深度学习在计算机视觉中的最新进展:范式转变与前沿探索
引言
计算机视觉,作为人工智能领域的核心分支,旨在使机器“看懂”世界。从早期的特征工程到如今深度学习的统治,其发展历程充满了突破与变革。近年来,随着模型架构、训练范式以及数据利用方式的不断演进,深度学习在计算机视觉领域展现出前所未有的能力,不仅在传统任务如图像分类、目标检测、语义分割上刷新了性能上限,更在图像生成、3D重建等新兴领域开辟了广阔天地。本文将深入探讨当前深度学习在计算机视觉中的几个关键最新进展,包括视觉Transformer的崛起、扩散模型的突破、自监督学习的成熟以及3D视觉的创新,并辅以代码结构示意,以期为读者提供全面的技术洞察。
1. 视觉Transformer (Vision Transformer, ViT) 与注意力机制的革新
长期以来,卷积神经网络(CNN)一直是计算机视觉领域的基石。然而,Transformer模型在自然语言处理(NLP)领域的巨大成功,促使研究者思考其在视觉任务中的潜力。2020年,Google提出的Vision Transformer(ViT)模型证明了纯粹基于Transformer架构的模型在图像分类任务上可以匹敌甚至超越先进的CNN模型,开启了视觉领域的新篇章。
1.1 核心思想与工作原理
ViT的核心思想是将图像分割成一系列固定大小的图像块(patches),将每个图像块视为一个“词元”(token),然后将这些词元序列输入到标准的Transformer编码器中进行处理。这种方式使得Transformer的强大自注意力机制能够直接作用于图像数据,捕捉长距离依赖关系。
主要组成部分:
- 图像分块与线性嵌入 (Patch Embedding): 将输入图像分割成不重叠的图像块,每个图像块展平后通过一个线性层映射到高维向量,作为Transformer的输入词元。此外,还会添加一个可学习的“类别词元”(Class Token)用于最终的分类预测,以及位置嵌入(Positional Embedding)来保留图像块的空间信息。
- Transformer编码器 (Transformer Encoder): 由多层堆叠的自注意力模块(Multi-Head Self-Attention, MSA)和多层感知机(Multi-Layer Perceptron, MLP)组成。MSA允许模型同时关注输入序列中的不同部分,捕捉全局依赖。
- 分类头 (Classification Head): 通常是一个简单的MLP层,接收类别词元的输出进行分类。
1.2 ViT的优势与挑战
优势:
- 全局感受野: 自注意力机制使其能够捕获图像中任意两个图像块之间的关系,具有天然的全局感受野,这与CNN的局部感受野形成对比。
- 可扩展性: 随着模型规模和训练数据量的增加,ViT的性能有显著提升的空间。
- 统一架构: 为NLP和CV任务提供了一个统一的建模框架。
挑战:
- 数据需求: ViT通常需要大规模数据集进行预训练才能表现出色,在小数据集上可能不如CNN。
- 计算成本: 自注意力机制的计算复杂度与输入序列长度的平方成正比,对于高分辨率图像,计算量较大。
1.3 关键变体与发展
为了解决ViT的挑战并进一步提升性能,研究者们提出了多种变体:
- DeiT (Data-efficient Image Transformers): 引入教师-学生蒸馏策略,使得ViT在较小数据集上也能有效训练。
- Swin Transformer: 引入“分层特征图”和“移动窗口”机制,将自注意力计算限制在局部窗口内,并允许跨窗口的信息交流,显著降低了计算复杂度,使其更适用于目标检测、语义分割等密集预测任务。Swin Transformer被认为是连接CNN和ViT的关键桥梁。
- MAE (Masked Autoencoders): 采用自监督学习范式,随机遮蔽图像块并让模型重建被遮蔽的部分,通过这种方式预训练的ViT在下游任务上表现出色,且预训练效率高。
1.4 代码结构示意 (PyTorch风格)
import torch
import torch.nn as nn
from einops.layers.torch import Rearrange # 一个方便的库用于张量重排# 1. 图像分块与线性嵌入
class PatchEmbedding(nn.Module):def __init__(self, img_size, patch_size, in_channels, embed_dim):super().__init__()self.img_size = img_sizeself.patch_size = patch_sizeself.num_patches = (img_size // patch_size) ** 2self.embed_dim = embed_dim# 将图像分割成patch并线性投影self.proj = nn.Sequential(Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=patch_size, p2=patch_size),nn.Linear(patch_size * patch_size * in_channels, embed_dim))# 可学习的位置编码self.pos_embedding = nn.Parameter(torch.randn(1, self.num_patches + 1, embed_dim))# 可学习的类别tokenself.cls_token = nn.Parameter(torch.randn(1, 1, embed_dim))def forward(self, x):# x: (batch_size, channels, img_h, img_w)x = self.proj(x) # (batch_size, num_patches, embed_dim)# 拼接类别tokencls_tokens = self.cls_token.expand(x.shape[0], -1, -1)x = torch.cat((cls_tokens, x), dim=1) # (batch_size, num_patches + 1, embed_dim)# 添加位置编码x += self.pos_embeddingreturn x# 2. 自注意力模块 (Multi-Head Self-Attention)
class Attention(nn.Module):def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.):super().__init__()self.num_heads = num_headshead_dim = dim // num_headsself.scale = head_dim ** -0.5self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)def forward(self, x):B, N, C = x.shape # batch_size, sequence_length, embedding_dim# 计算 Q, K, Vqkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2] # q, k, v: (B, num_heads, N, head_dim)# 计算注意力权重attn = (q @ k.transpose(-2, -1)) * self.scaleattn = attn.softmax(dim=-1)attn = self.attn_drop(attn)# 加权求和x = (attn @ v).transpose(1, 2).reshape(B, N, C)x = self.proj(x)x = self.proj_drop(x)return x# 3. Transformer编码器中的MLP块
class MLP(nn.Module):def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return x# 4. Transformer编码器层
class Block(nn.Module):def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, drop=0., attn_drop=0.,act_layer=nn.GELU, norm_layer=nn.LayerNorm):super().__init__()self.norm1 = norm_layer(dim)self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop)self.norm2 = norm_layer(dim)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = MLP(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)def forward(self, x):x = x + self.attn(self.norm1(x)) # 残差连接x = x + self.mlp(self.norm2(x)) # 残差连接return x# 5. 完整的Vision Transformer模型
class VisionTransformer(nn.Module):def __init__(self, img_size=224, patch_size=16, in_channels=3, num_classes=1000,embed_dim=768, depth=12, num_heads=12, mlp_ratio=4., qkv_bias=True,drop_rate=0., attn_drop_rate=0., norm_layer=nn.LayerNorm):super().__init__()self.num_classes = num_classesself.num_features = self.embed_dim = embed_dimself.patch_embed = PatchEmbedding(img_size=img_size, patch_size=patch_size, in_channels=in_channels, embed_dim=embed_dim)self.blocks = nn.Sequential(*[Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias,drop=drop_rate, attn_drop=attn_drop_rate, norm_layer=norm_layer)for _ in range(depth)])self.norm = norm_layer(embed_dim)self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()def forward_features(self, x):x = self.patch_embed(x)x = self.blocks(x)x = self.norm(x)return x[:, 0] # 只取类别token的输出进行分类def forward(self, x):x = self.forward_features(x)x = self.head(x)return x# 示例:创建一个ViT模型
# model = VisionTransformer(img_size=224, patch_size=16, num_classes=1000, embed_dim=768, depth=12, num_heads=12)
# dummy_input = torch.randn(1, 3, 224, 224)
# output = model(dummy_input)
# print(output.shape) # torch.Size([1, 1000])
2. 扩散模型 (Diffusion Models) 的崛起与生成能力
近年来,生成对抗网络(GANs)在图像生成领域取得了显著成就,但其训练不稳定性、模式崩溃等问题一直困扰着研究者。扩散模型(Diffusion Models)作为一种新兴的生成模型,在图像质量、多样性和训练稳定性方面展现出超越GANs的潜力,成为当前图像生成领域的焦点。
2.1 核心思想与工作原理
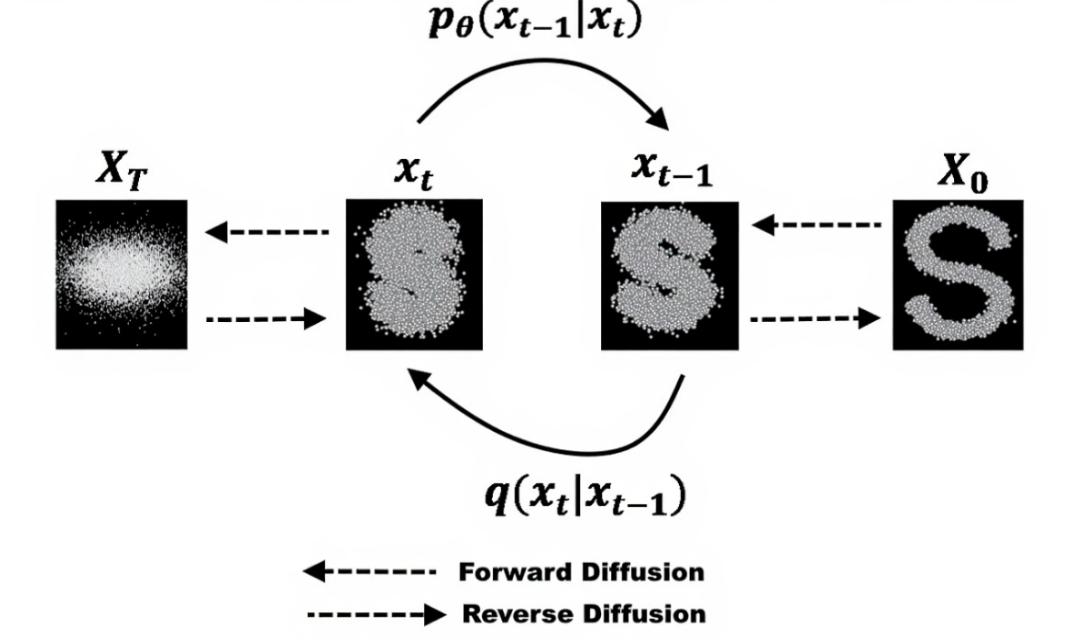
扩散模型的核心思想是通过一个逐步加噪(前向扩散过程)和逐步去噪(反向生成过程)的过程来学习数据分布。
前向扩散过程 (Forward Diffusion Process):
这个过程是将数据样本(例如一张图像)逐步地添加高斯噪声,直至其完全变成一个纯粹的随机噪声。这个过程是马尔可夫链式的,每一步添加少量噪声,并且这个过程是可控且无参数的。
反向生成过程 (Reverse Diffusion Process):
这是模型的学习目标。模型尝试学习如何逆转前向扩散过程,即从一个纯噪声中逐步去除噪声,最终恢复出清晰的图像。这个过程也是马尔可夫链式的,每一步模型预测当前噪声的量,然后从当前状态去除噪声以接近上一步的去噪结果。
训练目标: 模型通常是一个U-Net结构的神经网络,其任务是预测在给定当前带噪图像和时间步的情况下,前向扩散过程中添加的噪声。通过优化这个去噪任务,模型学会了如何从噪声中逐步还原数据。
2.2 扩散模型的优势
- 生成质量高: 能够生成极其逼真、细节丰富的图像。
- 模式覆盖广: 不像GANs容易出现模式崩溃,扩散模型能够更好地覆盖数据分布,生成更多样化的样本。
- 训练稳定: 相较于GANs对抗训练的复杂性,扩散模型的训练过程更为稳定,易于优化。
- 可控性强: 结合条件信息(如文本描述、类别标签),可以实现高度可控的图像生成(如DALL-E 2, Stable Diffusion)。
- 多任务应用: 不仅限于图像生成,在图像修复、超分辨率、风格迁移等任务上也表现出色。
2.3 关键变体与发展
- DDPM (Denoising Diffusion Probabilistic Models): 奠定了扩散模型的基础,通过预测噪声来逆转扩散过程。
- DDIM (Denoising Diffusion Implicit Models): 提出了一种非马尔可夫的反向过程,可以在更少的采样步数下生成高质量图像,大大加速了采样过程。
- Latent Diffusion Models (LDMs) / Stable Diffusion: 不在原始像素空间进行扩散,而是在 VAE(变分自编码器)编码后的低维潜在空间进行扩散。这显著降低了计算成本,使得模型能够处理高分辨率图像,并支持条件生成。这便是目前广泛使用的Stable Diffusion模型背后的核心思想。
2.4 代码结构示意 (PyTorch风格)
扩散模型通常由一个U-Net作为核心去噪网络,并包含前向和反向采样逻辑。
import torch
import torch.nn as nn
import torch.nn.functional as F
import math# 核心:U-Net去噪网络 (简化版)
class Block(nn.Module):def __init__(self, in_ch, out_ch, time_emb_dim):super().__init__()self.conv1 = nn.Conv2d(in_ch, out_ch, 3, padding=1)self.bn1 = nn.BatchNorm2d(out_ch)self.relu = nn.ReLU()self.conv2 = nn.Conv2d(out_ch, out_ch, 3, padding=1)self.bn2 = nn.BatchNorm2d(out_ch)self.time_proj = nn.Linear(time_emb_dim, out_ch) # 注入时间步信息def forward(self, x, t_emb):h = self.relu(self.bn1(self.conv1(x)))h = self.relu(self.bn2(self.conv2(h)))# 时间步信息通过加法注入h += self.time_proj(t_emb)[:, :, None, None] # 广播到特征图维度return hclass Downsample(nn.Module):def __init__(self, in_ch, out_ch, time_emb_dim):super().__init__()self.block = Block(in_ch, out_ch, time_emb_dim)self.pool = nn.MaxPool2d(2)def forward(self, x, t_emb):x = self.block(x, t_emb)return self.pool(x)class Upsample(nn.Module):def __init__(self, in_ch, out_ch, time_emb_dim):super().__init__()self.block = Block(in_ch, out_ch, time_emb_dim)self.upsample = nn.Upsample(scale_factor=2, mode='nearest') # 或使用转置卷积def forward(self, x, t_emb):x = self.upsample(x)return self.block(x, t_emb)class UNet(nn.Module):def __init__(self, in_channels=3, out_channels=3, time_emb_dim=256, base_channels=64):super().__init__()# 时间步嵌入self.time_mlp = nn.Sequential(nn.Linear(time_emb_dim, time_emb_dim * 4),nn.GELU(),nn.Linear(time_emb_dim * 4, time_emb_dim))# 编码器self.inc = Block(in_channels, base_channels, time_emb_dim)self.down1 = Downsample(base_channels, base_channels * 2, time_emb_dim)self.down2 = Downsample(base_channels * 2, base_channels * 4, time_emb_dim)self.down3 = Downsample(base_channels * 4, base_channels * 8, time_emb_dim)# 瓶颈层self.mid = Block(base_channels * 8, base_channels * 8, time_emb_dim)# 解码器self.up1 = Upsample(base_channels * 8 + base_channels * 8, base_channels * 4, time_emb_dim) # 注意跳跃连接的通道self.up2 = Upsample(base_channels * 4 + base_channels * 4, base_channels * 2, time_emb_dim)self.up3 = Upsample(base_channels * 2 + base_channels * 2, base_channels, time_emb_dim)self.outc = nn.Conv2d(base_channels + base_channels, out_channels, 1)def forward(self, x, t):t_emb = self.time_mlp(self._sinusoidal_positional_embedding(t, self.time_mlp[0].in_features))x1 = self.inc(x, t_emb)x2 = self.down1(x1, t_emb)x3 = self.down2(x2, t_emb)x4 = self.down3(x3, t_emb)xm = self.mid(x4, t_emb)# 跳跃连接x = self.up1(torch.cat([xm, x4], dim=1), t_emb) # 拼接操作是关键x = self.up2(torch.cat([x, x3], dim=1), t_emb)x = self.up3(torch.cat([x, x2], dim=1), t_emb)output = self.outc(torch.cat([x, x1], dim=1))return output# 简化的时间步位置编码def _sinusoidal_positional_embedding(self, timesteps, dim):"""将时间步转换为正弦位置嵌入"""half_dim = dim // 2freq = torch.exp(torch.arange(half_dim, device=timesteps.device) *-math.log(10000) / (half_dim - 1))emb = timesteps[:, None] * freq[None, :]emb = torch.cat((emb.sin(), emb.cos()), dim=-1)return emb# 简化的扩散过程模拟
class DiffusionModel:def __init__(self, model: UNet, timesteps=1000, beta_start=0.0001, beta_end=0.02):self.model = modelself.timesteps = timestepsself.betas = self._cosine_schedule(timesteps, beta_start, beta_end) # 可以是线性或余弦调度self.alphas = 1. - self.betasself.alphas_cumprod = torch.cumprod(self.alphas, dim=0)self.sqrt_alphas_cumprod = torch.sqrt(self.alphas_cumprod)self.sqrt_one_minus_alphas_cumprod = torch.sqrt(1. - self.alphas_cumprod)def _cosine_schedule(self, timesteps, s=0.008):"""余弦调度beta值"""steps = timesteps + 1x = torch.linspace(0, timesteps, steps)alphas_cumprod = torch.cos(((x / timesteps) + s) / (1 + s) * math.pi * 0.5) ** 2alphas_cumprod = alphas_cumprod / alphas_cumprod[0]betas = 1 - (alphas_cumprod[1:] / alphas_cumprod[:-1])return torch.clip(betas, 0.0001, 0.9999) # 裁剪以避免极端值# 前向扩散:添加噪声def q_sample(self, x_start, t, noise=None):if noise is None:noise = torch.randn_like(x_start)sqrt_alphas_cumprod_t = self.sqrt_alphas_cumprod[t].view(-1, 1, 1, 1)sqrt_one_minus_alphas_cumprod_t = self.sqrt_one_minus_alphas_cumprod[t].view(-1, 1, 1, 1)# x_t = sqrt(alpha_cumprod_t) * x_0 + sqrt(1 - alpha_cumprod_t) * noisereturn sqrt_alphas_cumprod_t * x_start + sqrt_one_minus_alphas_cumprod_t * noise# 反向采样:去噪(简化DDPM采样步骤)@torch.no_grad()def p_sample(self, x, t_index):betas_t = self.betas[t_index].view(-1, 1, 1, 1)sqrt_one_minus_alphas_cumprod_t = self.sqrt_one_minus_alphas_cumprod[t_index].view(-1, 1, 1, 1)sqrt_recip_alphas_t = 1. / torch.sqrt(self.alphas[t_index]).view(-1, 1, 1, 1)# 预测噪声model_mean = sqrt_recip_alphas_t * (x - betas_t * self.model(x, t_index) / sqrt_one_minus_alphas_cumprod_t)# 添加噪声用于下一轮去噪,除了最后一个时间步if t_index == 0:return model_meanelse:posterior_variance_t = self.betas[t_index].view(-1, 1, 1, 1) # DDPM中通常用beta_tnoise = torch.randn_like(x)return model_mean + torch.sqrt(posterior_variance_t) * noise# 生成图像 (完整采样过程)@torch.no_grad()def sample(self, shape):batch_size, channels, H, W = shapeimg = torch.randn(shape, device='cuda' if torch.cuda.is_available() else 'cpu') # 从纯噪声开始for i in range(self.timesteps - 1, -1, -1): # 从T到1逐步去噪t = torch.full((batch_size,), i, device=img.device, dtype=torch.long)img = self.p_sample(img, t)return img# 训练步骤:给定图像,随机采样时间步t,添加噪声,预测噪声def train_step(self, x_start):batch_size = x_start.shape[0]t = torch.randint(0, self.timesteps, (batch_size,), device=x_start.device).long()noise = torch.randn_like(x_start)x_noisy = self.q_sample(x_start=x_start, t=t, noise=noise)predicted_noise = self.model(x_noisy, t)loss = F.mse_loss(noise, predicted_noise) # 预测噪声与真实噪声的MSE损失return loss# 示例:
# device = 'cuda' if torch.cuda.is_available() else 'cpu'
# unet_model = UNet(in_channels=3, out_channels=3, time_emb_dim=256).to(device)
# diffusion = DiffusionModel(unet_model)
# dummy_image = torch.randn(1, 3, 32, 32).to(device) # 模拟一张输入图像
#
# # 训练步骤
# loss = diffusion.train_step(dummy_image)
# print(f"训练损失: {loss.item()}")
#
# # 采样生成图像
# generated_image = diffusion.sample(shape=(1, 3, 32, 32))
# print(f"生成图像形状: {generated_image.shape}")
3. 自监督学习 (Self-supervised Learning, SSL) 与基础模型 (Foundation Models)
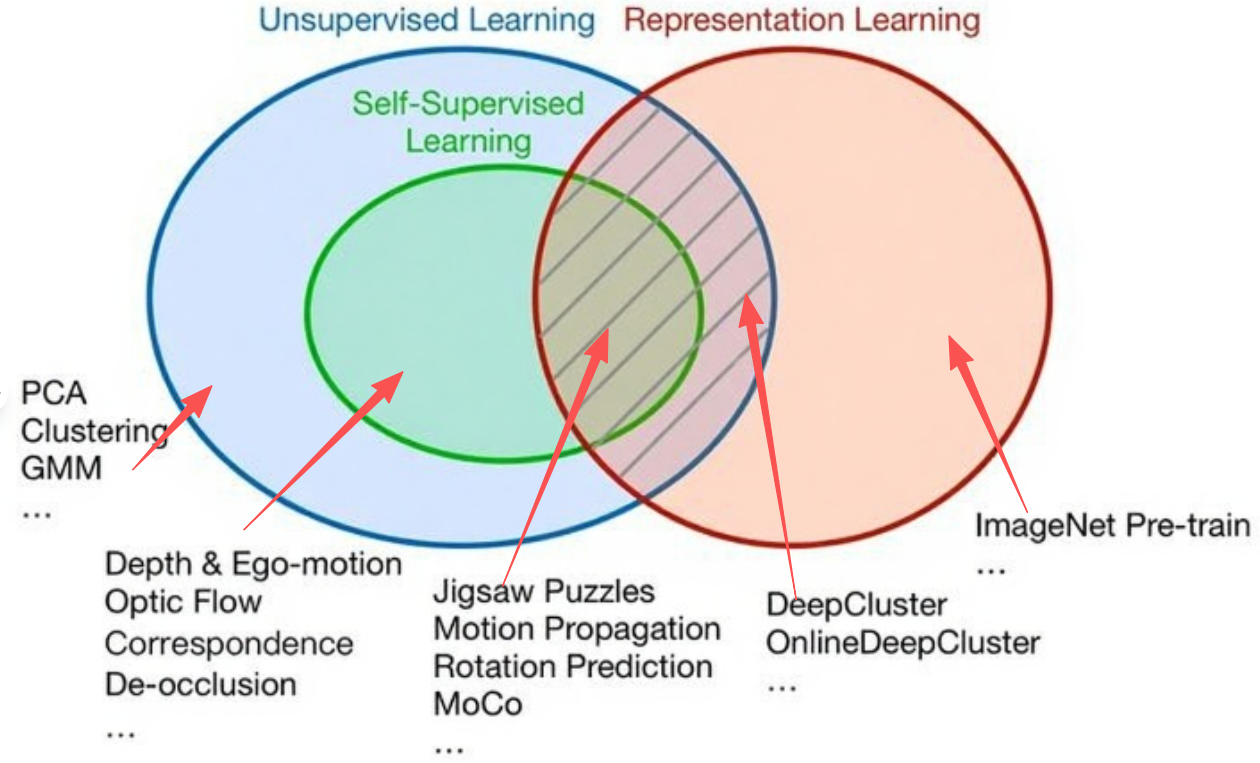
在深度学习早期,大规模标注数据集(如ImageNet)对模型的成功至关重要。然而,数据标注成本高昂且耗时。自监督学习提供了一种无需人工标注即可从海量未标注数据中学习有效表示的方法,它通过设计“代理任务”(pretext task)让模型从数据自身中生成监督信号。自监督学习的成功推动了基础模型(Foundation Models)的兴起,即在海量数据上预训练的、能够适应多种下游任务的通用模型。
3.1 核心思想与工作原理
自监督学习通常分为以下几类:
- 对比学习 (Contrastive Learning): 通过最大化同一数据不同增强视图之间的相似性,同时最小化与不同数据视图之间的相似性来学习表示。典型的代表有SimCLR、MoCo、BYOL等。它使模型能够学习区分不同实例的特征,即使这些实例在像素层面差异很小。
- 预测/重建类 (Generative/Predictive Learning): 让模型预测或重建数据的某个部分。例如,MAE(Masked Autoencoders)通过遮蔽图像块并预测其内容来学习。
- 聚类类 (Clustering-based Learning): 利用聚类算法在特征空间中对样本进行分组,并利用聚类结果作为监督信号来指导表示学习。
3.2 优势与重要性
- 减少对标注数据的依赖: 这是自监督学习最核心的优势,解决了标注成本高昂的问题。
- 学习更鲁棒的特征: 通过处理各种代理任务,模型能够学习到对多种语义信息都敏感的通用特征。
- 推动基础模型发展: 自监督学习是构建“大一统”基础模型的关键技术,这些模型经过大规模无监督预训练后,只需少量标注数据或零样本/少样本学习即可适应新任务。
- 促进跨模态学习: 在视觉-语言模型(如CLIP)中,自监督学习通过对齐图像和文本的表示,实现了强大的零样本识别能力。
3.3 关键方法与发展
- SimCLR (A Simple Framework for Contrastive Learning of Visual Representations): 通过数据增强创建正样本对,使用大batch size和动量编码器来提高负样本的数量和质量。
- MoCo (Momentum Contrast for Unsupervised Visual Representation Learning): 使用一个动态更新的队列和动量编码器来维持大量负样本,解决了SimCLR对大batch size的依赖。
- BYOL (Bootstrap Your Own Latent): 不使用负样本对,通过预测同一图像不同增强视图的表示来学习,避免了模式崩溃。
- DINO (Emerging Properties in Self-Supervised Vision Transformers): 专注于在ViT架构上进行自监督学习,通过自蒸馏(student-teacher learning)避免了崩溃,并能学习到有意义的图像语义分割能力。
- CLIP (Contrastive Language-Image Pre-training): OpenAIs推出的跨模态基础模型,通过在大规模图像-文本对上进行对比学习,使得模型能够理解图像和文本之间的语义关系,实现了强大的零样本识别和图像生成能力。
3.4 代码结构示意 (PyTorch风格 - 以SimCLR为例)
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as T
from PIL import Image# 1. 数据增强 (SimCLR的关键)
class TwoCropTransform:"""对同一图像应用两次不同的数据增强"""def __init__(self, transform):self.transform = transformdef __call__(self, x):return [self.transform(x), self.transform(x)]# SimCLR常用的数据增强策略
def get_simclr_transforms(image_size):return T.Compose([T.RandomResizedCrop(image_size, scale=(0.2, 1.)),T.RandomApply([T.ColorJitter(0.4, 0.4, 0.4, 0.1)], p=0.8),T.RandomGrayscale(p=0.2),T.RandomHorizontalFlip(),T.ToTensor(),T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])# 2. 编码器 (例如ResNet)
class Encoder(nn.Module):def __init__(self, base_model='resnet50', out_dim=128):super().__init__()# 使用预训练的ResNet作为骨干网络 (去除分类头)if base_model == 'resnet50':resnet = torch.hub.load('pytorch/vision:v0.10.0', 'resnet50', pretrained=False)self.features = nn.Sequential(*list(resnet.children())[:-1]) # 去掉平均池化和全连接层in_features = resnet.fc.in_featureselse:raise NotImplementedError(f"Base model {base_model} not supported.")# 投影头 (Projection Head)# 通常是一个MLP,将特征映射到更低维的空间进行对比学习self.projection_head = nn.Sequential(nn.Linear(in_features, in_features),nn.ReLU(),nn.Linear(in_features, out_dim))def forward(self, x):features = self.features(x).squeeze() # (batch_size, in_features)out = self.projection_head(features) # (batch_size, out_dim)return F.normalize(out, dim=1) # L2归一化# 3. 对比损失函数 (NT-Xent Loss)
class NTXentLoss(nn.Module):def __init__(self, temperature=0.07):super().__init__()self.temperature = temperaturedef forward(self, z_i, z_j):"""计算SimCLR的NT-Xent损失。z_i, z_j 是两个视图的归一化特征表示,形状为 (batch_size, feature_dim)。"""batch_size = z_i.shape[0]# 拼接两个视图的特征,形成 (2*batch_size, feature_dim)z = torch.cat([z_i, z_j], dim=0)# 计算所有样本之间的余弦相似度 (2*batch_size, 2*batch_size)# S_ij = z_i @ z_j.Tsim_matrix = torch.matmul(z, z.T) / self.temperature# 创建正样本对的掩码 (对角线为0,因为自己和自己不是正样本对)# 批次内每个i都有一个对应的j作为正样本 (i != j)# 对应位置是 (i, i+batch_size) 和 (i+batch_size, i)labels = torch.arange(2 * batch_size, device=z.device)# 假设batch_size=2, 则z_i = [z_0, z_1], z_j = [z_2, z_3]# 正样本对为 (z_0, z_2), (z_1, z_3), (z_2, z_0), (z_3, z_1)# 索引对应为 (0, 2), (1, 3), (2, 0), (3, 1)labels = (labels + batch_size) % (2 * batch_size)# 移除对角线上的自相似性# 在计算log_softmax时,自相似项的log(exp(sim)/sum(exp(sim))) 会导致除以0的问题# 因此通常在log_softmax之前,将自相似项设置为负无穷logits = sim_matrix# 排除自相似项logits_mask = torch.scatter(torch.ones_like(labels, dtype=torch.bool),1,torch.arange(2 * batch_size, device=z.device).view(-1, 1),0).to(z.device)# 应用掩码,将自相似项设为非常小的负数logits = logits[logits_mask].view(2 * batch_size, -1)# 计算交叉熵损失# cross_entropy(logits, target) 等价于 -log(softmax(logits)[target])# 这里target就是正样本的索引positive_logits = sim_matrix[torch.arange(2 * batch_size), labels]# 计算分母部分(所有负样本加上正样本)denominator = torch.logsumexp(logits, dim=1)# 最终的NT-Xent损失loss = (- positive_logits + denominator).mean()return loss# 训练循环示意
def train_simclr(encoder, dataloader, optimizer, loss_fn, device):encoder.train()total_loss = 0for batch_idx, (images, _) in enumerate(dataloader):# images 是 [view1, view2]x_i, x_j = images[0].to(device), images[1].to(device)optimizer.zero_grad()# 获取特征z_i = encoder(x_i)z_j = encoder(x_j)loss = loss_fn(z_i, z_j)loss.backward()optimizer.step()total_loss += loss.item()return total_loss / len(dataloader)# 示例:
# from torch.utils.data import DataLoader, TensorDataset
#
# # 准备一些假数据
# dummy_images = torch.randn(100, 3, 32, 32)
# dummy_labels = torch.randint(0, 10, (100,))
#
# # 应用TwoCropTransform
# transform = TwoCropTransform(get_simclr_transforms(32))
# dummy_dataset = TensorDataset(dummy_images, dummy_labels) # 实际中使用自定义数据集
#
# # 需要一个能应用transform的自定义Dataset
# class DummySimCLRDataset(torch.utils.data.Dataset):
# def __init__(self, data, transform):
# self.data = data
# self.transform = transform
# def __len__(self):
# return len(self.data)
# def __getitem__(self, idx):
# img = self.data[idx]
# return self.transform(img), 0 # 标签在自监督学习中不直接使用
#
# simclr_dataset = DummySimCLRDataset(dummy_images, transform)
# simclr_dataloader = DataLoader(simclr_dataset, batch_size=32, shuffle=True)
#
# device = 'cuda' if torch.cuda.is_available() else 'cpu'
# simclr_encoder = Encoder(out_dim=128).to(device)
# simclr_optimizer = torch.optim.Adam(simclr_encoder.parameters(), lr=1e-3)
# simclr_loss_fn = NTXentLoss(temperature=0.5)
#
# # print(f"SimCLR Epoch 1 Loss: {train_simclr(simclr_encoder, simclr_dataloader, simclr_optimizer, simclr_loss_fn, device):.4f}")
4. 3D 视觉的创新:NeRF与隐式神经表示
传统的3D视觉通常依赖于显式表示(如点云、网格、体素),这些表示往往受到分辨率限制,且对重建精度要求高。近年来,隐式神经表示(Implicit Neural Representations, INR)成为3D视觉领域的重要突破,其中Neural Radiance Fields (NeRF) 及其变体是代表性工作,它们能够以极高的真实感渲染3D场景。
4.1 核心思想与工作原理
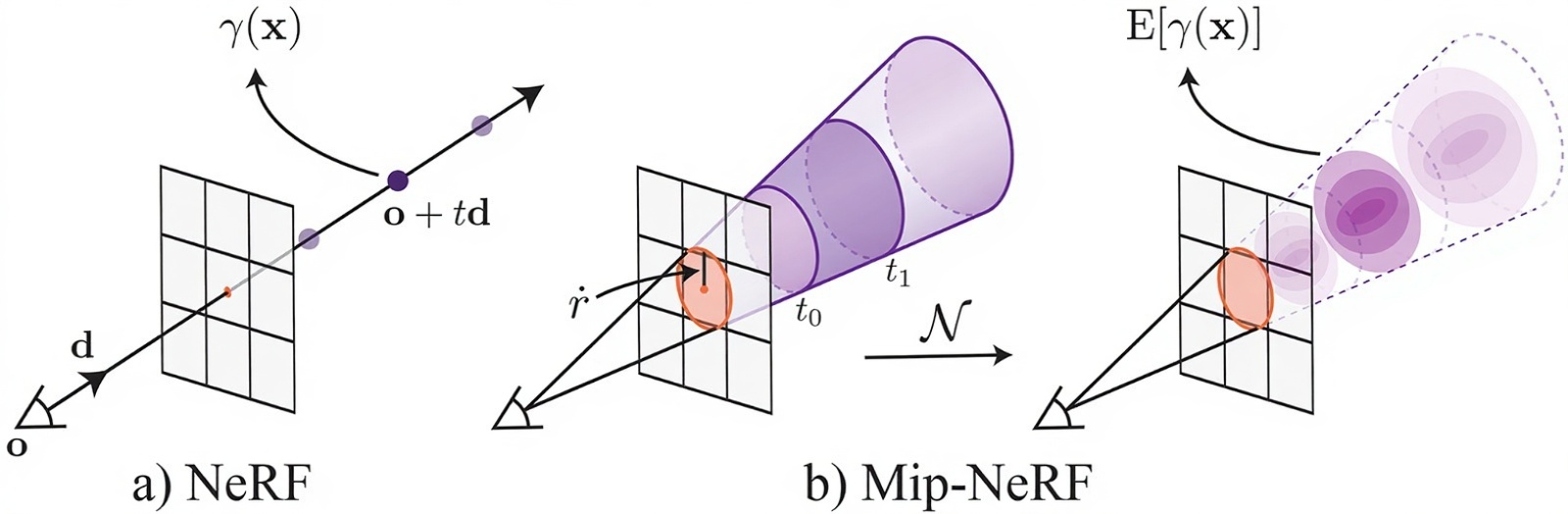
NeRF的核心思想是使用一个深度神经网络来隐式地表示一个3D场景。这个网络以一个3D空间点坐标 (x, y, z) 和一个2D视角方向 (θ, φ) 作为输入,输出该点在该视角方向上的颜色 (R, G, B) 和体密度 σ(表示该点的不透明度或存在概率)。
渲染过程:
- 射线投射 (Ray Casting): 对于图像中的每个像素,从相机中心沿着该像素的方向投射一条射线进入3D场景。
- 采样点 (Sampling Points): 沿着这条射线,采样一系列3D点。
- 神经网络查询 (Network Query): 对于每个采样点,将其3D坐标和视角方向输入到NeRF网络中,得到该点的颜色和体密度。
- 体渲染 (Volume Rendering): 利用经典的光线追踪体渲染方程,将沿射线所有采样点的颜色和体密度信息累积起来,计算出最终的像素颜色。这个过程是可微分的,使得可以通过梯度下降优化NeRF网络。
训练目标: NeRF通过最小化渲染出的图像与真实图像之间的重建损失(例如L2损失)来训练网络参数。
4.2 NeRF的优势与挑战
优势:
- 极高真实感: 能够生成极其逼真的新视角图像,甚至超越传统的基于几何重建的方法。
- 连续表示: 场景以连续函数形式存在,不受离散采样分辨率的限制。
- 存储效率: 对于复杂场景,单个神经网络通常比存储高分辨率网格或体素更节省空间。
挑战:
- 训练和推理速度: 原始NeRF模型的训练和渲染速度较慢,每个新视角渲染需要多次神经网络查询。
- 泛化能力: 原始NeRF模型通常针对单个场景进行优化,难以直接泛化到新场景。
- 多尺度表示: 难以有效地处理场景中的不同尺度细节。
4.3 关键变体与发展
为了解决上述挑战,研究者们提出了多种NeRF变体:
- Mip-NeRF: 引入了多尺度表示,通过集成圆锥体而非射线来采样,有效地解决了抗锯齿问题并提升了渲染质量。
- NeRF++: 扩展NeRF以处理 unbounded 场景(例如开放的室外场景)。
- Plenoxels / TensoRF: 放弃了多层感知机(MLP),转而使用显式的体素网格来存储辐射场信息,通过张量分解等技术实现高效存储和快速训练/渲染。这些方法极大地提升了NeRF的实用性。
- Instant-NGP (Instant Neural Graphics Primitives): 结合了多分辨率哈希编码(multi-resolution hash encoding)技术,可以在几秒钟内训练出高质量的NeRF模型,实现近乎实时的渲染,是该领域的重要突破。
- 3D Gaussian Splatting: 一种完全脱离神经网络,通过优化大量3D高斯球来表示场景,并在GPU上进行快速光栅化的技术,其渲染速度和质量都达到了新的高度。
4.4 代码结构示意 (PyTorch风格 - NeRF核心Mlp)
NeRF的核心是一个MLP,用于查询3D点和视角方向。
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np# 1. 位置编码 (Positional Encoding)
# NeRF使用位置编码将输入坐标映射到高维空间,以帮助MLP捕捉高频细节
class PositionalEncoder(nn.Module):def __init__(self, input_dims, num_freqs, log_sampling=True, include_input=True):super().__init__()self.include_input = include_inputself.num_freqs = num_freqsself.input_dims = input_dimsself.funcs = [torch.sin, torch.cos]self.freq_bands = 2**torch.linspace(0., num_freqs - 1, num_freqs) if log_sampling else torch.linspace(1., 2**(num_freqs-1), num_freqs)def forward(self, x):"""x: (N, input_dims) - 3D点坐标或2D视角方向"""# x_encoded = [x] if self.include_input else []# for freq in self.freq_bands:# for func in self.funcs:# x_encoded.append(func(x * freq))# return torch.cat(x_encoded, dim=-1)# 优化后的实现,避免for循环embeddings = [x] if self.include_input else []for freq in self.freq_bands:for func in self.funcs:embeddings.append(func(x * freq))return torch.cat(embeddings, dim=-1)# 2. NeRF核心MLP网络
class NeRFMLP(nn.Module):def __init__(self,D=8, # 网络层数W=256, # 每层宽度input_ch=3, # 3D点坐标的输入通道数 (经过位置编码后会增加)input_ch_views=3, # 视角方向的输入通道数 (经过位置编码后会增加)output_ch=4, # RGB + sigmaskips=[4]): # 残差连接层super().__init__()self.D = Dself.W = Wself.input_ch = input_chself.input_ch_views = input_ch_viewsself.skips = skipsself.pts_linears = nn.ModuleList([nn.Linear(input_ch, W)] +[nn.Linear(W, W) if i not in self.skips else nn.Linear(W + input_ch, W) for i in range(D-1)])# 密度 (sigma) 分支self.sigma_linear = nn.Linear(W, 1)# 颜色 (RGB) 分支self.feature_linear = nn.Linear(W, W) # 用于与视角方向拼接self.views_linear = nn.Linear(W + input_ch_views, W // 2)self.rgb_linear = nn.Linear(W // 2, 3)def forward(self, x, views):"""x: 编码后的3D点坐标 (N_rays*N_samples, input_ch)views: 编码后的视角方向 (N_rays*N_samples, input_ch_views)"""input_pts = xh = input_ptsfor i, l in enumerate(self.pts_linears):h = self.pts_linears[i](h)h = F.relu(h)if i in self.skips:h = torch.cat([input_pts, h], -1) # 残差连接sigma = torch.relu(self.sigma_linear(h)) # 密度值非负feature = self.feature_linear(h)h = torch.cat([feature, views], -1) # 拼接视角方向h = F.relu(self.views_linear(h))rgb = torch.sigmoid(self.rgb_linear(h)) # RGB值在0-1之间return torch.cat([rgb, sigma], -1)# 3. 体渲染 (Volume Rendering) 函数 (简化版)
def raw2outputs(raw, z_vals, rays_d, raw_noise_std=0, white_bkgd=False):"""将NeRF MLP的原始输出 (颜色+密度) 转换为可渲染的颜色."""# raw: (N_rays, N_samples, 4) [RGB, sigma]# z_vals: (N_rays, N_samples) 深度值# rays_d: (N_rays, 3) 射线方向dists = z_vals[..., 1:] - z_vals[..., :-1] # (N_rays, N_samples-1)# 对于最后一个点,假设其距离无穷远dists = torch.cat([dists, torch.tensor([1e10], device=dists.device).expand(dists[..., :1].shape)], -1)dists = dists * torch.norm(rays_d[..., None, :], dim=-1) # (N_rays, N_samples)rgb = torch.sigmoid(raw[..., :3]) # (N_rays, N_samples, 3)sigma = torch.relu(raw[..., 3]) # (N_rays, N_samples)noise = 0.if raw_noise_std > 0.:noise = torch.randn(sigma.shape, device=sigma.device) * raw_noise_stdalpha = 1. - torch.exp(-sigma * dists + noise) # (N_rays, N_samples)# 累积透明度 Tweights = alpha * torch.cumprod(torch.cat([torch.ones((alpha.shape[0], 1), device=alpha.device), 1.-alpha + 1e-10], -1), -1)[:, :-1]rgb_map = torch.sum(weights[..., None] * rgb, -2) # (N_rays, 3)depth_map = torch.sum(weights * z_vals, -1) # (N_rays)acc_map = torch.sum(weights, -1) # (N_rays)if white_bkgd:rgb_map = rgb_map + (1.-acc_map[...,None])return rgb_map, depth_map, acc_map, weights# 示例:
# # 初始化位置编码器
# pos_enc_pts = PositionalEncoder(input_dims=3, num_freqs=10) # 编码3D点坐标
# pos_enc_views = PositionalEncoder(input_dims=3, num_freqs=4) # 编码视角方向
#
# # 计算编码后的维度
# encoded_pts_dim = pos_enc_pts.forward(torch.zeros(1,3)).shape[-1]
# encoded_views_dim = pos_enc_views.forward(torch.zeros(1,3)).shape[-1]
#
# # 初始化NeRF MLP
# nerf_model = NeRFMLP(input_ch=encoded_pts_dim, input_ch_views=encoded_views_dim)
#
# # 模拟输入数据
# num_rays = 1
# num_samples_per_ray = 64
# dummy_pts = torch.randn(num_rays * num_samples_per_ray, 3) # 采样点坐标
# dummy_views = torch.randn(num_rays * num_samples_per_ray, 3) # 视角方向
# dummy_z_vals = torch.linspace(0, 1, num_samples_per_ray).repeat(num_rays, 1)
# dummy_rays_d = torch.randn(num_rays, 3)
#
# # 编码输入
# encoded_dummy_pts = pos_enc_pts(dummy_pts)
# encoded_dummy_views = pos_enc_views(dummy_views)
#
# # 传入NeRF模型
# raw_output = nerf_model(encoded_dummy_pts, encoded_dummy_views)
# print(f"NeRF MLP原始输出形状: {raw_output.shape}") # (N_rays*N_samples, 4)
#
# # 体渲染得到最终颜色
# rgb_map, depth_map, acc_map, weights = raw2outputs(
# raw_output.reshape(num_rays, num_samples_per_ray, 4),
# dummy_z_vals,
# dummy_rays_d
# )
# print(f"渲染的RGB图形状: {rgb_map.shape}") # (N_rays, 3)
总结与展望
深度学习在计算机视觉领域的最新进展呈现出多样化和交叉融合的趋势。Vision Transformer及其变体打破了CNN在视觉领域的垄断,展现了注意力机制的强大通用性;扩散模型以其卓越的生成质量和稳定性,成为图像生成领域的新范式;自监督学习通过从海量无标注数据中学习通用表示,为基础模型的构建铺平了道路;而NeRF和隐式神经表示则革新了3D场景的建模与渲染方式,极大地提升了虚拟世界的真实感。
展望未来,计算机视觉领域将继续在以下几个方向深入探索:
- 多模态融合: 视觉与语言、听觉等多种模态的深度融合将是未来的重要方向,以实现对世界的更全面、更语义化的理解,如大模型中的图像理解、视频问答等。
- 通用智能与具身智能: 将视觉感知与具身智能(如机器人、自动驾驶)相结合,使机器能够在真实世界中进行感知、决策和行动。
- 高效与低成本: 随着模型规模的不断扩大,如何设计更高效、更轻量级的模型,以及如何在计算资源有限的边缘设备上部署模型,将是持续的挑战。
- 可解释性与鲁棒性: 提高深度学习模型的可解释性,理解其决策过程,并增强模型对对抗性攻击、数据噪声的鲁棒性,以确保其在关键应用中的可靠性。
- 3D理解与重建: 随着XR(扩展现实)技术的发展,对3D场景的实时、高精度理解和重建需求将持续增长,NeRF及其后续工作仍有巨大的发展潜力。
这些进展不仅推动了计算机视觉技术的边界,也为人工智能在各个领域的应用开辟了更广阔的空间。随着技术的不断成熟和创新,我们可以预见,未来机器将能够以更加智能和自然的方式“看”懂并理解这个世界。