机器学习-逻辑回归-考试预测通过-1
逻辑回归:用于解决分类问题的一种模型。根据数据特征或属性,计算其归属于某一类别的概率
,根据概率数值判断其所属类别。主要应用场景:二分类问题。
考试预测通过实战:
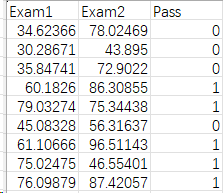
examdata.csv数据如图:
Pass等于0划分为考试未通过,Pass等于1划分为考试通过。
边界函数: theta0+theta1 * x1 +theta2 * X2 = 0
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
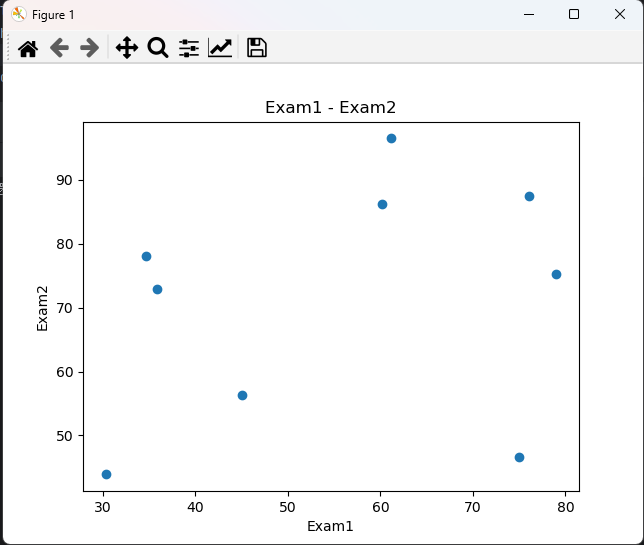
data=pd.read_csv('examdata.csv')fig1 = plt.figure()
plt.scatter(data.loc[:,'Exam1'],data.loc[:,'Exam2'])
plt.title('Exam1 - Exam2')
plt.xlabel('Exam1')
plt.ylabel('Exam2')
plt.show()
# add label mask
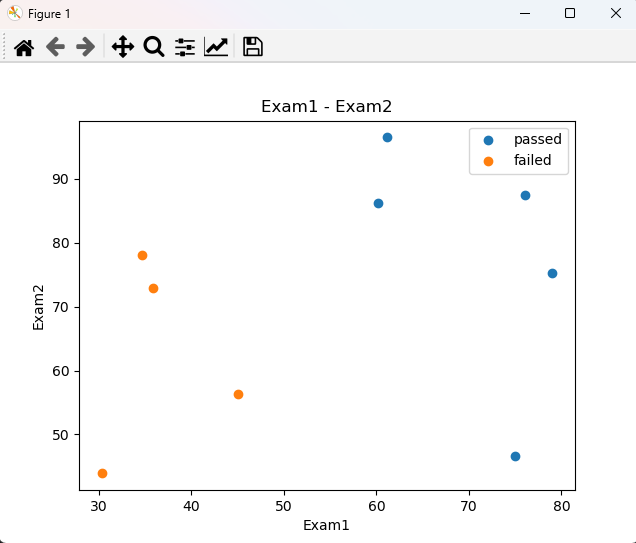
mask=data.loc[:,'Pass'] == 1fig2 = plt.figure()
passed = plt.scatter(data.loc[:,'Exam1'][mask],data.loc[:,'Exam2'][mask]) # 筛选通过考试的用户
failed = plt.scatter(data.loc[:,'Exam1'][~mask],data.loc[:,'Exam2'][~mask]) #筛选未通过考试的用户
plt.legend((passed, failed), ('passed', 'failed')) # 增加一个右上角的标签
plt.title('Exam1 - Exam2')
plt.xlabel('Exam1')
plt.ylabel('Exam2')
plt.show()# define X,y
X = data.drop(['Pass'],axis= 1)
y = data.loc[:,'Pass']
X1 = data.loc[:,'Exam1']
X2 = data.loc[:,'Exam2']# establish the model and train it
from sklearn.linear_model import LogisticRegression
LR = LogisticRegression()
LR.fit(X,y)# show the predicted result and its accuracy
y_predict = LR.predict(X)
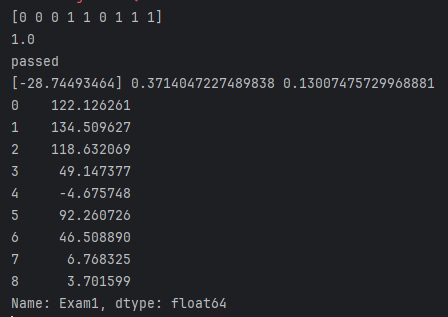
print(y_predict)# evaluate the model
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y,y_predict)
print(accuracy)# 使用模型进行预测
# exam1=70,exam2=65
y_test=LR.predict([[70,65]])
print('passed' if y_test==1 else 'failed')# 输出边界函数:
theta0 = LR.intercept_
theta1,theta2 = LR.coef_[0][0],LR.coef_[0][1] # 两个变量对应两个θ
print(theta0,theta1,theta2)
# theta0+theta1 * x1 +theta2 * X2 = 0
X2_new = -(theta0+theta1*X1)/theta2 # 用X1反推X2_new
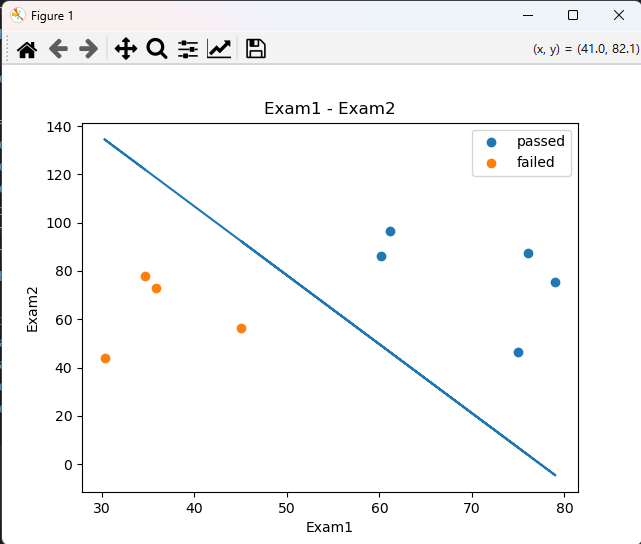
print(X2_new)fig3 = plt.figure()
passed = plt.scatter(data.loc[:,'Exam1'][mask],data.loc[:,'Exam2'][mask])
failed = plt.scatter(data.loc[:,'Exam1'][~mask],data.loc[:,'Exam2'][~mask])
plt.legend((passed, failed), ('passed', 'failed'))
plt.plot(X1,X2_new) # 画出边界函数
plt.title('Exam1 - Exam2')
plt.xlabel('Exam1')
plt.ylabel('Exam2')
plt.show()运行结果:
初始数据拟合图:
数据分类图:
数据分类+边界函数图:
控制台结果: