【论文阅读】GR-1:释放大规模视频生成式预训练用于视觉机器人操控
ByteDance研究院推出了GR-1,一个GPT风格的Transformer,它利用大规模以自我为中心的视频生成预训练,在多任务视觉机器人操纵中实现了增强的泛化能力和数据效率。该模型在基准测试和真实世界任务中均优于现有基线,在未见场景和语言泛化以及有限机器人数据方面表现出鲁棒性能。
引言
机器人学习领域长期以来一直受制于数据稀缺的挑战——收集多样化、高质量的机器人演示既昂贵又耗时。本文介绍了 GR-1 模型,该模型通过将自然语言处理和计算机视觉领域非常成功的生成式预训练范式应用于视觉机器人操作,从而解决了这一根本性瓶颈。其关键洞察在于,机器人轨迹本质上是视频序列,而根据过去的观测和语言指令预测未来视觉状态的能力可以作为学习机器人策略的强大基础。
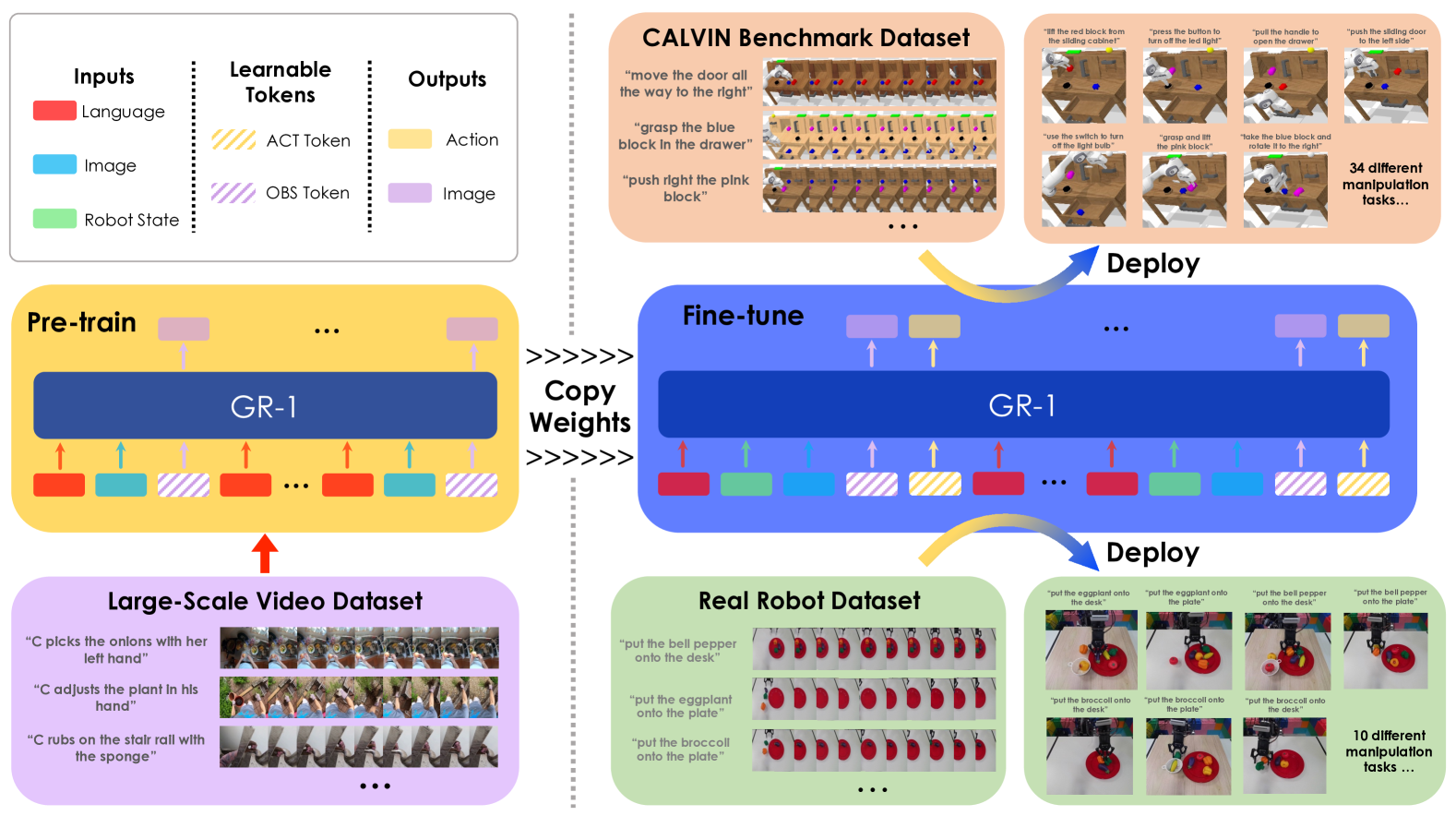
字节跳动研究院的作者们证明,通过在大型第一视角视频数据(来自 Ego4D 数据集的 800,000 个片段)上预训练一个 GPT 风格的 Transformer,可以显著提高下游机器人操作任务的性能。这种方法代表了与传统主要依赖于特定机器人演示数据的机器人学习方法的一次范式转变。
架构与方法
GR-1 采用统一的 GPT 风格 Transformer 架构,通过专用编码器和可学习的 token 处理多种输入模态。该模型通过冻结的 CLIP 文本编码器处理语言指令,通过使用掩码自编码器预训练的冻结 Vision Transformer (ViT) 处理视觉观测,并通过线性层处理机器人状态。
该架构引入了两个关键的可学习 token:用于动作预测的 [ACT] token 和用于未来图像预测的 [OBS] token。这些 token 在训练期间被策略性地掩码,以保持自回归特性并防止信息泄露。模型的序列处理包括时间嵌入和每个时间步重复的语言 token,以确保一致的指令条件作用。
训练遵循两阶段方法:
阶段1 - 视频生成预训练:模型学习在给定语言描述和过去观测的情况下预测未来的视频帧。此阶段使用以下公式:
$$
\pi(l, o_{t-h:t}) \rightarrow o_{t+\Delta t}
$$
其中 $l$ 表示语言指令,$o_{t-h:t}$ 是过去的观测,而 $o_{t+\Delta t}$ 是未来帧(其中 $\Delta t = 1/3$ 秒)。
阶段2 - 机器人微调:模型通过联合预测动作和未来图像来适应机器人控制:
$$
\pi(l, o_{t-h:t}, s_{t-h:t}) \rightarrow o_{t+\Delta t}, a_t
$$
其中 $s_{t-h:t}$ 表示机器人状态,$a_t$ 是预测的动作。
损失函数结合了多个目标:
$$
L_{finetune} = L_{arm} + L_{gripper} + L_{video}
$$
其中 $L_{arm}$ 对连续机械臂动作使用 Smooth-L1 损失,$L_{gripper}$ 对夹持器控制使用二元交叉熵,$L_{video}$ 对图像重建使用均方误差。
实验结果
作者们在 CALVIN 基准(模拟)和真实机器人任务上进行了全面的实验,以验证他们的方法。
CALVIN 基准性能
在具有34个操作任务的挑战性 CALVIN 基准上,GR-1 显著优于现有方法:
- 多任务学习:实现了94.9%的成功率(HULC 为88.9%),平均任务完成长度为4.21(HULC 为3.06)
- 零样本泛化:在未见过的场景中展示了85.4%的成功率(RT-1 为53.3%)
- 数据效率:在仅使用10%训练数据的情况下保持了77.8%的成功率(HULC 为66.8%)
- 语言泛化:在 GPT-4 生成的同义指令上实现了76.4%的成功率


真实机器人实验
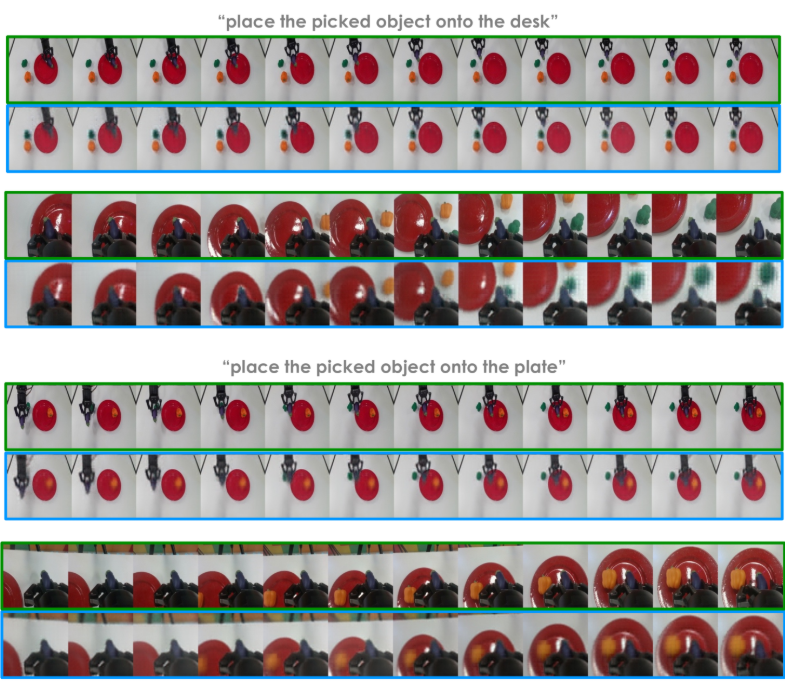
实际实验表明,GR-1在不同场景中具有实际适用性:
- 物体搬运(已见物体):79%的成功率(RT-1为27%)
- 未见物体实例:73%的成功率,显示出强大的泛化能力
- 未见物体类别:30%的成功率,表明有前景但具挑战性的泛化能力
- 关节物体操作:75%的成功率用于抽屉的开合任务

技术贡献与创新
该论文提出了几项关键的技术贡献,使其区别于现有方法:
统一的视频-动作学习:与将视觉理解与动作预测分离的方法不同,GR-1在单一的Transformer架构中共同学习这两个任务。这种设计利用了预测未来视觉状态为动作生成提供宝贵指导的直觉。
大规模跨领域预训练:使用来自Ego4D的80万个以自我为中心的视频片段进行预训练,这与机器人专用预训练数据集显著不同。这种方法极大地增加了模型可用的预训练数据的多样性和规模。
冻结编码器策略:通过在整个训练过程中保持CLIP文本编码器和MAE视觉编码器冻结,GR-1保留了强大的预学习表示,同时使Transformer骨干网络适应机器人任务。
时间遮蔽策略:在训练过程中对动作和观测标记进行仔细遮蔽,保持了自回归特性,同时能够共同预测多种输出模态。
意义与影响
这项工作通过几项重要贡献解决了机器人学习中的基本挑战:
数据效率:通过证明大规模视频预训练可以显著减少对机器人专用演示的需求,该论文为更具可扩展性的机器人学习提供了一条实用的路径。10%的数据效率结果对于演示收集昂贵的实际应用尤其引人注目。
泛化能力:在未见场景、物体和语言指令上的出色表现表明,视频预训练提供了强大的视觉-语言理解能力,并能有效地转移到机器人任务中。这种泛化能力对于在多样化、非结构化环境中部署机器人至关重要。
架构简洁性:统一的GPT风格架构为多模态机器人学习提供了一个清晰的框架,与更复杂的、多组件的方法相比,可能简化未来机器人学习系统的开发。
跨领域迁移:从人类自我中心视频到机器人操作的成功迁移表明,利用大量人类活动数据进行机器人学习的潜力,为数据收集和模型训练开辟了新途径。
这项工作确立了视频生成预训练作为机器人学习的一种可行方法,并为未来该方向的研究奠定了基础。在多个评估指标和场景中持续的改进表明,这种范式可能成为开发强大机器人策略的标准方法。