深度学习(十一):深度神经网络和前向传播
深度神经网络的核心思想是将输入数据通过多层非线性变换逐步映射到输出空间。这个过程的核心机制就是 前向传播(Forward Propagation, FP)。
深度神经网络(DNN)
神经元模型
人工神经网络的灵感来源于生物神经元。一个神经元的基本计算过程为:
- 接收来自前一层的输入信号;
- 对输入加权求和并加上偏置项;
- 通过非线性激活函数得到输出;
- 将输出传递到下一层。
数学形式表示为:

网络层次结构
一个典型的深度神经网络由以下几部分组成:
- 输入层:负责接收原始数据,如图像像素或文本特征;
- 隐藏层:通常包含多个层,每层由大量神经元构成,逐步抽象和提取数据特征;
- 输出层:给出最终结果,如分类概率或预测值。
当网络层数超过两层隐藏层时,就被称为“深度神经网络”。
前向传播(Forward Propagation)
定义
前向传播是指:数据从输入层经过各层神经元的加权求和与激活函数运算,逐层传递,最终在输出层得到预测结果的过程。
它可以看作是一种 函数复合:
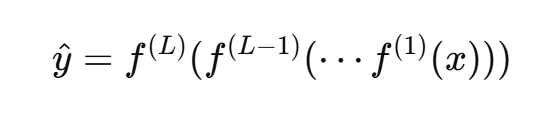
其中:
- x 为输入,
- L为网络层数,
- f(l) 表示第 l 层的非线性变换。
数学推导
假设第 l 层有 n[l] 个神经元,则:
-
线性计算:
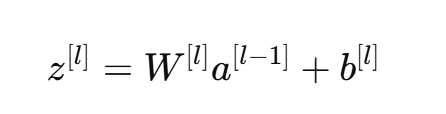
其中:
- W[l] 是第 l 层的权重矩阵,
- b[l] 是偏置向量,
- a[l−1] 是上一层的输出(第0层为输入 x)。
-
激活函数:
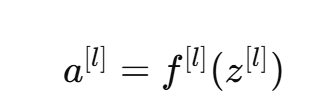
-
最终输出:
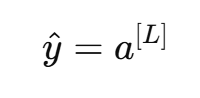
激活函数的作用
若没有激活函数,神经网络就退化为简单的线性变换,无法表示复杂的非线性关系。常见激活函数包括:
- Sigmoid:输出范围 (0,1),常用于二分类;
- Tanh:输出范围 (-1,1),相对居中;
- ReLU(Rectified Linear Unit):常用,计算简单,解决梯度消失问题;
- Softmax:常用于多分类输出,将结果转化为概率分布。
前向传播的实现流程
一个典型的前向传播步骤如下:
- 输入数据准备:将训练样本或测试样本输入网络;
- 逐层线性计算与激活:对每一层执行 z=Wx+b 和 a=f(z);
- 结果输出:在最后一层获得预测值;
- 损失函数计算:通过损失函数衡量预测结果与真实标签之间的差异。
常见损失函数包括:
- 均方误差(MSE):用于回归问题;
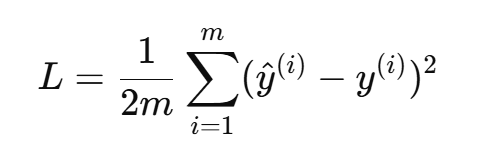
- 交叉熵损失(Cross-Entropy Loss):用于分类问题;
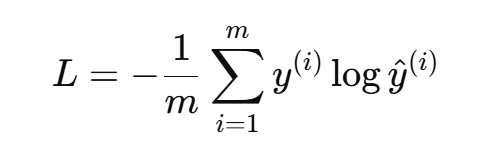
前向传播的示例
假设一个简单的神经网络:
- 输入层:2个神经元;
- 隐藏层:2个神经元;
- 输出层:1个神经元。
输入:
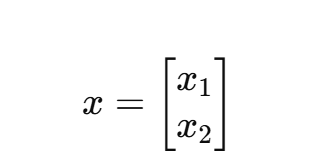
隐藏层计算:
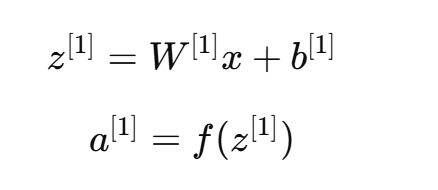
输出层计算:
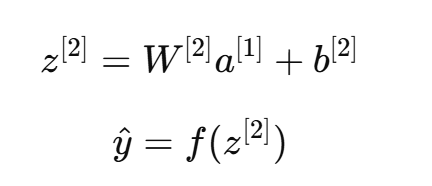
整个过程就是一次完整的前向传播。
前向传播特点
- 多层次抽象能力:前向传播通过层层变换,使低级特征(像素点、词向量)逐步转化为高级语义特征(物体类别、语义含义)。
- 参数规模大:DNN中通常包含数百万甚至数亿个参数,因此前向传播需要高效的矩阵运算库(如 BLAS、CUDA)。
- 可并行化计算:前向传播中的矩阵乘法和激活函数运算可高度并行化,这是 GPU 加速深度学习的重要原因。
应用案例
- 图像识别:输入为像素矩阵,前向传播逐层提取边缘、纹理、形状等特征,最终输出类别概率。
- 语音识别:输入为声学特征(MFCC等),通过前向传播提取语音模式,输出对应文字。
- 自然语言处理:输入为词向量,前向传播提取语义关系,输出情感分类或翻译结果。
总结与展望
深度神经网络通过多层结构和非线性映射实现了对复杂问题的强大建模能力,而前向传播是其中最基本、最核心的计算过程。它不仅是模型训练的起点,也是模型推理的关键步骤。
随着计算能力和数据规模的提升,前向传播在更深层次网络(如卷积神经网络CNN、循环神经网络RNN、Transformer等)中得到了更广泛的应用。未来,如何进一步优化前向传播的计算效率、降低能耗、提升模型可解释性,将是深度学习的重要研究方向。