《理解Reactor网络编程模型》
由于最近要重写Muduo网络库,了解到Muduo使用的是Reactor模型,于是就查阅了几篇资料做了以下总结。
“The reactor design pattern is an event handling pattern for handling service requests delivered concurrently to a service handler by one or more inputs. The service handler then demultiplexes the incoming requests and dispatches them synchronously to the associated request handlers.” ----Wikipedia
Reactor设计模式是一种事件处理模式,用于处理由一个或多个输入源并发传递给服务器的服务请求。之后,服务器会对传入的请求进行解复用,并将其同步分发给相关的请求处理器。
在《Linux高性能服务器编程》书中,作者游双是这样介绍Reactor模式的:
Reactor是这样一种模式,它要求主线程负责监听文件描述符上是否有事件发生,有的话就立即将该事件通知工作线程。除此之外,主线程不做任何其他实质性的工作。读写数据,接受新的连接,以及处理客户请求均在工作线程中完成。
使用同步I/O模型(以epoll_wait为例)实现的Reactor模式的工作流程是:
1)主线程往epoll内核事件中注册socket上的读就绪事件。
2)主线程调用epoll_wait等待socket上有数据可读。
3)当socket上有数据可读时,epoll_wait通知主线程。主线程则将socket可读事件放入请求队列。
4)睡眠在请求队列上的某个工作线程被唤醒,它往socket上写入服务器处理客户请求的结果。
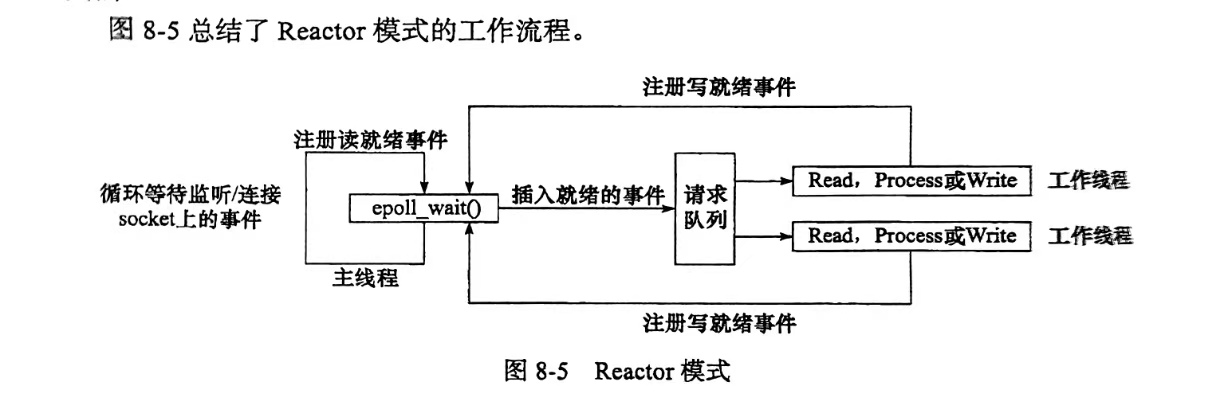
图中,工作线程从请求队列中取出事件后,将根据事件的类型决定如何处理它:对于可读事件,执行读数据和处理请求的操作;对于可写事件,执行写数据的操作。因此,图所示的Reactor模式中,没必要区分所谓的“读工作线程”和“写工作线程”。
----《Linux高性能服务器编程》
通过书中简单的描述,可以了解到其核心思想就是“分离I/O事件监听”和“业务逻辑处理”。Reactor模式的工作流程可以总结为以下三个步骤:
- 主线程专注监听:通过select/poll/epoll等I/O多路复用机制,同时监听多个文件描述符(如socket)上的事件(可读、可写、连接等)。
- 事件到来时快速转发:一旦某个文件描述符有事件发生,主线程不做任何数据处理,仅将该事件快速分发给某个工作线程。
- 工作线程处理具体任务:工作线程负责完成实际的I/O操作(如读写数据)、连接管理(如接受新连接)和业务逻辑处理(如解析请求、生成响应)。
了解到Reactor模型的思想之后,那么为什么要使用Reactor模型?
传统的阻塞I/O服务模型
如果服务器使用一个线程服务一个客户端(对客户端请求建立连接、处理业务逻辑),处理完业务逻辑之后,随着连接的关闭,线程也随之销毁。当并发高时,也就是说有多个客户端连接时,就需要创建大量线程。
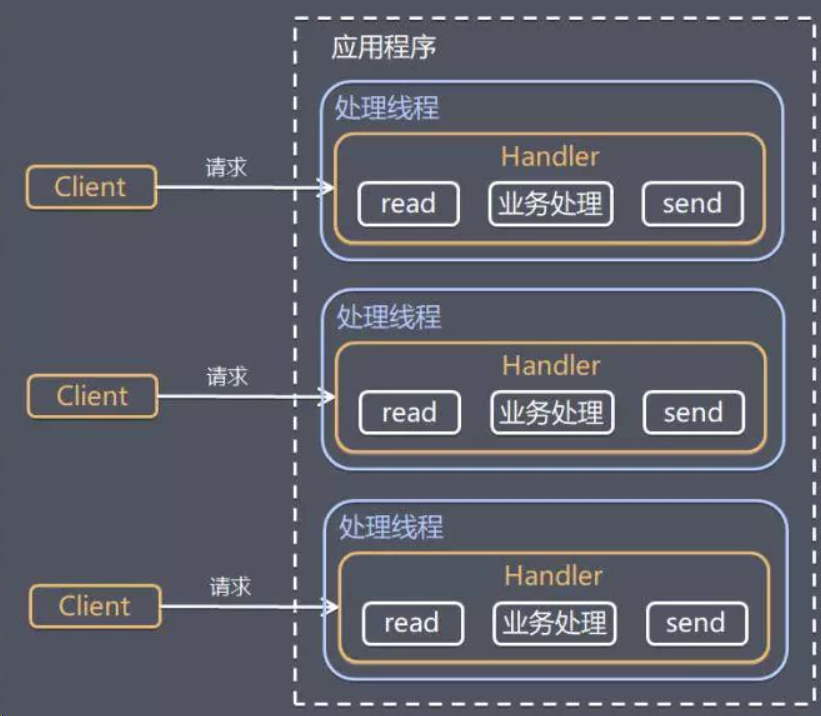
首先,线程的创建并不是越多越好。
- 频繁的创建和销毁线程,会带来性能的开销和资源的浪费。
- 线程的上下文切换也需要花费CPU时间,CPU利用率就不高了。
- 系统能创建的线程数也是有限的,维护起来也要浪费大量资源。
其次,线程处理业务逻辑的流程通常是阻塞式的:read+业务处理+send。如果当前连接没有数据可读,线程就会阻塞在read上(socket默认是阻塞),等待数据就绪,造成线程资源浪费。
要解决“为每个个连接创建一个线程”造成线程资源浪费的问题,可以使用“资源复用”的方式。不需要为每一条连接都创建一个线程,而是创建一个线程池,那么一个线程就可以处理多个连接了。
工作流程:
- 服务器启动时,提前创建好固定数量的线程,组成线程池。
- 当新连接到来时,不再创建新连接,而是从线程池中取出一个空闲线程来处理这个连接业务。
- 当这个线程处理完当前连接的业务以后,不会被销毁,而是继续放到线程池中等待处理下一个连接业务。
- 因此,一个线程就可以先后处理多个不同连接的业务。
此时,又有一个关键的问题,一个线程如何高效的处理多个连接的业务?也就是如何高效的IO?
既然引入了线程池,一个线程要处理多个连接业务,如果线程由于当前连接没有数据而阻塞,那么线程就没有办法处理其他连接的业务了。
非阻塞I/O服务模型
此时,就需要把socket套接字改为非阻塞,线程不断地轮询检测当前连接是否有数据,有数据就进行处理,没数据就去处理其他连接,如此,单个线程就可以处理多个连接。解决了阻塞问题,但是解决方式比较粗暴,轮询会花费CPU资源(即使当前连接没有数据,也需要轮询)。
阻塞I/O和非阻塞I/O的方式主要在于不知道当前连接是否有数据可读,从而需要每次通过read判断。
如果线程只在连接有数据的情况下去读(read)写,read一定能读到数据,而不再需要花费事件进行I/O等待了,不会阻塞。I/O多路复用技术就是基于这样的“事件驱动”思想实现的。
I/O多路复用模型
I/O多路复用通过系统调用函数select/poll/epoll,让线程可以一次监听多个连接事件,如果没有事件就绪,就阻塞在这个系统调用,如果有某个事件就绪,就返回对应事件的套接字,线程进行业务处理。
对比阻塞I/O,单个线程可以监控多个事件;对比非阻塞I/O,不需要主动轮询。
“于是,大佬们基于面向对象的思想,对 I/O 多路复用作了一层封装,让使用者不用考虑底层网络 API 的细节,只需要关注应用代码的编写。大佬们还为这种模式取了个让人第一时间难以理解的名字:Reactor模式。
Reactor 翻译过来的意思是“反应堆”,这里的反应指的是对事件的反应,也就是来了一个事件,Reactor 就有相对应的反应/响应。,也叫Dispatcher模式,即I/O多路复用监听到事件后,根据事件类型分发给某个线程处理。”
----小林coding
Reactor模式
I/O复用结合线程池,就是Reactor模式的基本设计思想。
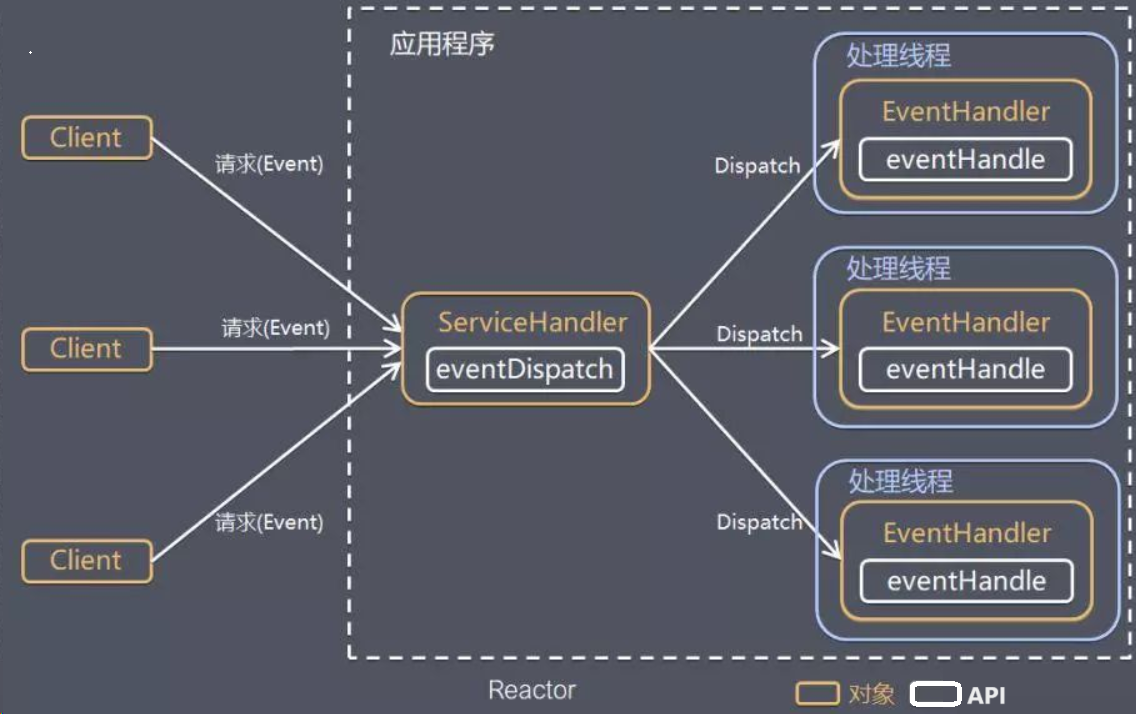
Reactor模型有两个核心部分:
Reactor线程(事件管理器):负责监听、分发事件。
- 监听事件:通过I/O多路复用同时监控多个连接事件(比如:连接建立、数据可读、数据可写)
- 分发事件:一旦监听到事件,根据事件类型(如:“新连接到来”、“连接有数据”)分发给对应的“处理器”。
比如:
- 监听到“新连接事件”,交给“连接处理器”处理(完成TCP三次握手,创建新的socket)。
- 监听到“数据可读事件”,交给“读处理器”处理(调用read读取数据)。
- 监听到“数据可写事件”,交给“写处理器”处理(调用send发送数据)。
Handlers处理器:负责实际的I/O操作、连接管理、处理业务逻辑。
Reactor 模式通过 “事件驱动”(只有事件发生时才会处理,避免了主动轮询造成的CPU资源浪费) 和 “分工协作”(主线程负责监听分发事件、工作线程负责具体的业务处理,提高了线程利用率线程切换开销) 解决了 “线程高效处理多连接” 的问题。
Reactor三种典型模式
根据Reactor和工作线程分工的细化程度,Reactor模式有几种典型的实现:
- 单Reactor单线程。
- 单Reactor多线程。
- 多Reactor多线程(主从多线程模型)。
单Reactor单线程模式
只有一个主线程运行Reactor。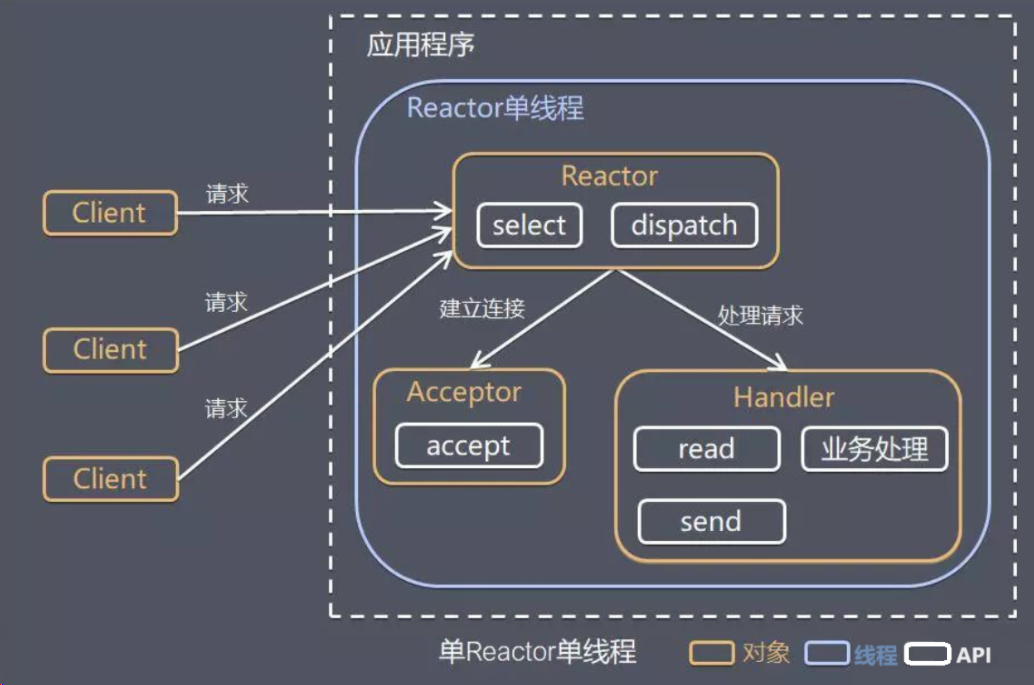
有三个对象。
- Reactor:负责select监听和dispatch分发事件
- Acceptor:负责获取新连接
- Handler:负责处理业务逻辑
方案流程:
- Reactor对象通过I/O多路复用监听多个事件,收到事件后,通过dispatch进行分发,根据事件的类型,选择分发给Acceptor还是Handler。
- 如果是建立连接的事件,交由Acceptor对象,Acceptor通过accept获取连接,并创建一个Handler对象来处理该连接后续的响应事件(如该连接可读)
- 如果不是建立连接的事件,是一个已建立连接的事件发生(如连接可读),则交由该连接对应的Handler对象来进行响应。
- Handler对象通过read->业务处理->send的流程完成整个业务的处理。
优点:
- 所有工作流程(建立连接、分发事件,I/O读写、业务处理等)只使用一个线程实现,实现简单,不需要考虑线程间通信或资源竞争问题。
缺点:
- 只有一个线程,无法充分利用多核CPU的性能(多线程可以并行执行)。
- 只有一个线程,Handler对象在处理业务时,整个线程无法处理其他连接的事件,如果业务处理比较耗时,就可能造成延迟响应的问题。
总结:
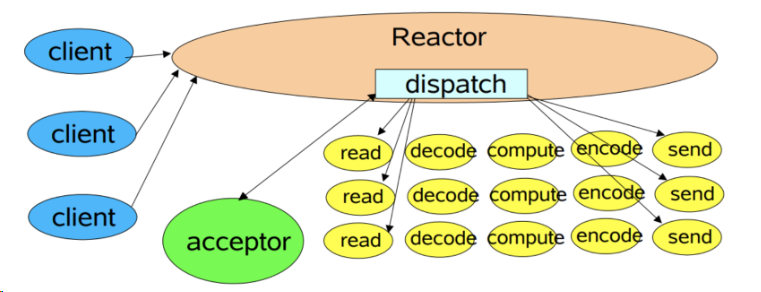
在单Reactor单线程模型中,所有的I/O操作(包括连接建立、数据读写、事件分发等)、业务逻辑处理,都是由一个线程完成的,逻辑简单。单Reactor单线程的方案不适用于I/O密集型场景和CPU计算密集型场景,只使用于业务处理非常快的场景。
Redis就是使用的单Reactor单线程。Redis业务处理是在内存中完成的,速度非常快。
单Reactor多线程模式
要克服单Reactor/单线程的缺点,就引入了单Reactor/多线程方案。
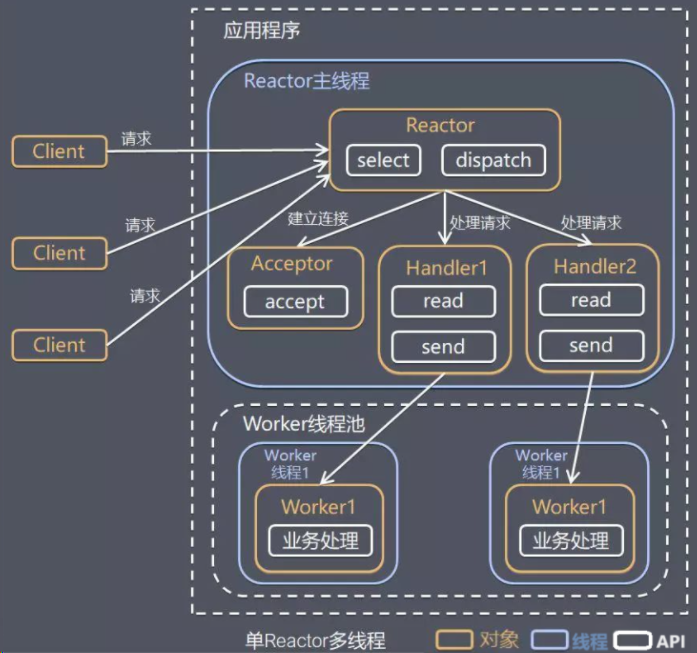
方案流程:
- Reactor对象通过I/O多路复用监听多个事件,收到事件后,通过dispatch进行分发,根据事件的类型,选择分发给Acceptor还是Handler。
- 如果是建立连接的事件,交由Acceptor对象,Acceptor通过accept获取连接,并创建一个Handler对象来处理该连接后续的响应事件(如该连接可读)
- 如果不是建立连接的事件,是一个已建立连接的事件发生(如连接可读),则交由该连接对应的Handler对象来进行响应。
- 此时,Handler对象不再负责业务处理,只负责数据的读取和发送,Handler对象通过read读取到数据之后,会将数据发送给Worker线程池进行业务处理。
- Worker线程池会分配独立的线程完成业务处理,处理完成后,将结果发送给Handler。
- Handler收到响应结果之后,通过send发送给Client。
优点:
- 可以充分利用多核CPU的性能(多线程可以并行执行)。
缺点:
- 多线程会导致竞争共享资源问题,需要对共享资源加互斥锁,保证同一时间只有一个线程操作共享资源。
- Reactor主线程要监听所有的事件,不仅要关心客户端新连接的事件,还要关心已连接套接字的I/O事件。在面对瞬间高并发的场景,容易成为性能瓶颈的地方。
总结:
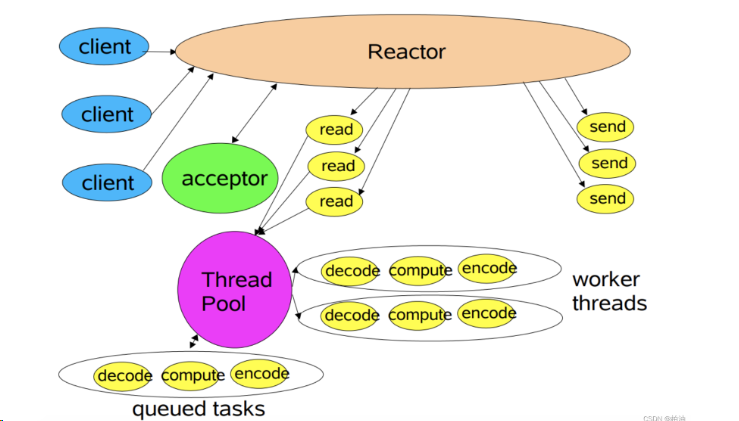
多线程模模式将业务逻辑的处理交给线程池中的多个子线程完成,其他操作流程与单线程类似,比如连接建立、事件分发、I/O读写都是由一个主线程完成的。其主要缺陷在于同一时间无法处理大量新连接、IO就绪事件。
对于像 Nginx、Netty 这种对高性能、高并发要求极高的网络框架,这种模式便显得有些吃力了。因为,无法及时处理新连接、就绪的 IO 事件以及事件转发等。
多Reactor多线程模式
又名主从多线程模式。针对单Reactor/多线程模式下,Reactor在单线程运行容易引发的性能瓶颈问题,可以让Reactor在多线程中运行。就产生了主从多线程模型。
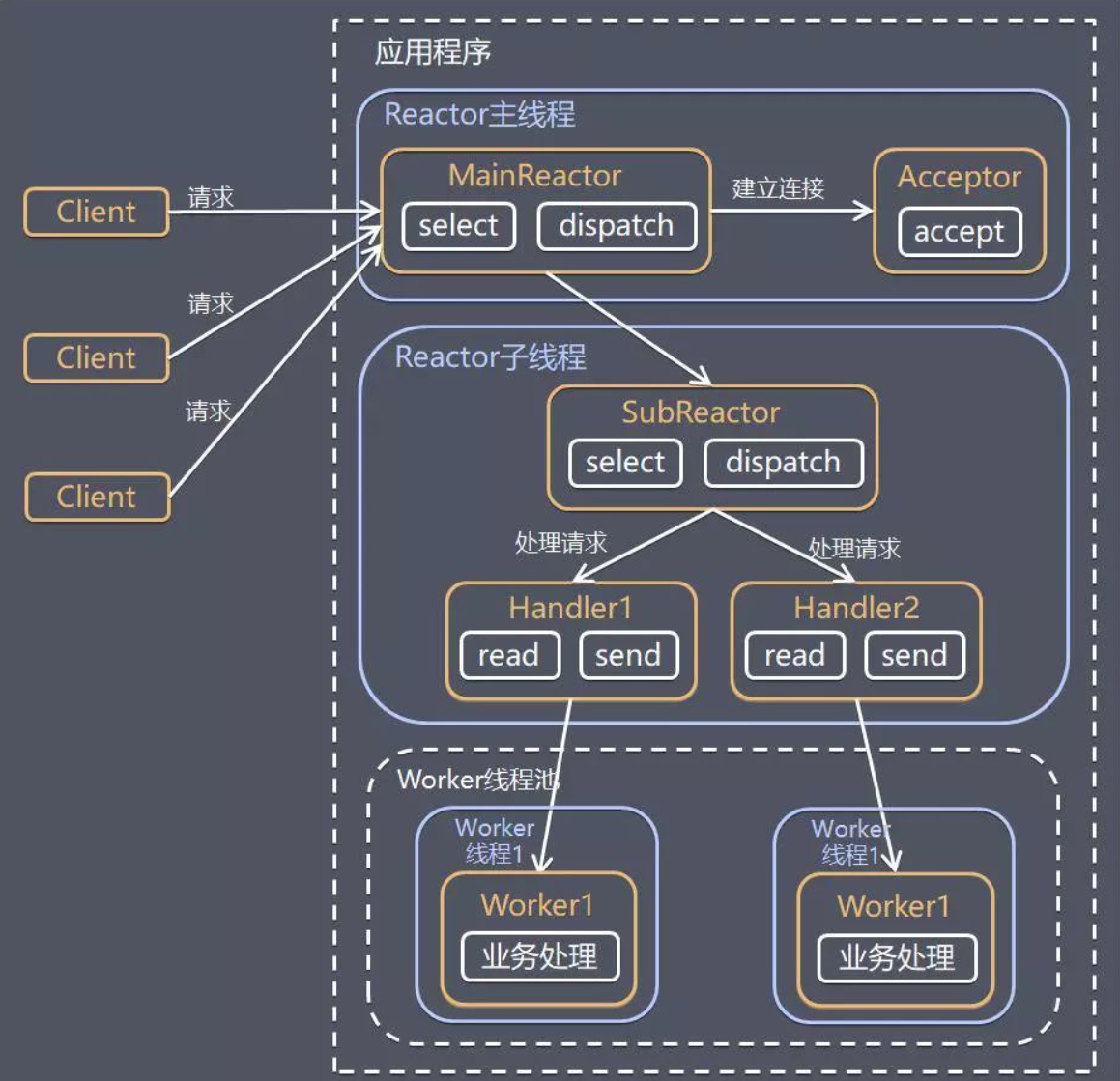
方案流程:
- 主线程中的MainReactor对象通过select监控新连接建立事件,收到事件后,通过Acceptor对象获取新连接,将新连接分配给某个子线程。
- 子线程中的SubReactor对象将MainReactor对象分配的连接加入连接队列继续监听,并创建对应的Handler对象用于处理该连接后续的响应事件。
- 如果该连接有新的事件发生,SubReactor会调用该连接对应的Handler来进行响应。
- Handler对象通过read读取数据之后,会将数据发送给Worker线程池中的某个线程来进行业务处理。
- Worker线程池会分配独立的线程来完成业务处理,处理完成后将结果发给Handler进行处理。
- Handler对象收到响应结果之后,通过send将响应结果返回给Client。
优点:
- 可以解决瞬间高并发导致的性能瓶颈,主线程可以解决同一时间大量新连接事件,将其注册到从Reactor上进行I/O事件监听。
- 主线程和子线程分工明确,主线程只负责接收新连接,子线程负责完成该连接的后续业务处理。
- 主线程和子线程的交互很简单,主线程只需要把新连接传给子线程,子线程无须返回数据,直接就可以在子线程将处理结果发送给客户端。
总结:
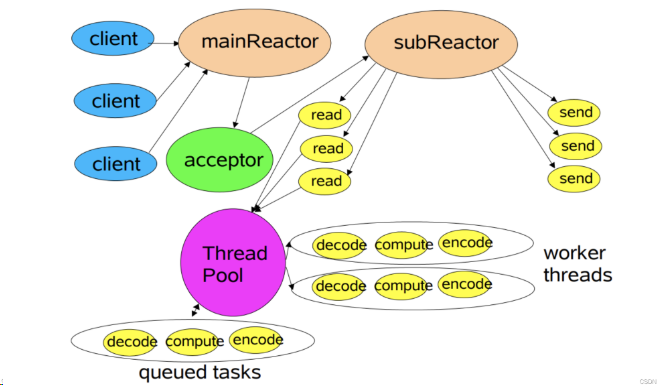
主从多线程模式,由多个Reactor线程组成,分为了主Reactor和从Reactor,MainReactor只负责客户端新连接的建立,连接成功后将新连接对象注册给SubReactor继续监听。再由SubReactor分配线程池中的I/O线程与其连接绑定,它将负责该连接生命周期内的所有I/O事件。
在海量客户端并发请求的场景下,主从多线程模式甚至可以适当增加 SubReactor 线程的数量,从而利用多核能力提升系统的吞吐量。这种模型在许多项目中广泛使用,包括 Nginx服务器 主从 Reactor 多进程模型,Memcached 主从多线程,Netty框架 主从多线程模型的支持。
Reactor模式总结
Reactor 模型是高并发网络编程的核心设计模式,其本质是通过 “事件驱动” 和 “分工协作”,解决 “少量线程高效处理大量网络连接” 的问题,避免传统 “一个连接一个线程” 模式的资源浪费与性能瓶颈。核心思想是通过一个主线程负责监控事件,收到事件后,将事件派发给子线程,子线程负责处理业务逻辑,从而实现高效的并发处理。
-
高效响应:通过非阻塞 I/O+I/O多路复用和事件驱动机制,避免线程资源浪费。
-
可扩展性:通过增加 Reactor 线程或线程池大小,充分利用多核 CPU。
-
高复用性:模型与具体业务逻辑解耦,具有较高的复用性。
局限性
-
复杂性:实现和调试较为复杂,尤其是在多线程环境下。
-
单点瓶颈:单 Reactor 线程可能成为性能瓶颈。
以上就是我关于Reactor模式的大概了解,相信通过对Muduo网络库源码的剖析,可以进一步体验Reactor模式的精妙之处。
参考:
如何深刻理解Reactor和Proactor? - 知乎
五分钟快速理解 Reactor 模型-CSDN博客
高性能网络编程之 Reactor 网络模型(彻底搞懂)_reactor网络模型-CSDN博客