第14章 MySQL索引
第14章 MySQL索引
MySQL索引-语法
查看索引
查看索引的语法:
show index from 表名;
创建索引
创建索引语法如下:
create [ unique ] index 索引名 on 表名 (字段名,... ) ;
案例:为device_data 表的iot_id和product_key字段建立一个索引
create index idx_iot_id_product_key on device_data (iot_id, product_key);
在创建表时,如果添加了主键和唯一约束,就会默认创建:主键索引、唯一约束索引
注意事项:
- 一般情况下,要选择经常作为查询条件的字段作为索引
- 多字段做索引:
idx_idx_location_type_physical_location_type_access_location
删除索引
语法:
drop index 索引名 on 表名;
案例:删除 tb_emp 表中name字段的索引
drop index idx_iot_id_product_key on device_data ;
MySQL索引-分类
在MySQL数据库,将索引的具体类型主要分为以下几类:主键索引、唯一索引、常规索引、全文索引。
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对于表中主键创建的索引 | 默认自动创建, 只能有一个 | PRIMARY |
| 唯一索引 | 避免同一个表中某数据列中的值重复 | 可以有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 全文索引查找的是文本中的关键词,而不是比较索引中的值 | 可以有多个 | FULLTEXT |
而在在InnoDB存储引擎中,根据索引的存储形式,又可以分为以下两种:
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引(Clustered Index) | 将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据 | 必须有,而且只有一个 |
| 二级索引(Secondary Index) | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以存在多个 |
聚集索引(聚簇索引)选取规则:
- 如果存在主键,主键索引就是聚集索引。
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
- 如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引。
聚集索引和二级索引的具体结构如下:
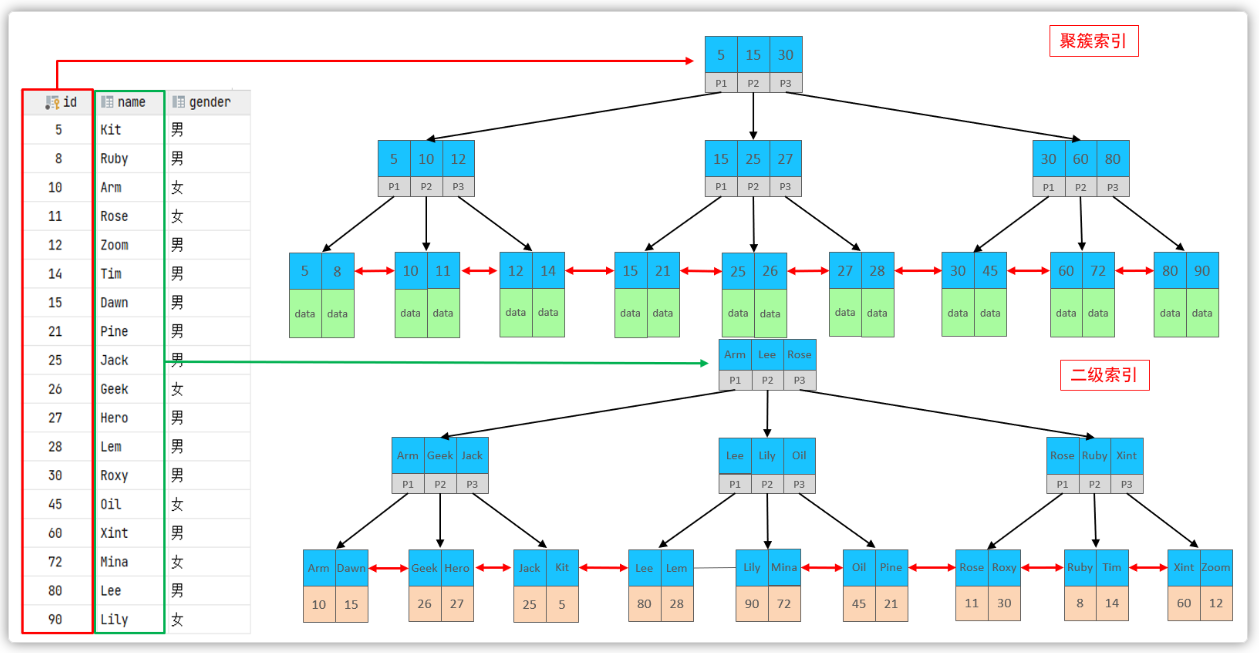
- 聚集索引的叶子节点下挂的是这一行的数据 。
- 二级索引的叶子节点下挂的是该字段值对应的主键值。
接下来,咱们来分析一下,当咱们执行如下的SQL语句时,具体的查找过程是什么样子的。
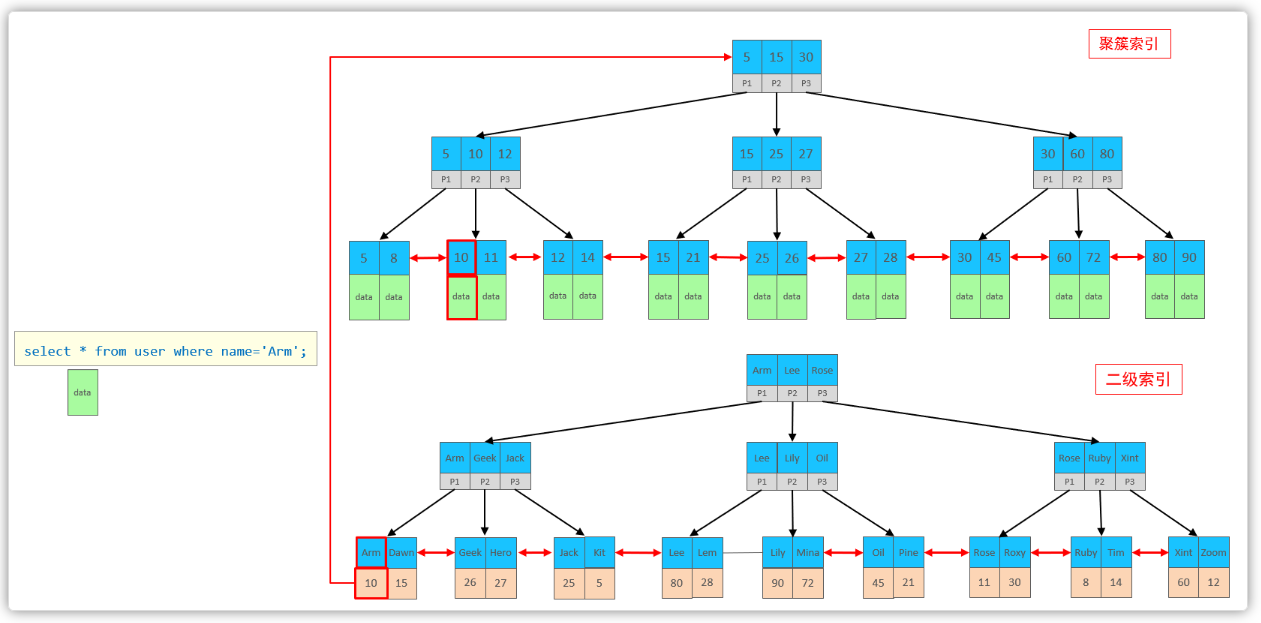
具体过程如下:
①. 由于是根据name字段进行查询,所以先根据name='Arm’到name字段的二级索引中进行匹配查找。但是在二级索引中只能查找到 Arm 对应的主键值 10。
②. 由于查询返回的数据是*,所以此时还需要根据主键值10,到聚集索引中查找10对应的记录,最终找到10对应的行row。
③. 最终拿到这一行的数据,直接返回即可。
回表查询: 这种先到二级索引中查找数据,找到主键值,然后再到聚集索引中根据主键值,获取数据的方式,就称之为回表查询。
索引失效检查
可以采用EXPLAIN 或者 DESC命令获取 SELECT 语句的执行计划
语法:
EXPLAIN SELECT 字段列表 FROM 表名 WHERE 条件 ;

-
possible_keys 当前sql可能会使用到的索引
-
key 当前sql实际命中的索引
-
key_len 索引(物理内存)占用的大小
-
常见数据类型大致的
key_len计算方式(以常见默认设置为例):数据类型 是否允许 NULL 字符集(如适用) 大致 key_len 值 计算说明 INT 否 - 4 字节 固定长度 4 字节 INT 是 - 5 字节 4 字节 + 1 字节(NULL 标识) BIGINT 否 - 8 字节 固定长度 8 字节 VARCHAR(10) 否 utf8mb4 42 字节 10字符 * 4字节/字符 + 2字节(记录实际长度) VARCHAR(10) 是 utf8mb4 43 字节 上述 42 字节 + 1 字节(NULL 标识) CHAR(10) 否 utf8mb4 40 字节 10字符 * 4字节/字符
-
-
Extra 额外的优化建议
Extra 含义 Using index 查找使用了索引,需要的数据都在索引列中能找到,不需要回表查询数据 Using where 没有找到合适的索引 Using index condition 查找使用了部分索引,但是需要回表查询数据 Using where; Using index 查找使用了部分索引,需要的数据都在索引列中能找到,不需要回表查询数据
-
type 这条sql的连接的类型,性能由好到差为NULL、system、const、eq_ref、ref、range、 index、all
- system:查询最多只有一条记录的表,几乎不会出现
- const:根据主键查询(只扫描一行。效率最高)
- eq_ref:主键索引查询或唯一索引查询(通常是多表联查中性能最优的连接类型之一)
- ref:索引查询(扫描索引中匹配某个单值的所有行)
- range:范围查询(扫描索引中特定范围的条目)
- index:索引树扫描(扫描整个索引结构,比 all 好)
- all:全盘扫描(扫描整张表,效率低)
索引失效场景
- 不符合最左匹配法则
- 范围查询右边的列,不能使用索引
- 不要在索引列上进行运算操作, 索引将失效
- 字符串不加单引号,造成索引失效(类型转换)
- 以%开头的Like模糊查询,索引失效
索引可存储行数
计算一个三层的 B+Tree 数据结构的索引可存储多少行数据?
三层 B+ 树索引能存储的数据量取决于几个关键参数。下面是一个快速参考表格:
| 关键参数 | 典型值/假设 | 说明 |
|---|---|---|
| 节点大小(页大小) | 16 KB | InnoDB 存储引擎的默认设置,是磁盘 I/O 和数据存储的基本单元。 |
| 主键类型 | BIGINT(8 字节) | 假设使用 8 字节的长整型作为主键。 |
| 指针大小 | 6 字节 | InnoDB 中指向子节点(页)的指针通常占用 6 字节。 |
| 单行数据大小 | 1 KB | 一个常见的业务表数据行大小的估算值。 |
| 非叶子节点容量 | 约 1170 个索引项 | 单个非叶子节点可存储的键值对(主键+指针)数量,计算过程见下文。 |
| 叶子节点容量 | 16 行数据 | 单个叶子节点可存储的数据行数量,计算过程见下文。 |
| 总数据行数 | 约 2190 万行 | 在以上典型假设下,三层 B+ 树能存储的估算数据总量。 |
⚖️ 重要影响因素
需要强调的是,“约2190万行”是一个基于特定假设的理论值。实际情况会受到以下因素影响:
-
主键类型:若使用 4 字节的 INT 主键,指针仍为6字节,则索引项变为10字节。分支因子
fan_out = 16384 / 10 ≈ 1638。总叶子节点数 = 1638 * 1638 ≈ 2,683,044个。若每行仍为1KB,则总行数可达 2,683,044 * 16 ≈ 42,928,704行。可见主键类型影响巨大。 -
行实际大小:这是另一个关键变量。如果你的表字段很少,单行大小只有 200 字节,那么一个叶子页可存储
16KB / 0.2KB ≈ 80行。总行数会非常庞大(1,368,900 * 80 ≈ 1.09亿行)。反之,若单行很大(例如包含长文本),存储的行数会急剧减少。 -
页面填充率:上面的计算均假设每个页都100%填满。但实际上,由于数据不断的插入、删除和更新,页面会存在一定的碎片空间,平均填充率可能只有 70% - 90%。因此,实际存储量通常低于理论值。
-
索引类型:以上计算针对的是聚簇索引(在InnoDB中通常就是主键索引),其叶子节点直接存储完整行数据。如果是二级索引(非聚簇索引),其叶子节点存储的是主键值而非完整数据。
因此,相同条件下,一个三级B+树的二级索引可以“覆盖”的行数会多得多,因为它每页能存储的索引条目更多。
🔍 补充说明
- 如果键更大(如 UUID,16 字节),扇出会降低,总容量减少。
- 如果页更大(如使用 32KB 或 64KB 页),容量会显著增加。
- 实际中还会受填充因子、行格式、变长字段等影响,此为理论最大值。