduce_sum 所有元素:", sum_all.numpy())
print("reduce_sum 按行:", sum_axis1.numpy())
#
# 4. tf.reduce_max:最大值
max_all = tf.reduce_max(x)
max_axis0 = tf.reduce_max(x, axis=0)
print("\nreduce_max 所有元素:", max_all.numpy())
print("reduce_max 按列:", max_axis0.numpy())
#
# 5. tf.math.log:自然对数
log_x = tf.math.log(x)
print("\nlog(x):")
print(log_x.numpy())许多函数和类都有别名。例如,tf.add()和tf.math.add()是相同的函数。这允许TensorFlow为常见的操作提供简洁的名称 。
但是,也有不同的,例如:tf.transpose()函数的功能与NumPy的T属性完全不相同。在TensorFlow中,使用自己的转置数据副本创建一个新的张量,而在NumPy中,t.T只是相同数据的转置视图。类似地,tf.reduce_sum()之所以这样命名,是因为其GPU内核(即GPU实现)使用的reduce算法不能保证元素添加的顺序:32位浮点数的精度有限,因此每次调用此操作时,结果可能会稍有不同。tf.reduce_mean()也是如此(当然,tf.reduce_max()是确定性的)。
2、张量和Numpy之间的转换
张量可以与numpy配合使用:用numpy数组创建张量,反之亦然。两个数据类型可以通过tf.constant()和张量.numpy()进行转换。
| 特性 | NumPy 数组 (np.ndarray) | TensorFlow 张量 (tf.Tensor) |
|---|---|---|
| 核心目的 | 通用数值计算 | 机器学习模型构建和训练 |
| 硬件加速 | 仅在 CPU 上运行 | 可透明地在 CPU, GPU, TPU 上运行 |
| 计算图 | 即时执行(Eager Execution): 命令式编程,代码立即执行并返回结果。 | 两种模式: 1. 即时执行(默认): 和 NumPy 一样立即执行。 |
| 不可变性 | 数组内容可以被修改(可变)。 | 张量内容不可以被修改(不可变)。在机器学习中,模型的权重是 tf.Variable,它是可变的特殊张量。 |
| 梯度计算 | 不支持自动求导(Autograd)。 | 原生支持自动求导(通过 这是训练神经网络(反向传播)的核心功能。 |
| 原生API | 拥有极其丰富和成熟的数学函数库。 | API 更专注于机器学习所需的操作(如卷积、池化、损失函数等)。 |
3、tensorflow的类型转换
类型转换会严重影响性能,并且自动完成的类型转换很容易被忽视。为了避免这种情况,TensorFlow 不会自动执行任何类型转换:如果对不兼容类型的张量执行此操作,会引发异常。例如,不能把浮点数张量和整数张量相加,甚至不能将32位浮点数和64位浮点数相加。
import tensorflow as tf
tf.constant(2.) + tf.constant(40) # 报错,一个是float32,一个是int类型
tf.constant(2.) + tf.constant(40., dtype=tf.float64) # 报错,一个是float64,一个是float32使用tf.cast()方法进行数据类型转换则可以将两个tensor进行相加:
t2 = tf.constant(40, dtype=tf.float64)
tf.constant(2.0) + tf.cast(t2, tf.float32) # 确实需要转换类型时,使用tf.cast()4、张量数组(tf.TensorArray)
张量数组可以理解为张量列表,其默认固定长度,可以动态增长(通常预先指定大小,避免不必要的内存重新分配),包含的张量必须有相同的形状和数据类型。
通常使用有:
- 使用tf.TensorArray()构造函数
- 使用write(index,value)方法在指定的索引位置写入一个张量(这里所有写入的dtype都必须一致,shape也要兼容)
- 使用read(index)方法从指定的索引位置读取一个张量
- 使用stack()方法将TensorArray中所有元素堆叠起来,形成一个更高维度的常见张量
- 使用unstack()方法将一个常规的张量,沿着0维度将每一部分分解并存入TensorArray中
import tensorflow as tfta = tf.TensorArray(dtype=tf.float32, # 要存储的数据类型为:浮点数size=0, # 初始大小, 0表示动态大小,但指定大小更高效dynamic_size=True, # 允许在超出初始大小的时候自动增长clear_after_read=False # 读取后是否清除值
)# clear_after_read参数的展示
array = tf.TensorArray(dtype=tf.float32, size=3)
array = array.write(0, tf.constant([1., 2.]))
array = array.write(1, tf.constant([3., 10.]))
array = array.write(2, tf.constant([5., 7.]))
array.stack() # 现在是一个(3,2)的张量数组
tensor1 = array.read(1) # tf.constant([3., 10.]) , 输出位置清0,也就是读出之后3,10的位置就清零了
tensor1 # 这是一个张量:[3.,10.]
array.stack() # 现在这里第二行的值就被清零了# 展示unstack()的用法
input_tensor = tf.constant([[1, 2], [3, 4], [5, 6]], dtype=tf.float32) # 使用 unstack 将其分解到 TensorArray 中
ta_from_unstack = tf.TensorArray(dtype=tf.float32, size=3) # 这会创建 3 个元素,每个元素的形状是 (2,)
ta_from_unstack = ta_from_unstack.unstack(input_tensor)
elem = ta_from_unstack.read(0) # 读取第一个元素
print(elem) # 输出: tf.Tensor([1. 2.], shape=(2,), dtype=float32)- 与tf.while_loop结合使用
import tensorflow as tf
def dynamic_loop(n):# 1. 创建一个 TensorArray 来收集结果,预先指定大小 nta = tf.TensorArray(dtype=tf.int32, size=n, dynamic_size=False)# 2. 定义循环条件和 body 函数i = 0def cond(i, ta): # 循环条件:i < nreturn i < ndef body(i, ta): # 循环体:将 i*2 写入数组,然后 i+1ta = ta.write(i, i * 2) # 在位置 i 写入值 i * 2return (i + 1, ta)# 3. 执行循环_, final_ta = tf.while_loop(cond=cond, # 循环条件body=body, # 循环体loop_vars=(i, ta),# 循环变量,body执行后更新变量集合parallel_iterations=1 # 对于有写入操作的循环,通常设为 1)# 4. 将结果堆叠成一个一维张量return final_ta.stack()# 调用函数
result = dynamic_loop(5)
print(result) # 输出: tf.Tensor([0 2 4 6 8], shape=(5,), dtype=int32)三、tensorflow函数和计算图
1、计算图
计算图是用于计算任务的有向图,主要由两部分组成:节点(代表操作,包括数学运算、数据输出和输入)和边(代表张量,输入和输出的关系)。它定义了计算步骤和依赖关系,但并不执行实际计算。
计算图的工作模式:惰性求值,它将图与会话进行了分离。一般分为两步:先构建图,再执行图。
构建图:在这个极端,只是定义计算图的机构,代码不会执行任何实际的计算,只是在图中创建节点。
import tensorflow as tf# 1. 构建图
# 定义两个常量节点(操作)
a = tf.constant(5, name='input_a')
b = tf.constant(3, name='input_b')# 定义一个乘法操作节点
c = tf.multiply(a, b, name='mul_c')# 定义一个加法操作节点
d = tf.add(a, b, name='add_d')# 定义最终输出节点,这里的e并不是计算结果而是一个tensor,name为add_e。
e = tf.add(c, d, name='add_e')执行图:这个阶段要实际计算图,并得到结果。它必须在session会话中或调用tf.function执行。session负责将图的操作分配到CPU或GPU等硬件上执行,并提供执行方法。可以联想到文件的操作,有些类似,都需要close操作。
# 2. 在会话中执行图
# 创建一个会话,运行计算图来计算节点 ‘e’ 的值
sess = tf.Session()
output = sess.run(e)
print("Output of the computation:", output) # 输出: 23
sess.close() # 关闭会话,释放资源
# 使用with块更方便
with tf.Session() as sess:output = sess.run(e)print("Output:", output)eager和graph
- eager execution:这是命令式逐行执行的编程方式。操作会在被调用的时候立即计算并返回具体值,像numpy一样。
- graph:就是图执行。先创建图,需要调用的时候在执行对应操作。
既然编程函数就能成功运行程序,为什么要将函数变成计算图,主要有以下4个原因:
- 计算梯度(自动微分):
- 深度学习训练的核心是反向传播,反向传播需要前向运算的“依赖关系”,而计算图正好就是一张依赖图,有输入有输出。
- tensorflow可以在图上“从输出往输入走”,自动套用链式法则。
- 系统可以很容易的分析那些操作时独立的,从而将它们并行的调度到不同的计算机设备(CPU\GPU)上执行,极大的提高效率
- 硬件优化。图是静态的,因此 tf 能够在图级别做很多全局优化,而eager模式下操作时一步步立即执行的,没有机会做整体优化:
- 常数折叠:预先计算那些由常量组成的节点(比如
tf.constant(2) + tf.constant(3)会在图编译时直接被替换为tf.constant(5))。 - 修剪无用的节点:自动去除途中与最终输出无关的计算分支
- 算子融合(简化表达式):将多个小操作合并成一个更大更高效的操作(例如,将矩阵乘法和加法融合成一个单一的操作)
- 内存复用:释放重用张量内存,避免爆显存
- 常数折叠:预先计算那些由常量组成的节点(比如
- 部署和可移植性
- 计算图是一个独立的、与语言和平台无关的实体(一个json/protobuf格式)
- 训练好模型后,可以将图导出:tfserving(服务器上推理)、tf lite(移动端、嵌入式)、tf.js(浏览器)
- 没有图只能在python中运行,无法跨平台部署
- 调试和可视化:图能够在tensorboard中显示:图的结构、数据流、梯度规模、耗时瓶颈
准备好优化的图后,TF函数会以适当的顺序有效地执行图中的操作。因此,TF函数通常比原始的Python函数运行得更快,尤其是在执行复杂计算的情况下。大多数时候,想利用tensorflow加速Python函数时,不需了解更多,只需将其转换为TF函数即可。
2、tf.function
tf.function是一个装饰器,将python函数编译成可调用的计算图。使用它修饰函数后,TensorFlow 在第一次调用时跟踪(Tracing)每一步运算,最终把这些操作记录成一张 计算图(Graph)。之后,在调用function对象的时候执行图中的结构。
默认情况下,TF函数会为每个不同的输入形状和数据类型集生成一个新图,并将其缓存以供后续调用。例如,如果调用tf_cube(tf.constant(10)),将为形状为[ ]的int32张量生成图。如果调用tf_cube(tf.constant(20)),则会重用相同的图。但是,如果随后调用tf_cube(tf.constant([10,20])),则会为形状为[2]的int32张量生成一个新图。这就是TF函数处理多态(即变化的参数类型和形状)的方式。
但是,这仅适用于张量参数:如果将Python数值传递给TF函数,则将为每个不同的值生成一个新图,例如,调用tf_cube(10)和tf_cube(20)将生成两个图。如果用不同的Python数值多次调用TF函数,则会生成许多图,这会降低程序运行速度并消耗大量RAM(必须删除TF函数才能释放它)
@tf.function # 更常用的写法,直接换成装饰器
def tf_cube(x):print(f"x = {x}")return x ** 3
tf_cube.python_function(2) # 使用原始的python函数
tf_cube(tf.constant(2.0)) # 运行多次但只打印一次 ,这里会跟踪1次
# 如果传入的是python数据,则每次都会跟踪生成新的图
tf_cube(2) # 跟踪,生成新的计算图
tf_cube(3) # 跟踪@tf.function 的一个高级且非常重要的用法:使用input_signature参数指定形状和类型来精确控制函数何时被追踪(Retracing)。,只要输入的(形状、类型)与第一次追踪时相同,TensorFlow 就不会再次追踪,而是直接复用之前构建好的计算图,只执行这个高效的图。
# 1. 使用 input_signature 参数指定函数输入的“形状”和类型
@tf.function(input_signature=[tf.TensorSpec([None, 28, 28], tf.float32)])
def shrink(images):# 2. 打印语句,用于调试和观察追踪行为print("Tracing", images)# 3. 函数的实际操作:对图像进行下采样(缩小)return images[:, ::2, ::2]
# 假设我们有一些数据
batch_of_imgs = tf.random.normal([32, 28, 28]) # 32张28x28的图片
another_batch = tf.random.normal([64, 28, 28]) # 64张28x28的图片
wrong_shape_imgs = tf.random.normal([32, 32, 32]) # 错误的形状# 第一次调用:触发追踪
# 输出: Tracing Tensor("images:0", shape=(None, 28, 28), dtype=float32)
result1 = shrink(batch_of_imgs)
print(result1.shape) # 输出: (32, 14, 14)# 第二次调用:批次大小不同,但符合签名 (None, 28, 28) -> 不会重新追踪!
# 不会有 "Tracing" 输出
result2 = shrink(another_batch)
print(result2.shape) # 输出: (64, 14, 14)# 第三次调用:形状不符合签名 (28,28 vs 32,32) -> 会报错!
# 抛出 ValueError: Python inputs incompatible with input_signature
try:result3 = shrink(wrong_shape_imgs)
except ValueError as e:print(e)在自定义指标并在keras模型中使用的时候keras会自动将函数转化称为tf函数,无需使用tf.function(),如果想让keras使用加速线性代数,只需要在调用compile()方法的时候设置jit_compile=True。
在大多数情况下,将执行 TensorFlow 操作的 Python 函数转换为 TF 函数很简单:用 tf.function 装饰它或让 Keras 处理。但是,有一些规则需要遵守:
- 避免调用外部库
- 如果调用任何外部库,包括 NumPy 基础标准库,此调用将在跟踪过程中执行,它不会成为图的一部分。 实际上,TensorFlow 图只能包含 TensorFlow 结构(张量、运算、变量、数据集等)。
- 因此,请使用 `tf.reduce_sum()` 代替 `np.sum()`,使用 `tf.sort()` 代替内置的 `sorted()` 函数。除非确实希望这些代码只在跟踪过程中运行。)
- 随机数生成必须使用 TF 提供的方法
- 如果你写了一个返回 `np.random.rand()` 的 TF 函数 `f(x)`,那么随机数只会在跟踪函数时生成一次。
- tf.constant(2.) 和 tf.constant(np.random.rand()) 返回相同的随机数。但tf.constant([2., 3.])将返回不同的随机值。要生成真正的随机数,请使用 `tf.random.uniform([])`。这样每次操作都会生成新的随机数,因为它属于图的一部分。
- 避免副作用:如果非 TensorFlow 代码具有副作用(例如写日志、更新 Python 计数器),不要期望每次调用 TF 函数都会发生这些副作用,因为它们只会在**跟踪**函数时执行。
- 慎用 `py_function`
- 可以在 `tf.py_function()` 操作中包装任何 Python 代码,但这样会降低性能,因为 TensorFlow 无法对其中代码做任何图优化。
- 这会降低可移植性,因为该代码只能在安装了 Python 的平台上运行。
- Python 函数要符合规则
- 可以调用其他 Python 函数,它们也必须遵循相同的规则,因为 TensorFlow 会在计算图中捕获它们的操作。
- 注意:这些函数本身需要用 `@tf.function` 修饰。
- 变量必须只创建一次
- 如果在 TF 函数内部创建了变量(例如数据集或张量列表),必须确保只创建一次,否则会引发错误。
- 常见做法:在 `__init__` 或 `build()` 方法中创建变量,更新时用 `assign()`,而不是重新赋值。
- 源码可用性
- Python 源码必须可用才能用于 TensorFlow。
- 如果函数定义在交互式 Python shell 中,或者没有源码(比如 `.pyc` 编译文件),生成图可能失败。
- 避免使用 Python 原生循环遍历 Dataset
- TensorFlow 图会捕获张量级别的循环(`tf.range()`),而不会捕获 Python 原生 `for` 循环。
- 如果用 Python 的 `for` 循环迭代 Dataset,则无法在图模式下被捕获,也无法在分布式环境下正常运行。(不在图里的计算,无法重现到其他机器)
- 出于性能原因,应尽可能使用向量化实现,而不是使用循环。