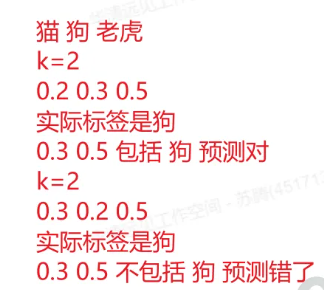
小杰机器学习高级(five)——分类算法的评估标准
1. 混淆矩阵是什么?
混淆矩阵(Confusion Matrix)是用于评估分类模型性能的一种表格,特别是在二分类问题中。它展示了模型在预测过程中实际类别和预测类别之间的关系。混淆矩阵的四个元素分别是真正例(True Positive, TP)、真负例(True Negative, TN)、假正例(False Positive, FP)和假负例(False Negative, FN)。
下面是混淆矩阵的一般形式:

解释每个元素的含义:
●真正例 (True Positive, TP): 模型正确地将正类别样本预测为正类别的数量。
●真负例 (True Negative, TN): 模型正确地将负类别样本预测为负类别的数量。
●假正例 (False Positive, FP): 模型错误地将负类别样本预测为正类别的数量。
●假负例 (False Negative, FN): 模型错误地将正类别样本预测为负类别的数量。
混淆矩阵可以帮助计算许多分类性能指标,如准确度(Accuracy)、精确度(Precision)、召回率(Recall)、F1 分数等。这些指标提供了对模型在不同方面性能的更详细的了解,有助于评估其适用性和效果。
2. 评估指标
1准确度(Accuracy):
○描述模型正确预测样本的能力。
2.损失函数(Loss):
观察模型在测试集上的损失函数值,可以帮助了解模型的泛化能力。低损失值表明模型在未见过的数据上表现较好。
3.精确度(Precision):
精确度是指所有被模型预测为正类的样本中实际为正类的比例。它关注的是预测为正类的准确性,衡量模型在预测为正类的样本中有多少是真正的正类。

假设在测试集中,LeNet-5将100张手写数字图片识别为数字3。而其中80张是真实的数字3,而其他20张是其他数字被错误地预测为数字3。
真正例:是模型预测为数字3的图片数量,即80张。
假正例:是模型错误地将其他数字预测为数字3的图片数量,这里是20张
所以,精确度可以计算为:
Precision=80/(80+20)=0.8
4 召回率(Recall):召回率是指所有实际为正类的样本中被模型正确的识别为正类的比例。
●衡量模型对于真正的正类样本能够检测出多少。

例子巩固:
假设在测试集中共有1000张手写数字图片。其中实际是数字3的图片有200张。LeNet-5将其中150张图片正确预测为数字3,但有50张实际是数字3的图片被错误地预测为其他数字。
正例:是模型预测为数字3的图片数量,即150张。
假负例:是模型错误地将其他数字预测为数字3的图片数量,这里是50张
所以,召回率可以计算为:
Recall=150/(150+50)=0.75
5.F1分数(f1 Score)
F1分数是精确度(Precision)和召回率(Recall)的调和平均数它综合考虑了模型的预测精度和覆盖率。
公式如下:
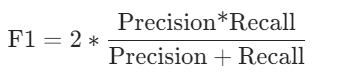
假设有100张手写数字图片,其中有30张实际是数字3。
假设LeNet-5将其中25张图片正确地预测为数字3,但是有5张实际是数字3的图片被错误地预测为其他数字,有 10张是其他数字的图片被错误的预测为3。
在这个例子中,
真正例:25张(25张图片正确地预测为数字3)
假正例:10张(其他数字的图片被错误的预测为3)
假负例:5张(实际是数字3的图片被错误地预测为其他数字)
Precision=25/(25+10)=0.714
Recall=25/(25+5)=0.833
计算
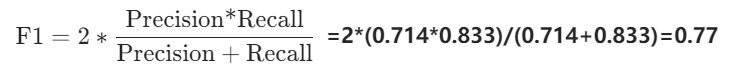
LeNet-5在这个例子中F1分数约为0.77。这个值表明模型在同时考虑了精确度和召回率后的综合性能。
F1分数是精确度和召回率的调和平均数,它为模型的综合性能提供了一个单一的度量。F1分数越高,意味着模型在召回率和精度度上都表现良好,综合性能较优。
6.ROC 曲线和AUC(ROC Curve and AUC):
●ROC 曲线是用于评估二分类模型性能的一种可视化工具。它以假正例率(False Positive Rate,FPR)为横坐标,真正例率(True Positive Rate,TPR)为纵坐标,绘制出的曲线反映了模型在不同阈值下的分类性能。

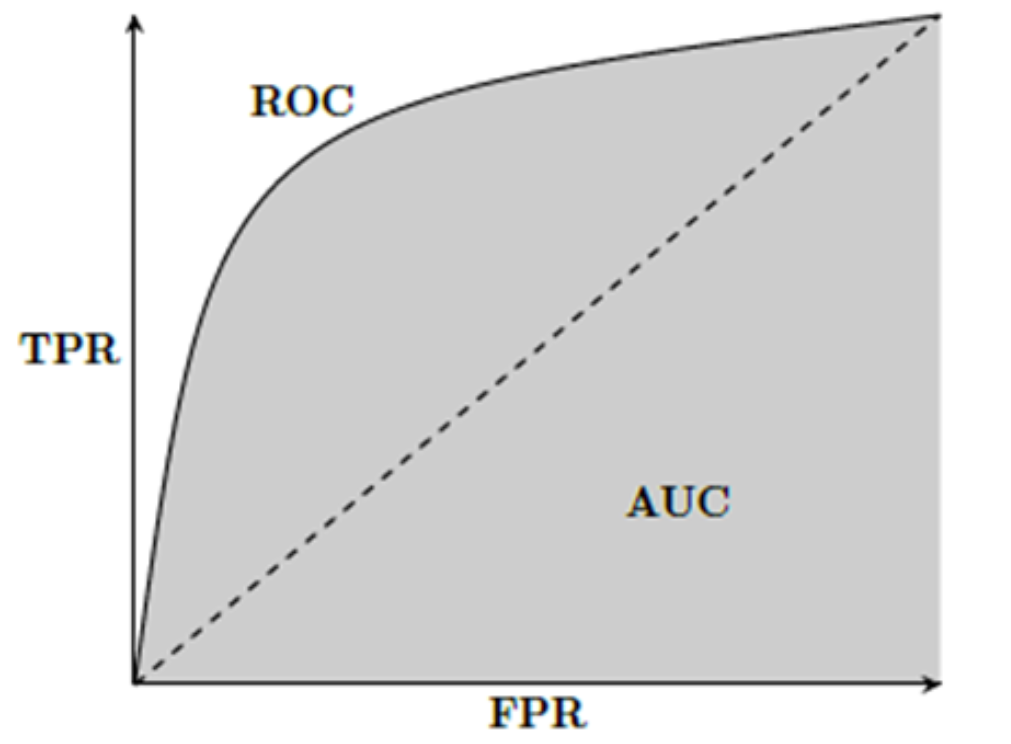
AUC(Area Under the Curve)是 ROC 曲线下的面积,用于衡量模型在不同阈值下的性能。
●通常,AUC越接近1,模型性能越好。
.7.均方误差(Mean Squared Error,MSE):
○用于衡量回归模型预测值与实际值之间的平方差的平均值。
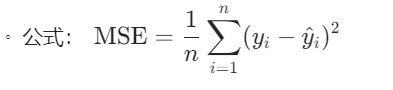
8.Top-K精度
在多分类任务中,有时会考虑模型预测的前K个最优可能类别中是否包含正确答案,这种情况下会用到Top-K精度作为评估指标。