BERT:用于语言理解的深度双向Transformer预训练【简单分析】

文章目录
- 摘要
- 当前问题
- 提出的方法
- 要点
- 实验结论
- 论文解析
- ❤️ 一起学AI
摘要
- https://arxiv.org/abs/1810.04805
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- BERT:用于语言理解的深度双向Transformer预训练
我们提出了一种名为 BERT 的新型语言表示模型,其全称为“基于 Transformer 的双向编码器表示 (Bidirectional Encoder Representations from Transformers)”。与近期语言表示模型不同,BERT 旨在通过在所有层中联合地对左右语境进行条件化,从而从无标注文本中预训练深度双向表示。因此,预训练的 BERT 模型只需增加一个输出层即可进行微调,从而在无需对特定任务架构进行大幅修改的情况下,为问答和语言推理等一系列广泛任务创建出最先进的模型。 BERT 概念上简单,且在实践中表现出强大能力。它在十一个自然语言处理任务上取得了新的最先进结果,其中包括将 GLUE 分数推高到 80.5%(绝对提升 7.7 个百分点),MultiNLI 准确率提升至 86.7%(绝对提升 4.6 个百分点),SQuAD v1.1 问答测试 F1 分数达到 93.2(绝对提升 1.5 点),以及 SQuAD v2.0 测试 F1 分数达到 83.1(绝对提升 5.1 点)。
当前问题
- 先前的微调模型,如OpenAI GPT,受到单向预训练(从左到右)的限制,无法充分利用单词两侧的上下文。
- 以前的基于特征的模型,如ELMo,提供了双向性,但通过拼接独立训练的从左到右和从右到左的LSTM实现,导致了“浅层”的双向理解。
- 需要一个统一的语言表示模型,能够在最小化任务特定架构修改的情况下,在广泛的自然语言处理任务中实现最先进的性能。
提出的方法
- BERT采用多层双向Transformer编码器架构,允许令牌在所有层中同时条件化左右上下文。
- 该模型使用两个新颖的无监督任务进行预训练:掩码语言模型(MLM)用于实现深度双向性,下一句预测(NSP)用于理解句子关系。
- 在大型语料库上预训练后,整个模型通过添加最小的任务特定输出层进行微调,以适应特定的下游自然语言处理任务,使其适用于各种应用。
要点
- 通过掩码语言建模(MLM)实现的深度双向性对于学习各种自然语言处理任务中丰富的上下文表示至关重要,其表现优于单向和浅层双向方法。
- 使用下一句预测(NSP)任务进行预训练能有效提高需要理解句子间关系的下游任务的性能。
增加模型大小(例如,从BERT_BASE到BERT_LARGE)能持续提升各种自然语言处理基准的性能,即使对于微调数据有限的任务也是如此。
实验结论
- BERT在11项自然语言处理任务上取得了新的最先进结果,包括GLUE得分80.5%(绝对提升7.7%),MultiNLI准确率86.7%(绝对提升4.6%),SQuAD v1.1 F1得分93.2,以及SQuAD v2.0 F1得分83.1。
- 消融研究证实,掩码语言模型(MLM)和下一句预测(NSP)预训练目标都至关重要,移除NSP会显著损害句子对任务的性能。
- 更大的BERT模型(例如,BERT_LARGE_)在所有测试的GLUE任务中持续优于较小的版本,展示了增加模型容量的益处。
论文解析
目录
- 概览
- 架构与设计
- 训练方法
- 实验结果与分析
- 架构比较
- 意义与影响
- 相关引用
概览
BERT(Bidirectional Encoder Representations from Transformers,来自Transformer的双向编码器表示)代表了自然语言处理领域的一项重大进展,它解决了语言模型理解上下文方面的根本局限性。由Google AI Language的研究人员开发,BERT引入了一种预训练方法,使模型能够同时考虑左右上下文,而不是仅单向处理文本。
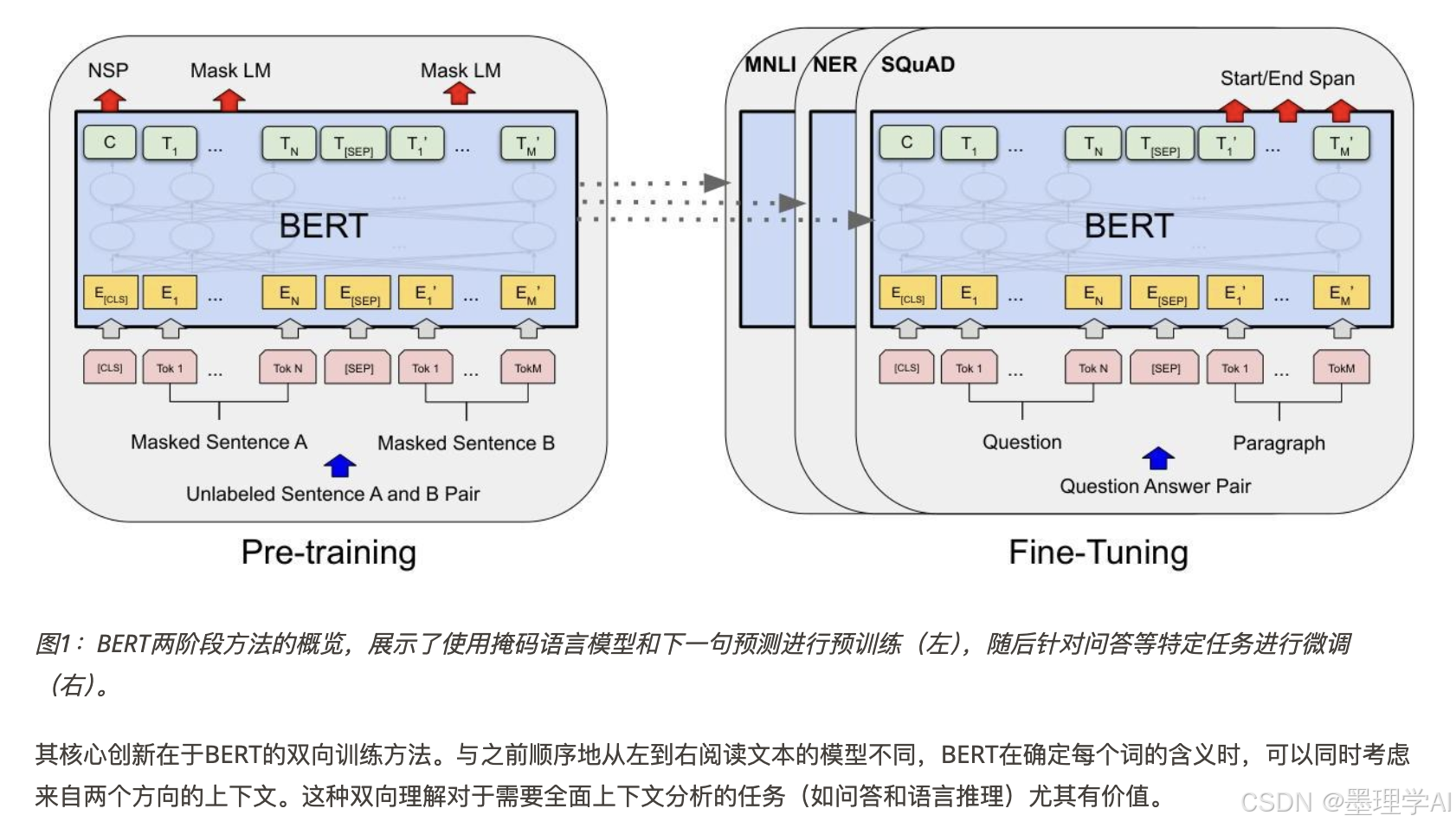
 图1:BERT两阶段方法的概览,展示了使用掩码语言模型和下一句预测进行预训练(左),随后针对问答等特定任务进行微调(右)。
图1:BERT两阶段方法的概览,展示了使用掩码语言模型和下一句预测进行预训练(左),随后针对问答等特定任务进行微调(右)。
其核心创新在于BERT的双向训练方法。与之前顺序地从左到右阅读文本的模型不同,BERT在确定每个词的含义时,可以同时考虑来自两个方向的上下文。这种双向理解对于需要全面上下文分析的任务(如问答和语言推理)尤其有价值。
架构与设计
BERT采用多层双向Transformer编码器架构,利用自注意力机制,允许每个词元关注输入序列中的所有其他词元。这种设计使模型能够捕获词语之间复杂的联系,无论它们在文本中的距离如何。
该模型有两种主要配置:
- BERT-BASE:12层,768个隐藏单元,12个注意力头(1.1亿参数)
- BERT-LARGE:24层,1024个隐藏单元,16个注意力头(3.4亿参数)
 图2:BERT的输入表示结合了词元嵌入、段嵌入(用于区分句子)和位置嵌入,以创建输入文本的综合表示。
图2:BERT的输入表示结合了词元嵌入、段嵌入(用于区分句子)和位置嵌入,以创建输入文本的综合表示。
BERT的输入表示巧妙地通过三种类型的嵌入来处理单个句子和句子对:
- 词元嵌入,使用WordPiece分词,词汇量为30,000个词元
- 段嵌入,用于区分句子对中的不同句子
- 位置嵌入,用于编码词元的顺序
特殊词元扮演着关键角色:开头的[CLS]提供用于分类任务的聚合序列表示,而[SEP]则用于分隔句子对中的句子。
训练方法
BERT的训练包括两个截然不同的阶段:在大型无标注语料库上进行预训练和任务特定的微调。
预训练目标
BERT引入了两个新颖的预训练任务,以实现双向学习:
掩码语言模型(MLM):为了克服双向条件反射会使每个词在标准语言模型中“看到自己”的限制,BERT随机掩码15%的输入词元。然后模型必须根据周围上下文预测这些被掩码的词元。掩码策略包括:
- 80%替换为
[MASK]词元 - 10%替换为随机词元
- 10%保持不变的词元
这种方法迫使模型为所有词元维护丰富的上下文表示,同时防止了简单复制输入的平凡解决方案。
下一句预测(NSP):由于许多下游任务涉及理解句子之间的关系,BERT在句子对上进行训练,其中50%是实际连续的句子,50%是随机配对的句子。这教会模型理解句子间的关系。
微调过程
微调通过添加最少的任务特定层,并在标注数据上端到端地训练整个模型,使预训练的BERT模型适应特定任务。这种方法与使用预训练表示作为固定特征的基于特征的方法形成对比。
 图3:BERT针对不同任务类型的通用微调方法:(a) 句子对分类,(b) 单句分类,(c) 基于跨度预测的问答,以及 (d) 词元级序列标注。
图3:BERT针对不同任务类型的通用微调方法:(a) 句子对分类,(b) 单句分类,(c) 基于跨度预测的问答,以及 (d) 词元级序列标注。
实验结果与分析
BERT在十一个NLP任务上取得了最先进的性能,展示了其双向方法的有效性。主要结果包括:
- GLUE基准:80.5% 总分(绝对提升7.7%)
- SQuAD v1.1:93.2 F1 分数(提升1.5分)
- SQuAD v2.0:83.1 F1 分数(提升5.1分)
- MultiNLI:86.7% 准确率(提升4.6%)
消融研究
该论文包含全面的消融研究,以验证BERT的设计选择:
双向性的影响:将BERT的掩码语言模型方法与从左到右的训练进行比较,发现在性能上存在显著差距,特别是在问答等词元级任务上。即使在单向预训练的基础上添加双向LSTM也无法与BERT的性能相媲美。
