π0:一个 VLA 流匹配模型用于通用机器人控制(又称 pi0)
π0\pi_0π0:一个 VLA 流匹配模型用于通用机器人控制
关键词:具身智能;VLA

- 论文题目:π0\pi_0π0: A Vision-Language-Action Flow Model for General Robot Control
- arXiv:2410.24164
- 单位:Physical Intelligence
- https://www.physicalintelligence.company/blog/pi0

论文速读:
- 研究问题:现有的具身智能模型跨本体能力弱,未达到现实世界所需要的泛化水平,对新任务的鲁棒性弱。
- 研究方法:本文提出了一个基于 VLM 的 flow matching 架构,
- 利用 VLM 引入互联网规模的语义知识。基于 VLM 架构的模型集成了语言-视觉模型在常识认知、语义推理和问题解决方面的核心能力;
- 通过机器人动作模态的扩展训练,将其升级为 VLA 模型。
实验部分涵盖了各种各样的任务,例如叠衣服、清理桌子和组装盒子。
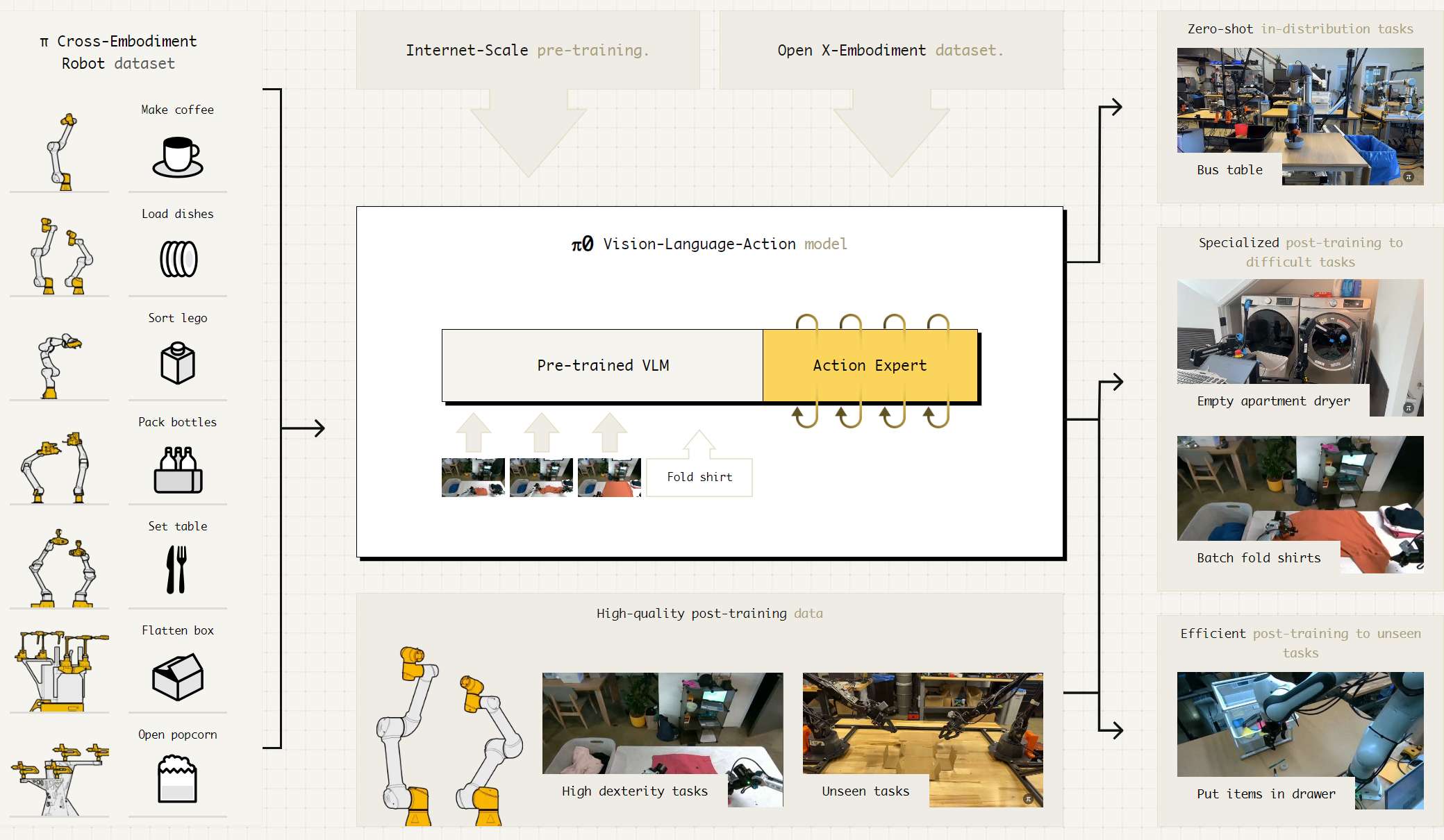
本文所谓的“通用”,既指任务的多样性,也指可部署机器人的泛用性。演示效果可以查看其官网 blog。
π0\pi_0π0 方法介绍
Input / Output
π0\pi_0π0 可以建模为一个数据分布 p(At∣ot)p(A_t | o_t)p(At∣ot)
- Input:ot=[It1,…,Itn,lt,qt]o_t = [I_t^1, \dots, I_t^n, l_t, q_t]ot=[It1,…,Itn,lt,qt] 是一个观测值,包括:
- 在一个 timestep 的最多 3 个 RGB images,其中 ItiI_t^iIti 是第 i 个 image;
- 文本指令,ltl_tlt 是语言 token 序列;
- 机器人的本体感受状态,qtq_tqt 是关节角度的向量。
- Output:预测的未来动作 action chunk A=[at,at+1,…,at+H−1]A = [a_t, a_{t+1}, \dots, a_{t+H-1}]A=[at,at+1,…,at+H−1],对于本文的任务,使用了 H = 50。
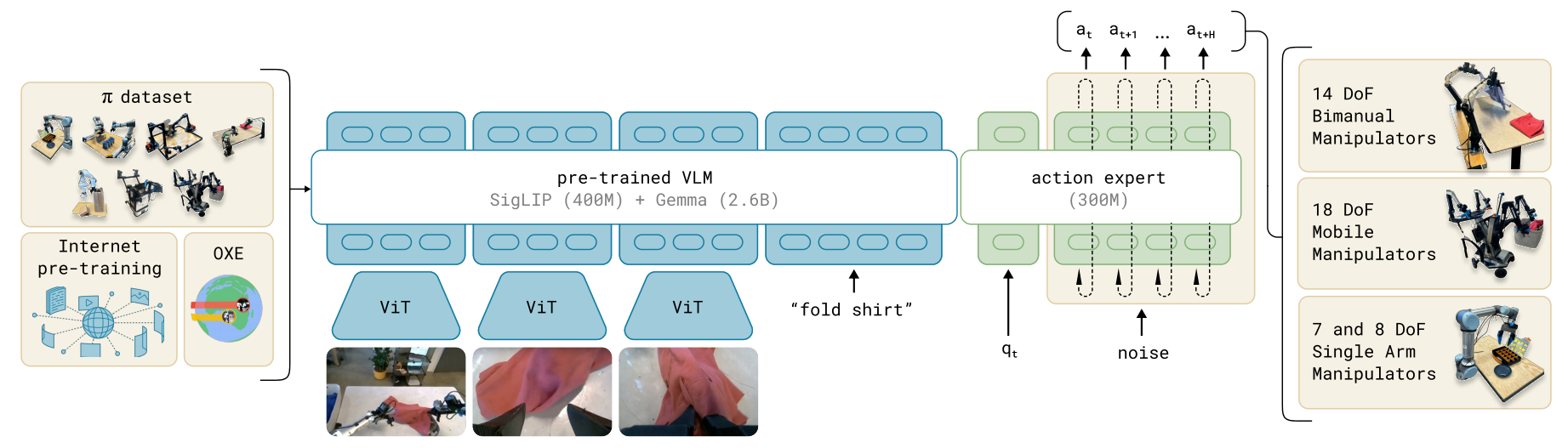
Architecture
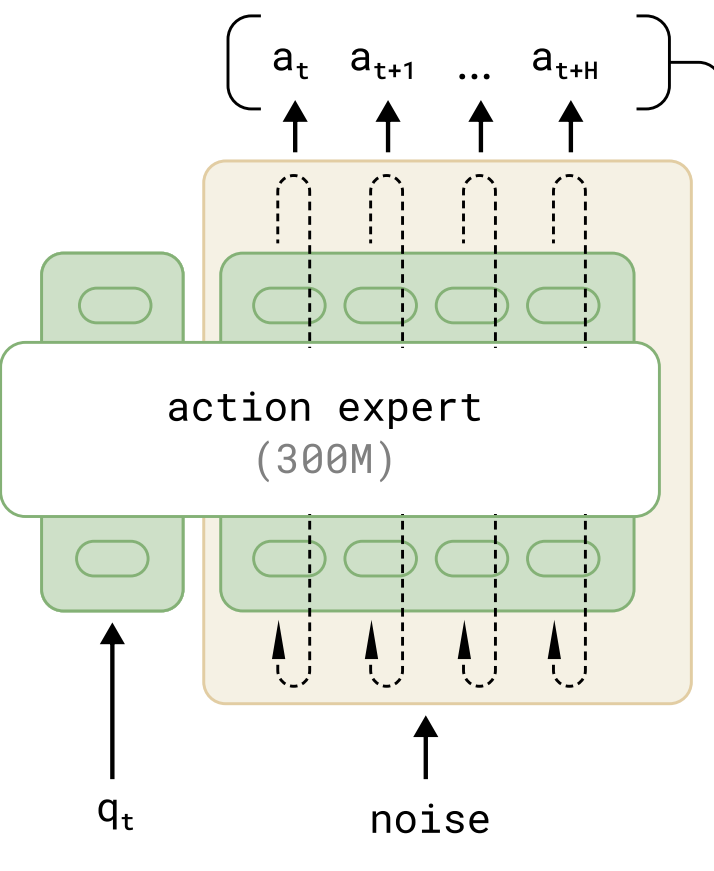
受 Transfusion 启发:通过单一 Transformer 处理多类目标,其中 continuous tokens 受到 flow matching loss 监督,discrete tokens 受到 cross-entropy loss 监督。于是,π0\pi_0π0 在 Transfusion 基础上,为机器人专用 token(动作和状态)配置了独立权重可提升性能,这样的设计类似于多专家系统:第一专家(VLM 主干部分)来处理图像和文本输入,第二专家(Action Expert)专用于机器人的专用输入输出。
π0\pi_0π0 包含两大部分:
- 预训练的 VLM 主干;
- 一个独立的相对较小的 Language Model(即 Action Expert),用于处理机器人状态和 noisy action。
两个模型的深度和 Attention 结构一样,但宽度不同,其 config 初始化代码如下:
if variant == "gemma_2b":return Config(width=2048,depth=18,mlp_dim=16_384,num_heads=8,num_kv_heads=1,head_dim=256,)if variant == "gemma_300m":return Config(width=1024,depth=18,mlp_dim=16_384,num_heads=8,num_kv_heads=1,head_dim=256,)
之所以 Action Expert 会输入 noisy action,是因为它是一个 Flow Matching 模型,类似于 Diffusion 一样需要多次 denoise。因此,π0\pi_0π0 在一次推理时,庞大的 VLM 只会运行一次,而小的 Action Expert 会多次运行。
语言模型主干 PaliGemma
π0\pi_0π0 的 VLM 主干 PaliGemma 包含三个部件:
- 图像编码器 SigLIP(400M 参数量):该模型通过 sigmoid 损失进行大规模对比预训练,在小规模模型中展现出较好的性能。
- Gemma-2B:在性能和参数量之间取得了优异平衡。
- 线性投影层:将 SigLIP 输出的 token 投影到与 Gemma-2B 词嵌入相同的维度空间以实现拼接。
Action Expert
这是一个 Flow Matching 模型,由 flow-matching loss 进行监督学习。输入包括一个机器人的本体感知状态 qtq_tqt 和一个 noisy action,然后通过多次 denoise 得到一个 action chunk。
✏️ Flow Matching 可以理解成,它可以把扩散的多个步骤用一个等效函数来代替。
Inference Pipeline
VLM 部分
VLM 部分所使用的 PaliGemma 如下图所示:
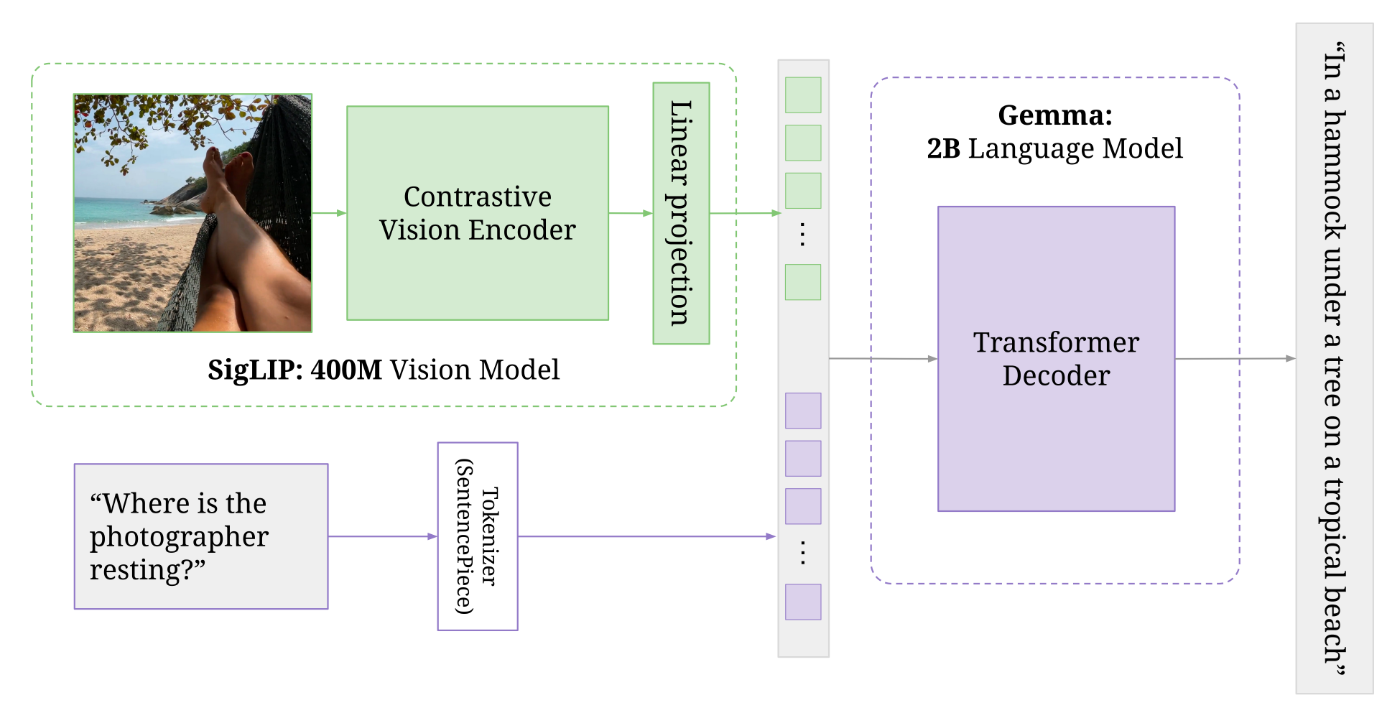
SigLIP 会将 images 缩放到 224 这个尺寸,如果 image 不是一个方形的图像,就需要用黑色将其填充成方形的。图像经过 ViT 得到一系列 tokens,不需要经过 pooling 就直接拼接到 textual tokens 上。
整个 token sequence 将被 VLM 一次 forward pass 中被处理。
输入中的任务文本指令被称为 prefix,PaliGemma 以文本字符串的形式进行自回归预测(这部分被称为 suffix)。对于 Attention,PailGemma 在 image 和 prefix 上做 Block-Attention,在 suffix 上做自回归 Attention,下图中的每个方块表示该行是否可以关注该列:
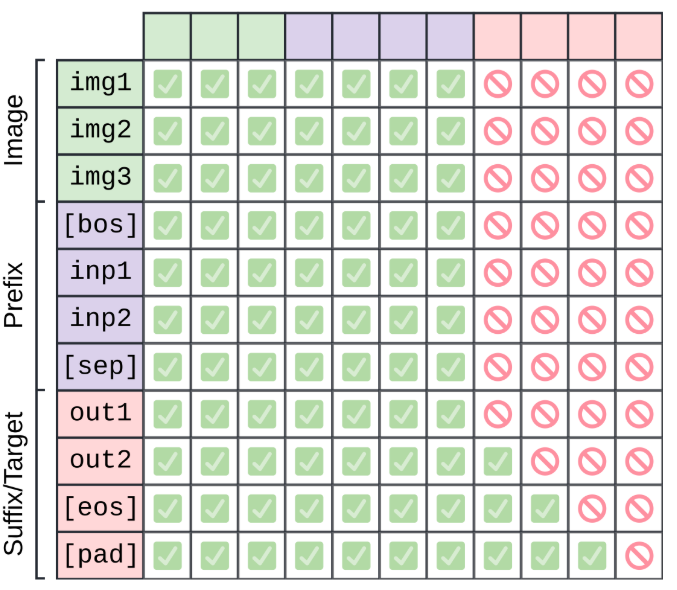
之所以这么做,主要是因为这个 VLM 主要职责像一个编码,所以互注意力是很合适的。
Flow Matching Action Generation
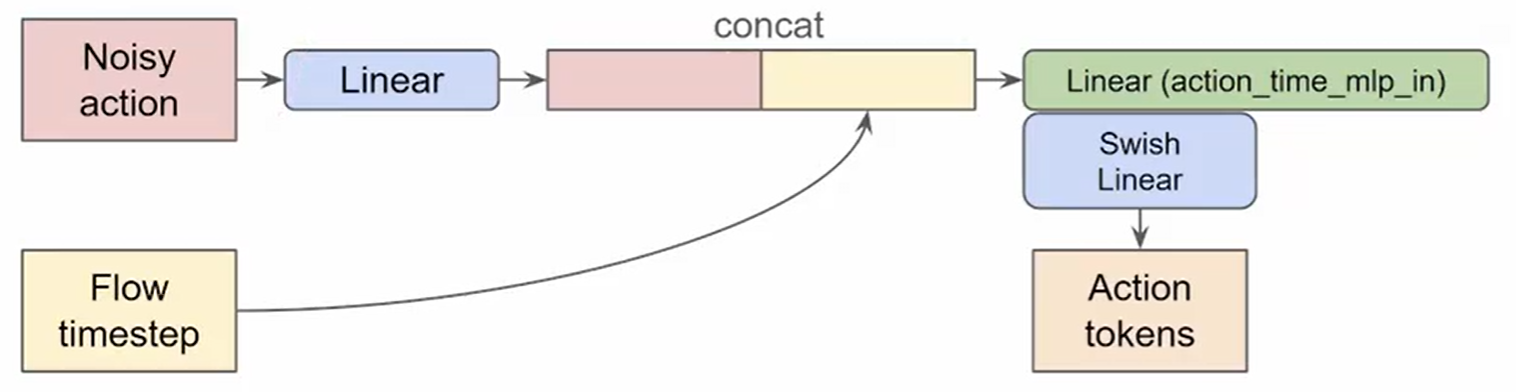
Action Expert 的输入有:[Robot State token, Action tokens]
- Robot State token = Linear(robot state)
state_token = self.state_proj(obs.state)[:, None, :] # (batch, 1, width)
- Action tokens 需要考虑:noisy action,flow matching timestamp
noisy action 的采样
noisy action 是从一个标准正态分布中采样得到的:At0∼N(0,1)A^0_t \sim N(0, 1)At0∼N(0,1),他的形状就与我们想要生成的 action 的 horizon 和 dim 保持一致:
noise = jax.random.normal(rng, (batch_size, self.action_horizen, self.action_dim))
Attention Mask 的设计
然后是 Attention Mask 的设计,这里遵循 PaliGemma 的一个观察:相同模态的所有 tokens 之间是可以互相 attend 的,而不同模态的 tokens 之间保持 casual attention 的关系,即前面的 tokens 看不到后面的 tokens。这样,不同模态之间的 Attention 关系如下(比如,State 只能看到前面的 Image/Lang,看不到后面的 Action):
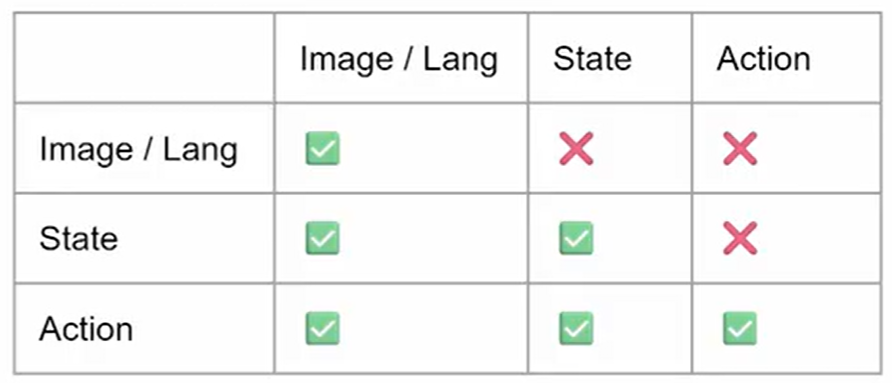
在具体实现上,由于一个 batch 内的 images 数量和文本长度可能不同,所以需要将每个 example 都 padding 到 3 个 images 和最长 text。
Flow Matching 过程
Flow Matching 会多次运行来逐步 denoise,本质上就是一个 while_loop 循环,直到 timestamp 达到我们预设的一个终点。
# 判断是否达到预设的终点
def cond(carry):x_t, time = carry# robust to floating-point errorreturn time >= -dt / 2# Flow-Matching 的循环
def while_loop(cond_fun, body_fun, init_val):val = init_valwhile cond_fun(val):val = body_fun(val)return valx_0, _ = jax.lax.while_loop(cond, step, (noise, 1.0))
Training Pipeline
使用 conditional flow matching loss 进行监督训练:
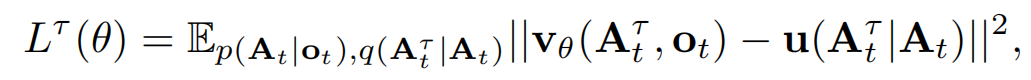
- 下标表示 robot timesteps
- 上标表示 flow matching timesteps,其中 τ∈[0,1]\tau \in [0, 1]τ∈[0,1]
- vθ\textbf{v}_\thetavθ 是网络的预测,u\textbf{u}u 是 ground-truth
大致的思想就是让模型的预测与 target direction 尽可能接近。几个关键代码如下:
noise = jax.random.normal(noise_rng, actions.shape)
u_t = noise - actions...
v_t = self.action_out_proj(suffix_out[:, -self.action_horizon, :]) # decode the predicted speddloss = jnp.mean(jnp.square(v_t - u_t), axis=-1)
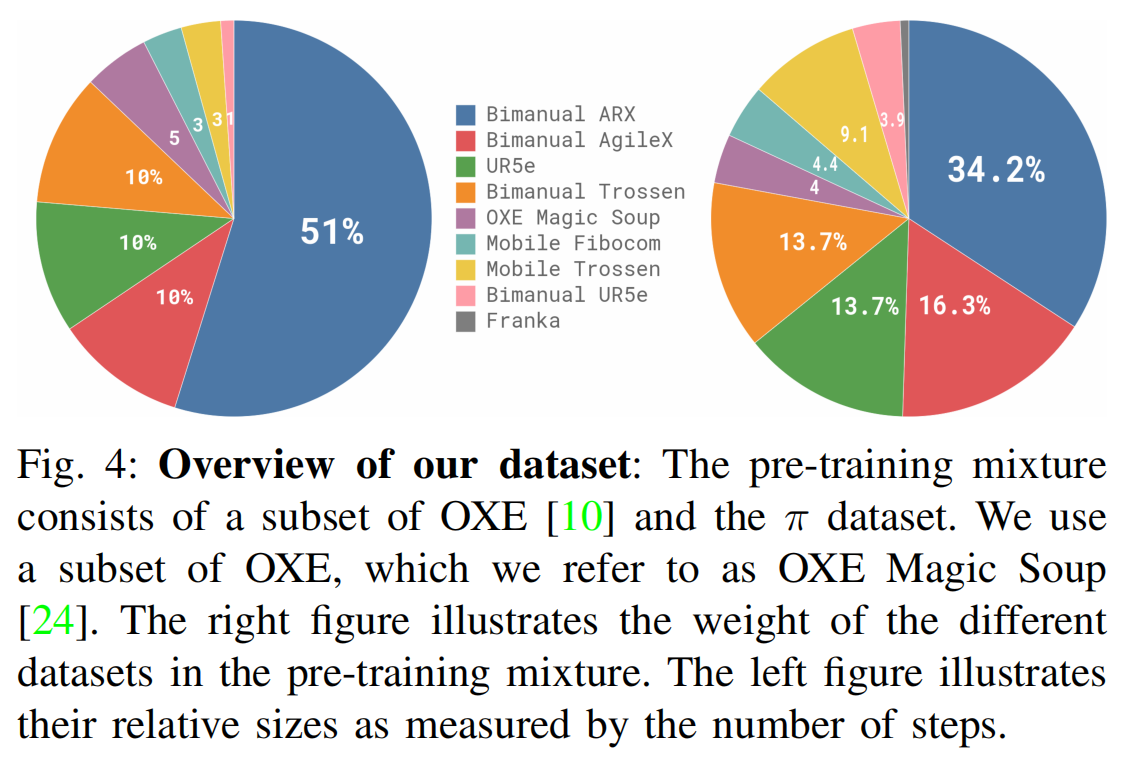
训练数据
训练数据包括开源 + 自采的数据,在超过 10,000 小时的机器人数据上进行了训练。主要由 OXE(是 Open X-Embodiment 的子集)和 π\piπ 数据集组成。
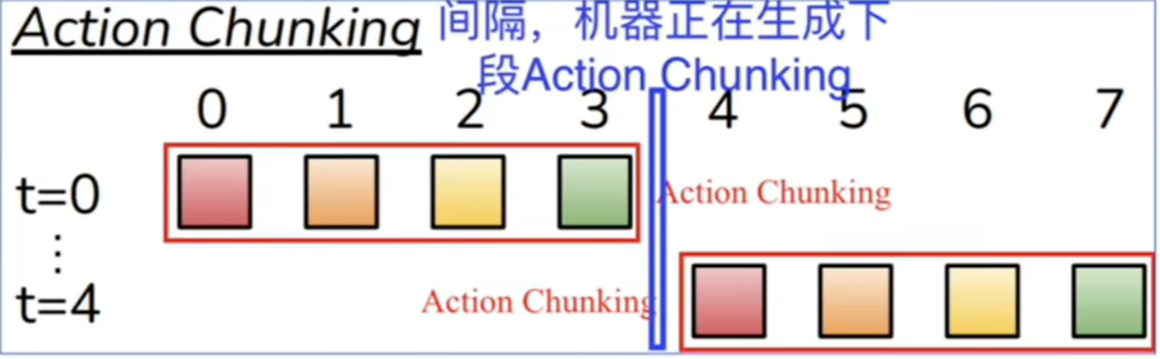
Real-time Chunking
当真机部署时,为了不让机械臂摆来摆去,需要使用 Real-time Chunking 这个技巧。
上文说了,模型在一次预测时,是预测生成一个 action chunk 的,也就是未来的多个 actions。但如果每次把一个 action chunk 都做完后再去预测下一个 chunk,就会出现机器人动作很机械、很僵硬,甚至可能会“摆来摆去”地做动作,缺乏连贯性。
为了解决这个问题,就需要 Real-time Chunking 这个 trick 了:
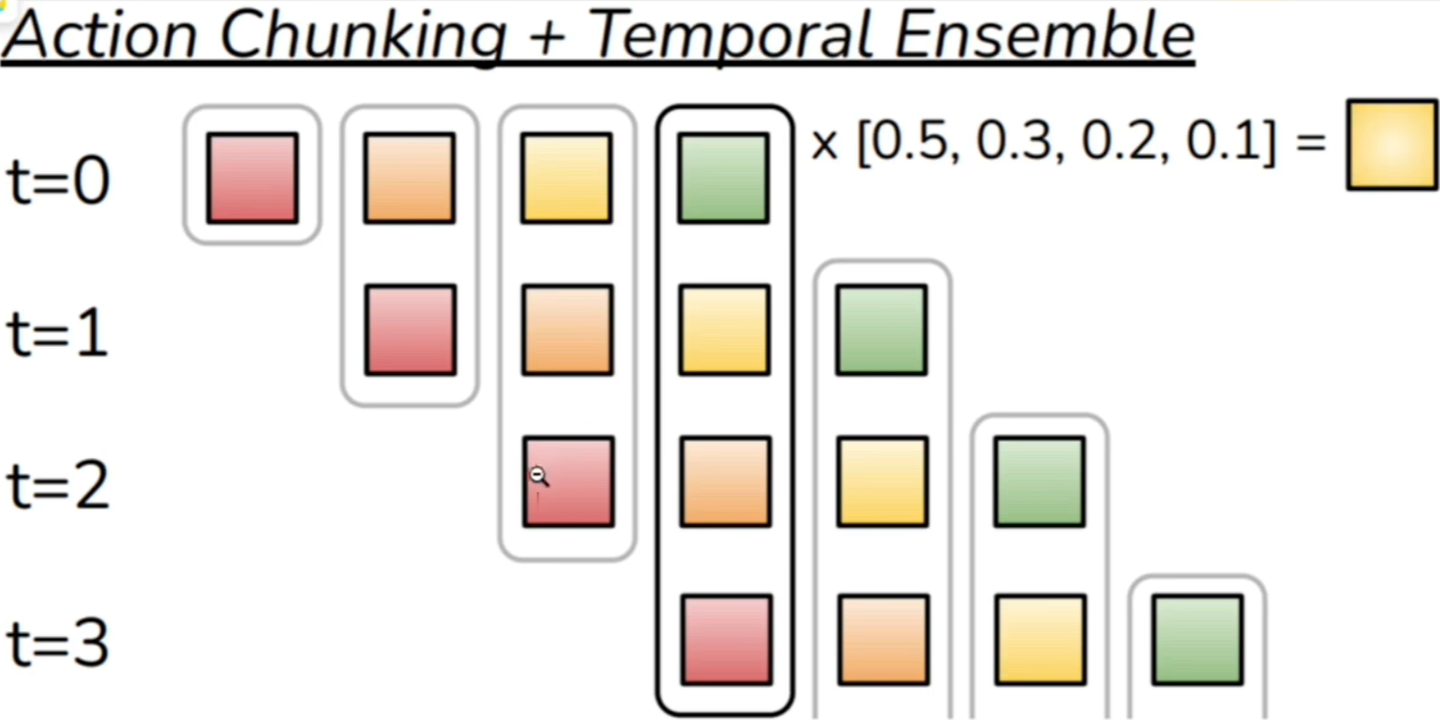
在每一个时刻,会将之前的动作的一部分作为上下文用于预测下一个 action chunk,实现了动作的平滑,防止动作的不连贯导致的“摆来摆去”的问题,而且模型也不是等一个 chunk 都执行完后再去预测下一个 chunk。
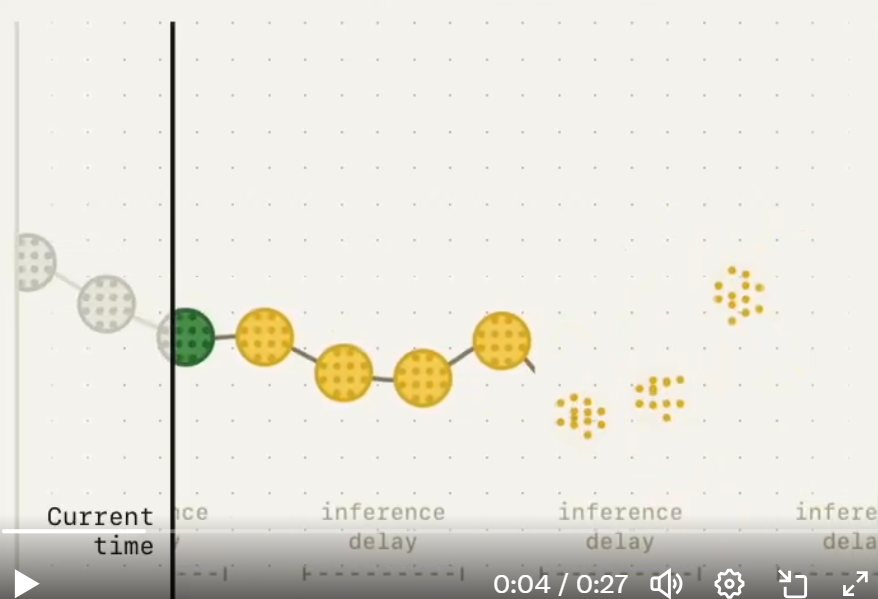
实验效果
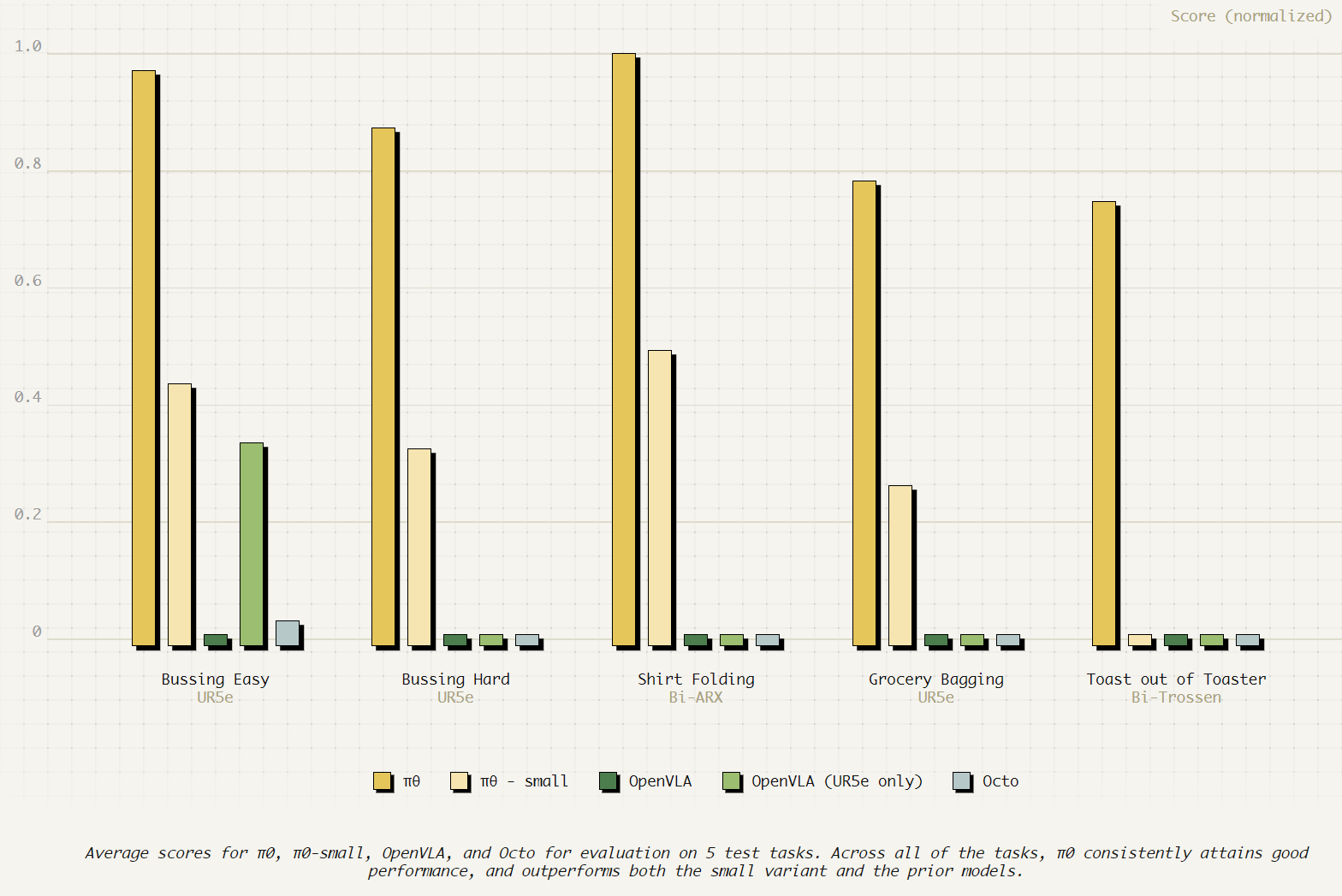
OpenVLA 实际部署效果很差,很难落地使用。但 π0\pi_0π0 效果远远好于其他模型。为了消融,作者还使用与其他模型相同的训练 steps 训练了一个 π0\pi_0π0-small,可以看到它也比其他模型效果好,说明 π0\pi_0π0 的效果不仅仅来自于它使用了更多的数据,还包括其架构的设计。
结论
π0\pi_0π0 作为 VLA 发展中的一个里程碑式的模型,通过结合预训练的 VLM 和 flow-matching 技术,实现了通用机器人控制。实验结果表明,π0\pi_0π0 模型在基础任务和复杂任务上都表现出色,显著优于现有的基线模型。
为了更深一步的学习 π0\pi_0π0,可以尝试深入阅读他的代码,并尝试对其进行部署。