机器学习相关内容
文章目录
- 感知机和SVM
- 感知机
- SVM(支持向量法)
- 二者联系和区别
- GRU和LSTM
- GRU
- LSTM
- 二者区别与联系
- 正则化
- L1正则化和L2正则化
感知机和SVM
感知机
参考文章
对上述文章部分内容进行额外补充和解释:

这里的“在训练数据集中选取数据(x,y)”具体是如何选取的?

通俗解释:

SVM(支持向量法)
参考文章
二者联系和区别
感知机(Perceptron)和支持向量机(Support Vector Machine, SVM)都是经典的线性分类器,它们旨在找到一个能够将不同类别数据分开的超平面。SVD可以认为是基于感知机基础上的改进。
区别:
主要是下图标注的地方内容

GRU和LSTM

GRU
参考文章
额外补充:

上述内容的记忆和遗忘是针对新的候选信息h^t\hat h_th^t!GRU通过一个更新门ztz_tzt同时控制遗忘和更新,当ztz_tzt很大,就意味着大量遗忘旧信息并大量吸收新信息;如果ztz_tzt很小,就意味着大量保留旧信息并大量忽略新消息。它没有 LSTM 那样独立地“只遗忘一部分旧信息,但完全不吸收新信息”的能力。

LSTM
参考文章
二者区别与联系
联系:
上述两者都是基于循环神经网络(RNN)的改进,可以解决RNN中不能长期记忆和反向传播中的梯度等问题。它们通过引入门控机制来选择性地记忆和遗忘信息。
区别:
主要的区别在于它们的内部结构、门的数量以及门控机制的实现方式。
1.门控机制和数量
LSTM有是三个门,俩状态:

两个状态分别为:
(1).细胞状态CtC_tCt

(2).隐藏状态hth_tht

细胞状态 (CtC_tCt) 负责长期信息的存储和传输,是 LSTM 核心的记忆通道。
隐藏状态 (hth_tht) 负责当前时间步的输出,并在一定程度上也携带了信息,参与到下一个时间步的门控计算中。
GRU有两个门:

2.内部结构与状态

3.对信息的控制粒度

4.参数数量和计算效率

正则化
参考文章
正则化存在的意义,能帮助我们在训练模型的过程中,防止模型过拟合。在不减少模型特征参数的前提情况下,降低模型的复杂程度。
为什么正则化约束可以防止模型过拟合?

通过约束参数的数值,从而限制模型的复杂程度。
L1正则化和L2正则化

图中的“L2正则化只能使得模型的参数数值趋于零,但不能等于0,而L1正则化却可以”内容,这是为什么?
下图从数学角度分析:

文章中也有从几何方式解释内容:
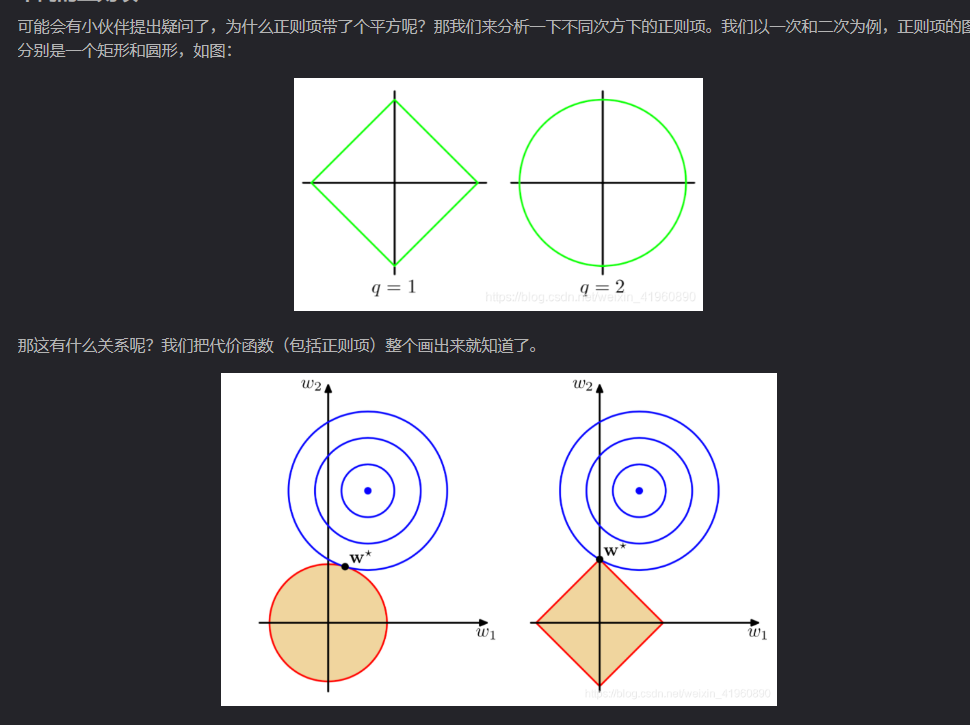
上述图是从二维空间进行分析,(坐标系分别对应w1,w2w_1,w_2w1,w2)
注:带正则化的约束问题的目标函数是:minwL(w)+tR(w)min_wL(w)+tR(w)minwL(w)+tR(w),可以转化为带有约束的形式为minwL(w),s.t.R(w)<=Tmin_wL(w) ,s.t.R(w)<=TminwL(w),s.t.R(w)<=T。
图具体表示什么意思:图中的蓝色图像表示的是损失函数的等高线(代表L(w)L(w)L(w)的值), 图中的红色图像分别表示的是L2正则化约束区域和L1正则化约束区域(代表了R(w)<=TR(w)<=TR(w)<=T的区域,优化算法只能在这个区域内寻找解,否则www值过大,则会使得带约束的问题目标函数数值很大)。
L2正则化目标函数公式:
minw(L(w)+t∣∣w∣∣22min_w(L(w)+t||w||_2^2minw(L(w)+t∣∣w∣∣22
其中的蓝色的圆的半径长度对应的就是L(w)L(w)L(w)数值,红色的图形中,红色圆表示的是L2正则化约束范围,即t∣∣w∣∣22t||w||_2^2t∣∣w∣∣22(原点到红色边的距离),
同理:
L1正则化目标函数公式:
minw(L(w)+t∣∣w∣∣1)min_w(L(w)+t||w||_1)minw(L(w)+t∣∣w∣∣1)
红色菱形图形表示的就是L1正则化约束范围,即t∣∣w∣∣1t||w||_1t∣∣w∣∣1(原点到红色边的距离)。
我们想要求目标函数数值最低时的www数值,即红色图像和蓝色图像关于某个点(www)的距离之和最小。这个数值往往是蓝色和红色这两个图像的相切地方。