VLA-Adapter:一种适用于微型 VLA 的有效范式
VLA-Adapter:一种适用于微型 VLA 的有效范式
关键词:具身智能;VLA

- 论文题目:VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
- arXiv:2509.09372
- 单位:西湖大学 & 北邮 & 浙大
- https://vla-adapter.github.io/

论文速读
- 研究问题:本文主要解决的问题是如何有效地将 VLA 中的「视觉语言表示 VL」与「动作 A」进行桥接,从而减少 VLA 模型对大规模 VLM 和大量预训练的依赖。
- 研究方法:提出了一个轻量级的 policy 模块,其包含 Bridge Attention 机制,可以条件性地将 VLM 中的感知信息注入到 action space 中。通过这种方式,本文的方法仅使用一个 0.5B 参数的骨干网络,无需任何机器人数据预训练即可实现高性能。

在模拟与真实世界机器人基准上的大量实验表明,VLA-Adapter 不仅达到了当前最先进的性能水平,还实现了迄今为止最快的推理速度。此外,得益于所提出的先进桥接范式,VLA-Adapter 仅需在单个消费级 GPU 上运行 8 小时即可训练出强大的 VLA 模型,极大降低了 VLA 模型部署的门槛。
Background
VLA 模型
VLA 模型的出现为实现由指令驱动的机器人操作提供了一种新的解决方案,因此,如何有效地将视觉-语言感知空间与动作空间之间的 gap 连接起来,已成为 VLA 模型设计的一个挑战。
通常,VLA 模型需要大规模的具身数据集(如 Open X-Embodiment)进行预训练。该过程将 VLM 与专用 policy network 结合,使系统能够以端到端的方式解码或生成多样任务的动作序列。此外,双系统 VLA 架构近期也受到关注,这些方法通常引入一个中间潜在 token 来连接 VLMs 与策略网络,采用异步机制以增强两个系统之间的协调性。这个设计缓解了 action 生成过程中的延迟问题。
从感知空间到动作空间的衔接
早期的研究尝试通过将 action 离散化为 token 来直接对齐感知空间和动作空间。然而,这种离散化不可避免地引入了固有的损失。最近的研究则将重点转向连续动作空间。
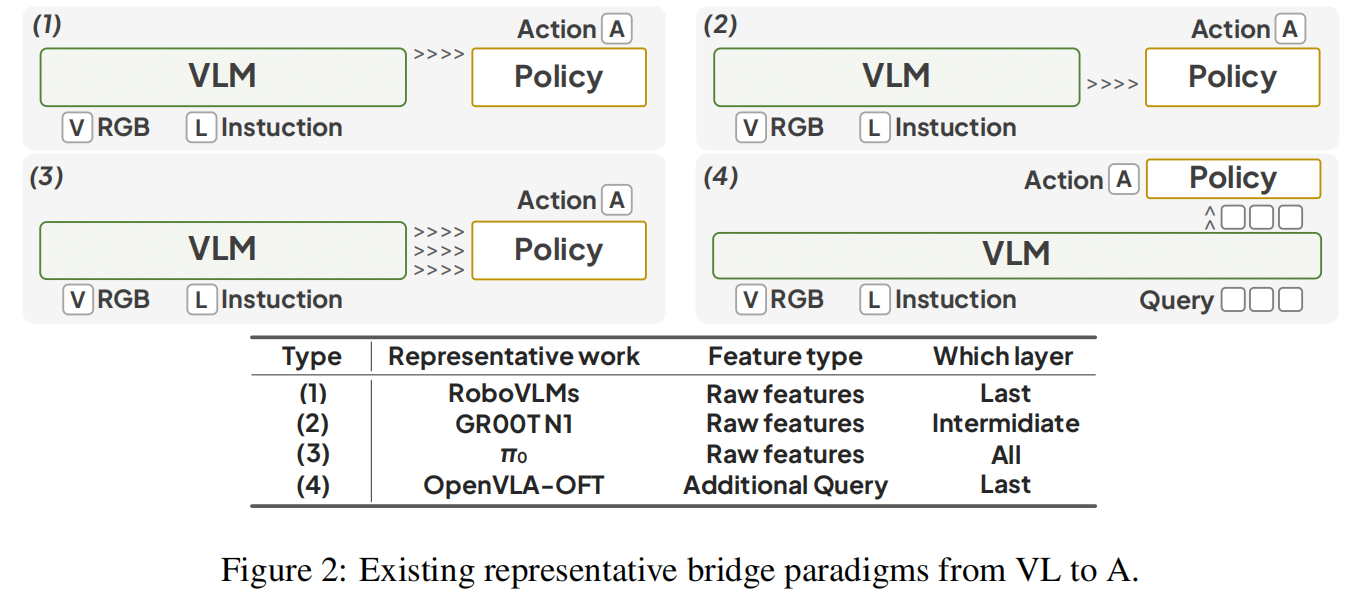
根据用于连接到动作空间的感知特征类型,以往的方法可以被分类为:
- 来自 VLM 的原始特征:这类方法直接从 VLM 中提取 VL 的原始特征。早期的方法从 VLM 的最终层提取 representation,基于该层编码了最相关的语义信息这一假设。较新的方法则利用 VLM 中间层特征,他们认为这些 representation 可能保留更丰富的多模态信息,从而在需要细粒度感知或复杂推理的任务中对策略有益。
- 作为 Interface 的额外 query:最近的研究提出了一个新颖的接口,该接口使用额外的 query 作为 VLM 和 policy 之间的桥梁,而不是传输原始特征。这些 query 是可学习的,能够融合多模态信息,表现出更优的性能。
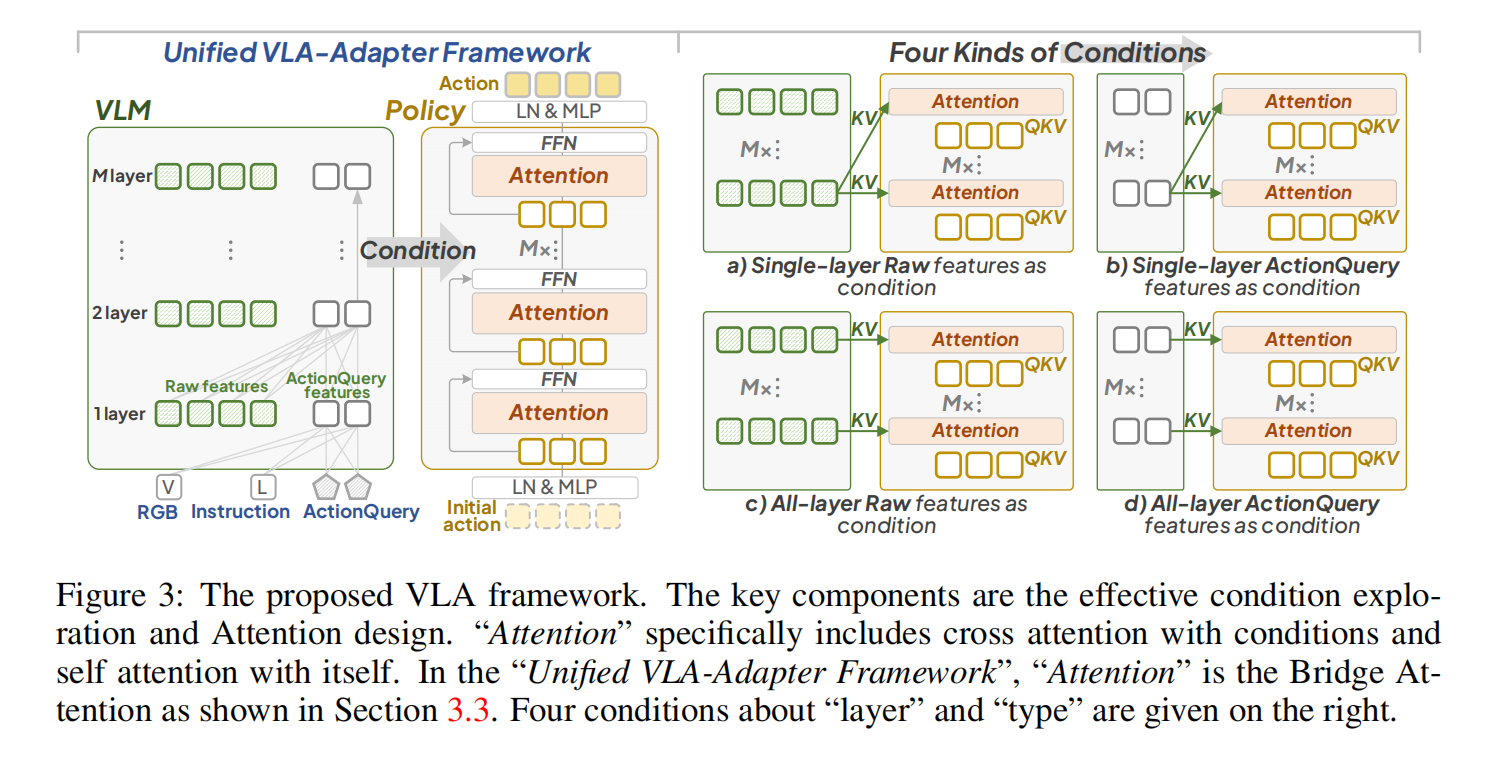
VLA-Adapter 方法
VLA-Adapter 包含 VLM 和 Policy 两部分,两者之间通过 Bridge Attention 进行信息交融。

VLA-Adapter 框架如下图所示。VLM 遵循 Prismatic-VLM 架构,包含 M 个 layer,在时间步 t,输入包括:第三视角图像、夹爪图像、指令 LtL_tLt 以及额外的 ActionQuery AQtAQ_{t}AQt。输入的图像由 DINOv2 和 SigLIP 提取 Visual Embeddings,LtL_tLt 被分词。输出为指定 layer 的 Raw latent CtRC_t^RCtR 和 ActionQuery latent CtAQC_t^{AQ}CtAQ,这些输出作为 Policy 的 conditions。
Backbone model
作者在不同规模的 backbone model 上对 VLA-Adapter 进行了实验,选取了在 Qwen2.5-0.5B 上训练的 PrismaticVLM、在 LLaMA2-7B 上训练的 Prismatic VLM 以及在机器人数据上预训练的 OpenVLA-7B。
作者发现,在 VLA-Adapter 中,增加骨干网络规模所带来的收益有限。因此,作者默认使用了 Qwen2.5-0.5B 作为 backbone model。
从 VL 到 A 过渡所必需的条件是什么?
VLM 和 Policy 设计上的差异导致了现有的方法尝试构建这两者之间的桥梁,但对其相对有效性仍不明确。本文探讨了 Policy network 中生成 action 所必需的感知信息类型。总结而言,本文主要关注以下两个问题:
- 问题 1.1:VLM 中哪一层的特征对 Policy 更有效?
- 问题 1.2:动作查询特征是否优于原始特征?
实验设置
在 VLA-Adapter 中,Policy 的层数等于 VLM 的层数,在 Policy 的每一层中,action latent 会与 condition 进行 Cross-Attention 计算,并与自身进行 Self-Attention 计算。这一迭代过程最终生成 action 输出。
- 针对问题 1.1:
- 为了评估 single layer 的信息,我们使用 single-layer latent 作为 condition 来提供给 Policy 的 all-layer。如 Figure 3a 和 3c。
- 为了评估 all-layer 的信息,我们将 each-layer latent 交给了 Policy 的对应 layer,如 Figure 3b 和 3d 所示。
- 针对问题 1.2:
- 为了比较 feature types 的效果,我们使用 CtRC_t^{R}CtR 和 CtAQC_t^{AQ}CtAQ 分别作为 condition。
这些比较在 LIBERPO-Long 上进行,结果如下:
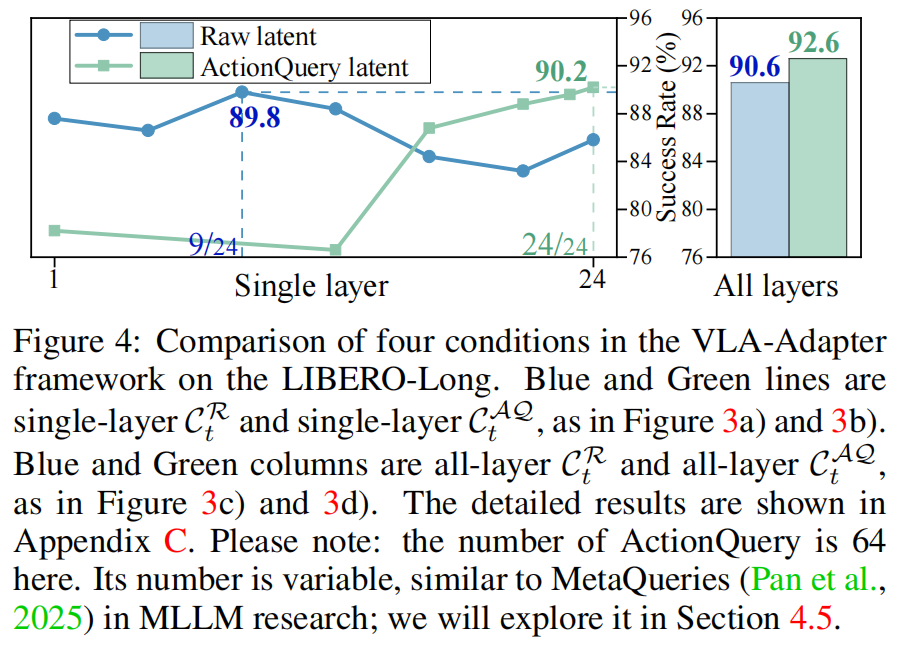
Key Findings

最终决定
VLA-Adapter 并不仅依赖于 CtQAC_t^{QA}CtQA 作为 condition,尽管 all-layer 的 CtQAC_t^{QA}CtQA 表现优于 CtRC_t^{R}CtR,但在一些困难任务上,中层 CtRC_t^{R}CtR 表现最佳。对比结果如下:
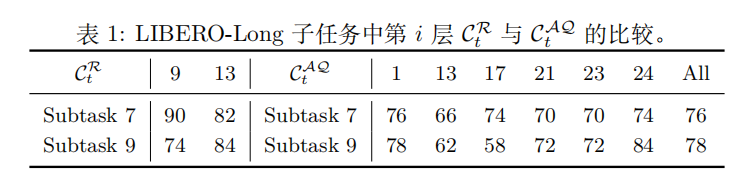
因此,我们的目标是利用 CtRC_t^{R}CtR 中的部分知识来提升性能。
带 Bridge Attention 的 Policy
Policy 网络的概览
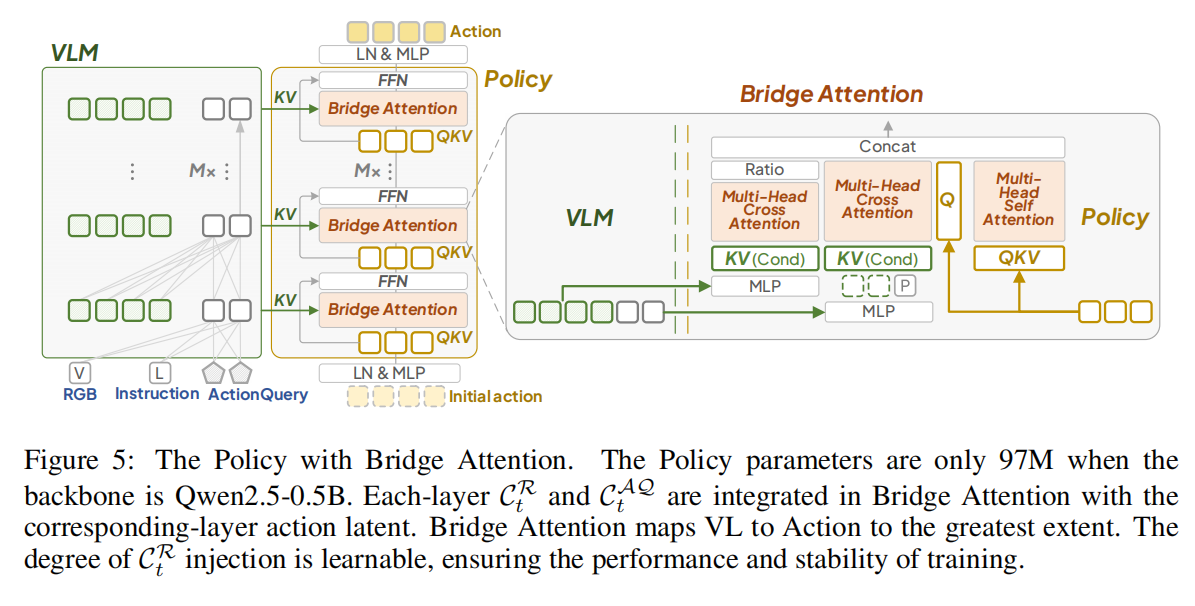
作者设计了一个 L1-based Policy 网络,Policy 的每一层由一个 Bridge Attention 模块和一个前馈神经网络(FFN)组成。在 t-th 时间步,Policy Network 的输入包括:CtRC_t^RCtR、CtAQC_t^{AQ}CtAQ、initial action At0A_t^0At0、Proprioceptive State PtP_tPt。
- CtRC_t^RCtR、CtAQC_t^{AQ}CtAQ 分别是 VLM 部分的输出;
- AtτA_t^\tauAtτ 表示 Policy Network 的第 τ\tauτ 层的 state。At0A_t^0At0 是一个 H-step 的 initial action,元素为全 0,At0A_t^0At0 经过 LayerNorm 和 MLP 得到 At0~=[a~t0,a~t+10,⋯ ,a~t+H−10]\tilde{A_t^0}= [\tilde{a}_t^0, \tilde{a}_{t+1}^0, \cdots, \tilde{a}_{t+H-1}^0]At0~=[a~t0,a~t+10,⋯,a~t+H−10]。
- Proprioceptive State PtP_tPt 是机器人内部传感器的实时测量数据,包括关节级信息(各关节角度/角速度)、末端执行器状态、基座信息(位置、朝向、速度等)等。在 VLA-Adapter 中,PtP_tPt 默认包含 7 维数据(6 关节角度 + 1 夹爪状态),与 7-DOF Franka Emika Panda 机械臂的硬件配置匹配。
Bridge Attention
本文所提出的 Bridge Attention 旨在通过条件 CtRC_t^RCtR 和 CtAQC_t^{AQ}CtAQ 尽可能地引导动作生成。每个 Bridge Attention 由两个交叉注意力和一个自注意力组成。如上架构图所示。
为了有选择性地将某些 CtRC^R_{t}CtR 注入到 Policy 的动作空间中,我们引入了一个学习参数 Ratio ggg 来调节 Bridge Attention 所形成的 values。ggg 初始化为全 0 值,并采用 tanh 激活函数 tanh(g)∈[−1,1]tanh(g) \in [-1, 1]tanh(g)∈[−1,1] 来防止极端值导致分布不稳定。
训练
训练采用端到端方式进行,Policy 从零开始训练。给定真实动作轨迹 AtA_tAt 和动作的 latent representation AtτA^\tau_tAtτ,我们以如下目标训练 VLA-Adapter πθ(⋅)\pi_\theta(\cdot)πθ(⋅):
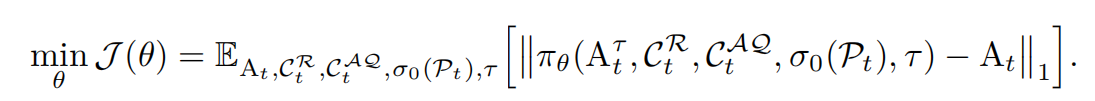
实验
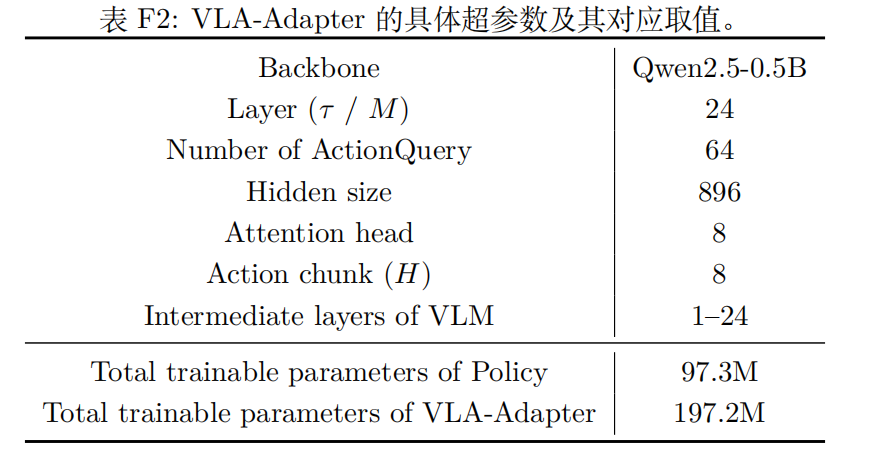
所有实验均在 4 块 NVIDIA H100 GPU 上运行,超参数如下:
VLA-Adapter 的必要性验证
在 LIBERO-Long 基准上,VLA-Adapter 在使用未预训练 VLM 的情况下表现出显著的改进,并且在主干网络冻结的情况下仍表现强劲。作者在这里总结出两点结论:
- 当视觉语言模型未经过机器人预训练时,VLA-Adapter 的改进效果显著。
- 即使主干网络冻结,VLA-Adapter 依然表现强劲。
这可以归因于,在机器人数据上完成预训练后,最后一层特征已适应动作领域,从而能够通过简单的 MLP 实现高效的微调。然而,对于未经过预训练的 VLMs,仅依赖最后一层潜在特征,不足以实现有效的动作映射。因此,采用 VLA-Adapter 变得至关重要,以实现高效的微调。这些见解突显了一个关键优势:VLA-Adapter 能够促进未经过机器人预训练的 VLMs 的高效微调,其性能超越了使用小型骨干网络的基准方法。
各项任务的整体表现
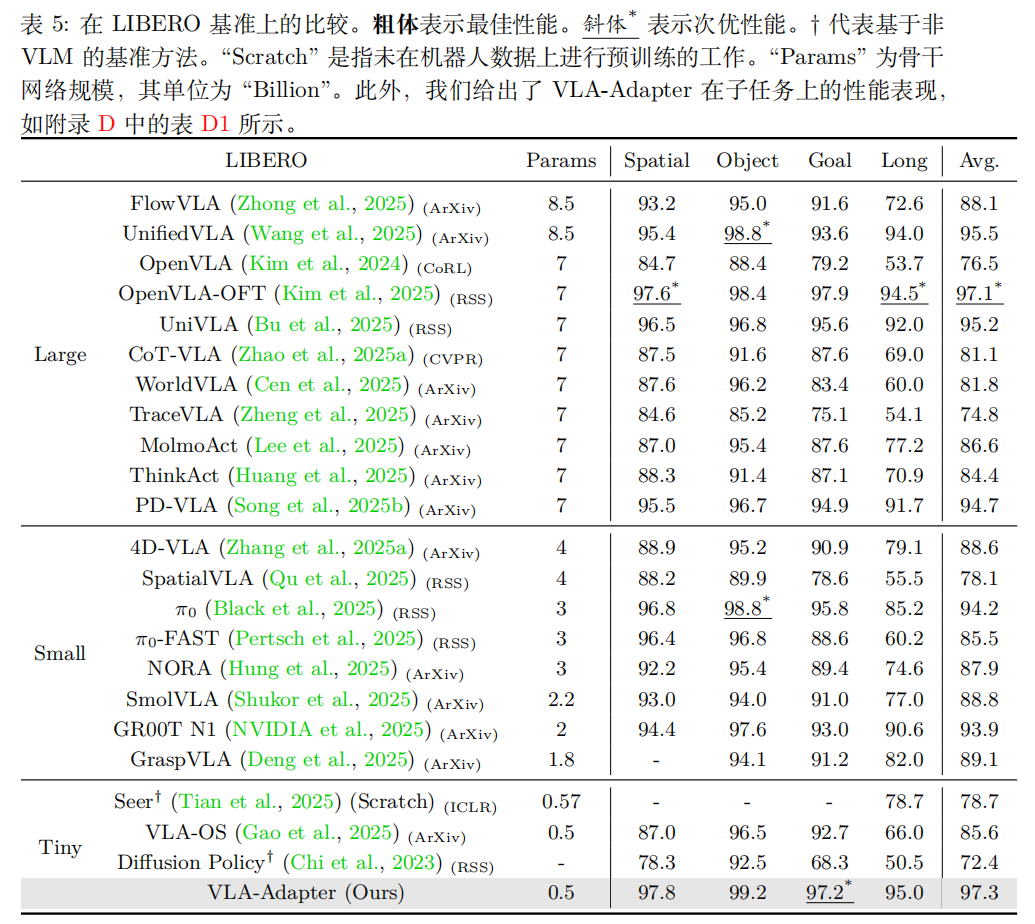
选择了 LIBERO 基准来评估在各类任务中的性能。在 LIBERO 基准上,VLA-Adapter 使用微小规模的主干网络就能达到与 OpenVLA-OFT 相当的性能,并且在多个子任务上表现优异。
泛化能力
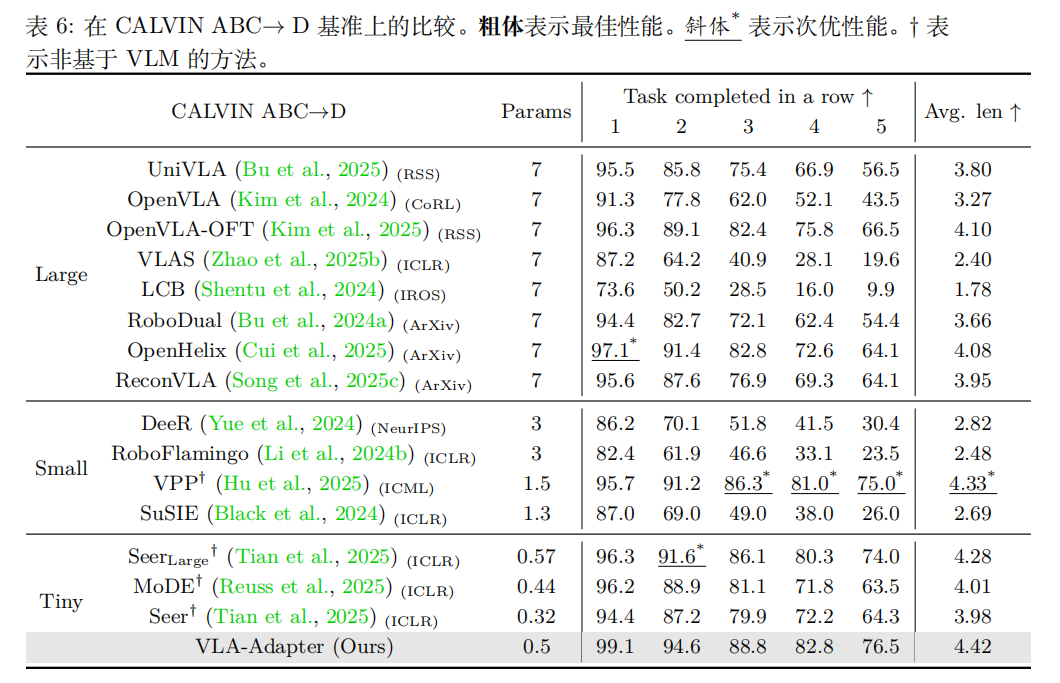
在 CALVIN ABC→D 基准上,VLA-Adapter 展现出强大的零样本泛化能力,平均完成任务的序列长度优于现有方法。
真实世界任务
我们使用一个机器人系统来执行现实世界中的任务。采用配备 1-DOF 夹爪的 6-DOF Synria Alicia-D 机械臂,并使用 Logitech C920e 和 RealSense D405 摄像头捕捉第三人称视角图像和夹爪图像。

在真实世界任务中,VLA-Adapter 在各种场景下表现出良好的泛化能力,显著降低了VLA在实际应用中的部署门槛。
结论
我们提出 VLA-Adapter,这是一种新颖且高效的 VLA 桥梁范式。通过利用原始数据和动作查询的潜在表示,该方法能够有效将多模态知识迁移至策略,以生成动作。实验表明,VLA-Adapter 在使用小规模主干网络的情况下即可达到最先进性能。即使视觉语言模型(VLM)被冻结,其表现依然强劲。此外,我们的方法具有低显存占用和高推理速度的特点。这些结果表明,VLA-Adapter 减轻了 VLA 对大规模 VLM 及高昂训练成本的依赖,降低了 VLA 部署的门槛。
最终,我们希望 VLA-Adapter 方法及本研究的关键发现能为未来 VLA 领域的研究提供坚实基础,并激发更先进 VLA 方法的发展。