python爬虫(请求+解析+案例)
requests
requests中普通的get请求
import requests
content = input("请输入需要检索的内容")
#拼接url
url = f"https://www.sogou.com/web?query={content}"
#请求头
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0"
}
#发送get请求
resp = requests.get(url, headers=headers)
#打印相应信息的文本形式(字符串)
print(resp.text)
#可以查看到请求头信息
print(resp.headers)
requests中普通的post请求
import requests
import jsonurl = "https://fanyi.baidu.com/sug"
#请求头
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0"
}
#配置请求信息
data = {"kw":input("请输入需要翻译的词"),
}
#发送post请求
resp = requests.post(url,data=data, headers=headers)
#解析json数据
content = json.loads(resp.text)
#打印解析后的数据
print(content)
#因为是字典形式,所以可以根据索引取到指定值
print(content['data'][0]['v'])
post中使用data对象传输请求数据,get多参数时,使用params对象传输数据。用法类似
正则表达式
代码示例
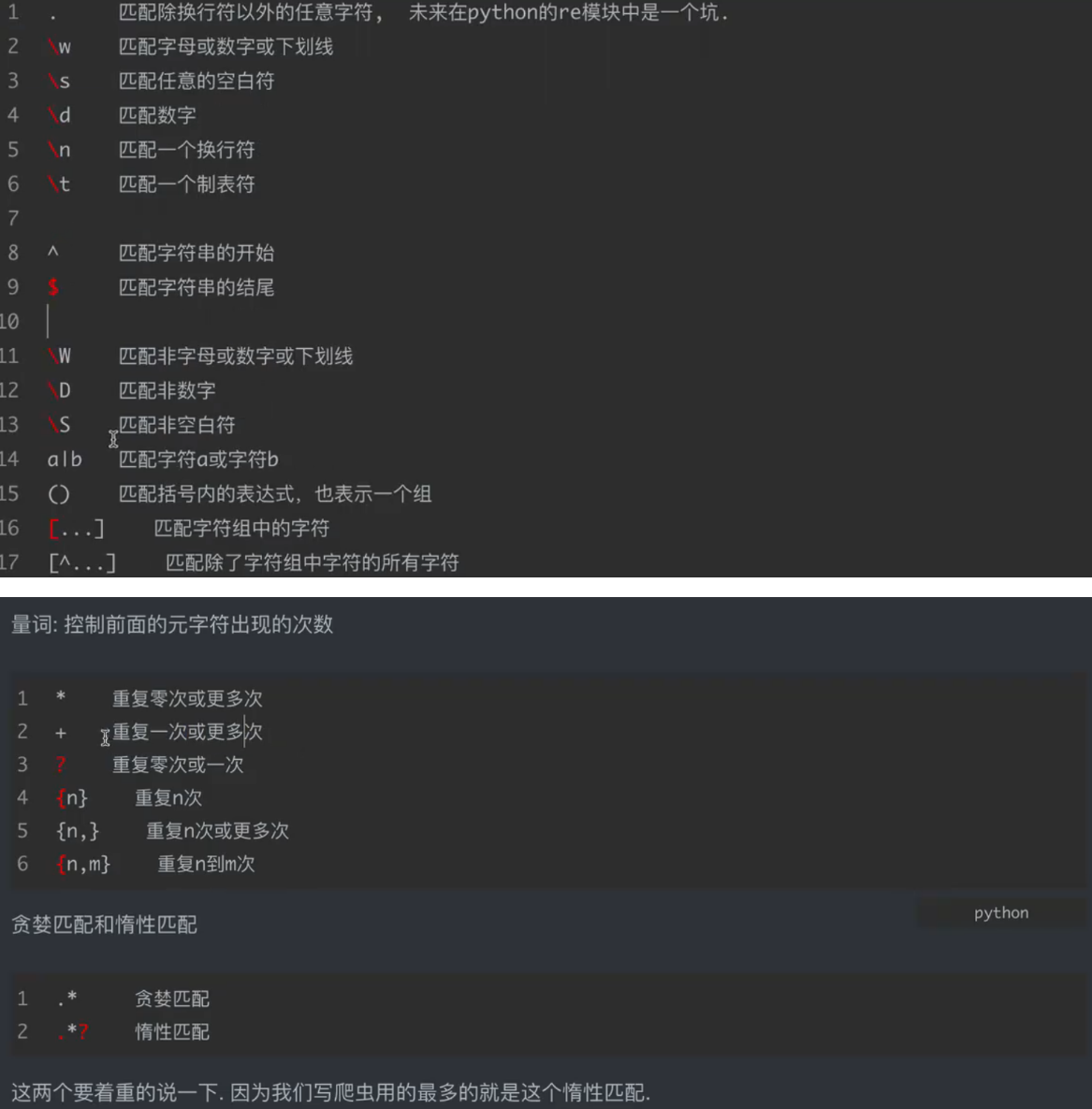
import retext = "Hello 123_World\n\tPython@2025"# 1. . :匹配除换行外任意字符(默认)
print("1. . 匹配:", re.findall(r".", text))
# 输出:['H','e','l','l','o',' ','1','2','3','_','W','o','r','l','d','\n','\t','P','y','t','h','o','n','@','2','0','2','5']# 2. \w :匹配字母/数字/下划线
print("2. \\w 匹配:", re.findall(r"\w", text))
# 输出:['H','e','l','l','o','1','2','3','_','W','o','r','l','d','P','y','t','h','o','n','2','0','2','5']# 3. \s :匹配空白符(空格、换行、制表符)
print("3. \\s 匹配:", re.findall(r"\s", text))
# 输出:[' ', '\n', '\t']# 4. \d :匹配数字
print("4. \\d 匹配:", re.findall(r"\d", text))
# 输出:['1','2','3','2','0','2','5']# 5. \n :匹配换行符(需开启多行模式时更常用,此处演示字符匹配)
print("5. \\n 匹配:", re.findall(r"\n", text))
# 输出:['\n']# 6. \t :匹配制表符
print("6. \\t 匹配:", re.findall(r"\t", text))
# 输出:['\t']# 7. ^ :匹配字符串开头(需结合多行模式,或简单文本开头)
print("7. ^ 匹配:", re.findall(r"^Hello", text))
# 输出:['Hello'](因 text 以 Hello 开头)# 8. $ :匹配字符串结尾
print("8. $ 匹配:", re.findall(r"2025$", text))
# 输出:['2025'](因 text 以 2025 结尾)# 9. \W :匹配非字母/数字/下划线(与 \w 相反)
print("9. \\W 匹配:", re.findall(r"\W", text))
# 输出:[' ', '\n', '\t', '@']# 10. \D :匹配非数字(与 \d 相反)
print("10. \\D 匹配:", re.findall(r"\D", text))
# 输出:['H','e','l','l','o',' ','_','W','o','r','l','d','\n','\t','P','y','t','h','o','n','@']# 11. \S :匹配非空白符(与 \s 相反)
print("11. \\S 匹配:", re.findall(r"\S", text))
# 输出:['H','e','l','l','o','1','2','3','_','W','o','r','l','d','P','y','t','h','o','n','@','2','0','2','5']# 12. a|b :匹配 a 或 b(此处演示匹配 'Hello' 或 'Python')
print("12. a|b 匹配:", re.findall(r"Hello|Python", text))
# 输出:['Hello', 'Python']# 13. ( ) :分组(提取子匹配,此处提取数字前后的字符)
match = re.search(r"(\w+)(\d+)(\w+)", text)
print("13. ( ) 分组:", match.groups())
# 输出:('Hello_', '123', 'World')(因 text 中 'Hello_123_World' 可匹配,需调整文本更明显,示例仅演示分组语法)# 14. [...] :匹配字符组(匹配 'H' 或 'P' 开头)
print("14. [...] 匹配:", re.findall(r"^[HP]", text))
# 输出:['H'](text 以 H 开头)# 15. [^...] :匹配非字符组(匹配非 'H' 开头的行首,需多行模式,此处简化演示)
print("15. [^...] 匹配:", re.findall(r"[^H]\w+", text))
# 输出:['ello 123_World', 'n\tPython@2025'](匹配非 H 开头的单词,结果需结合实际文本调整)
text = "aaaabbbbccccc 1111 22 3"# 1. * :0 次或多次(匹配任意长度的字母串)
print("1. * 匹配:", re.findall(r"[a-z]*", text))
# 输出:['aaaa', '', 'bbbb', '', 'ccccc', '', '', '1111', '', '22', '', '3', ''](空串是因为匹配到分隔符)# 2. + :1 次或多次(匹配连续字母)
print("2. + 匹配:", re.findall(r"[a-z]+", text))
# 输出:['aaaa', 'bbbb', 'ccccc']# 3. ? :0 次或 1 次(匹配 '2' 或 '22' 中的单个 2)
print("3. ? 匹配:", re.findall(r"2?", text))
# 输出:['', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '2', '2', '', '2', '', ''](需调整文本,示例演示语法)# 4. {n} :重复 n 次(匹配连续 4 个数字)
print("4. {n} 匹配:", re.findall(r"\d{4}", text))
# 输出:['1111']# 5. {n,} :重复 n 次或更多(匹配至少 2 个数字)
print("5. {n,} 匹配:", re.findall(r"\d{2,}", text))
# 输出:['1111', '22']# 6. {n,m} :重复 n 到 m 次(匹配 2-3 个数字)
print("6. {n,m} 匹配:", re.findall(r"\d{2,3}", text))
# 输出:['111', '22'](因 '1111' 可拆为 '111' 和 '1',需调整文本,示例演示语法)
text = "<div>Hello</div><div>World</div>"# 1. 贪婪匹配(.* 匹配最长可能)
greedy_match = re.findall(r"<div>(.*)</div>", text)
print("1. 贪婪匹配:", greedy_match)
# 输出:['Hello</div><div>World'](匹配从第一个 <div> 到最后一个 </div>)# 2. 惰性匹配(.*? 匹配最短可能)
lazy_match = re.findall(r"<div>(.*?)</div>", text)
print("2. 惰性匹配:", lazy_match)
# 输出:['Hello', 'World'](匹配每个 <div> 内的内容)
re模块的使用
import reresult1 = re.findall('a',"woshiaawdja")
print(result1) #['a', 'a', 'a']result2 = re.findall(r'\d+',"我今年18岁,我有200000块")
print(result2) #该匹配字符串前加一个r,可以防止字符串中的\发生转义for item in result2:print(item)#18#200000#下述是迭代器需要加上.group()取值result2 = re.finditer(r'\d+',"我今年18岁,我有200000块")
for item in result2:print(item)#<re.Match object; span=(3, 5), match='18'>#<re.Match object; span=(9, 15), match='200000'>print(item.group())#18#200000result3 = re.search(r"\d+","我叫周杰伦,今年32岁,3年级2班")
print(result3.group()) #32 search只会匹配到第一次匹配到的内容#match,在匹配的时候,是从字符串的开头进行匹配的,类似在正则前面加上了^
result4 = re.match(r"\d+","我叫周杰伦,今年32岁,3年级2班")
print(result4.group()) # 空 search只会匹配到第一次匹配到的内容#预加载,提前把正则对象加载完毕
obj = re.compile(r"\d+")
#直接把加载好的正则进行使用
result5 = re.search(r"\d+","我叫周杰伦,今年32岁,3年级2班")
print(result5.group())
#32
正则在爬虫中的用法
import re
s = """
<div class = '西游记'><span id = '10010'>中国联通</span></div>
<div class = '西游记'><span id = '10086'>中国移动</span></div>
"""
#预加载正则表达式
obj1 = re.compile(r"<span id = '\d+'>.*?</span>")
#匹配查找
result1 = obj1.findall(s)
print(result1) #["<span id = '10010'>中国联通</span>", "<span id = '10086'>中国移动</span>"]
#小括号用于分割元素
obj2 = re.compile(r"<span id = '(\d+)'>(.*?)</span>")
result2 = obj2.findall(s)
print(result2) #[('10010', '中国联通'), ('10086', '中国移动')]
#?P<name>用于命名,方便针对性读取
obj3 = re.compile(r"<span id = '(?P<id>\d+)'>(?P<name>.*?)</span>")
#迭代器时使用finditer
result3 = obj3.finditer(s)
for item in result3:print(item.group())#{'id': '10010', 'name': '中国联通'}#{'id': '10086', 'name': '中国移动'}print(item.group("id"))#10010#10086print(item.group("name"))#中国联通#中国移动
正则提取数据综合案例
#思路
#1,拿到页面源代码'''
部分页面源代码....
< ol
class ="grid_view" >
< li >
< div
class ="item" >
< div
class ="pic" >
< em > 1 < / em >
< a
href = "https://movie.douban.com/subject/1292052/" >
< img
width = "100"
alt = "肖申克的救赎"
src = "https://img3.doubanio.com/view/photo/s_ratio_poster/public/p480747492.webp" >
< / a >
< / div >
< div
class ="info" >
< div
class ="hd" >
< a
href = "https://movie.douban.com/subject/1292052/" >
< span
class ="title" > 肖申克的救赎 < / span >
< span
class ="title" > & nbsp; / & nbsp;The Shawshank Redemption < / span >
< span
class ="other" > & nbsp; / & nbsp;月黑高飞(港) / 刺激1995(台) < / span >
< / a >
< span
class ="playable" >[可播放] < / span >< / div >
< div
class ="bd" >< p >
导演: 弗兰克·德拉邦特
Frank
Darabont & nbsp; & nbsp; & nbsp;
主演: 蒂姆·罗宾斯
Tim
Robbins / ... < br >
1994 & nbsp; / & nbsp;
美国 & nbsp; / & nbsp;
犯罪
剧情
< / p >< div >
< span
class ="rating5-t" > < / span >< span
class ="rating_num" property="v:average" > 9.7 < / span >
< span
property = "v:best"
content = "10.0" > < / span >
< span > 3199635
人评价 < / span >
< / div >< p
class ="quote" >< span > 希望让人自由。 < / span >
< / p >
< / div >
< / div >
< / div >
< / li >
< li >
'''#2,编写正则,提取页面数据
#3,保存数据
import requests
import re
#csv文件是数据文件,比较方便
f = open("top250.csv", "w", encoding="utf-8")url = 'https://movie.douban.com/top250'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0'
}
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
html = response.text #页面源代码的字符串#编写正则表达式
#re.S可以正则中的.匹配换行符
#定位到每个电影信息都是 <div class="item"> 开头,中间用.*?略去所有没用的内容直到电影标题处<span class="title">此处是电影标题</span>,使用(?P<name>.*?)匹配电影标题
#然后再使用.*?略去一部分无用内容后到
obj = re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?<p>.*?导演:(?P<daoyan>.*?) .*?主演: (?P<zhuyan>.*?)<br>'r'(?P<nianfen>.*?) / (?P<guojia>.*?) / (?P<leixing>.*?) </p>.*?<span>(?P<pingjia>.*?)</span>'r'.*?<span>(?P<zongjie>.*?)</span>',re.S)
#进行正则匹配
result = obj.finditer(html)
for item in result:print('-------------------------')pianming = item.group("name")print('片名:'+pianming)daoyan = item.group("daoyan")print('导演:'+daoyan)zhuyan = item.group("zhuyan")print('主演:'+zhuyan)nianfen = item.group("nianfen").strip()#.strip()去掉字符串两端的空白符print('年份:'+nianfen)guojia = item.group("guojia")print('国家:'+guojia)leixing = item.group("leixing").strip()print('类型:'+leixing)pingjia = item.group("pingjia").strip()print('评价:'+pingjia)zongjie = item.group("zongjie")print('总结:'+zongjie)print('-------------------------')f.write(f"{pianming},{daoyan},{zhuyan},{nianfen},{guojia},{leixing},{pingjia},{zongjie}\n")#也可以使用csv模块写入数据
f.close()
response.close()
print('豆瓣TOP250数据提取完毕')
提取到的数据 top250.csv
肖申克的救赎, 弗兰克·德拉邦特 Frank Darabont,蒂姆·罗宾斯 Tim Robbins /...,1994,美国,犯罪 剧情,3199678人评价,希望让人自由。
霸王别姬, 陈凯歌 Kaige Chen,张国荣 Leslie Cheung / 张丰毅 Fengyi Zha...,1993,中国大陆 中国香港,剧情 爱情 同性,2361838人评价,风华绝代。
泰坦尼克号, 詹姆斯·卡梅隆 James Cameron,莱昂纳多·迪卡普里奥 Leonardo...,1997,美国 墨西哥,剧情 爱情 灾难,2428950人评价,失去的才是永恒的。
阿甘正传, 罗伯特·泽米吉斯 Robert Zemeckis,汤姆·汉克斯 Tom Hanks / ...,1994,美国,剧情 爱情,2373460人评价,一部美国近现代史。
千与千寻, 宫崎骏 Hayao Miyazaki,柊瑠美 Rumi Hîragi / 入野自由 Miy...,2001,日本,剧情 动画 奇幻,2471371人评价,最好的宫崎骏,最好的久石让。
美丽人生, 罗伯托·贝尼尼 Roberto Benigni,罗伯托·贝尼尼 Roberto Beni...,1997,意大利,剧情 喜剧 爱情 战争,1447047人评价,最美的谎言。
这个杀手不太冷, 吕克·贝松 Luc Besson,让·雷诺 Jean Reno / 娜塔莉·波特曼 ...,1994,法国 美国,剧情 动作 犯罪,2499838人评价,怪蜀黍和小萝莉不得不说的故事。
星际穿越, 克里斯托弗·诺兰 Christopher Nolan,马修·麦康纳 Matthew Mc...,2014,美国 英国 加拿大,剧情 科幻 冒险,2106815人评价,爱是一种力量,让我们超越时空感知它的存在。
盗梦空间, 克里斯托弗·诺兰 Christopher Nolan,莱昂纳多·迪卡普里奥 Le...,2010,美国 英国,剧情 科幻 悬疑 冒险,2268931人评价,诺兰给了我们一场无法盗取的梦。
楚门的世界, 彼得·威尔 Peter Weir,金·凯瑞 Jim Carrey / 劳拉·琳妮 Lau...,1998,美国,剧情 科幻,1954723人评价,如果再也不能见到你,祝你早安,午安,晚安。
辛德勒的名单, 史蒂文·斯皮尔伯格 Steven Spielberg,连姆·尼森 Liam Neeson...,1993,美国,剧情 历史 战争,1220622人评价,拯救一个人,就是拯救整个世界。
忠犬八公的故事, 莱塞·霍尔斯道姆 Lasse Hallström,理查·基尔 Richard Ger...,2009,美国 英国,剧情,1510867人评价,永远都不能忘记你所爱的人。
海上钢琴师, 朱塞佩·托纳多雷 Giuseppe Tornatore,蒂姆·罗斯 Tim Roth / ...,1998,意大利,剧情 音乐,1838111人评价,每个人都要走一条自己坚定了的路,就算是粉身碎骨。
三傻大闹宝莱坞, 拉库马·希拉尼 Rajkumar Hirani,阿米尔·汗 Aamir Khan / 卡...,2009,印度,剧情 喜剧 爱情 歌舞,2029878人评价,英俊版憨豆,高情商版谢耳朵。
疯狂动物城, 拜伦·霍华德 Byron Howard / 瑞奇·摩尔 Rich Moore,金妮弗·...,2016,美国,喜剧 动画 冒险,2196129人评价,迪士尼给我们营造的乌托邦就是这样,永远善良勇敢,永远出乎意料。
放牛班的春天, 克里斯托夫·巴拉蒂 Christophe Barratier,让-巴蒂斯特·莫尼...,2004,法国 瑞士 德国,剧情 音乐,1439772人评价,天籁一般的童声,是最接近上帝的存在。
机器人总动员, 安德鲁·斯坦顿 Andrew Stanton,本·贝尔特 Ben Burtt / 艾丽...,2008,美国,科幻 动画 冒险,1449959人评价,小瓦力,大人生。
无间道, 刘伟强 / 麦兆辉,刘德华 Andy Lau / 梁朝伟 Tony Leung Chiu W...,2002,中国香港,剧情 犯罪 惊悚,1522289人评价,香港电影史上永不过时的杰作。
控方证人, 比利·怀尔德 Billy Wilder,泰隆·鲍华 Tyrone Power / 玛琳·...,1957,美国,剧情 犯罪 悬疑 惊悚,679619人评价,比利·怀德满分作品。
大话西游之大圣娶亲, 刘镇伟 Jeffrey Lau,周星驰 Stephen Chow / 吴孟达 Man Tat Ng...,1995,中国香港 中国大陆,喜剧 爱情 奇幻 古装,1671957人评价,一生所爱。
熔炉, 黄东赫 Dong-hyuk Hwang,孔侑 Yoo Gong / 郑有美 Yu-mi Jung /...,2011,韩国,剧情,1015105人评价,我们一路奋战不是为了改变世界,而是为了不让世界改变我们。
触不可及, 奥利维·那卡什 Olivier Nakache / 艾力克·托兰达 Eric Toledano,...,2017,美国,喜剧 动画 奇幻 音乐,1914334人评价,死亡不是真的逝去,遗忘才是永恒的消亡。
教父, 弗朗西斯·福特·科波拉 Francis Ford Coppola,马龙·白兰度 M...,1972,美国,剧情 犯罪,1074803人评价,千万不要记恨你的对手,这样会让你失去理智。
当幸福来敲门, 加布里尔·穆奇诺 Gabriele Muccino,威尔·史密斯 Will Smith ...,2006,美国,剧情 传记 家庭,1651920人评价,平民励志片。
电影天堂爬取子页面
主页面匹配代码和子页面匹配代码预览
、
#1,提取到主页面中的每一个电影的背后的url地址#1,拿到“本站推荐电影”那一块的HTML代码#2,从刚才拿到的HTML代码中提取到href的值
#2,访问子页面,提取到电影的名称以及下载地址#1,拿到子页面的页面源代码#2,数据提取
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0"
}import requests
import re
url = 'https://dydytt.net/html/gndy/dyzz/index.html'
response = requests.get(url,headers=headers)
response.encoding='gbk'
html = response.text
# print(html)#提取“本站推荐电影”部分的HTML代码#编写正则
obj1 = re.compile(r"本站推荐电影.*?<ul>(?P<html>.*?</ul>)", re.S)
#匹配正则
result = obj1.search(html)
content = result.group('html')
#提取a标签中的href的值
#随便点开一个 : https://dydytt.net/html/gndy/dyzz/20240925/65429.html
#主url : https://dydytt.net
base_url = 'https://dydytt.net'
#编写正则
obj2 = re.compile(r"<a href='(?P<href>.*?)'>", re.S)
#匹配正则(的索引形式)
hrefhtml = obj2.finditer(content)
obj3 = re.compile(r'<div id="Zoom">.*?◎片[\s ]{1,2}名(?P<name>.*?)<br\s*\/?>.*?◎年[\s ]{1,2}代(?P<time>.*?)<br\s*\/?>.*?◎产[\s ]{1,2}地(?P<where>.*?)<br\s*\/?>'r'.*?◎类[\s ]{1,2}别(?P<style>.*?)<br\s*\/?>.*?◎语[\s ]{1,2}言(?P<lang>.*?)<br\s*\/?>.*?上映日期(?P<data>.*?)<br\s*\/?>', re.S)
obj4 = re.compile(r'<div id="Zoom">.*?◎译[\s ]{1,2}名(?P<name>.*?)<br\s*\/?>.*?◎年[\s ]{1,2}代(?P<time>.*?)<br\s*\/?>.*?◎产[\s ]{1,2}地(?P<where>.*?)<br\s*\/?>'r'.*?◎类[\s ]{1,2}别(?P<style>.*?)<br\s*\/?>.*?◎语[\s ]{1,2}言(?P<lang>.*?)<br\s*\/?>.*?上映日期(?P<data>.*?)<br\s*\/?>', re.S)
for item in hrefhtml:child_url = base_url + item.group('href')#合成完整子路径:https://dydytt.net/html/gndy/dyzz/20240927/65435.html#访问child_response = requests.get(url = child_url,headers=headers,timeout=30)child_response.encoding = 'gbk'child_html = child_response.text#print(child_html)if child_html:result3 = obj3.search(child_html)#检测编码后的片名是否乱码,如果乱码说明不是中文,则匹配译文if re.search('&', result3.group('name')):result4 = obj4.search(child_html)if result4:print('--------------------------------')print("电影片名:", result4.group('name')+'\n',"年代:", result4.group('time')+'\n',"产地:", result4.group('where')+'\n',"类别:", result4.group('style')+'\n',"语言:", result4.group('lang')+'\n',"上映日期:", result4.group('data')+'\n')else:print("译文子页面解析错误")else:if result3:print('--------------------------------')print("电影片名:", result3.group('name')+'\n',"年代:",result3.group('time')+'\n',"产地:", result3.group('where')+'\n',"类别:", result3.group('style')+'\n',"语言:", result3.group('lang')+'\n',"上映日期:", result3.group('data')+'\n')else:print(f"{child_url} 子页面解析错误")else:print("解析子页面错误")爬取结果
E:\python\python.exe C:\Users\Administrator\Desktop\python-list\pachong_learn\电影天堂爬取.py
--------------------------------
电影片名: 抓娃娃年代: 2024产地: 中国大陆类别: 喜剧语言: 汉语普通话/英语上映日期: 2024-07-13(大规模点映)/2024-07-16(中国大陆)--------------------------------
电影片名: 负负得正年代: 2024产地: 中国大陆类别: 剧情/爱情语言: 汉语普通话/粤语上映日期: 2024-08-10(中国大陆)--------------------------------
电影片名: 乘船而去年代: 2023产地: 中国大陆类别: 剧情/家庭语言: 汉语普通话/吴语/英语上映日期: 2023-06-12(上海国际电影节)/2024-04-12(中国大陆)--------------------------------
电影片名: 白日之下年代: 2023产地: 中国香港类别: 剧情/犯罪语言: 国粤双语上映日期: 2023-06-11(上海国际电影节)/2023-11-02(中国香港)/2024-04-12(中国大陆)--------------------------------
电影片名: 劫机/劫机1971(港)/亡命劫机(台)年代: 2024产地: 韩国类别: 剧情/悬疑/惊悚/灾难语言: 韩语上映日期: 2024-06-21(韩国)--------------------------------
电影片名: 图腾/女孩的成长图腾(港)/最后一次的生日派对(台)年代: 2023产地: 墨西哥/丹麦/法国类别: 剧情语言: 西班牙语上映日期: 2023-02-20(柏林国际电影节)/2023-04-22(北京国际电影节)--------------------------------
电影片名: 姥姥的外孙/金孙爆富攻略(台)/全职乖孙(港)/中国家庭/粥味奇缘年代: 2024产地: 泰国类别: 剧情语言: 泰语/潮州话上映日期: 2024-04-04(泰国)/2024-08-23(中国大陆)--------------------------------
电影片名: 孤注一掷年代: 2023产地: 中国大陆类别: 剧情/犯罪语言: 普通话上映日期: 2023-08-05(大规模点映)/2023-08-08(中国大陆)/2024-08-24(中国大陆重映)--------------------------------
电影片名: Inside Out 2年代: 2024产地: 美国类别: 剧情/喜剧/动画/奇幻/冒险语言: 国英双语上映日期: 2024-06-12(德国)/2024-06-14(美国)/2024-06-21(中国大陆)--------------------------------
电影片名: Bad Boys: Ride or Die年代: 2024产地: 美国类别: 喜剧/动作/犯罪语言: 国英双语上映日期: 2024-06-07(美国)/2024-06-22(中国大陆)--------------------------------
电影片名: IF/Imaginary Friends年代: 2024产地: 美国类别: 剧情/喜剧/奇幻语言: 国英双语上映日期: 2024-05-08(法国)/2024-05-17(美国)/2024-06-15(中国大陆)--------------------------------
电影片名: Rebel Ridge年代: 2024产地: 美国类别: 动作/惊悚语言: 英语上映日期: 2024-09-06(美国网络)--------------------------------
电影片名: 富都青年年代: 2023产地: 马来西亚类别: 剧情语言: 马来语/汉语普通话/粤语/英语/闽南语/手语上映日期: 2023-03-19(瑞士佛瑞堡影展)/2023-07-26(FIRST青年电影展)/2023-12-01(中国台湾)/2024-09-21(中国大陆)--------------------------------
电影片名: 从21世纪安全撤离年代: 2024产地: 中国大陆类别: 喜剧/科幻语言: 普通话上映日期: 2024-08-02(中国大陆)--------------------------------
电影片名: Maharaja/What Goes Around Comes Around年代: 2024产地: 印度类别: 剧情/动作/惊悚/犯罪语言: 泰米尔语上映日期: 2024-06-14(印度)进程已结束,退出代码为 0bs4基本语法
方便对html文件内的指定元素定位
from bs4 import BeautifulSouphtml = '''
<ul>
<li><a href="zhangwuji.com">张无忌</a></li>
<li id="abc"><a href="zhouxingchi.com">周星驰</a></li>
<li><a href="zhangwuji.com">张无忌</a></li>
<li><a href="zhangwuji.com">张无忌</a></li>'''# 初始化BeautifulSoup对象
page = BeautifulSoup(html, 'html.parser')
# page.find("标签名",attrs={"属性":"值"}) # 查找某个元素,只会找到一个结果
li = page.find("li",attrs={"id":"abc"})
# page.find_all("标签名",attrs={"属性":"值"})#找到一堆结果
# print(li) #<li id="abc"><a href="zhouxingchi.com">周星驰</a></li>
a = li.find("a") #可以接着使用find进行接着查找
print(a) #<a href="zhouxingchi.com">周星驰</a>
print(a.text) #周星驰 .text拿文本
print(a.get("href")) #zhouxingchi.com 使用get("属性名")拿属性li_list = page.find_all("li")
print(li_list) #[<li><a href="zhangwuji.com">张无忌</a></li>,
# <li id="abc"><a href="zhouxingchi.com">周星驰</a></li>,
# <li><a href="zhangwuji.com">张无忌</a></li>,
# <li><a href="zhangwuji.com">张无忌</a></li>]
for li in li_list:a = li.find("a")text = a.texthref = a.get("href")print(text,href)#张无忌 zhangwuji.com# 周星驰 zhouxingchi.com# 张无忌 zhangwuji.com# 张无忌 zhangwuji.com
bs4实战北京菜市场(会封ip)
#所有爬虫仅作为学习,不做非法盈利。import requests
from bs4 import BeautifulSoup
import time
import randomuser_agents = [ #构建随机用户池"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.5 Safari/605.1.15","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/115.0"
]headers = { #模拟请求头"User-Agent": random.choice(user_agents),#随机用户"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8","Accept-Language": "zh-CN,zh;q=0.9", # 模拟中文浏览器'Referer':'https://price.21food.cn/market/1006.html' #跳转前的网页}
Cookie={ #该市场的临时Cookie
"__51vcke__3GzAxR3EGfmHrtLx": "ce5eef68-9eaf-5381-9888-8859686c85fa",
"__51vuft__3GzAxR3EGfmHrtLx": "1754996232156",
"_clientkey_": "39.144.27.94",
"JSESSIONID": "aaamm8fYFl09q-vSKsiIz",
"__vtins__3GzAxR3EGfmHrtLx": "%7B%22sid%22%3A%20%2212354566-14e4-5e54-9736-0ecfa9965eb7%22%2C%20%22vd%22%3A%201%2C%20%22stt%22%3A%200%2C%20%22dr%22%3A%200%2C%20%22expires%22%3A%201755061623487%2C%20%22ct%22%3A%201755059823487%7D",
"__51uvsct__3GzAxR3EGfmHrtLx": "2",
"Hm_lvt_130a926bf7ac0d05a0769ad61f7730b2": "1754996232,1755059824",
"Hm_lpvt_130a926bf7ac0d05a0769ad61f7730b2": "1755059824",
"HMACCOUNT": "508EB5806548989F",
"_ga": "GA1.2.1654917759.1755059824",
"_gid": "GA1.2.2021476627.1755059824",
"_gat": "1",
"_ga_G8T1QC9BGW": "GS2.2.s1755059824$o1$g1$t1755059824$j60$l0$h0",
"code": "2",
"view": "188"
}f = open("北京新发地农副产品批发市场信息中心最新批发报价.csv", "w", encoding="utf-8")
#表头
f.write(f"产品名称 报价市场 最高价 最低价 平均价 报价日期 \n")
for i in range(1,5):#time.sleep(random.uniform(2, 5)) #原本是打算2~5s请求一次防止被封,但还是被封了。url = f'https://price.21food.cn/market/1006-p{i}.html' #配置url实现翻页#模拟浏览器发请求response = requests.get(url,headers=headers,cookies=Cookie)#初始化BS4对象page = BeautifulSoup(response.text,features="html5lib")ul = page.find_all('ul')[4:] #定位商品信息的ul,需要先略去前面4个普通的ul,最后也就是第五个ul中包含全部的table#所以ul数组只有ul[0]这一个元素,不需要遍历tables = ul[0].find_all('table') #tables中包含的很多个table,是一个数组for table in tables:tr = table.find('tr')#每个table中只有一个tr,进一步提取#此时已经到商品数据的最内层了,其中tr中的每个td都是一条数据tds = tr.find_all('td')#此时tds中存储着商品具体数据name = tds[0].text #[索引]是指定每个表中的第几个数据 .text是为了拿到该td标签的文本where = tds[1].text #地点price_max = tds[3].text #最高价price_min = tds[4].text #最低价price_average = tds[5].text #平均价data = tds[6].text# 格式化每一行数据,固定宽度line = f"{name:<10}{where:20}{price_max:<10}{price_min:<10}{price_average:<10}{data:<15}\n"#写入f.write(line)print(name,where,price_max,price_min,price_average,data)
xpath解析XML
from lxml import etreexml = '''
<book><id>1</id><name>野花遍地香</name><price>1.23</price><nick>臭豆腐</nick><author><nick id="10086">周大强</nick><nick id="10010">周芷若</nick><nick class="joy">周杰伦</nick><nick class="jolin">蔡依林</nick><div><nick>惹了</nick></div></author><partner><nick id="ppc">胖胖陈</nick><nick id="ppbc">胖胖不陈</nick></partner>
</book>
'''et = etree.XML(xml)
result = et.xpath("/book") # / 表示根节点
print(result) #[<Element book at 0x185cee0>]result = et.xpath("/book/name") #xpath中间的 / 是父子关系
print(result) #[<Element name at 0x201252d8>]result = et.xpath("/book/name/text()") #text()拿文本
print(result) # ['野花遍地香'] #xpath默认返回的是列表,可以索引零拿数据
print(result[0]) #野花遍地香result = et.xpath("/book//nick/text()") # //表示book的所有子孙nick
print(result) #[<Element nick at 0x1ffa4440>, <Element nick at 0..........]
#上下两个作对比,前者"/book//nick/text()"拿到了book中的所有无论辈分的nick 后者"/book/*/nick/text()"只拿book的孙子辈的,拿不到直属儿子的和重孙的。
result = et.xpath("/book/*/nick/text()") #表示book里面的任意儿子的nick儿子,也就是只要是book的孙子就可
print(result) # *表示通配符 (谁都行)result = et.xpath("/book/author/nick[@class='joy']/text()")
print(result) # ['周杰伦'] [@...] 属性控制,该示例是筛选 class属性为joy的nick标签result = et.xpath("/book/partner/nick/@id") #最后一个/表示拿到id属性
print(result) #['ppc', 'ppbc']result = et.xpath("/book//nick/@class") #得到的是有class属性的该属性值
print(result)
xpath解析HTML
from lxml import etree
html = '''
<html>
<body><ul><li><a href="http://www.baidu.com">百度</a></li><li><a href="http://www.google.com">谷歌</a></li><li><a href="http://www.sogou.com">搜狗</a></li></ul><ol><li><a href="feiji">飞机</a></li><li><a href="dapao">大炮</a></li><li><a href="huoche">火车</a></li></ol><div class="job">李嘉诚</div><div class="common">胡辣汤</div>
</body>
</html>
'''
et = etree.HTML(html)
result = et.xpath("/html/body/ul/li")
print(result) #[<Element li at 0x1f7253a0>, <Element li at 0x1f725378>, <Element li at 0x1f725350>]result = et.xpath("/html/body/ul/li[2]") #直接定义到第二个
print(result) #[<Element li at 0x1f735350>]result = et.xpath("//li") #所有的li
print(result) #[<Element li at 0x202b43c8>, <Element li at=.....,]
#也可以对该results列表进行遍历
for li in result:href = li.xpath("./a/@href") #./表示当前节点,然后可以逐级寻找text = li.xpath("./a/text()")print(href,text) #['http://www.baidu.com'] ['百度'] ......#后续的爬虫操作
xpath实战八戒网
其中获取到的单个商品信息盒子<div class = ‘class='service-card-wrap’ > 的HTML代码示例
<div data-styleonly="" source="10" positionCode="30003" cssType="4" idx="20"employerLabels="[object Object],[object Object],[object Object],[object Object],[object Object],[object Object],[object Object]"pos="20" ym="1" showWechat="true" showAd="true" class="service-card-wrap"data-v-567f2e56><div data-href="https://www.zbj.com/fw/1756267.html?pdcode=17&pos=25&ym=1&pst=searchf-list-service-2021-1-25"data-trace-id="f55ceb4b-d518-444d-ae6c-c53051665b620025"data-expose="{"type":9,"id":"1756267","traceId":"f55ceb4b-d518-444d-ae6c-c53051665b620025","pdcode":"17","xdverid":"","pst":"searchf-list-service-2021-1-25"}"data-adlinkid="" data-zzencrypt="" data-locationname=""class="serve-item serve-item-im"><div></div><div class="card-box"><a target="_blank"href="https://www.zbj.com/fw/1756267.html"data-href="https://www.zbj.com/fw/1756267.html?pdcode=17&pos=25&ym=1&pst=searchf-list-service-2021-1-25"><div class="carousel-wrapper" style="overflow:hidden;"><div height="137px" loop="loop" indicator-position=""><div><imgsrc="https://rms.zbj.com/resource/redirect?key=homesite/task/2021/08/18/系统.png/origine/1e0d1be2-3635-481f-a878-5ea66863d5b5&s.w=420&s.format=webp"width="100%" height="100%" alt="图片"></div><!----></div></div></a></div><div data-href="https://www.zbj.com/fw/1756267.html?pdcode=17&pos=25&ym=1&pst=searchf-list-service-2021-1-25"class="bot-content"><div class="price"><span>¥600</span></div><div class="name-pic-box"><div data-linkid="sp-pc-search pg-qyfw-se list-20-2-28170762"class="serve-name text-overflow-line-two oneline"><!----><span>系统界面软件ui后台管理网页设计<hl>saas</hl>设计erp设计网站</span></div></div><!----><div class="descprit-box"><!----><!----></div><div></div></div><div></div><div data-linkid="sp-pc-search pg-qyfw-se list-20-1-28170762"data-href="https://www.zbj.com/fw/1756267.html?pdcode=17&pos=25&ym=1&pst=searchf-list-service-2021-1-25"class="name-address"><div class="shop-box"><div class="shop-detail"><!----><!----><div class="shop-info text-overflow-line">艺站库设计-一站式设计解决方案</div><!----></div></div></div><div class="tool-content list tool-content-line"><pdata-linkid="sp-pc-search pg-qyfw-se list-20-3-28170762"data-pdcode="17" data-xdverid=""class="btn item-link has-wechat"><i class="consult-icon"></i>咨询TA</p><!----></div><div data-href="https://www.zbj.com/fw/1756267.html?pdcode=17&pos=25&ym=1&pst=searchf-list-service-2021-1-25"class="special-demand-blank-block"></div></div></div>
下列代码的45行获取到包含一个个类似于上面页面的代码的列表,之后的操作就是从中分离信息。
#1,拿到页面源代码
#2,从页面源代码中提取你需要的数据,价格,名称,公司名称
#八戒网 信息测试
#随意搜索一个类型 eg:saas
#然后下面会展示出各种商品业务的信息
#右键任意一个商品然后检查,进入到子div里面,然后逐级折叠,找到每个div代表一整个商品信息的盒子,
#该案例中是 service-card-wrap 为class属性的盒子
#提取该属性盒子,得到的数组是一个个商品信息的div
import requests
from lxml import etreeheaders = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0','Referer':'https://www.zbj.com/',
}
Cookie={
"_uq": "b1322d4eaf28426dacab4518c911f02e",
"uniqid": "d0136fcp9u0kt9",
"_suq": "d670f7db-3c94-4f48-93b4-0ba650f0d3fe",
"local_city_path": "qinghai",
"local_city_name": "%E9%9D%92%E6%B5%B7",
"local_city_id": "3748",
"jdymenuchannel": "1",
"organizeId": "3315536",
"orgMaster": "1",
"oldvid": "39f586b309a9c82182e4f606f3550d12",
"vid": "4ea44c920aa0ffd9abdd043fc9b806b1",
"unionJsonOcpc": "eyJvdXRyZWZlcmVyIjoiaHR0cHM6Ly9jbi5iaW5nLmNvbS8iLCJwbWNvZGUiOiIifQ==",
"Hm_lvt_a360b5a82a7c884376730fbdb8f73be2": "1752646611,1754525580,1755228858",
"HMACCOUNT": "508EB5806548989F",
"vidSended": "1",
"nsid": "s%3AkgDUM3X-Z-ZmaqHDR460DG55ZpPIJLDk.bgu%2FX7uoNWmIYjGLCQHhP9jwBqxiO6RKnxq%2BTglAUks",
"Hm_lpvt_a360b5a82a7c884376730fbdb8f73be2": "1755237251",
"s_s_c": "xhA3dh7QsA2lgP8ro4tGR5BZFW0M3FGAsgIN3UtXDegMJF3cPyZwMEBrWgcsQ%2BbbEP8KK%2B3Q68RYJTAOKXJnlg%3D%3D"
}url ='https://www.zbj.com/fw/?k=saas'
response = requests.get(url=url,headers=headers,cookies=Cookie)
response.encoding = "utf-8"
#print(response.text) #页面源代码字符串#提取数据
et = etree.HTML(response.text)
#search-result-list-service / div 找到该属性的大盒子
divs = et.xpath("//div[@class='service-card-wrap']") #开头的//是全部任意查找,无论父级是啥,无论有几层,找到该标签为止
#print(divs)
print('---------------------------------------------------')
for div in divs:#此时的div就是一条数据,对应一个商品信息title = div.xpath("./div/div[3]/div[2]/div/span//text()") # //text()是指提取span中所有的文本,包括span的子标签中的文本,此处针对于<span>开发设计<h1>saas</h1>大厂信赖</span>其中的h1内容文本saasprint("标题:" + ''.join(title))price = div.xpath("./div/div[3]/div[1]/span/text()") #之所以使用 ''.join()来字符串化列表,是因为str()方法会保留列表的[,,] 。print("价格:"+''.join(price))company = div.xpath("./div/div[5]/div/div/div/text()")print("公司:"+''.join(company))print('---------------------------------------------------')获取的结果
E:\python\python.exe C:\Users\Administrator\Desktop\python-list\pachong_learn\xpaath实战.py
---------------------------------------------------
标题:saas软件开发SaaS会员办公管理票务通信工程ERP
价格:¥5000
公司:动视湾流官方旗舰店
---------------------------------------------------
标题:SAAS软件开发/电商SAAS/医疗SAAS
价格:¥1300
公司:帮利智能科技-10年系统开发
---------------------------------------------------
标题:SAAS微信小程序会员分销商城招聘直播点餐预约
价格:¥2000
公司:南京捷创科技
---------------------------------------------------
标题:saas软件开发协同办公项目管理SaaS营销生产财务系统
价格:¥5000
公司:江东才俊官方旗舰店
---------------------------------------------------
标题:协同办公SaaS服务/OA办公系统/软件开发
价格:¥1198
公司:帮利智能科技-10年系统开发
---------------------------------------------------
标题:SAAS微信小程序会员分销商城招聘直播点餐预约
价格:¥3000
公司:南京捷创科技
---------------------------------------------------
标题:saas医疗卫生软件开发SAAS系统预约挂号在线问诊体检
价格:¥5000
公司:鸭嘴兽创新集团官方旗舰店
---------------------------------------------------
标题:SAAS|saas软件|sass|saas管理
价格:¥100
公司:MES-生产管理-防伪溯源-物联网-APS排产-WMS-车间
---------------------------------------------------
标题:发票查验|SaaS增值税电子发票真伪验证校验
价格:¥5
公司:八戒工商财税服务
---------------------------------------------------
标题:saas微信小程序开发定制作单用商城回收盲盒点餐saas
价格:¥600
公司:六牛科技-专精特新企业
---------------------------------------------------
标题:软件开发协同办公项目管理SaaS营销生产财务系统
价格:¥5000
公司:动视湾流官方旗舰店
---------------------------------------------------
标题:OA办公企业管理餐饮电商教育培训SaaS系统定制
价格:¥1000
公司:木风软件-国家高新企业15年店
---------------------------------------------------
标题:saasCRM|OA|saas会员管理系统|定制餐饮开发|进库存系统
价格:¥5000
公司:悦商东方-国家高新技术企业
---------------------------------------------------
标题:企业财务管理SaaS系统|代账云财务管理软件系统
价格:¥2988
公司:八戒工商财税服务
---------------------------------------------------
标题:生产管理软件MES开发定制SAAS系统数据档案仓
价格:¥5000
公司:江东才俊官方旗舰店
---------------------------------------------------
标题:saas微信求职招聘小程序开发西陆招聘SAAS招聘软件
价格:¥4800
公司:上海西陆科技-11年实体企业
---------------------------------------------------
标题:房产美容健身能源erp管理saas后台系统ui界
价格:¥138
公司:鹿跃设计
---------------------------------------------------
标题:SAAS定制系统开发CRM客户管理系统
价格:¥200
公司:本亚信息科技
---------------------------------------------------
标题:saas精准营销【拓客宝】精准获客系统SaaS
价格:¥5088
公司:八戒软件开发服务
---------------------------------------------------
标题:B2C商城独立站建设/SAAS电商商城开发建设
价格:¥168
公司:海贝石科技
---------------------------------------------------
标题:app开发定制外包物联网教育电商城直播安卓软件saas
价格:¥1000
公司:京科智汇重庆科技有限公司
---------------------------------------------------
标题:模板网站SAAS系统,三千套模板。无需购买服务器
价格:¥488
公司:辰君网络
---------------------------------------------------
标题:进销存|软件应用开发|SAAS软件|系统开发|成品软件
价格:¥1000
公司:跟进数科
---------------------------------------------------
标题:app开发定制物联网教育安卓苹果IOS软件saas
价格:¥10000
公司:聚诚13年国高专精特新实体企业
---------------------------------------------------
标题:软件开发ERP管理软件开发SaaS软件OA办公系统定制
价格:¥1000
公司:起搏软件-专业12年软件开发
---------------------------------------------------
标题:系统界面软件ui后台管理网页设计saas设计erp设计网站
价格:¥600
公司:艺站库设计-一站式设计解决方案
---------------------------------------------------
标题:saas微信商城NFT数字藏品前端小程序定制开发
价格:¥1000
公司:北京麦萌科技有限公司
---------------------------------------------------
标题:能源管理碳管理碳排放碳达峰项目管理SaaS生产管
价格:¥2100
公司:木风软件-国家高新企业15年店
---------------------------------------------------
标题:SaaS商城电商网站外贸独立站H5定制软件开发
价格:¥1000
公司:三只熊科技
---------------------------------------------------
标题:北京软件开发|OA|SAAS|ERP|CRM|HRO开发系统
价格:¥20000
公司:悦商东方-国家高新技术企业
---------------------------------------------------
标题:抖音支付宝微信小程序定制开发saas百度公众号开
价格:¥5888
公司:上海鼎朔-13年深耕定制化服务
---------------------------------------------------
标题:微信求职招聘小程序开发西陆招聘SAAS招聘软件
价格:¥4800
公司:上海西陆科技-11年实体企业
---------------------------------------------------
标题:车辆调度系统开发物流运输配送管理软件SAAS开发
价格:¥6888
公司:上海鼎朔-13年深耕定制化服务
---------------------------------------------------
标题:saas支付宝微信公众号小程序商城H5定制分销旅
价格:¥20000
公司:天迅达科技-国家高新技术企业
---------------------------------------------------
标题:SAAS系统定制开发/SAAS软件开发
价格:¥5000
公司:云兴软件科技
---------------------------------------------------
标题:软件开发网站定制OA系统CRM系统SaaS平台ERP系统
价格:¥107
公司:汇创时代-已获得千万级天使轮
---------------------------------------------------
标题:数智社区SaaS平台
价格:¥200
公司:天智通
---------------------------------------------------
标题:企SaaS软件办公OA进销存crm管理系统erp定制开发
价格:¥2980
公司:安徽高智网络科技有限公司
---------------------------------------------------
标题:前端html代码切图开发软件大屏硬件触摸屏展示saas
价格:¥500
公司:轻妙设计
---------------------------------------------------
标题:掌上预约服务SAAS平台
价格:¥150
公司:蓉辰软件十年品质
---------------------------------------------------
标题:快速部署-社交电商系统,saas交付/源码交付
价格:¥6800
公司:慧科盈商
---------------------------------------------------
标题:SIP服务软件定制化
价格:¥3500
公司:呼呼通saas呼叫中心
---------------------------------------------------
标题:互联网医院软件/小程序源码saas模版成品APP开发制作
价格:¥1980
公司:匠通科技-10年专注互联网开发-猪八戒行业之星
---------------------------------------------------
标题:SaaS电商APP服务|电商小程序及商城
价格:¥4999
公司:中创云服-高品质软件服务商
---------------------------------------------------
标题:模板saas建网站/模板站/微站搭建制作模板商城
价格:¥899
公司:匠通科技-10年专注互联网开发-猪八戒行业之星
---------------------------------------------------
标题:微信小程序商城SaaS开发服务
价格:¥5999
公司:千鸟互联
---------------------------------------------------
标题:软件开发/SAAS平台/多商户商城/AI/区块链
价格:¥99
公司:壹加云
---------------------------------------------------
标题:微信小程序定制开发购物商城,多门店商城,SAAS商城
价格:¥3000
公司:如峰网络
---------------------------------------------------
标题:Saas小程序开发H5公众号APP开发支持二三级分销商城
价格:¥1899
公司:珊泽网络服务
---------------------------------------------------
标题:能源管理碳管理碳排放碳达峰项目管理SaaS生产管理MES
价格:¥10000
公司:完梦科技-有梦想找完梦
---------------------------------------------------
标题:app开发定制外包物联电商城直播购物医疗安卓软件saas
价格:¥2000
公司:皮皮虾科技★专业定制开发
---------------------------------------------------
标题:SAAS点餐小程序系统开发java源码外卖预约
价格:¥1
公司:青岛蓝图科技-为您提供技术支持
---------------------------------------------------
标题:小程序定制开发saas商城前端后端游戏UI设计定制开发
价格:¥100
公司:皮皮虾科技★专业定制开发
---------------------------------------------------
标题:SAAS商城小程序系统开发java源码拼团砍价秒
价格:¥198
公司:青岛蓝图科技-为您提供技术支持
---------------------------------------------------
标题:微信抖音支付宝Saas模板小程序分销商城源码定制
价格:¥10000
公司:书坤网络--十年老店值得信赖
---------------------------------------------------
标题:WhatsApp 全渠道自动化外贸营销获客系统
价格:¥1000
公司:海贝石科技
---------------------------------------------------
标题:【定制化开发】SaaS服装餐饮批发收银,网站小程序app
价格:¥101
公司:书坤网络--十年老店值得信赖
---------------------------------------------------
标题:【旗舰产品】商城小程序开发-快速搭建商城
价格:¥4588
公司:八戒软件开发服务
---------------------------------------------------
标题:技术培训报名小程序H5公众号界面自定义可导出
价格:¥200
公司:成都辰宁科技
---------------------------------------------------
标题:AI智能/物联网/自动化控制/上位机/CS通讯/远程备份
价格:¥1000
公司:艾迪科技
---------------------------------------------------进程已结束,退出代码为 0pyquery解析HTML
from pyquery import PyQuery as pq# 1. 定义要解析的HTML内容(模拟网页结构)
html_content = """
<html><head><title>示例商城</title></head><body><div class="header"><h1>热门商品列表</h1><p class="update-time">更新时间: 2023-10-01</p></div><div class="product-list"><!-- 商品1 --><div class="product-item" data-id="1001"><img src="/img/phone1.jpg" alt="智能手机A" class="product-img"><h3 class="product-name">智能手机A</h3><p class="product-price">¥3999</p><div class="tags"><span class="tag">新品</span><span class="tag">热销</span></div></div><!-- 商品2 --><div class="product-item" data-id="1002"><img src="/img/laptop1.jpg" alt="笔记本电脑B" class="product-img"><h3 class="product-name">笔记本电脑B</h3><p class="product-price">¥5999</p><div class="tags"><span class="tag">促销</span></div></div></div><div class="footer"><a href="/about" class="link">关于我们</a><a href="/contact" class="link">联系我们</a></div></body>
</html>
"""# 2. 初始化PyQuery对象(加载HTML内容)
doc = pq(html_content)
print("===== 初始化后的文档对象 =====")
print(type(doc)) # 输出:<class 'pyquery.pyquery.PyQuery'>(确认对象类型)# 3. 提取网页标题
title = doc('title').text()
print("\n===== 网页标题 =====")
print(title) # 输出:示例商城(提取<head>中的title文本)# 4. 提取头部信息
header = doc('.header') # 通过class选择器定位头部
update_time = header.find('.update-time').text() # 在头部内查找更新时间
print("\n===== 头部信息 =====")
print("页面标题:", header.find('h1').text()) # 输出:页面标题: 热门商品列表
print("更新时间:", update_time) # 输出:更新时间: 2023-10-01# 5. 提取所有商品项
product_items = doc('.product-item') # 选择所有商品容器
print("\n===== 商品总数 =====")
print(len(product_items)) # 输出:2(当前有2个商品)# 6. 遍历商品并提取详细信息
print("\n===== 商品详细信息 =====")
for item in product_items.items(): # 使用items()遍历每个商品# 提取商品ID(自定义属性)product_id = item.attr('data-id')# 提取商品名称name = item.find('.product-name').text()# 提取商品价格price = item.find('.product-price').text()# 提取商品图片链接img_url = item.find('.product-img').attr('src')# 提取所有标签(可能多个)tags = [tag.text() for tag in item.find('.tag').items()]# 打印单条商品信息print(f"商品ID: {product_id}")print(f"名称: {name}")print(f"价格: {price}")print(f"图片链接: {img_url}")print(f"标签: {tags}")print("-" * 30)# 输出结果:# 商品ID: 1001# 名称: 智能手机A# 价格: ¥3999# 图片链接: /img/phone1.jpg# 标签: ['新品', '热销']# ------------------------------# 商品ID: 1002# 名称: 笔记本电脑B# 价格: ¥5999# 图片链接: /img/laptop1.jpg# 标签: ['促销']# ------------------------------# 7. 提取底部链接
footer_links = doc('.footer .link') # 层级选择器:footer下的link类
print("\n===== 底部链接 =====")
for link in footer_links.items():print(f"链接文本: {link.text()}, 链接地址: {link.attr('href')}")# 输出结果:# 链接文本: 关于我们, 链接地址: /about# 链接文本: 联系我们, 链接地址: /contact# 8. 动态修改HTML(演示操作功能)
doc('.header h1').text('精选商品推荐') # 修改标题文本
doc('.product-price').addClass('special-price') # 给价格添加新类名
print("\n===== 修改后的标题 =====")
print(doc('.header h1').text()) # 输出:精选商品推荐(修改后的标题)
print("价格标签的class:", doc('.product-price').attr('class')) # 输出:product-price special-price